技术总览项目搭建流程环境搭建前端基础商品分类管理分类数据封装树形列表组件前端路由规则树形列表请求数据请求接口数据网关路由转发请求跨域问题逻辑删除后端实现前端实现树形控件展开优化新增分类记录前端后端接口修改分类记录前端后端节点拖拽前端拖拽效果分类数据拖拽关联后端批量删除节点前端后端商品品牌管理列表功能对话框第三方服务对话框再优化SPU和SKU品牌关联分类SPU和SKU属性分组分页查询后端前端新增属性分组属性分组关联属性属性分组未关联属性规格参数新增规格参数查询规格参数修改规格参数销售属性商品维护商品新发布录入商品基本信息录入规格参数录入销售属性SPU管理商品管理仓储服务仓库列表查询商品库存采购需求新建采购需求查询采购需求合并采购需求采购单领取采购单采购完成整合ElasticSearch环境安装ES常用WEB API节点信息相关索引文档CURD相关BULK批量相关检索相关Query DSL的语法Aggregation聚合分析相关Mapping映射字段类型核心类型复合类型地理类型特定类型多字段muti-fields映射MappingAPI分词器Tokenizer分词相关APIik分词器自定义ik扩展词库Elasticsearch-Rest-ClientJava High Level REST Client APIRequestOptionsDocument APIsSearch APIsES在项目中的应用商品上架nested数据类型数据渲染Thymeleaf渲染商城首页渲染商品分类二三级菜单域名访问环境压力测试性能指标JMeter接口性能优化JVM内存模型JconsoleJvisualvm中间件性能影响分析压测首页性能优化策略缓存整合redis缓存商品分类数据缓存相关问题分布式锁基础实现Redisson缓存数据一致性SpringCache配置使用自动配置原理相关注解相关概念SpringCache的不足前台检索业务搭建检索页面检索逻辑检索页面DSL语句用Java动态构建DSL封装检索结果前端数据渲染拼接检索参数面包屑导航商品详情线程池详解业务逻辑异步编排认证服务短信验证码阿里云短信验证码服务用户注册业务用户登录账号/手机+密码登录社交登录单点登录开源项目业务实现分布式session共享Session的使用问题集群session共享子域session共享分布式集群session解决方案自定义SpringSessionSpringSession核心原理购物车服务页面跳转后端获取购物车添加购物车更改购物项消息队列RabbitMQDocker安装RabbitMQWEB界面简介基本用法延时队列SpringBoot整合RabbitMQ整合流程自动配置原理AmqpAdminAPIRabbitTemplateAPI定制消息序列化器@RabbitListener可靠性投递订单服务页面环境订单中心登录拦截订单确认页Feign远程调用携带cookie远程调用异步编排页面数据渲染提交订单接口幂等性方案订单提交幂等性问题创建订单逻辑付款页渲染本地事务分布式系统定理分布式事务Seata分布式事务异步确保型方案消息可靠性投递支付业务支付宝支付生产环境沙箱环境内网穿透电脑网站支付用户同步通知页服务器异步通知收单加密算法秒杀业务后台系统后端设计秒杀商品上架定时任务Cron表达式SpringBoot整合定时任务分布式场景查询秒杀商品高并发系统设计秒杀流程后端总览前端总览技术设计亮点问题解决方案项目前端设计商品分类树形列表设计跨域解决方法逻辑删除树形控件展开优化【重点】新增和修改数据请求参数校验AOP的应用场景MP分页查询Object规范SPU和SKUES节点启动报错docker无法拉取镜像ES文档映射设计响应类R解决服务调用端类型自动转换问题商品库存返回值处理Nginx携带客户端的请求头JMeter压测大量异常的问题Jvisualvm更改插件地址性能优化策略缓存操作对象问题缓存失效相关问题检索商品页面的DSL语句构建商品详情页面用户注册用户注册流程引入短信接口后的业务流程POST请求处理后转发GET请求处理接口报错用户登录方案平台账号密码登录社交账号登录注册单点登录session共享SpringSession原理购物车方案Feign远程调用丢失请求头接口幂等性分布式系统定理消息可靠投递支付宝支付业务流程秒杀商品上架定时任务方案秒杀库存预热简历项目经验分布式基础要点附录
技术总览
技术栈
后端:SpringBoot、SpringCloud、Docker、MybatisPlus、MySQL、Redis、Nacos、Nginx、JSR303、Elasticsearch、Redisson、SpringCache、RabbitMQ
前端:VUE、ELEMENT-UI
测试:Jmeter
业务逻辑:商品服务、购物车、订单、结算、库存、秒杀
分布式架构:SpringCloud+Nacos【配置中心、注册中心】、Sentinel流量保护、Seata分布式事务控制、网关SpringCloud GATEWAY、Ribbon负载均衡、远程调用OpenFeign、链路追踪Slueth、缓存、session同步方案、全文商品信息检索ES、异步编排、线程池、压力测试、性能调优、redis分布式锁、MySQL主从分片集群、缓存Redis集群、RabbitMQ镜像集群队列【实现服务异步解耦和分布式数据一致性】、线上监控系统Prometheus+grafana【Prometheus对Sleuth搜集的调用链路信息进行聚合分析,由grafana进行可视化和展示,通过Prometheus提供的AlterManager实时得到服务的告警信息以邮件和手机短信的方式通知给开发和运维人员】、ELK【ES、Kibana、LogStash】日志处理【存储和文书检索、LogStash负责搜集日志并存入ES、使用Kibana从ES中检索相关的信息快速定位线上的问题】、服务熔断降级、高并发场景下的编码方式、阿里云对象存储服务存储图片和视频等
集群架构:一主两从k8s集群、使用KUBESPHERE平台控制整个k8s集群、持续集成持续部署【CI/CD】【即开发人员敲完代码,以流水线的形式自动化的打包、发布、测试、运行、上线;开发人员将代码提交到远程库、运维人员通过自动化部署工具从远程库获取代码打包成Docker镜像,使用K8s集成Docker服务组成集群以Docker容器的方式进行运行】、jenkins自动化部署
商业模式:B2C商家对用户【商业零售】
微服务总览:
前端:admin-vue【后台管理系统,码云人人开源
/renren-security】、shop-vue前台界面分布式架构服务治理:Nacos注册配置中心、Seata分布式事务、Sentinel服务容错降级限流、OpenFeign服务远程调用和负载均衡、Slueth服务调用链路追踪【zipkin可视化追踪】、GATEWAY API网关【限流、鉴权、熔断降级、过滤、路由、负载均衡】,使用Prometheus+grafana对应用进行监控
业务微服务群:商品、支付、优惠、用户、仓储、秒杀、订单、检索、中央认证【单点登录、社交注册】、购物车、后台管理【新增商品】
第三方服务:物流信息检索、短信发送、金融支付、退款、对账、用户身份认证
数据支撑层:缓存redis集群、数据持久化mysql集群【使用shardingSphere对mysql进行分库分表操作】、消息队列RabbitMQ集群、全文检索【ES集群】、图片视频存储【阿里云OSS】
软件版本
【软件环境安装事项】
mysql8.x的文件位置由
/etc/mysql变化为/etc/mysql/conf.d,容器数据卷的挂载需要由-v /mydata/mysql/conf:/etc/mysql \改为-v /mydata/mysql/conf:/etc/mysql/conf.d \
软件 原始版本 备注 VirtualBox 6.0.12 Vagrant 2.2.5 docker 19.03.2 docker -vmysql 5.7.27 redis 4.0 maven 3.6.1 nodejs 10.16.3 LTS SpringBoot 2.1.8.RELEASE MyBatisPlus 3.2.0 Lombok 1.18.8 Httpcore 4.4.12 Commons-lang 2.6 Mysql驱动 8.0.17 servlet-api 2.5 nacos-server 1.1.4 gson 2.8.5 nginx 1.10 Jmeter 5.2.1 Elasticsearch 7.4.2 Kibana 7.4.2 Redisson 3.12.0 SpringCache 2.1.8.RELEASE SpringSession 2.1.8.RELEASE RabbitMQ 4.0.3 Seata 2.1.0.RELEASE alipay-sdk-java 4.9.28.ALL 【IDEA插件】
Lombok【简化开发】
MyBatisX【MP开发的,从一个Mapper方法快速定位到XML文件】
Gitee【提交代码到码云】
【VSCode插件】
Auto Close Tag【自动开闭标签】
Auto Rename Tag【】
Chinese简体中文包【】
ESLint【ES语法检查】
HTML CSS Support【对html和css语法提示】
JavaScript(ES6) code snippets【JS的ES6语法提示】
Live Server【】
open in browser【在浏览器打开页面的】
Vetur【开发vue项目最常用的工具】
项目搭建流程
环境搭建
下载VirtualBox7.0.41
下载Vagrant2.4.1
搭建虚拟机环境CentOS7
🚁:Centos对VirtualBox和Vagrant的版本要求
📓:VirtualBox和Vagrant必须是最新版才能通过vagrant连接VirtualBox快速安装Centos7
安装Docker
Docker安装mysql:5.7.27
mysql:5.7有一个文件老是拉取不下来,最后拉的5.7.27;原来的系统默认安装在C盘,重装了,你猜怎么着,又能装了,最后还是装的5.7
mysql的默认字符编码是拉丁,需要修改配置文件将字符编码改为utf-8
镜像拉取不了是DNS服务器的设置问题,解决方法看linux操作手册的docker常见问题
xxxxxxxxxxdocker run -p 3306:3306 --privileged=true --name mysql \-v /malldata/mysql/log:/var/log/mysql \-v /malldata/mysql/data:/var/lib/mysql \-v /malldata/mysql/conf:/etc/mysql \-e MYSQL_ROOT_PASSWORD=Haworthia0715 \-d mysql:5.7【mysql开放root用户远程连接权限】
在mysql本地客户端输入以下两行代码,无需重启可以直接连
xxxxxxxxxxgrant all privileges on *.* to 'root'@'%' identified by 'Haworthia0715' with grant option;flush privileges;Docker安装redis:6.0.8
老师的太老了,自己拉了一个熟悉的
容器数据卷一定要先创建
/malldata/redis/conf/redis.conf文件再进行挂载,否则会自动创建redis.conf目录,如果强行修改为文件,redis会直接停掉;先创建了文件就会将容器数据卷识别为对应的文件,一旦没匹配上配置文件,外部任何配置都不会生效使用Redis Desktop Manager连接redis
redis等其他镜像创建容器实例没指定随docker启动而自动启动可以通过命令
docker update redis --restart=always追加设置xxxxxxxxxxdocker run -p 6379:6379 --privileged=true --name redis -v /malldata/redis/data:/data \-v /malldata/redis/conf/redis.conf:/etc/redis/redis.conf \-d redis:6.0.8 redis-server /etc/redis/redis.conf创建商城数据库表
使用数据库脚本创建的,SQLYog的脚本运行一定要点击一次性运行所有查询,否则可能涉及局部脚本操作,而且需要根据数据的位置执行查询,很容易发生各种错误
引入
人人开源/renren-fast后台管理系统后端项目使用的是老师的版本
3.0.0使用该项目的数据库创建后台管理系统数据库
mall_admin表,并修改项目直到项目成功运行因为后端为了尽量和老师的版本保持一致,包括
SpringBoot和Cloud的版本,因为时间久了一旦出现问题很可能找不到合适的解决办法,所以项目后端直接使用的老师的renren-fast交付代码,保持后端版本的一致真特么服了,使用老师交付的代码因为前后台系统的版本不一致存在跨域问题,跨域类的写法发生了变化,老版本SpringBoot的跨域无法适应新的前台请求,这里renren-fast的前后台代码都使用的人人开源仓库最新克隆的,单后台管理系统SpringBoot的版本是2.6.6的
引入
人人开源/renren-fast-vue后台管理系统前端项目这个是直接在Gitee上拉取的,看了版本和老师的一样都是1.2.2
安装nodejs v10.16.3(LTS),直接拿着对应版本到百度搜也会跳出官方下载页面,直接去官网找不一定找得到,直接下载Windows 64-bit Installer: https://nodejs.org/dist/v10.16.3/node-v10.16.3-x64.msi
VScode调出控制台的快捷键是Ctrl+`
renren-fast-vue和老版本变化不大,package.json中少量版本变化,且直接使用老师的交付代码会因为老师整合服务修改了前端的端口和路径问题,导致项目验证码无法正常请求到后端的接口【导致验证码不显示】和跨域设置,这里前端页面直接使用人人开源上克隆的最新版
这里更换多个版本出现无法使用命令
npm install安装的情况,经过评论区指出是node-sass4.9.0安装失败的问题【但是不需要根据评论的下载python,就是node-sass的下载和nodejs的版本适配问题】,而且nodejs的版本和node-sass的版本存在对应关系,对应关系通过网址https://www.npmjs.com/package/node-sass查看;1. 在使用nodejs10.16.3的情况下把项目文件夹下的package.json里面的node-sass4.9.0改成4.9.2;第二将原来的node_modules文件夹删除【也可以使用命令npm rebuild node-sass或者npm uninstall node-sass重装或者卸载node-sass】;第三在项目文件下打开CMD窗口执行npm i node-sass --sass_binary_site=https://npm.taobao.org/mirrors/node-sass/单独安装node-sass[因为使用淘宝镜像会去从github下载,但是下载并不会成功],没报错就是下载成功了;在CMD窗口执行npm install对项目进行安装,没报错就是成功;然后就可以在VScode上使用npm run dev运行项目了使用
人人开源/renren-generator逆向工程生成后端各个服务模块的结构修改端口并测试接口是否能够正常访问这个直接使用的老师的版本,傻逼Maven有些报红,折腾了好久,不影响执行,通过访问控制台;在控制面板选择表生成对应的实体类和前端包括端口,以浏览器下载的方式将main目录和Resources目录下的mapper文件以及vue的前端代码发送给用户,用户在对应模块下自行替换,不像mybatis的插件,这个更加强大,连接口的方法都能生成甚至前端代码都能生成
直接拷贝替换对应main、mapper目录;vue文件不要删,后面会用到,据说这个逆向生成的代码中已经包含了前端例如三级分类的代码和前端的增删改查功能【有点逆天啊】,一般基础的功能前端后端都用逆向工程生成,只有核心的业务逻辑前后端自定义编写
重新搞吧,克隆最新的
人人开源/renren-generator,因为生成的代码中需要使用人人开源/renren-fast中的工具类PageUtils和Query工具类反正人人开源的就直接现场克隆就完事了,在人人开源代码生成器生成的代码中需要依赖renren-fast中的工具类,需要进行拷贝到公共工程下,并在其他模块对公共工程进行引入,同时公共模块下需要引入相关的依赖才能让生成的代码不报错
引入的相关依赖包括mybatisPlus、Lombok、httpcore、commons-lang、mysql驱动[mysql-connector-java]、servlet-api
定义统一返回类R,R继承了
HashMap<String,Object>这个R是从renren-fast项目拷贝过来的
x/*** 返回数据** @author Mark sunlightcs@gmail.com*/public class R extends HashMap<String, Object> {private static final long serialVersionUID = 1L;public R() {put("code", 0);put("msg", "success");}public static R error() {return error(HttpStatus.SC_INTERNAL_SERVER_ERROR, "未知异常,请联系管理员");}public static R error(String msg) {return error(HttpStatus.SC_INTERNAL_SERVER_ERROR, msg);}public static R error(int code, String msg) {R r = new R();r.put("code", code);r.put("msg", msg);return r;}public static R ok(String msg) {R r = new R();r.put("msg", msg);return r;}public static R ok(Map<String, Object> map) {R r = new R();r.putAll(map);return r;}public static R ok() {return new R();}public R put(String key, Object value) {super.put(key, value);return this;}}
前端基础
学习前端知识
笔记在
E:\JavaStudy\project\ol_edu\vpc_ol_js目录下
商品分类管理
分类数据封装
商品分类数据的三级封装逻辑和实现、重点关注这个逻辑中一级分类和二级分类的主键值肯定会发生大于Long类型常量池范围的情况,此时子分类的
parent_cid和父类的catId不能再使用==来过滤流判断是否类的子分类【因为即使值相等也会因为==判断引用地址是否相同始终返回false,导致子分类直接误判,会发生主键太大的一级分类和二级分类的子分类数据全部丢失,表现在前端的效果是子分类数据能成功添加,但是永远显示不出子分类列表】,必须使用Long类型的equals方法来对较大Long类型主键判断分类的parent_cid和父类的catId值相等
商品三级分类
三级分类是很常用的功能
导入pms_category中的所有商品分类数据
查询所有分类并以父子分类方式的结构组装起来方便后台管理系统维护
封装逻辑
查询出所有的商品分类数据,因为mybatis的缓存功能,只有第一次查询需要真正访问数据库,此后访问直接从缓存中获取商品分类数据,使用java8新特性stream流的filter对商品分类进行过滤筛出一级分类,使用map方法对每个一级分类根据当前分类和总的分类列表查询出所有子分类,对一级分类列表的流使用sorted方法按照sort字段进行排序,使用collect聚合函数转成list集合并返回,
对查询某个分类的所有子分类的实现是查询出当前分类的下一级子分类,对查询出的子分类递归调用当前方法查询出二级分类的所有子分类,递归跳出的条件是当前子分类没有子分类,即过滤得到流的元素个数为0,不再执行后续的map方法继续查找所有子分类;查询完成后对每级子分类进行排序并返回每级子分类的List集合
代码实现
卧槽,这里有个数据库mybatis的查询数据缓存【据大佬说是mybatis二级缓存】,能节省超多时间,对数据的封装递归写的这么烂也只需要20ms,但是数据库查询1000条数据要170到180ms,写的烂也不存在啊,数据库查询才是耗时比较久的
xxxxxxxxxx/*** @return {@link List }<{@link CategoryEntity }>* @描述 查找所有商品分类,以树形结构对商品分类数据进行封装,* @性能 junit显示一千条数据耗时560ms,为什么浏览器显示响应时间25ms-33ms* 这个可能是自带缓存啊,下面这段代码服务器重启以后第一次执行是198ms,此后每次执行都是18-20ms,* 但是junit执行同样的代码每次都需要560ms* 实际第一次这段代码执行需要200ms,此后每次执行只需要20ms左右,浏览器响应也只需要25ms左右,junit的测试结果* 和直接在程序中测差别很大啊* 这里第一次请求耗时长是因为后续数据库查询走的mybatis的缓存* @author Earl* @version 1.0.0* @创建日期 2024/02/23* @since 1.0.0*/public List<CategoryEntity> listWithTree(){//long initTime=System.currentTimeMillis();//1. 查询所有商品分类List<CategoryEntity> categoryList = baseMapper.selectList(null);//2. 组装商品分类为父子结构//找到所有一级商品分类并封装成list集合,一级商品分类的标志是字段parent_cid为0,使用Stream流实现List<CategoryEntity> firstLevelCategory = categoryList.stream().filter(category -> category.getParentCid() == 0).map(curCategory->{//获取当前商品的子商品分类需要传递当前商品和所有商品curCategory.setChildren(getChildren(curCategory,categoryList));return curCategory;}).//排序按照升序排序,即sort字段小的排在前面sorted((category1,category2)->(category1.getSort()==null?0:category1.getSort())-(category2.getSort()==null?0:category2.getSort())).collect(Collectors.toList());//System.out.println(System.currentTimeMillis()-initTime+"ms");return firstLevelCategory;}/*** @param rootCategory 当前根商品分类* @param categoryList 所有商品分类* @return {@link List }<{@link CategoryEntity }>* @描述 获取当前商品分类的所有子分类* @author Earl* @version 1.0.0* @创建日期 2024/02/23* @since 1.0.0*/private List<CategoryEntity> getChildren(CategoryEntity rootCategory, List<CategoryEntity> categoryList) {List<CategoryEntity> children = categoryList.stream().//所有的流筛选出当前分类的子一级分类//filter(category -> category.getParentCid() == rootCategory.getCatId()).//子分类可能还有子分类,对当前子分类递归求出其所有子分类,跳出递归的条件是最后一级分类没有子分类自然无法执行map方法//这里判断当前分类的parentCid和父分类的catId不能使用等号比较值的大小,因为数据库表初始的一级分类id都比较小,在-128-127范围内,Long类型数据以及其他的包装类都实现了常量池,主键小的时候==永远可以判断值是否相等,但是后期创建的一级分类和二级分类的主键值肯定会超过这个范围,一旦超过这个范围,即使父id和子的pid都是值相等的Long类型也是两个完全不同的对象,用==除了基本数据类型是直接判断值,引用数据类型都是比较引用的内存地址;此时使用Long等包装类的equals方法就是判断的两个Long类型对应的基本类型值是否相等filter(category -> rootCategory.getCatId().equals(category.getParentCid())).map(category->{category.setChildren(getChildren(category,categoryList));return category;}).//对子分类按照表category的sort字段进行升序排序sorted((category1,category2)->(category1.getSort()==null?0:category1.getSort())-(category2.getSort()==null?0:category2.getSort())).collect(Collectors.toList());return children;}
树形列表组件
使用ELEMENT-UI的树形列表控件对三级商品分类数据进行展示和管理
包括前端路由规则、分类树形列表控件、树形列表控件优化
前端路由规则
启动后台管理系统前台
renren-fast-vue和后台模块renren-fast对商品分类进行联调先启动后台系统的服务器模块在启动前端,因为需要获取验证码并对用户名和密码进行验证
在后台管理系统前台的系统管理--菜单管理--新增--目录能创建出和系统管理一样的侧边栏菜单,选择菜单是创建该菜单的二级目录,也是从新增点进去选择已有目录创建菜单

菜单数据和目录数据都会进入renren-fast的对应数据库表mall_admin的sys_menu表中,生成对应的记录
需要在分类维护菜单的页面中对商品分类信息进行增删改
页面路由的规则是
http://localhost:8001/#/路由路径,路由路径对应菜单管理中每个菜单的菜单URL把/换成-如菜单URL
product/category对应页面的路由路径是product-category,完整路径是http://localhost:8001/#/product-category路径和页面的匹配规则是
sys-role对应文件src\views\modules\sys\role.vue,即菜单页面的根目录是src\views\modules,短横线前面的sys是目录名,短横线后面的role是文件名,文件以.vue作为后缀这种.vue文件就是vue中的一个单文件组件,在
E:\JavaStudy\project\ol_edu\vpc_ol_js\vue_demo\vue-demo\APP.vue中有介绍,整个单文件组件的页面会展示在菜单窗口中对应这种规则,商品的菜单URL对应的文件是
src\views\modules\product\category.vue,用自定义模版快捷键vue生成对应的单文件组件模板VSCode自定义文件模板在
C:\Users\Earl\AppData\Roaming\Code\User\snippets目录下,文件--首选项--配置用户片段也能查看已有的自定义文件模板
树形列表
商品分类列表前端组件
树形展示列表使用Element-ui的Tree属性控件
【树形控件】
el-tree标签的data是要展示的所有数据即json数组,props是属性设置【设置每个目录的子目录属性名和要展示的值的属性名】,@node-click是绑定的单击函数
xxxxxxxxxx<el-tree :data="data" :props="defaultProps" @node-click="handleNodeClick"></el-tree><script>export default {data() {return {data: json数组,defaultProps: {//children指json数组下的哪个属性的值是作为节点的子节点的children: 'children',//label是指json数组以及子节点哪个属性的值是作为要展示的文字的label: 'label'}};},methods: {handleNodeClick(data) {console.log(data);}}};</script>【自定义树形节点内容】
可以使用
render-content和scope-slot两种方式删除增加节点,项目使用scope-slot方式render-content是给el-tree组件中添加一个:render-content="renderContent"属性,这里很奇怪,明明是双向绑定的写法,但是这里的renderContent是定义在methods中的一个函数,该方法直接返回节点管理的dom元素【图层包含按钮和点击事件】scope-slot是直接在组件中添加节点管理组件,slot-scope是vue中的插槽机制,即把上诉方法返回的Dom元素写在树形结构组件中【树形节点的管理组件】
这个
@node-click="handleNodeClick"单机函数没啥用,可以删掉xxxxxxxxxx<el-tree:data="categoryTree":props="defaultProps"@node-click="handleNodeClick"><!--{ node, data }是一种解构写法,node是当前标签的节点,这个node不是从数据库获取的每个商品分类对象,而是树形控件自己封装的节点对象,包含节点的额外信息,比如节点是否被选中,节点所属的层级等等,通过node.label可以获取到tree节点的属性值;data是对应树形节点对应的从数据库获取到的商品封装的数据,是完整的每个节点的原始数据--><span class="custom-tree-node" slot-scope="{ node, data }"><span>{{ node.label }}</span><span><el-button type="text" size="mini" @click="() => append(data)">Append</el-button><el-button type="text" size="mini" @click="() => remove(node, data)">Delete</el-button></span></span></el-tree>树形控件优化
点击箭头展开
此时点击整个节点都会弹出节点的子节点,点击删除或者增加节点也会展开子节点,el-tree中有一个属性
expand-on-click-node,该属性值设置为true就表示点击整个节点,节点的所有子节点都会展开;设置成false表示只有点击节点前的箭头节点的子节点才会展开xxxxxxxxxx<el-tree:data="categoryTree":props="defaultProps":expand-on-click-node="false"></el-tree>一级菜单和二级菜单显示append按钮,三级菜单不能增加子菜单,没有子菜单的菜单才能显示Delete按钮
使用v-if来对按钮的显示逻辑进行实现
node.level树形显示当前节点为几级节点,一级值为1,二级值为2,一二级节点给添加节点按钮node.childNodes.length是子节点数组的元素个数,为0表示没有子节点,没有子节点给删除按钮xxxxxxxxxx<el-tree:data="categoryTree":props="defaultProps":expand-on-click-node="false"><span class="custom-tree-node" slot-scope="{ node, data }"><span>{{ node.label }}</span><span><el-button v-if="node.level<=2" type="text" size="mini" @click="() => append(data)">Append</el-button><el-button v-if="node.childNodes.length==0" type="text" size="mini" @click="() => remove(node, data)">Delete</el-button></span></span></el-tree>给商品分类添加选择框
商品分类后期存在批量选中的需求,el-tree的
show-checkbox属性,意思是节点是否可被选择,默认是false,只要在el-tree添加该属性或者赋值为true节点就能显示选中框,而且自带全选和全不选的功能xxxxxxxxxx<el-tree:data="categoryTree":props="defaultProps":expand-on-click-node="false"show-checkbox>...</el-tree>补充<el-tree:data="categoryTree":props="defaultProps":expand-on-click-node="false"show-checkbox="true">...</el-tree>和上述写法效果是一样的为每个节点添加唯一表示属性
el-tree标签的
node-key属性可以用来作为树节点的唯一标识,每个节点的该属性值在整颗树中应该是唯一的,每个节点的主键是唯一的,所以可以将商品分类的主键id赋值给node-key属性,只需要写属性名catId,树形组件会自动去找每个节点原始数据的指定catId属性xxxxxxxxxx<el-tree:data="categoryTree":props="defaultProps":expand-on-click-node="false"show-checkboxnode-key="catId">...</el-tree>
请求数据
请求后端商品分类接口获取商品分类树形列表数据
包括renren-fast-vue向api接口发送请求的方式、网关对请求的转发以及请求跨域处理
请求接口数据
renren-fast-vue前端向后端发起数据请求的方法,响应数据结构、URL配置文件
向后台商品系统发送获取商品树形列表请求
在vue对象的
created方法中【页面数据和方法已经加载,但是还没有渲染,此时可以访问this实例访问当前的vue对象】调用获取菜单分类的方法getCategoryTree(),在getCategoryTree()方法中定义发送请求获取数据renren-fast前台发送请求的方式
注意此时发送请求的ip和端口还是前台项目的ip和端口,需要改为后台管理系统的ip和端口
【GET请求方式】
xxxxxxxxxx// 获取数据列表getDataList () {this.dataListLoading = true//下面的代码是向服务器发送请求获取数据的脚手架代码this.$http({//括号中是请求的地址,需要带/url: this.$http.adornUrl('/sys/role/list'),//请求方式method: 'get',//请求参数,k:v键值对,没有请求参数就直接把params属性删掉即可params: this.$http.adornParams({'page': this.pageIndex,'limit': this.pageSize,'roleName': this.dataForm.roleName})//发送成功执行then方法,then是ES6的异步编排promise的用法,详细笔记见E:\JavaStudy\project\ol_edu\vpc_ol_js\es6_std\12_promise语法.html}).then(({data}) => {if (data && data.code === 0) {this.dataList = data.page.listthis.totalPage = data.page.totalCount} else {this.dataList = []this.totalPage = 0}this.dataListLoading = false})},【POST请求方式】
xxxxxxxxxxremove(node, data) {var ids = [data.catId]this.$http({url: this.$http.adornUrl("/product/category/delete"),method: "post",data: this.$http.adornData(ids, false),}).then(({ data }) => {console.log("删除成功")//这个是重新发送请求刷新列表数据,因为列表数据和树形列表是双向绑定关系,更新了数据自然会重新渲染树形列表,注意这个不是跳转路由this.getCategoryTree()});},【根据格式抽取出代码片段】
在VSCode的文件--首选项--用户代码片段,在vue组件模板中追加下列发送请求的模板
下面是完整模板,该文件包含3个模板,通过在需要的地方输入prefix指定的字符串生成模板,其中的
http-get 请求和http-post 请求是追加的renren-fast-vue发送请求的模板,分别通过httpget和httppost在指定地方快速生成模板xxxxxxxxxx//{// Place your 全局 snippets here. Each snippet is defined under a snippet name and has a scope, prefix, body and// description. Add comma separated ids of the languages where the snippet is applicable in the scope field. If scope// is left empty or omitted, the snippet gets applied to all languages. The prefix is what is// used to trigger the snippet and the body will be expanded and inserted. Possible variables are:// $1, $2 for tab stops, $0 for the final cursor position, and ${1:label}, ${2:another} for placeholders.// Placeholders with the same ids are connected.// Example:// "Print to console": {// "scope": "javascript,typescript",// "prefix": "log",// "body": [// "console.log('$1');",// "$2"// ],// "description": "Log output to console"// }{"生成 vue 模板": {"prefix": "vue","body": ["<template>","<div></div>","</template>","","<script>","//这里可以导入其他文件(比如: 组件, 工具 js, 第三方插件 js, json文件, 图片文件等等) ","//例如: import 《组件名称》 from '《组件路径》 ';","","export default {","//import 引入的组件需要注入到对象中才能使用","components: {},","props: {},","data() {","//这里存放数据","return {","","};","},","//计算属性 类似于 data 概念","computed: {},","//监控 data 中的数据变化","watch: {},","//方法集合","methods: {","","},","//生命周期 - 创建完成(可以访问当前 this 实例) ","created() {","","},","//生命周期 - 挂载完成(可以访问 DOM 元素) ","mounted() {","","},","beforeCreate() {}, //生命周期 - 创建之前","beforeMount() {}, //生命周期 - 挂载之前","beforeUpdate() {}, //生命周期 - 更新之前","updated() {}, //生命周期 - 更新之后","beforeDestroy() {}, //生命周期 - 销毁之前","destroyed() {}, //生命周期 - 销毁完成","activated() {}, //如果页面有 keep-alive 缓存功能, 这个函数会触发","}","</script>","<style lang='scss' scoped>","//@import url($3); 引入公共 css 类","$4","</style>"],"description": "生成 vue 模板"},"http-get 请求": {"prefix": "httpget","body": ["this.\\$http({","url: this.\\$http.adornUrl(''),","method: 'get',","params: this.\\$http.adornParams({})","}).then(({data}) => {","})"],"description": "httpGET 请求"},"http-post 请求": {"prefix": "httppost","body": ["this.\\$http({","url: this.\\$http.adornUrl(''),","method: 'post',","data: this.\\$http.adornData(data, false)","}).then(({ data }) => { });"],"description": "httpPOST 请求"}}$http
$http是项目定义的工具类,定义在
utils/httpRequest.jsxxxxxxxxxximport Vue from 'vue'import axios from 'axios'import router from '@/router'import qs from 'qs'import merge from 'lodash/merge'import { clearLoginInfo } from '@/utils'const http = axios.create({timeout: 1000 * 30,withCredentials: true,headers: {'Content-Type': 'application/json; charset=utf-8'}})/*** 请求拦截,每次发请求都会拦截请求从cookie中获取到后台服务器存入cookie的token放到请求的头信息中供后端服务器校验并进行权限控制*/http.interceptors.request.use(config => {config.headers['token'] = Vue.cookie.get('token') // 请求头带上tokenreturn config}, error => {return Promise.reject(error)})/*** 响应拦截,发生401错误说明token失效,用户没有登录,router.push跳转登录页面*/http.interceptors.response.use(response => {if (response.data && response.data.code === 401) { // 401, token失效clearLoginInfo()router.push({ name: 'login' })}return response}, error => {return Promise.reject(error)})/*** 请求地址处理,请求地址拼接* @param {*} actionName action方法名称,actionName就是用户指定的接口uri,和index.js中定义的协议、IP和端口号等一起拼接成完整url*/http.adornUrl = (actionName) => {// 非生产环境 && 开启代理, 接口前缀统一使用[/proxyApi/]前缀做代理拦截!非生产环境和生产环境的拼串方式不同return (process.env.NODE_ENV !== 'production' && process.env.OPEN_PROXY ? '/proxyApi/' : window.SITE_CONFIG.baseUrl) + actionName}/*** get请求参数处理,上面的示例中已经用了params参数,会通过该参数调用http.adornParams方法,这里就是get请求拼接请求参数的方法,传递的参数写在params对象中* @param {*} params 参数对象* @param {*} openDefaultParams 是否开启默认参数?默认参数是时间戳,这里的开启默认参数的意思是如果开启默认参数,每次发送请求就会在get请求后拼接时间戳,避免浏览器的ajax的get请求结果被浏览器缓存*/http.adornParams = (params = {}, openDefaultParams = true) => {var defaults = {'t': new Date().getTime()}return openDefaultParams ? merge(defaults, params) : params}/*** post请求数据处理* @param {*} data 数据对象* @param {*} openDefaultData 是否开启默认数据?开启还是拼接时间戳* @param {*} contentType 数据格式,不指定默认发送的是json格式的请求参数,参数类型有两种方式,一种是json,参数类型是'application/json; charset=utf-8',还有一种参数类型是form表单,完整类型是'application/x-www-form-urlencoded; charset=utf-8'* json: 'application/json; charset=utf-8'* form: 'application/x-www-form-urlencoded; charset=utf-8'*/http.adornData = (data = {}, openDefaultData = true, contentType = 'json') => {var defaults = {'t': new Date().getTime()}data = openDefaultData ? merge(defaults, data) : datareturn contentType === 'json' ? JSON.stringify(data) : qs.stringify(data)}export default http响应数据展示
【前端代码】
xxxxxxxxxxgetCategoryTree() {this.$http({url: this.$http.adornUrl("/product/category/list/tree"),method: "get",}).then((data) => {console.log("获取数据:...",data);});},【数据响应结构】
data.data是响应内容,我对响应做了封装,返回一个R对象,R继承了HashMap<String,Object>
【解构data方式写法】
{data}的意思是用结构表达式{data}=data,即then参数列表中的data参数去获取响应数据中data对象的data属性,此时then参数列表的data实际上是data.data不使用解构表达式获取数据的写法
xxxxxxxxxxgetCategoryTree() {this.$http({url: this.$http.adornUrl("/product/category/list/tree"),method: "get",}).then((data) => {console.log("获取数据:...",data.data)this.categoryTree=data.data.categoryTree});},使用解构表达式获取数据的写法
xxxxxxxxxxgetCategoryTree() {this.$http({url: this.$http.adornUrl("/product/category/list/tree"),method: "get",}).then(({data}) => {console.log("获取数据:...",data)this.categoryTree=data.categoryTree});},
在
static\config\index.js中定义了请求的ip和端口号如果每个服务都单独指定ip和端口号会显得很复杂也不好实现,直接配置给网关发送请求,由网关进行路由转发,网关端口是88,正确的请求ip和端口是
http://localhost:88xxxxxxxxxx/*** 开发环境*/;(function () {window.SITE_CONFIG = {};// api接口请求地址window.SITE_CONFIG['baseUrl'] = 'http://localhost:8080/renren-fast';// cdn地址 = 域名 + 版本号window.SITE_CONFIG['domain'] = './'; // 域名window.SITE_CONFIG['version'] = ''; // 版本号(年月日时分)window.SITE_CONFIG['cdnUrl'] = window.SITE_CONFIG.domain + window.SITE_CONFIG.version;})();
网关路由转发
网关对请求转发
网关对验证码的请求进行转发
转发需要将被转发的服务注册到注册中心
【renren-fast后台服务注册】
引入common模块和com.google.code.gson.gson2.8.5,common里面服务注册的依赖,引入注册中心的过程看笔记Java生态,这里只做一次演示
renren-fast后台服务的Springboot版本过高,多方权衡,决定把renren-fast的版本降成和Springboot一致2.1.8.RELEASE
【application.yml配置注册中心和服务名】
xxxxxxxxxxspringapplicationnamerenren-fastcloudnacosdiscoveryserver-addr:127.0.0.1:8848【启动类添加注解@EnableDiscoveryClient】
xxxxxxxxxxpublic class RenrenApplication {public static void main(String[] args) {SpringApplication.run(RenrenApplication.class, args);}}【配置网关路由转发】
后台登录验证码的访问格式是
http://localhost:8080/renren-fast/captcha.jpg?uuid=e9ffdca7-538c-41eb-898a-b6c35a45f261但是目前前端的路径统一更改为访问网关
http://localhost:88/api/captcha.jpg?uuid=e9ffdca7-538c-41eb-898a-b6c35a45f261,需要在网关用过滤器对请求路径进行重写路由精确匹配的需要放在模糊匹配的前面才能被匹配上,这点和nginx不一样,nginx是优先精确匹配,如果精确匹配在模糊匹配后面,相应的请求会报401错误
xxxxxxxxxxspringcloudgatewayroutes#配置网关对第三方网站的路由功能,如果请求的参数中含有url=baidu就路由到百度idbaidu_routeurihttps//www.baidu.compredicatesQuery=url,baiduidqq_routeurihttps//www.qq.compredicatesQuery=url,qqidproduct_route#lb意思是负载均衡,后面只需要写服务名urilb//mall-productpredicates#Path断言意思是uri为指定路径就路由到该路由上来,这个表示请求路径的uri以/api开始都路由到renren-fast中#路由精确匹配的需要放在模糊匹配的前面才能被匹配上,这点和nginx不一样,nginx是优先精确匹配,如果精确匹配在模糊匹配后面,相应的请求会报401错误Path=/api/product/**filtersRewritePath=/api/(?<segment>.*),/renren-fast/$\segmentidadmin_routeurilb//renren-fastpredicatesPath=/api/**filters#filters过滤器对请求uri进行重写,RewritePath=/api/(?<segment>.*),/renren-fast/$\{egment}表示将api换成renren-fastRewritePath=/api/(?<segment>.*),/renren-fast/$\segment
请求跨域问题
跨域问题
浏览器从一个网段localhost:8001访问另一个网段localhost:88,浏览器会对请求做出跨域限制,跨域值浏览器不能执行其他网站的脚本,是浏览器同源策略造成的,是浏览器对JavaScript施加的安全限制,同源策略指协议、域名、端口号都要相同,其中一个不同就会产生跨域问题【就是当前服务器地址是localhost:8001;但是想要发送ajax请求给localhost:88是不允许的,http发给https也是不允许的】
同时请求会被403禁止,且会显示请求方式是OPTIONS,表示该请求是一个预检请求,真正的请求还没有发送出去,非简单请求【PUT、DELETE】需要先发送预检请求,详细说明见文档
https://developer.mozilla.org/zh-CN/docs/Web/HTTP/CORS,GET、HEAD、POST请求同时满足Content-Type的值为text/plain、multipart/from-data或者application/x-www-form-urlencoded都是简单请求,只要不是简单请求发送正式请求前就需要发送预检请求,预检请求会先访问服务器是否允许跨域请求,服务器响应允许跨域请求就会发起真实请求,这里的验证码的Content-Type是图片为啥就不会被限制跨域【难道这个接受图片也是文本类型?】,登录请求发送的是post请求,是非简单请求,所以被同源策略限制
【跨域流程】

跨域问题的几种解决方案
根本原因是当前页面网站和想要请求的网站不在同一个域【协议、域名、端口号】
方案1:将前端项目和网关部署到同一台nginx服务器上,这样前端项目和网关就在同一个域,网关再将请求路由到其他的上游服务器上,从头到尾都是访问nginx,这种方式在开发期间很麻烦,因为前端项目和网关在开发中,不可能提前打包部署到nginx上
方案2:服务器给预检请求的响应中添加响应头信息,告诉浏览器服务器允许跨域,可配置的响应头信息如下所示
在网关中统一写一个filter,在请求处理完成后返回前用过滤器给响应头添加上以下字段
Access-Control-Allow-Origin:服务器配置支持哪些来源的跨域请求,如果配置成*表示支持任何来源的跨域请求Access-Control-Allow-Methods:配置支持哪些请求方式跨域访问Access-Control-Allow-Credentials:跨域请求默认不能包含cookie,设置为true可以包含cookieAccess-Control-Expose-Headers:指定XMLHttpRequest对象想从跨域请求中拿到的额外字段,跨域请求XMLHttpRequest.getResponseHeader()【这是浏览器的对象还是服务器的对象】默认只允许拿到六个基本字段:Cache-Control、Content-Language、Content-Type、Expire、Last-Modified、PragmaAccess-Control-Max-Age:指定预检请求响应后多长时间内无需为同一请求发起预检请求,浏览器自身也维护着一个最大有效时间,如果该字段指定的时间大于浏览器默认的最大有效时间,配置将不会生效
网关对跨域问题的实现
添加一个过滤器,对每个请求的响应都添加跨域相关的响应头信息
在网关的目录下创建config包,并通过以下代码配置跨域,SpringBoot已经为用户提供了一个
CorsWebFilter新版renren-fast配置了跨域,这也是之前降级SpringBoot报错的原因,哪个跨域可以直接删了,直接在网关设置跨域,使用这个配置一定要将renren-fast的跨域配置删了,否则会在响应头追加一次跨域配置,即
Access-Control-Allow-Credentials:true,true,其他响应头参数也会被重复设置,会导致浏览器报错响应头不符合配置规范从而仍然跨域失败xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 商城的统一跨域配置,Cors是跨域的意思* @创建日期 2024/02/23* @since 1.0.0*/public class MallCorsConfiguration {public CorsWebFilter corsWebFilter(){//2. 创建跨域配置信息对象,注意是cors.reactive.CorsConfigurationSource,//但是创建的时候发现CorsConfigurationSource是一个接口,需要对抽象方法进行实现//双击CorsConfigurationSource快捷键ctrl+h就能显示该接口的实现类,发现有一个基于URL路径的跨域配置信息实现UrlBasedCorsConfigurationSource//仍然是选择cors.reactive.UrlBasedCorsConfigurationSource包下的,因为网关使用的是webflux实现的响应式编程//相关的类都使用cors.reactive.包下的//CorsConfigurationSource source = new CorsConfigurationSource();UrlBasedCorsConfigurationSource source = new UrlBasedCorsConfigurationSource();//4. 创建CorsConfiguration,跨域相关的配置都写在该对象中CorsConfiguration corsConfiguration = new CorsConfiguration();//5. 配置跨域,就是配置预检请求允许跨域的响应头参数了//允许哪些请求头进行跨域,*表示允许所有请求头跨域corsConfiguration.addAllowedHeader("*");//允许哪些请求方式进行跨域,*表示允许所有请求方式跨域corsConfiguration.addAllowedMethod("*");//允许哪个请求来源进行跨域,*表示允许所有请求来源跨域corsConfiguration.addAllowedOrigin("*");//是否允许携带cookie进行跨域,true表示允许携带cookie跨域,不配置跨域请求就会丢失相关的cookie信息corsConfiguration.setAllowCredentials(true);//3. 对跨域配置信息对象的实现类进行配置//source.registerCorsConfiguration(path,config);//path表示对哪些uri进行跨域配置,"/**"表示任意路径//config的类型是CorsConfiguration,需要创建一个CorsConfigurationsource.registerCorsConfiguration("/**",corsConfiguration);//1. 创建CorsWebFilter对象,需要CorsConfigurationSource跨域配置信息对象return new CorsWebFilter(source);}}【预检请求的跨域配置响应效果】

对商品模块进行注册中心注册,对商品列表树形查询的api在网关配置路由断言规则和url重写,并指定商品服务的配置中心配置
目的是为了网关对商品服务的路由
【配置中心注册】
xxxxxxxxxxspring.application.name=mall-productspring.cloud.nacos.config.server-addr=127.0.0.1:8848spring.cloud.nacos.config.namespace=6c0c487b-206b-41fb-8cd2-e4b2c19e0477
逻辑删除
分类数据逻辑删除
后端实现
商品分类的逻辑删除功能后端
mybatisplus逻辑删除实现
mybatisplus的逻辑删除是更新操作,根据id和对应的逻辑删除字段将逻辑存在的指定id的记录的逻辑删除字段改成逻辑删除
配置了逻辑删除查询操作也会自动变成查询满足条件且逻辑删除字段为逻辑未删除的记录
在对应模块的application.yml文件中配置逻辑删除字段值
和默认配置相同可省略
xxxxxxxxxx#mybatisplus逻辑删除配置,这是统一的全局配置,该配置就默认配置,如果配置和默认配置相同可以不写#从mybatisPlus3.3.0以后要配置logic-delete-field属性了,这里是3.2.0不需要配置#logic-delete-field: flag # 全局逻辑删除的实体字段名(since 3.3.0,配置后可以忽略不配置步骤2)logic-delete-value1 # 逻辑已删除值(默认为 1)logic-not-delete-value0 # 逻辑未删除值(默认为 0)配置逻辑删除组件ISqlInjector并注入IOC容器
从MybatisPlus3.1.1开始不再需要配置该ISqlInjector组件,即高版本可省略
xxxxxxxxxxpublic class MyBatisPlusConfiguration{public ISqlInjector sqlInjector(){return new LogicSqlInjector();}}在实体类的逻辑删除标识字段上添加
@Tablelogic注解@Tablelogic注解内部有两个属性value和delval,分别表示代表逻辑未删除的字面值和逻辑删除的字面值,该属性值的默认值都为空字符串,为空字符串会自动获取全局配置,全局配置没有使用默认配置,如果不为空字符串就会优先使用该注解的配置来确定哪些值表示逻辑删除和逻辑未删除【
@Tablelogic注解】xxxxxxxxxx(RetentionPolicy.RUNTIME)(ElementType.FIELD)public @interface TableLogic {/*** 默认逻辑未删除值(该值可无、会自动获取全局配置)*/String value() default "";/*** 默认逻辑删除值(该值可无、会自动获取全局配置)*/String delval() default "";}【配置实例】
xxxxxxxxxx(value = "1",delval = "0")private Integer showStatus;【执行的SQL语句】
xxxxxxxxxx==> Preparing: UPDATE pms_category SET show_status=0 WHERE cat_id IN ( ? ) AND show_status=1==> Parameters: 1432(Long)<== Updates: 1
SpringBoot调整日志级别配置打印MyBatisPlus的SQL语句
在应用的application.yml中配置MyBatisPlus日志级别
这样就能打印dao包下的MyBatisPlus的SQL执行语句
xxxxxxxxxx#将SpringBoot应用的com.earl.mall包下所有类的日志级别调整成DEBUG级别logginglevelcom.earl.malldebug
前端实现
商品分类逻辑删除前端
业务逻辑
删除前弹出提示框是否删除目标节点
弹框使用Element-ui的MessageBox 弹框组件
this.$confirm("弹框提示内容","弹框标题",用于弹框设置的对象)
弹框设置对象中前两个是取消和确认按钮的文本,type是弹框类型,点了确定按钮调用then方法,点了取消按钮调用catch方法,then方法和catch方法无论是否有代码都必须写,否则控制台会报错
this.$message(弹窗消息设置对象)
这是消息弹窗组件,可以单独使用,也可以在其他方法中使用,效果就是弹出提示框
type设置弹窗的颜色,success表示绿色,info表示灰色,message是提示文字
xxxxxxxxxx<template><el-button type="text" @click="open">点击打开 Message Box</el-button></template><script>export default {methods: {open() {this.$confirm('此操作将永久删除该文件, 是否继续?', '提示', {confirmButtonText: '确定',cancelButtonText: '取消',type: 'warning'}).then(() => {this.$message({type: 'success',message: '删除成功!'});}).catch(() => {this.$message({type: 'info',message: '已取消删除'});});}}}</script>
前端发送Post请求携带json格式的商品分类id【id通过树形组件的移除按钮的自动传参原始节点数据的catId获取】,
删除请求响应成功后弹窗删除成功消息提示
再次请求刷新树形列表数据,通过双向绑定更新树形列表
同时删除以后列表的展开状态应该维持原样
el-tree组件有一个属性值
default-expanded-keys,属性值双向绑定一个数组,作用是数组中的元素作为唯一节点标识,该节点会被默认展开,一个节点的父节点的catId可以通过树形组件的node.parent.data.catId获取
代码实现
xxxxxxxxxxremove(node, data) {console.log(data.catId)this.$confirm("将删除该商品分类, 是否继续?", "提示", {confirmButtonText: "确定",cancelButtonText: "取消",type: "warning",}).then(() => {var ids = [data.catId];this.$http({url: this.$http.adornUrl("/product/category/delete"),method: "post",data: this.$http.adornData(ids, false),}).then(({ data }) => {this.$message({type: "success",message: "删除成功!",});this.getCategoryTree();//设置删除节点的父节点为展开状态,expandKey双向绑定了el-tree组件的default-expanded-keys属性//但是现在这个优化不够完美,应该把此前展开的节点设置为默认展开,这样可能需要对节点进行遍历//最好的实现方法是点击展开按钮,默认展开就将当前节点的catId追加到数组中,点击关闭按钮,//就将对应的节点id从数组中移除,这个以后实现//暂时使用追加的方式将删除的节点的父节点追加到默认展开节点列表中,等实现了上一个逻辑这一步就不需要了this.expandKey=[this.expandKey,node.parent.data.catId]});}).catch(() => {this.$message({type: "info",message: "已取消删除",});});},
树形控件展开优化
el-tree组件有节点展开关闭的事件,分别是
node-expand和node-collapse,可以使用这两个事件来在默认展开节点中记录下来被展开的节点唯一标识即节点商品分类的id这是独立翻阅文档做出的前端用户体验优化,面试可以吹
背景
对树形列表中的节点进行逻辑删除,最初的策略是删除单个节点以后直接再次请求被双向绑定的树形列表数据
这种方式出现一个问题,子节点很可能是三级子节点,页面刷新以后展开的节点全部折叠,用户观察不到删除商品分类的效果
针对上述问题进一步优化,使用
el-tree组件的属性default-expanded-keys双向绑定一个数组expandKey,该属性的作用是能够配置在vue对象的生命周期中,数组中存在的节点对应的唯一标识【这里是此前设置的商品分类catId】的对应树形组件的节点将会始终被展开,在每次删除一个节点后将其父节点的唯一主键标识添加到expandKey数组中就能实现删除节点的父节点在节点删除前后都处于展开状态这一方式解决了删除节点刷新数据父节点自动关闭的问题,但是仍然存在其他展开节点,展开节点的子节点在某个节点增删以后自动关闭的问题
需求
对树形控件进行进一步优化,默认请款下所有展开的节点总是处于展开状态,不会因为增删节点重新请求刷新分类数据,任何已经展开的节点都不会被关闭
实现原理
通过翻阅文档,发现树形组件有一个展开事件和关闭事件,通过在展开事件中将被展开节点的唯一主键标识追加到数组
expandKey中设置始终默认展开,在关闭事件发生时从数组expandKey中移除掉对应的节点主键标识和该节点所有已经展开的子节点主键标识【不移除子节点的主键标识即便移除节点的主键标识节点也无法关闭】,关闭事件的函数自动传参第一个参数data是当前节点的原始商品分类对象,第二个参数node是当前节点的Node对象,Node对象中的childNodes是子节点数组,每个子节点对象中有一个expanded属性,为true表示该节点被展开,子节点的data属性中的catId为当前子节点的主键唯一标识,对所有子节点进行遍历,如果子节点是展开状态就从数组expandKey中移除对应的主键标识,最后再从数组中移除当前节点的主键标识,从而实现了只要页面不刷新不重新初始化,树形组件列表的展开关闭状态始终只由节点的展开关闭事件控制,其他任何操作都不会影响节点的展开状态与否,所以原来删除节点后将父节点加入数组expandKey的操作也不在需要了,实现了展开节点始终展开,关闭节点始终关闭;用户可以实时看到节点增删的效果同时也能随心所欲地控制节点展开状态,且后续处理新增节点无需再考虑节点展开与否的问题
代码完整实现
xxxxxxxxxx<template><div><el-tree:data="categoryTree":props="defaultProps":expand-on-click-node="false"show-checkboxnode-key="catId":default-expanded-keys="expandKey"@node-expand="handleNodeExpand"@node-collapse="handleNodeCollapse"><span class="custom-tree-node" slot-scope="{ node, data }"><span></span><span><el-buttonv-if="node.level <= 2"type="text"size="mini"@click="() => append(data)">Append</el-button><el-buttonv-if="node.childNodes.length == 0"type="text"size="mini"@click="() => remove(node, data)">Delete</el-button></span></span></el-tree></div></template><script>export default {components: {},props: {},data() {return {categoryTree: [],expandKey: [],defaultProps: {children: "children",label: "name",},};},computed: {},watch: {},methods: {getCategoryTree() {this.$http({url: this.$http.adornUrl("/product/category/list/tree"),method: "get",}).then(({ data }) => {this.categoryTree = data.categoryTree;});},append(data) {},remove(node, data) {console.log(data.catId);this.$confirm("将删除该商品分类, 是否继续?", "提示", {confirmButtonText: "确定",cancelButtonText: "取消",type: "warning",}).then(() => {var ids = [data.catId];this.$http({url: this.$http.adornUrl("/product/category/delete"),method: "post",data: this.$http.adornData(ids, false),}).then(({ data }) => {this.$message({type: "success",message: "删除成功!",});this.getCategoryTree();//设置删除节点的父节点为展开状态,expandKey双向绑定了el-tree组件的default-expanded-keys属性//但是现在这个优化不够完美,应该把此前展开的节点设置为默认展开,这样可能需要对节点进行遍历//最好的实现方法是点击展开按钮,默认展开就将当前节点的catId追加到数组中,点击关闭按钮,//就将对应的节点id从数组中移除,这个以后实现//暂时使用追加的方式将删除的节点的父节点追加到默认展开节点列表中,等实现了上一个逻辑这一步就不需要了//this.expandKey=[...this.expandKey,node.parent.data.catId]});}).catch(() => {this.$message({type: "info",message: "已取消删除",});});},//当节点被展开记录节点被默认展开handleNodeExpand(data) {console.log(data.catId);this.expandKey = [this.expandKey, data.catId];},//当节点被关闭时从数组中移除掉对应的节点和子节点idhandleNodeCollapse(data, node) {//获取子节点对象数组,不从默认展开节点数组this.expandKey中移除调用子节点父节点即便移除也无法关闭展开状态//所以需要先从this.expandKey移除所有的展开子节点idvar childNodes = node.childNodes;//对子节点对象数组进行遍历,判断节点对象的expanded属性是否为true,为true表示该子节点展开for (var i in childNodes) {if (childNodes[i].expanded == true) {//展开的子节点从默认展开节点列表数组中移除this.expandKey = this.expandKey.filter(function (item) {return item !== childNodes[i].data.catId;});}}this.expandKey = this.expandKey.filter(function (item) {return item !== data.catId;});},},created() {this.getCategoryTree();},mounted() {},beforeCreate() {},beforeMount() {},beforeUpdate() {},updated() {},beforeDestroy() {},destroyed() {},activated() {},};</script><style lang='scss' scoped></style>
新增分类记录
前端
使用Element-Ui对话框组件作为点击新增弹出的对话框
对话框组件
对话框的打开由按钮的
visible.sync属性控制,双向绑定dialogVisible属性值,该属性值变成true对话框就会自动弹出,变成false就会自动关闭,直接把这个组件el-dialog放在template标签中,但是该元素要求template标签中必须有一个根元素div标签,该组件需要放在该div中;对话框绑定了一个:before-close事件,在对话框关闭前会调用handleClose方法
弹出框需要填写表单的使用嵌套表单的对话框组件
el-form组件是在对话框组件中添加的一个表单组件
一般对话框的自动关闭功能和表单的提交都放在确定按钮的点击事件完成
xxxxxxxxxx<!-- Form --><el-button type="text" @click="dialogFormVisible = true">打开嵌套表单的 Dialog</el-button><el-dialog title="收货地址" :visible.sync="dialogFormVisible"><el-form :model="form"><el-form-item label="活动名称" :label-width="formLabelWidth"><el-input v-model="form.name" autocomplete="off"></el-input></el-form-item><el-form-item label="活动区域" :label-width="formLabelWidth"><el-select v-model="form.region" placeholder="请选择活动区域"><el-option label="区域一" value="shanghai"></el-option><el-option label="区域二" value="beijing"></el-option></el-select></el-form-item></el-form><div slot="footer" class="dialog-footer"><el-button @click="dialogFormVisible = false">取 消</el-button><el-button type="primary" @click="">确 定</el-button></div></el-dialog><script>export default {data() {return {dialogFormVisible: false,form: {name: '',region: '',date1: '',date2: '',delivery: false,type: [],resource: '',desc: ''},formLabelWidth: '120px'};}};</script>表单组件
表单组件el-form的单向绑定属性model绑定的是表单内容对应参数目标封装对象,比如商品分类对象category
el-form-item标签是每个表单元素,里面可以填充各种表单类型,label属性是该项表单的名字,label-width属性是表单的宽度el-input标签是文本输入框,v-model是双向绑定,绑定的是表单对象category的某个属性,比如category.name绑定的是对象category的name属性,默认值一般给空串el-button标签是按钮,表单有默认的提交按钮,但是可以不用,一般是用对话框的确定按钮来提交表单
xxxxxxxxxx<el-form ref="form" :model="category" label-width="80px"><el-form-item label="分类名称"><el-input v-model="category.name"></el-input></el-form-item><el-form-item label="活动区域"><el-select v-model="form.region" placeholder="请选择活动区域"><el-option label="区域一" value="shanghai"></el-option><el-option label="区域二" value="beijing"></el-option></el-select></el-form-item><el-form-item label="活动时间"><el-col :span="11"><el-date-picker type="date" placeholder="选择日期" v-model="form.date1" style="width: 100%;"></el-date-picker></el-col><el-col class="line" :span="2">-</el-col><el-col :span="11"><el-time-picker placeholder="选择时间" v-model="form.date2" style="width: 100%;"></el-time-picker></el-col></el-form-item><el-form-item label="即时配送"><el-switch v-model="form.delivery"></el-switch></el-form-item><el-form-item label="活动性质"><el-checkbox-group v-model="form.type"><el-checkbox label="美食/餐厅线上活动" name="type"></el-checkbox><el-checkbox label="地推活动" name="type"></el-checkbox><el-checkbox label="线下主题活动" name="type"></el-checkbox><el-checkbox label="单纯品牌曝光" name="type"></el-checkbox></el-checkbox-group></el-form-item><el-form-item label="特殊资源"><el-radio-group v-model="form.resource"><el-radio label="线上品牌商赞助"></el-radio><el-radio label="线下场地免费"></el-radio></el-radio-group></el-form-item><el-form-item label="活动形式"><el-input type="textarea" v-model="form.desc"></el-input></el-form-item><el-form-item><el-button type="primary" @click="onSubmit">立即创建</el-button><el-button>取消</el-button></el-form-item></el-form><script>export default {data() {return {category: {name: '',region: '',date1: '',date2: '',delivery: false,type: [],resource: '',desc: ''}}},methods: {onSubmit() {console.log('submit!');}}}</script>业务逻辑
点击树形组件的Append按钮触发append方法调出对话框并为商品类赋值除了分类名字的其他所有属性,添加一个商品分类需要添加的字段信息有名字、父分类id、分类级别、排序、图标、商品计量单位【product_unit】、商品数量
商品数量通过其他方式进行累计添加,这里不管
注意前端的封装对象的属性名要和后端实体类的属性名相同
商品分类的父分类id通过树形组件的节点append按钮自动传参的data的catId属性获得
注意append点击调用的append方法自动传参的data中已经包含了服务器父分类对象的完整对应数据
分类层级可以通过父分类的层级自加1获得
后端传过来的数据被解析成对象,属性值是字符串,如果需要做数学运算可以使用
字符串*1转换成数字再做数学运算排序使用默认值0、逻辑删除标识使用默认值1表示存在、
图标和商品计量单位和名字一样都通过对话框添加
对话框的确定按钮绑定单机事件触发saveCategory函数发送post请求提交表单参数保存记录
响应成功弹框提示信息并关闭对话框,将分类对象category恢复成初始配置,刷新属性列表数据,同时注意用户点击Append按钮一般是不会展开子目录的,为了观察到节点添加效果,这里需要自动将父节点展开
category恢复成初始配置的方式如下:抽取初始设置作为常量,对话框每次关闭或者新增时进行初始化,通过js方法
this.category = Object.assign({}, INITCATEGORY);将两个对象合并成一个新对象赋值给category由于每次打开对话框都会重新初始化category,不会存在对话框回显混乱的问题
xxxxxxxxxx<script>//定义一个常量作为category对象的初始化配置const INITCATEGORY = {catId: null,name: "",parentCid: 0,catLevel: 1,showStatus: 1,sort: 0,icon: "",productUnit: "",};export default {components: {},props: {},data() {return {isAdd: true,dialogFormVisible: false,//category设置为一个空对象,等待处理赋值默认值category: {},};},methods: {//点击新增节点弹出对话框,给部分属性值赋值append(data) {this.isAdd = true//弹出新增分类对分类数据进行初始化this.category = Object.assign({}, INITCATEGORY)this.dialogFormVisible = truethis.category.parentCid = data.catIdthis.category.catLevel = data.catLevel * 1 + 1},//保存新增商品分类记录saveCategory() {this.$http({url: this.$http.adornUrl("/product/category/save"),method: "post",data: this.$http.adornData(this.category, false),}).then(({ data }) => {this.getCategoryTree();this.dialogFormVisible = false;//自动展开父目录this.expandKey = [this.expandKey, this.category.parentCid];//新增商品分类成功后再次对商品分类数据进行初始化this.category = Object.assign({}, INITCATEGORY);this.$message({type: "success",message: "新增商品分类成功!",});});},},};</script>
后端接口
业务逻辑
使用renren-generator逆向工程生成的save方法使用@RequestBody注解将json数据自动转成商品实体类,根据实体类使用自增主键保存新增商品记录
注意前端提交对象的属性名要和后端实体类的属性名一一对应
修改分类记录
前端
业务逻辑
修改分类记录的对话框复用添加分类数据的对话框,根据新增按钮或者修改按钮设置isAdd值为true或者false,由此判断对话框标题并以此确定点击确认后是修改分类还是新增分类,且要对数据实时进行回显
回显过程中为了避免用户在列表界面停留很久,其他用户已经在该期间对数据进行了修改而重复修改的问题,回显的数据专门请求根据catId查询单个分类记录的接口获取最新数据进行回显
确定按钮要增加判断条件,如果是修改就调用修改分类的方法发起修改请求,如果是新增就调用新增分类的方法发起修改请求,这里可以用当前分类记录是否含有catId字段作为修改还是新增的判据【判断策略经过考虑后换成根据isAdd判断执行新增分类还是执行修改分类比较简洁和优雅】
修改分类的数据只会修改部分分类的名字,图标和计量单位,可以使用category的解构表达式只获取这三个外加一个catId解构以后构建新的只包含这四个参数的对象
根据主键修改记录,如果属性值为null就会跳过修改
请求成功响应弹窗提示信息,重新请求树形列表数据,关闭对话框,
在修改过程中鼠标稍微往外一滑一点,对话框就会自动消失,对话框的属性中有个
close-on-click-modal属性,表示是否可以通过点击modal来关闭对话框,默认值为true,需要设置成false来禁止对话框的随意点击消失,属性值需要布尔值,如果非要写字符串使用单向绑定即可
后端
业务逻辑
renren-generator逆向工程生成了对单个分类记录的查询方法info,直接调用接口即可
renren-generator的逆向工程生成了对单个分类记录的修改方法update,直接调用接口即可
节点拖拽
树形组件的节点拖拽后要满足三次商品分类结构,树形节点拖拽上下移动并和排序字段进行绑定
前端拖拽效果
业务逻辑
element-ui的树形列表控件中有一个
draggable属性,意思是是否开启节点拖拽功能,属性值是布尔类型,默认值为false,将其设置为true就能开启节点的拖拽功能【不能写成单向绑定会报错,直接单加一个draggable属性即可】但是原始的节点拖拽功能很自由,同级节点之间可以更换先后顺序,也可以让其中一个节点变成另一个节点的子节点,演变成超过三层分类,所以需要对拖拽功能进行限制
树形控件的另一个属性
allow-drop,作用是拖拽时触发allowDrop函数判断目标节点能否被放置,allow-drop是一个函数Function(draggingNode, dropNode, type)【这个函数就是allowDrop】,函数有三个参数,draggingNode是当前正在被拖拽的节点,type是当前节点可以放在哪些位置,dropNode是目标节点;返回布尔类型,该函数返回false时,任意节点的拖拽效果都是被禁止的type的值可以取三个,
prev指可以放在目标节点前面、inner指可以放在目标节点里面、next指可以放在目标节点后面,这个参数是根据被拖拽节点的位置和目标节点的位置关系判断的,目标节点是鼠标滑动时最后一次经过的哪个节点,type就是相对于最后划过的哪个节点判断的allowDrop函数的拉拽判断逻辑
allowDrop函数会传参三个参数,意义分别是
draggingNode是当前正在被拖拽的节点,以后统称当前节点;当前节点参数中的level属性会随着层级变化而持续变化,对应的父节点的childNodes数组中也会实时更新新增的节点,而且保持节点顺序,就是树形组件中所有的节点数据都是实时的,数据库原始数据不会变化
dropNode是拖拽过程中鼠标最后划过的节点,以后统称目标节点type是当前节点的最终位置与目标节点的关系,inner表示最终位置在目标节点里面,prev表示在目标节点前一个,next表示在目标节点后一个
allowDrop函数通过逻辑判断返回布尔类型的值,true表示可以拖拽,false表示不能拖拽
判断当前节点能否拖拽到目标位置的逻辑是,以当前节点为根的子树的深度加上目标位置父节点的层级要小于等于三级分类的最大层级深度即3,即拖拽后的节点层级仍然要满足三层分类效果
实现是定义一个变量maxLevel,对当前节点进行的所有子节点进行递归遍历,取出所有子节点中的最大层级存入变量maxLevel,最大层级减去当前节点的层级加1就是当前节点为根的子树的深度;因为在拖拽过程中,allowDrop函数会被频繁调用,会不停地执行对当前节点子树的遍历,因此在对子树遍历以前,用一个变量将当前节点缓存起来,只要变量没有被更新,maxLevel中的最大层级数就是当前节点的子树最大层级,由此减少大量的重复无效计算【减少重复计算是本人独立优化】
拿到当前节点的子树深度根据type是否inner类型进行判断,
如果是inner类型说明目标节点就是目标位置的父节点,子树深度加目标节点的层级之和小于等于3目标位置就合法
如果不是inner类型说明目标节点的父节点才是目标位置当前节点的父节点,子树深度加上目标节点的父节点的层级之和小于等于3目标位置就合法
代码实现
xxxxxxxxxx<!--树形组件部分,和拖拽相关的属性为draggable和:allow-drop="allowDrop";draggable默认是关闭的,写上就表示开始,给其赋值true反而报错--><el-tree:data="categoryTree":props="defaultProps":expand-on-click-node="false"show-checkboxnode-key="catId":default-expanded-keys="expandKey"@node-expand="handleNodeExpand"@node-collapse="handleNodeCollapse"draggable:allow-drop="allowDrop">methods:{//判断一个节点是否能被拖拽到指定指定位置,draggingNode是被拖拽节点、dropNode是目标节点,即鼠标最后经过的节点//type是当前正在被拖拽的节点与目标节点间的关系allowDrop(draggingNode, dropNode, type){//一、整体逻辑当前节点拖拽后于其父节点构成的节点总层数必须小于等于3//判断当前节点的深度是否已经保存到isDraggingNode对象中了,如果保存了就不要再求当前节点的深度了,//this.nodeMaxLevel保存的就是当前节点的最大层级,节省拖拽过程重复调用子树遍历浪费系统性能if(this.isDraggingNode!=draggingNode){this.isDraggingNode=draggingNode//1--求当前节点的子树深度//初始化当前节点层级this.nodeMaxLevel=draggingNode.level//计算当前节点子树的最大levle值,结果保存在this.nodeMaxLevel中this.countCurNodeMaxLevel(draggingNode)}//当前节点子树深度let draggingNodeTreeDeep=this.nodeMaxLevel-draggingNode.level+1//如果type类型是inner,当前节点深度和目标节点深度之和要小于等于3,//否则说明当前节点是平移或者平移到其他目录,这种情况计算当前节点深度和目标节点的父节点层级之和小于等于3//这两种情况都可以总结为目标节点和移动后的父节点构成的树的最大深度小于等于3if(type=='inner'){return draggingNodeTreeDeep+dropNode.level <= 3}else{return draggingNodeTreeDeep+dropNode.level-1 <= 3}},//求一个节点的最大目录层级,相当于遍历所有的子节点获取子节点的最大levelcountCurNodeMaxLevel(node){//判断一个节点是否有子节点,当前节点没有子节点就使用当前节点的层级作为返回值if(node.childNodes!=null && node.childNodes.length>0){for(let i=0;i<node.childNodes.length;i++){if(node.childNodes[i].level>this.nodeMaxLevel){this.nodeMaxLevel=node.childNodes[i].level}//对每个子节点递归求最大目录层级this.countCurNodeMaxLevel(node.childNodes[i])}}}}
分类数据拖拽关联
拖拽效果会引起商品分类的parent_cid【父ID】、level【层级】、sort【排序】三个字段变化,进行一次拖拽效果就要给后台发送一次对当前节点和同级节点【同级节点的sort字段发生了变化】的更新请求修改对应的字段,子节点只需要处理层级变化,当前节点在什么位置和子节点没什么关系,但是当前子节点的层级发生变化,所有子节点的层级也会相应的发生变化,也需要对所有子节点的层级进行更新,所有的节点记录可以一次性提交,数组中的对象只需要设置需要修改的字段,SpringBoot在处理的时候会自动把不需要修改的字段全部置为null,相应的数据库表的数据也也会修改不为null的字段
element-ui的树形控件中有一个拖拽结束事件
node-drag-end【拖拽结束不管是否成功都会触发】和一个拖拽成功事件node-drop【拖拽成功完成触发事件】,拖拽成功完成触发事件的回调函数handleDrop一共有四个参数,分别是被拖拽的当前节点、目标节点、type【目标位置相对于目标节点的相对位置before、after、inner、最后一个参数是整个事件对象】目标节点的parent保存了中的children保存了目标节点的全部数据,即便目标节点是一级节点其父不是节点而是所有一级节点的数组也同样在parent中保存了全部一级节点的信息,但是当前节点是一级节点或者变成了一级节点parent字段是不会有值的
树形列表一级节点的父是一个数组,不再是某个分类了,父id此时会变成
undefined【这里可以用更优雅的断路写法pCid = dropNode.parent.data.catId || 0;】业务逻辑
分插入到目标节点内部还是目标节点前后获取到当前节点的父节点,父节点是通过目标节点获取的,如果当前节点是一级节点,当前节点的parent属性是
undefined,但是目标节点即使是一级节点,parent属性仍然是包含所有兄弟节点的数组创建数组
this.updateNodesAfterDrop用于封装要修改的商品记录,使用this.updateNodesAfterDrop.push(追加对象)来向数组中追加要修改的记录对拖拽后的当前节点的兄弟节点进行遍历,对非当前节点的兄弟节点,统一修改排序字段为数组索引;对当前节点修改父节点id,排序,层级【层级使用当前节点实时变化的level属性】;如果当前节点的层级发生变化,对当前节点为根的子树所有节点的层级字段以节点的level属性为标准递归修改;修改了的记录全部追加到数组中等待向后端接口发起请求
注意所有对象都追加catId属性获取分类记录的主键作为修改数据库数据的查找条件【注意节点的id和分类记录的原始catId是不一样的,不要写错了】
当前节点拖拽到一级节点获取父节点的id为undefined,在js中和0做短路或运算将undefined处理成0即可【js中的短路或运算见附录】
向后端接口发送post请求更新数据库字段,响应成功以后将更新数组清空
刷新页面【不刷新其实也可以】,向默认展开的数组中添加当前节点的父节点
代码实现
xxxxxxxxxx树形组件<el-tree:data="categoryTree":props="defaultProps":expand-on-click-node="false"show-checkboxnode-key="catId":default-expanded-keys="expandKey"@node-expand="handleNodeExpand"@node-collapse="handleNodeCollapse"draggable:allow-drop="allowDrop"@node-drop="handleDrop">handleDrop(draggingNode, dropNode, dropType, ev) {/*一、整体思路:1. 获取当前节点的父节点,通过父节点的获取到拖拽结束后的所有子节点2. 对子节点进行遍历,目标是凡是涉及到数据字段变化的节点记录全部更新,目标节点的父节点下的同级子节点的排序字段全部更新【获取子节点的id和更新排序】目标节点的更新内容包括排序、父节点id、层级【获取节点的id和更新排序、父节点id、层级】目标节点层级发生变化,目标节点为根的子树上所有节点有且仅有层级都会发生变化【子节点的id和更新层级】[这里不考虑目标节点的父节点的子节点sort字段变化,因为不影响排序,后续该节点下发生节点移入会自动更新]3. 更新方式为一次传参整个数组,每个对象根据属性名自动封装,没有的属性值设置为null,更新时自动忽略*///1. 获取当前节点拖拽后父节点下的所有子节点//定义当前节点的父节点下的所有子节点let brosOfDraggingNode=null;let pCidOfDraggingNode=0;//如果当前节点的父节点是目标节点的父节点if(dropType == "before" || dropType=="after"){//目标节点即使是一级节点dropNode.parent.childNodes也是所有一级节点brosOfDraggingNode=dropNode.parent.childNodespCidOfDraggingNode=(dropNode.parent.data.catId || 0)}else{//当前节点的父节点是目标节点brosOfDraggingNode=dropNode.childNodespCidOfDraggingNode=dropNode.data.catId}console.log("同级数据:",brosOfDraggingNode,pCidOfDraggingNode)//2. 对所有兄弟节点进行遍历,至少有一个子节点,直接遍历即可for(let i=0;i<brosOfDraggingNode.length;i++){//如果子节点是当前节点,将要修改的数据封装成对象封装到this.updateNodesAfterDro中等待发起更新请求//注意节点的id不一定是分类数据的catId,一定要看好了let curNode=brosOfDraggingNode[i]let curNodeData=brosOfDraggingNode[i].dataif(curNodeData.catId==draggingNode.data.catId){let catLevelOfDraggingNode = draggingNode.data.catLevel//如果当前节点的层级发生变化if(curNode.level!=catLevelOfDraggingNode){//当前节点的层级需要更新catLevelOfDraggingNode=curNode.level//对当前节点的所有子节点递归更改层级this.updateChildNodesLevel(curNode)}this.updateNodesAfterDrop.push({catId: curNodeData.catId,sort: i,parentCid: pCidOfDraggingNode,catLevel: catLevelOfDraggingNode})}else{this.updateNodesAfterDrop.push({catId: curNodeData.catId,sort: i})}}//console.log("tree drop: ", draggingNode,dropNode, dropType);console.log(this.updateNodesAfterDrop)},//更新一个节点下所有节点的层级updateChildNodesLevel(node){if(node.childNodes.length>0){for(let i=0;i<node.childNodes.length;i++){let curNode=node.childNodes[i]this.updateNodesAfterDrop.push({catId: curNode.data.catId,catLevel: curNode.level})this.updateChildNodesLevel(curNode)}}},优化
为了避免点击添加不小心拖动节点导致拖动逻辑执行,在界面添加一个拖动开关,只有开启拖动开关的时候才能进行拖动
开关组件
用开关组件双向绑定变量
draggable,树形组件单向绑定draggablexxxxxxxxxx<el-switchv-model="value"active-color="#13ce66"inactive-color="#ff4949"active-text="按月付费"inactive-text="按年付费"></el-switch><script>export default {data() {return {value: true}}};</script>配置实例
xxxxxxxxxx开关组件<el-header height="30px"><div el-row><el-col :span="24" :offset="11"><div class="grid-content bg-purple-dark">   <el-switchv-model="draggable"active-icon-class="el-icon-d-caret"width="30"></el-switch></div></el-col></div></el-header>树形组件<el-tree:data="categoryTree":props="defaultProps":expand-on-click-node="false"show-checkboxnode-key="catId":default-expanded-keys="expandKey"@node-expand="handleNodeExpand"@node-collapse="handleNodeCollapse":draggable="draggable":allow-drop="allowDrop"@node-drop="handleDrop">
多次批量拖拽一次提交同步雷神的实现有大问题
根本没有考虑对同一个当前节点的多次拖拽导致的单次提交数据重复修改的问题,前端学的不太全,这里以后看有没有类似HashMap的前端数据结构,只保留同一个节点最后的更新数据,避免重复修改问题;同时还有锁的问题,可能存在多用户同时修改的情况都没有考虑
拖拽一次更新一次数据库确实不合理,以后看有没有什么优化手段
尝试了一下,添加了批次拖拽的功能,就是添加一个保存更改的按钮,将所有节点包括重复更改的节点数据一次性点击保存更改进行提交,把提交代码放到了保存更改的按钮点击事件中去了;额外增加了关闭拖拽的数据保存提醒功能
现在功能一切正常,有bug遇到再说,仍然存在同一个当前节点和兄弟节点重复更新的情况,只是目前看起来没啥bug,功能仍然正常
后端
业务逻辑
后端添加一个批量修改商品分类数据的接口,很简单,用List集合直接接收,通过
updateBatchById方法批量修改数据;
批量删除节点
树形列表有选中框
show-checkbox设置为true时,树形组件有一个内部方法getCheckedNodes(leafOnly, includeHalfChecked),该方法返回当前被选中的节点组成的数组,组价内部的方法需要通过组件进行调用,获取组件需要给指定组件添加ref=tree属性,即给组件起一个名字作为唯一标识,在方法中通过this.$refs.tree.filter(val)进行调用【this表示vue实例,this.$ref是当前实例中的所有组件,this.$refs.tree是拿到组件中名为tree的组件,this.$refs.tree.filter(val)表示调用tree组件内部的filter方法】
前端
getCheckedNodes(leafOnly, includeHalfChecked)方法参数
leafOnly是是否只返回叶子节点【?三级分类全被选中,二级分类是否包含?默认是全返回,包含二级一级节点】,默认是false参数
includeHalfChecked)是否包含半选节点,就是子节点没有被全部选中父节点的状态,默认是false返回值是一个包含选中节点的数组
对数组每个元素进行处理并将处理结果对应返回成一个新的数组
获取选中树形控件的节点名称
let menuName = this.$refs.menuTree.getCheckedNodes().map(node => node.name);获取选中树形的节点id:
let catIds = this.$refs.menuTree.getCheckedNodes().map(node => node.catId)本质都是一样的,数组的map方法遍历原数组中的所有元素,将对每个元素的处理结果存入一个相同大小的信数组
业务逻辑
给一个删除按钮,删除按钮单向绑定一个变量,该变量根据树形控件的节点复选框点击事件进行判断,通过调用树形控件内置的
this.$refs.menuTree.getCheckedNodes()方法获取到被选中的节点,如果选中节点数为0,删除按钮禁用;如果有被选中的节点,删除按钮可用删除的逻辑是从树形控件内置方法中获取到选中节点的catId,将catId数组直接传到后端进行删除,后端删除也只需要id的Long类型数组
后端
业务逻辑
复用后端批量逻辑删除的接口,此前单个删除使用的是批量删除接口,根据商品分类的id批量删除商品分类记录
商品品牌管理
品牌表对应数据库
mall_pms的pms_brand表,字段内容包括品牌id、名字、logo、介绍、逻辑删除标志位、检索首字母、品牌排序后台管理系统的列表功能直接使用renren-generator逆向工程的前端标准组价,不再自己实现,renren逆向生成也是基于element-ui的组件实现的
准备工作
后台前端界面新增商品菜单--品牌管理,路由规则
product/brand直接使用逆向工程生成的商品组件代码,文件位置,后端product模块
src/views/modules/product/brand.vue【品牌列表】和src/views/modules/product/brand-add-or-update.vue【品牌的添加和修改组件】,直接把这两个文件复制到前端项目的路由规则目录src\views\modules\product下效果
生成过程中会自动将数据库的字段备注作为表头信息;没有新增和删除按钮是因为当前还没有做权限系统,默认当前用户是没有权限增删品牌的;按钮显示会调用
isAuth()方法判断用户是否拥有权限,没有权限直接v-if不显示对应的按钮isAuth方法的定义位置看是从哪儿导出的,全局搜索isAuth,即找到export关键字所在位置【实际位置在utils/index.js中】目前还没有涉及权限系统,让
isAuth方法返回为true关闭权限系统
列表功能
列表优化
显示状态给一个按钮,需要显示打开开关,不想显示关闭开关
开关的
active-value属性可以设置指定激活值,inactive-value属性设置指定不激活值,默认激活值是true,不激活值是false,指定的变量是数字需要使用单向绑定;而且设定以后开关变化对应双向绑定的值也会自动封装成指定值,不再使用true和false
自定义表格模板
element-ui表格通过
Scope.slot即vue中的卡槽机制给要修改的列el-table-column标签定义一个template模板【template标签】,其中的slot-scope属性的属性值scope中封装了当前列所在一整行的所有数据,在template中定义所有行的当前字段要展示的内容,这里面可以继续放element-ui的组件表格结构为el-table>>el-table-column>>template
scope.row是当前行后端响应的单个记录的全部数据,这个数据可以看做就是后端传过来的原始数据,双向绑定的变量会实时变更数据的值,这个scope.row可以作为参数直接传递到组件调用的方法中去
xxxxxxxxxx<template><el-table :data="tableData" style="width: 100%"><el-table-column label="日期" width="180"><template slot-scope="scope"><i class="el-icon-time"></i><span style="margin-left: 10px"></span></template></el-table-column><el-table-column label="姓名" width="180"><template slot-scope="scope"><el-popover trigger="hover" placement="top"><p>姓名: </p><p>住址: </p><div slot="reference" class="name-wrapper"><el-tag size="medium"></el-tag></div></el-popover></template></el-table-column></el-table></template><script>export default {data() {return {tableData: [{date: '2016-05-02',name: '王小虎',address: '上海市普陀区金沙江路 1518 弄'}]}},methods: {handleEdit(index, row) {console.log(index, row);},handleDelete(index, row) {console.log(index, row);}}}</script>
对话框
优化新增品牌对话框
对话框组件实际上是从当前目录的
brand-add-or-update.vue文件中导入的【也就是后端生成的另一个文件】,导入语句import AddOrUpdate from "./brand-add-or-update";,组件的使用通过对应的add-or-update【引用组件的语法规则】标签,组件使用的变量值已经提前生成在变量中了,对对话框组件修改直接去文件./brand-add-or-update中修改将显示状态换成开关组件
通过开关的change事件可以监听组件的变化,自动传参组件的当前状态,给服务器发送数据修改品牌的显示状态,除此以外
el-form表单的宽度调整el-form有一个label-width属性,规定了表单项中每个表单名称占用的宽度,改为140px品牌logo改成一个文件上传框
绑定的值应该是文件上传以后返回的地址
上传框使用Upload组件,从这里开始需要涉及到图片文件存储的问题
【Upload组件】
action是文件上传的地址,file-list是文件列表展示,
xxxxxxxxxx<el-uploadclass="upload-demo"action="https://jsonplaceholder.typicode.com/posts/":on-change="handleChange":file-list="fileList"><el-button size="small" type="primary">点击上传</el-button><div slot="tip" class="el-upload__tip">只能上传jpg/png文件,且不超过500kb</div></el-upload><script>export default {data() {return {fileList: [{name: 'food.jpeg',url: 'https://fuss10.elemecdn.com/3/63/4e7f3a15429bfda99bce42a18cdd1jpeg.jpeg?imageMogr2/thumbnail/360x360/format/webp/quality/100'}, {name: 'food2.jpeg',url: 'https://fuss10.elemecdn.com/3/63/4e7f3a15429bfda99bce42a18cdd1jpeg.jpeg?imageMogr2/thumbnail/360x360/format/webp/quality/100'}]};},methods: {handleChange(file, fileList) {this.fileList = fileList.slice(-3);}}}</script>将文件上传组件upload上传到项目
src/components目录下由于项目中会多次用到文件上传组件以及签名请求,特意将组件和请求单独封装放在
src/components组件包含一个多文件上传组件和单文件上传组件和一个获取签名的模块【单文件上传组件】
action是文件要上传位置的域名,注意就是用http协议
文件点击点击上传按钮会触发before-upload事件,会调用beforeUpload方法向服务端获取签名
上传成功以后会将响应的图片地址放在fileList数组的对应元素的url属性并在img标签回显对应的图片
上传前将文件名变成了UUID+文件名防止图片重复,同样的名字会直接进行覆盖
xxxxxxxxxx<template><div><el-uploadaction="http://gulimall.oss-cn-shanghai.aliyuncs.com":data="dataObj"list-type="picture":multiple="false" :show-file-list="showFileList":file-list="fileList":before-upload="beforeUpload":on-remove="handleRemove":on-success="handleUploadSuccess":on-preview="handlePreview"><el-button size="small" type="primary">点击上传</el-button><div slot="tip" class="el-upload__tip">只能上传jpg/png文件,且不超过10MB</div></el-upload><el-dialog :visible.sync="dialogVisible"><img width="100%" :src="fileList[0].url" alt=""></el-dialog></div></template><script>import {policy} from './policy'import { getUUID } from '@/utils'export default {name: 'singleUpload',props: {value: String},computed: {imageUrl() {return this.value;},imageName() {if (this.value != null && this.value !== '') {return this.value.substr(this.value.lastIndexOf("/") + 1);} else {return null;}},fileList() {return [{name: this.imageName,url: this.imageUrl}]},showFileList: {get: function () {return this.value !== null && this.value !== ''&& this.value!==undefined;},set: function (newValue) {}}},data() {return {dataObj: {policy: '',signature: '',key: '',ossaccessKeyId: '',dir: '',host: '',// callback:'',},dialogVisible: false};},methods: {emitInput(val) {this.$emit('input', val)},handleRemove(file, fileList) {this.emitInput('');},handlePreview(file) {this.dialogVisible = true;},beforeUpload(file) {let _self = this;return new Promise((resolve, reject) => {policy().then(response => {_self.dataObj.policy = response.data.policy;_self.dataObj.signature = response.data.signature;_self.dataObj.ossaccessKeyId = response.data.accessid;_self.dataObj.key = response.data.dir +getUUID()+'_${filename}';_self.dataObj.dir = response.data.dir;_self.dataObj.host = response.data.host;resolve(true)}).catch(err => {reject(false)})})},handleUploadSuccess(res, file) {console.log("上传成功...")this.showFileList = true;this.fileList.pop();this.fileList.push({name: file.name, url: this.dataObj.host + '/' + this.dataObj.key.replace("${filename}",file.name) });this.emitInput(this.fileList[0].url);}}}</script><style></style>【引用单文件组件】
xxxxxxxxxx<template><div><single-upload></single-upload></div></template><script>import SingleUpload from '@/Components/upload/singleUpload'export default {//components:{SingleUpload:SingleUpload},//前后名字相同,可以只写一个,标签名字是根据第一个名字进行引用的components:{SingleUpload},}</script>【policy模块】
这个是浏览器请求服务端签名的请求模块
xxxxxxxxxximport http from '@/utils/httpRequest.js'export function policy() {return new Promise((resolve,reject)=>{http({url: http.adornUrl("/thirdparty/oss/policy"),method: "get",params: http.adornParams({})}).then(({ data }) => {resolve(data);})});}【前端直接请求OSS服务器】
前端直接请求OSS服务器也会存在跨域问题,需要在OSS控制台设置允许自己的浏览器的跨域请求【文档搜索修改CORS】,在bucket的基础设置中的设置跨域访问
注意事项
来源设置成自己的前端所在的域
允许post请求
允许Header设置成
*
文件存储方案
类似图片之类的文件存储,本分布式项目选择云服务商提供的对象服务,优点是搭建简单,前期成本低
单体应用
单体应用直接将文件上传到后端服务器,用户需要再直接响应给用户
集群应用
用户上传文件负载均衡到某一台服务器上,用户下次请求被负载均衡到别的服务器就找不到对应的文件了,需要额外进行优化
解决办法是,无论文件从哪个服务器上传,最后都统一存在一台文件存储服务器上,这样无论哪一台服务器响应文件数据都从这一台文件存储服务器上获取
七牛云有免费10G的云存储容量
该文件存储服务器可以自己搭建【使用FastDFS、vsftpd搭建】,搭建成本和前期费用高
也可以使用第三方的云存储服务功能【阿里云对象存储、七牛云】,即开即用,按量计费
业务逻辑
由于业务需要,需要引入阿里云对象存储服务来保存品牌的上传信息
在common中引入alicloud-oss starter依赖
文件存储方式
方式一:用户文件上传,服务端拿到用户的文件流,使用Java代码将文件上传到OSS
但是这种方式不好,文件需要经过用户自己的服务器,还会经过网关,消耗系统性能,用户量大的情况下会带来瓶颈
但是安全,因为账号密码由服务器自己控制
让用户直传阿里云服务器需要将账号密码写在js代码中让浏览器直接发送请求给阿里云服务器,但是这种方式不安全,存在账号密码泄露的问题
人数一多服务器文件上传非常占用带宽,服务器就无法处理别的请求了
方式二:服务端签名后直传
上传前请求应用服务器获取防伪签名令牌,浏览器带着防伪令牌和文件直接访问阿里云服务器
用户上传前先向应用服务器请求上传策略、应用服务器使用阿里云的账号密码生成一个防伪签名,签名信息包括用户访问阿里云的授权令牌,文件上传到阿里云的哪个位置等信息,防伪签名中不含账号密码【和https非对称加密原理是一样的,请求由公钥加密,私钥解密;响应由私钥加密,公钥解密;公钥加密的内容公钥无法解密】,保证了服务器使用公钥加密的令牌只能被阿里云服务器的私钥进行解密,阿里云返回的数据即便能被泄露的公钥解密也无伤大雅,因为阿里云服务器已经实现了服务器的认证工作
第三方服务
本项目使用到多种第三方服务,包括对象存储颁发访问授权签名,短信验证码、第三方支付等服务;将这些服务专门整合到一个模块中统一处理
在品牌模块中仅实现OSS对象存储的签名直传功能
创建模块mall-third-party
web开发环境SpringMVC、OpenFeign远程调用功能、注册中心配置中心依赖common
将oss服务的依赖放在第三方服务中,不要放在common服务下,因为有些模块是不需要使用第三方服务的,放在common下每个服务都需要进行相应的配置,而且引入的renren-fast本身使用了oss服务,如果common引入oss会导致和renren-fast的发生版本冲突
注册中心、配置中心【命名空间】、服务名、服务端口号、
【使用配置中心的配置文件】
对应配置项
xxxxxxxxxxspring.cloud.nacos.config.server-addr=127.0.0.1:8848spring.cloud.nacos.config.namespace=d37d5dd6-2b25-45b3-8bf2-916e5ec92193spring.cloud.nacos.config.ext-config[0].data-id=oss.ymlspring.cloud.nacos.config.ext-config[0].group=DEFAULT_GROUP#配置指定配置文件动态刷新spring.cloud.nacos.config.ext-config[0].refresh=true根据官方文档最佳实战---服务端签名后直传编写服务端签名代码
浏览器请求服务端拿签名,浏览器拿到签名后将文件直传阿里云对象存储服务器
编写第三方模块OSS服务端签名直传签名颁发接口【签名逻辑为读取配置文件的OSS操作用户的keyId、KeySecret、bucket和endpoint,用LinkedHashMap封装操作用户ID、对由文件大小阈值、文件存储路径、签名有效时间、OssClient信息封装成的策略编码和服务端签名、文件存储路径、bucket对应host、和签名有效时间;】
配置网关对服务的路由策略
前端基于element-ui实现一个单文件上传组件,一个多文件上传组件,以及向应用服务器要签名的policy方法
这些组件放在
src/modules/update目录中
业务逻辑是前端选择图片后触发文件上传组件的
before-upload事件,调用方法向应用服务器第三方模块请求签名,并将签名信息封装到上传组件的data属性单向绑定的对象中,上传组件在该事件方法执行结束后才会自动请求组件中action对应的地址,传参data属性的对象【前端文件上传到OSS服务器的写法详见前端常用模块】,上传完毕后触发on-success事件执行对应的方法【自动传参file参数,file.name可以获取到文件的名字】按规律拼接图片访问链接并使用img标签对logo图片进行回显renren-fast-vue的element-ui版本好像不支持element-ui的el-image标签
对话框再优化
使用Element-ui的form表单的表单验证对表单提交内容进行验证,renren-fast-vue的表单验证功能只有基础的非空验证,无法对内容进行逻辑判断,使用element-ui对表单校验进一步优化
form表单的rules属性对表单内容进行校验
el-form表单的model属性把表单数据和对象进行绑定,用rules属性绑定表单的校验规则,rules的定义规则
rules也是Vue中定义的一个对象,name表示对表单绑定的对象的name属性的数据进行校验,校验可以设置多种校验规则,一个大括号就是一条校验规则,多条校验规则按顺序进行校验
required: true为非空检验,
message表示当前校验规则不满足对应的提示信息
trigger表示校验触发的时机,
trigger: 'blur'表示失焦的时候触发校验min是最小长度,max是最大长度
xxxxxxxxxxrules: {name: [{ required: true, message: '请输入活动名称', trigger: 'blur' },{ min: 3, max: 5, message: '长度在 3 到 5 个字符', trigger: 'blur' }],region: [{ required: true, message: '请选择活动区域', trigger: 'change' }],date1: [{ type: 'date', required: true, message: '请选择日期', trigger: 'change' }],date2: [{ type: 'date', required: true, message: '请选择时间', trigger: 'change' }],type: [{ type: 'array', required: true, message: '请至少选择一个活动性质', trigger: 'change' }],resource: [{ required: true, message: '请选择活动资源', trigger: 'change' }],desc: [{ required: true, message: '请填写活动形式', trigger: 'blur' }]}自定义校验规则
每个属性的单条校验规则可以写一个validator属性,属性值为对应的方法名;调用校验规则时会自动传参rule校验规则、value表单当前接收的值、callback是校验成功失败以后的回调,callback不传参就表示校验成功,传参error对象表单校验就会显示对应的错误信息
validatePass可以以匿名方法的方式写在rules中,自定义校验规则可以和普通的校验规则混写,依然是按照顺序依次校验
注意callback如果没执行,表单无法进行提交
xxxxxxxxxxvar validatePass = (rule, value, callback) => {if (value === '') {callback(new Error('请输入密码'));} else {if (this.ruleForm.checkPass !== '') {this.$refs.ruleForm.validateField('checkPass');}callback();}};return {ruleForm: {pass: '',checkPass: '',age: ''},rules: {pass: [{ validator: validatePass, trigger: 'blur' }]}};表单额外增加的校验逻辑
检索首字母只能是一个字母
排序字段只能是数字,且必须是大于等于0的整数,可以这样写: !/^[0-9]*$/.test(value)
前端校验后后端还要再次校验【比如对一些攻击,只要知道接口的请求参数类型不使用浏览器使用postman发送请求,参数就想怎么输就怎么输了,前端校验防君子,后端校验防小人】
实例
对
firstLetter和sort属性设置校验规则xxxxxxxxxxfirstLetter: [{ required: true, message: "检索首字母不能为空", trigger: "blur" },{validator:(rule,value,callback)=>{if(!/^[a-zA-Z]$/.test(value)){callback(new Error("检索首字母必须为a-z的一个小写或大写字母"))}callback()}},],sort: [{ required: true, message: "排序不能为空", trigger: "blur" },{validator:(rule,value,callback)=>{if(!/^[0-9]*$/.test(value)){callback(new Error("排序必须填写大于0的整数"))}callback()}},],
form表单数据后端校验
使用JSR303【Java Specification Requests,即Java规范提案】,JSR303规定了数据校验的相关标准,在SpringBoot中对应实体类的属性值上标注注解来对属性值进行约束
name字段不能为空,也不能为单个空格字符
logo字段不能为空且必须是合法的url地址,但是可以是空格字符串
检索首字母不能为空且必须为单个字母
排序不能为空且必须为非负整数
后端对校验异常进行统一全局处理
开发过程中只有有问题,就大胆地将异常抛出,统一使用
@Controller+@ExceptionHandler进行全局异常处理,系统会返回给前端各种状态码,前端就能根据状态码和公司规范文档判断到底是什么问题错误码和错误信息规范
错误码定义规则为5位数字
前两位表示业务场景,最后三位表示错误码,例如10001,10:通用 001:系统未知异常
维护错误码后需要维护错误描述,将错误码和错误描述定义为枚举形式
错误码列表
10:通用 001:参数格式错误
11:商品
12:订单
13:购物车
14:物流
在common包下定义异常状态码和信息的枚举类StatusCode,在商品模块创建对校验异常的统一处理
【异常枚举类】
xxxxxxxxxxpublic enum StatusCode {UNKNOWN_EXCEPTION(10000,"系统未知异常"),VALID_EXCEPTION(10001,"参数格式校验失败"),;private int code;private String msg;StatusCode(int code,String msg){this.code=code;this.msg=msg;}public int getCode() {return code;}public String getMsg() {return msg;}}【校验异常的统一处理】
xxxxxxxxxx(MethodArgumentNotValidException.class)public R handleValidException(MethodArgumentNotValidException e){//特定异常类型可以通过发生异常后对应异常的getClass方法获取log.error("数据校验错误:{},异常类型:{}",e.getMessage(),e.getClass());//1. bindingResult可以通过e.getBindingResult()获取BindingResult bindingResult = e.getBindingResult();//1. 准备封装错误校验信息的容器Map<String,String> bingErrors = new HashMap<>();//2. 获取所有的错误校验结果并封装进MapbindingResult.getFieldErrors().forEach(item->{//获取错误属性名字String field = item.getField();//获取对应错误属性的错误校验信息String msg = item.getDefaultMessage();bingErrors.put(field,msg);});return R.error(StatusCode.VALID_EXCEPTION.getCode(), StatusCode.VALID_EXCEPTION.getMsg()).put("data",bingErrors);}
JSR303分组校验
对于一个品牌实体类,新增品牌和修改品牌的参数很可能是不一样的,比如新增不需要携带品牌ID,但是修改必须要带品牌ID、新增品牌和修改品牌时品牌名都不能为空。但是此时实体类的校验规则只有一套,此时就需要使用JSR303分组校验功能
每一种校验注解都有一个
groups属性,group属性是一个接口【Classs<?>】数组,这个接口是自定义的接口,比如在包valid下创建两个接口AddGroup和UpdateGroup,这是两个空接口,标注在不同的校验注解中分别表示在新增的时候才调用新增的校验,修改的时候才调用修改的校验,只是作为一种校验组合的区分在控制器方法中进行区分如果一个校验规则新增和修改都需要校验,则在group属性同时指定
AddGroup和UpdateGroup两个接口实例:
xxxxxxxxxx("pms_brand")public class BrandEntity implements Serializable {private static final long serialVersionUID = 1L;/*** 品牌id*/(message = "品牌ID不能为空",groups = {UpdateGroup.class})private Long brandId;/*** 品牌名*/(message = "必须填写品牌名",groups = {AddGroup.class,UpdateGroup.class})private String name;/*** 品牌logo地址*/(message = "请输入合法的logo地址",groups = {AddGroup.class,UpdateGroup.class})(groups = {AddGroup.class})private String logo;/*** 介绍*/private String descript;/*** 显示状态[0-不显示;1-显示]*/private Integer showStatus;/*** 检索首字母*/(groups = {AddGroup.class})(regexp = "^[a-zA-Z]$",message = "检索首字母必须是一个字母",groups = {AddGroup.class,UpdateGroup.class})private String firstLetter;/*** 排序*/(value = 0,message = "排序数字必须大于等于0",groups = {AddGroup.class,UpdateGroup.class})(groups = {AddGroup.class})private Integer sort;}
制定好校验规则后在控制器方法中将原来validation中的校验注解换成spring框架提供的
@Validated注解,该注解中的value属性也是接口数组,即在其中指定校验分组实现多场景情况下的复杂校验
注意:
@validated如果指定了分组,那么Bean中只校验属于该分组注解标注的值是否合法,没有指定分组的注解不会进行校验,如果@validated没有标注group,就会校验bean中所有没有分组的校验注解,此时被分组的注解反而不会生效注意啊,因为空值情况下有专门的非空注解来进行校验,所以基本上注解是不会对空值情况还进行相应的校验,也就是会默认校验正确,因为一个实体类针对不同的操作比如新增和修改可能涉及到指定多组校验,此时某些字段修改时可能会提交修改也可能不会提交修改,此时分组内的校验规则没指定非空校验,此时就会默认触发对应有值情况下需要校验的规则返回为正确,这样能同时实现空值情况下不进行入参校验【或者说空值默认校验结果为真】,有值的情况下严格执行入参校验规则
实例:
xxxxxxxxxx("/save")//@RequiresPermissions("product:brand:save")public R save((AddGroup.class) BrandEntity brand){brandService.save(brand);return R.ok();}("/update")//@RequiresPermissions("product:brand:update")public R update((UpdateGroup.class) BrandEntity brand){brandService.updateById(brand);return R.ok();}
JSR303自定义校验注解
现有的校验注解可能无法满足需求,比如校验排序字段必须为非负整数,此时能想到使用
@Pattern注解使用正则表达式对字段进行校验,但是该字段类型为Integer类型,@Pattern注解不能使用在Integer类型上【正则只能校验字符串】,此时就需要考虑使用自定义校验注解了自定义校验的实现需要三步:编写一个自定义校验注解,编写一个自定义检验器,关联自定义校验器和自定义校验注解
自定义校验注解要求
一个自定义校验注解必须满足JSR303规范,必须包含3个属性
message、groups、payloadmessage是校验出错以后的默认提示消息去哪儿获取
groups是注解必须支持分组校验功能
payload是自定义校验注解还可以自定义一些负载信息
自定义校验注解必须标注指定的元信息数据【标注指定的注解并配置源信息数据】
@Target({METHOD,FIELD,ANNOTATION_TYPE,CONSTRACTOR,PARAMTER,TYPE_USE})@Target注解指定该注解可以标注的位置@Retention(RUNTIME)@Retention(RUNTIME)指定该注解运行时可被获取Constraint(validatedBy={})Constraint(validatedBy={})指定该注解关联的校验器,这个地方不指定就需要在系统初始化的时候进行指定@Repeatable(List.calss)@Repeatable(List.calss)表示该注解是一个可重复注解
自定义校验注解实例
自定义校验注解
xxxxxxxxxx// validatedBy要指定一个ConstraintValidator的子类数组,我们可以指定自定义校验器,// 以自定义校验器ListValueConstraintValidator为例// 一个校验器只能适配一种参数类型,如果还需要适配其他参数类型,需要再定义一个校验器,并在同一个自定义校验注解使用validatedBy属性// 进行多个校验器的关联,校验注解会自动根据注解标注参数的类型自动地选出对应类型的校验器进行校验(validatedBy = {ListValueConstraintValidator.class})({ElementType.METHOD, ElementType.FIELD, ElementType.ANNOTATION_TYPE, ElementType.CONSTRUCTOR, ElementType.PARAMETER, ElementType.TYPE_USE})(RetentionPolicy.RUNTIME)//可重复注解,ListValue.List是校验注解内部自定义的可重复注解容器(ListValue.List.class)public @interface ListValue {//JSR303规范中message消息都统一在validationMessages.properties//我们也可以创建一个和该文件名一样的文件,在其中写对应的消息,Spring找不到会自动到自定义的同名文件中查找//消息的属性名一般都使用注解全类名.messageString message() default "{com.earl.common.validate.annotation.ListValue.message}";Class<?>[] groups() default {};Class<? extends Payload>[] payload() default {};int[] vals() default {};//java8新特性,定义可重复注解,一个注解可能对多种情况进行分组标注,可能使用多个相同注解,这是校验注解的重复注解定义({ElementType.METHOD, ElementType.FIELD, ElementType.ANNOTATION_TYPE, ElementType.CONSTRUCTOR, ElementType.PARAMETER, ElementType.TYPE_USE})(RetentionPolicy.RUNTIME)public @interface List {ListValue[] value();}}创建
ValidationMessages.properties同名文件并配置默认消息提示properties文件读取中文乱码的问题件附录30,这个地方需要修改IDEA的File--Setting--Editor--File Encodings--将Properties Files中的Transparent native-to-ascii conversion勾选上并重新创建文件【最好将File Encodings中的所有编码格式都改成UTF-8】
xxxxxxxxxxcom.earl.common.validate.annotation.ListValue.message=必须提交指定的值自定义校验器
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述* 自定义注解需要实现ConstraintValidator接口* ConstraintValidator<A extends Annotation, T>有两个泛型,第一个泛型是关联的注解@ListValue,第二个* 泛型是@ListValue注解能标注的地方,该接口中有两个抽象方法* @创建日期 2024/02/28* @since 1.0.0*/public class ListValueConstraintValidator implements ConstraintValidator<ListValue,Integer> {private Set<Integer> set=new HashSet<>();/*** @param constraintAnnotation* @描述 该方法能获取到ListValue注解中的属性值,该属性值能在isValid中对数据进行校验,遍历vals中的值封装到set集合中供* initialize方法对实际传参进行判断* @author Earl* @version 1.0.0* @创建日期 2024/02/28* @since 1.0.0*/public void initialize(ListValue constraintAnnotation) {int[] vals = constraintAnnotation.vals();for (int val:vals) {set.add(val);}}/*** @param value 要检验的实际入参* @param context* @return boolean* @描述 判断是否校验成功* @author Earl* @version 1.0.0* @创建日期 2024/02/28* @since 1.0.0*/public boolean isValid(Integer value, ConstraintValidatorContext context) {return set.contains(value);}}
SPU和SKU
SPU【Standard Product Unit】标准化产品单元,是一组可复用、易检索的标准化信息集合,是描述一个产品信息聚合的最小单位
通过SPU能知道商品的特性,比如手机的像素、分辨率、尺寸等
SKU【Stock Keeping Unit】库存量单位,库存进出计量的基本单元,以件、盒、托盘为单位
通过SKU能知道一个商品下面分哪些版本,比如同一种型号iphone有对应好几种颜色的不同版本,不同颜色又对应不同大小的内存,对应不同的版本有不同的售价,不同版本对应的库存量也不同
SPU更像java中的一个类,SKU像Java中的一个对象,同一款SKU除了版本不同和特定参数不同其他的特性都可以共享SPU中的特性信息【XS Max256G和64G的商品特性是相同的,比如大小、像素、芯片等】,商品的SPU信息称为基本属性【也叫规格与包装】,能完全决定库存和售价的属性称为销售属性
SPU包含一个商品分类的所有相同的基本属性、SKU包含了决定商品售价和库存量的差异化销售属性,一种商品分类的基本属性的属性名是一致的,属性值各有不同
SPU总结
即一个商品的SPU信息被设计为商品大类-属性分组-属性列表-属性值,同一类商品的大类-属性分组-属性列表是相同的,属性值有商品决定,属性值可以作为商品检索信息
基本属性是三级分类的【商品大类--属性分组--属性和属性值,如手机--基本信息--机身颜色 深空灰色】,每个商品分类有特性的属性分组,每个商品分组都有固定的规格参数列表,规格参数的值是不同商品决定的
属性信息可以供手机分类页面根据属性值【也叫规格参数】进行检索,
SKU总结
SKU信息决定一个商品的售价和库存量
每个SKU有一个唯一的编号,可以在商品界面的url看到
商品数据表设计
商品三级分类表--属性分组表从属三级分类,属性分组表和属性表通过属性关联表中的双方id关联起来
pms_attr:属性表
字段包含属性名【规格参数的属性名】、检索标志【1表示可检索属性,0表示不可检索】、属性类型、属性所属商品分类id
pms_attr_group:属性分组表
字段包含属性分组id、属性分组名、关联的商品分类id
pms_attr_attrgroup_relation:属性和属性分组关联表
字段包含关联分组id、属性id、属性分组id
pms_product_attr_value:商品属性值表
属性值是根据商品不同而不同的,所以设计一个商品属性值表,字段包含商品id、spu的id、属性id、属性名、属性对应的值;每个属性和属性值都是一条记录,一个商品的完整基本属性有很多条记录
商品属性表通过商品id或者spu的id统一查出来,
pms_spu_info:spu信息表
字段包含商品SPU的id、商品名字、商品描述、商品所属三级分类id,品牌id、商品所属状态,记录创建时间、更新时间
pms_sku_info:sku信息表
字段包含所属spu的id、sku标题、sku描述、sku名称、
pms_sku_images:sku图片
每个SKU的图片都存储在该表中,字段包含sku_id,图片url、每个图片都有一个记录
pms_sku_sale_attr_value:sku属性值表
字段包含sku的id、属性id、属性名、属性值、sku的每个属性都有一条记录
表逻辑
商品分类表、属性分组表、属性表、属性和属性分组关联表的关系
属性分组表和属性表通过
catelogId表明从属商品分类id,属性分组表和属性表通过属性和属性分组表关联商品属性值表通过属性
attrId和SPU属性表关联,通过SPU属性表的catelogId和商品分类信息关联,销售属性表通过skuid和sku信息表进行关联,通过spuid和spu信息进行关联,销售属性的属性名和属性值也在属性表中,和商品属性值表一样通过属性值id和属性值相关联说白了就是属性表定义属性名,属性名表有id和分类id;商品属性值表有主键、通过spuid绑定spu分类、通过属性值id绑定属性表中的属性名,通过attrVal指定属性值;销售属性值表有主见,通过skuId指定所属的sku,通过spuId指定所属的spu,通过attrId指定属性名,通过attrVal指定销售属性值
品牌关联分类
完善品牌列表的带条件分页模糊查询功能
一个可能关联多个商品分类,一个商品分类下也会有很多个品牌,多对多一般在数据库中就会有一张多对多的中间表pms_category_brand_relation,保存了商品id,分类id;为了避免做多表连接或者多表查询【这样很影响数据库性能】,在商品和分类关系表中添加了冗余字段商品名称和商品分类名称【这叫冗余存储,数据库数据单是分类就很多,为了保证效率只能这样。不出意外只是物品都有上万的数据。多表只能一个一个改。不然效率影响太大了。链表最多最多只能是两张】,这种冗余存储也会增加业务复杂度,当商品分类名称发生修改时,对应涉及到冗余存储的地方需要同时进行修改,当品牌名称改了,对应冗余存储的地方也同样需要同时进行修改,比较麻烦;当记录新增的时候需要单独查询出对应的冗余字段信息并对相应字段进行赋值
安装了mybatisX插件可以在对应的Dao中通过
ALT+Enter快捷键选择generate statement在对应的xml文件中创建出对应的SQL语句,xml文件中使用#{},如果dao方法中有两个以上的参数,一定要在参数列表中使用@Param注解为每个参数起对应的名字方便在xml文件中进行引用,否则很麻烦,需要使用${}和p0、p1之类的方式
SPU和SKU
属性分组
renren-fast-vue后台前端的分类菜单通过在表
sys_menu中使用sql脚本创建菜单,对应的所有前端菜单sql在,以后的项目前端页面直接拷贝,不再自己编写,前端接口文档地址公共维护到地址https://easydoc.net/s/78237135/ZUqEdvA4/HqQGp9TI【注意这个地址可能失效,要注意总结成文】,这里面有很多其他接口功能,课堂只讲一些主要功能
属性分组前端
需求:页面展示一个三级分类列表、点击列表展示该商品分类下的所有分组属性;包括后续的规格参数、销售属性都需要一个三级分类列表,因此将该三级列表单独抽取成一个组件放在
src/vues/modules/common下在
src/vues/modules/common下创建一个三级分类属性组件category.vue根据路由规则在
src/vue/modules/product目录下创建属性分组页面attrgroup.vue使用element-ui的Layout布局组件规划页面
gutter属性是每列中间的间距是20px,这是栅格系统的风格
el-row中每一行可以有24列,通过span属性告知一个el-col占用多少列
实现三级列表占用6列,表格数据占用18列
xxxxxxxxxx<el-row :gutter="20"><el-col :span="6"><div class="grid-content bg-purple"></div></el-col><el-col :span="6"><div class="grid-content bg-purple"></div></el-col><el-col :span="6"><div class="grid-content bg-purple"></div></el-col><el-col :span="6"><div class="grid-content bg-purple"></div></el-col></el-row>在第一列中使用树形组件的数据展示商品分类数据
拖拽、复选框、节点自动展开功能都不要,只展示数据、用catId来作为节点主键,组件名字叫menuTree
参数值为菜单数据,props属性
方法包括页面初始化时请求后端获取商品分类数据展示在属性菜单列表中
xxxxxxxxxx<template><el-tree :data="menu" :props="defaultProps" node-key="catId" ref="menuTree"></el-tree></template><script>export default {//import 引入的组件需要注入到对象中才能使用components: {},props: {},data() {//这里存放数据return {menu: [],expandeKey: [],defaultProps: {children: "children",label: "name"}};},}</script>在第二列中使用renren-fast逆向生成的属性分组列表来填充第二列数据,将相应的变量和方法都拷贝到attrgroup.vue中
父子组件传递数据
父子组件是vue中一个高级功能,在父组件attrgroup.vue中引用了子组件Category,我们希望实现子组件元素被点击后能通知父组件哪些元素被点击了,父组件知道子组件被点击的数据通知另一个子组件显示被点击数据关联的内容
子组件给父组件通过事件机制传递数据
子组件被点击时给父组件发送一个事件,携带上数据
给el-tree组件绑定单机事件node-click,回调自动传参节点原始数据,组件节点Node的数据,以及节点组件本身,这个单机事件写在子组件中,在子组件的回调函数中使用代码
this.$emit("tree-node-click",data,node,component)表示向父组件发送事件,事件名tree-node-click随意写,推荐按一般标准用短横线连接单词,后面接的是该事件传递的参数,这个事件名会在父组件中使用xxxxxxxxxxnodeClick(data,node,component){console.log("子组件被点击了:",data,node,component)this.$emit("tree-node-click",data,node,component)}在父组件对子组件引用的标签中添加上该事件,在父组件中定义对应的回调方法并接收子组件传递过来的参数
xxxxxxxxxx<template><el-row :gutter="20"><el-col :span="6"><category @tree-node-click="treeNodeClick"></category></el-col><el-col :span="18">...</el-col></el-row></template><script>import Category from "../common/category";export default {components: { Category},props: {},data() {return {};},methods: {treeNodeClick(data,node,component){console.log("父组件接收到子组件发送的事件:",data,node,component)},}</script>
分页查询
带条件分页查询属性分组
后端
根据商品分类id和搜索框关键字查询属性分组数据
编写后端根据商品分类id查询出对应的attrgroup表中的属性分组
使用
Map<String,Object>类型的参数和@RequestParam注解封装查询条件,请求路径中的Long类型参数catelogId的获取使用注解@PathVariable进行标注,使用分页查询方法queryPage进行分页查询【这里的QueryPage方法是renren-fast提供的,里面的很多API是使用common模块中utils下的renrenfast的Page工具类的方法】,返回PageUtils对象;传递特定的值在该方法的基础上扩展额外带特定参数的方法业务需求:分页查询属性分组数据,如果没有选择三级商品分类就查询所有属性分组,catelogId参数设置为0;如果有指定的三级商品分类就查询对应分类下的所有属性分组,catelogId设置为对应的商品分类的catId
后端分页查询实现方法
这个带条件分页查询实现很贴近企业的实现,这里的内容对应谷粒商城72P,以后好好总结一下这里,用MP和工具类做带条件分页查询
xxxxxxxxxx("attrGroupService")public class AttrGroupServiceImpl extends ServiceImpl<AttrGroupDao, AttrGroupEntity> implements AttrGroupService {/*** @param params* @return {@link PageUtils }* @描述 这个queryPage方法是renren-generator自动生成的** this.page(new Query<AttrGroupEntity>().getPage(params),new QueryWrapper<AttrGroupEntity>())* IPage中封装的分页信息,QueryWrapper是查询条件,* page方法是MyBatisPlus提供的一个方法传参IPage和一个查询条件* IPage的获取是通过renren-generator提供的工具类Query提供的,通过getPage方法可以将前端传入的查询条件中获取到分页信息* 比如PAGE是当前页码,LIMIT是每页显示记录数,ORDER_FIELD是排序字段,ORDER是排序方式、ASC是升序,实际上这些* 是常量,常量值是分页数据的key,该工具类通过从Map中获取数据封装到IPage对象中然后返回* new QueryWrapper<AttrGroupEntity>()是创建一个QueryWrapper对象,没有任何查询条件的时候就是查询所有* 公司里这些东西也是直接封装好的,** IPage<T> page(IPage<T> page, Wrapper<T> queryWrapper);是mybatisPlus扩展包下的方法,不需要引入分页插件就能直接使用** @author Earl* @version 1.0.0* @创建日期 2024/02/29* @since 1.0.0*/public PageUtils queryPage(Map<String, Object> params) {//这一步就已经把数据查出来了,封装在page对象中,PageUtils对page进行处理将数据读取出来统一封装到PageUtils中IPage<AttrGroupEntity> page = this.page(new Query<AttrGroupEntity>().getPage(params),new QueryWrapper<AttrGroupEntity>());//PageUtils是另一个工具类,将page对象传入其中,会自动将page中的分页参数传给PageUtils的属性值,这个PageUtils//也是renren-generator生成的,PageUtils对象的数据结构为/*** "page": {* "totalCount": 0,* "pageSize": 10,* "totalPage": 0,* "currPage": 1,* "list": [{* "attrGroupId": 0, //分组id* "attrGroupName": "string", //分组名* "catelogId": 0, //所属分类* "descript": "string", //描述* "icon": "string", //图标* "sort": 0 //排序* "catelogPath": [2,45,225] //分类完整路径* }]* }* */return new PageUtils(page);}/*** @param params* @param catelogId* @return {@link PageUtils }* @描述 分页查询请求的参数中有一个key字段,key字段就是检索关键字,分页查询参数和key都是连接在请求url后的,* 这个key是renren-generator封装在自动生成的前端列表组件中的搜索框的,因为这个搜索框只有一个,想要尽可能多的展示* 数据,需要对该key进行模糊匹配* 带搜索框的查询条件为select * from pms_attr_group where catelog_id=? and (attr_group_id=key or* attr_group_name like %key%* 即查询属性分组表中商品分类id为指定值且属性分组id为搜索框内容或者属性分组的名字模糊匹配搜素内容的属性分组* Spring中有一个工具类StringUtils.isEmpty(str)方法能判断str是否空字符串,自5.3版本起,isEmpty(Object)已建议弃用,* 使用hasLength(String)或hasText(String)替代。* QueryWrapper的and方法可以接受函数式接口Consumer,自动传参QueryWrapper,可以在函数式接口中连续添加查询条件* @author Earl* @version 1.0.0* @创建日期 2024/02/29* @since 1.0.0*/public PageUtils queryPage(Map<String, Object> params, String catelogId) {if(catelogId=="0"){//查询所有属性分组IPage<AttrGroupEntity> page = this.page(new Query<AttrGroupEntity>().getPage(params),new QueryWrapper<>());return new PageUtils(page);}else{String key = (String) params.get("key");QueryWrapper<AttrGroupEntity> wrapper = new QueryWrapper<AttrGroupEntity>().eq("catelog_id", catelogId);if (StringUtils.hasLength(key)) {wrapper.and(obj->{obj.eq("attr_group_id",key).or().like("attr_group_name",key);});}IPage<AttrGroupEntity> page = this.page(new Query<AttrGroupEntity>().getPage(params),wrapper);return new PageUtils(page);}}}
前端
前端逻辑
点击三级商品分类,在触发子组件向父组件发起事件时判断点击节点是否三级商品节点【node.level】,一级和二级商品节点不查询对应的属性分组;
如果点击节点的catId发生变化就向服务器带条件分页查询发起请求并获取响应结果;
页面初始化时查询catId为0的数据
新增属性分组
新增属性分组包括组名、排序、描述、组图标、所属分类ID
要点:
需求详解
点击新增弹出对话框,分别填入属性分组名、排序、属性分组描述、分组图标和所属分类信息
所属分类信息使用级联列表来选择,
所属商品分类应该做成下拉框【级联选择器】来供后台选择,使用el-cascader组件
options属性是指定级联列表的数据对象categories;
props属性是指定级联列表的value、label和children,其中value属性是当列表被选中封装进v-model绑定变量dataForm.catelogIds中的值,注意value是指定options绑定变量中的属性,但是封装到catelogIds中的数据包含多级列表中父列表和子列表对应value的数组,同时这个dataForm.catelogIds中要有完整的多级列表数组才能对分类属性进行回显,label是列表展示的内容,比如商品分类名字,children是一个列表的子节点对应的categories中的子节点数据集合【注意如果最后一级列表的原始数据还含有children属性,即使该children属性为空数组,最后也会展示为一个多余的空列表】
对于解决封装的实体类对象第三级分类数据没有children属性值但仍然带有children属性的处理办法:在category实体类上的children属性上使用jackson包下的@JsonInclude注解,其中的value类型是一个枚举类型,可以设置的枚举值包含
ALWAYS、NON_NULL【字段不为NULL才响应包含该字段】、NON_EMPTY【字段不为空的时候才返回该字段】,这样就能自动实现在封装数据对象为json时某个属性的值为空数组或者空内容的情况下自动不封装该数据,这个应该是转换成json数据的时候才自动判断的添加数据以后的数据回显是通过子组件发送请求以后,通过this.$emit给父组件发送一个名为refreshDataList的事件,父组件监听到该事件后,调用获取属性分组列表数据的接口重新获取属性列表数据
该级联选择器可以绑定了一个change事件
el-cascader组件添加一个filterable组件就能添加级联列表的快速搜索功能
placeholder属性可以设置搜索框的默认值,可以告知用户可以进行搜索
this.$nextTick(()=>{})方法是组件渲染完成以后再回调该方法中参数定义的方法
xxxxxxxxxx<div class="block"><el-form-item label="所属分类" prop="catelogId"><!--options是绑定商品数据,props属性是指定级联列表的属性值,光有options是不行的,还需要用props属性指定级联列表中的具体值props中有很多值可以填,详情看官方文档,这里介绍部分,value是指定哪个选项值作为标签对象的值[即需要响应给后端的catId],label是指定哪个值作为标签的属性值来展示,children是设置一个标签的子集合,对应返回对象的children注意这个组件有多少层是根据一个标签下是否还含有children属性名来确定的,封装的时候由于最后一级分类没有子节点了,但是还有children属性,此时会显示有四级选框,且最后一级选框什么内容都没有,此时需要设置后端让后端没有子节点的情况下不要封装children属性,可以在category实体类上的children属性上使用jackson包下的@JsonInclude注解,其中的value类型是一个枚举类型,可以设置的枚举值包含ALWAYS、NON_NULL【字段不为NULL才响应包含该字段】、NON_EMPTY[字段不为空的时候才返回该字段]注意:级联列表中的props属性中的v-model值会自动封装成一个数组,该数组的元素就是三级列表对应的props属性中的catId,但是提交分类id的时候只需呀提交最后一个id,提交数据的时候注意处理一下子组件点击提交以后除了发送请求给后端新增属性分组记录以外,还会使用this.$emit给父组件发送一个名为refreshDataList的事件,父组件中监听了该事件,调用getDataList自动更新属性分组列表修改的时候发现商品分类数据不能回显,这是因为后端发过来的数据,dataForm.catelogId只是其中一个数据,并不是一个包含完整三级分类的ID的数组,所以无法进行回显--><el-cascaderv-model="dataForm.catelogIds":options="categories":props="props"></el-cascader></el-form-item></div><div class="block"><span class="demonstration">hover 触发子菜单</span><el-cascaderv-model="value":options="options":props="{ expandTrigger: 'hover' }"@change="handleChange"></el-cascader></div>存在问题:点击修改的时候由于所属分组的
dataForm.catelogIds没有获取到完整一级到三级商品分类的catId数组,级联列表无法回显商品分类数据后端给属性分组实体类添加一个数据库没有相应字段的商品三级分类catId的List数组【会自动被处理成数组】,在根据属性分组id查询分组信息的同时,获取到商品分类ID并递归查询出该商品分类的所有一二级实体类的catId并封装成List集合存入返回的属性分组对象的对应属性中一并返回
前端对话框关闭时会触发closed事件,在触发对话框关闭的同时将三级商品分类的catId数组初始化,避免打开对话框时商品分类信息没有变化
mp没有分页插件,原生的page方法能返回分页数据,但是无法显示当前页码和总记录条数等信息
配置分页插件
属性分组关联属性
需求
在属性分组页面点击关联能弹框显示当前属性分组下的所有属性,展示属性的id、属性名、可选值、并可以对属性进行操作,但是获取的还是完整的属性所有字段
点击操作中的移除按钮能批量移除掉属性和属性分组的关联记录
业务实现
前端发送请求
/product/attrgroup/{attrgroupId}/attr/relation,后端响应数据xxxxxxxxxx{"msg": "success","code": 0,"data": [{"attrId": 4,"attrName": "aad","searchType": 1,"valueType": 1,"icon": "qq","valueSelect": "v;q;w","attrType": 1,"enable": 1,"catelogId": 225,"showDesc": 1}]}后端的逻辑是从属性属性关联表查询到同一个属性分组id下的所有关联属性id,返回属性id列表,根据属性id列表查询所有的属性记录返回属性记录列表并响应给前端,注意属性分组下可能并没有创建关联的属性,所以这里获取到属性的id集合后一定要判断一下集合是否有值,否则使用listByIds查询属性的时候如果SQL中的IN没有数据会直接报500错误
注意mp的操作不允许将单个字段组合成list集合,返回的是记录的list集合,
前端发送请求
/product/attrgroup/attr/relation/delete,后端移除对应的属性和属性分组关联记录【请求参数】
xxxxxxxxxx[{"attrId":1,"attrGroupId":2}]【响应数据】
xxxxxxxxxx{"msg": "success","code": 0}封装一个接收属性id和属性分组id的实体VO类,用VO类的数组对数据进行接收,再处理成属性属性分组实体类的List集合
因为是批量删除,希望只发送一次请求,使用or来连接删除判断条件,自定义Dao方法并编写SQL语句
属性分组未关联属性
需求
传参属性分组id和分页参数,查询出所有没有被属性分组关联的属性记录并以分页列表的形式进行返回,目的是给前端某个属性分组选择同一个商品分类下的所属属性【不属于属性分组所属商品分类下的属性不能进行展示和关联;当前属性分组只能关联没有被别的属性分组引用的属性,因为查询一个属性的关联属性分组时使用的selectOne方法,如果一个属性同时关联多个属性分组,在根据属性查询属性关联的属性分组时会直接报错,这里不知道这样设计是否系统缺陷,因为这样就限制死了一个属性只能对应一个属性分组,不过一个属性分组确实可以有多个属性】
前端选择好要关联的属性后点击确认新增发送post请求给后端新增属性和属性分组记录,注意可以批量添加关联关系;此前写修改和新增属性的时候就有写过可选创建属性和属性分组关联关系的方法,但是那个是单个属性关联单个属性分组,这里是可以批量添加属性和属性分组关联关系
业务逻辑
根据属性分组id从属性分组表查出属性分组所属商品分类id
根据商品分类id查询当前分类下的其他分组,查询这些属性分组关联的所有属性,
从商品分类的所有属性中查询所有已经被关联的属性id并封装成list集合【属性分组关联表中没有商品分类id字段,所以需要属性分组表中查询出某个商品分类下的所有属性分组id,再根据属性分组id从属性属性分组关联表中查询出已经被属性分组关联的对应商品分类下的所有属性,实际生产中多表查询很多,因为并不是所有的公司都会涉及高并发】
封装查询条件设置查询属性表不包含这些属性id的Wrapper,并使用带条件分页查询方法分页查询满足条件的属性数据【条件是属性名模糊匹配查询关键字key】,注意属性表中除了分组属性还有销售属性,查询属性分组未关联属性需要排除掉所有的销售属性,使用分页工具PageUtils进一步封装分页查询数据
注意mp使用notIn方法封装查询条件一定要判断集合中要有数据且不为
null,否则拼接的SQL语句会发生NOT IN关键字中不带内容的情况直接导致后端报SQL语句错误写一个批量新增关联关系的后端接口,uri为
/product/attrgroup/attr/relation
规格参数
新增规格参数
新增规格参数的提交表单中一方面有属性表的记录,一方面还有属性、属性分组关联表的数据;用VO对象attrAddVO封装请求参数,分别处理成表pms_attr中的记录和表pms_attr_attrgroup_relation表中的记录【这里的属性分组和属性关联只保存和属性id和属性分组id,并没有对二者的名字进行冗余存储】,同时加上事务
查询规格参数
业务需求
带条件分页查询属性列表,查询除了带属性自身的信息还要额外封装所属商品分类的名称和所属属性分组的名称
商城系统不要做多表连接查询,即便属性表只有100万条的数据,属性分组只有1000个分组,极端情况下做笛卡尔积会生成十亿条数据,这是非常可怕的操作,所以商城不要做多表连接查询
多对多关系的记录不好做冗余存储,即一个属性可能被多个属性分组使用,一个属性分组也可能被多个属性使用;此外一个属性也可能被多个商品分类使用,一个商品分类也可能被多个属性使用,此时还是需要对关联关系单独做一个表,查询的时候再根据属性id或者属性分组id专门再次到该表中单独查询而不使用多表连接的方式进行查询
老师的演示的逻辑是根据属性id响应一个属性分组实体,并没有返回属性分组实体集合,即属性和属性分组的关系还是一对一的关系
要对属性属性分组关联表的属性id和属性分组id进行判空,因为新建的属性分组或者属性在属性属性分组表中一开始不会有对应记录的数据
业务逻辑
封装新的VO类【
AttrListVo】来封装属性列表的响应数据,单个属性添加VO【AttrAddVo】不包含关联的属性分组和商品分类的名字,其中只包含商品分类id,属性分组id都需要去属性属性分组关联表中查询,需要查询对应的属性分组和商品分类名称封装到AttrListVo统一返回,由于AttrListVo属性中大部分都是AttrAddVo中的属性值,所以可以直接让AttrListVo继承AttrAddVo前端请求路径
/product/attr/base/list/{catelogId}请求参数格式
xxxxxxxxxx{page: 1,//当前页码limit: 10,//每页记录数sidx: 'id',//排序字段order: 'asc/desc',//排序方式key: '华为'//检索关键字}
分页查询所有属性信息,处理带关键字查询【关键字精确匹配id以及模糊匹配属性名】以及是否带商品分类id的情况
将分页查询的数据封装到PageUtils中,从page中取出封装的数据,使用Stream流将原属性记录实体处理成
AttrListVo,通过属性id从属性属性分组关联表查出属性分组id,根据属性分组id从属性分组表查出对应的属性分组名称,设置到AttrListVo;通过属性中的所属商品分类id查询从商品分类表查询到商品分类名称,设置到AttrListVo中,把转换类型后的stream流转换成list集合将PageUtils中的list属性设置为二次封装以后的list集合,响应给前端即可
修改规格参数
业务需求
点击修改按钮,回显属性信息,回显属性对应商品分类的完整路径,回显属性分组信息【属性对应的商品分类下没有属性分组信息,这里的属性的可选属性分组没有属性分组可以选择】
业务逻辑
根据属性的id查询回显属性信息、属性分组id、属性对应商品分类完整路径,对应表单数据进行回显
商品分类完整数据页面初始化时获取,点击修改时根据属性对应的商品分类id使用带条件分页查询属性分组列表接口查询完整的属性分组信息【如果对应商品分类没有属性分组此处】
由商品分类确定的属性分组列表请求是在activated函数中触发的,请求路径是通过飘号字符串绑定变量动态选择接口的
在被keep-alive包含的组件/路由中,会多出两个生命周期的钩子:activated 与 deactivated。在 2.2.0 及其更高版本中,activated 和 deactivated 将会在树内的所有嵌套组件中触发。activated在组件第一次渲染时会被调用,之后在每次缓存组件被激活时调用。
点击确定以后根据属性id是否有值动态决定请求的接口地址,更新就跳转更新的接口,这里的数据是全量提交,这样很不好,会导致后端把没有更改的数据也提交修改,导致数据库每次更新都对所有字段进行修改;
修改的逻辑是先对属性信息进行提交修改,然后对属性属性分组关联表的记录进行判断是否有记录存在,因为商品分类没有选择以前,属性分组是不能选择的【注意啊,这里判断商品是否存在的逻辑以及查询属性列表信息的selectOne还有前端的选择效果都决定了一个属性只能对应一个属性分组,但是一个属性分组肯定有多个属性】,如果已经存在属性关联记录就执行修改操作,如果不存在属性关联记录就执行新增关联操作【我感觉这儿的新增没有必要,因为即便无法选择属性分组新增属性也同样会生成属性关联的记录,只是属性分组字段没有数据】,这里最好还是使用新增属性没有属性分组字段就不新增属性属性分组关联记录,这样能减少关联记录的存储空间,需要添加的时候点击修改根据数据库属性属性分组关联表是否存在记录进行判断是新增还是修改
注意事项
renren生成的前端新增或修改组件的标题判断是用的id字段,但是如果数据库中的主键id不叫id而叫attrId,此时表单的属性中id字段是没有值的,需要单独赋值或者改成根据attrId来判断标题
销售属性
销售属性和规格参数都统一放在属性表中,通过字段
attr_type区分销售属性和规格参数,0表示销售属性,1表示规格参数;后端的接口也可以通过请求路径的值来做逻辑判断执行不同的业务【因为都是对同一个表的相同操作,只需要区分单个字段的不同,所以可以使用同一个接口,不要随便什么表都用一个接口】注意销售属性不存在分组
销售属性的前端页面也完全是复用的规格参数的页面组件
只在查询列表和删除属性的两个接口对请求路径设置了判断属性类型的变量,分别用于展示不同类型的数据以及作为删除是否删除属性分组数据的判据,其他接口使用实体类的对应属性类型的属性值来进行判断是否是基础属性进而需要对属性分组进行操作
设置一个商品相关的常量
好处是以后数据库设计更改,直接改枚举类不需要改代码
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 代码中使用枚举类进行不同类型取值判断,数据库如果后续发生变化,只需要修改枚举类,无需再修改代码* @创建日期 2024/03/06* @since 1.0.0*/public enum AttrTypeEnum{ATTR_TYPE_BASE(1,"base"),ATTR_TYPE_SALE(0,"sale");private int code;private String msg;AttrTypeEnum(int code,String msg){this.code=code;this.msg=msg;}public int getCode() {return code;}public String getMsg() {return msg;}}所有销售属性的增删改查接口都复用规格参数的接口,只是添加对属性分组的操作只对规格参数生效,同时查询需要设置
attr_type字段对两个界面的请求分别设置查询条件为对应的值,带条件分页查询对应的属性值列表删除接口因为是根据属性id列表删除,不好获取到属性类型,办法还是修改前端请求接口的路径参数为变量判断是否执行删除属性分组的操作
商品维护
商品新发布
前端代码在
views/module/product/spuadd.vue中
业务需求
点击菜单发布商品就会发送获取会员等级的请求
/member/memberlevel/list【POST】,接口在后端模块mall-user中,请求用户的分页数据配置用户模块的注册中心功能,配置网关对用户模块的路由转发功能
前端用户系统的会员等级会显示用户列表,
新增会员等级会设置用户等级名称、达到会员需要的成长值、设置当前会员是否默认会员等级、设置当前会员等级的免运费标准、每次评价能获取的成长值、是否有免邮特权、是否可以适用会员价格、是否有生日特权、备注
会员等级列表会在会员等级菜单页面进行展示
录入商品基本信息
业务需求
录入商品名称、商品描述、商品分类、品牌、商品重量、商品积分【购买该商品用户能获取多少金币和成长值,金币可以抵消商品金额、成长值可以提升用户等级】、商品介绍【商品介绍通过大图的形式展示】、商品图集【按销售属性选择商品以后会在右侧展示对应的商品图集】
录入商品信息时品牌是根据商品分类来动态获取分类关联的品牌,请求接口是
/product/categorybrandrelation/brands/list【GET】,该接口在商品模块商品分类与品牌关联接口中,通过商品分类id获取商品分类关联的品牌@RequestParam(value="catId",required=true)是获取地址栏中的请求参数catId,且请求必须携带该参数响应的品牌参数在controller中封装成响应的vo类List集合,在service中还是从数据库中获取完整的实体类数据,因为可能以后需要改代码或者service中的别处还会使用其他的字段,又或者vo以后可能需要更多的字段
品牌于商品分类关联表中冗余存储了品牌名称和商品分类名称
这里会遇到选择商品分类对应组件无法发送改请求的情况,解决办法如下
不知道Pubsub是用来干嘛的,以后学习前端补上;疑问为啥不用之前用过的钩子函数
activated来实现在组件第一次渲染时会被调用,之后在每次缓存组件被激活时调用。此前组件每次渲染结束后调用该钩子函数的示例本文档搜索activated可以查看在
main.js中的操作是进行全局引用xxxxxxxxxx※p84 关于pubsub、publish报错,无法发送查询品牌信息的请求:1、npm install --save pubsub-js2、在src下的main.js中引用:① import PubSub from 'pubsub-js'② Vue.prototype.PubSub = PubSub
录入规格参数
业务需求
点击下一步会跳转规格参数,首先发送请求
/product/attrgroup/{catelogId}/withattr【GET】根据商品分类id查询一个商品分类下的属性分组列表和对应属性分组下的所有基本属性并封装成一个list集合返回通过商品分类id从属性分组表获取单个商品分类下的所有属性分组记录
遍历属性分组根据属性分组的id调用此前的方法获取一个属性分组下的所有关联属性【这里还是循环查库】
这个前端很牛皮啊,会自动根据属性是否勾选单选还是多选判断属性值只能选一个还是多个,从下拉列表选择,单选只能选择一个,多选可以选中多个
设置规格参数的逻辑是根据商品分类在表单右侧显示属性分组菜单,左侧对属性分组菜单的关联属性设置属性值,以下拉列表的形式进行选择,也可以自己输入属性值,可以输入或者选择多个值,快速展示默认使用属性的设置,也可以针对不同商品进行自定义修改
快速展示是是否将属性和属性值直接展示到商品的介绍页面,属性定义的时候可以定义属性是否默认快速展示,针对单个商品也可以选择对当前商品该属性值是否快速展示
没有的属性值可以不进行录入,前端页面只会搜集已经录入的数据
录入销售属性
销售属性用笛卡尔积的形式,比如一款商品的每种颜色下都对应每种的版本【内存+存储】,红色对应8G+128G、黑色对应8G+128G等等,并根据自定义的版本信息自动排列组合生成所有的sku信息,对生成的所有商品组合对sku信息进行补充【比如副标题、价格、满减折扣、】
更多的SPU和SKU信息保存【商品信息保存】完善工作,比如保存失败怎么处理,在高级部分来进行处理
业务需求
录入销售属性根据商品分类下的销售属性查询出所有的销售属性并设置为可选列表
在每个商品的可选列表中根据销售属性会生成对应的组合字段并设置商品的标题、副标题、价格、回显设置基础属性添加的图集并选择对应商品的图集和默认图集、折扣【满多少件打多少折,是否可叠加优惠】、满减优惠、会员价
商品标题默认为商品名称追加版本内容,
点击保存商品信息会发送
/product/spuinfo/save【POST】注意:方法开启事务以后提交是最后提交的,在方法还没运行完成的情况下,数据并不会被数据库默认读出来,因为mysql的默认隔离级别是可重复读,即默认只能读到已经提交了的数据,在数据库使用命令
SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;将当前窗口的隔离级别提升到读未提交,当前窗口就可以读到已经执行但是未提交的数据请求提交的参数包括商品名、商品描述、商品分类id、品牌id、商品重量、商品发布状态、商品描述图地址的数组、图集地址数组、购物积分、用户等级成长值、基本属性【每个基本属性都封装成一个单独的对象,包含属性id、属性值、是否快速展示,整个基本属性以json数组的形式存在】、skus保存了所有的sku信息【就是上面的销售属性形成的json数组】
这个接收前端数据的json对象比较复杂,但是网上有根据json对象生成java实体类的工具,可以设置实体类的类名和包名
这个在线生成实体类会将每个json对象都生成一个对应的实体类,在最大的一个VO类中进行引用,最好使用在线JSON字符串转Java实体类(JavaBean、Entity)-BeJSON.com,这个和老师一样,生成的代码是完整的;有些网址比如JSON转JAVA实体|在线JSON转JavaBean工具 - JSON中文网连代码都不是完整的,product模块中vo包下作者为
bejson.com的类全是使用在线工具bejson生成的积分、折扣、满减价格、优惠金额、价格字段全部改为使用BigDecimal,自动生成的类不会自动识别价格属性
getter和setter全部使用Lombok的
@Data注解数据库主键相关全部由int改为Long
接收数据将数据保存到表pms_spu_info、pms_sku_info等还要跨表保存【后面业务的时候再详细总结】
该接口访问的是pms_spu_Info表对应的控制器方法,在保存方法上添加事务注解
@Transactional处理保存spu基本信息,表为数据库
mall_pms中的pms_spu_info表中,保存spu名字、spu描述、商品分类id、品牌id、商品重量、发布状态、记录创建时间、记录更新时间直接将vo中的数据拷贝到表对应的实体类中,只有创建时间和更新时间两个字段没有对应的数据,创建时间和更新时间使用MP的置自动填充
@TableField(fill = FieldFill.INSERT)和@TableField(fill = FieldFill.INSERT_UPDATE)来设置,不要用new Date()目前的主键策略都是自增策略、暂时不考虑分布式情况下的主键策略,后面在来考虑这个问题
spu商品介绍描述的图片集保存在数据库
mall_pms中的pms_spu_info_desc表中保存spu_id和spu的长图描述图集这个图片集是供sku选择的时候使用的
其中的spu_id是使用上一步保存spu基本信息生成并回填的自增主键;descript使用图片的url集合拼装成字符串用逗号分隔,使用String的API:
String.join(",",descript)将集合descript中的元素使用分隔符逗号拼接成字符串,主键是引用的spu_id,不是自增的,需要在对应实体类上使用注解@TableId(type=IdType.INPUT)将主键设置为自定义插入值,这个插入值就像正常的插入字段值,只是插入的其中一个字段是主键,如果主键没有设置为INPUT默认会使用自增,此时即便插入了主键的值,数据库也不会设置上主键值,此时就会报错抛异常spu图片集保存在数据库
mall_pms中的pms_spu_images表中,每个图片保存一条记录,生成一个独立的主键、字段包括spu_id、图片名称、图片url、图片排序、是否默认图片spu_id同样从回写的数据中获取
这里的图片集合可能为空,即暂时不上传任何图片,保存的时候需要添加图片集合的非空判断
spu基本属性【规格参数】保存在数据库
mall_pms中的pms_product_attr_value表中【这个是对应商品有值的属性记录,不再是属性定义的记录,所以和原来的属性表pms_attr无关了】,保存商品spu_id、属性id、属性名、属性值、属性排序【暂时不管】、是否快速展示封装请求的BaseAttr类中只包含属性id、属性值和showDesc,并不包含属性名,属性名等其他信息需要通过attr_id进行查询并封装
spu的积分信息保存在数据库
mall_cms的cms_spu_bounds积分信息表中,包括spu_id、商品spu成长积分、购物积分、work是积分信息的生效状态【按照二进制组成四位数,从左到右依次为:0 - 无优惠,成长积分是否赠送;1 - 无优惠,购物积分是否赠送;2 - 有优惠,成长积分是否赠送;3 - 有优惠,购物积分是否赠送,积分赠送0表示不赠送,1表示赠送】需要使用OpenFeign进行远程服务调用,要求对应服务已经上线注册中心且有对应的功能,使用TO对象来传递数据,积分相关的数据封装在VO对象Bounds对象中,包含spu对应的购物积分和成长积分;除了这俩积分,保存商品积分记录还需要商品的spu_id;
spu对应的sku信息也要保存在多张表中
spu对应的sku信息保存在类Skus类中,包含销售属性列表【元素为
Attr】、sku名字、价格、sku标题、sku副标题、sku图片集、sku的版本信息descar、满几件打折、折扣、countStatus、满减价格、优惠价格、priceStatus、会员价格;一个spu有多个商品的sku信息,整个spu的sku信息存入一个Skus元素的列表中这里面同样有循环操作数据库的问题,但是设置新记录的字段又需要使用前一次数据库新增记录生成的主键,如果想避免循环操作数据库需要设置额外的操作
sku基本信息保存在数据库
mall_pms中的pms_sku_info表中,包括spu_id、sku_id、sku_name、sku描述、商品分类id、品牌id、sku默认图片、sku标题、sku副标题、价格、销售数量sku基本信息中只有sku名、价格、标题、副标题、默认图片是准备在Skus中的,默认图片在Skus中的sku图片集列表中,其中默认图片的默认图片属性为1,图片的遍历涉及到局部变量的赋值,此时不能使用lambda表达式,使用集合的foreach遍历,默认图片需要的是图片的url字符串;其他的信息需要根据操作此前存储的spu信息来获取品牌id、商品分类id、spu_id;销量默认设置为0
但是这里没有设置商品的描述信息啊,而且sku的版本信息没有处理
sku图片集保存在数据库
mall_pms中的pms_sku_images表中,保存sku_id、图片url、是否默认图片、图片排序图片从Skus中的图片集中获取图片url,图片是否默认图片、并设置sku_id,将这些实体统一存储
这里面没有选中的图片集直接加个流式编程的过滤器过滤掉
sku销售属性保存在数据库
mall_pms中的pms_sku_sale_attr_value表中,保存sku_id、attr_id、attr名字、attr值和属性排序对应Skus对象中的Attr属性,可以直接拷贝的属性包括属性id、属性名和属性值,skuId通过上面保存的sku基本属性记录回显获取,排序字段不管【排序字段可以像商品分类一样通过前端组件获取排序信息并进行动态调整,而且可以设置子序列,比如一级、二级列表,不一定只有一种拉通排序】
sku的优惠、满减信息跨库保存在数据库
mall_cms的cms_sku_ladder折扣表,保存spu_id、满几件打折、折扣、折后价price、add_other字段是是否叠加其他优惠;满减优惠信息保存在数据库mall_cms的cms_sku_full_reduction满减表,保存sku_id、满减价格、优惠价格、是否可叠加优惠;会员价格保存在数据库mall_cms的cms_member_price会员价格表,保存sku_id、会员等级id、会员等级名称、会员价格、是否可叠加优惠这些服务需要远程操作其他模块将数据存入其他数据库中,准备TO类将优惠满减和会员相关信息打包发送给mall-coupon服务对应接口,VO中Skus对象的满减、折扣信息包括fullCount满减数量、discount折扣、countStatus折扣是否可以叠加、fullPrice满减价格、reducePrice优惠价格、priceStatus【满减是否可叠加优惠】、menberPrice会员价格列表【因为
memberPrice在VO和TO中都会使用,这里直接把VO中使用的memberPrice改成TO中的memberPrice,列表对象类型不同也是无法使用BeanUtils进行对拷的】,TO除了以上信息,还需要传递sku_id保存打折数据到
cms_sku_ladder折扣表,折扣价需要通过折扣进行计算,可以使用BeanUtils对拷,Sku_id、FullCount、Discount都可以对拷、AddOther属性是是否可叠加其他优惠【这个对应TO中的countStatus】,price是折扣价【折扣价可以现在算,也可以最后下订单的时候才计算折扣价,这里选择下订单再算折扣价,这里暂时先不设置最终价格】保存满减数据到
cms_sku_full_reduction,属性值为sku_id,需要满足多少价格、优惠价格、是否叠加其他优惠【满减的可叠加优惠字段为priceStatus,不是countStatus,要注意】,直接使用属性对拷会员价格数据到
cms_member_price,包括sku_id,会员等级id、会员等级名称、会员价格、是否能叠加其他优惠【会员价格的对象没有设置是否可叠加优惠的字符,这里默认设置为可叠加其他优惠,即默认设置为1】,这里基本不对应属性名,需要自己手动设置值【会员价格集合一定要做非空判断】远程服务和会员服务都需要根据响应状态码判断远程调用是否成功并打印日志,注意service中mp自带了log对象不是slf4j的,是ServiceImpl中的成员变量,类型是
org.apache.ibatis.logging.Log当满减数量大于0或者满减价格大于0就会调用优惠信息保存的接口,同时在coupon模块中也进行判断,对应的To对象中的满减数量大于0,满减价格大于0才存入对应的数据,同时在coupon中存储会员价格前过滤掉小于等于0的会员价格来避免三个优惠信息表的冗余存储
SPU管理
业务需求
查看管理商品对应的SPU信息,请求对应接口文档的
18:SPU检索,/product/spuinfo/list【Get】,带条件分页查询SPU信息,关键字为检索搜索框输入内容,模糊匹配SPU名称和描述;额外还可以从复选框选择商品分类id,品牌id,和商品状态
对spu可能进行规格参数的修改,需要对商品的属性参数进行回显,请求地址
/product/attr/base/listforspu/{spuId}【GET】,根据spuId从表pms_product_attr_value查询对应的规格属性信息,返回商品属性信息的list集合【返回数据不需要分页】这一步前端代码有问题,需要以下修正
总结了一下: 首先在前端中该路由
/src/router/index.js在mainRoutes->children【】里面加上这个就不会404了:{ path: '/product-attrupdate', component: _import('modules/product/attrupdate'), name: 'attr-update', meta: { title: '规格维护', isTab: true } },改完就可以跳转,但是没有数据, 是因为 前端穿的是catalogId 后端是catelogId, 我的做法是将前端所有的cata改为cate, 就能回显数据了
当规格参数的值类型为【允许多个值】但是只填了一个值时无法回显:在attrupdate.vue110行附近修改一下判断条件即可(if里增加attr.valueType的判断&& attr.valueType == 0):
xxxxxxxxxxif (v.length == 1 && attr.valueType == 0) {v = v[0] + "";}
修改了spu规格参数后发起请求
/product/attr/update/{spuId}【POST】,传递的请求参数是商品属性实体类数组中的部分参数【属性id、属性名、属性值、快速展示与否,和原来一样,没有排序字段,额外添加spu_id字段就是完备数据】,可以直接在控制器方法的参数列表封装成对应实体类的List集合,这个请求参数是单个商品的完备属性,不管是否修改还是删除了某些商品规格参数,总之是商品的完备规格参数,处理方式是直接将旧的商品数据直接删掉,重新向数据库插入新数据
业务实现
关键字模糊匹配spu的名字或者精确匹配spu的id【这两个条件需要使用and括起来,否则只要这俩条件有一个满足后续的约束就不起作用了】、status参数精确匹配字段publish_status表示spu发布状态、品牌id、商品分类id精确匹配对应字段值;品牌id、商品分类id为0直接忽略对应的查询条件
回显规格参数直接根据spuId查询出所有的商品规格属性记录,封装成list集合返回给前端
更新规格参数直接把老的规格参数全部删除,重新插入修改后完备的商品规格参数,实际业务一般是逻辑删除,并添加事务
商品管理
业务需求
前端发送请求
/product/skuinfo/list【GET】查看管理商品的SKU,携带参数分页参数、检索关键字、商品id、品牌id、最低价格和最高价格;主要功能还是关键字key模糊匹配商品品牌名称或者精确匹配商品的skuid,品牌id、商品分类id、精确匹配对应字段,商品添加价格区间的判断,注意价格、品牌id或者商品分类id为默认值0直接忽略对应的条件
仓储服务
表介绍
仓储数据库在
mall_sms,服务对应的mall-stock,服务使用前添加服务注册中心地址,开启服务发现注解、mapper包扫描注解、事务注解、网关路由路径重写配置sms_ware_info是仓库信息,包括仓库名、仓库信息、仓库邮编sms_ware_sku是仓库商品关联表,包括商品sku_id、仓库id、库存量、sku名称、库存锁定sms_ware_order_task是跟订单锁库存的表sms_ware_order_task_detail是订单锁库存的表wms_purchase是采购单表,包括采购单id、采购人id、采购人名、联系方式、优先级、状态、仓库id、总金额、创建时间、修改时间wms_purchase_detail是采购细节,包括采购单id、采购商品id、采购数量、采购金额、仓库id、采购状态【采购需求表还应该带上应采购数量、实际采购数量、采购失败或异常原因等,这些需要自己进行补充】
仓库列表
仓库列表记录的带条件模糊查询
需求:
发送
/ware/wareinfo/list【GET】请求携带分页参数和关键字查询仓库列表输入的检索条件精确匹配仓库id、或者模糊匹配仓库名称、模糊匹配仓库地址、模糊匹配仓库邮编,不带检索条件为查询全部
分页查询符合检索条件的仓库记录
查询商品库存
需求
发送
/ware/waresku/list【GET】请求携带分页参数、仓库id、商品id【skuid】查询指定仓库商品库存的分页数据商品库存的添加不是简单通过新增商品库存记录来添加的,通过sku列表界面的更多操作也能跳转到商品库存列表界面并自动填充skuid参数进行商品库存查询,商品库存记录的添加和采购单息息相关,商品库存是由采购人员采购确认后自动生成对应的商品仓库记录的【即采购人员按照采购单采购商品回来并通过对应的硬件设备确认后,商品会自动进行入库】
采购需求
新建采购需求
需求
新建采购需求来生成采购单,采购需求来源包括人工在后台主动建立的采购需求、系统发现商品数量太低自动发起的采购需求;采购人员通过这些需求生成的采购单来进行商品采购,主动新增的采购需求需要填入参数采购商品id、采购数量和商品仓库
查询采购需求
需求
前端发送
/ware/purchasedetail/list【GET】请求携带分页参数,检索关键字、采购需求状态、仓库id查询分页查询采购需求,对应表wms_purchase_detail,检索关键字精确匹配采购需求id或者商品id,采购需求状态精确匹配status字段,仓库id精确匹配仓库id
合并采购需求
需求
采购需求来源于人工主动创建的采购需求和库存预警自动创建的采购需求,这两个采购需求可以人工合并也可以系统定时合并为采购单,采购单分配给采购员,采购员通知供应商或者自主采购,采购单入库同时自动更新库存
在采购需求页面点击合并采购需求到采购单,合并的前提是必须有一个还没有被采购员领取的采购单,处于已领取以后的采购单都是已经被采购人员分配去确认以后的采购单,此时的采购单不能再被修改;新建采购单以后需要手动分配采购员【注意把采购单的新增时间和更新时间字段设置为自动填充,默认采购单的状态为0,这些状态使用枚举类进行封装】,采购员通过管理员列表进行添加,此时采购单会自动补足采购员的相应信息
点击采购需求列表界面的批量操作--合并整单,会发送
/ware/purchase/unreceive/list【GET】传递分页参数分页查询所有已创建但是未被分配给采购员的采购单,采购单状态0表示采购单还未分配给采购员,采购单状态为1表示采购员还没有出发进行采购,查询出状态字段为0或者1的所有记录,显示为复选框,信息为采购单id和对应的采购员合并采购需求会发送
/ware/purchase/merge【POST】,传递采购单id和采购需求id的数组,没有选中采购单的情况下会自动创建一个新的采购单进行合并【这种情况下只会传递要合并的采购需求的id,不会上传采购单的id,但是都是访问相同的接口,所以需要对采购单id是否存在进行判断来确定是否创建一个新的采购单】,这里需要添加对采购端状态为0或者1的再次判断,避免后台系统被攻击
业务实现
使用VO类封装采购单id和items采购需求idList集合封装请求参数,使用包装类型能避免参数没有值为null时基本参数类型无法处理
如果采购单id为null就新建采购单并获取采购单id,如果采购单id有值就使用请求参数的采购单
合并采购需求的实现就是修改采购需求记录对应的所属采购单id,将采购需求记录的状态由新建变更为已分配;通过要合并采购需求的id构建采购需求的List集合,设置好对应参数批量修改采购需求记录
采购需求的枚举同样使用枚举类,包括新建、已分配、正在采购、已完成、采购失败【采购端的已分配是分配给采购单,采购单的已分配是分配给采购员】
同时更新采购单的更新时间
给整个方法添加上事务
采购单
领取采购单
需求
采购人员打开设备或者手机上的APP,查看分配给他的所有采购单,由采购人员自己选中确认领取
这是对接采购员的功能,相关的设备或者业务不属于我们开发的范围,使用Postman模拟这些请求
已经领取的采购单,采购需求就不能再被分配到被领取的采购单上去了
业务实现
采购人员发送POST请求
/ware/purchase/received【POST】,提交请求参数为采购单的id数组第一确认当前采购单状态是新建或者已分配状态,将满足条件的采购单的状态更改为已领取
将采购单下的所有采购需求的状态变更为正在采购的状态
采购完成
需求
采购人员完成采购以后自己点击一个完成,就会调用后台更改采购单的状态并将商品添加到库存
业务实现
使用PostMan模拟发送
/ware/purchase/done【POST】发送请求参数采购单id,在items中发送每个采购单的采购需求的id、状态和采购需求状态详情【失败时填写采购失败原因,正常时啥都不用写】,使用VO类来接收数据,用JSR303数据校验对采购单进行非空约束修改采购单状态为已完成或者有异常【同一个采购单下有一个采购需求没有完成采购单就处于有异常的状态】,修改采购需求的状态为已完成或者采购失败,采购成功的情况下将商品进行
将成功采购的商品加到表
sms_ware_sku中,存储为商品的库存信息,存储商品信息需要指定为那个仓库累加库存,需要商品id、仓库id、和商品入库数量,这些数据可以通过采购需求id从采购需求数据库中进行查询,使用SQL语句对库存数量进行更新,sql为UPDATE 'sms_ware_sku' SET stock=stock+#{skuNum} WHERE sku_id=#{skuId} AND ware_id=#{wareId};如果商品从来没有库存,商品库存记录就是一个新增操作【新增设定默认锁住的库存为0,sku的名字需要跨库或者在前端页面进行完善,这里为了方便直接远程查商品服务从pms_sku_info表来获取,给服务发送请求也可以有两种写法,一种是向前端一样写网关地址,一种是直接写服务地址不走网关】,不是更新操作,在更新前对指定商品id和仓库id的记录进行判断是否存在,如果没有记录就新增库存记录,如果存在就使用更新操作,这种获取商品名字的操作可以万一发生错误可以写在try中,第一种方式出现异常捕获不进行回滚,第二种方式@Transactional(rollbackFor = Exception.class)指定异常不进行回滚给整个操作添加事务
整合ElasticSearch
ES的功能包含存储、分析和检索文档数据,常用于结构化和非结构化数据
ElasticSearch相比于MySQL更适合从海量数据中检索出用户感兴趣的数据,如果是MySQL单表打到百万以上的数据量,检索查询效率就会变得很低,在电商系统中需要按照属性等检索很多的商品,使用mysql很难抗住这么大的压力,电商系统中所有的检索功能都使用ElasticSearch来构建,ElasticSearch使用倒排索引表来实现文档数据快速检索,Mysql的检索逻辑是查询每一条数据是否含检索词条,倒排索引是将文档数据用分析器将文档分词,词条经过过滤分析后组成倒排索引表并和文档id相联系,通过检索词条来确定相关度较大的文档数据,这种方式不需要检索每个文档数据,通过检索词条就能找到相关度最匹配的对应文档,自动按相关度算法对检索文档进行排序,如果使用Mysql,还需要自己实现非常复杂的操作来对各种情况进行分析依据相关度对文档进行排序,非常地复杂;
此外ES还能引入不同的分词器来个性化的对文档数据分词,还能引入npl自然语言模型自动对文档数据的人名、地点、日期进行提取并生成对应属性值
环境安装
Docker安装ElasticSearch7.4.2
ES的作用是存储和检索数据,virtualBox安装的Centos7的默认内存为512M,这个数字对于ElasticSearch来说非常地小,实际上8G以下的单JVM内存都会对检索效率有负面影响,而且一般还都是集群配置,这里不是生产环境,直接调成1G内存,更改配置需要先停止虚拟机
使用命令
sudo docker pull elasticsearch:7.4.2拉取ES的Docker镜像创建ElasticSearch实例
使用命令
mkdir -p /malldata/elasticsearch/config创建ES实例的配置挂载目录使用命令
mkdir -p /malldata/elasticsearch/data创建ES数据的挂载目录使用命令
mkdir -p /malldata/elasticsearch/plugins创建ES插件的挂载目录,可以放ik分词器或者npl相关的插件使用命令
echo "http.host: 0.0.0.0" >> /malldata/elasticsearch/config/elasticsearch.yml向配置文件elasticsearch.yml中写入配置http.host: 0.0.0.0,该配置表示ES可以被远程的任何机器进行访问使用命令
chmod -R 777 /malldata/elasticsearch/来设置容器实例【设置任何用户或者任何组都可读可写可执行】对挂载目录的相应可读可写可执行权限【这里教学图方便用的777】,如果没有该设置,容器实例会运行失败使用以下命令创建并运行docker实例
创建一个名为
elasticsearch:7.4.2的ES实例,分别指定HTTP通信端口和内部节点通信端口分别为9200和9300\表示当前命令要换行到下一行了-e "discovery.type=single-node"表示当前实例以单节点的方式运行-e ES_JAVA_OPTS="-Xms64m -Xmx512m"设置ES的JVM内存占用,这个非常重要,因为ES的默认JVM内存配置为1G,但是我们的虚拟机内存总共就只有1G,不将该配置减小,ES一启动就会将虚拟机卡死,实际生产环境ES服务器的内存占用单节点一般都是32G左右-v /malldata/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml将容器实例中的配置文件elasticsearch.yml和挂载到自定义挂载目录中的配置文件-v /malldata/elasticsearch/data:/usr/share/elasticsearch/data将ES的数据目录挂载到自定义挂载目录中的data目录-v /malldata/elasticsearch/plugins:/usr/share/elasticsearch/plugins将ES的插件目录挂载到自定义的插件目录来方便直接在容器外挂载目录-d elasticsearch:7.4.2是指定要运行的镜像并以后台运行的方式启动,注意原版文档的启动命令没有在容器数据卷后添加
--privileged=true,能正常启动,但是无法正常通过浏览器访问,需要在挂载的容器数据卷后面添加--privileged=true启动后才能正常访问,原因还是Docker挂载主机目录Docker访问出现cannot open directory .: Permission denied,解决办法:在挂载目录后多加一个--privileged=true参数即可,猜测是因为容器没有读取到挂载目录的配置文件配置http.host: 0.0.0.0,所以无法被访问【Docker的ES配置和windows以及linux上的配置不同,其他两个上即使没有http.host: 0.0.0.0浏览器和其他工具也照样能访问,而且单机情况下的配置Docker明显更简单】
xxxxxxxxxxdocker run --name elasticsearch -p 9200:9200 -p 9300:9300 \-e "discovery.type=single-node" \-e ES_JAVA_OPTS="-Xms64m -Xmx512m" \-v /malldata/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml --privileged=true \-v /malldata/elasticsearch/data:/usr/share/elasticsearch/data --privileged=true \-v /malldata/elasticsearch/plugins:/usr/share/elasticsearch/plugins --privileged=true \-d elasticsearch:7.4.2通过浏览器访问
http://192.168.56.10:9200看到如下信息说明安装成功xxxxxxxxxx{"name": "ecb880026b14","cluster_name": "elasticsearch","cluster_uuid": "zxPeJYB9SraGL0p_R4dT0g","version": {"number": "7.4.2","build_flavor": "default","build_type": "docker","build_hash": "2f90bbf7b93631e52bafb59b3b049cb44ec25e96","build_date": "2019-10-28T20:40:44.881551Z","build_snapshot": false,"lucene_version": "8.2.0","minimum_wire_compatibility_version": "6.8.0","minimum_index_compatibility_version": "6.0.0-beta1"},"tagline": "You Know, for Search"}
Docker安装Kibana7.4.2
作用是可视化检索数据,就像Navicat、Sqlyog一样的可视化操作数据库数据,不使用这些工具就需要在命令行控制台上进行操作和展示数据
使用命令
sudo docker pull kibana:7.4.2拉取kibana镜像使用命令
sudo docker run --name kibana -e ELASTICSEARCH_HOSTS=http://192.168.56.10:9200 -p 5601:5601 \ -d kibana:7.4.2来运行kibana实例ELASTICSEARCH_HOSTS=http://192.168.56.10:9200是指定kibana要链接ES服务器的地址-p 5601:5601是指定kibana的HTTP访问地址
ES容器实例安装ik分词器
使用命令
docker exec -it 容器id /bin/bash进入容器的控制台,使用命令pwd能看见当前路径,默认路径就在/usr/share/elasticsearch目录下,该目录就是ElasticSearch的根目录使用命令
cd plugins进入ES容器的plugins目录,使用命令wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.4.2/elasticsearch-analysis-ik-7.4.2.zip获取ik分词器的压缩文件,plugins目录由于已经挂载到malldata目录,也可以直接在malldata目录进行操作注意,基础的容器实例不包含wget命令,无法在容器中使用wget,所以还是在挂载目录使用wget下载和操作对应的插件比较好
virtual box安装的CentOS也是没有wget和unzip的,需要先试用命令
yum install wget和yum install unzip安装wget和unzip
使用命令
unzip elasticsearch-analysis-ik-7.4.2.zip -d ik解压缩ik分词器的压缩文件使用命令
rm -rf *.zip删除ik分词器的压缩文件进入
/bin目录,其中有一个命令elasticsearch plugin list:列出当前系统安装的插件,观察是否有ik分词器退出容器,使用命令
docker restart elasticsearch重启容器实例
Docker安装Nginx
使用命令
docker run -p 80:80 --name nginx -d nginx:1.10随便启动一个nginx实例,这一步只是为了复制出nginx的配置不用单独拉取nginx镜像,docker运行上述命令发现没有对应的镜像会自动先去拉取该镜像
在目录
/malldata下使用命令docker container cp nginx:/etc/nginx .将容器内的配置文件拷贝到当前目录,此时拷贝过来的目录名字就叫nginx,/etc/nginx目录实际上就是nginx的conf目录依次使用命令
docker stop nginx和docker rm 容器id终止容器运行并删除容器实例在
malldata目录使用命令mv nginx conf将nginx目录的名字改为conf,使用命令mkdir nginx在malldata目录下创建nginx目录,使用命令mv conf nginx/将conf目录移动到nginx目录下使用命令
mkdir /malldata/nginx/logs和命令mkdir /malldata/nginx/html创建静态资源和日志文件对应的挂载目录,使用命令chmod -R 777 /malldata/nginx给予nginx目录可读可写可执行权限实际上不用执行该命令,执行容器实例带挂载目录的命令也会自动创建对应的挂载目录,这里为了保证万无一失提前创建了
使用以下命令创建新的nginx容器实例
将nginx上所有的静态资源挂载到
/malldata/nginx/html目录下将nginx上的所有日志文件挂载到
/malldata/nginx/logs目录下将nginx上的所有配置文件挂载到
/malldata/nginx/conf目录下
xxxxxxxxxxdocker run -p 80:80 --privileged=true --name nginx \-v /malldata/nginx/html:/usr/share/nginx/html \-v /malldata/nginx/logs:/var/log/nginx \-v /malldata/nginx/conf:/etc/nginx \-d nginx:1.10使用命令
docker update --restart=always nginx将容器实例设置为开机随docker自启动在nginx的挂载目录html中设置一个首页,通过ip从浏览器进行访问来验证容器实例的运行是否正常
ES常用WEB API
节点信息相关
【GET】
http://192.168.56.10:9200/请求体:无
功能:测试ES的安装运行是否正常
响应内容:
xxxxxxxxxx{"name": "ecb880026b14","cluster_name": "elasticsearch","cluster_uuid": "zxPeJYB9SraGL0p_R4dT0g","version": {"number": "7.4.2","build_flavor": "default","build_type": "docker","build_hash": "2f90bbf7b93631e52bafb59b3b049cb44ec25e96","build_date": "2019-10-28T20:40:44.881551Z","build_snapshot": false,"lucene_version": "8.2.0","minimum_wire_compatibility_version": "6.8.0","minimum_index_compatibility_version": "6.0.0-beta1"},"tagline": "You Know, for Search"}
【GET】
http://192.168.56.10/_cat/nodes请求体:无
功能:查看当前ES集群的节点信息
响应内容:
响应当前集群下的所有节点信息,当前单节点模式启动,所以只有一个节点,这个最后的
ecb880026b14就是上面URL响应结果中的节点名称星号表示当前节点是一个主节点
xxxxxxxxxx127.0.0.1 12 93 0 0.05 0.05 0.05 dilm * ecb880026b14补充说明:_cat下应该有很多的相关API,单纯的
http://192.168.56.10/_cat响应结果如下,返回_cat后能跟所有子urixxxxxxxxxx=^.^=/_cat/allocation/_cat/shards/_cat/shards/{index}/_cat/master/_cat/nodes/_cat/tasks/_cat/indices/_cat/indices/{index}/_cat/segments/_cat/segments/{index}/_cat/count/_cat/count/{index}/_cat/recovery/_cat/recovery/{index}/_cat/health/_cat/pending_tasks/_cat/aliases/_cat/aliases/{alias}/_cat/thread_pool/_cat/thread_pool/{thread_pools}/_cat/plugins/_cat/fielddata/_cat/fielddata/{fields}/_cat/nodeattrs/_cat/repositories/_cat/snapshots/{repository}/_cat/templates
【GET】
http://192.168.56.10:9200/_cat/health请求体:无
功能:查看ES集群的所有节点健康信息
响应内容:
green表示当前节点健康,后面的数字是集群分片信息
xxxxxxxxxx1715958975 15:16:15 elasticsearch green 1 1 3 3 0 0 0 0 - 100.0%
【GET】
http://192.168.56.10:9200/_cat/master请求体:无
功能:查看主节点信息
响应内容:
hcAGB9fFT0uRZ2xR36VZlA是主节点的唯一编号,ecb880026b14是主节点的名称,127.0.0.1是主节点地址
xxxxxxxxxxhcAGB9fFT0uRZ2xR36VZlA 127.0.0.1 127.0.0.1 ecb880026b14
索引文档CURD相关
【GET】
http://192.168.56.10:9200/_cat/indices请求体:无
功能:查看ES集群中的所有索引,相当于查看查看mysql中的所有数据库
响应内容:
目前还没有向ES中添加索引,这些索引都是kibana相关的一些配置信息,由kibana在ES中创建的
xxxxxxxxxxgreen open .kibana_task_manager_1 Pk143YyKQci-HaAIS4oQ8w 1 0 2 0 38.2kb 38.2kbgreen open .apm-agent-configuration btC4ECICSQStzecqlpLb7Q 1 0 0 0 283b 283bgreen open .kibana_1 hckOIIBjTJesypzK4lrXhQ 1 0 8 0 28.6kb 28.6kb
【PUT】
http://192.168.56.10:9200/customer/external/1请求体:
请求体json就是文档数据
xxxxxxxxxx{"name": "John Doe"}功能:向ES服务器索引一个文档,customer是文档的索引,external是文档类型,值得注意的是在ES8中已经废除了文档类型的概念,可以直接以【PUT】
http://192.168.56.10:9200/customer/1来索引文档,PUT带id的索引文档操作,PUT请求方式的索引文档必须携带id,不携带id会直接报错,多次执行是更新操作,文档数据的版本号会累加,一般都将PUT方式的索引文档用来做更新操作响应内容:
响应数据中以
_开头的称为元数据,反应一个文档的基本信息,_index表示当前文案数据在哪一个索引下,_type表示当前文档所在的类型,_id是文档数据对应的id,_version是文档数据的版本,result是本次操作的结果,_shards是分片的相关信息
xxxxxxxxxx{"_index": "customer","_type": "external","_id": "1","_version": 1,"result": "created","_shards": {"total": 2,"successful": 1,"failed": 0},"_seq_no": 0,"_primary_term": 1}补充说明:
再次发送该请求响应内容中的
result会变成updated,且版本号自动发生了累加xxxxxxxxxx{"_index": "customer","_type": "external","_id": "1","_version": 2,"result": "updated","_shards": {"total": 2,"successful": 1,"failed": 0},"_seq_no": 1,"_primary_term": 1}这种方式是全量更新,即请求体文档数据直接覆盖原文档数据内容
【POST】
http://192.168.56.10/customer/external请求体:
请求体json就是文档数据
xxxxxxxxxx{"name": "John Doe"}功能:像ES服务器索引一个文档,不指定id的情况下会自动生成唯一id,多次放松请求,每次响应都是created操作,且都会响应不同的唯一id,版本号不发生变化;携带id,第一次请求是created操作,此后多次发送相同请求,会显示是updated操作,且文旦数据的id唯一,版本号会相应累加;即带id和PUT方式的功能是完全相同的,不带id自动生成id并且每次请求都是全新的新增文档操作
响应内容:
【不携带id】
xxxxxxxxxx{"_index": "customer","_type": "external","_id": "1ll4io8B6tdhia0R4XMN","_version": 1,"result": "created","_shards": {"total": 2,"successful": 1,"failed": 0},"_seq_no": 2,"_primary_term": 1}【不携带id多次发送效果】
xxxxxxxxxx{"_index": "customer","_type": "external","_id": "11l5io8B6tdhia0Rn3Mj","_version": 1,"result": "created","_shards": {"total": 2,"successful": 1,"failed": 0},"_seq_no": 3,"_primary_term": 1}【携带id】
xxxxxxxxxx{"_index": "customer","_type": "external","_id": "3","_version": 1,"result": "created","_shards": {"total": 2,"successful": 1,"failed": 0},"_seq_no": 5,"_primary_term": 1}【携带id多次发送效果】
xxxxxxxxxx{"_index": "customer","_type": "external","_id": "3","_version": 2,"result": "updated","_shards": {"total": 2,"successful": 1,"failed": 0},"_seq_no": 6,"_primary_term": 1}补充说明:
这种方式是全量更新,即请求体文档数据直接覆盖原文档数据内容
【GET】
http://192.168.56.10:9200/customer/external/1请求体:无
功能:通过指定索引分类和id检索指定文档数据
响应内容:
_seq_no和_primary_term是做乐观锁操作的,数据发生改动,序列号_seq_no就会往上加,分片发生变化如集群重启或者主分片重新选举,_primary_term也会发生相应的变化;老版本做乐观锁用的是version,新版本禁止使用version而在请求参数中带这两个参数来替代了;不过对于版本控制又外部逻辑处理的时候还是可以使用versionfound表示对应的文档数据被找到_source表示文档数据的具体内容
xxxxxxxxxx{"_index": "customer","_type": "external","_id": "1","_version": 3,"_seq_no": 4,"_primary_term": 1,"found": true,"_source": {"name": "John Doe"}}
【PUT】
http://192.168.56.10:9200/customer/external/1?if_seq_no=4&if_primary_term=1请求体
xxxxxxxxxx{"name": "1"}功能:当文档数据的
_seq_no和_primary_term和请求参数的对应参数值相同时执行更新操作,即使用乐观锁来做文档数据的并发操作控制响应内容:
xxxxxxxxxx{"_index": "customer","_type": "external","_id": "1","_version": 4,"result": "updated","_shards": {"total": 2,"successful": 1,"failed": 0},"_seq_no": 8,"_primary_term": 1}补充说明:
注意文档索引过程中使用了类型,更新文档时的URI中也必须使用类型,否则请求会直接报错
【POST】
http://192.168.56.10:9200/customer/external/1/_update请求体
xxxxxxxxxx{"doc":{"name": "John"}}功能:根据文档数据的索引、类型、文档id和文档内容对文档数据进行更新,如果文档数据和ES服务器中的文档数据内容相同,多次操作ES服务器中的数据不会发生任何变化,连数据的版本号都不会发生变化,在响应内容的result为noop,表示什么都不做,然而不带
_update的更新操作不会检查原文档数据是否和需要更新后的文档数据是否一致;同时注意使用_update进行更新,更新内容要放在请求体的doc属性中响应内容:
xxxxxxxxxx{"_index": "customer","_type": "external","_id": "1","_version": 6,"result": "updated","_shards": {"total": 2,"successful": 1,"failed": 0},"_seq_no": 10,"_primary_term": 1}【多次操作单文档数据不变的响应】
xxxxxxxxxx{"_index": "customer","_type": "external","_id": "1","_version": 6,"result": "noop","_shards": {"total": 0,"successful": 0,"failed": 0},"_seq_no": 10,"_primary_term": 1}补充说明:
带
_update的更新请求只能是POST请求方式,不能使用PUT请求方式,且带_update的POST请求是局部更新,即文档数据不会直接全部覆盖,有对应属性的数据相应修改,没有对应的属性就保留原文档数据,新增没有的属性和相应的数据;但是注意不带_update的上述两种PUT和POST方式的更新都是全量更新,即直接用请求体的数据直接将原文档数据全部直接覆盖
【DELETE】
http://192.168.56.10:9200/customer/external/1请求体:无
功能:根据索引、类型和文档id删除指定文档数据
响应内容:
xxxxxxxxxx{"_index": "customer","_type": "external","_id": "1","_version": 10,"result": "deleted","_shards": {"total": 2,"successful": 1,"failed": 0},"_seq_no": 14,"_primary_term": 1}
【DELETE】
http://192.168.56.10:9200/customer请求体:无
功能:根据索引名称删除索引和索引下的所有数据
响应内容:
xxxxxxxxxx{"acknowledged": true}补充说明:
ES中没有提供删除类型的操作,删除索引会自动删除所有类型,清空一个文档下的所有文档数据也会同时删除掉其所属的类型,实际上基于用法的感知上没啥区别,因为向某个类型下添加文档数据也需要知道对应类型的名字
BULK批量相关
【POST】
http://192.168.56.10:9200/customer/external/_bulk请求体
每两行是一个整体,请求体语法格式在补充说明部分给出,index表示这是批量新增操作,
{"_id":"1"}是在URI中已知索引和类型的情况下指定当前数据的id,实际上完整的内容为{ "index": { "_index": "customer", "_type": "external", "_id": "1" }},第二行是完整的文档数据请求体的数据类型还是选择json,虽然PostMan会标红
注意使用PostMan发送该请求,后一行后面要加一个回车才行,使用kibana不需要加回车
xxxxxxxxxx{"index":{"_id":"1"}}{"name": "John Doe" }{"index":{"_id":"2"}}{"name": "Jane Doe" }功能:批量操作数据
响应内容:
"took": 134表示该批量操作耗时134毫秒"errors": false表示过程中没有发生任何错误items保存批量处理中每个处理的对应响应结果,index表示本次操作是一个保存操作,接着是三个元信息,版本号、操作结果、分片信息、版本号相关信息、"status": 201是该操作的状态码,表示刚新建完成
xxxxxxxxxx{"took": 134,"errors": false,"items": [{"index": {"_index": "customer","_type": "external","_id": "1","_version": 1,"result": "created","_shards": {"total": 2,"successful": 1,"failed": 0},"_seq_no": 0,"_primary_term": 1,"status": 201}},{"index": {"_index": "customer","_type": "external","_id": "2","_version": 1,"result": "created","_shards": {"total": 2,"successful": 1,"failed": 0},"_seq_no": 1,"_primary_term": 1,"status": 201}}]}补充说明:
批量操作的每一条记录都是独立的,上一条文档数据的操作失败不会影响下一条数据的操作
请求体数据的语法格式
action是操作类型,
metadata是一个文档数据的原数据信息如索引、类型和id第二行紧跟完整的文档数据
随后循环添加要批量执行的其他操作
xxxxxxxxxx{ action: { metadata }}\n{ request body }\n{ action: { metadata }}\n{ request body }\n【action的所有类型,偶数行是对应的文档数据,删除操作不需要文档数据】
xxxxxxxxxx{ "delete": { "_index": "website", "_type": "blog", "_id": "123" }}{ "create": { "_index": "website", "_type": "blog", "_id": "123" }}{ "title": "My first blog post" }{ "index": { "_index": "website", "_type": "blog" }}{ "title": "My second blog post" }{ "update": { "_index": "website", "_type": "blog", "_id": "123", "_retry_on_conflict" : 3} }{ "doc" : {"title" : "My updated blog post"} }在uri中指定了索引和类型就是针对具体索引及类型下的操作,没有指定就是针对整个ES的操作,需要在请求体中指定索引和类型
ES官方提供的批量处理测试数据,原网址数据已经找不到了,这里从谷粒商城评论区找的移动到自己的gitee上的https://gitee.com/earl-Li/ES-bulk-testdata/blob/master/%E6%95%B0%E6%8D%AE,注意这个数据的元数据不含索引和类型,必须要自己在URI中进行指定,否则执行报错,这里的URI使用【POST】
http://192.168.56.10:9200/bank/account/_bulk,使用官方的批量操作测试数据进行批量操作API的测试
检索相关
ES的检索支持两种方式:
第一种方式是在uri中直接添加请求参数
第二种方式是在请求体中添加请求参数
【GET】
http://192.168.56.10:9200/bank/_search?q=*&sort=account_number:asc请求体:无【使用uri中直接添加请求参数的方式,所以请求体无】
功能:查询索引bank下的所有数据并将查询结果按照字段
account_number进行升序排列响应内容:
took- Elasticsearch执行搜索的时间( 毫秒)time_out- 告诉我们搜索是否超时_shards- 告诉我们多少个分片被搜索了, 以及统计了成功/失败的搜索分片hits- 搜索结果hits.total- 搜索结果整体信息,value是有多少条记录被搜索到hits.hits- 实际的搜索结果数组( 默认为前 10 的文档),包含文档数据的元数据信息,当前文档的得分,_source原文档数据,sort是排序,从0开始;ES一次只会最多返回前10条数据,不会一次性返回所有数据,sort- 结果的排序 key( 键) ( 没有则按 score 排序)score和max_score–相关性得分和最高得分(全文检索用)【因为本次查询就是查所有,不涉及模糊匹配等过程,所以没有评分数据】
xxxxxxxxxx{"took" : 72,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 1000,"relation" : "eq"},"max_score" : null,"hits" : [{"_index" : "bank","_type" : "account","_id" : "0","_score" : null,"_source" : {"account_number" : 0,"balance" : 16623,"firstname" : "Bradshaw","lastname" : "Mckenzie","age" : 29,"gender" : "F","address" : "244 Columbus Place","employer" : "Euron","email" : "bradshawmckenzie@euron.com","city" : "Hobucken","state" : "CO"},"sort" : [0]},{"_index" : "bank","_type" : "account","_id" : "9","_score" : null,"_source" : {"account_number" : 9,"balance" : 24776,"firstname" : "Opal","lastname" : "Meadows","age" : 39,"gender" : "M","address" : "963 Neptune Avenue","employer" : "Cedward","email" : "opalmeadows@cedward.com","city" : "Olney","state" : "OH"},"sort" : [9]}]}}补充说明:
请求参数中
q=*表示查询所有,sort=account_number:asc表示查询数据按照字段account_number的值升序排列
【GET】
http://192.168.56.10:9200/bank/_search请求体:
query表示查询条件,match_all是进行精确匹配,匹配全部内容后面写写一个空的大括号sort表示设置排序规则,按照account_number进行升序排列;排序规则是一个数组,可以多个排序规则组合使用,如第二个查询请求体,对应的排序规则是先按照account_number字段升序,在account_number相等的情况下再按照balance字段降序排序规则可以简写为
字段: 排序方式的方式,如第三个查询请求体所示可以通过
from和size指定当前页第几位开始的文档数据和当前页的总记录条数
xxxxxxxxxx#第一个查询请求体{"query": {"match_all": {}},"sort": [{"account_number": {"order": "asc"}}]}#第二个查询请求体{"query": {"match_all": {}},"sort": [{"account_number": {"order": "asc"},"balance": {"order": "desc"}}]}#第三个查询请求体{"query": {"match_all": {}},"sort": [{"account_number": "asc"},{"balance": "desc"}]}#第四个查询请求体{"query": {"match_all": {}},"sort": [{"account_number": "asc"}],"from": 10,"size": 10}功能:查询索引bank下的所有数据并将查询结果按照字段
account_number进行升序排列响应内容:
xxxxxxxxxx{"took" : 1,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 1000,"relation" : "eq"},"max_score" : null,"hits" : [{"_index" : "bank","_type" : "account","_id" : "0","_score" : null,"_source" : {"account_number" : 0,"balance" : 16623,"firstname" : "Bradshaw","lastname" : "Mckenzie","age" : 29,"gender" : "F","address" : "244 Columbus Place","employer" : "Euron","email" : "bradshawmckenzie@euron.com","city" : "Hobucken","state" : "CO"},"sort" : [0]},{"_index" : "bank","_type" : "account","_id" : "9","_score" : null,"_source" : {"account_number" : 9,"balance" : 24776,"firstname" : "Opal","lastname" : "Meadows","age" : 39,"gender" : "M","address" : "963 Neptune Avenue","employer" : "Cedward","email" : "opalmeadows@cedward.com","city" : "Olney","state" : "OH"},"sort" : [9]}]}}补充说明:
这种将查询条件封装到请求体中的方式被ES称为Query DSL【领域对象语言】,ES官方文档中专门对Query DSL开了一个章节进行介绍,也是ES中最常用的查询方式,即请求体中封装查询参数的部分称为Query DSL
Query DSL的语法
ES提供一个可以被执行查询的JSON风格的DSL【domain-specific language 领域特定语言】,被称为Query DSL
一个查询语句DSL的典型结构
QUERY_NAME是指定查询操作,查询操作非常多,在kibana中可以看到相应的提示,这里只介绍常用的,完整的列表以后再补ARGUMENT: VALUE是对查询操作的进一步配置
xxxxxxxxxx{QUERY_NAME: {ARGUMENT: VALUE,ARGUMENT: VALUE,}}针对一个字段的DSL典型结构
xxxxxxxxxx{QUERY_NAME: {FIELD_NAME: {ARGUMENT: VALUE,ARGUMENT: VALUE,}}}常用的查询DSL以及相关
QUERY_NAME举例query定义查询的方法,match_all表示查询所有内容sort表示查询结果列表的排序方式,可以多字段组合排序,表示在前序字段相等的条件下后续字段依次内部排序,前序字段不等以前序为准from和size组合完成分页功能,from表示第一个结果在排序列表中的位次,size表示当前页显示的记录条数_source指定返回结果只包含指定的字段,属性值为字段名数组,不写表示返回完整文档
xxxxxxxxxx{"query": {"match_all": {}},"from": 0,"size": 5,"sort": [{"account_number": {"order": "desc"}}]"_source": ["age","balance"]}query.match的用法一般的使用规定是,查询非
text字段都使用term进行查询,文本字段的全文检索使用match来进行查询,多词条字符串的精确全文检索用match_phrase,字段值的完全精确匹配用match查询中的keyword基本类型【非字符串】的精确匹配
表示精确匹配索引bank下
account_number字段等于20的文档记录,这个20用字符串或者单纯的数字都是可以的
xxxxxxxxxxGET bank/_search{"query": {"match": {"account_number": "20"}}}字符串单个单词的全文检索
match检索字符串时会进行全文检索,查询出
address字段包含对应字符串milld的所有记录,并给出每条记录的相关性评分
xxxxxxxxxxGET bank/_search{"query": {"match": {"address": "mill"}}}字符串多个单词的全文检索
这种以空格分隔的字符串,ES会将检索字符串进行分词、词条过滤处理后再分别到倒排索引表中进行匹配,最终查询出address字段中包含
mill或者road或者mill road的所有记录,并给出相关性得分
xxxxxxxxxxGET bank/_search{"query": {"match": {"address": "mill road"}}}字符串的字段值精确匹配
字段.keyword会让字段值完整精确匹配检索字符串,必须字段值完全等于检索字符串才会被查询到
xxxxxxxxxxGET bank/_search{"query": {"match": {"address.keyword": "789 Madison Street"}}}
query.match_phrase的用法字符串多个单词不分词进行全文检索
查出字段
address中包含mill road的所有记录并给出相关性评分,注意是否区分大小写要看分词器的具体类型,默认的是不区分大小写的
xxxxxxxxxxGET bank/_search{"query": {"match_phrase": {"address": "mill road"}}}
query.multi_match的用法查询多个字段同时包含指定字符串的查询
查出字段
state或者address有一个或者同时包含字符串mill的文档记录,注意这种方式的检索字符串也是会分词的,即"query": "mill road"会分词查询出对应字段包含mill或者road的文档记录
xxxxxxxxxxGET bank/_search{"query": {"multi_match": {"query": "mill","fields": ["state","address"]}}}
bool的用法bool用于复合查询,用法是合并任何其他查询语句即QUERY_NAME,复合语句可以相互嵌套,可以组合出非常复杂的逻辑must表示必须满足must列举的所有条件,示例如下查询同时满足
address字段含有字符串mill,gender字段含有字符串M的
xxxxxxxxxxGET bank/_search{"query": {"bool": {"must": [{ "match": { "address": "mill" } },{ "match": { "gender": "M" } }]}}}range表示筛选出字段满足指定范围的文档记录
xxxxxxxxxxGET bank/_search{"query": {"bool": {"must": [{"range": {"age": {"gte": 18,"lte": 20}}},{"match": {"address": "mill"}}]}}}term的用法term会精确匹配对应的检索词条,而且在对text类型的字段【即字段值为字符串类型】的时候,由于文档进行了分词,但是term中的检索词条不会进行分词,即便文档对应字段数据和term的检索字符串一模一样,也无法检索到属性值相同的那个文档数据,因此term常用来做非text字段的精确匹配,注意经过测试是精确匹配,而且只会精确匹配非text类型的字段
xxxxxxxxxxGET bank/_search{"query": {"bool": {"must": [{"term": {"age": {"value": "28"}}},{"match": {"address": "990 Mill Road"}}]}}}should的查询条件不会影响查询结果,只会影响查询结果的评分,满足should中查询条件会增加文档的评分,如果query中只有should且should中只有一种匹配规则,should的条件会作为默认匹配条件改变查询的结果查询索引
bank下同时满足address字段含有词条mill,gender字段含有词条M的文档记录,优先展示address字段含有lane词条的文档记录
xxxxxxxxxxGET bank/_search{"query": {"bool": {"must": [{ "match": { "address": "mill" } },{ "match": { "gender": "M" } }],"should": [{"match": { "address": "lane" }}]}}}must_not表示查询到的文档必须满足不是指定的查询条件查询索引
bank下同时满足address字段含有词条mill以及gender字段含有词条M,且email字段不含有词条baluba.com的文档记录,优先展示address字段含有lane词条的文档记录
xxxxxxxxxxGET bank/_search{"query": {"bool": {"must": [{ "match": { "address": "mill" } },{ "match": { "gender": "M" } }],"should": [{"match": { "address": "lane" }}],"must_not": [{"match": { "email": "baluba.com" }}]}}}filter的用法bool中的must和should中的查询条件满足是会增加文档相关性评分的,must_not中的条件不会影响相关性评分;filter中的条件也不会影响相关性评分
filter中的条件可能和must中的条件一致,比如range要求筛选出某个字段在一定范围内的文档记录,请求的写法分别为
【must筛选范围】
must中没有match只有这个range也会有相关性得分
xxxxxxxxxxGET bank/_search{"query": {"bool": {"must": [{"range": {"age": {"gte": 18,"lte": 20}}},{"match": {"address": "mill"}}]}}}【filter筛选范围】
filter会将记录中不满足预设条件的文档记录直接过滤清除掉
满足filter中范围条件的文档记录的_score字段每条记录都为0,这是因为只进行了filter过滤,filter本身不计算得分,如果filter还组合了其他如should等条件,得到的记录还是会有相关性评分,比如以下这个含must的还是有评分数据的
xxxxxxxxxxGET bank/_search{"query": {"bool": {"must": [{"match": { "address": "mill"}}],"filter": {"range": {"balance": {"gte": 10000,"lte": 20000}}}}}}
Aggregation聚合分析相关
聚合功能是ES提供的数据分组和提取数据的功能,聚合类型比较多,有三类好几十种,这里主要讲terms和avg,其他的一些常用聚合函数后边用到再总结
聚合查询语法
aggregation_name是聚合操作的具体名称,aggregation_type是指定聚合操纵的类型,aggregation_body是指定聚合体【聚合体一般都指定field属性表示要聚合的字段以及size指定要展示的数据条数】,meta是指定聚合操作的元数据一个总的聚合查询语句中可以指定多个平行的聚合操作如
aggregation_name_2,也可以使用第一次聚合aggregation_name的结果再次发起聚合操作sub_aggregation【注意啊,这个操作只是把上次聚合的结果作为新聚合操作的分组,实际上你可以在年龄分组操作后再对同一个分组的薪资进行聚合操作】,sub_aggregation称为子聚合aggregations可以缩写为aggs
xxxxxxxxxx"aggregations" : {"<aggregation_name>" : {"<aggregation_type>" : {<aggregation_body>}[,"meta" : { [<meta_data_body>] } ]?[,"aggregations" : { [<sub_aggregation>]+ } ]?}[,"<aggregation_name_2>" : { } ]*}一个查询操作多个平行聚合操作
搜索bank索引中的address字 段包含
mill的所有人的年龄分布以及平均年龄,但是不显示对应的记录详情aggs表示对query中的查询结果执行聚合操作,group_by_state是当前聚合的名字,term是一种聚合的类型AGG_TYPE,其他的聚合类型包括avg、termssize为0表示不显示query对应的即hits中的搜索数据
xxxxxxxxxxGET bank/_search{"query": {"match": {"address": "mill"}},"aggs": {"group_by_state": {"terms": {"field": "age","size": 10}},"avg_age": {"avg": {"field": "age"}}},"size": 0}响应结果
其中
hits中显示query查询的结果,因为size为0所以不显示查询结果,注意这个size也可以在aggs中的聚合类型内部使用,作用是只显示聚合结果中的前size条数据aggregations中显示聚合操作的结果,每个聚合操作的json结果都以聚合操作的名字作为json对象的名字,doc_count_error_upper_bound是聚合中发生的错误信息,sum_other_doc_count是本次聚合操作统计到的其他文档的数量,buckets意思是桶,桶中的每个json对象都是一个统计结果,key表示一个结果的统计值,doc_count表示当前统计值下的文档记录数量,比如年龄为38的文档有2个,avg_age是第二个聚合操作的结果,value显示当前所有文档的平均年龄
xxxxxxxxxx{"took" : 17,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 4,"relation" : "eq"},"max_score" : null,"hits" : [ ]},"aggregations" : {"avg_age" : {"value" : 34.0},"group_by_state" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : 38,"doc_count" : 2},{"key" : 28,"doc_count" : 1},{"key" : 32,"doc_count" : 1}]}}}
一个聚合操作含有子聚合操作的查询
按照年龄进行分组聚合,并对每个年龄分组求这些年龄段的人的平均薪资
xxxxxxxxxxGET bank/account/_search{"query": {"match_all": {}},"aggs": {"age_avg": {"terms": {"field": "age","size": 1000},"aggs": {"banlances_avg": {"avg": {"field": "balance"}}}}},"size": 0}响应结果
xxxxxxxxxx{"took" : 9,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 1000,"relation" : "eq"},"max_score" : null,"hits" : [ ]},"aggregations" : {"age_avg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : 31,"doc_count" : 61,"banlances_avg" : {"value" : 28312.918032786885}},{"key" : 39,"doc_count" : 60,"banlances_avg" : {"value" : 25269.583333333332}},{"key" : 29,"doc_count" : 35,"banlances_avg" : {"value" : 29483.14285714286}}]}}}
对文本字段的聚合操作需要使用
字段.keyword,同时子聚合中使用多个并行聚合操作对所有年龄分组, 并且这些年龄段中字段gender为M的平均薪资和F的平均薪资以及这个年龄段的总体平均薪资
xxxxxxxxxxGET bank/account/_search{"query": {"match_all": {}},"aggs": {"age_agg": {"terms": {"field": "age","size": 100},"aggs": {"gender_agg": {"terms": {"field": "gender.keyword","size": 100},"aggs": {"balance_avg": {"avg": {"field": "balance"}}}},"balance_avg":{"avg": {"field": "balance"}}}}},"size": 0}响应结果
xxxxxxxxxx{"took" : 5,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 1000,"relation" : "eq"},"max_score" : null,"hits" : [ ]},"aggregations" : {"age_agg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 879,"buckets" : [{"key" : 31,"doc_count" : 61,"balance_avg" : {"value" : 28312.918032786885},"gender_agg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "M","doc_count" : 35,"balance_avg" : {"value" : 29565.628571428573}},{"key" : "F","doc_count" : 26,"balance_avg" : {"value" : 26626.576923076922}}]}},{"key" : 39,"doc_count" : 60,"balance_avg" : {"value" : 25269.583333333332},"gender_agg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "F","doc_count" : 38,"balance_avg" : {"value" : 26348.684210526317}},{"key" : "M","doc_count" : 22,"balance_avg" : {"value" : 23405.68181818182}}]}}]}}}
Mapping映射
字段类型
类型的所有分类见官方文档的Field datatypes,Mapping Type【即一个索引下有一个或者多个文档类型的类型】在ES 6.0版本已经被宣称过时并移除,原因是在Lucene中ES不同的文档类型但是名称相同的字段属性在Lucene中的处理方式是一样的,这种基于Lucene的对字段的处理方式要求在不同的类中定义相同的字段属性,否则不同定义的不同类型中同名字段属性在处理的时候就会发生冲突,导致Lucene的处理效率下降,因此废除类型怪你按就是为了提高ES的处理效率,这里的Mapping指的是数据类型
ES 7.x中URL中的type参数仍然是可选选项,但是已经修改为索引一个文档不再要求提供文档类型
ES 8.x中已经不在支持URL中的type参数,而是将索引从多类型迁移到单类型,每种类型文档一个独立的索引
核心类型
字符串
text
keyword
数字类型
long
integer
short
byte
double
float
half_float
scaled_float
日期类型
date
date_nanos
兼容纳秒的日期类型
布尔类型
boolean
二进制类型
binary
复合类型
数组类型
Array
对象类型
Object
Object类型用于单JSON对象
嵌套类型
nested
nested用于JSON对象数组
地理类型
地理坐标Geo
地理坐标Geo-points
Geo-points用于描述经纬度坐标
地理图形Geo-Shape
Geo-Shape用于描述多边形等复杂形状
特定类型
IP类型
ip用于描述ipv4和ipv6
补全类型Completion
completion提供自动完成提示
令牌计数类型Token count
token_count用于统计字符串的词条数量
附件类型attachment
参考mapper-attachements插件,支持将附件如Microsoft Office格式、Open Document格式、ePub、HTML等等索引为attachment数据类型
多字段muti-fields
概念
为了满足业务场景使用不同的方法同时索引同一个字段
如String类型字段可以同时映射为一个text字段用于全文检索,或者一个keyword字段用于排序和聚合,此外text字段还可以被各种类型的分析器standard analyzer、english analyzer、french analyzer来进行分词并建立索引
映射Mapping
概念
Mapping用于定义一个文档所包含的属性field是如何存储和被索引的,使用mapping可以定义:
哪些字符串属性应该被看做全文本属性
full text field哪些属性为数字类型、日期类型或者地理位置类型
文档中所有属性是否都能被索引
mapping还可以定义日期的格式
自定义映射规则来执行动态添加属性
索引一个文档,文档数据的类型会被ES自动进行类型猜测,这些映射可以在索引数据后修改,也可以在索引数据前进行指定
数字都会被猜测为long
字符串都会被猜测为文档text,且每个文本默认都会有对应的keyword子类型
API
【GET】
http://192.168.567.10:9200/bank/_mapping请求体:无
功能:查看索引下的映射信息
响应内容:
properties会显示所有字段的类型text类型会自动进行全文检索,对对应的文档信息进行分词分析,同时一个字段还可以有子类型fields,表示address字段还可以是keyword这种类型,表示该字段值可以被完全精确匹配
xxxxxxxxxx{"bank" : {"mappings" : {"properties" : {"account_number" : {"type" : "long"},"address" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}},"age" : {"type" : "long"},"balance" : {"type" : "long"},"state" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}}}}}}
【PUT】
http://192.168.56.10:9200/my-index请求体:
可以直接指定字段数据类型为keyword,注意这种指定方式指定的text没有子数据类型keyword,指定为keyword的类型和text类型也没有关系
xxxxxxxxxx{"mappings": {"properties": {"age": { "type": "integer" },"email": { "type": "keyword" },"name": { "type": "text" }}}}功能:创建索引
my-index的同时为索引指定映射规则响应内容:
xxxxxxxxxx{"acknowledged" : true,"shards_acknowledged" : true,"index" : "my_index"}【索引映射】
xxxxxxxxxx{"my_index" : {"mappings" : {"properties" : {"age" : {"type" : "integer"},"email" : {"type" : "keyword"},"name" : {"type" : "text"}}}}}补充说明:
不能再次使用该请求并在请求体中修改映射规则如请求体如下,实际上不更改映射规则也会报错,报错信息是目标索引已经存在
xxxxxxxxxx{"mappings": {"properties": {"age": { "type": "integer" },"email": { "type": "keyword" },"name": { "type": "text" },"employee_id": {"type": "long"}}}}响应内容
xxxxxxxxxx{"error": {"root_cause": [{"type": "resource_already_exists_exception","reason": "index [my_index/fb9JRcDTShyvbPWoq7vriQ] already exists","index_uuid": "fb9JRcDTShyvbPWoq7vriQ","index": "my_index"}],"type": "resource_already_exists_exception","reason": "index [my_index/fb9JRcDTShyvbPWoq7vriQ] already exists","index_uuid": "fb9JRcDTShyvbPWoq7vriQ","index": "my_index"},"status": 400}每个映射的数据类型在定义的时候都默认添加了
"index": true,即xxxxxxxxxx{"mappings": {"properties": {"employee_id": {"type": "long","index": true}}}}意思是当前字段属性会被索引并能被检索,如果将index设置为false,则该字段不会被索引,也无法通过该字段索引文档,该属性只是作为文档的冗余存储
【PUT】
http://192.168.56.10:9200/my_index/_mapping请求体:
xxxxxxxxxx{"properties": {"employee_id": {"type": "keyword","index": false}}}作用:为索引新增映射
响应内容:
xxxxxxxxxx{"acknowledged" : true}【此时对应索引下的映射信息】
xxxxxxxxxx{"my_index" : {"mappings" : {"properties" : {"age" : {"type" : "integer"},"email" : {"type" : "keyword"},"employee_id" : {"type" : "keyword","index" : false},"name" : {"type" : "text"}}}}}补充说明:
注意这种方式不能用于修改当前已经存在的映射关系,如不能把
email的数据类型改为text官方规定了已经存在的映射关系是不能修改的,变更一个已经存在的映射可能会导致已经存在的数据失效【比如检索规则】,如果是在需要变更某个字段的映射关系,官方建议创建一个新的索引并设置新的映射规则,并且索引老索引下的所有旧数据到新索引下,也即把旧数据迁移到被设置正确映射关系的新索引下
【POST】
http://192.168.56.10:9200/_reindex请求体:
【旧索引不含类型的情况】
该WEB API的作用是在两个不同的索引间迁移所有的数据
dest表示设置目标索引的位置、source表示旧索引的位置,index属性都填写对应的索引名
注意啊,经过测试,原来的索引有mapping映射而且新索引也有不同的mapping映射也一样可以通过该方式进行数据迁移
xxxxxxxxxx{"source": {"index": "twitter"},"dest": {"index": "new_twitter"}}【旧索引包含类型的情况】
即需要指定旧索引的索引和类型,新索引只需要指定索引不需要指定类型
❓:如果一个索引下有多个类型怎么办,可以把
type写成数组吗❓:如何查询一个索引下的全部文档类型
xxxxxxxxxx{"source": {"index": "bank","type": "account"},"dest": {"index": "new_bank"}}
分词器Tokenizer
分词器接收一个字符流,将其分割为独立的词条Token【也叫词元】,然后输出tokens流
ES提供很多内置的分词器,实际上是内置很多的字符过滤器,分词器和词条过滤器,三者公共构成分析器,通过这些过滤器和分析器,我们可以自定义各种类型的词条分析器
whitespace tokenizer遇到空白字符会分割文本,该分词器还负责记录各词条的顺序或者位置用于做短语查询或者临近词条的查询,还会记录词条对应的原始单词的字符偏移量【即起始字符和结束字符的下标】用于高亮显示搜索的内容等功能
分词器在官方文档的Analysis章节
分词相关API
【POST】
http://192.168.56.10:9200/_analyze请求体:
xxxxxxxxxx{"analyzer": "standard","text": "我是中国人!"}功能:使用标准分析器对指定文本进行分析并响应分析结果,
analyzer是指定分析器,常用的分析器有standard、ik响应内容:
xxxxxxxxxx{"tokens" : [{"token" : "我","start_offset" : 0,"end_offset" : 1,"type" : "<IDEOGRAPHIC>","position" : 0},{"token" : "是","start_offset" : 1,"end_offset" : 2,"type" : "<IDEOGRAPHIC>","position" : 1},{"token" : "中","start_offset" : 2,"end_offset" : 3,"type" : "<IDEOGRAPHIC>","position" : 2},{"token" : "国","start_offset" : 3,"end_offset" : 4,"type" : "<IDEOGRAPHIC>","position" : 3},{"token" : "人","start_offset" : 4,"end_offset" : 5,"type" : "<IDEOGRAPHIC>","position" : 4}]}补充说明:
标准分析器对英文文档会以空格作为标准对文档进行分词,对待中文的处理方式是直接分词到字,这种方式很不好,而且ES中内置的大多数分析器都是针对英文的,一般对中文的分析都使用ik分词器
ik分词器
ik分词器有两种常用的分词器
ik_smart、ik_max_word,不能直接指定分词器为ik,会报错
测试
ik_smart分词器【POST】
http://192.168.56.10:9200/_analyze请求体:
xxxxxxxxxx{"analyzer": "ik_smart","text": "我是中国人!"}功能:使用ik分词器的
ik_smart分词器分析文档我是中国人!,该分词器会尽可能按文档意思按最粗粒度进行分词,但是不会分词到字响应结果:
xxxxxxxxxx{"tokens" : [{"token" : "我","start_offset" : 0,"end_offset" : 1,"type" : "CN_CHAR","position" : 0},{"token" : "是","start_offset" : 1,"end_offset" : 2,"type" : "CN_CHAR","position" : 1},{"token" : "中国人","start_offset" : 2,"end_offset" : 5,"type" : "CN_WORD","position" : 2}]}补充说明:
标点符号是不进行索引的,默认无法识别自定义词
测试
ik_max_word分词器【POST】
http://192.168.56.10:9200/_analyze请求体:
xxxxxxxxxx{"analyzer": "ik_max_word","text": "我是中国人!"}功能:使用
ik_max_word分词器分析我是中国人!,该分词器会尽可能找到每一个短语,即便每个字被多次使用,但是不会分词到单个字响应内容:
xxxxxxxxxx{"tokens" : [{"token" : "我","start_offset" : 0,"end_offset" : 1,"type" : "CN_CHAR","position" : 0},{"token" : "是","start_offset" : 1,"end_offset" : 2,"type" : "CN_CHAR","position" : 1},{"token" : "中国人","start_offset" : 2,"end_offset" : 5,"type" : "CN_WORD","position" : 2},{"token" : "中国","start_offset" : 2,"end_offset" : 4,"type" : "CN_WORD","position" : 3},{"token" : "国人","start_offset" : 3,"end_offset" : 5,"type" : "CN_WORD","position" : 4}]}补充说明:
默认无法识别自定义词,如
尚硅谷
自定义ik扩展词库
对一些网络热词或者公司名字等词汇,ik分词器不能很好地识别,这时候我们可以配置自己的本地词库或者远程词库并在ik分词器的配置文件中进行配置
配置远程词库可以自己写一个项目,让ik分词器处理过程中向我们自己的项目发送请求;也可以配置nginx,将最新的词库放在nginx中,让ik分词器给nginx发送请求
这里使用Nginx配置远程词库的方式,原来的虚拟机1G内存现在已经不够用了,使用命令
free -m能看到当前的内存只有100来MB了,将虚拟机的内存修改为3G,由于ES的虚拟机内存此前只设置了512M也太小了,可能会导致ES运行中出现各种各样的问题,把容器实例删了重新创建容器实例,由于容器数据卷进行了挂载,重新创建容器实例指定相同的容器数据卷不会导致数据发生丢失
在nginx上搭建远程词库
1️⃣:参考整合Elasticsearch--环境安装安装nginx容器实例
2️⃣:在容器数据卷nginx的静态资源目录
/malldata/nginx/html下创建es目录专门存放ik分词器使用到的远程词库,在es目录下创建文件ik_remote_lexicon.txt,在文件中输入以下词条本质上是将词典从本地弄成网络资源供ik分词器自己去获取,区别只是ik分词器从ES本地获取或者从网络获取
xxxxxxxxxx尚硅谷乔碧萝3️⃣:使用命令
vi /malldata/elasticsearch/plugins/ik/config/IKAnalyzer.cfg.xml修改ik分词器的配置文件内容如下打开配置远程字典的配置注释,填入词典的URL地址
http://192.168.56.10/es/ik_remote_lexicon.txt
xxxxxxxxxx<properties><comment>IK Analyzer 扩展配置</comment><!--用户可以在这里配置自己的扩展字典 --><entry key="ext_dict"></entry><!--用户可以在这里配置自己的扩展停止词字典--><entry key="ext_stopwords"></entry><!--用户可以在这里配置远程扩展字典 --><entry key="remote_ext_dict">http://192.168.56.10/es/ik_remote_lexicon.txt</entry><!--用户可以在这里配置远程扩展停止词字典--><!-- <entry key="remote_ext_stopwords">words_location</entry> --></properties>4️⃣:使用命令
docker restart elasticsearch重启容器实例5️⃣:使用ES的ik分词API尝试索引包含对应词条的文档,观察相应词条是否索引成功
【POST】
/analyzexxxxxxxxxx{"analyzer": "ik_max_word","text": "尚硅谷的乔碧萝"}响应结果
xxxxxxxxxx{"tokens" : [{"token" : "尚硅谷","start_offset" : 0,"end_offset" : 3,"type" : "CN_WORD","position" : 0},{"token" : "硅谷","start_offset" : 1,"end_offset" : 3,"type" : "CN_WORD","position" : 1},{"token" : "的","start_offset" : 3,"end_offset" : 4,"type" : "CN_CHAR","position" : 2},{"token" : "乔碧萝","start_offset" : 4,"end_offset" : 7,"type" : "CN_WORD","position" : 3}]}
Elasticsearch-Rest-Client
业务中检索请求的处理逻辑是前端发起检索请求给后端Java服务器,Java服务器向ES服务器发起检索请求获取数据并响应给前端,Java客户端操作ES的方式有两种
第一种方式是使用
spring-data-elasticsearch:transport-api.jar通过ES的TCP端口9300,也即节点间的通信端口;这种方式SpringBoot版本不同,对应的transport-api.jar也不同,更换ES的版本就要更换对应的transport-api.jar和SpringBoot的版本,而且ES版本对应的transport-api.jar根本就没出或者SpringBoot压根还没整合,这样不好;其次7.x版本已经不建议使用transport-api.jar,8以后就直接准备废弃了通过9300端口操作ES的jar包第二种方式是通过HTTP协议走9200端口发送请求操作ES,市面上通过这种方式操作ES的产品有
JestClient:非官方,更新慢,从maven仓库可以查询到最近版本的更新时间,比较慢,落后ES好几个小版本
RestTemplate:这个产品只是模拟发送HTTP请求,ES很多操作需要自己进行封装,封装起来很麻烦
HttpClient:该产品也只是模拟发送HTTP请求,ES的相关请求和响应数据处理需要自己封装,很麻烦;像这些只能用来发送HTTP请求的如OKHTTP等等都可以操作ES,但是DSL语句和响应结果需要自己封装工具进行处理
Elasticsearch-Rest-Client:官方RestClient,封装了ES操作,API层次比较分明,官方的ES发布到哪个版本,这个工具也会同时更新相应的版本,本项目就使用该客户端
据说有个开源的ebatis,用起来也非常爽
Elasticsearch-Rest-Client的官方文档在ES的Docs中的Elasticsearch Clients章节,里面列举了各种语言对ES的操作API,其中还有JavaScript客户端,但是ES一般属于后台服务器集群中一部分,一般不直接对外暴露,暴露可能会被公网恶意利用;使用js操作也不需要使用ES官方的工具,直接用js发送请求即可;Java API是基于9300端口操作ES的【而且文档标记7.0版本已经过时,在8.0版本将移除,在文档中推荐使用Java High Level REST Client,Java High Level REST Client是Java REST Client中两个工具的一种,还有一种是Java Low Level REST Client,两者的关系相当于
mybatis<High>和JDBC<Low>的关系;现在8.13版本都过时了,现在只有一个Java Client了】,Java REST Client是基于9200端口操作ES的❓:为什么不用js发送查询请求,由nginx进行转发呢,还是因为安全的原因吗?反正就是用后端服务器调用来查询,以后再去看实际的情况
创建一个单独的模块
mall-search来使用Elasticsearch-Rest-Client中的Java High Level REST Client来操作ES服务器集群
搭建操作ES的模块
1️⃣:创建模块
mall-search,勾选整合Web中的Spring Web说明:NoSQL中有个Spring Data Elasticsearch因为最新只整合到6.3版本的ES【当时ES的最新版本是7.4】,所以就不考虑SpringData Elasticsearch,如果ES使用的版本不是那么新,选择SpringData Elasticsearch其实也是很好的选择,相比于官方的Elasticsearch-Rest-Client做了更简化的封装
2️⃣:导入
Java High Level REST Client的maven依赖,将版本号改为对应ES服务器的版本号,将ES服务器的版本号在properties标签中进行重新指定注意通过右侧的maven依赖树能够看到elasticsearch-rest-high-level-client虽然版本是7.4.2,但是子依赖中的部分版本还是6.8.5,这是因为SpringBoot对ES的版本进行了默认仲裁,SpringBoot2.2.2.RELEASE当引入SpringData Elasticsearch会自动仲裁Elasticsearch的版本为6.8.5【点开父依赖中的
spring-boot-starter-parent的父依赖的spring-boot-dependencies能够看见相关的版本信息】
xxxxxxxxxx<!--导入es的rest-high-level-client--><dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId><version>7.4.2</version></dependency>更改SpringBoot对Elasticsearch的版本自动仲裁,刷新maven直到依赖树中的相关依赖版本全部变成7.4.2
xxxxxxxxxx<properties><elasticsearch.version>7.4.2</elasticsearch.version></properties>
3️⃣:对
rest-high-level-client进行配置🔎:如果使用SpringData Elasticsearch对ES操作,配置就非常简单,这个在ES的整合SpringData Elasticsearch中已经实现了,这里要配置我们自己选择的
rest-high-level-client会稍微复杂一些编写配置类
MallElasticsearchConfig并注入IoC容器,这个配置类参考ES的官方文档Java High Level REST Client中的Getting started中的Initialization需要创建一个
RestHighLevelClient实例client,通过该实例来创建ES的操作对象
【单节点集群的创建客户端实例】
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 对Java High Level REST Client进行配置,配置ES操作对象* @创建日期 2024/05/24* @since 1.0.0*/public class MallElasticSearchConfig {/*** @return {@link RestHighLevelClient }* @描述 通过单节点集群的ip地址和端口以及通信协议名称来创建RestHighLevelClient对象* @author Earl* @version 1.0.0* @创建日期 2024/05/24* @since 1.0.0*/public RestHighLevelClient esRESTClient(){RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("192.168.56.10", 9200, "http")));return client;}}【多节点集群下的创建客户端实例】
多节点集群就在
RestClient.builder(HttpHost...)方法中的可变长度参数列表中输入各个节点的IP信息
xxxxxxxxxxpublic RestHighLevelClient esRESTClient(){RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http"),new HttpHost("localhost", 9201, "http")));return client;}
4️⃣:导入模块
mall-common引入注册中心【这里面引入的其他依赖挺多的,包含mp、Lombok、HttpCore、数据校验、Servlet API等】,配置配置中心、注册中心,服务名称在主启动类上使用注解@EnableDiscoveryClient开启服务的注册发现功能,在主启动类使用@SpringBootApplication(exclude = DataSourceAutoConfiguration.class)排除数据源【配置中心
bootstrap.properties配置】注意
bootstrap.properties文件必须在引入nacos的配置中心依赖后才会展示出小叶子图标
xxxxxxxxxxspring.application.name=mall-stockspring.cloud.nacos.config.server-addr=127.0.0.1:8848spring.cloud.nacos.config.namespace=9c29064b-64f8-4a43-9375-eceb6e3c79575️⃣:编写测试类检查ES操作对象是否创建成功
只要能打印出client对象,说明成功连接并创建ES操作对象,后续只需要参考官方文档使用对应的API即可,对应的文档也在
Java High Level REST Client中的所有APIs部分
xxxxxxxxxx(SpringRunner.class)public class MallSearchApplicationTests {private RestHighLevelClient esRESTClient;public void contextLoads() {System.out.println(esRESTClient);//org.elasticsearch.client.RestHighLevelClient@3c9c6245}}
Java High Level REST Client API
RequestOptions
RequestOptions是请求设置项,ES添加了安全访问规则的情况下,所有的请求都必须携带一些安全相关的头信息,通过RequestOptions来对所有请求做一些统一设置,设置的文档在Java Low Level REST Client的文档
官方建议将RequestOptions做成单实例,所有请求都来共享这一个单实例RequestOptions,使用RequestOptions的各类型builder来为请求头添加各种头信息,比如头Authorization=Bearer+授权令牌,还可以使用builder来自定义响应的消费者,比如和异步相关的HttpAsyncResponseconsumerFactory
将RequestOptions添加至
mall-search模块的统一配置类中配置实例
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 对Java High Level REST Client进行配置,配置ES操作对象、RequestOptions对象* @创建日期 2024/05/24* @since 1.0.0*/public class MallElasticSearchConfig {public static final RequestOptions COMMON_OPTIONS;//这里可以结合单实例的五种方式有时间看看哪种好static {RequestOptions.Builder builder = RequestOptions.DEFAULT.toBuilder();//以下是RequestOptions的各种配置,按需要到时候再添加//builder.addHeader("Authorization","Bearer"+TOKEN);//builder.setHttpAsyncResponseConsumerFactory(// new HttpAsyncResponseConsumerFactory// .HeapBufferedResponseConsumerFactory(30*1024*1024*1024)//);COMMON_OPTIONS=builder.build();}/*** @return {@link RestHighLevelClient }* @描述 通过单节点集群的ip地址和端口以及通信协议来创建RestHighLevelClient对象* @author Earl* @version 1.0.0* @创建日期 2024/05/24* @since 1.0.0*/public RestHighLevelClient esRESTClient(){RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("192.168.56.10", 9200, "http")));return client;}}
Document APIs
索引文档到ES
使用IndexRequest对象来索引一个文档,创建IndexRequest对象时指定索引名称,也可以创建IndexRequest以后指定,IndexRequest对象中大部分属性都有对应的同名方法来传参对应的属性值,如index和id等;ES服务器中没有对应索引会自动创建同名索引;而且该api是保存更新操作二合一,多次操作会更新版本号
可以使用各种工具来将文档数据对象转换为json格式的字符串
indexRequest的source方法是传参文档数据,支持如下多种参数类型,最常用的是直接传参一个json字符串
文档数据参数类型1:JSON字符串
注意传递JSON格式的数据一定要指定内容类型为
XContentType.JSON,否则会报错提示传参的Object对象只有一个
xxxxxxxxxxIndexRequest request = new IndexRequest("posts");request.id("1");String jsonString = "{" +"\"user\":\"kimchy\"," +"\"postDate\":\"2013-01-30\"," +"\"message\":\"trying out Elasticsearch\"" +"}";request.source(jsonString, XContentType.JSON);文档数据参数类型2:Map集合
xxxxxxxxxxMap<String, Object> jsonMap = new HashMap<>();jsonMap.put("user", "kimchy");jsonMap.put("postDate", new Date());jsonMap.put("message", "trying out Elasticsearch");IndexRequest indexRequest = new IndexRequest("posts").id("1").source(jsonMap);文档数据参数类型3:K-V键值对构造的
XContentBuilder,直接在大括号内用XContentBuilder的相关方法传递键值对数据xxxxxxxxxxXContentBuilder builder = XContentFactory.jsonBuilder();builder.startObject();{builder.field("user", "kimchy");builder.timeField("postDate", new Date());builder.field("message", "trying out Elasticsearch");}builder.endObject();IndexRequest indexRequest = new IndexRequest("posts").id("1").source(builder);文档数据参数类型4:可变长度参数列表直接传入键值对
xxxxxxxxxxIndexRequest indexRequest = new IndexRequest("posts").id("1").source("user", "kimchy","postDate", new Date(),"message", "trying out Elasticsearch");
传参JSON字符串代码实例
xxxxxxxxxx(SpringRunner.class)//指定使用Spring的驱动来跑单元测试,这是老版本SpringBoot的写法,新版本已经不这么写了public class MallSearchApplicationTests {private RestHighLevelClient esRESTClient;/*** @描述 IndexAPI索引一个文档* @author Earl* @version 1.0.0* @创建日期 2024/05/27* @since 1.0.0*/public void indexDoc() throws IOException {//创建IndexRequest对象,构建的时候指定文档对应的索引名称IndexRequest indexRequest = new IndexRequest("users");//指定文档的id,文档id的类型要求传入String类型indexRequest.id("1");//构建一个文档数据对象User user = new User("张三","男",18);//使用fastjson来将文档数据对象处理成json字符串,注意nacos-discovery中的父依赖nacos-api中引入了fastjson,可以直接用String userJSONStr = JSON.toJSONString(user);//indexRequest.source(userJSONStr);传入要索引的文档数据,支持的方式有四种,最常用的就是传入json字符串的方式indexRequest.source(userJSONStr);//执行索引文档的操作,要传参RequestOptionsIndexResponse response = esRESTClient.index(indexRequest, MallElasticSearchConfig.COMMON_OPTIONS);System.out.println(response);//}class User{private String userName;private String gender;private Integer age;}}IndexRequest中还可以设置文档保存超时时间、刷新策略、版本号等等
文档数据的保存可以分为同步和异步两种方式,同步是等待保存操作执行结束再继续执行后续代码,异步是不等待数据继续执行后续代码用监听器监听响应后执行回调,暂时先不考虑异步的问题,上述代码使用的是同步的索引文档操作
Search APIs
文档中包含了所有对文档的检索操作和聚合查询操作,做检索都是通过构建SearchRequest对象来封装检索条件实现的
检索和聚合文档记录
使用
searchRequest.source(searchSourceBuilder);来封装检索条件用
esRESTClient.search(searchRequest,MallElasticSearchConfig.COMMON_OPTIONS)来执行检索操作用
searchSourceBuilder.query(QueryBuilders.matchQuery("address","mill"));来封装词条检索条件用
searchSourceBuilder.from();和searchSourceBuilder.size();来封装分页操作用
searchSourceBuilder.aggregation(AggregationBuilders.terms("ageByGroup").field("age").size(10));来封装值分布聚合操作条件用
searchSourceBuilder.aggregation(AggregationBuilders.avg("balanceAvg").field("balance"));来封装均值聚合操作条件带条件检索和Terms值分布和AVG均值聚合操作的代码实例
以下代码前半部分是发起带聚合的检索操作
后半部分是获取响应的记录以及聚合操作的结果
xxxxxxxxxx(SpringRunner.class)public class MallSearchApplicationTests {private RestHighLevelClient esRESTClient;/*** @描述 检索和聚合操作满足条件的文档* @author Earl* @version 1.0.0* @创建日期 2024/05/27* @since 1.0.0*/public void searchDoc() throws IOException {//创建检索请求SearchRequest searchRequest = new SearchRequest();//指定检索文档的索引范围,是可变长度参数列表,表示可以从1个或者多个索引下检索文档searchRequest.indices("bank");//通过SearchSourceBuilder来构建检索条件,用searchRequest来封装检索条件SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();//用SearchSourceBuilder来构建检索条件,在文档的Using the SearchSourceBuilder部分,这里面的根属性和DSL的json对象的对象名是一样的//而且都使用链式编程的方式//query方法需要传参QueryBuilder,QueryBuilders是QueryBuilder对应的工具类,可以快速方便地生成QueryBuilder//QueryBuilders中有matchQuery方法对应DSL中的match,有matchAllQuery方法对应DSL中的matchAll,传参键值对String-ObjectsearchSourceBuilder.query(QueryBuilders.matchQuery("address","mill"));//searchSourceBuilder.from();//searchSourceBuilder.size();//构造聚合条件,聚合函数aggregation中需要传参封装聚合查询参数的AggregationBuilder,相应的也有对应的工具类AggregationBuilders快速构建AggregationBuilder//构造第一个聚合//terms聚合函数用于对字段统计分组[按字段的值分布进行聚合],传参本次聚合的名字,用于存放返回的聚合信息,链式调用来设置要统计的字段和返回的记录条数等searchSourceBuilder.aggregation(AggregationBuilders.terms("ageByGroup").field("age").size(10));//构造第二个聚合//对薪资进行平均值聚合,每个聚合都要使用searchSourceBuilder.aggregation对每个searchBuilder都进行聚合searchSourceBuilder.aggregation(AggregationBuilders.avg("balanceAvg").field("balance"));System.out.println(searchSourceBuilder);//除了我们设置的检索条件外,还添加了很多默认设置,如boost,默认是1.0,是设置当前检索条件的权重/*** {* "query": {* "match": {* "address": {* "query": "mill",* "operator": "OR",* "prefix_length": 0,* "max_expansions": 50,* "fuzzy_transpositions": true,* "lenient": false,* "zero_terms_query": "NONE",* "auto_generate_synonyms_phrase_query": true,* "boost": 1.0* }* }* },* "aggregations": {* "ageByGroup": {* "terms": {* "field": "age",* "size": 10,* "min_doc_count": 1,* "shard_min_doc_count": 0,* "show_term_doc_count_error": false,* "order": [* {* "_count": "desc"* },* {* "_key": "asc"* }* ]* }* },* "balanceAvg": {* "avg": {* "field": "balance"* }* }* }* }* */searchRequest.source(searchSourceBuilder);//执行检索操作,传参searchRequest和RequestOptionsSearchResponse searchResponse = esRESTClient.search(searchRequest,MallElasticSearchConfig.COMMON_OPTIONS);//searchResponse是检索结果,封装了检索信息,官方文档也介绍了各个属性的具体获取apiSystem.out.println(searchResponse);//响应结果中最重要的是命中记录和聚合结果的获取/**响应结果* {* "took": 3,* "timed_out": false,* "_shards": {* "total": 1,* "successful": 1,* "skipped": 0,* "failed": 0* },* "hits": {* "total": {* "value": 4,* "relation": "eq"* },* "max_score": 5.4032025,* "hits": [{* "_index": "bank",* "_type": "account",* "_id": "970",* "_score": 5.4032025,* "_source": {* "account_number": 970,* "balance": 19648,* "firstname": "Forbes",* "lastname": "Wallace",* "age": 28,* "gender": "M",* "address": "990 Mill Road",* "employer": "Pheast",* "email": "forbeswallace@pheast.com",* "city": "Lopezo",* "state": "AK"* }* }, {* "_index": "bank",* "_type": "account",* "_id": "136",* "_score": 5.4032025,* "_source": {* "account_number": 136,* "balance": 45801,* "firstname": "Winnie",* "lastname": "Holland",* "age": 38,* "gender": "M",* "address": "198 Mill Lane",* "employer": "Neteria",* "email": "winnieholland@neteria.com",* "city": "Urie",* "state": "IL"* }* }, {* "_index": "bank",* "_type": "account",* "_id": "345",* "_score": 5.4032025,* "_source": {* "account_number": 345,* "balance": 9812,* "firstname": "Parker",* "lastname": "Hines",* "age": 38,* "gender": "M",* "address": "715 Mill Avenue",* "employer": "Baluba",* "email": "parkerhines@baluba.com",* "city": "Blackgum",* "state": "KY"* }* }, {* "_index": "bank",* "_type": "account",* "_id": "472",* "_score": 5.4032025,* "_source": {* "account_number": 472,* "balance": 25571,* "firstname": "Lee",* "lastname": "Long",* "age": 32,* "gender": "F",* "address": "288 Mill Street",* "employer": "Comverges",* "email": "leelong@comverges.com",* "city": "Movico",* "state": "MT"* }* }]* },* "aggregations": {* "avg#balanceAvg": {* "value": 25208.0* },* "lterms#ageByGroup": {* "doc_count_error_upper_bound": 0,* "sum_other_doc_count": 0,* "buckets": [{* "key": 38,* "doc_count": 2* }, {* "key": 28,* "doc_count": 1* }, {* "key": 32,* "doc_count": 1* }]* }* }* }* *///获取响应状态码RestStatus status = searchResponse.status();//获取检索操作花费的时间TimeValue took = searchResponse.getTook();//检索操作是否提前终止Boolean terminatedEarly = searchResponse.isTerminatedEarly();//检索操作是否超时boolean timedOut = searchResponse.isTimedOut();//检索涉及的分片总数int totalShards = searchResponse.getTotalShards();//成功的分片数int successfulShards = searchResponse.getSuccessfulShards();//失败的分片数int failedShards = searchResponse.getFailedShards();//操作失败的分片检索for (ShardSearchFailure failure : searchResponse.getShardFailures()) {//对失败检索的自定义操作}//获取检索命中的记录,这里面包含命中记录总数和记录的数据SearchHits hits = searchResponse.getHits();//拿到命中记录的总记录数,其中的value才是确切的总记录数TotalHits totalHits = hits.getTotalHits();long value = totalHits.value;//记录的相关性得分TotalHits.Relation relation = totalHits.relation;//命中记录的最大得分float maxScore = hits.getMaxScore();//获取记录数据数组,这是真正命中的所有记录,每个记录都有对应的索引、类型、文档id和对应的文档评分,以及SearchHit[] searchHits = hits.getHits();for (SearchHit searchHit : searchHits) {//自定义对命中记录的操作//获取命中记录的索引String index = searchHit.getIndex();//获取命中记录的idString id = searchHit.getId();//获取命中记录的分数float score = searchHit.getScore();//将返回的命中记录转换为对应的json字符串,命中记录统一在名为_source的数组下/**** :{"account_number":970,"balance":19648,"firstname":"Forbes","lastname":"Wallace","age":28,"gender":"M","address":"990 Mill Road","employer":"Pheast","email":"forbeswallace@pheast.com","city":"Lopezo","state":"AK"}* :{"account_number":136,"balance":45801,"firstname":"Winnie","lastname":"Holland","age":38,"gender":"M","address":"198 Mill Lane","employer":"Neteria","email":"winnieholland@neteria.com","city":"Urie","state":"IL"}* :{"account_number":345,"balance":9812,"firstname":"Parker","lastname":"Hines","age":38,"gender":"M","address":"715 Mill Avenue","employer":"Baluba","email":"parkerhines@baluba.com","city":"Blackgum","state":"KY"}* :{"account_number":472,"balance":25571,"firstname":"Lee","lastname":"Long","age":32,"gender":"F","address":"288 Mill Street","employer":"Comverges","email":"leelong@comverges.com","city":"Movico","state":"MT"}** */String sourceAsString = searchHit.getSourceAsString();System.out.println(":"+sourceAsString);Account account = JSON.parseObject(sourceAsString, Account.class);System.out.println("account: "+account);}//获取本次检索拿到的聚合信息//拿到所有的聚合根数据Aggregations aggregations = searchResponse.getAggregations();//将聚合信息转换为list集合来进行遍历for (Aggregation aggregation : aggregations.asList()) {System.out.println("####"+aggregation+" | "+aggregation.getName()+" | "+aggregation.getMetaData());/*** ####org.elasticsearch.search.aggregations.metrics.ParsedAvg@4872669f | balanceAvg | null* ####org.elasticsearch.search.aggregations.bucket.terms.ParsedLongTerms@483f286e | ageByGroup | null* 备注:这种方式拿不到具体的聚合数据,要获取对应的聚合数据需要将类型Aggregation强转为对应的子类型,不同的聚合子类型的聚合数据名称不同,* 所以用循环不好处理* */}//其实就是ES自定义了一套jsonBean对象,用户将响应数据转换为对应的对象来获取数据//获取响应的第一个聚合数据Terms ageByGroup = (Terms)aggregations.get("ageByGroup");//对年龄的值分布聚合响应的是Bucket的list集合for (Terms.Bucket bucket : ageByGroup.getBuckets()) {//获取bucket中的key属性,对应属性值分布的每个值和对应值下的文档数量String keyAsString = bucket.getKeyAsString();System.out.println("年龄:"+keyAsString+";记录数:"+bucket.getDocCount());}//获取第二个聚合数据Avg balanceAvg = (Avg) aggregations.get("balanceAvg");System.out.println("平均薪资:"+balanceAvg.getValue());/*** 聚合结果* 年龄:38;记录数:2* 年龄:28;记录数:1* 年龄:32;记录数:1* 平均薪资:25208.0* *//*** ES的对应响应内容* 名字实际上还是ageByGroup和balanceAvg,井号前面的是聚合类型,这个聚合类型是ES官方方便自己添加的,从aggregations中获取用户要的聚合数据* 使用自定义聚合名称即可* "aggregations": {* "avg#balanceAvg": {* "value": 25208.0* },* "lterms#ageByGroup": {* "doc_count_error_upper_bound": 0,* "sum_other_doc_count": 0,* "buckets": [{* "key": 38,* "doc_count": 2* }, {* "key": 28,* "doc_count": 1* }, {* "key": 32,* "doc_count": 1* }]* }* }* }* */}/*** Auto-generated: 2024-05-29 0:43:57* @描述 根据ES返回的结果使用Json工具bejson生成的JavaBean对象,以供测试程序使用,使用Lombok来生成getter和setter以及toString方法* 注意fastjson只能创建静态的内部类实例* @author bejson.com (i@bejson.com)* @website http://www.bejson.com/java2pojo/*/static class Account {private int account_number;private int balance;private String firstname;private String lastname;private int age;private String gender;private String address;private String employer;private String email;private String city;private String state;}}
must函数的用法
1️⃣示例代码
请求参数
http://localhost:12000/list.html?keyword=华为&catelog3Id=225&attrs=11_海思芯片:Apple芯片&attrs=12_HUAWEI Kirin 980:M1这种方式也可以使用在要求满足每一种属性可能的属性值条件的场景,这个方式也是可用的;经过验证这种方式不能用啊,这个语句很神奇啊,must下只有任意一个bool语句都能正常检索,但是must下同时有这两个bool会直接什么都查不出来啊,而且看起来逻辑也是对的,这是框架底层的原因,不要深究,直接用第四种
xxxxxxxxxxif (param.getAttrs() != null && param.getAttrs().size()>0) {//封装属性的query语句BoolQueryBuilder nestedBoolQueryBuilder = QueryBuilders.boolQuery();for (String attr:param.getAttrs()) {//对属性进行处理,属性信息格式为attrs=属性id1_属性值1:属性值2String[] attrObject = attr.split("_");String[] attrValue = attrObject[1].split(":");nestedBoolQueryBuilder.must(QueryBuilders.boolQuery().must(QueryBuilders.termQuery("attrs.attrId",attrObject[0])).must(QueryBuilders.termsQuery("attrs.attrValue",attrValue)));}boolQueryBuilder.filter(QueryBuilders.nestedQuery("attrs",nestedBoolQueryBuilder,ScoreMode.None));}对应DSL
可以看到,同一个
QueryBuilders.boolQuery()不论调用多少个must(),都是放在一个"must"语句中
xxxxxxxxxx{"filter": [{"term": {"catelogId": {"value": 225,"boost": 1}}},{"nested": {"query": {"bool": {"must": [{"bool": {"must": [{"term": {"attrs.attrId": {"value": "11","boost": 1}}},{"terms": {"attrs.attrValue": ["海思芯片","Apple芯片"],"boost": 1}}],"adjust_pure_negative": true,"boost": 1}},{"bool": {"must": [{"term": {"attrs.attrId": {"value": "12","boost": 1}}},{"terms": {"attrs.attrValue": ["HUAWEI Kirin 980","M1"],"boost": 1}}],"adjust_pure_negative": true,"boost": 1}}],"adjust_pure_negative": true,"boost": 1}},"path": "attrs","ignore_unmapped": false,"score_mode": "none","boost": 1}}]}2️⃣示例代码
请求参数
http://localhost:12000/list.html?keyword=华为&catelog3Id=225&attrs=11_海思芯片:Apple芯片&attrs=12_HUAWEI Kirin 980:M1
xxxxxxxxxxif (param.getAttrs() != null && param.getAttrs().size()>0) {//封装属性的query语句BoolQueryBuilder nestedBoolQueryBuilder = QueryBuilders.boolQuery();for (String attr:param.getAttrs()) {//对属性进行处理,属性信息格式为attrs=属性id1_属性值1:属性值2String[] attrObject = attr.split("_");String[] attrValue = attrObject[1].split(":"); nestedBoolQueryBuilder.must(QueryBuilders.termQuery("attrs.attrId",attrObject[0])).must(QueryBuilders.termsQuery("attrs.attrValue",attrValue));} boolQueryBuilder.filter(QueryBuilders.nestedQuery("attrs",nestedBoolQueryBuilder,ScoreMode.None));}对应DSL
可以看到,我们希望每个属性的属性id和可能的属性值关联起来,但是由于对同一个
nestedBoolQueryBuilder调用must方法,导致所有的属性id和属性值都关联到一个must中去了
xxxxxxxxxx{"filter": [{"term": {"catelogId": {"value": 225,"boost": 1}}},{"nested": {"query": {"bool": {"must": [{"term": {"attrs.attrId": {"value": "11","boost": 1}}},{"terms": {"attrs.attrValue": ["海思芯片","Apple芯片"],"boost": 1}},{"term": {"attrs.attrId": {"value": "12","boost": 1}}},{"terms": {"attrs.attrValue": ["HUAWEI Kirin 980","M1"],"boost": 1}}],"adjust_pure_negative": true,"boost": 1}},"path": "attrs","ignore_unmapped": false,"score_mode": "none","boost": 1}}]}3️⃣示例代码
用
bool语句隔开must,用should语句对各个must求或运算请求参数
http://localhost:12000/list.html?keyword=华为&catelog3Id=225&attrs=11_海思芯片:Apple芯片&attrs=12_HUAWEI Kirin 980:M1
xxxxxxxxxxif (param.getAttrs() != null && param.getAttrs().size()>0) {//封装属性的query语句BoolQueryBuilder nestedBoolQueryBuilder = QueryBuilders.boolQuery();for (String attr:param.getAttrs()) {//对属性进行处理,属性信息格式为attrs=属性id1_属性值1:属性值2String[] attrObject = attr.split("_");String[] attrValue = attrObject[1].split(":");nestedBoolQueryBuilder.should(QueryBuilders.boolQuery().must(QueryBuilders.termQuery("attrs.attrId",attrObject[0])).must(QueryBuilders.termsQuery("attrs.attrValue",attrValue)));} boolQueryBuilder.filter(QueryBuilders.nestedQuery("attrs",nestedBoolQueryBuilder,ScoreMode.None));}对应DSL
这个是能正常使用的,但是如果能有只构建"query"语句不带bool语句的API就更好了
不对啊,这个也不能用啊,因为要求是选出满足对应属性的商品,如果使用或就会导致商品只要满足一个属性就能被展示出来,但是实际上要求商品满足用户选择的所有属性,因此这里的should应该换成must,即第一种情况
xxxxxxxxxx{"filter": [{"term": {"catelogId": {"value": 225,"boost": 1}}},{"nested": {"query": {"bool": {"should": [{"bool": {"must": [{"term": {"attrs.attrId": {"value": "11","boost": 1}}},{"terms": {"attrs.attrValue": ["海思芯片","Apple芯片"],"boost": 1}}],"adjust_pure_negative": true,"boost": 1}},{"bool": {"must": [{"term": {"attrs.attrId": {"value": "12","boost": 1}}},{"terms": {"attrs.attrValue": ["HUAWEI Kirin 980","M1"],"boost": 1}}],"adjust_pure_negative": true,"boost": 1}}],"adjust_pure_negative": true,"boost": 1}},"path": "attrs","ignore_unmapped": false,"score_mode": "none","boost": 1}}],}4️⃣示例代码
请求参数
http://localhost:12000/list.html?keyword=华为&catelog3Id=225&attrs=11_海思芯片:Apple芯片&attrs=12_HUAWEI Kirin 980:M1
xxxxxxxxxxif (param.getAttrs() != null && param.getAttrs().size()>0) {/*比较一下和上面最终生成的DSL语句的区别,这段是老师的,如果上面的不对再用老师的试一下*/for (String attr:param.getAttrs()) {//封装属性的query语句BoolQueryBuilder nestedBoolQueryBuilder = QueryBuilders.boolQuery();//对属性进行处理,属性信息格式为attrs=属性id1_属性值1:属性值2String[] attrObject = attr.split("_");String[] attrValue = attrObject[1].split(":"); nestedBoolQueryBuilder.must(QueryBuilders.termQuery("attrs.attrId",attrObject[0])).must(QueryBuilders.termsQuery("attrs.attrValue",attrValue)); boolQueryBuilder.filter(QueryBuilders.nestedQuery("attrs",nestedBoolQueryBuilder,ScoreMode.None));}}对应DSL
这种相当于用
filter语句来过滤掉每一个属性匹配条件,这种也是可以用来处理同时满足所有商品属性
xxxxxxxxxx"filter": [{"term": {"catelogId": {"value": 225,"boost": 1}}},{"nested": {"query": {"bool": {"must": [{"term": {"attrs.attrId": {"value": "11","boost": 1}}},{"terms": {"attrs.attrValue": ["海思芯片","Apple芯片"],"boost": 1}}],"adjust_pure_negative": true,"boost": 1}},"path": "attrs","ignore_unmapped": false,"score_mode": "none","boost": 1}},{"nested": {"query": {"bool": {"must": [{"term": {"attrs.attrId": {"value": "12","boost": 1}}},{"terms": {"attrs.attrValue": ["HUAWEI Kirin 980","M1"],"boost": 1}}],"adjust_pure_negative": true,"boost": 1}},"path": "attrs","ignore_unmapped": false,"score_mode": "none","boost": 1}}]
ES在项目中的应用
ES作为全文检索引擎承担项目中的全文检索功能,如商城中按照商品名称或者商品的sku属性信息来全文检索相关的商品记录
ES还会承担项目中的日志分析检索功能,一些故障需要快速定位,日常运行产生的日志也存在全文检索需求,将日志存储在ES中来对日志做全文检索功能,日志的处理使用ELK技术栈,由LogStash负责收集日志,将搜集的日志存储到ES中,以Kibana作为可视化界面,这部分在运维阶段介绍ELK技术栈
腾讯云ES服务的环境架构
架构说明
服务器、移动设备、或者物联网传感器产生的日志通过Kafka或者LogStash搜集到ES服务器中,通过可视化工具来对日志进行检索和监控
架构图

商品上架
ES做sku全文检索分析
需要将sku商品信息存储在ES服务器上,将sku信息存入ES的过程称为商品上架,只有上架的商品才能在商城界面展示出来,没有上架的商品只能在后台管理系统看见
使用ES做全文检索而不采用mysql的原因是mysql的全文检索功能没有ES的强大,mysql做复杂全文检索的性能远不及ES,ES将数据存储在内存中,性能远高于mysql;其次,ES天然就支持分布式集群,如果当前集群内存不够,直接像集群中添加ES节点即可
由于内存比较贵,虽然商品上架点击的是spu管理中的上架按钮,但是为了节省内存,只向ES中保存商城搜索页面会使用到的数据【商品展示数据和用于检索的数据】,类似于商品图片,细节的sku属性,spu属性等商品详情页面都等拿到商品的sku_id后,商品的完整介绍、全部图片、完整的信息再去数据库直接查
业务逻辑
1️⃣:后台管理界面商品维护菜单下的spu管理中spu列表每条记录有对应的上架按钮,点击上架按钮一方面将商品的
spu_info表中的状态字段publish_status改为上架状态【0表示未上架状态,1表示上架状态】,另一方面对应的商品数据保存至ES服务器中2️⃣:分析需要存储到ES的具体数据
检索词条商品标题和副标题
用户可能按照商品sku的价格区间进行检索
可能按照商品的销量进行排序,以上都属于商品的sku属性
可能直接点击商品分类检索跳转商品页面,这是按照商品分类进行检索,需要保存商品的分类信息
可能直接点击商品的所属品牌,按照品牌进行检索,需要保存商品的品牌信息
可能按照商品额规格属性进行检索,如屏幕尺寸、CPU类型等等,因此还需要保存商品的spu属性
3️⃣:文档数据存储方案
设计1:如果每个商品都设计为如下的文档类型,这种设计的好处是方便检索,但是可能会存在大量的数据冗余,因为同一个spuId下存在大量的sku商品,但是这些商品的spu属性都是相同的,如果有100万个商品,平均每个商品有20个sku,假设每个sku的重复数据为100Byte,需要额外1000000*2KB=2000MB=2GB,一般来说,这个冗余量还是比较好处理,即使是20G的冗余也比较容易处理,加一根内存条就能解决
xxxxxxxxxx{skuId: 1,spuId: 11,skuTitle: 华为XX,price: 998,saleCount: 99,attrs: [{尺寸: 5寸},{CPU: 高通945},{分辨率: 全高清}]}设计2:如果商品设计为下列文档类型,这种方式检索也比较方便,数据也不会出现冗余存储;但是这种方式有一个致命问题,检索条件的spu属性是统计当前检索商品文档对应的所有spu的可能属性动态生成的,意味着比如检索一个品牌如小米,需要检索出商品名字含小米的全部商品,并且查询出所有的spuId,假设1000个商品对应4000个spu,需要单次网络传输传递4000个Long类型的id,每个Long类型数据占8个字节,单次查询spu属性的请求体数据大小为4000*8Byte=32KB,一个请求就会发送超过32KB的数据,如果是10000的并发,每秒内网传输的数据就是320MB的大小,像超大型电商平台百万的并发,内网传输的数据将会变成32GB,这将会造成极大的网络阻塞,而且还没有考虑其他请求的情况下【单是拆分出spu单独检索就会产生的额外开销】,因此考虑第一种冗余设计,以空间换时间
xxxxxxxxxxsku索引{skuId: 1,spuId: 11,xxxxsku相关信息}attr索引{spuId: 11,attrs: [{尺寸: 5寸},{CPU: 高通945},{分辨率: 全高清}]}
4️⃣:商品文档数据映射设计
索引product映射设计
skuId:用于用户点击后查询商品详情
spuId:用户点击商品后查询商品的spu信息,spu还会涉及到一个数据折叠功能,因此设计为keyword类型,后面讲
skuTitle:商品的标题,商品的副标题不进行保存,因为一般用户检索也是检索标题,注意只有商品标题才需要全文检索,因此只将标题设置为text类型并使用ik_smart分词器
skuPrice:做商品价格区间统计聚合使用,为了精度问题设计为keyword
skuImg:设置为
"index": false,让该字段不可被检索,但是可以被作为文档数据查出来,"doc_values": false意思是该字段不需要做聚合操作,冗余存储的字段都可以设置这两个属性来达到节省内存空间的目的【不会被索引和做一些聚合相关的其他操作】saleCount:商品销量用于销量排序
hasStock:是否有库存,用于用户点击仅显示有货按钮检索有库存的商品,存布尔类型,这样的好处是不需要频繁地更新文档数据【文档数据只要修改,ES就会重新索引文档,频繁更新就会极大增加维护索引的开销】,只有在商品没库存的时候才更改ES中的文档数据
hotScore:商品热度评分,用来表征商品的访问量
brandId:品牌id,用于商品按照品牌名进行检索
catalogId:商品分类id,用于商品按照商品分类进行检索
brandName、catalogName、brandImg:这三个字段用于展示对应的品牌图片、名字和商品分类名称,只需要被展示,不需要检索和聚合
attrs:当前商品的属性规格,nested表示attrs是一个数组【这个nested非常重要,不使用nested会出问题,因为spu属性的个数是未知的】,数组的每个元素包含attrId、attrName、attrValue
xxxxxxxxxxPUT product{"mappings": {"properties": {"skuId": {"type": "long"},"spuId": {"type": "keyword"},"skuTitle": {"type": "text","analyzer": "ik_smart"},"skuPrice": {"type": "keyword"},"skuImg": {"type": "keyword","index": false,"doc_values": false},"saleCount": {"type": "long"},"hasStock": {"type": "boolean"},"hotScore": {"type": "long"},"brandId": {"type": "long"},"catelogId": {"type": "long"},"brandName": {"type": "keyword","index": false,"doc_values": false},"brandImg": {"type": "keyword","index": false,"doc_values": false},"catelogName": {"type": "keyword","index": false,"doc_values": false},"attrs": {"type": "nested","properties": {"attrId": {"type": "long"},"attrName": {"type": "keyword","index": false,"doc_values": false},"attrValue": {"type": "keyword"}}}}}}
业务实现
前端点击商品系统spu管理的上架按钮,发送请求
http://localhost:88/api/product/spuinfo/${spuId}/up到后端接口创建ES中product索引文档数据对应的java实体类,注意,因为product模块和search模块都会使用该java实体类,选择将该实体类创建在common模块下,但是实际的微服务开发中,写search模块的哥们根本拿不到common模块的权限,实际上都是product模块中写一个product对应实体类,search模块再写一个相同的实体类
实体类【根据文档映射创建,JavaBean的属性类型与对应数据库实体类的属性类型保持一致,数据库没有的自定义,属性类型用静态内部类创建】
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 对应ES中product索引下的文档映射* @创建日期 2024/05/30* @since 1.0.0*/public class Product {/*** "properties": {* "skuId": {* "type": "long"* },* "spuId": {* "type": "keyword"* },* "skuTitle": {* "type": "text",* "analyzer": "ik_smart"* },* "skuPrice": {* "type": "keyword"* },* "skuImg": {* "type": "keyword",* "index": false,* "doc_values": false* },* "saleCount": {* "type": "long"* },* "hasStock": {* "type": "boolean"* },* "hotScore": {* "type": "long"* },* "brandId": {* "type": "long"* },* "catalogId": {* "type": "long"* },* "brandName": {* "type": "keyword",* "index": false,* "doc_values": false* },* "brandImg": {* "type": "keyword",* "index": false,* "doc_values": false* },* "catalogName": {* "type": "keyword",* "index": false,* "doc_values": false* },* "attrs": {* "type": "nested",* "properties": {* "attrId": {* "type": "long"* },* "attrName": {* "type": "keyword",* "index": false,* "doc_values": false* },* "attrValue": {* "type": "keyword"* }* }* }* }*/private Long skuId;private Long spuId;private String skuTitle;private BigDecimal skuPrice;private String skuImg;private Long saleCount;private Boolean hasStock;private Long hotScore;private Long brandId;private Long catelogId;private String brandName;private String brandImg;private String catelogName;private List<Attr> attrs;/*** @author Earl* @version 1.0.0* @描述 静态内部类也需要添加@Data注解来生成getter和setter* 为了其他第三方工具能对该实体类进行序列化和反序列化,需要添加权限修饰符public* 静态内部类才会和外部的类一起加载* @创建日期 2024/05/30* @since 1.0.0*/public static class Attr{private Long attrId;private String attrName;private String attrValue;}}
后端使用spuId获取spu下的所有skuInfo实体类,对sku信息进行属性对拷,其中属性名不同的有skuPrice【数据库表中为price】,skuImg【skuDefaultImg】,这两个单独拷贝即可;非skuInfo的数据包含hasStock、hotScore、brandName、brandImg、catelogName、Attrs,是否有库存需要给库存模块mall-ware发送请求查询是否有库存,热度评分默认设置为0【但是实际上新品上市热度评分应该要给比较高的权重,实际上热度评分应该是后台一个比较复杂的操作】,单独查询品牌和商品分类的名字并进行拷贝【注意这里还是循环查库,据说后面会优化】,查出当前sku所有的可以被检索的spu规格属性【因为一个sku的所有商品的spu属性都是一样的,所以可以在循环外实现查出来后在循环中进行属性对拷】,先通过spuId从表
pms_arrt_value查出对应的所有spu属性并拿到所有的属性id,拿着所有的属性id从表pms_attr中筛选出字段为search_type为1表示可检索的属性【这个用xml中手写sql实现】,对应SQL语句为resultType为返回值的对应类型
xxxxxxxxxx<select id="selectSearchAttrIds" resultType="java.lang.Long">SELECT attr_id FROM `pms_attr` WHERE attr_id IN<foreach collection="attrIds" item="id" separator="," open="(" close=")">#{id}</foreach>AND search_type=1</select>将查出的满足搜索条件的属性id转换成一个Set集合
new HashSet<>(List集合)可以直接将List集合转换成set集合,对pms_arrt_value查出的数据进行过滤,检查对应的元素的属性id是否在set集合中,在则过滤出来作为商品的规格属性封装到ES文档数据中,属性表的字段名和ES文档类中的Attr的属性名都是相同的,可以直接属性对拷远程查询库存系统是否还含有库存的业务实现,,远程调用也是传递skuId来调库存模块获取每种商品是否含义库存,如果循环调用,性能非常慢,需要一次调用,获取所有skuId的库存状态;在ware模块中写一个通过skuId集合查询表
wms_ware_sku表对应sku是否含有库存的接口,用实体类传递响应内容,用map多客户端协调不容易知道响应内容,用Vo不需要浏览代码就知道响应内容;用wms_ware_sku表中商品总库存数量减去锁定库存的数量是否大于0来判断商品是否有货【锁定的库存是用户已经下单但是还没有支付完】,SUM()计算两个字段的加减运算,返回数据可以使用泛型来标记响应数据的类型,这样数据可以直接自动转换到存入类型,而不需要自己拿到数据再进行强转,当然,当前模块还是需要一份对应的Vo或者To类,renren项目的响应R是没有涉及泛型的,远程调用查询网络可能存在波动,用try,catch来应对万一发生的网络波动,失败就打印日志,不管失败还是成功都要继续执行上架的功能【没有库存了还是上架并设置仍然有库存】将数据使用
mall-search模块发送给ES服务器进行保存,代码接口/search/save/up/product,批量操作进行保存,全部保存成功即成功,没有全部成功返回商品上架异常错误码,但是已经上传的商品仍然上架此时还存在问题,第一商品上架重复调用即上架服务接口幂等性的问题【search模块中商品上架失败要考虑是否需要重试,多次调用是否以及如何保证幂等性问题】
主要代码
xxxxxxxxxx/*** @param spuId* @描述 使用spuId实现商品上架功能* 1. 查询出对应ES的product索引文档映射对应实体类com.earl.common.to.es.Product的全部数据* @author Earl* @version 1.0.0* @创建日期 2024/05/31* @since 1.0.0*/public void upProduct(Long spuId) {//查询spuId下的所有skuInfo信息List<SkuInfoEntity> skuInfoEntities = skuInfoService.list(new QueryWrapper<SkuInfoEntity>().eq("spu_id", spuId));//获取spuId下的所有skuIdList<Long> skuIds = skuInfoEntities.stream().map(skuInfoEntity -> skuInfoEntity.getSkuId()).collect(Collectors.toList());//1. 远程调用mall-stock服务查询skuId列表对应的商品是否还有库存//注意TypeReference的构造器修饰符是protected,只能通过内部类的方式来创建对象Map<Long, Boolean> stockStatus = null;try{List<SkuStockExistTo> skuStockExistTos = stockFeignClient.isStockExist(skuIds).getData(new TypeReference<List<SkuStockExistTo>>() {});//将该集合skuStockExistTos转成Map准备属性对拷stockStatus = skuStockExistTos.stream().collect(Collectors.toMap(SkuStockExistTo::getSkuId, SkuStockExistTo::getIsExist));}catch (Exception e){log.error("远程调用库存服务超时,原因:{}",e);}//3. 根据品牌Id和catelogId查询出对应的品牌名、商品分类名以及品牌图片//获取品牌名和品牌图片List<Long> brandIds = skuInfoEntities.stream().map(skuInfoEntity -> skuInfoEntity.getBrandId()).distinct().collect(Collectors.toList());Map<Long, BrandEntity> brands = brandService.list(new QueryWrapper<BrandEntity>().in("brand_id", brandIds)).stream().collect(Collectors.toMap(BrandEntity::getBrandId, brandEntity -> brandEntity));//获取商品分类名List<Long> catelogIds = skuInfoEntities.stream().map(skuInfoEntity -> skuInfoEntity.getCatelogId()).distinct().collect(Collectors.toList());Map<Long, String> cateLogNames = categoryService.list(new QueryWrapper<CategoryEntity>().in("cat_id", catelogIds)).stream().collect(Collectors.toMap(CategoryEntity::getCatId, CategoryEntity::getName));//4. 获取所有可被搜索的spu规格属性//查询spuId下所有的属性idList<ProductAttrValueEntity> attrValueEntities = productAttrValueService.list(new QueryWrapper<ProductAttrValueEntity>().eq("spu_id", spuId));List<Long> attrIds = attrValueEntities.stream().map(attrValueEntity -> attrValueEntity.getAttrId()).collect(Collectors.toList());//获取可检索的属性id列表Set<Long> searchableAttrIds = attrService.list(new QueryWrapper<AttrEntity>().eq("search_type", 1).in("attr_id", attrIds)).stream().map(attrEntity -> attrEntity.getAttrId()).collect(Collectors.toSet());//组装为Attr属性的集合List<Product.Attr> attrs = attrValueEntities.stream().filter(attrValueEntity -> searchableAttrIds.contains(attrValueEntity.getAttrId())).map(attrValueEntity -> {Product.Attr attr = new Product.Attr();BeanUtils.copyProperties(attrValueEntity, attr);return attr;}).collect(Collectors.toList());//5. 准备已经拷贝skuId、spuId、skuTitle、brandId、catelogId的传输至ES的product文档记录列表和skuInfo列表对拷,并拷贝处理此前处理的所有数据Map<Long, Boolean> finalStockStatus = stockStatus;List<Product> products = skuInfoEntities.stream().map(skuInfoEntity -> {Product product = new Product();BeanUtils.copyProperties(skuInfoEntity, product);//将其中的sku_default_img和price字段拷贝至product文档记录列表product.setSkuImg(skuInfoEntity.getSkuDefaultImg());product.setSkuPrice(skuInfoEntity.getPrice());//2. 设置商品的热度评分,默认设置为0,实际上是热度评分是一个很复杂的功能product.setHotScore(0L);//将库存状态拷贝至文档数据// 这里为什么报错:Lambda表达式可能在另一个线程中执行,如果这个局部变量在外部或者Lambda内部或者同时发生修改,那么可能出现线程安全问题。// 所以需要设置局部变量为final或者为effectively final的,来防止发生修改操作product.setHasStock(finalStockStatus == null? true : finalStockStatus.get(product.getSkuId()));//将品牌和分类名进行拷贝BrandEntity brand = brands.get(product.getBrandId());product.setBrandName(brand.getName());product.setBrandImg(brand.getLogo());product.setCatelogName(cateLogNames.get(product.getCatelogId()));//将可检索规格属性列表拷贝到文档product.setAttrs(attrs);return product;}).collect(Collectors.toList());//6. 将文档数据products远程调用mall-search服务上传至ES服务器R response = searchFeignClient.upProduct(products);//上架成功修改数据库表pms_spu_info中的spu的字段publish_status为1,表示商品上架成功if(response.getCode()==0){//远程调用成功且商品全部成功上架,将上架状态改为1SpuInfoEntity spuInfoEntity = new SpuInfoEntity();spuInfoEntity.setId(spuId);spuInfoEntity.setPublishStatus(ProductConstant.UpStatusEnum.SPU_UP.getCode());baseMapper.updateById(spuInfoEntity);}else{//远程调用失败,要考虑//TODO 重复调用即商品上架接口的幂等性问题以及商品上架失败重试机制的问题}}远程调用商品上架服务,调用失败会有重试机制,服务调用用的是Feign的重试机制,
SynchronousMethodHandler中调用Retryer的continueOrPropagate重试代码如下当第一次尝试
this.executeAndDecode(template)发生了异常,异常被捕获并调用retryer.continueOrPropagate(e)来进行重试retryer.continueOrPropagate(e)如果重试的最大次数超过maxAttempts【默认值是5】,则抛异常e被invoke方法捕获如果没超次数,
retryer.continueOrPropagate(e)执行后,由于while(true)死循环,该方法还会继续执行,直到抛异常或者执行成功才会从该循环中跳出
【
SynchronousMethodHandler的invoke代码】xxxxxxxxxxpublic Object invoke(Object[] argv) throws Throwable {RequestTemplate template = this.buildTemplateFromArgs.create(argv);Retryer retryer = this.retryer.clone();while(true) {try {return this.executeAndDecode(template);} catch (RetryableException var8) {RetryableException e = var8;try {retryer.continueOrPropagate(e);} catch (RetryableException var7) {Throwable cause = var7.getCause();if (this.propagationPolicy == ExceptionPropagationPolicy.UNWRAP && cause != null) {throw cause;}throw var7;}if (this.logLevel != Level.NONE) {this.logger.logRetry(this.metadata.configKey(), this.logLevel);}}}}【Retryer部分代码】
xxxxxxxxxxpublic void continueOrPropagate(RetryableException e) {if (this.attempt++ >= this.maxAttempts) {throw e;} else {long interval;if (e.retryAfter() != null) {interval = e.retryAfter().getTime() - this.currentTimeMillis();if (interval > this.maxPeriod) {interval = this.maxPeriod;}if (interval < 0L) {return;}} else {interval = this.nextMaxInterval();}try {Thread.sleep(interval);} catch (InterruptedException var5) {Thread.currentThread().interrupt();throw e;}this.sleptForMillis += interval;}}【
SynchronousMethodHandler的invoke代码】xxxxxxxxxxpublic Object invoke(Object[] argv) throws Throwable {RequestTemplate template = this.buildTemplateFromArgs.create(argv);Retryer retryer = this.retryer.clone();while(true) {try {return this.executeAndDecode(template);} catch (RetryableException var8) {RetryableException e = var8;try {retryer.continueOrPropagate(e);} catch (RetryableException var7) {Throwable cause = var7.getCause();if (this.propagationPolicy == ExceptionPropagationPolicy.UNWRAP && cause != null) {throw cause;}throw var7;}if (this.logLevel != Level.NONE) {this.logger.logRetry(this.metadata.configKey(), this.logLevel);}}}}【商品上架代码】
xxxxxxxxxx("ESDocService")public class ESDocServiceImpl implements ESDocService {/*** 操作索引文档的客户端*/private RestHighLevelClient esRESTClient;/*** @param products* @return boolean* @描述 根据索引映射类集合即文档数据将商品文档数据批量上传至ES服务器* 没有上架失败的商品返回true,有上架失败的商品返回false* @author Earl* @version 1.0.0* @创建日期 2024/06/01* @since 1.0.0*/public boolean upProduct(List<Product> products) {//批量操作BulkRequest bulkRequest = new BulkRequest();BulkResponse bulkResponse=null;//向批量请求添加上架商品文档数据for (Product product : products) {//创建索引文档请求IndexRequest indexRequest = new IndexRequest(EsConstant.PRODUCT_INDEX);//指定商品文档的id,因为商品skuId具有唯一性,以skuId作为文档的idindexRequest.id(product.getSkuId().toString());//将商品映射对象转换成对应的json格式字符串String productJSONStr = JSON.toJSONString(product);//索引请求添加JSON文档数据indexRequest.source(productJSONStr, XContentType.JSON);bulkRequest.add(indexRequest);}try{bulkResponse = esRESTClient.bulk(bulkRequest, MallElasticSearchConfig.COMMON_OPTIONS);}catch (Exception e){log.error("商品文档上架ES服务器远程操作发生错误:{}",e);}//处理批量操作错误信息,item。getId是拿到操作失败的文档数据的id,getIndex是拿到对应的索引信息,// 一般只有ES出现问题或者文档数据和映射不符才会出现文档数据操作失败的情况,这里上架成功也会在errorDocInfo中返回上传成功或者更新成功的文档id,特别诡异,二刷注意,这种情况会导致即使操作成功也会记录错误日志List<String> errorDocInfo = Arrays.stream(bulkResponse.getItems()).map(item -> item.getId()).collect(Collectors.toList());//这里有问题,上架成功或者更新成功这个errorDocInfo都会保存上架成功的文档数据id,按照这里的理解在日志中显示失败,但是实际上更新文档数据或者新增文档数据都是成功的,这里二刷要特别注意啊,这个返回的errorDocInfo到底是什么意思要搞清楚,否则上架或者更新成功都会记录错误日志log.error("上架失败商品数据:{}",errorDocInfo);return !bulkResponse.hasFailures();}}
nested数据类型
在ES中将nested称为嵌入式的,官方文档介绍,数组类型的请求体中的json对象会被扁平化处理,扁平化处理的概念看下列介绍
数组扁平化处理
请求体提交数据
xxxxxxxxxxPUT my_index/_doc/1{"group": "fans","user": [{"first": "John","last": "Smith"},{"first": "Alice","last": "White"}]}将在ES中被处理转换后的文档
即将数组每个对象的属性名和数组名结合起来,将对象的每一个属性作为一个数组
xxxxxxxxxx{"group": "fans","user.first": ["alice","john"],"user.last": ["smith","white"]}这种方式存在的问题
因为数组被扁平化处理了,在用户层面理解的检索条件如
xxxxxxxxxxGET my_index/_search{"query": {"bool": {"must": [{"match": {"user.first": "Alice"}},{"match": {"user.last": "Smith"}}]}}}检索结果
xxxxxxxxxx{"took" : 12,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 1,"relation" : "eq"},"max_score" : 0.5753642,"hits" : [{"_index" : "my_index","_type" : "_doc","_id" : "1","_score" : 0.5753642,"_source" : {"group" : "fans","user" : [{"first" : "John","last" : "Smith"},{"first" : "Alice","last" : "White"}]}}]}}数组的默认映射是将
user.first作为一个带keyword的text,并不是nestedxxxxxxxxxx{"my_index" : {"mappings" : {"properties" : {"group" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}},"user" : {"properties" : {"first" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}},"last" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}}}}}}}}用户需要找到同时满足
"user.first": "Alice"且"user.last": "Smith"的数据,从存储的数据上来看并没有满足这样要求的数据,但是实际运行还是会得到全部的文档数据,因为数组被扁平化处理了,ES只会去检索数组user.first中是否含有Alice,同时去检查user.last数组中去检查是否含有Smith,发现该文档两个数组都满足检索条件,就会返回该文档数据,实际上这两个条件并不同时满足在同一个对象的要求,即数组被处理的无法处理同一个对象的属性之间的联系,这样会发生检索错误的问题,需要使用nested数据类型【注意这种问题一般发生在数组元素是对象的情况下,数组元素是单个值不会发生这样的情况】
使用nested类型来定义索引的映射关系
此时再向该索引下索引对应的文档数据并使用相同的条件检索文档,不会再发生检索出错误数据的问题
xxxxxxxxxxPUT my_index{"mappings": {"properties": {"user": {"type": "nested"}}}}检索结果
xxxxxxxxxx{"took" : 1,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 0,"relation" : "eq"},"max_score" : null,"hits" : [ ]}}此时的映射关系为
只是给user即数组元素对象增加了一个nested类型,增加以后的效果是不会发生扁平化处理产生的不能区分同一个对象属性联系的问题,但是没有讲明具体的区分原理,通过WEB API
GET my_index/_mapping可以查看哪些属性被设置为哪种类型
xxxxxxxxxxGET my_index/_mapping{"my_index" : {"mappings" : {"properties" : {"group" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}},"user" : {"type" : "nested","properties" : {"first" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}},"last" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}}}}}}}}因此数组元素为多属性对象时一定要在索引映射中声明该对象是一个nested数据类型
nested数据类型的查询
如果一个属性被声明为nested类型,通过该属性查询文档必须使用nested对应的查询语法进行查询,否则查询不到文档数据
1️⃣[nested类型数据使用原始查询方式查不到数据示例]
xxxxxxxxxxGET product/_search{"query": {"bool": {"filter": {"term": {"attrs.attrId": "11"}}}}}[响应内容]
通过普通方式查询
nested类型的数据没有查到一条记录
xxxxxxxxxx{"took" : 1,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 0,"relation" : "eq"},"max_score" : null,"hits" : [ ]}}2️⃣[nested类型数据正确查询方式]
nested语句中的path属性指定文档中的匹配属性名,就是设置为nested类型的属性attrs,因为attrs中是一个未知元素个数的数组,所以attrs属性被设置为nested类型,数组中的每一个元素都可能是一个
json对象,每个json对象都有确定个数的多个属性名和属性值,这些要匹配的属性名和属性值在query语句中指定,注意属性名需要写完整的属性名即attrs.attrId,不要忽略前缀写attrId注意
term和terms都是匹配同一个字段,term是匹配属性值为单一值的记录,terms是匹配属性值为多个可能值的所有记录的并集
xxxxxxxxxxGET product/_search{"query": {"bool": {"filter": {"nested": {"path": "attrs","query": {"bool": {"must": [{"term": {"attrs.attrId": "11"}},{"terms": {"attrs.attrValue": ["海思芯片","以官网信息为准"]}}]}}}}}}}[响应内容]
xxxxxxxxxx{"took" : 1,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 8,"relation" : "eq"},"max_score" : 0.0,"hits" : [{"_index" : "product","_type" : "_doc","_id" : "5","_score" : 0.0,"_source" : {"attrs" : [{"attrId" : 3,"attrName" : "入网型号","attrValue" : "LIO-AL00;是;否"},{"attrId" : 11,"attrName" : "CPU品牌","attrValue" : "海思芯片"}],"brandId" : 4,"brandImg" : "https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/03/ca1e4c86-a0f0-4a46-8fa9-db8f92bbc0a1_huawei.png","brandName" : "华为","catelogId" : 225,"catelogName" : "手机","hasStock" : false,"hotScore" : 0,"saleCount" : 0,"skuId" : 5,"skuImg" : "https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/26//e87743d5-526d-467b-855d-6213f64b0965_0d40c24b264aa511.jpg","skuPrice" : 5699.0,"skuTitle" : "华为 HUAWEI Mate60 Pro 星河银 128G 旗舰新品手机","spuId" : 5}},{"_index" : "product","_type" : "_doc","_id" : "6","_score" : 0.0,"_source" : {"attrs" : [{"attrId" : 3,"attrName" : "入网型号","attrValue" : "LIO-AL00;是;否"},{"attrId" : 11,"attrName" : "CPU品牌","attrValue" : "海思芯片"}],"brandId" : 4,"brandImg" : "https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/03/ca1e4c86-a0f0-4a46-8fa9-db8f92bbc0a1_huawei.png","brandName" : "华为","catelogId" : 225,"catelogName" : "手机","hasStock" : true,"hotScore" : 0,"saleCount" : 0,"skuId" : 6,"skuImg" : "https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/26//e87743d5-526d-467b-855d-6213f64b0965_0d40c24b264aa511.jpg","skuPrice" : 6299.0,"skuTitle" : "华为 HUAWEI Mate60 Pro 星河银 256G 旗舰新品手机","spuId" : 5}},,{"_index" : "product","_type" : "_doc","_id" : "12","_score" : 0.0,"_source" : {"attrs" : [{"attrId" : 3,"attrName" : "入网型号","attrValue" : "LIO-AL00;是;否"},{"attrId" : 11,"attrName" : "CPU品牌","attrValue" : "海思芯片"}],"brandId" : 4,"brandImg" : "https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/03/ca1e4c86-a0f0-4a46-8fa9-db8f92bbc0a1_huawei.png","brandName" : "华为","catelogId" : 225,"catelogName" : "手机","hasStock" : false,"hotScore" : 0,"saleCount" : 0,"skuId" : 12,"skuImg" : "https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/26//e87743d5-526d-467b-855d-6213f64b0965_0d40c24b264aa511.jpg","skuPrice" : 6299.0,"skuTitle" : "华为 HUAWEI Mate60 Pro 罗兰紫 256G 旗舰新品手机","spuId" : 5}}]}}nested数据聚合
聚合分析所有检索到的记录的nested类型的数据
attrsnested类型的数据进行聚合除了要在一般的聚合分析外面多套一层聚合分析并且用nested对象的path属性指明要被聚合分析的nested类型的字段,如下例所示
[语法格式]
第一个comments是聚合的自定义名字,age_group也是聚合的自定义名字,blogposts也是自定义聚合的名字
xxxxxxxxxxGET /my_index/blogpost/_search{"size" : 0,"aggs": {"comments": {"nested": {"path": "comments"},"aggs": {"age_group": {"histogram": {"field": "comments.age","interval": 10},"aggs": {"blogposts": {"reverse_nested": {},"aggs": {"tags": {"terms": {"field": "tags"}}}}}}}}}}1️⃣[对nested类型数据聚合查询]
xxxxxxxxxxGET mall_product/_search{"query": {"match_all": {}},"aggs": {"brand_agg": {},"catelog_agg": {},"attrs_agg": {"nested": {"path": "attrs"},"aggs": {"attrs_id_agg": {"terms": {"field": "attrs.attrId","size": 10},"aggs": {"attr_name_agg": {"terms": {"field": "attrs.attrName","size": 10}},"attr_value_agg": {"terms": {"field": "attrs.attrValue","size": 10}}}}}}}}[响应结果]
xxxxxxxxxx"aggregations" : {"attrs_agg" : {"doc_count" : 24,"attrs_id_agg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : 3,"doc_count" : 12,"attr_name_agg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "入网型号","doc_count" : 12}]},"attr_value_agg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "LIO-AL00;是;否","doc_count" : 8},{"key" : "LIO-AL00","doc_count" : 4}]}},{"key" : 11,"doc_count" : 12,"attr_name_agg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "CPU品牌","doc_count" : 12}]},"attr_value_agg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "海思芯片","doc_count" : 8},{"key" : "Apple芯片","doc_count" : 4}]}}]}},"catelog_agg" : {},"brand_agg" : {}}
数据渲染
使用模板引擎thymeleaf来渲染页面,优点是编写的页面前端可以直接使用,缺点是在模板引擎中性能偏低,但是生产环境开启缓存功能性能也是非常高的
在商品模块引入dev-tools来实现热部署
Thymeleaf渲染商城首页
在商品模块引入Thymeleaf依赖做首页渲染
pom.xml
xxxxxxxxxx<!--模板引擎Thymeleaf--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-thymeleaf</artifactId></dependency>将首页用到的静态资源目录index拷贝到类目录下的static目录下,将首页模板页面放在类路径目录
template目录下
Thymeleaf相关配置
在
application.yml使用下列配置关闭Thymeleaf的缓存关闭Thymeleaf缓存,这样开发期间就能看见实时的更改效果
Thymeleaf的前缀默认配置
spring.thymeleaf.prefix="classpath:/templates/"后缀默认配置是
spring.thymeleaf.suffix=".html"
xxxxxxxxxxSpringthymeleafcachefalse #关闭Thymeleaf缓存,这样开发期间就能看见实时的更改效果在项目包
com.earl.product目录下创建web包用来专门放商城前台的控制器方法静态资源目录
静态资源放在默认的
static目录下可以通过路径如http://127.0.0.1:9000/index/css/GL.css直接访问【访问不到可能是target目录没有载入】,静态页面模板index.html放在template目录下此时可以直接通过http://127.0.0.1:9000直接访问,注意默认不能通过http://127.0.0.1:9000/index.html访问【默认情况下没有做对应URI为index.html的映射】注意项目里的前端静态资源统一加了
static前缀,即http://127.0.0.1:10000/static/index/css/GL.css,此时对应的静态资源需要放在目录static/static下,使用下列配置让SpringBoot忽略static前缀,这样将静态资源放在static目录下即可访问xxxxxxxxxxSpringthymeleafcachefalse #关闭Thymeleaf缓存,这样开发期间就能看见实时的更改效果mvcstatic-path-pattern/static/** #这里前端所有的静态资源路径加了static前缀,使用该配置让SpringBoot处理过程中去掉该前缀,这样仍然将index目录放在static目录下即可,而不需要放在static/static目录下
业务逻辑
设置URI路径数组跳转的首页视图
xxxxxxxxxxpublic class IndexController {/*** @return {@link String }* @描述 匹配uri为"/"和"/index.html"都跳转首页视图* 1. Thymeleaf的前缀默认配置spring.thymeleaf.prefix="classpath:/templates/"* 2. 后缀默认配置是spring.thymeleaf.suffix=".html"* 3. 返回视图地址,视图解析器会自动对视图地址进行拼串 前缀+返回值+后缀 即视图地址* @author Earl* @version 1.0.0* @创建日期 2024/06/03* @since 1.0.0*/({"/","/index.html"})public String urisToIndexPage(){return "index";}}跳转页面后需要查询到所有商品的一级分类。模板中数据是写死的,使用ModelAndView来缓存数据并从视图中取出相应的数据
从表pms_category中查询出所有一级分类商品,特征是字段
cat_level字段属性值为1使用Thymeleaf从ModelAndView中获取数据渲染到视图中需要使用Thymeleaf的语法,Thymeleaf官方文档-英文,点击Using Thymeleaf下的链接可以下载对应版本的说明文档,包括PDF、EPUB、MOBI等等版本
使用Thymeleaf的优点是渲染以html为后缀的文件,浏览器可以直接打开,和前端沟通起来成本小,使用JSP浏览器打不开且前端不好做优化
【获取一级分类数据并存入ModelAndView】
model.addAttribute("firstLevelCategories",firstLevelCategories);需要指明变量的名称,否则只有打断点才知道对应变量的名称
xxxxxxxxxxpublic class IndexController {private CategoryService categoryService;/*** @return {@link String }* @描述 匹配uri为"/"和"/index.html"都跳转首页视图* 1. Thymeleaf的前缀默认配置spring.thymeleaf.prefix="classpath:/templates/"* 2. 后缀默认配置是spring.thymeleaf.suffix=".html"* 3. 返回视图地址,视图解析器会自动对视图地址进行拼串 前缀+返回值+后缀 即视图地址* 4. 在跳转首页的过程中将数据查询出来放在ModelAndView中等待渲染* @author Earl* @version 1.0.0* @创建日期 2024/06/03* @since 1.0.0*/({"/","/index.html"})public String urisToIndexPage(Model model){List<CategoryEntity> firstLevelCategories=categoryService.getAllFirstLevelCategory();model.addAttribute("firstLevelCategories",firstLevelCategories);return "index";}}【使用Thymeleaf语法需要在渲染视图引入Thymeleaf的名称空间
xmlns:th="http://www.thymeleaf.org"】xxxxxxxxxx<html lang="en" xmlns:th="http://www.thymeleaf.org">...</html>【获取变量并渲染成标签的文本内容】
th:text="${}"表示获取变量并将其渲染成文本填充到当前标签
xxxxxxxxxx<div th:text="${}"></div>【表格遍历语法】
<tr th:each="prod : ${prods}">的作用是循环遍历指定元素prods,并根据元素集合中元素的个数决定循环创建多少个当前tr标签及其子标签,${prods}是要遍历的元素,prod是当前元素,使用th:text来展示当前元素的各个属性变量【如果标签已经有文本,会使用当前变量值直接进行替换】,th:each表示有多少个子元素就会生成多少个tr标签和其子标签,这个标签也可以是其他html标签
xxxxxxxxxx<table><tr><th>NAME</th><th>PRICE</th><th>IN STOCK</th></tr><tr th:each="prod : ${prods}"><td th:text="${prod.name}">Onions</td><td th:text="${prod.price}">2.41</td><td th:text="${prod.inStock}? #{true} : #{false}">yes</td></tr></table>使用Thymeleaf渲染商品一级分类列表
Thymeleaf自定义属性
th:attr="ctg-data=${category.catId},渲染后的展示效果是ctg-data=商品分类id,该属性是用来查询该分类id下的二三级商品分类的
xxxxxxxxxx<ul><li th:each="category : ${firstLevelCategories}"><a href="#" class="header_main_left_a" th:attr="ctg-data=${category.catId}"><b th:text="${category.name}"></b></a></li></ul>
渲染商品分类二三级菜单
业务逻辑
index页面加载会触发事件,模版调用js文件中的
catalogLoader.js,发送ajax请求static/index/json/catalog.json拿到所有的二三级商品分类数据catalog.json,实际上二三级分类数据应该从数据库查,而不是拿静态数据,需要将数据库拿到的数据组织成对应catalog.json的数据格式【直接用】,数据格式分析如下【
catalog.json数据组织形式】json中的第一层属性名是一级商品分类的id【以一级分类id作为key】,后面的数组是所属二级商品分类

单个二级商品分类数据是一个对象,包含四个属性,所属一级分类id,旗下三级分类列表【三级分类对象包含所属二级分类id和当前三级分类id和三级分类名称】,当前二级商品分类id,当前商品分类名称
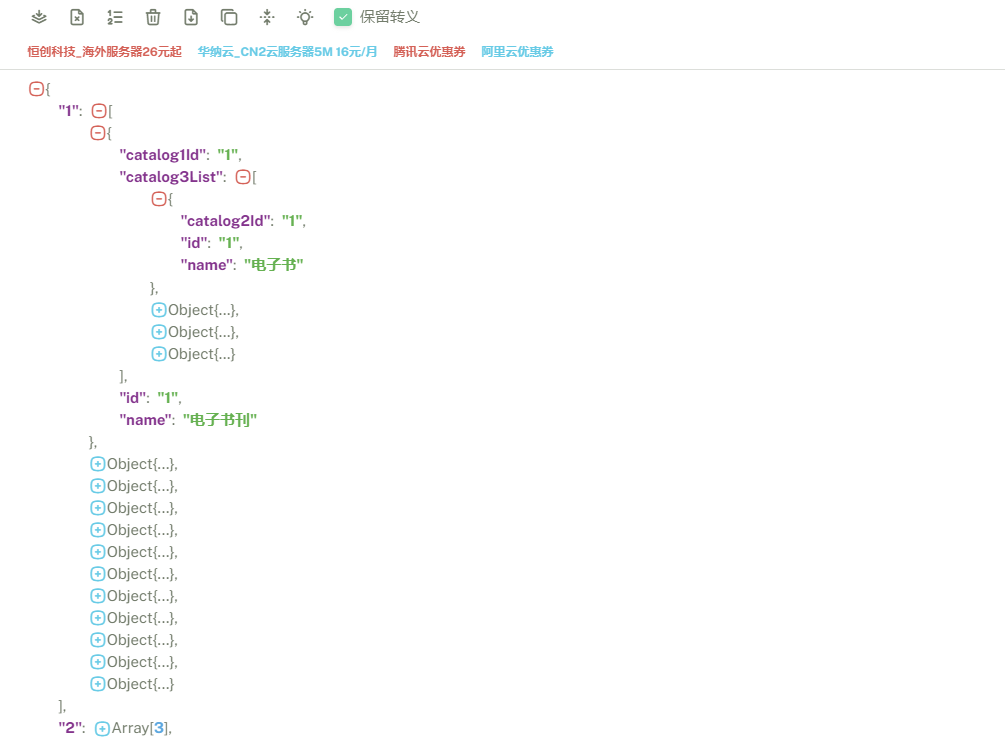
根据数据组织关系创建对应的实体类,最外层根据数据形式考虑组织成一个Map集合
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 一级商品分类对应的二级分类和二级分类的子分类* @创建日期 2024/06/04* @since 1.0.0*/public class IndexSecondLevelCategoryVo {private String catalog1Id;private List<IndexThirdLevelCategoryVo> catalog3List;private String id;private String name;public static class IndexThirdLevelCategoryVo {private String catalog2Id;private String id;private String name;}}编写控制器方法处理该Ajax请求,由于直接返回数据,控制器方法上使用注解
@ResponseBody,封装逻辑参考前面商品分类的树形结构封装,不使用视频中的循环查库xxxxxxxxxx/*** @return {@link Map }<{@link String },{@link List }<{@link IndexSecondLevelCategoryVo }>>* @描述 查询所有的商品分类数据,封装成以一级商品分类的id作为key,所属二级分类和其子分类的集合作为value* @author Earl* @version 1.0.0* @创建日期 2024/06/04* @since 1.0.0*/("/static/index/json/catalog.json")public Map<String,List<IndexSecondLevelCategoryVo>> getIndexCategories(){Map<String,List<IndexSecondLevelCategoryVo>> categories = categoryService.getIndexCategories();return categories;}【以下实现比此前的递归实现三级分类效率更高】
xxxxxxxxxx/*** @return {@link Map }<{@link String }, {@link List }<{@link IndexSecondLevelCategoryVo }>>* @描述 查询所有的商品分类数据,封装成以一级商品分类的id作为key,所属二级分类和其子分类的集合作为value* 性能:首次查询20ms,奇怪这个性能居然和此前三级分类一次查询数据库的首次响应时间差10倍,经过测试,首次拿数据,数据量差不多,* 不同的查询条件性能差20倍* 有了数据库缓存以后查询处理性能稳定10ms左右[单处理数据小于1ms,那个递归处理数据时间约10ms],吊打之前stream流递归封装三级分类结构* 处理数据的部分性能小于1ms,主要时间在数据库查询* 首次数据库查询23ms,拿缓存是9ms* @author Earl* @version 1.0.0* @创建日期 2024/06/04* @since 1.0.0*/public Map<String, List<IndexSecondLevelCategoryVo>> getIndexCategories() {//1. 查询出所有二三级的商品分类数据List<Long> catLevels = Arrays.asList(2L, 3L);List<CategoryEntity> categories = baseMapper.selectList(new QueryWrapper<CategoryEntity>().in("cat_level",catLevels));//创建Map准备封装返回数据Map<String, List<IndexSecondLevelCategoryVo>> indexCategories=new HashMap<>();//筛出所有二级商品分类并返回以id作为key,二级分类作为value的Map,方便三级分类List集合存入二级分类的子分类列表属性Map<Long,IndexSecondLevelCategoryVo> secondLevelCategories =new HashMap<>();Map<Long,List<IndexSecondLevelCategoryVo.IndexThirdLevelCategoryVo>> thirdLevelCategories =new HashMap<>();for (CategoryEntity category : categories) {if(category.getCatLevel() == 2 ){IndexSecondLevelCategoryVo secondCategoryVo = new IndexSecondLevelCategoryVo();String categoryPid = category.getParentCid().toString();secondCategoryVo.setCatalog1Id(categoryPid);String categoryId = category.getCatId().toString();secondCategoryVo.setId(categoryId);secondCategoryVo.setName(category.getName());secondLevelCategories.put(category.getCatId(),secondCategoryVo);if(indexCategories.get(categoryPid)==null){indexCategories.put(categoryPid,new ArrayList<>());}indexCategories.get(categoryPid).add(secondCategoryVo);}else{IndexSecondLevelCategoryVo.IndexThirdLevelCategoryVo thirdCategoryVo = new IndexSecondLevelCategoryVo.IndexThirdLevelCategoryVo();Long parentCid = category.getParentCid();thirdCategoryVo.setCatalog2Id(parentCid.toString());thirdCategoryVo.setId(category.getCatId().toString());thirdCategoryVo.setName(category.getName());if(thirdLevelCategories.get(parentCid)==null){thirdLevelCategories.put(parentCid,new ArrayList<>());}thirdLevelCategories.get(parentCid).add(thirdCategoryVo);}}//遍历thirdLevelCategories,将三级分类列表添加到对应的二级分类的对应属性上for(Map.Entry<Long, List<IndexSecondLevelCategoryVo.IndexThirdLevelCategoryVo>> entry : thirdLevelCategories.entrySet()){secondLevelCategories.get(entry.getKey()).setCatalog3List(entry.getValue());}return indexCategories;}
域名访问环境
正向代理和反向代理的概念区分:帮助我们的电脑上网就是正向代理【如科学上网,隐藏客户端信息】,帮助服务器被访问就是反向代理【屏蔽内网服务器信息,帮助内网服务器做负载均衡】
使用SwitchHosts软件来创建windows本机对域名的映射规则
使用
SwitchHosts创建本机对域名的映射规则创建本地方案earlmall【注意添加需要点击左下角的绿色加号按钮】,编写以下内容,并勾选右下角绿色对钩来进行应用
xxxxxxxxxx# earlmall192.168.56.10 earlmall.com使用域名
earlmall.com:9200来访问ES来测试hosts配置是否生效【出现以下内容则成功访问】xxxxxxxxxx{"name": "3133dc7bb77a","cluster_name": "elasticsearch","cluster_uuid": "zxPeJYB9SraGL0p_R4dT0g","version": {"number": "7.4.2","build_flavor": "default","build_type": "docker","build_hash": "2f90bbf7b93631e52bafb59b3b049cb44ec25e96","build_date": "2019-10-28T20:40:44.881551Z","build_snapshot": false,"lucene_version": "8.2.0","minimum_wire_compatibility_version": "6.8.0","minimum_index_compatibility_version": "6.0.0-beta1"},"tagline": "You Know, for Search"}
nginx配置文件简介
nginx配置文件大纲

业务逻辑
访问域名直接跳转到商城首页【不走网关是路径短,响应快】,这里做的不好,首页数据可以前移至nginx做资源静态化,这个项目直接访问后端服务器,访问量一大后端服务器根本扛不住
域名访问到nginx,nginx又将请求代理到首页所在的本机,本机地址在windows上使用命令
ipconfig查看,有几个可选项,第一是localhost、127.0.0.1;第二是无线局域网适配器WLAN的IPv4地址192.168.0.103;第三是以太网适配器Virtual Box或者以太网3的ipv4192.168.56.1,这是本机和nginx所在虚拟机通信的地址【使用该地址作为虚拟机的首页反向代理地址】【转发商城首页的nginx配置】
这个
server_name对应的请求头中的HOST头信息
xxxxxxxxxxserver {listen 80;server_name earlmall.com;location / {proxy_pass http://192.168.56.1:9000;}error_page 500 502 503 504 /50x.html;location = /50x.html {root /usr/share/nginx/html;}}配置对网关集群的代理转发和负载均衡
这样后台服务接口也可以统一用域名走nginx进行代理转发到网关,不直接走网关
【总配置文件配置网关集群】
注意http块最好配置在总配置文件中
xxxxxxxxxx[root@localhost conf]# cat nginx.confuser nginx;worker_processes 1;error_log /var/log/nginx/error.log warn;pid /var/run/nginx.pid;events {worker_connections 1024;}http {include /etc/nginx/mime.types;default_type application/octet-stream;log_format main '$remote_addr - $remote_user [$time_local] "$request" ''$status $body_bytes_sent "$http_referer" ''"$http_user_agent" "$http_x_forwarded_for"';access_log /var/log/nginx/access.log main;upstream gateway{server 192.168.56.1:88;}sendfile on;keepalive_timeout 65;include /etc/nginx/conf.d/*.conf;}【子配置文件earlmall.conf配置对网关的路由转发和负载均衡】
这个设计挺der的,让网关访问后端全部走网关集群,对首页的访问也走网关,将此前访问商城首页的路由转发改为转发到网关集群,目前没有配置网关集群
xxxxxxxxxx[root@localhost conf.d]# cat earlmall.confserver {listen 80;server_name earlmall.com;location / {proxy_set_header Host $host;proxy_pass http://gateway;}error_page 500 502 503 504 /50x.html;location = /50x.html {root /usr/share/nginx/html;}}配置网关对商城前台的路由转发
对请求头中Host进行断言,匹配所有earlmall.com域名及其子域名的请求,不对路径进行过滤处理【因为后端对前台处理的控制器路径映射就是实际的uri】
存在一个严重的问题,nginx代理转发会丢掉原来的请求头Host,默认情况下到网关网关无法根据Host请求头信息对请求进行针对Host的断言和路由,需要在nginx中配置续写host请求头【实际会丢掉很多请求头,需要在nginx中重新配置】
xxxxxxxxxxspringcloudgatewayroutesidmall_host_routeurilb//mall-productpredicatesHost=**.earlmall.com【nginx中设置对host的重写】
在站点的proxy_pass前面添加,表示对该代理转发携带指定host请求头
对host的断言路由规则净量放在路由规则的最后,因为路由规则会优先匹配前面的路由规则,如果使用和前台相同的域名访问其他路由,会因为匹配了Host而匹配Host路由规则,不会在后续匹配URI的路由规则【匹配上Host也会因为过滤器处理不当导致404】,但是URI的区分度比较高更精细,匹配不到对应的uri再去匹配Host【优先匹配URI再匹配Host】
xxxxxxxxxxproxy_set_header Host $host
压力测试
微服务模块正式上线前都需要经过压力测试,压力测试的目的是找出系统在当前配置下的最大负荷即系统瓶颈,直到该瓶颈,可以通过负载均衡系统避免过多的流量倾斜
压力测试能发现很多常规方法无法发现的问题,比如内存泄露【比如频繁创建对象没有复用对象,百万并发一上导致内存被撑爆】、并发同步问题【单线程跑没问题,高并发情况下出现各种线程安全问题】,单元测试只能测试功能是否正常
性能指标
一般使用TPS来衡量整个业务流程,用QPS来衡量接口查询次数,用HPS表示对服务器的单击请求
经验数据:一般TPS、QPS、HPS指标都是越大越好,一般情况下
金融行业1000TPS-50000TPS,不包含互联网化的秒杀营销策略
保险行业100TPS【保险的业务一般比较复杂】-100000TPS,不包含互联网化的秒杀营销策略
制造行业10TPS-5000TPS,因为制造业面向的用户比较少
互联网电商10000TPS-1000000TPS,像京东淘宝双十一每秒肯定要达到百万级别的TPS
互联网中型网站1000TPS-50000TPS
互联网小型网站500TPS-10000TPS
性能测试一般关注三个指标
吞吐量:每秒钟系统能处理的请求数、任务数,吞吐量越大越好
响应时间:服务处理一个请求或者任务的耗时,响应时间越短越好
错误率:一批请求中响应出错的请求所占比例,错误率越小越好
压力测试常用的工具有
Apache Benchmark【AB工具】、
Apache JMeter【适合做专业的压力测试,本项目使用该工作做压力测试】、
加特林【现在比较流行,融入CICD做线上的压力测试】
响应时间 Response Time【RT】
概念:用户从客户端发起一个请求开始,到客户端接收到从服务端返回的响应结束整个过程耗费的时间
每秒点击次数 Hits Per Second【HPS】
概念:每秒钟用户的总点击次数,单位次每秒
每秒处理交易数 Transaction Per Second【TPS】
概念:每秒处理的交易数,认为是一次用户完整请求,一次业务请求带起的所有并发请求
每秒处理查询次数 Query Per Second【QPS】
概念:每秒处理查询次数,单位次每秒,认为是单个接口每秒钟能处理的请求次数
最大响应时间 Max Response Time
概念:一系列请求中响应时间最大的请求的响应时间
最小响应时间 Mininum ResponseTime
概念:一系列请求中响应时间最短的请求的响应时间
90%响应时间 90% Response Time
概念:对响应时间进行排序,第百分之90个请求的响应时间
JMeter
JMeter设置
一秒内模拟200个用户总共请求20000次,线程组中的一个线程数是一个用户发起的请求,会占用tomcat中的一个线程资源,如果还要并发响应内容的中超链接,每个用户可能发起10的并发请求,最终的并发度会变成2000,实际上一些大型网站带起的并发请求可能高达一百六

压测首页结果
【汇总结果】
最小响应时间9毫秒、最大响应时间11s,标准偏差700【百度压测网络情况较好是40多】、吞吐量263【受网络环境影响较大,如果将服务器地址更改为127.0.0.1,吞吐量会瞬间飙升到1213,接受数据的速度达到41799k/s】

【聚合报告】
平均响应时间700ms左右,中位数是712毫秒,90%的请求在900毫秒响应完成,99%的请求在5秒内响应,没有异常说明接口非常稳定

原因分析
为了减少服务的内存占用,启动的时候设置了后台服务的内存只有100m

增大JVM内存到512M的测试数据
效果提升有限,老师的提升也不大【132-242.7】,可能是老师的CPU不太行吧
弹幕说nginx代理ip要和本机ip处于同一个局域网,不然特别慢

Jmeter设置像浏览器一样自动请求超链接和统计一次请求带起的所有并发请求的统计数据
注意如果下面这个并行下载的数量调的太大,电脑可能会蓝屏卡死

接口性能优化
应用分类
CPU密集型
特点:CPU密集型涉及到大量的计算,比如排序、过滤、整合,CPU占用率长时间百分之七十-百分之八十
优化手段:增加服务器分担机器压力并行处理业务、更换更好的CPU
IO密集型
特点:IO密集型主要体现在于通过网络传输数据、磁盘的频繁读写、数据库IO、缓存中间件的数据磁盘IO和网络数据传输,CPU占用率经常百分之三四十,但是IO占用率高、内存占用率高、磁盘疯狂地读写数据、网络的流量也非常大
优化手段:更换固态硬盘、增加内存条、使用各种缓存技术,提高网卡数据传输效率等等
JVM内存模型
JVM内存模型
java源代码文件会被编译成字节码文件,字节码文件会被类装载器装载到JVM,所有的数据都在运行时数据区,优化工作的大部分都在运行时数据区,技术很强的情况下可以优化代码的执行引擎,当Java中的所有数据都进入运行时数据区后,执行引擎在虚拟机栈中依次调用方法入栈出栈,本地方法栈调用操作系统暴露的本地接口和本地方法栈,程序计数器用于记录程序调用到什么位置了,
虚拟机栈、本地方法栈、程序计数器都是线程隔离的数据区,即每个栈都有独立程序计数器记录当前程序调用到什么位置,当前调用的是本地接口的哪个方法等,每个栈的这部分数据都是隔离的,只保留对应栈内的相应数据
方法区和堆数据是各个栈共享的,比较重要的就是堆,优化更多地也集中在堆
【JVM内存模型示意图】

堆
Java的JVM是由C语言开发的,使用C语言需要开辟空间、释放内存,使用起来很麻烦,基于C语言进行封装形成JVM,用JVM来翻译程序员写的Java代码,内存的开辟和释放都是由JVM在底层进行控制的
【JVM内存模型示意图2】
堆:所有对象实例的创建、内存分配、数组空间的分配都在堆,所有的调优都针对堆
元数据区:Java8以后新增一个元数据区,元数据区直接操作物理内存,
运行期间代码没编译即时编译的缓存都在CodeCache区域,针对该区域也是有调优的,更多的还是针对堆

堆分区
堆大体分为新生代和老年代两个区域,新生代区域又分为3个区域,伊甸园区Eden、S0和S1【两个Survival幸存者区】,这些分区和垃圾回收机制GC有关,让JVM及时回收内存空间来为新对象的创建提供空间
垃圾回收示意图
【基于Java8的内存模型示意图】
Permanent Generation在Java8被移除,称为永久代,取而代之的是元空间Metaspace,可以直接操作物理空间内存
垃圾回收存在于新生代三个区域和老年代【Old Generation for older objects】之间

垃圾回收机制示意图
说明:浅黄色区域是老年代,浅黄色区域左边是新生代区域,新创建的数据都在新生代,存活了很久的东西都在老年代
流程:新创建对象进入新生代需要分配内存,先判断伊甸园区内存是否足够,如果不够会先进行一次YGC【Young GC】操作,也叫MinorGC【小GC,速度非常快】,主要清理新生代的内存空间,GC逻辑是清除伊甸园中已经没有被使用的对象,将还在使用中的对象存入幸存者区【存入幸存者区也要判断是否能放下,不能就放入旧生代,能就存入新生代并定期判断对象存活时间是否超过阈值,阈值默认是幸存者区清理了15次,超过就放入旧生代】,再次判断伊甸园区是否还能存下新创建的对象
如果进行了YGC伊甸园区还是放不下,就认为这是一个超大新对象,尝试将该新数据放在老年代并判断老年代是否能够放下
如果老年代放不下,就会执行一次FGC【全面的GC】,FGC会将老年代和新生代中不会再被使用的对象全部剔除出去,然后再判断老年代是否能放下该数据
如果老年代还是放不下,直接抛出OOM内存溢出异常
如果能放下就在老年代给数据分配对象内存
如果能放下就在老年代给数据分配对象内存
如果能放下就在伊甸园区分配对象内存
要点:
Full GC非常慢,YGC速度比FGC耗时短十倍以上,如果YGC100次时间为1s,FGC不到十次就会耗时1s【相较于YGC性能慢十倍的GC】,因此优化监控的时候一定要避免应用频繁FUll GC的问题
老年代中存放的总是生命力持久的对象和大对象
xxxxxxxxxx+ 垃圾回收流程图
Jconsole
监控堆内存变化、CPU、线程指标的jconsole和jvisualvm工具
这两个工具都是Java提供的,jvisualvm是jdk6以后提供的工具,是jconsole的升级版工具,一般推荐使用jvisualvm,相比于jconsole功能更强大,还可以将运行期间出现的问题以快照的形式下载下来慢慢分析来优化应用
jconsole的使用
安装了java环境直接在CMD窗口敲命令
jconsole启动jconsole控制台上来就提示需要新建连接,指要连接的具体应用,可以连接本地的,也可以连接远程的,本地进程会列举所有运行java程序的进程名称和对应的进程号,选择对应的应用进行监控
监控面板
概览面板
监控的数据包括堆内存使用量,线程数【压力测试线程数会一直向上涨】,已加载的类数量,CPU占用率

内存面板
绿条第一个是老年代内存,第二个是伊甸园区内存,第三个是幸存者区内存,

线程面板
显示当前的每个线程和对应的堆栈跟踪信息

类面板
显示当前加载的类信息

Jvisualvm
jvisualvm的使用
安装了java环境直接在CMD窗口使用命令
jvisualvm启动,弹幕说IDEA可以安装VisualVM Launcher插件,启动后选择连接目标进程,注意Java8以后不再自带jvisualvm概述面板显示了JVM参数和系统变量属性

监视面板显示CPU信息、堆内存信息、线程数,已装载类
压测期间需要观察已经使用的堆空间和已经使用的堆空间大小,线程情况和CPU情况,来观察当前应用到底是局限在CPU的计算上,还是内存经常容易满,还是线程数不够导致运行太慢等等,像下图CPU的使用了一直维持个位数的使用率,说明CPU太闲了

线程面板显示线程的具体信息,还展示当前线程是在运行、休眠【休眠状态是调用了sleep方法的线程】、等待【等待是调用了wait方法的线程】、驻留【线程池中等待接收新任务的空闲线程】以及监视【监视的意思是两个线程发生了锁的竞争,当前线程正在进行等待锁】

项目中还需要监控内存的垃圾回收等信息,jvisualvm默认是不带该功能的,需要安装插件,点击工具--插件,点击可用插件--检查最新版本来测试是否报错无法连接到VisualVM插件中心,如果报错,原因是需要指定插件中心的版本【修改插件中心的地址】,按照以下方式解决
打开插件中心的网址
https://visualvm.github.io/pluginscenters.html使用命令
java -version查看本机的jdk版本java version "1.8.0_101",重点关注小版本号101在插件中心的网址中找到小版本所在对应的版本号区间,拷贝对应版本区间的插件更新地址【点进该地址,复制页面最顶上的地址】

在jvisualvm中点击设置--编辑Java VisualVM插件中心,将地址粘贴到弹出框的URL栏中,点击确定后会自动进行更新
此时就可以直接使用可用插件菜单的插件了,安装不来用个梯子,因为github有可能连不上
在可用插件中选择插件VisualVM GC,通过该插件可以观察到垃圾回收的过程,点击安装,安装完点击文件--退出,重启jvisualvm,面板会多出一个Visual GC面板,其中Old表示老年代,右边的表示新生代【最上面是伊甸园区、下面是两个幸存者区】
GC Time 4875 collections表示总共GC的次数为4875次,后面跟的是GC花费的总时间10.714s
Eden Space中是4872次GC,耗时10.495s,单次约2.15毫秒,下面的图标显示的是内存用量的实时曲线,正常健康的曲线是如下图所示的类直角三角形曲线,意味着伊甸园区的内存满了以后触发一次GC然后内存用量清零

Old Gen是老年代,是3次GC,耗时218.686毫秒,单次约72.9毫秒,性能远远低于YGC,因此线上一定要避免频繁地进行FGC,老年代内存缓慢增长,老年代满了以后执行一次FGC
Metaspace是元空间,是直接操作物理空间的,前面的数字是最大空间,后面的数字是当前用量,元空间的内存用量不需要关心

中间件性能影响分析
使用JMeter对接口首页和首页商品分类数据进行压测,使用Jvisualvm来观察压测期间的CPU占用率、内存占用率、GC次数,根据这些指标对应用进行相应优化
使用Jmeter压测Nginx来观察中间件对整个应用的性能影响情况,主要单独压测90%请求看响应时间
使用Jmeter无限请求压测单台nginx
在ngixn所在服务器上使用命令
docker stats查看容器实例的系统资源占用情况,CPU占用率,内存使用量,内存用量占比,NET I/O【网络数据传输量】🔎:虚拟机网卡如果用NAT网络。网速会有瓶颈,最好用桥接
使用Jmeter访问nginx的ip地址对nginx进行压测,观察服务器容器系统资源消耗量
【初始数据】

【压测nginx数据】
吞吐量2400,这个数据对于nginx来说非常垃圾,CPU核数给少了,nginx正常都能上万,复习nginx的时候再确认一下
响应时间中位数是1ms,90%的请求在2ms内就返回了
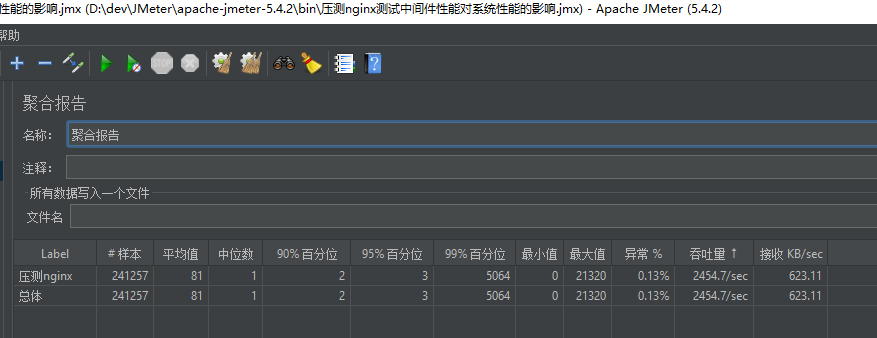
【压测时系统数据】
压测时CPU占用率直接飙满,因为nginx主要是做计算处理的,主要负责把请求交给别的服务器,不需要自己创建太多对象,所以性能瓶颈更多在CPU的计算能力上,对请求处理需要更多的线程,CPU在线程间来回切换进行计算

【压测发生的异常情况】
这个异常是正常的,表示连接已经关闭了,这是因为压测结束手动关闭连接但是一些请求还没有接收到响应的结果

使用Jmeter压测单台GATEWAY网关
使用JMeter对网关的ip地址
localhost:88进行压测,网关默认返回信息为404,也是网关的返回,可以不管直接测试网关性能【GATEWAY初始数据系统资源占用】

【堆内存情况】

【Jmeter压测结果】
吞吐量七万多,这个数据很夸张啊,响应时间中位数2ms、90%响应时间5ms,95%响应时间6ms;可能是响应内容较复杂
这个吞吐量经过验证含夸张成分,是uri为"/"或者没有uri的特例才会到7万,只要有uri对于该商城项目【不知道是有路由匹配还是注册中心等其他原因,吞吐量只有4500-4800,注意这是本机数据,此前的nginx是容器实例所在服务器的数据】
纯净不拖后端服务器的Gateway网关带静态资源IDEA上跑能跑8000左右,打成jar包跑能跑12000,提升JVM内存对性能的提升非常有限,带了后端服务器有路由匹配即便后端没有接收任何请求也只有四千多【可能是进行了路由的特殊处理以及维持和集群状态的额外开销】

【压测系统资源占用】
启动的总线程数也不大

【压测Gateway堆内存占用】
并发量上来以后系统频繁地YGC,YGC一万多次,短时间压测就占用12秒,当前限制了堆内存大小只有100m,如果提升堆内存空间

使用Jmeter压测简单响应接口【直接响应数据内容】
【控制器方法】
字符串长度太大无法使用这种方式响应,如69K的字符串不能用这种方式响应,必须转成对象通过json进行解析才能响应这么大的字符串【经过测试,长度15K的字符串还是可以响应的】
xxxxxxxxxx("/hello")public String hello(){return "Hello world";}【压测数据】
直接响应数据吞吐量特别大,直接9万了,这个是带uri且成功响应内容的吞吐量,非常地夸张;注意,经过测试,这个吞吐量和响应数据的大小也很有关系,当数据为Hello world的时候,吞吐量能到9w,但是当数据达到15K的大小的字符串时,吞吐量只能达到5万,如果查询的数据还涉及到数据库数据,速度会非常慢,甚至只有几百的吞吐量
如果是响应内容很大的从数据库查出的对象转成的json直接进行相应,此时的吞吐量会非常低,只有400左右,这是走缓存取的响应数据,直接响应同等量级的字符串还没找到对应的场景进行测试,有机会再测
使用Jmeter压测SpringBoot响应静态页面【非纯净响应静态页面】
响应静态文件内容过多吞吐量只会略降,即便是64K的文件也会在4800左右,但是这个响应时间非常长,平均长达37ms,90%都去到半秒了
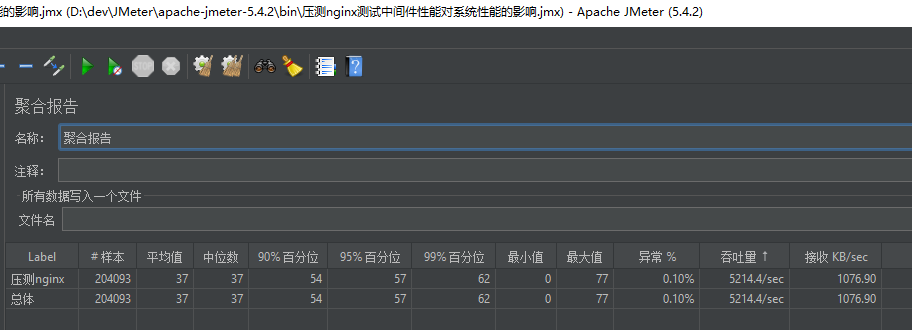
使用Jmeter压测Gateway+SpringBoot响应简单字符串【HelloWorld】,注意不要过nginx,需要对hello这个uri进行单独路由
Gateway响应自己的静态文件不太行,小于一万,但是带直接响应的数据挺快的,原来直接响应HelloWorld是九万,加上网关还有23000,对字符个数比较多的响应数据如此前的15K的字符串,吞吐量削减的不是特别明显,仍然有19000
经过一层Gateway网关吞吐量和响应时间都大幅增加,差不多是原来单个中间件的3倍多【这可能是内网还行的原因,网络速度比较快,导致中间件内部的时间占比较大,可以认为多一层中间件就多一层网络传输耗时】
因此中间件越多,性能损失越大,大多损失在网络传输上

使用Jmeter压测Nginx+Gateway+SpringBoot响应简单字符串
这里的nginx所在服务器是单核服务器上的容器实例,性能很渣单核3G内存,gateway和SpringBoot服务都在本机上,内存32G,24个核,所以这里Nginx拉这俩的测试结果并不客观
吞吐量数据和老师的比较吻合啊,因为机器配置差不多,这也说明此时nginx才是性能的瓶颈,但是这个响应时间的延迟比老师大很多,老师90%是80ms
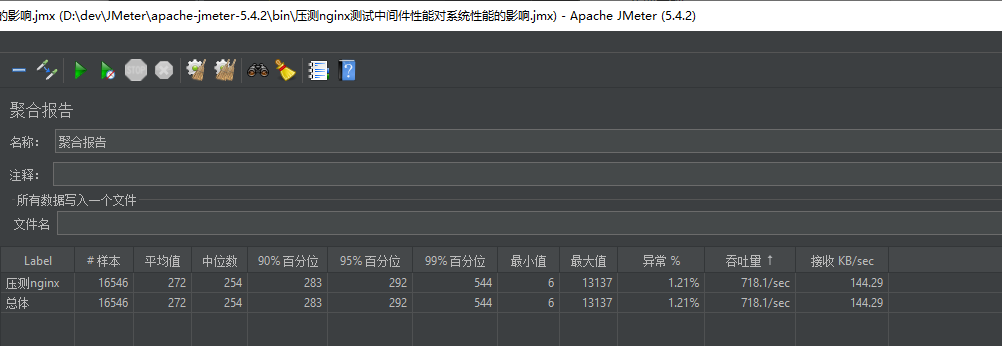
老师机器的压测数据汇总

优化中间件的措施
优化中间件的吞吐量【即中间件性能】
使用更好的网线和网卡来提升数据网络传输的效率
压测首页
拖慢业务代码接口性能的重要原因,
一个是查数据库,即使有缓存性能的消耗也是比较大的【参考封装69k数据只需要1ms不到,但是从缓存中拿这些数据耗时10ms,如果是直接从数据库查则耗时200ms】
一个是使用Thymeleaf进行模板数据渲染
一定不要使用循环查库,这会非常严重地拖慢系统性能甚至到几十秒的响应时间
性能分析
业务方法中涉及到查询数据库数据和模版引擎渲染页面数据的代码,速度会显著变慢
使用Jmeter直接压测首页
【压测数据1】
这只是单纯机器性能比老师好啊,老师的吞吐量只有270,Jmeter压测接口只是接收响应的被渲染后的首页内容,至于首页中发起的大量并发请求是不计算在内的,不像浏览器会去解析响应结果对超链接自动对超链接发起并发请求,因此都只是涉及一次相同的查库和相同的Thymeleaf渲染过程,并不涉及老师循环查库的问题

【压测数据2】
90%在47ms内完成响应,也比老师的好很多
浏览器平时使用的时候一般10ms就响应完了,但是在压测的时候浏览器的响应时长甚至会略高于压测平均时长

使用Jmeter直接压测首页中获取二三级商品分类数据的接口
http://localhost:9000/static/index/json/catalog.json这里老师故意使用循环查库,我这里当时对循环查库进行了优化,使用一次查库;而且也不是像老师一样使用stream流嵌套式操作而是使用HashMap对所有二三级分类数据一次循环,对所有二级分类的三级分类列表一次循环两次循环封装的数据
卧槽,循环查库的吞吐量每秒只有2,响应时间均值都是23s,50个样本90%的响应时间都是23s,这性能可以直接宣布项目失败了,就算是有数据库缓存吞吐量仍然只有2,不要循环查库
【压测数据】
数据量比较大,单次响应接近69K的数据,加上从缓存中拿数据,吞吐量低一点很正常,但是比循环查库强太多了

使用Jmeter压测首页中超链接发起的所有并发请求
我这一开并发量太大Jmeter直接卡死了,看不到数据,老师的吞吐量是7【他这个数据感觉没有加查询三级商品分类的循环查库接口一样,但是首页并发请求静态资源确实把首页的吞吐量从270直接打成个位数】,我这倒是没有死机蓝屏,实际项目静态资源都放Nginx,QPS跑几千没有问题,情况倒是也没有这个这么极端
性能优化策略
中间件优化
调整中间件的性能,让中间件本身的性能增加
使用更先进的网卡网线,更先进的数据传输技术、传输协议等等来增加网络传输性能
业务优化
数据库的查询速度优化
Mysql优化高级课中讲解了很多优化手段,到时候学习一下
该项目中的数据库优化
查询使用的是cat_level字段从1425条记录中进行查询,非主键,查询没走索引,查询比较慢,首次查询一级商品分类耗时基本200ms【数据库一千条数据,查询到的数据二十多条和查询一千多条不走索引差不多都是200ms】往上,后续查询时间会降低到3-6ms左右【老师的时间比这个时间长多了第一次1432ms,第二次6ms】;在navicat中右键表选择管理索引,给对应的查询字段添加索引,索引类型为Normal,首次查询178ms,后续每次2-4ms,2和3ms的出现频率比原来更频繁;日志级别为debug即控制台打印sql,压测从原来的1212.6提升为2173;日志级别设置为error即控制台不打印sql的情况下,压测吞吐量从2173提升至2399【由此可以看出,打印日志和数据库走索引对接口性能都有影响,其中以数据库查询走索引对接口性能提升极大,接近80%的提升,不打印sql提升约10%】,特别注意添加索引对mybatis有了缓存以后仍然有效啊,查询速度几乎可以提升一半,可能是像浏览器缓存一样发送请求验证数据是否被更改
模板的渲染数据
开发期间模版引擎一般要看到实时效果,所以一般在配置文件是关闭了缓存功能的,上线后一定要打开缓存,数据渲染吃CPU,开了Thymeleaf的缓存功能吞吐量从1212.7提升到了1287,提升有限,不过还是有接近约6.2%的提升【主要的限制还是在数据库上,这里在控制台打印SQL日志也是有影响的】
静态资源的响应速度【tomcat本身的并发不高,响应静态资源还需要分出线程资源,整个吞吐量就会下去很多】
一次动态请求返回的静态页面特别是大型网站会并发发起几十到上百个并发请求请求静态资源,tomcat的本身支持的并发就不高,处理静态资源分出的线程资源极大,占用处理动态请求的线程资源,整个吞吐量就会下降很多,tomcat直接变成系统瓶颈,解决办法是做动静分离,把静态文件前置nginx或者CDN,开启浏览器的静态资源缓存功能,让tomcat把几乎全部的资源拿来处理动态请求,将静态资源中非模版的部分文件夹index全部上传nginx的指定站点目录html下的static目录下,nginx返回的静态资源响应头中Server字段会带nginx的版本;做了动静分离后jmeter能全量压测了,不像之前直接卡死,测出来吞吐量为13【比老师的结果11稍好】,老师的jmeter更给力啊,可能是他的服务不给力【循环查库查二三级分类的数吞吐量很低,这个数据一个响应就是69K的数据,我这个接口的吞吐量还可以,可能jmeter处理不了这么多数据,最后的效果是jmeter页面卡死,看不到数据,但是服务器一直在响应压测,直到若干分钟后手动关闭了jmeter,而且整个过程的FGC非常少,老师的FGC太多也可能是循环查库造成的,我这儿只有几个Map对象比较大】,jmeter没有接收到很多响应,我这儿服务器效果还行
集中修改首页中对静态资源的超链接方法【给所有静态资源的uri添加前缀static】:
href="替换为href="/static,<script src="替换为<script src="static/,<img src="替换为<img src="static/<src="index替换为<src="static/index
修改nginx配置将静态资源站点修改至nginx的挂载目录
xxxxxxxxxxserver {listen 80;server_name earlmall.com;location /static {root /usr/share/nginx/html;}location / {proxy_set_header Host $host;proxy_pass http://gateway;}error_page 500 502 503 504 /50x.html;location = /50x.html {root /usr/share/nginx/html;}}
调高日志打印级别,控制台打印日志也会影响吞吐量,大约10%的提升
提升JVM内存
全量压测【即自动发起响应中的并发请求】,老师的接口中JVM中的老年代区域的FGC和YGC变得频繁【可能是因为他的循环查库,我这儿FCG只有个位数,我还以为Jvisualvm出问题了】,增大JVM内存也能提升性能
【老师的全量压测数据】
提升并发请求量比如增加用户数到200,吞吐量也会提升,老师的压测数据从11来到三四十了,最后因为频繁地FGC导致JVM内存爆满溢出导致他的商品服务直接崩溃了【他这里压的是localhost,请求根本就没走nginx,全走的tomcat,静态资源也走的tomcat,但是之前他是将tomcat中的静态资源全部剪切到nginx的,所以他的静态资源请求会全部快速失败,因此jmeter不会有这么多的静态数据需要处理,说白了就是在压首页渲染和二三级分类数据两个接口,而且二三级分类接口还是循环查库,因此jmeter的压力才这么小,我改成和他一样的配置以后jmeter也没有崩过了,但是这样测出来的数据是不对的,因为tomcat还分担了线程处理静态资源,只是全部快速失败而已】
【压力测试首页且静态资源请求tomcat,200用户全量并发的情况】
100mJVM内存的情况下,Jmeter没有数据报告而且没卡死,说明第一个请求都没有处理完,Jvisualvm中显示情况为伊甸园区和老年代区的内存全部直接飙满且没有GC过程,FGC的时间飙到两分钟,卡死以后老年代内存缓慢增加到满内存,老年代内存满了以后控制台开始打印线程异常

【老年代内存爆满后控制台抛线程异常】

【商城首页直接崩溃】
感觉崩溃的原因主要还是带上静态资源请求并发量太高,上千的并发直接瞬间把tomcatJVM内存压满,连GC都无法进行,老年代内存满了以后控制台开始抛异常,服务直接不可用

修改JVM参数
-Xmx1024m -Xms1024m -Xmn512m增加JVM内存空间,并给新生代的JVM空间调整到512M【伊甸园区分配384M,两个幸存者区分别64M】,原来新生代只有54M,老年代67M,200的用户并发,吞吐量只有11,但是没有发生内存爆满溢出和服务崩溃的问题,更改内存后即使384M的伊甸园区也是频繁YGC,几乎一秒左右就一次【这里不能用jmeter直接压nginx,响应的资源太多会直接把jmeter压垮卡死,不显示数据,无法正常停止,单压tomcat即使返回69K的数据jmeter还是能显示数据,静态资源光文件夹就有10M】,JVM内存增加到1024M,即使200用户,再加上所有快速失败的巨多静态资源请求,只是伊甸园区内存频繁约每秒一次的GC,老年代并没有频繁GC,增长的也比较慢,没有服务崩溃的风险
优化业务逻辑【二三级商品分类数据获取优化为例】
这里讲师使用的是stream流循环查库的方式来获取封装二三级商品分类数据,吞吐量极慢,只有2,且响应时间长达二三十秒,我这儿没有使用循环查库,对数据的封装也使用了HashMap进行优化,以O(N)量级的时间复杂度完成了封装操作,对比此前stream流递归调用封装三级商品分类列表执行时间10ms,成功优化成执行时间少于1ms,对于单次返回69K且带不走索引查询数据库操作的接口,压测吞吐量为421;添加索引后,压测吞吐量没什么变化,判断使用in多个值不会走索引,仍然为420左右,响应时间没什么变化;更有效的优化策略学了Mysql优化再考虑
以下是老师对该原接口的优化策略
循环封装前首先查询出所有的商品分类数据再使用stream流来对商品数据进行封装
但是即便这样,接口的吞吐量也不是很高,数据库还是主要的瓶颈,此时就需要考虑分布式系统中性能提升的大神器缓存
加redis缓存
真牛逼,我这儿加了缓存,而且还是从后端程序获取的redis缓存处理以后响应的,接口吞吐量直接从400提升至1100【直接返回String,使用的lettuce作为redis操作客户端】,返回Map两段冗余数据转换是1000的吞吐量
老师的循环查库是2,加了索引控制台日志提升至error是8,优化循环查库一次查询是111,加了redis缓存直接从111飙到411【冗余转换而且使用jedis作为redis操作客户端】
缓存
数据访问量非常大【比如商城首页数据】,数据变更频率低,将这部分数据放入缓存能极大提升系统性能,提升系统吞吐量,让数据库主要承担数据的落盘工作,重心不在负责数据的频繁查询
整体逻辑:获取首页的三级分类数据,对首页接口压测并指出性能优化策略,使用缓存、分布式锁、SpringCache、双重检查锁、数据一致性方面对首页商品分类数据进行了优化
适合放入缓存的数据【实时性要求不高,数据查询量大】
及时性,数据一致性要求不高的数据
比如物流状态信息,不可能每时每刻都更新物流信息,间隔一段时间才更新的数据信息,用户对物流数据的准确性也不是很高
数据一致性指的是数据库中存放的数据和最终读取到的数据是否一致
商品分类数据的一致性要求也不是特别高,数据库数据更新以后隔几分钟或者几十分钟缓存再更新,商品发布后等待5分钟商品才能上架,这是可以接受的,可以考虑给商品分类缓存数据添加一个失效时间
访问量大且更新频率不高的数据【读多写少】
比如商品的基本属性很少会进行修改,商品的访问量又特别大,每次都查数据库这是一个非常慢的操作
读模式缓存使用流程
根据请求读取缓存数据,缓存命中直接响应,缓存没有命中记录,查数据库并将数据放入缓存

缓存的种类
本地Map缓存
原理:在程序中准备一个Map类型的属性,将数据返回值存入该属性,执行查询方法前先判断属性是否为空,为空再执行业务查询方法,不为空直接返回缓存数据,本地缓存指运行在项目中,在该项目的JVM中存入一个副本
优点:快
问题:
缓存分布在每个服务内部,如果是集群化部署,每个服务器第一次查不到都会查询并生成自己的缓存,冗余存储
数据发生更改以后需要考虑更新缓存,更新缓存以后不同机器上的缓存数据可能不一致,更新数据可能需要考虑其他机器上的缓存更新或者其他机器要等到自身数据更新时才更新缓存,可能存在时间窗口缓存数据不一致
本地缓存容量不能无限扩充,容量上限是服务的JVM内存
分布式缓存
原理:服务产生的缓存数据都统一存入缓存中间件,比如redis
优点:
查询服务时服务会首先从缓存中获取数据,如果缓存中没有会查出数据并给缓存放一份,以后其他服务要查询相关数据就可以直接从缓存中获取
数据更改时服务也会一同更新缓存中的数据,这样任意一个服务更新操作都能保证其他服务获取的也是更新后的数据
如果缓存中间件性能不足,可以使用集群;如果数据容量不够,还可以做分片存储【redis支持集群也支持分片存储】,理论上可以无限扩容
缓存可以直接前置到nginx直接访问或者更靠前,连网关都不需要过,减少网络传输过程和不必要的中间件消耗
整合redis
安装redis容器实例,此前已安装
SpringBoot配置
引入场景启动器依赖
xxxxxxxxxx<!--redis做缓存操作,搜索RedisAutoConfiguration能找到redis相关配置对应的属性类,所有相关配置都在该属性类中--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId></dependency>SpringBoot对redis的配置
host指定redis所在主机地址,
port指定redis在主机上的端口号,默认就是6379
如果指定了用户和密码还可以在配置文件中指定用户和密码,默认安装没有密码和用户名
xxxxxxxxxxSpringredishost192.168.56.10port6379
redis的自动配置类
redis的自动配置类给容器中添加了
RedisTemplate<Object,Object>对象【对应k-v键值对的数据】一般操作k-v都是字符串较多,因此自动配置类还专门给容器添加了一个
StringRedisTemplate对象,该类继承自RedisTemplate<String,String>,对应的key和value是用String的序列化来做的
【StringRedisTemplate的源码】
注意这个
RedisSerializer.string()
xxxxxxxxxxpublic class StringRedisTemplate extends RedisTemplate<String, String> {public StringRedisTemplate() {setKeySerializer(RedisSerializer.string());setValueSerializer(RedisSerializer.string());setHashKeySerializer(RedisSerializer.string());setHashValueSerializer(RedisSerializer.string());}public StringRedisTemplate(RedisConnectionFactory connectionFactory) {this();setConnectionFactory(connectionFactory);afterPropertiesSet();}protected RedisConnection preProcessConnection(RedisConnection connection, boolean existingConnection) {return new DefaultStringRedisConnection(connection);}}RedisTemplate的使用
示例
xxxxxxxxxx(SpringRunner.class)public class MallProductApplicationTests {StringRedisTemplate stringRedisTemplate;public void testStringRedisTemplate(){//RedisTemplate下有很多opsXXX,这主要牵扯到redis中不同的数据类型,本项目基本使用以下五种类型,更多后面复习redis再说//1. stringRedisTemplate.opsForValue() 这是存放简单类型//拿到ops操作对象ValueOperations<String, String> ops = stringRedisTemplate.opsForValue();//保存数据ops.set("Hello","world_"+ UUID.randomUUID());//从redis中查询对应key的数据String hello = ops.get("Hello");System.out.println("Hello:"+hello);//Hello:world_46a44c4e-8436-4eb0-9dc6-86f49e6aa2e2//stringRedisTemplate.opsForHash() 这是value类型也是一个Map类型//stringRedisTemplate.opsForList() 这是value类型是一个数组//stringRedisTemplate.opsForSet() 这是value类型是一个Set集合//stringRedisTemplate.opsForZSet() 这是value类型是一个ZSet带排序集合类型}}redis中的存入的数据
缓存商品分类数据
业务代码
数据都以json的格式存入缓存中间件,方便跨平台、跨语言解析
存在两段冗余的对象转换,对吞吐量的影响大概10%,即直接返回字符串1100吞吐量、多了两段对象转换吞吐量降至1000
@ResponseBody标注的控制器方法直接可以直接返回字符串变量,但是不确认有没有风险啊,从redis中取出的就是json格式字符串,如果存在风险需要转换成对象等后台自动处理成json字符串数据量大的情况下对吞吐量有影响【69K的数据吞吐量影响为10%】,但是控制器方法不能直接返回很大的字符串常量【如69k】,项目无法启动,目前测试可以返回15K的字符串常量,解决办法还可以是直接用nginx从redis中获取数据直接返回字符串
xxxxxxxxxx/*** @return {@link Map }<{@link String }, {@link List }<{@link IndexSecondLevelCategoryVo }>>* @描述 听说fastjson长度超过三四万就没法转成json字符串了,老是报错,数据量不大可以使用fastjson,很快;* 漏洞一般很少触发,重要的数据使用jackson,ObjectMapper就是Jackson的json工具转换类,了解一下ObjectMapper怎么用的,而且新版fastjson可能修复了* 给缓存中存放json字符串,拿到json字符串还要能逆转为可用对象类型,这个过程也称为序列化和反序列化的过程* 注意受保护的类需要写匿名实现才能创建对象* 在缓存中间件中一律存储json格式的字符串,好处是JSON支持跨变成语言,跨服务平台,各个语言拿到json格式数据都支持解析,如果是使用* java序列化的字符串,就只能在java平台才能解析* 这里存在冗余操作,响应过程中也会把对象转换成json,这里获取到封装对象以后先转成json存入缓存,再将对象由SpringBoot自动转成json响应给前端,* 做了两次对象转换成json的工作,一次就是69k的数据,虽然处理时间大概率不超过1ms,但是这样存在冗余操作* 直接从缓存取到了也要转成Map对象然后响应又转成json字符串,白白多了两个转换的消耗* 考虑用切面编程或者此前用过的在最后响应前添加响应头信息的时间点将响应的json串存入redis集群,SpringBoot还有一个问题,使用@ResponseBody* 注解,响应字符串长度过大会无法启动项目,69K不能支持,但是目前测试出15K能支持,但是对于商品分类数据这种大量数据,响应字符串存在隐患* 注意直接响应很长的字符串是可以的,但是这个字符串不要写到控制器方法的返回值处。直接返回变量压测结果是1100,比老师报错率90%的吞吐量都高* 加了两段解析字符串到对象,对象解析成字符串的过程吞吐量只下降了100,吞吐量为1000* @author Earl* @version 1.0.0* @创建日期 2024/06/09* @since 1.0.0*/public Map<String, List<IndexSecondLevelCategoryVo>> getIndexCategories() {//从缓存中获取首页二三级商品分类数据String indexCategoriesOfJSONStr = stringRedisTemplate.opsForValue().get("indexCategories");//判断缓存中间件是否有数据,没有数据从数据库查,有数据解析成对象直接返回,注意这里直接返回字符串可能会有问题//注意,StringUtils.isEmpty(indexCategories)是判断字符串不为null且地址不等于空串的地址来判断该字符串不是null,因此处理较大字符串不会太消耗性能if(StringUtils.isEmpty(indexCategoriesOfJSONStr)){//缓存没有从数据库拿Map<String, List<IndexSecondLevelCategoryVo>> indexCategoriesFromDb = getIndexCategoriesFromDb();String indexCategoriesOfJsonStr = JSON.toJSONString(indexCategoriesFromDb);//将数据存入缓存中间件stringRedisTemplate.opsForValue().set("indexCategories",indexCategoriesOfJsonStr);//响应二三级商品分类数据return indexCategoriesFromDb;}//如果能从缓存中拿到数据,转成Map进行返回return JSON.parseObject(indexCategoriesOfJSONStr, new TypeReference<Map<String, List<IndexSecondLevelCategoryVo>>>() {});}异常情况
Jmeter压测过程中发生了大量异常【异常一度飙升至50%-90%不等】,异常响应内容如下
异常信息:
Redis exception; nested exception is io.lettuce.core.RedisException: io.netty.util.internal.OutOfDirectMemoryError: failed to allocate 499122176 byte(s) of direct memory (used: 511705088, max: 1006632960)",,浏览器访问发现服务已经崩了;

后台控制台连续抛出大量异常
io.netty.util.internal.OutOfDirectMemoryError: failed to allocate 499122176 byte(s) of direct memory (used: 511705088, max: 1006632960)原因分析:
抛出异常的信息为:lettuce在io使用netty操作时出现了
OutOfDirectMemoryError异常,专业术语对外内存溢出,只要使用当前版本及以前版本的lettuce就会出现该问题,即使现在没出现问题,上线以后也依然会出现该问题,出现该问题的原因是内存不够【弹幕说就是直接内存,接触netty和网络编程就会知道】,不使用压测就浏览器访问测试一点问题没有,但是使用压测或者服务上线后,并发量一上来就发生了该错误,报错说是内存问题,设置JVM的堆内存为-Xmx100m,但是使用Jvisualvm分析堆内存情况发现堆内存一切正常,YGC频繁正常进行,老年代缓慢增长,metaspace没什么变化;SpringBoot2.0【2.1.8.RELEASE】【据说2.3.2.REALEASE不会爆该异常】以后整合的操作redis的客户端是lettuce【5.1.8.RELEASE】,该客户端使用netty【4.1.38.Final】和redis进行网络通信,因为Luttuce配合netty进行网络操作时做的不到位,导致netty的堆外内存溢出【我们本机的内存32G完全是够用的,但是还是爆堆外内存】,通过控制台的错误日志发现,爆该异常的原因是要要分配的堆外内存【直接内存】加已经使用的直接内存大于最大的堆外内存,但是我们并没有设置过堆外内存,只是设置了JVM的内存-Xmx100m,对该值,300m和1G都发生了该异常,经过研究发现netty没有指定堆外内存,会默认使用-Xmx100m作为堆外内存,在并发处理过程中,获取数据的量特别大【一次就是69K】,数据在传输、转换过程中都需要占用内存,导致内存分配不足,出现堆外内存溢出问题;当-Xmx调大成1G的时候,发现不会瞬间发生堆外内存溢出,甚至还能测出吞吐量好一会儿以后才会发生该异常;即使将该值调整到很大的值,也只能延迟该堆外内存溢出的情况,但是该异常永远都会出现,根本原因是源码中netty在运行过程中会判断需要使用多少内存,计数一旦超过常量DIRECT_MEMORY_LIMIT【直接内存限制】就会抛OutOfDirectMemoryError异常,调用操作完以后应该还要调用释放内存的方法并计数释放的内存使用量,但是在操作的过程中没有及时地调用减去已释放内存导致报错堆外内存溢出,直接内存限制使用的是虚拟机运行参数设置-Dio.netty.maxDirectMemory,该问题在线上也会出现,到时候线上演示如何通过日志定位该问题并进行操作
解决方案:
不能只调大虚拟机参数
-Dio.netty.maxDirectMemory来调大虚拟机内存,因为经过多段测试,调大内存只会延缓出现该异常的时间,延缓时间也非常有限,长久运行后也会直接爆堆外内存,根本的解决方案有两个,lettuce和jedis都是操作redis的最底层客户端,其中封装了操作redis的api,SpringBoot的RedisTemplate又对这俩客户端进一步进行了封装,在RedisAutoConfiguration中也使用@Import注解引入了这俩的ConnectionConfiguration,在该ConnectionConfiguration中会给容器中放入连接工厂RedisConnectionFactory的实现类,由该工厂对象创建出RedisTemplate对象并注入容器,无论使用jedis还是lettuce,都可以直接使用RedisTemplate来不动代码仅通过更改pom排除和引入另一个来更换底层操作redis的客户端第一是升级lettuce客户端操作netty
luttuce从5.2.0.RELEASE开始就解决了这个问题,但是诡异的是
spring-boot-starter-data-redis直到最新的3.3.0【2024.5.23】都还是用的5.1.8.RELEASE【从2.1.8.RELEASE以前就开始用】,到现在还没换,直接排除原来的lettuce,更换5.2.0.RELEASE版本即可,使用这个不会报错【56w的样本】而且吞吐量较jedis大了一倍多,比5.1.8.RELEASE的吞吐量1000还要高,达到1180;如果直接从缓存拿到json不冗余转换,吞吐量能达到1200【这里使用lettuce5.2.0.RELEASE是否对从redis中拿到的数据进行冗余转换影响不大,提升了20的吞吐量】
xxxxxxxxxx<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId><exclusions><exclusion><groupId>io.lettuce</groupId><artifactId>lettuce-core</artifactId></exclusion></exclusions></dependency><!-- https://mvnrepository.com/artifact/io.lettuce/lettuce-core --><dependency><groupId>io.lettuce</groupId><artifactId>lettuce-core</artifactId><version>5.2.0.RELEASE</version></dependency>第二是使用老版客户端jedis来操作redis,缺点是更新频率低,lettuce的优点是使用netty作为底层的网络框架,吞吐量极大【据说lettuce5.2.0以后解决了该问题,弹幕说把版本改成5.3.4.RELEASE也可以】,以下是排除lettuce使用jedis来操作redis,这种方式吞吐量只有400了,比使用lettuce导致吞吐量直接少了600
xxxxxxxxxx<!--redis做缓存操作,搜索RedisAutoConfiguration能找到redis相关配置对应的属性类,所有相关配置都在该属性类中--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId><exclusions><exclusion><groupId>io.lettuce</groupId><artifactId>lettuce-core</artifactId></exclusion></exclusions></dependency><!--springboot默认jedis版本控制是2.9.3--><dependency><groupId>redis.clients</groupId><artifactId>jedis</artifactId></dependency>
缓存相关问题
缓存失效可能引发的问题,缓存失效指缓存没有命中,缓存一旦没有命中可能出现以下问题:缓存穿透、缓存雪崩、缓存击穿
缓存穿透
概念:查询一个一定不存在的数据,默认情况下没有该数据的缓存,由于缓存不命中,请求将会去查询数据库,但是数据库也没有该记录,如果不将此次查询的结果null写入缓存,那么相同的请求每次都会去请求数据库,如果有恶意请求针对不存在商品进行高频攻击,会给数据库造成瞬时高压,可能直接把数据库压垮
解决办法:
查询查不到结果,就将空结果也进行缓存,并设置一个短暂的过期时间,这样一方面是避免缓存过大,另一个方面是避免空值数据万一有了数据无法及时更新
也可以使用布隆过滤器对高频ip进行封禁
缓存雪崩
概念:设置缓存时key使用了相同的过期时间,导致缓存再某一时刻同时失效,然而此时的并发请求非常高,瞬间请求压力全部给到数据库,数据库瞬间压力过重雪崩
解决办法:在原有失效时间上添加一个短时间内的随机值【如1-5min随机】,这样每个缓存的过期时间重复率降低,从而很难发生极短时间内缓存集体失效的情况
缓存击穿
某些热点数据可能在瞬间突然被超高并发地访问,比如秒杀,但是对应的key正好在大量请求瞬间到来前已经失效,且在超高并发请求到来前没有请求再次形成缓存,那么瞬间的超高并发对同一个key对应的数据查询压力全部落在数据库上,称为缓存击穿,又比如一个接口只缓存一个数据结果,但是这个结果总会失效,失效的瞬间加入还是高并发请求【如首页商品分类数据】,此时所有并发查询压力就会直接加到数据库上
解决办法:
对重建缓存的过程加双重检查锁,对超高的瞬时并发,只让一个请求通过去重建缓存,剩下的请求都等待缓存
针对以上问题对首页商品二三级分类数据获取进一步优化
优化点
空结果缓存,解决缓存穿透问题
设置附带随机值的过期时间,解决缓存雪崩问题
给代码加锁,解决缓存击穿问题
空结果缓存
空结果缓存,没从数据库获取到数据就给对应的key放一个带过期时间的空值进去,获取到就缓存获取到的数据
缓存雪崩问题,set方法保存数据时调用重载方法,在第三个参数写随机时间长度,在第四个参数指定时间单位TimeUnit.XXX
本地锁解决缓存击穿问题
缓存穿透和缓存雪崩都好解决,缓存击穿加锁问题比较复杂,锁加不好会引发一系列问题【重点是确认缓存是否重建和将数据放入缓存是原子操作,在同一把锁内执行,否则会导致释放锁的时序问题,导致数据库被查询超过一次】
考虑单体项目加同步代码块,缓存拿不到数据进入数据库拿数据操作逻辑,为了避免过多的数据库查询造成压力,给整个数据库查询代码加锁,使用this即service容器实例作为锁,因为service实例在IoC容器中都是单实例,只要所有的锁都是同一把锁,就能锁住需要这把锁的所有线程,因此以this指向的当前service单实例可以锁住当前并发请求的所有线程,synchronized可以加到方法上也可以加到代码块上;
注意多个请求进来竞争同一把锁,只有一个拿到锁重建缓存后,其他等待锁的请求不再次检查缓存数据是否重建还会执行相同的从数据库获取数据重建缓存的操作,因此拿到锁以后需要再次检查缓存数据是否重建,如果已经重建则直接拿缓存数据直接返回且不要再执行将数据放入缓存的操作;这样的锁称为双重检查锁
但是这样还存在问题,如果只对从数据库获取数据加双重检查锁,并没有对将数据序列化存入缓存加锁,当第一个请求从数据库拿到数据后就直接释放锁,然后再去执行重建缓存的操作,此时存在网络操作,可能时间几毫秒到几十上百毫秒不等,这个期间后续拿到锁的线程同样立即尝试检查缓存是否建立,结果数据还没来得及存入缓存,后续线程获取不到数据又再次执行查询数据库操作,无法实现只锁住执行一次数据库查询操作,经过jmeter压测,确实发生了不止一次的数据库查询操作,因此要将数据存入缓存的操作也加锁,避免后续线程因为数据发起重建缓存请求到缓存重建完毕期间因为拿不到缓存再多次发起数据库查询和再次重建缓存操作
问题:这种锁使用的是当前服务的容器单实例,集群部署时一个服务一个容器,一个容器一个实例,对于整个集群来说,这个锁只对当前服务有效,相当于有几个服务就有几把锁,因为负载均衡,每个服务上都有对应的重建缓存操作,因此这种锁无法完全锁住分布式集群的重建缓存操作,但是也极大地削减了对数据库的压力,集群环境下使用这种锁【本地锁,synchronized或者JUC包下的各种锁都称为本地锁,只能锁当前服务,也叫进程锁】也是可以的,这种锁更轻量,效率更高【对性能其实影响不大,查询数据库的过程中参数竞争锁的线程只有14个甚至更少,即便我将用户数调整到了500,一般就个位数到十几个参与竞争锁,并不是所有的请求都被受理竞争锁了,因此这里也就最多十几个请求需要一个一个拿锁操作,经过测试,十几个对象竞争锁是不对的,因为是将缓存删了才用jmeter测试,jmeter刚开始并发请求少,要jmeter运行起来再删除缓存才能看到实际效果,经过实测,这里直接将tomcat能同时处理请求的最大线程数200压满了,也就意为着一个线程处理一个请求,很快啊,几个语句执行200个请求和线程就压满了,而且感觉是早就压满了200个等待拿到锁的线程执行重建缓存操作,且后续不会再有竞争锁的请求进来,意味着定死了重建缓存每个服务会有200个线程竞争锁和串行执行,对总的吞吐量影响不大,一般少个几十,仍然在1100以上,关于tomcat线程池的只是参考博客tomcat线程池-CSDN博客】,对数据库的压力削减相当明显,即便千万并发100个服务也只会产生一百次数据库查询操作,对数据库的压力削减相当可观;但是想要完全锁住集群中的所有服务必须使用分布式锁,分布式锁相较于每个服务锁服务单例性能太低,设计更重
本地锁在分布式系统下的问题
锁不住所有服务,每个服务都会执行一次数据库查询,极端情况下每个服务都会有200个请求竞争锁并串行获取缓存数据,但是对性能影响不大,使用lettuce吞吐量1180左右只会减少几十
分布式锁
分布式锁就是大家都去一个公共的地方占唯一的坑,占到了就是拿到了唯一的锁
这里细节只是去看分布式锁的笔记,这里只讲实现逻辑和优化过程,其实这些优化都是分布式锁里面自己实现的优化逻辑
分布式锁是分布式系统下各种锁的集合,其实和本地锁功能分类都是一样的,只是管的范围更宽了,Redis官方文档指出了各种语言对红锁算法实现的框架,
基础实现
业务逻辑
用
RedisTemplate.setIfAbsent()来模拟Redis的setnx命令来尝试让所有请求线程创建同名key键值对,创建成功的拿到锁重建缓存,创建失败的等待一段时间自旋重试获取锁删除键值对来释放锁
只有第一次拿到锁的请求线程才会去数据库重建缓存,同时刻的并发请求还是会竞争分布式锁,但是抢到锁进入重建缓存逻辑还是会首先去双重检查缓存是否已经建立,如果已经建立就不会去访问数据库重建缓存了,因此实现了所有服务只去数据库建立一次缓存
存在问题
线程抛出异常没来的及释放锁线程就结束运行导致死锁,可以通过把解锁代码放在finally语句块中执行
应用程序宕机占有的锁没释放也会导致死锁问题,解决办法是给锁设置过期时间,而且要保证设置过期时间和创建键值对两步操作是原子性的,否则还是可能出现获取到锁,但是还没来得及设置过期时间服务器宕机导致死锁,使用完整的set命令即
set NX EX创建键值对的同时指定过期时间能实现,完整的set命令也通过RedisTemplate.setIfAbsent()的重载方法来调用这种设置锁有效期会导致出现两个问题,业务还没执行完锁提前释放,业务代码无锁裸奔,同时其他线程会抢到锁出现线程并发安全问题,第二是当前线程释放锁删除键值对删的是别的线程上的锁
优化
解锁放finally,加锁和设置过期时间使用
set NX EX保证原子性锁提前释放需要使用定时调度任务来给锁自动续期【自动续期老师没做但是我们做过】
正确删除当前线程的锁可以给当前线程指定一个uuid,用uuid作为键值对的value,当前线程删除键值对释放锁前先验证uuid是否当前线程的uuid,是才去释放锁,同时还要保证查uuid和删除锁两步操作是原子性的,这个就不能通过指令实现了,必须使用Lua脚本一次提交执行多步Redis指令和Redis的单线程特性来保证验证并释放锁的两步操作原子性【自动续期线程挂了如果不保证验锁和释放锁的原子性在存在自动续期优化的情况下仍然会出现线程安全问题】,使用Lua脚本是Redis官方文档指出的,甚至还给出了脚本代码,这个也自己写过,细节看分布式锁,还做了封装
这里可以吹牛逼啊,我们有比项目自己实现更专业的方案【锁重入和自动续期以及对set加锁指令的优化,锁还实现了JUC的Lock接口,JUC中的锁怎么用,我们定义的锁就怎么用】,使用Redisson也是专业学过的
Redisson
使用Redisson中的分布式锁来锁系统请求线程,只让一个请求线程去重建缓存,其他请求拿到分布式锁后马上检查缓存是否重建,已经重建了直接拿着缓存数据返回
但是这样引出一个新的问题,缓存更新只会发生在缓存到有效期以后,如果日常数据发生变化,从缓存中拿到的还是旧数据,如何让缓存中的数据和数据库的数据保持一致也就是缓存的一致性问题
通过
RLock lock=redisson.getLock("my-lock")来获取锁,获取锁以后执行业务方法,在finally语句块中解锁,Redisson采用了更好的基于netty时间轮的锁自动续期机制,默认锁的有效期都是30s,在获取锁后第10秒去进行有效期重置,还有一个优点,没看过Redisson的续期源码,基于Timer写过一个,在本次定时任务中只去执行一次有效期重置,成功再去启动下一个有效期重置定时任务,当前的定时调度任务就算结束了,通过这种方式能保证只在当前服务存活的情况下才去续期,而且续期还会检查锁是否当前线程获取的锁,宕机情况下续期任务自动结束,线程抛异常结束会进入finally语句块自动释放锁,此时锁和定时任务中的Field属性对不上,续期失败就不会再继续续期了配合业务逻辑
加分布式锁,获取到锁去执行重建缓存的操作,重建缓存方法一进入就要再次检查缓存是否建立,如果缓存已经建立就不再去数据库获取商品分类数据,在finally语句块中释放锁
为一个业务指定一个唯一名字的分布式锁,这样能避免很多业务都使用同一把分布式锁,锁的粒度越细,系统的性能就越高,比如11号商品的库存锁命名最好命名为
product-11-stock-lock,净量保证一个业务一把分布式锁;同时锁粒度太粗导致完全不相关的两个业务相互影响相当于业务逻辑就出问题了
使用Redisson能保证锁的独占、重入、阻塞、自动续期、防宕机死锁、正确释放锁,使用异步编排和阻塞锁实现也大大提升了分布式锁的性能,基于Redis实现的分布式锁也能大大保证系统的性能
我对这里的阻塞锁表示怀疑,可能雷丰阳老师的意思是自旋重试也是一种阻塞方式吧,我们认为的阻塞是线程一次获取几次尝试后获取不到锁,线程就进入阻塞状态,因为源码中第一次没获取到锁后续就去while死循环里面去不停尝试了,Zookeeper的哪个实现确实用闭锁实现了阻塞锁
要点
使用
redissonLock.lock(10,TimeUnit.SECONDS)会存在一个严重问题,使用这个方法上锁,如果指定时间为10s自动释放,而锁自动续期时间间隔也是10s,如果使用该方法锁是不会自动续期的,如果此时业务方法还没有执行完,其他的请求线程就能抢占锁了,不仅会发生线程安全问题,还会因为锁被自动释放了,续期任务因为检查不到对应线程的锁或者查到不是目标线程上的锁就不会再执行自动续期任务了,此时业务代码就会无锁裸奔,这是RedissonLock使用中存在的问题,在分布式锁中没有讲过但是确实存在的问题,很重要啊,即使用方法redissonLock.lock(10,TimeUnit.SECONDS)上锁,锁的自动解锁时间一定要比业务方法执行时间长,否则一旦锁自动释放,续期机制因为锁被释放了或者检查到是别的线程上的锁也会失效,导致并发请求线程无锁裸奔,一定会并发线程安全问题雷丰阳老师说实际开发中更推荐使用
redissonLock.lock(30,TimeUnit.SECONDS)来明确指定锁自动释放时间,没给出理由,只是说这样可以省掉续期过程并且业务方法执行时间不可能超过30s,超出30s业务就完蛋了,执行完业务方法通过手动解锁的方式来释放锁,弹幕说实战推荐写一个注解,通过AOP加锁解锁Reddison的信号量RedissonSeamphore在后面的秒杀设计中也用到了
代码实现
xxxxxxxxxx("categoryService")public class CategoryServiceImpl extends ServiceImpl<CategoryDao, CategoryEntity> implements CategoryService {private StringRedisTemplate stringRedisTemplate;private RedissonClient redissonClient;/*** @return {@link Map }<{@link String }, {@link List }<{@link IndexSecondLevelCategoryVo }>>* @描述 从缓存中拿首页商品分类数据,如果缓存中没有就使用分布式可重入锁去数据库拿* @author Earl* @version 1.0.0* @创建日期 2024/09/02* @since 1.0.0*/public Map<String, List<IndexSecondLevelCategoryVo>> getIndexCategories() {//从缓存中获取首页二三级商品分类数据String indexCategoriesOfJSONStr = stringRedisTemplate.opsForValue().get("indexCategories");//判断缓存中间件是否有数据,没有数据从数据库查,有数据解析成对象直接返回,注意这里直接返回字符串可能会有问题//注意,StringUtils.isEmpty(indexCategories)是判断字符串不为null且地址不等于空串的地址来判断该字符串不是null,因此处理较大字符串不会太消耗性能if(StringUtils.isEmpty(indexCategoriesOfJSONStr)){//缓存没有就使用分布式锁去数据库重建缓存return getIndexCategoriesWithDistributedLock();}//如果能从缓存中拿到数据,转成Map进行返回return JSON.parseObject(indexCategoriesOfJSONStr, new TypeReference<Map<String, List<IndexSecondLevelCategoryVo>>>() {});}/*** @return {@link Map }<{@link String }, {@link List }<{@link IndexSecondLevelCategoryVo }>>* @描述 使用Redisson分布式锁去数据库拿数据并重建缓存* @author Earl* @version 1.0.0* @创建日期 2024/09/02* @since 1.0.0*/public Map<String, List<IndexSecondLevelCategoryVo>> getIndexCategoriesWithDistributedLock(){RLock lock = redissonClient.getLock("index-categories-lock");Map<String, List<IndexSecondLevelCategoryVo>> indexCategoriesFromDb;try{lock.lock();//从数据库查数据并重建缓存indexCategoriesFromDb = getIndexCategoriesFromDb();}finally {lock.unlock();}return indexCategoriesFromDb;}/*** @return {@link Map }<{@link String },{@link List }<{@link IndexSecondLevelCategoryVo }>>* @描述 重数据库重建缓存,方法中首先使用双重检查锁检查缓存是否已经重建,已经重建直接返回缓存数据* @author Earl* @version 1.0.0* @创建日期 2024/09/02* @since 1.0.0*/public Map<String,List<IndexSecondLevelCategoryVo>> getIndexCategoriesFromDb(){//拿到锁以后首先检查缓存是否已经重建,构成双重检查锁String indexCategoriesOfJSONStr = stringRedisTemplate.opsForValue().get("indexCategories");//如果缓存已经重建直接返回不再进行数据库查询操作,不为空拿到缓存解析以后直接返回if(! StringUtils.isEmpty(indexCategoriesOfJSONStr)){return JSON.parseObject(indexCategoriesOfJSONStr, new TypeReference<Map<String, List<IndexSecondLevelCategoryVo>>>() {});}System.out.println("重建缓存"+Thread.currentThread());//如果检查到缓存没有重建就执行数据库查询//1. 查询出所有二三级的商品分类数据List<Long> catLevels = Arrays.asList(2L, 3L);List<CategoryEntity> categories = baseMapper.selectList(new QueryWrapper<CategoryEntity>().in("cat_level",catLevels));//创建Map准备封装返回数据Map<String, List<IndexSecondLevelCategoryVo>> indexCategories=new HashMap<>();//筛出所有二级商品分类并返回以id作为key,二级分类作为value的Map,方便三级分类List集合存入二级分类的子分类列表属性Map<Long,IndexSecondLevelCategoryVo> secondLevelCategories =new HashMap<>();Map<Long,List<IndexSecondLevelCategoryVo.IndexThirdLevelCategoryVo>> thirdLevelCategories =new HashMap<>();for (CategoryEntity category : categories) {if(category.getCatLevel() .equals(2)){IndexSecondLevelCategoryVo secondCategoryVo = new IndexSecondLevelCategoryVo();String categoryPid = category.getParentCid().toString();secondCategoryVo.setCatalog1Id(categoryPid);String categoryId = category.getCatId().toString();secondCategoryVo.setId(categoryId);secondCategoryVo.setName(category.getName());secondLevelCategories.put(category.getCatId(),secondCategoryVo);if(indexCategories.get(categoryPid)==null){indexCategories.put(categoryPid,new ArrayList<>());}indexCategories.get(categoryPid).add(secondCategoryVo);}else{IndexSecondLevelCategoryVo.IndexThirdLevelCategoryVo thirdCategoryVo = new IndexSecondLevelCategoryVo.IndexThirdLevelCategoryVo();Long parentCid = category.getParentCid();thirdCategoryVo.setCatalog2Id(parentCid.toString());thirdCategoryVo.setId(category.getCatId().toString());thirdCategoryVo.setName(category.getName());if(thirdLevelCategories.get(parentCid)==null){thirdLevelCategories.put(parentCid,new ArrayList<>());}thirdLevelCategories.get(parentCid).add(thirdCategoryVo);}}//遍历thirdLevelCategories,将三级分类列表添加到对应的二级分类的对应属性上for(Map.Entry<Long, List<IndexSecondLevelCategoryVo.IndexThirdLevelCategoryVo>> entry : thirdLevelCategories.entrySet()){secondLevelCategories.get(entry.getKey()).setCatalog3List(entry.getValue());}//数据库查询结果封装结束后一定要对重建缓存的操作加锁,否则可能出现重建缓存到建立缓存的过程中,其他线程拿到锁拿不到缓存再次执行数据库查询操作String indexCategoriesOfJsonStr = JSON.toJSONString(indexCategories);//将数据存入缓存中间件stringRedisTemplate.opsForValue().set("indexCategories",indexCategoriesOfJsonStr);return indexCategories;}}
缓存数据一致性
一般用双写模式或者失效模式以及canal订阅binlog日志来解决缓存数据的一致性问题
双写模式
原理图

原理
双写模式就是缓存对应的数据内容在数据库更改以后立马更新一遍缓存,如果数据量比较大比如首页数据,改一个商品就得重新查所有商品分类数据太麻烦,特别是更新操作多会导致缓存频繁重建
失效模式
原理图

原理
失效模式就是更新后的结果写入数据库成功后直接删掉缓存,这样只有等到下一次被查询的时候才会去重建缓存,
canal订阅binlog日志
原理图

原理
Canal是阿里开源的一个中间件,安装canal以后canal会把自己伪装成mysql的一个从服务器,mysql中数据的变化都会同步到canal服务器中
业务代码更新了mysql数据库,mysql数据库开启了binlog二进制日志,binlog日志中就会有mysql每次更新的内容,伪装成从服务器的canal就会通过binlog日志将mysql的每一次更新都同步到canal中,而且可以通过canal改缓存,业务代码中根本不用管缓存更新的问题,缺点是加了一层中间件,而且需要额外开发利用canal实现的自定义功能
canal在大数据场景下还能解决数据异构问题,比如京东首页对用户进行差异化推荐,数据库中存储了用户的浏览记录,购物车的商品记录,用canal同步用户访问记录和对应的商品信息的更新,通过变化的数据做一些计算和分析,得到用户的商品推荐表,商城首页根据直接去从商品推荐表去查询对应的数据即可,甚至都不需要获取完整的商品数据来做计算;数据异构的意思是将不同架构中【比如数据一部分位于java架构中,一部分位于PHP架构中】的数据进行组装,这种方案要加大数据系统才需要考虑
问题分析
双写模式在高并发场景下存在的漏洞
问题:双写模式在高并发更新请求下,由于1号实例先执行完写操作,但是1号实例距离Redis服务器物理距离较远,写缓存的速度慢;2号实例相对后执行完写操作,但是距离Redis服务器物理距离近,有可能2号实例的写缓存操作先完成,此时就是最新数据,但是1号实例马上有将老数据写入缓存直接把2号实例重建的最新缓存覆盖了,相当于缓存中出现了脏数据,后续请求可能拿着脏数据一路狂奔并产生更脏的数据,一般不会,因为进行重要操作还会从数据库拿数据重新校验
解决方案一:对修改操作上锁,一个用户请求写数据库和写缓存操作都结束以后再执行下一个用户请求的写操作
解决方案二:这种是暂时性的脏数据问题,在缓存数据短期不会影响数据库数据的情况下,可以根据业务需求考虑能容忍缓存脏数据的最长时间,更改数据库到最终必须要看到正确的值期间的间隔时间可以有多长,可以把缓存有效期设计地比该时间小,这样在必须看到准确数据前就重建缓存拿到最新修改的数据
失效模式在高并发场景下存在的漏洞
问题:失效模式可能1号实例写数据,写完数据删缓存;2号实例也在写数据,但是可能机器性能差或者任务重,执行慢;1号实例缓存都删完了2号实例还没有执行完写数据库操作;结果此时1号或者3号实例有一个读操作要重建缓存,在查完1号实例的更改结果并发起网络请求准备重建缓存期间,2号实例的删除缓存请求先到达了,结果数据库没数据删除指令已经执行完了,然后更新缓存的指令到了,此时缓存的数据就是1号实例最后更新数据,数据库的数据是2号实例最后更新的数据,出现缓存脏数据问题
解决方案一:为写操作和读取缓存的操作加锁,比如加读写锁
缓存一致性解决方案
无论是双写模式还是失效模式,多实例同时写操作都会导致缓存和数据库的不一致问题,解决方案如下:
缓存一致性问题的解决最终目的是要保证最终一致性,即不能导致实际数据因为缓存的不一致问题而产生脏数据,基本上解决方案就是强一致性加读写锁,大多数情况下通过设置缓存有效期或者使用cannal订阅binlog日志,对一致性要求不高的低频更新数据,不需要考虑缓存一致性的问题
1️⃣:如果是并发写操作几率小的如用户数据、用户订单数据,几秒都干不了一个的写业务操作,不需要考虑缓存不一致的问题,最多加一个缓存过期时间,每隔一段时间自动更新
2️⃣:如果是菜单、商品介绍等基础数据,商家修改了并且实时同步到数据库,但是由于缓存不一致问题,用户可能要等1天、几天才能看到商家更新后的内容不会产生大影响,比如商品介绍的数据,这种数据也不需要考虑缓存不一致问题,如果实在要考虑就使用canal去订阅数据库binlog日志的方式来解决
3️⃣:对于不要求强一致性的缓存数据,可以使用给缓存数据添加合适的过期时间就能解决大部分业务对于缓存一致性的要求
4️⃣:对于实在要保证强一致性的缓存数据,我们可以给读写操作分别加读写锁,保证读读并发,读写互斥、写写互斥
这里商品三级分类数据缓存使用失效模式来处理缓存数据的一致性问题,用分布式读写锁来避免旧数据缓存重建发生在最后一次更新操作写入数据库并删除缓存之后导致脏数据
这种读写锁对于经常读而且经常写的操作对系统性能会造成极大的影响,偶尔写,大量读的操作对系统性能一点影响也没有;写操作期间用户可能会感知到延迟
对于所有缓存中的数据都要用失效模式和读写锁来保证缓存数据一致性太麻烦,Spring针对缓存专门抽象出一个SpringCache来处理缓存
SpringCache
从Spring3.1开始定义了
org.springframework.cache.Cache和org.springframework.cache.CacheManager两个接口来统一不同的缓存技术,Cache接口是来操作增删改查数据的,CacheManager接口是来管理各种各样的缓存的,支持使用JCache[JSR-107]注解通过注解的方式来简化开发,SpringCache属于Spring的部分,不属于SpringBoot官方文档:https://docs.spring.io/spring-framework/docs/5.3.39/reference/html/integration.html#cache
步骤1

步骤2
步骤3

步骤4

配置使用
引入依赖
引入缓存场景启动器
spring-boot-starter-cachexxxxxxxxxx<!--引入缓存相关的场景启动器--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-cache</artifactId></dependency>想要使用Redis作为缓存需要引入redis的场景启动器
spring-boot-starter-data-redis,使用基于netty的lettuce-core做网络通信,吞吐量极大,但是老版本的lettuce-core存在以下问题🔎:netty没有指定堆外内存,会默认使用-Xmx100m作为堆外内存,在并发处理过程中,获取数据的量特别大【比如一次就是69K】,数据在传输、转换过程中都需要占用内存,导致内存分配不足,出现堆外内存溢出问题;当-Xmx调大成1G的时候,发现不会瞬间发生堆外内存溢出,甚至还能测出吞吐量好一会儿以后才会发生该异常;即使将该值调整到很大的值,也只能延迟该堆外内存溢出的情况,但是该异常永远都会出现,根本原因是源码中netty在运行过程中会判断需要使用多少内存,计数一旦超过常量
DIRECT_MEMORY_LIMIT【直接内存限制】就会抛OutOfDirectMemoryError异常,调用操作完以后应该还要调用释放内存的方法并计数释放的内存使用量,但是在操作的过程中没有及时地调用减去已释放内存导致报错堆外内存溢出,直接内存限制使用的是虚拟机运行参数设置-Dio.netty.maxDirectMemory
xxxxxxxxxx<!--redis做缓存操作,搜索RedisAutoConfiguration能找到redis相关配置对应的属性类,所有相关配置都在该属性类中--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId><exclusions><exclusion><groupId>io.lettuce</groupId><artifactId>lettuce-core</artifactId></exclusion></exclusions></dependency><!-- https://mvnrepository.com/artifact/io.lettuce/lettuce-core --><dependency><groupId>io.lettuce</groupId><artifactId>lettuce-core</artifactId><version>5.2.0.RELEASE</version></dependency>配置示例
指定缓存的类型为redis即可
xxxxxxxxxx#指定缓存的类型spring.cache.type=redis#指定缓存的名字,在CacheProperties中的cacheNames属性上有注释说明,缓存名字可以以逗号分隔的list集合来表示,缓存管理器会根据#这里配置的名字来自动创建对应名字的缓存组件,但是在配置文件指定了缓存名字会禁用掉根据代码中自定义的缓存名字自动创建缓存组件的功能,#我们希望一边使用一边生成缓存组件,所以不对该项进行配置#spring.cache.cache-names=#这种方式会指定所有缓存在Redis中的有效时间,不太好,一个是缓存有效时间粒度太大,一个是容易造成缓存雪崩spring.cache.redis.time-to-live=3600000#spring.cache.redis.key-prefix=CACHE_spring.cache.redis.use-key-prefix=true开启缓存功能
在启动类上添加注解
@EnableCaching来开启缓存功能
xxxxxxxxxx("com.earl.mall.product.feign")("com/earl/mall/product/dao")public class MallProductApplication {public static void main(String[] args) {SpringApplication.run(MallProductApplication.class, args);}}
自动配置原理
CacheAutoConfigurationCacheAutoConfiguration在RedisAutoConfiguration后面才会配置,CacheAutoConfiguration根据默认配置文件配置的缓存类型redis来选择RedisCacheConfiguration对缓存进行配置,RedisCacheConfiguration会给容器注入一个RedisCacheManager,缓存管理器RedisCacheManager会按照我们定义的缓存名字调用this.customizerInvoker.customize(builder.build())来帮助用户初始化所有缓存,初始化缓存前会调用方法determineConfiguration(resourceLoader.getClassLoader())决定缓存初始化使用的配置,如果redisCacheConfiguration不为空即有Redis的缓存配置就拿到Redis的缓存配置redisCacheConfiguration,如果没有就使用默认配置,默认的缓存配置都是从RedisProperties中获取的,调用cacheDefaults方法构建RedisCacheManagerBuilder对象准备构造RedisCacheManager组件并根据缓存名字调用initialCacheNames方法来初始化缓存组件,自动配置类中的RedisCacheConfiguration是容器组件,而且只有有参构造方法,初始化org.springframework.boot.autoconfigure.cache.RedisCacheConfiguration时所有的参数都来自于容器组件,对象ObjectProvider<org.springframework.data.redis.cache.RedisCacheConfiguration>从容器中获取我们自定义的org.springframework.data.redis.cache.RedisCacheConfiguration,如果我们没有提供自定义的redisCacheConfiguration组件这里就赋不上值,如果redisCacheConfiguration为空值就会使用默认的redisProperties中的配置,想改缓存的配置需要给容器中添加一个redisCacheConfiguration组件,该配置就会应用到当前RedisCacheManager管理的所有缓存组件[缓存分区]中,注意org.springframework.data.redis.cache.RedisCacheConfiguration不是当前类,当前类是org.springframework.boot.autoconfigure.cache.RedisCacheConfiguration,org.springframework.data.redis.cache.RedisCacheConfiguration中的属性ttl、cacheNullValues、keyPrefix、keySerializationPair、valueSerializationPair分别指定缓存的有效时间、是否缓存空数据、是否加前缀、key的序列化方式和value的序列化方式;如果不指定自定义的RedisCacheConfiguration,会调用defaultCacheConfig()设置默认配置,该方法上的注释指明了默认redis缓存配置,分别为没有指定过期时间、支持缓存空值、缓存的key支持添加前缀、默认前缀为当前缓存的名字、key的序列化器使用的是StringRedisSerializer,value的序列化器使用的JdkSerializationRedisSerializer,涉及到的时间日期格式转化使用的是DefaultFormattingConversionService,如果不使用默认的redis缓存配置,需要我们向容器中自定义一个org.springframework.data.redis.cache.RedisCacheConfiguration容器组件
xxxxxxxxxxspring-boot-starter-cache2.1.8.RELEASE--------------------------------------------------------------------------------------------------(CacheManager.class)(CacheAspectSupport.class)(value = CacheManager.class, name = "cacheResolver")(CacheProperties.class)//配置文件中能配置的缓存相关属性在类CacheProperties中封装({ CouchbaseAutoConfiguration.class, HazelcastAutoConfiguration.class,HibernateJpaAutoConfiguration.class, RedisAutoConfiguration.class })//在Redis开启自动配置以后才开启缓存的自动配置(CacheConfigurationImportSelector.class)public class CacheAutoConfiguration {public CacheManagerCustomizers cacheManagerCustomizers(ObjectProvider<CacheManagerCustomizer<?>> customizers) {return new CacheManagerCustomizers(customizers.orderedStream().collect(Collectors.toList()));}public CacheManagerValidator cacheAutoConfigurationValidator(CacheProperties cacheProperties,ObjectProvider<CacheManager> cacheManager) {return new CacheManagerValidator(cacheProperties, cacheManager);}(LocalContainerEntityManagerFactoryBean.class)(AbstractEntityManagerFactoryBean.class)protected static class CacheManagerJpaDependencyConfiguration extends EntityManagerFactoryDependsOnPostProcessor {public CacheManagerJpaDependencyConfiguration() {super("cacheManager");}}/*** Bean used to validate that a CacheManager exists and provide a more meaningful* exception.*/static class CacheManagerValidator implements InitializingBean {private final CacheProperties cacheProperties;private final ObjectProvider<CacheManager> cacheManager;CacheManagerValidator(CacheProperties cacheProperties, ObjectProvider<CacheManager> cacheManager) {this.cacheProperties = cacheProperties;this.cacheManager = cacheManager;}public void afterPropertiesSet() {Assert.notNull(this.cacheManager.getIfAvailable(),() -> "No cache manager could " + "be auto-configured, check your configuration (caching "+ "type is '" + this.cacheProperties.getType() + "')");}}/*** {@link ImportSelector} to add {@link CacheType} configuration classes.*///使用CacheConfigurationImportSelector这个选择器又导入了很多缓存相关配置static class CacheConfigurationImportSelector implements ImportSelector {public String[] selectImports(AnnotationMetadata importingClassMetadata) {CacheType[] types = CacheType.values();String[] imports = new String[types.length];for (int i = 0; i < types.length; i++) {imports[i] = CacheConfigurations.getConfigurationClass(types[i]);//1️⃣ 从CacheConfigurations缓存配置类中根据缓存类型得到每一种缓存的配置,Redis类型的缓存从MAPPINGS中根据CacheType.REDIS获取到RedisCacheConfiguration.class。用户在默认配置文件中指明了缓存类型为redis就会导入跟Redis相关的缓存配置类RedisCacheConfiguration.class}return imports;}}}final class CacheConfigurations {//MAPPING在静态代码块中初始化,导入CacheType.REDIS对应导入的是RedisCacheConfiguration.classprivate static final Map<CacheType, Class<?>> MAPPINGS;static {Map<CacheType, Class<?>> mappings = new EnumMap<>(CacheType.class);mappings.put(CacheType.GENERIC, GenericCacheConfiguration.class);mappings.put(CacheType.EHCACHE, EhCacheCacheConfiguration.class);mappings.put(CacheType.HAZELCAST, HazelcastCacheConfiguration.class);mappings.put(CacheType.INFINISPAN, InfinispanCacheConfiguration.class);mappings.put(CacheType.JCACHE, JCacheCacheConfiguration.class);mappings.put(CacheType.COUCHBASE, CouchbaseCacheConfiguration.class);mappings.put(CacheType.REDIS, RedisCacheConfiguration.class);2️⃣ //根据CacheType.REDIS类型获取到Redis缓存的具体配置RedisCacheConfiguration.classmappings.put(CacheType.CAFFEINE, CaffeineCacheConfiguration.class);mappings.put(CacheType.SIMPLE, SimpleCacheConfiguration.class);mappings.put(CacheType.NONE, NoOpCacheConfiguration.class);MAPPINGS = Collections.unmodifiableMap(mappings);}private CacheConfigurations() {}1️⃣ cacheConfigurations.getConfigurationClass(types[i])//根据缓存的类型从MAPPING属性中获取每一种缓存public static String getConfigurationClass(CacheType cacheType) {Class<?> configurationClass = MAPPINGS.get(cacheType);Assert.state(configurationClass != null, () -> "Unknown cache type " + cacheType);return configurationClass.getName();}public static CacheType getType(String configurationClassName) {for (Map.Entry<CacheType, Class<?>> entry : MAPPINGS.entrySet()) {if (entry.getValue().getName().equals(configurationClassName)) {return entry.getKey();}}throw new IllegalStateException("Unknown configuration class " + configurationClassName);}}2️⃣ RedisCacheConfiguration中做的配置(RedisConnectionFactory.class)(RedisAutoConfiguration.class)(RedisConnectionFactory.class)(CacheManager.class)(CacheCondition.class)class RedisCacheConfiguration {private final CacheProperties cacheProperties;private final CacheManagerCustomizers customizerInvoker;private final org.springframework.data.redis.cache.RedisCacheConfiguration redisCacheConfiguration;RedisCacheConfiguration(CacheProperties cacheProperties, CacheManagerCustomizers customizerInvoker,ObjectProvider<org.springframework.data.redis.cache.RedisCacheConfiguration> redisCacheConfiguration) {this.cacheProperties = cacheProperties;this.customizerInvoker = customizerInvoker;this.redisCacheConfiguration = redisCacheConfiguration.getIfAvailable();}//对象ObjectProvider<org.springframework.data.redis.cache.RedisCacheConfiguration>从容器中获取我们自定义的redisCacheConfiguration,如果我们没有提供自定义的redisCacheConfiguration组件这里就赋不上值,如果redisCacheConfiguration为空值就会使用默认的redisProperties中的配置,想改缓存的配置需要给容器中添加一个redisCacheConfiguration组件,该配置就会应用到当前RedisCacheManager管理的所有缓存组件[缓存分区]中,注意org.springframework.data.redis.cache.RedisCacheConfiguration不是当前类,当前类是org.springframework.boot.autoconfigure.cache.RedisCacheConfiguration,org.springframework.data.redis.cache.RedisCacheConfiguration中的属性ttl、cacheNullValues、keyPrefix、keySerializationPair、valueSerializationPair分别指定缓存的有效时间、是否缓存空数据、是否加前缀、key的序列化方式和value的序列化方式;如果不指定自定义的RedisCacheConfiguration,会调用defaultCacheConfig()设置默认配置,该方法上的注释指明了默认redis缓存配置,分别为没有指定过期时间、支持缓存空值、缓存的key支持添加前缀、默认前缀为当前缓存的名字、key的序列化器使用的是StringRedisSerializer,value的序列化器使用的JdkSerializationRedisSerializer,涉及到的时间日期格式转化使用的是DefaultFormattingConversionService,如果不使用默认的redis缓存配置,需要我们向容器中自定义一个容器组件//给容器中放入了一个缓存管理器组件public RedisCacheManager cacheManager(RedisConnectionFactory redisConnectionFactory,ResourceLoader resourceLoader) {RedisCacheManagerBuilder builder = RedisCacheManager.builder(redisConnectionFactory).cacheDefaults(determineConfiguration(resourceLoader.getClassLoader()));//初始化缓存前会调用方法`determineConfiguration(resourceLoader.getClassLoader())`决定缓存初始化使用的配置,拿到Redis的缓存配置redisCacheConfiguration,调用cacheDefaults方法构建RedisCacheManagerBuilder对象准备构造RedisCacheManager组件List<String> cacheNames = this.cacheProperties.getCacheNames();if (!cacheNames.isEmpty()) {builder.initialCacheNames(new LinkedHashSet<>(cacheNames));2️⃣-1️⃣ //根据缓存名字调用initialCacheNames来初始化缓存组件}return this.customizerInvoker.customize(builder.build());}private org.springframework.data.redis.cache.RedisCacheConfiguration determineConfiguration(ClassLoader classLoader) {if (this.redisCacheConfiguration != null) {return this.redisCacheConfiguration;//如果redisCacheConfiguration不为空即有Redis的缓存配置就拿到Redis的缓存配置redisCacheConfiguration,如果没有就使用默认配置}Redis redisProperties = this.cacheProperties.getRedis();org.springframework.data.redis.cache.RedisCacheConfiguration config = org.springframework.data.redis.cache.RedisCacheConfiguration.defaultCacheConfig();//如果不指定自定义的RedisCacheConfiguration,会调用defaultCacheConfig()设置默认配置config = config.serializeValuesWith(SerializationPair.fromSerializer(new JdkSerializationRedisSerializer(classLoader)));//序列化机制使用JDK默认的序列化if (redisProperties.getTimeToLive() != null) {config = config.entryTtl(redisProperties.getTimeToLive());//从redisProperties中得到ttl过期时间,说实话,讲的一坨,唉;redisProperties是从当前类的cacheProperties属性中获取的,}if (redisProperties.getKeyPrefix() != null) {//每一个缓存的key有没有前缀config = config.prefixKeysWith(redisProperties.getKeyPrefix());}if (!redisProperties.isCacheNullValues()) {//是否缓存空数据config = config.disableCachingNullValues();}if (!redisProperties.isUseKeyPrefix()) {//是否使用缓存的前缀config = config.disableKeyPrefix();}return config;}//通过配置我们自己定义的`RedisCacheConfiguration`,会在`org.springframework.boot.autoconfigure.cache.RedisCacheConfiguration`中的`determineConfiguration(ClassLoader classLoader)`方法中取消用`cacheProperties`中的配置修改`org.springframework.data.redis.cache.RedisCacheConfiguration`中的对应属性,因此我们所有配置在默认配置文件中的属性都会失效<font color=green>**[比如我们在默认配置文件配置的缓存有效时间]**</font>,因为在执行自动配置时发现我们自己配置了`RedisCacheConfiguration`,就会直接返回我们配置的组件,不会再继续执行`cacheProperties`的配置属性赋值操作了;因此使用自定义`RedisCacheConfiguration`组件还需要将配置文件中的所有`Redis`缓存相关配置都配置到该组件中,可以参考`org.springframework.boot.autoconfigure.cache.RedisCacheConfiguration`中的`determineConfiguration(ClassLoader classLoader)`方法中的配置方式,这样我们仍然能通过配置文件指定对应的属性,缓存相关的配置类只是标注了注解`@ConfigurationProperties(prefix="spring.cache")`该注解只是声明该配置类和默认配置文件中以`spring.cache`为前缀的配置进行属性绑定,但是并没有将该配置类放入容器中,需要在配置使用类上标注`@EnableConfigurationProperties(CacheProperties.class)`导入该配置类,使用了该注解就能在配置使用类中通过`@Autowired`注解将配置类进行注入,此外给容器注入组件的方法的所有传参都会自动使用容器组件,因此我们不需要再使用`@Autowired`注解进行注入,直接给方法传参对应类型的组件即可,这就是完全模仿`org.springframework.boot.autoconfigure.cache.RedisCacheConfiguration`中的`determineConfiguration(ClassLoader classLoader)`方法做的配置}2️⃣-1️⃣ redisCacheManager.initialCacheNames(new LinkedHashSet<>(cacheNames))public RedisCacheManagerBuilder initialCacheNames(Set<String> cacheNames) {Assert.notNull(cacheNames, "CacheNames must not be null!");Map<String, RedisCacheConfiguration> cacheConfigMap = new LinkedHashMap<>(cacheNames.size());cacheNames.forEach(it -> cacheConfigMap.put(it, defaultCacheConfiguration));//对缓存名字进行遍历,将每个缓存名和默认缓存配置对应起来存入LinkedHashMap<String, RedisCacheConfiguration>类型的cacheConfigMapreturn withInitialCacheConfigurations(cacheConfigMap);2️⃣-1️⃣-1️⃣ //利用这个使用了默认配置的cacheConfigMap来初始化缓存}2️⃣-1️⃣-1️⃣ redisCacheManager.redisCacheManagerBuilder.withInitialCacheConfigurations(cacheConfigMap)public RedisCacheManagerBuilder withInitialCacheConfigurations(Map<String, RedisCacheConfiguration> cacheConfigurations) {Assert.notNull(cacheConfigurations, "CacheConfigurations must not be null!");cacheConfigurations.forEach((cacheName, configuration) -> Assert.notNull(configuration,String.format("RedisCacheConfiguration for cache %s must not be null!", cacheName)));this.initialCaches.putAll(cacheConfigurations);//将cacheConfigMap存入LinkedHashMap<String, RedisCacheConfiguration>中return this;}org.springframework.data.redis.cache.RedisCacheConfigurationxxxxxxxxxxspring-boot-starter-data-redis2.1.10RELEASED--------------------------------------------------------------------------------------------------public class RedisCacheConfiguration {//通过自定义组件指定以下属性的方式可以自定义配置基于Redis的缓存过期时间、是否缓存空值、是否加前缀、key和value分别采用哪种序列化方式,如果不指定就会在org.springframework.boot.autoconfigure.cache.RedisCacheConfiguration的determineConfiguration方法中使用这个类的defaultCacheConfig()方法private final Duration ttl;private final boolean cacheNullValues;private final CacheKeyPrefix keyPrefix;private final boolean usePrefix;private final SerializationPair<String> keySerializationPair;private final SerializationPair<Object> valueSerializationPair;private final ConversionService conversionService;("unchecked")private RedisCacheConfiguration(Duration ttl, Boolean cacheNullValues, Boolean usePrefix, CacheKeyPrefix keyPrefix,SerializationPair<String> keySerializationPair, SerializationPair<?> valueSerializationPair,ConversionService conversionService) {this.ttl = ttl;this.cacheNullValues = cacheNullValues;this.usePrefix = usePrefix;this.keyPrefix = keyPrefix;this.keySerializationPair = keySerializationPair;this.valueSerializationPair = (SerializationPair<Object>) valueSerializationPair;this.conversionService = conversionService;}/*** Default {@link RedisCacheConfiguration} using the following:* <dl>* <dt>key expiration</dt>* <dd>eternal</dd>* <dt>cache null values</dt>* <dd>yes</dd>* <dt>prefix cache keys</dt>* <dd>yes</dd>* <dt>default prefix</dt>* <dd>[the actual cache name]</dd>* <dt>key serializer</dt>* <dd>{@link org.springframework.data.redis.serializer.StringRedisSerializer}</dd>* <dt>value serializer</dt>* <dd>{@link org.springframework.data.redis.serializer.JdkSerializationRedisSerializer}</dd>* <dt>conversion service</dt>* <dd>{@link DefaultFormattingConversionService} with {@link #registerDefaultConverters(ConverterRegistry) default}* cache key converters</dd>* </dl>** @return new {@link RedisCacheConfiguration}.* 该方法上的注释指明了默认redis缓存配置,分别为没有指定过期时间、支持缓存空值、缓存的key支持添加前缀、默认前缀为当前缓存的名字、key的序列化器使用的是StringRedisSerializer,value的序列化器使用的JdkSerializationRedisSerializer,涉及到的时间日期格式转化使用的是DefaultFormattingConversionService*/public static RedisCacheConfiguration defaultCacheConfig() {return defaultCacheConfig(null);}//defaultCacheConfig()方法的返回值还是RedisCacheConfiguration,而且更改其中配置的entryTtl(Duration ttl)方法的返回值还是RedisCacheConfiguration,说明我们可以通过链式调用的方式来更改RedisCacheConfiguration组件的属性配置,但是通过entryTtl(Duration ttl)方法我们可以发现,RedisCacheConfiguration更改配置的方式是将我们的目标值替换对应属性的旧值并以对应属性的新值和调用修改方法的原对象的属性旧值作为参数再构造一个全新的对象进行返回,因此我们可以先通过静态defaultCacheConfig()创建出一个默认配置的RedisCacheConfiguration对象,在默认配置的基础上调用serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(new StringRedisSerializer()))更改key的序列化方式为Redis的序列化器StringRedisSerializer(),调用serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(new GenericJackson2JsonRedisSerializer()))来更改value的序列化方式使用Spring提供的基于Jackson的乐意将任意类型对象转换成json格式字符串的序列化器[这里key一般都是指定字符串,所以使用StringRedisSerializer将字符串转换成json格式即可,但是value一般都是各种各样的对象,因此需要使用Generic标识的json格式序列化器,该序列化器在转换过程中还会添加一个@Class属性指定json对象对应的全限定类名],org.springframework.boot.autoconfigure.cache.RedisCacheConfiguration的determineConfiguration方法中也是通过这种方式将默认配置修改为redisProperties中的对应属性配置/*** Create default {@link RedisCacheConfiguration} given {@link ClassLoader} using the following:* <dl>* <dt>key expiration</dt>* <dd>eternal</dd>* <dt>cache null values</dt>* <dd>yes</dd>* <dt>prefix cache keys</dt>* <dd>yes</dd>* <dt>default prefix</dt>* <dd>[the actual cache name]</dd>* <dt>key serializer</dt>* <dd>{@link org.springframework.data.redis.serializer.StringRedisSerializer}</dd>* <dt>value serializer</dt>* <dd>{@link org.springframework.data.redis.serializer.JdkSerializationRedisSerializer}</dd>* <dt>conversion service</dt>* <dd>{@link DefaultFormattingConversionService} with {@link #registerDefaultConverters(ConverterRegistry) default}* cache key converters</dd>* </dl>** @param classLoader the {@link ClassLoader} used for deserialization by the* {@link org.springframework.data.redis.serializer.JdkSerializationRedisSerializer}.* @return new {@link RedisCacheConfiguration}.* @since 2.1*/public static RedisCacheConfiguration defaultCacheConfig( ClassLoader classLoader) {DefaultFormattingConversionService conversionService = new DefaultFormattingConversionService();registerDefaultConverters(conversionService);return new RedisCacheConfiguration(Duration.ZERO, true, true, CacheKeyPrefix.simple(),SerializationPair.fromSerializer(RedisSerializer.string()),SerializationPair.fromSerializer(RedisSerializer.java(classLoader)), conversionService);}/*** Set the ttl to apply for cache entries. Use {@link Duration#ZERO} to declare an eternal cache.** @param ttl must not be {@literal null}.* @return new {@link RedisCacheConfiguration}.*/public RedisCacheConfiguration entryTtl(Duration ttl) {Assert.notNull(ttl, "TTL duration must not be null!");return new RedisCacheConfiguration(ttl, cacheNullValues, usePrefix, keyPrefix, keySerializationPair,valueSerializationPair, conversionService);}/*** Use the given prefix instead of the default one.** @param prefix must not be {@literal null}.* @return new {@link RedisCacheConfiguration}.*/public RedisCacheConfiguration prefixKeysWith(String prefix) {Assert.notNull(prefix, "Prefix must not be null!");return computePrefixWith((cacheName) -> prefix);}/*** Use the given {@link CacheKeyPrefix} to compute the prefix for the actual Redis {@literal key} on the* {@literal cache name}.** @param cacheKeyPrefix must not be {@literal null}.* @return new {@link RedisCacheConfiguration}.* @since 2.0.4*/public RedisCacheConfiguration computePrefixWith(CacheKeyPrefix cacheKeyPrefix) {Assert.notNull(cacheKeyPrefix, "Function for computing prefix must not be null!");return new RedisCacheConfiguration(ttl, cacheNullValues, true, cacheKeyPrefix, keySerializationPair,valueSerializationPair, conversionService);}/*** Disable caching {@literal null} values. <br />* <strong>NOTE</strong> any {@link org.springframework.cache.Cache#put(Object, Object)} operation involving* {@literal null} value will error. Nothing will be written to Redis, nothing will be removed. An already existing* key will still be there afterwards with the very same value as before.** @return new {@link RedisCacheConfiguration}.*/public RedisCacheConfiguration disableCachingNullValues() {return new RedisCacheConfiguration(ttl, false, usePrefix, keyPrefix, keySerializationPair, valueSerializationPair,conversionService);}/*** Disable using cache key prefixes. <br />* <strong>NOTE</strong>: {@link Cache#clear()} might result in unintended removal of {@literal key}s in Redis. Make* sure to use a dedicated Redis instance when disabling prefixes.** @return new {@link RedisCacheConfiguration}.*/public RedisCacheConfiguration disableKeyPrefix() {return new RedisCacheConfiguration(ttl, cacheNullValues, false, keyPrefix, keySerializationPair,valueSerializationPair, conversionService);}/*** Define the {@link ConversionService} used for cache key to {@link String} conversion.** @param conversionService must not be {@literal null}.* @return new {@link RedisCacheConfiguration}.*/public RedisCacheConfiguration withConversionService(ConversionService conversionService) {Assert.notNull(conversionService, "ConversionService must not be null!");return new RedisCacheConfiguration(ttl, cacheNullValues, usePrefix, keyPrefix, keySerializationPair,valueSerializationPair, conversionService);}/*** Define the {@link SerializationPair} used for de-/serializing cache keys.** @param keySerializationPair must not be {@literal null}.* @return new {@link RedisCacheConfiguration}.*/public RedisCacheConfiguration serializeKeysWith(SerializationPair<String> keySerializationPair) {Assert.notNull(keySerializationPair, "KeySerializationPair must not be null!");return new RedisCacheConfiguration(ttl, cacheNullValues, usePrefix, keyPrefix, keySerializationPair,valueSerializationPair, conversionService);}/*** Define the {@link SerializationPair} used for de-/serializing cache values.** @param valueSerializationPair must not be {@literal null}.* @return new {@link RedisCacheConfiguration}.*/public RedisCacheConfiguration serializeValuesWith(SerializationPair<?> valueSerializationPair) {Assert.notNull(valueSerializationPair, "ValueSerializationPair must not be null!");return new RedisCacheConfiguration(ttl, cacheNullValues, usePrefix, keyPrefix, keySerializationPair,valueSerializationPair, conversionService);}/*** @return never {@literal null}.* @deprecated since 2.0.4. Please use {@link #getKeyPrefixFor(String)}.*/public Optional<String> getKeyPrefix() {return usePrefix() ? Optional.of(keyPrefix.compute("")) : Optional.empty();}/*** Get the computed {@literal key} prefix for a given {@literal cacheName}.** @return never {@literal null}.* @since 2.0.4*/public String getKeyPrefixFor(String cacheName) {Assert.notNull(cacheName, "Cache name must not be null!");return keyPrefix.compute(cacheName);}/*** @return {@literal true} if cache keys need to be prefixed with the {@link #getKeyPrefixFor(String)} if present or* the default which resolves to {@link Cache#getName()}.*/public boolean usePrefix() {return usePrefix;}/*** @return {@literal true} if caching {@literal null} is allowed.*/public boolean getAllowCacheNullValues() {return cacheNullValues;}/*** @return never {@literal null}.*/public SerializationPair<String> getKeySerializationPair() {return keySerializationPair;}/*** @return never {@literal null}.*/public SerializationPair<Object> getValueSerializationPair() {return valueSerializationPair;}/*** @return The expiration time (ttl) for cache entries. Never {@literal null}.*/public Duration getTtl() {return ttl;}/*** @return The {@link ConversionService} used for cache key to {@link String} conversion. Never {@literal null}.*/public ConversionService getConversionService() {return conversionService;}/*** Registers default cache key converters. The following converters get registered:* <ul>* <li>{@link String} to {@link byte byte[]} using UTF-8 encoding.</li>* <li>{@link SimpleKey} to {@link String}</li>** @param registry must not be {@literal null}.*/public static void registerDefaultConverters(ConverterRegistry registry) {Assert.notNull(registry, "ConverterRegistry must not be null!");registry.addConverter(String.class, byte[].class, source -> source.getBytes(StandardCharsets.UTF_8));registry.addConverter(SimpleKey.class, String.class, SimpleKey::toString);}}自定义组件
org.springframework.data.redis.cache.RedisCacheConfigurationorg.springframework.data.redis.cache.RedisCacheConfiguration的defaultCacheConfig()方法的返回值还是RedisCacheConfiguration,而且更改其中配置的entryTtl(Duration ttl)方法的返回值还是RedisCacheConfiguration,说明我们可以通过链式调用的方式来更改RedisCacheConfiguration组件的属性配置,但是通过entryTtl(Duration ttl)方法我们可以发现,RedisCacheConfiguration更改配置的方式是将我们的目标值替换对应属性的旧值并以对应属性的新值和调用修改方法的原对象的属性旧值作为参数再构造一个全新的对象进行返回,因此我们可以先通过静态defaultCacheConfig()创建出一个默认配置的RedisCacheConfiguration对象,在默认配置的基础上调用serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(new StringRedisSerializer()))更改key的序列化方式为Redis的序列化器StringRedisSerializer(),调用serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(new GenericJackson2JsonRedisSerializer()))来更改value的序列化方式使用Spring提供的基于Jackson的乐意将任意类型对象转换成json格式字符串的序列化器[这里key一般都是指定字符串,所以使用StringRedisSerializer将字符串转换成json格式即可,但是value一般都是各种各样的对象,因此需要使用Generic标识的json格式序列化器,该序列化器在转换过程中还会添加一个@Class属性指定json对象对应的全限定类名],org.springframework.boot.autoconfigure.cache.RedisCacheConfiguration的determineConfiguration方法中也是通过这种方式将默认配置修改为redisProperties中的对应属性配置构造
Redis的序列化器需要通过方法RedisSerializationContext.SerializationPair.fromSerializer(new StringRedisSerializer())传参对应的Redis的序列化器RedisSerializer,接口RedisSerializer的直接实现类有十个,实现类中名字带Json的都是和json有关的序列化器,其中的GenericFastJsonRedisSerializer这种带Generic的实现类实现的是RedisSerializer<Object>支持转换任意类型的对象,该对象使用的是fastjson,如果系统中引入了fastjson就可以使用该序列化器,如果系统中没有引入就使用Spring提供的org.springframework.data.redis.serializer.GenericJackson2JsonRedisSerializer,这两个序列化器效果都是一样的通过配置我们自己定义的
RedisCacheConfiguration,会在org.springframework.boot.autoconfigure.cache.RedisCacheConfiguration中的determineConfiguration(ClassLoader classLoader)方法中取消用cacheProperties中的配置修改org.springframework.data.redis.cache.RedisCacheConfiguration中的对应属性,因此我们所有配置在默认配置文件中的属性都会失效[比如我们在默认配置文件配置的缓存有效时间],因为在执行自动配置时发现我们自己配置了RedisCacheConfiguration,就会直接返回我们配置的组件,不会再继续执行cacheProperties的配置属性赋值操作了;因此使用自定义RedisCacheConfiguration组件还需要将配置文件中的所有Redis缓存相关配置都配置到该组件中,可以参考org.springframework.boot.autoconfigure.cache.RedisCacheConfiguration中的determineConfiguration(ClassLoader classLoader)方法中的配置方式,这样我们仍然能通过配置文件指定对应的属性,缓存相关的配置类只是标注了注解@ConfigurationProperties(prefix="spring.cache")该注解只是声明该配置类和默认配置文件中以spring.cache为前缀的配置进行属性绑定,但是并没有将该配置类放入容器中,需要在配置使用类上标注@EnableConfigurationProperties(CacheProperties.class)导入该配置类,使用了该注解就能在配置使用类中通过@Autowired注解将配置类进行注入,此外给容器注入组件的方法的所有传参都会自动使用容器组件,因此我们不需要再使用@Autowired注解进行注入,直接给方法传参对应类型的组件即可,这就是完全模仿org.springframework.boot.autoconfigure.cache.RedisCacheConfiguration中的determineConfiguration(ClassLoader classLoader)方法做的配置,配置示例如下例代码所示❓:在
org.springframework.boot.autoconfigure.cache.RedisCacheConfiguration中也使用了cacheProerties,但是并没有使用下例所示的@EnableConfigurationProperties(CacheProperties.class)注解,而是使用了@Conditional(CacheCondition.class)注解,对应的配置类是通过该组件的构造方法传递进去的,思考以下@Conditional(CacheCondition.class)注解的作用,并思考能否采用这种方式来获取配置类
使用其他缓存媒介也可以通过上述方法来自定义对应的缓存规则
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 自定义缓存配置,该配置会自动在使用SpringCache相关功能时自动生效* @创建日期 2024/09/03* @since 1.0.0*/(CacheProperties.class)public class CustomCacheConfig {RedisCacheConfiguration redisCacheConfiguration(CacheProperties cacheProperties){RedisCacheConfiguration config = RedisCacheConfiguration.defaultCacheConfig();config = config.serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(new StringRedisSerializer())).serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(new GenericJackson2JsonRedisSerializer()));//下面完全是模仿`org.springframework.boot.autoconfigure.cache.RedisCacheConfiguration`的`determineConfiguration`方法CacheProperties.Redis redisProperties = cacheProperties.getRedis();if (redisProperties.getTimeToLive() != null) {config = config.entryTtl(redisProperties.getTimeToLive());}if (redisProperties.getKeyPrefix() != null) {config = config.prefixKeysWith(redisProperties.getKeyPrefix());}if (!redisProperties.isCacheNullValues()) {config = config.disableCachingNullValues();}if (!redisProperties.isUseKeyPrefix()) {config = config.disableKeyPrefix();}return config;}}
相关注解
使用
SpringCache提供的以下几个注解@Cacheable,@CacheEvict,@CachePut,@Caching,@CacheConfig就能完成日常开发中缓存的大部分功能
@Cacheable:Triggers cache population.触发将数据保存到缓存的操作,标注在方法上表示当前方法的结果需要缓存;而且如果方法的返回结果在缓存中有,方法都不需要调用;如果缓存中没有,就会调用被标注的方法获取缓存并将结果进行缓存🔎:这种方式适用于读模式下添加缓存,存储同一种业务类型的数据,我们都将缓存指定为同一个分区,比如不管是一级商品分类数据还是全部商品分类数据,我们都划分为同一个缓存分区,这样就能方便地修改一个相关数据就能一下清除掉整个缓存分区
注意使用该注解重建缓存只需要加分布式锁
缓存数据建议按照业务类型来对缓存数据进行分区,该注解的
value属性和cacheNames属性互为别名,属性的数据类型均为String[],表示可以给一个或者多个缓存组件同时放入一份被标注方法的返回值,在Redis中缓存的key为Cache自动生成的category::SimpleKey []即缓存的名字::SimpleKey [];其中的缓存数据因为使用的是JDK的序列化方式,Redis客户端直接读取出来全是二进制码,但是读取到java客户端以后被反序列化以后就可以变成正常的字符串信息,示例如下:注意啊这种方式设置的缓存,默认是不设置有效时间的,即
ttl=-1,意味着缓存永远不会过期,这大部分情况下是不可接受的key也是系统默认自己生成而不是用户指定的,我们更希望这个key能由我们自己进行指定
使用默认的JDK来序列化缓存数据,不符合互联网数据大多以json形式交互的规范,如果一个PHP架构的异构系统想要获取缓存数据如果是经过JDK序列化就可能导致和异构系统不兼容,因此我们更希望使用json格式的缓存数据
xxxxxxxxxx({"category","product"})//将该方法的返回值同时给category和product缓存组件中各放入一份public List<CategoryEntity> getAllFirstLevelCategory() {List<CategoryEntity> firstLevelCategories = baseMapper.selectList(new QueryWrapper<CategoryEntity>().eq("cat_level", 1));return firstLevelCategories;}存在问题分析
通过
@Cacheable注解的key属性,该属性的注释上标注了key属性值接受一个Spring Expression Language[SpEL表达式],意思是这个key可以不写死,可以通过#root.methodName获取当前的方法名作为key、#root.args[1]获取参数列表中的参数值来作为key等等缓存的过期时间无法通过该注解的属性指定,但是可以在SpringBoot默认配置文件中通过
spring.cache.redis.time-to-live=3600000指定以毫秒为单位的过期时间,这里是指定缓存的过期时间为一个小时,不过这种方式很容易导致缓存雪崩除了以上介绍还可以通过属性
keyGenerator指定一个key的生成器、通过属性cacheManager指定缓存管理器、通过属性condition()还能指定添加缓存的条件[接受一个SpEL表达式]、通过属性unless指定在除非满足指定条件下才将方法返回值添加缓存、通过属性sync指定通过同步的方式添加缓存[使用同步的方式unless属性就无法使用]SpEL表达式:
Location是定位使用的根对象
Name Location Description Example methodNameRoot object 使用方法名作为SpEl表达式 #root.methodNamemethodRoot object 使用方法名作为SpEl表达式 #root.method.nametargetRoot object The target object being invoked #root.targettargetClassRoot object The class of the target being invoked #root.targetClassargsRoot object 按顺序取出所有的参数,使用下标索引来获取指定的参数 #root.args[0]cachesRoot object 当前方法配置的value属性的第一个缓存组件名字 #root.caches[0].nameArgument name Evaluation context Name of any of the method arguments. If the names are not available (perhaps due to having no debug information), the argument names are also available under the #a<#arg>where#argstands for the argument index (starting from0).#ibanor#a0(you can also use#p0or#p<#arg>notation as an alias).resultEvaluation context The result of the method call (the value to be cached). Only available in unlessexpressions,cache putexpressions (to compute thekey), orcache evictexpressions (whenbeforeInvocationisfalse). For supported wrappers (such asOptional),#resultrefers to the actual object, not the wrapper.#result表达式中使用字符串需要使用单引号括起来
【指定key的代码示例】
xxxxxxxxxx(value = {"category"},key="#root.method.name")public List<CategoryEntity> getAllFirstLevelCategory() {List<CategoryEntity> firstLevelCategories = baseMapper.selectList(new QueryWrapper<CategoryEntity>().eq("cat_level", 1));return firstLevelCategories;}【指定过期时间的配置示例】
xxxxxxxxxx#这种方式会指定所有缓存在Redis中的有效时间,不太好,一个是缓存有效时间粒度太大,一个是容易造成缓存雪崩spring.cache.redis.time-to-live=3600000【指定缓存的key前缀】
实际开发中更推荐使用缓存分区的名字作为缓存key的前缀,即不再指定
spring.cache.redis.key-prefix=CACHE_,使用默认的前缀配置,同时不要禁用使用key的前缀,这样做的好处是以缓存分区的名字作为前缀会在Redis中以缓存分区名字作为根目录,在根目录下跟完整key的缓存键值对,这样看起来分区逻辑更明了【自定义key前缀的缓存数据结构】
【默认缓存分区名字作为key前缀的缓存数据结构】

xxxxxxxxxx#在缓存的key前面加上一个前缀来作为某种标识,这里使用CACHE_前缀标识以CACHE_开头的键值对都是缓存,注意这个key指定了前缀是以我们`指定的前缀`+`_`+`指定的key`作为缓存的key,此时前缀会取代默认的缓存分区名字,缓存的key就不会再自动以缓存分区名字作为key的前缀了spring.cache.redis.key-prefix=CACHE_#该配置表示是否开启对key前缀配置的使用,默认值是true,如果不想使用前缀可以指定false来禁用掉,如果禁用掉前缀连默认的以缓存分区名字作为前缀都会被禁用掉,用户在@Cacheable注解中指定的key是什么样对应缓存的key就是一模一样的spring.cache.redis.use-key-prefix=true【指定是否缓存空值】
xxxxxxxxxx#指定是否缓存空值,默认也是true,对于缓存穿透问题要求我们对不存在的结果进行空值缓存,这样能防止恶意请求对不存在的数据进行高频直接访问数据库来达到攻击数据库的目的,因此一般都要开启空值缓存,这样当使用SpringCache的相关注解功能时,如果查询到结果为null,也会将对应的空值缓存到缓存媒介中,缓存空值会使用一个NullValue对象来封装空值,缓存中能看到NullValue的全限定类名spring.cache.redis.cache-null-values=true将数据保存为json格式就比较麻烦了,牵涉到自定义缓存管理器
原理见下面的自动配置说明,并结合谷粒商城项目的
P167-P170来进行理解,这一块讲的很妙啊,应该多次回味,市面上很少有SpringCache的相关教程
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 自定义缓存配置,该配置会自动在使用SpringCache相关功能时自动生效* @创建日期 2024/09/03* @since 1.0.0*/(CacheProperties.class)public class CustomCacheConfig {RedisCacheConfiguration redisCacheConfiguration(CacheProperties cacheProperties){RedisCacheConfiguration config = RedisCacheConfiguration.defaultCacheConfig();config = config.serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(new StringRedisSerializer())).serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(new GenericJackson2JsonRedisSerializer()));//下面完全是模仿`org.springframework.boot.autoconfigure.cache.RedisCacheConfiguration`的`determineConfiguration`方法CacheProperties.Redis redisProperties = cacheProperties.getRedis();if (redisProperties.getTimeToLive() != null) {config = config.entryTtl(redisProperties.getTimeToLive());}if (redisProperties.getKeyPrefix() != null) {config = config.prefixKeysWith(redisProperties.getKeyPrefix());}if (!redisProperties.isCacheNullValues()) {config = config.disableCachingNullValues();}if (!redisProperties.isUseKeyPrefix()) {config = config.disableKeyPrefix();}return config;}}
@CacheEvict:Triggers cache eviction.触发将数据从缓存中删除的操作,只是在调用方法以后删除指定键值对的缓存,下次对相关数据进行读操作时会由对应的读数据方法重建缓存🔎:这种方式适用于在写数据库的情况下使用失效模式在写数据库以后清空对应的缓存
通过注解
@CacheEvict的value属性能指定要清空缓存所在的缓存分区,通过key属性指定要清空的目标缓存的key,value属性都是String类型的参数值,key属性值需要填入SpEl表达式,如果key属性值不是SpEL表达式正常情况下项目启动控制台就会报错说取不出该属性值[不加单引号表示字符串的都会被认为是动态取值],但是编译不会报错xxxxxxxxxx(value="category",key="'getAllFirstLevelCategory'")public void updateRelatedData(CategoryEntity category) {this.updateById(category);if(StringUtils.hasLength(category.getName())){categoryBrandRelationDao.updateCategoryNameByCatId(category.getCatId(),category.getName());}//TODO 商品分类名称变化更新对应的冗余字段}在通过注解
@CacheEvict的value属性指定缓存分区后,将布尔类型的属性allEntries设置为true,此时每次执行@CacheEvict注解标注的方法都会直接将整个缓存分区的所有缓存数据删掉通过这种方式能批量直接删除一个缓存分区中的所有数据
xxxxxxxxxx(value="category",allEntries = true)public void updateRelatedData(CategoryEntity category) {this.updateById(category);if(StringUtils.hasLength(category.getName())){categoryBrandRelationDao.updateCategoryNameByCatId(category.getCatId(),category.getName());}//TODO 商品分类名称变化更新对应的冗余字段}
@CachePut:以不影响方法执行的方式更新缓存业务类型对缓存进行分区,即使有缓存数据也会去执行业务方法,并且在业务方法执行结束以后将方法的返回结果替换掉缓存中相同key的缓存数据@Caching:组合@Cacheable,@CacheEvict,@CachePut多个缓存操作来一次执行@Caching注解中的属性类型分别是Cacheable[]、CachePut[]、CacheEvict[],即可以通过该注解指定多个@Cacheable,@CacheEvict,@CachePut操作,可以进行多缓存分区多种缓存操作类型xxxxxxxxxx(evict = {(value = "category",key = "'getAllFirstLevelCategory'"),(value = "category",key = "'getIndexCategories'")})public void updateRelatedData(CategoryEntity category) {this.updateById(category);if(StringUtils.hasLength(category.getName())){categoryBrandRelationDao.updateCategoryNameByCatId(category.getCatId(),category.getName());}//TODO 商品分类名称变化更新对应的冗余字段}
@CacheConfig:在类级别即一个类上共享缓存的相同配置
相关概念
使用说明图
一个应用要使用
SpringCache要首先给当前应用配置一个或者多个缓存管理器CacheManager

org.springframework.cache.CacheManager缓存管理器只有两个功能,第一个功能是按照String类型的名字获取缓存,第二个功能是获取当前缓存管理器管理的所有缓存的名字集合
CacheManager的实现非常多,直接实现类就有7个,比如ConcurrentMapCacheManager即该缓存管理器管理的所有缓存都是使用ConcurrentMap来做的,Redis对应也有缓存管理器RedisCacheManager,只要有对应的缓存管理器和缓存组件实现类,SpringCache就能兼容无限多种缓存场景老师说就把缓存管理器比作市政府,用来定制管理缓存组件即各个区的方法,比如缓存数据的过期时间是多少、缓存组件的缓存数据如何和具体的缓存媒介数据相互转换的,用缓存组件来保存缓存数据,每个缓存组件就相当于一个区,里面可以组织存放相关业务逻辑的缓存数据,只要清空一个缓存组件的缓存数据就能直接清空对应缓存媒介中关联的全部缓存
xxxxxxxxxxpublic interface CacheManager {Cache getCache(String var1);//按照String类型的名字获取缓存Collection<String> getCacheNames();//获取当前缓存管理器管理的所有缓存的名字集合}org.springframework.cache.Cachexxxxxxxxxxpublic interface Cache {String getName();//获取当前缓存的名字Object getNativeCache();Cache.ValueWrapper get(Object var1);//根据缓存的key从缓存中查询一个数据<T> T get(Object var1, Class<T> var2);<T> T get(Object var1, Callable<T> var2);void put(Object var1, Object var2);//将key-value键值对保存至缓存中Cache.ValueWrapper putIfAbsent(Object var1, Object var2);void evict(Object var1);//根据key从缓存中移除一个数据void clear();//清空整个缓存public static class ValueRetrievalException extends RuntimeException {private final Object key;public ValueRetrievalException( Object key, Callable<?> loader, Throwable ex) {super(String.format("Value for key '%s' could not be loaded using '%s'", key, loader), ex);this.key = key;}public Object getKey() {return this.key;}}public interface ValueWrapper {Object get();}}org.springframework.cache.concurrent.ConcurrentMapCacheManager缓存名字:缓存名字是缓存管理器要管理缓存组件,为了方便给每个组件起了一个名字,该名字就是缓存名字,一个缓存名字相当于给缓存数据划分了一个区,就像一个市里面的各个区,区里面的管理制度由市制定因此每个区的管理方法都是一样的,只是区里面的数据不一样;这样设计的好处是可以根据缓存名字一次性只清空某个区域下的全部缓存,这只是方便业务逻辑定义的一个缓存数据标识,不去指定也是可以的
xxxxxxxxxxpublic class ConcurrentMapCacheManager implements CacheManager, BeanClassLoaderAware {private final ConcurrentMap<String, Cache> cacheMap = new ConcurrentHashMap(16);private boolean dynamic = true;private boolean allowNullValues = true;private boolean storeByValue = false;private SerializationDelegate serialization;public ConcurrentMapCacheManager() {}//ConcurrentMapCacheManager的构造方法要传参可变长度字符串缓存名字,缓存名字的概念是缓存管理器要管理缓存组件,为了方便给每个组件起了一个名字,该名字就是缓存名字,一个缓存名字相当于给缓存数据划分了一个区,就像一个市里面的各个区,区里面的管理制度由市制定因此每个区的管理方法都是一样的,只是区里面的数据不一样;这样设计的好处是可以根据缓存名字一次性只清空某个区域下的全部缓存,这只是方便业务逻辑定义的一个缓存数据标识,不去指定也是可以的public ConcurrentMapCacheManager(String... cacheNames) {this.setCacheNames(Arrays.asList(cacheNames));1️⃣ //构造器会调用setCacheNames方法}1️⃣ //如果缓存不为空就会遍历每个缓存名字,以缓存名字作为key,以缓存Cache对象作为value,向ConcurrentMap<String,Cache>类型的cacheMap属性中添加缓存区域[这个Cache叫缓存组件],对应的缓存Cache通过方法createConcurrentMapCache(name)来创建,public void setCacheNames( Collection<String> cacheNames) {if (cacheNames != null) {Iterator var2 = cacheNames.iterator();while(var2.hasNext()) {String name = (String)var2.next();this.cacheMap.put(name, this.createConcurrentMapCache(name));1️⃣-1️⃣}this.dynamic = false;} else {this.dynamic = true;}}public void setAllowNullValues(boolean allowNullValues) {if (allowNullValues != this.allowNullValues) {this.allowNullValues = allowNullValues;this.recreateCaches();}}public boolean isAllowNullValues() {return this.allowNullValues;}public void setStoreByValue(boolean storeByValue) {if (storeByValue != this.storeByValue) {this.storeByValue = storeByValue;this.recreateCaches();}}public boolean isStoreByValue() {return this.storeByValue;}public void setBeanClassLoader(ClassLoader classLoader) {this.serialization = new SerializationDelegate(classLoader);if (this.isStoreByValue()) {this.recreateCaches();}}public Collection<String> getCacheNames() {return Collections.unmodifiableSet(this.cacheMap.keySet());}public Cache getCache(String name) {Cache cache = (Cache)this.cacheMap.get(name);if (cache == null && this.dynamic) {synchronized(this.cacheMap) {cache = (Cache)this.cacheMap.get(name);if (cache == null) {cache = this.createConcurrentMapCache(name);this.cacheMap.put(name, cache);}}}return cache;}private void recreateCaches() {Iterator var1 = this.cacheMap.entrySet().iterator();while(var1.hasNext()) {Entry<String, Cache> entry = (Entry)var1.next();entry.setValue(this.createConcurrentMapCache((String)entry.getKey()));}}1️⃣-1️⃣ //即初始化时根据传参的缓存名字创建一个缓存对象,对应ConcurrentMapCacheManager创建的Cache对象类型是ConcurrentMapCache,在该缓存组件会定义对缓存的增删改查操作protected Cache createConcurrentMapCache(String name) {SerializationDelegate actualSerialization = this.isStoreByValue() ? this.serialization : null;return new ConcurrentMapCache(name, new ConcurrentHashMap(256), this.isAllowNullValues(), actualSerialization);}}org.springframework.cache.concurrent.ConcurrentMapCache该缓存组件会定义对缓存的增删改查操作
xxxxxxxxxxpublic class ConcurrentMapCache extends AbstractValueAdaptingCache {private final String name;private final ConcurrentMap<Object, Object> store;//store属性是缓存组件存储所有数据的地方,所有的缓存数据按照键值对的形式存入这个ConcurrentMap中,增删改查数据都是对store的增删改查操作private final SerializationDelegate serialization;public ConcurrentMapCache(String name) {this(name, new ConcurrentHashMap(256), true);}public ConcurrentMapCache(String name, boolean allowNullValues) {this(name, new ConcurrentHashMap(256), allowNullValues);}public ConcurrentMapCache(String name, ConcurrentMap<Object, Object> store, boolean allowNullValues) {this(name, store, allowNullValues, (SerializationDelegate)null);}protected ConcurrentMapCache(String name, ConcurrentMap<Object, Object> store, boolean allowNullValues, SerializationDelegate serialization) {super(allowNullValues);Assert.notNull(name, "Name must not be null");Assert.notNull(store, "Store must not be null");this.name = name;this.store = store;this.serialization = serialization;}public final boolean isStoreByValue() {return this.serialization != null;}public final String getName() {return this.name;}public final ConcurrentMap<Object, Object> getNativeCache() {return this.store;}//lookup方法根据key从缓存组件中获取数据protected Object lookup(Object key) {return this.store.get(key);}public <T> T get(Object key, Callable<T> valueLoader) {return this.fromStoreValue(this.store.computeIfAbsent(key, (k) -> {try {return this.toStoreValue(valueLoader.call());} catch (Throwable var5) {throw new ValueRetrievalException(key, valueLoader, var5);}}));}public void put(Object key, Object value) {this.store.put(key, this.toStoreValue(value));}public ValueWrapper putIfAbsent(Object key, Object value) {Object existing = this.store.putIfAbsent(key, this.toStoreValue(value));return this.toValueWrapper(existing);}public void evict(Object key) {this.store.remove(key);}public void clear() {this.store.clear();}protected Object toStoreValue( Object userValue) {Object storeValue = super.toStoreValue(userValue);if (this.serialization != null) {try {return this.serializeValue(this.serialization, storeValue);} catch (Throwable var4) {throw new IllegalArgumentException("Failed to serialize cache value '" + userValue + "'. Does it implement Serializable?", var4);}} else {return storeValue;}}private Object serializeValue(SerializationDelegate serialization, Object storeValue) throws IOException {ByteArrayOutputStream out = new ByteArrayOutputStream();byte[] var4;try {serialization.serialize(storeValue, out);var4 = out.toByteArray();} finally {out.close();}return var4;}protected Object fromStoreValue( Object storeValue) {if (storeValue != null && this.serialization != null) {try {return super.fromStoreValue(this.deserializeValue(this.serialization, storeValue));} catch (Throwable var3) {throw new IllegalArgumentException("Failed to deserialize cache value '" + storeValue + "'", var3);}} else {return super.fromStoreValue(storeValue);}}private Object deserializeValue(SerializationDelegate serialization, Object storeValue) throws IOException {ByteArrayInputStream in = new ByteArrayInputStream((byte[])((byte[])storeValue));Object var4;try {var4 = serialization.deserialize(in);} finally {in.close();}return var4;}}
SpringCache的不足
缓存分区组件操作缓存的过程
CacheManager[RedisCacheManager]创建Cache[RedisCache]负责缓存的读写缓存未建立情况下首次查询数据并构建缓存流程
从第一次构建缓存的流程可以看出来,第一次调用
redisCache.lookup(key)方法查询缓存未命中和执行完业务方法对返回结果调用redisCache.put(key,value)方法进行缓存,期间的所有方法都是没有加锁的,RedisCache类中只有get(key)方法加了本地锁,因此默认重建缓存过程是没有加锁的,因此使用SpringCache是会存在缓存击穿问题的;解决方法一是不使用
SpringCache自己手写使用分布式双重检查锁重建缓存;解决方法二是将
SpringCache的@Cacheable注解的sync属性改为true,默认值为false,该属性的作用是同步潜在的几个调用该注解标注方法尝试获取同一个key的结果的线程,说人话就是缓存没命中构建缓存时让构建缓存的线程同步,注意这里加的是本地锁
xxxxxxxxxxspring-data-redis:2.1.10.RELEASE//CacheAspectSupport类是缓存切面支持器,缓存所有功能都是拿AOP做的--------------------------------------------------------------------------------------------------CacheAspectSupport.executeprivate Object execute(CacheOperationInvoker invoker, Method method, CacheAspectSupport.CacheOperationContexts contexts) {if (contexts.isSynchronized()) {CacheAspectSupport.CacheOperationContext context = (CacheAspectSupport.CacheOperationContext)contexts.get(CacheableOperation.class).iterator().next();if (this.isConditionPassing(context, CacheOperationExpressionEvaluator.NO_RESULT)) {Object key = this.generateKey(context, CacheOperationExpressionEvaluator.NO_RESULT);Cache cache = (Cache)context.getCaches().iterator().next();try {return this.wrapCacheValue(method, cache.get(key, () -> {return this.unwrapReturnValue(this.invokeOperation(invoker));}));} catch (ValueRetrievalException var10) {throw (ThrowableWrapper)var10.getCause();}} else {return this.invokeOperation(invoker);}} else {this.processCacheEvicts(contexts.get(CacheEvictOperation.class), true, CacheOperationExpressionEvaluator.NO_RESULT);ValueWrapper cacheHit = this.findCachedItem(contexts.get(CacheableOperation.class));1️⃣ //第一次获取缓存,通过返回值是否有值来检查缓存是否命中List<CacheAspectSupport.CachePutRequest> cachePutRequests = new LinkedList();if (cacheHit == null) {this.collectPutRequests(contexts.get(CacheableOperation.class), CacheOperationExpressionEvaluator.NO_RESULT, cachePutRequests);//}Object cacheValue;Object returnValue;if (cacheHit != null && !this.hasCachePut(contexts)) {cacheValue = cacheHit.get();returnValue = this.wrapCacheValue(method, cacheValue);} else {returnValue = this.invokeOperation(invoker);//这一步进去就是执行用户定义的目标方法即业务逻辑并获取返回值赋值给returnValuecacheValue = this.unwrapReturnValue(returnValue);//将方法返回值包装成缓存数据对象}this.collectPutRequests(contexts.get(CachePutOperation.class), cacheValue, cachePutRequests);2️⃣ //在这一步中将方法的返回值调用RedisCache.put()方法将缓存放入缓存媒介中,这儿一步到位跳到RedisCache的put方法Iterator var8 = cachePutRequests.iterator();while(var8.hasNext()) {CacheAspectSupport.CachePutRequest cachePutRequest = (CacheAspectSupport.CachePutRequest)var8.next();cachePutRequest.apply(cacheValue);}this.processCacheEvicts(contexts.get(CacheEvictOperation.class), false, cacheValue);return returnValue;}}1️⃣ CacheAspectSupport.findCachedItem(contexts.get(CacheableOperation.class))private ValueWrapper findCachedItem(Collection<CacheAspectSupport.CacheOperationContext> contexts) {Object result = CacheOperationExpressionEvaluator.NO_RESULT;Iterator var3 = contexts.iterator();while(var3.hasNext()) {CacheAspectSupport.CacheOperationContext context = (CacheAspectSupport.CacheOperationContext)var3.next();if (this.isConditionPassing(context, result)) {Object key = this.generateKey(context, result);ValueWrapper cached = this.findInCaches(context, key);1️⃣-1️⃣ //调用findInCaches第一次查询缓存,如果不是空直接返回查询到的缓存,如果是空检查是否需要打印日志并返回空值if (cached != null) {return cached;}if (this.logger.isTraceEnabled()) {this.logger.trace("No cache entry for key '" + key + "' in cache(s) " + context.getCacheNames());}}}return null;}2️⃣ redisCache.put()/** (non-Javadoc)* @see org.springframework.cache.Cache#put(java.lang.Object, java.lang.Object)*/public void put(Object key, Object value) {Object cacheValue = preProcessCacheValue(value);if (!isAllowNullValues() && cacheValue == null) {throw new IllegalArgumentException(String.format("Cache '%s' does not allow 'null' values. Avoid storing null via '@Cacheable(unless=\"#result == null\")' or configure RedisCache to allow 'null' via RedisCacheConfiguration.",name));}cacheWriter.put(name, createAndConvertCacheKey(key), serializeCacheValue(cacheValue), cacheConfig.getTtl());}1️⃣-1️⃣ CacheAspectSupport.findInCaches(context, key)private ValueWrapper findInCaches(CacheAspectSupport.CacheOperationContext context, Object key) {Iterator var3 = context.getCaches().iterator();Cache cache;ValueWrapper wrapper;do {if (!var3.hasNext()) {return null;}cache = (Cache)var3.next();wrapper = this.doGet(cache, key);1️⃣-1️⃣-1️⃣ //调用doGet方法从缓存媒介中拿缓存赋值给wrapper,如果wrapper不为null则直接返回,如果为null,检查是否需要打印日志,然后直接返回null} while(wrapper == null);if (this.logger.isTraceEnabled()) {this.logger.trace("Cache entry for key '" + key + "' found in cache '" + cache.getName() + "'");}return wrapper;}1️⃣-1️⃣-1️⃣ AbstractCacheInvoker.doGet(cache, key)protected ValueWrapper doGet(Cache cache, Object key) {try {return cache.get(key);1️⃣-1️⃣-1️⃣-1️⃣ //根据缓存的key尝试获取缓存} catch (RuntimeException var4) {this.getErrorHandler().handleCacheGetError(var4, cache, key);return null;}}1️⃣-1️⃣-1️⃣-1️⃣ AbstractValueAdaptingCache.get(key)public ValueWrapper get(Object key) {Object value = this.lookup(key);1️⃣-1️⃣-1️⃣-1️⃣-1️⃣ //从这儿进入Cache组件的lookup方法尝试获取缓存数据return this.toValueWrapper(value);}1️⃣-1️⃣-1️⃣-1️⃣-1️⃣ redisCache.lookup(key)/** (non-Javadoc)* @see org.springframework.cache.support.AbstractValueAdaptingCache#lookup(java.lang.Object)*/protected Object lookup(Object key) {//查询缓存的方法byte[] value = cacheWriter.get(name, createAndConvertCacheKey(key));//先从缓存中获取对应key的缓存数据,当缓存中没有数据时该方法会返回null,这是构建缓存执行业务方法前第一次尝试从缓存媒介中获取缓存if (value == null) {return null;//返回null的情况下lookup方法就执行结束了}return deserializeCacheValue(value);}开启
@Cacheable注解的sync功能后的缓存未建立情况下首次查询数据并构建缓存流程sync注解只有@Cacheable注解有,其他的SpringCache注解中是没有的,通过指定sync=true给重建缓存加本地锁解决缓存击穿问题,加的不是完整的分布式锁,老师说加本地锁就足够使用了,但是这里还是感觉不完美,第一个问题是可能有双重检查锁但是源码分析没看见第一次检查的影子,如果没有双重检查锁那不是开启了sync的缓存查询每次查缓存都会上锁,因此这里倾向于使用了双重检查锁但是目前还没看出来;第二个问题是锁的粒度非常大,直接锁单例组件redisCache,相当于直接锁服务实例,只要缓存重新构建就直接锁所有开启了sync的缓存的缓存重建过程❓:这里有没有使用双重检查锁要好好验证一下,对性能影响挺大的
xxxxxxxxxxspring-data-redis:2.1.10.RELEASE--------------------------------------------------------------------------------------------------cacheAspectSupport.execute()private Object execute(CacheOperationInvoker invoker, Method method, CacheAspectSupport.CacheOperationContexts contexts) {if (contexts.isSynchronized()) {//这里是判断@Cacheable注解的属性sync是否开启CacheAspectSupport.CacheOperationContext context = (CacheAspectSupport.CacheOperationContext)contexts.get(CacheableOperation.class).iterator().next();if (this.isConditionPassing(context, CacheOperationExpressionEvaluator.NO_RESULT)) {Object key = this.generateKey(context, CacheOperationExpressionEvaluator.NO_RESULT);Cache cache = (Cache)context.getCaches().iterator().next();try {return this.wrapCacheValue(method, cache.get(key, () -> {return this.unwrapReturnValue(this.invokeOperation(invoker));//1️⃣ 封装一个异步查询业务方法结果的任务Callable<T>到execute方法的调用者,该调用者在调用redisCache.get()方法时将该任务传参进去了,并在缓存未命中的情况下发起异步任务,这个查询业务方法结果的方法其实上面未开启sync功能的流程已经说过了,就是这个方法下面的invokeOperation(invoker);并在此处通过cache.get(key,Callable<T>)调用RedisCache中的get方法}));} catch (ValueRetrievalException var10) {throw (ThrowableWrapper)var10.getCause();}} else {return this.invokeOperation(invoker);}} else {this.processCacheEvicts(contexts.get(CacheEvictOperation.class), true, CacheOperationExpressionEvaluator.NO_RESULT);ValueWrapper cacheHit = this.findCachedItem(contexts.get(CacheableOperation.class));List<CacheAspectSupport.CachePutRequest> cachePutRequests = new LinkedList();if (cacheHit == null) {this.collectPutRequests(contexts.get(CacheableOperation.class), CacheOperationExpressionEvaluator.NO_RESULT, cachePutRequests);}Object cacheValue;Object returnValue;if (cacheHit != null && !this.hasCachePut(contexts)) {cacheValue = cacheHit.get();returnValue = this.wrapCacheValue(method, cacheValue);} else {returnValue = this.invokeOperation(invoker);cacheValue = this.unwrapReturnValue(returnValue);}this.collectPutRequests(contexts.get(CachePutOperation.class), cacheValue, cachePutRequests);Iterator var8 = cachePutRequests.iterator();while(var8.hasNext()) {CacheAspectSupport.CachePutRequest cachePutRequest = (CacheAspectSupport.CachePutRequest)var8.next();cachePutRequest.apply(cacheValue);}this.processCacheEvicts(contexts.get(CacheEvictOperation.class), false, cacheValue);return returnValue;}}1️⃣ redisCache.get()//这个有锁的get方法和我们以前写的逻辑是一样的,但是没有看到双重检查锁的影子,而且锁的粒度非常大,锁整个缓存的构建,而且如果外部没有第一次检查,这里每个开启sync的缓存查询都会被上锁,这肯定是没讲到public synchronized <T> T get(Object key, Callable<T> valueLoader) {ValueWrapper result = get(key);1️⃣-1️⃣ //第一次尝试从缓存中获取数据,注意因为是首次构建缓存,此时缓存中没有数据,该方法调用的是上面未开启功能时调用的从父类AbstractValueAdaptingCache继承来的1️⃣-1️⃣-1️⃣-1️⃣ AbstractValueAdaptingCache.get(key),这个方法实际上调用的是上面的1️⃣-1️⃣-1️⃣-1️⃣-1️⃣ redisCache.lookup(key)尝试去从缓存媒介获取缓存,但是因为是首次构建,所以此处会返回空值//如果缓存被命中直接返回if (result != null) {return (T) result.get();}//如果缓存没有命中就去执行业务方法,获取返回值并调用将键值对存入调用redisCache.put(key,value)方法缓存媒介中T value = valueFromLoader(key, valueLoader);1️⃣-2️⃣ //执行业务方法获取返回值put(key, value);1️⃣-3️⃣ //调用redisCache.put方法将缓存数据键值对存入缓存媒介return value;}1️⃣-1️⃣ AbstractValueAdaptingCache.get(key)public ValueWrapper get(Object key) {Object value = this.lookup(key);1️⃣-1️⃣-1️⃣ //从这儿进入Cache组件的lookup方法尝试获取缓存数据return this.toValueWrapper(value);}1️⃣-2️⃣ redisCache.valueFromLoader(key, valueLoader)private static <T> T valueFromLoader(Object key, Callable<T> valueLoader) {try {return valueLoader.call(); // 通过方法参数列表传参一个有返回结果的异步线程Callable的方式来调用业务方法,这里获取的返回值就是业务方法的返回值,该返回值返回给get方法} catch (Exception e) {throw new ValueRetrievalException(key, valueLoader, e);}}1️⃣-3️⃣ redisCache.put(key, value)public void put(Object key, Object value) {Object cacheValue = preProcessCacheValue(value);if (!isAllowNullValues() && cacheValue == null) {throw new IllegalArgumentException(String.format("Cache '%s' does not allow 'null' values. Avoid storing null via '@Cacheable(unless=\"#result == null\")' or configure RedisCache to allow 'null' via RedisCacheConfiguration.",name));}cacheWriter.put(name, createAndConvertCacheKey(key), serializeCacheValue(cacheValue), cacheConfig.getTtl());//将key和value序列化以后将数据存入缓存媒介}1️⃣-1️⃣-1️⃣ redisCache.lookup(key)/** (non-Javadoc)* @see org.springframework.cache.support.AbstractValueAdaptingCache#lookup(java.lang.Object)*/protected Object lookup(Object key) {//查询缓存的方法byte[] value = cacheWriter.get(name, createAndConvertCacheKey(key));//先从缓存中获取对应key的缓存数据,当缓存中没有数据时该方法会返回null,这是构建缓存执行业务方法前第一次尝试从缓存媒介中获取缓存if (value == null) {return null;//返回null的情况下lookup方法就执行结束了}return deserializeCacheValue(value);}
读取构建缓存时会涉及到缓存穿透、缓存雪崩、缓存击穿的问题
缓存穿透:恶意高并发查询一个不存在的数据,将查询压力给到数据库导致数据库崩掉,
SpringCache给出了缓存空值的解决方案缓存雪崩:大量的key同时过期,同时大量的并发请求因为获取不到缓存同时打到服务器上,此时就会发生缓存雪崩,自己管理缓存,我们通过加随机时间的方式来解决这个问题,但是老师说这种方式很容易弄巧成拙,老师给出的解释是不同有效期加上随机时间可能导致大量的缓存有效时间相同,我觉得这个解释有点牵强;
SpringCache中只要为每个数据指定有效期,每个缓存建立的时间是分散随机的,在有效期相同情况下,即使在大量分散并发请求下重建缓存的时间点也是随机的,因此不需要考虑给有效期加随机时间,而且老师说只有超大型系统才可能存在这种情况,在一般的系统中,只要不是十几万个key同时过期,即使是key同时过期了,而且所有key的请求都访问数据库重建缓存,就不会对数据库造成不可挽回的压力,因此一般系统中根本不需要考虑该问题🔎:而且这里的有效时间设置的太粗暴,直接把所有缓存的有效时间都设置成一样的了
缓存击穿,大量并发请求同时来查询一个正好过期的数据,解决办法是加锁,但是这里暂时还没有处理添加了
SpringCache以后的逻辑,应该加个双重检查锁也一样的,但是如何保证使用SpringCache以后判断完双重检查锁直接拿缓存且避免用拿到的缓存再更新缓存的问题呢
写数据库时考虑缓存数据一致性的问题
🔎:对于写数据库时缓存数据的一致性问题,SpringCache根本没管,需要根据业务场景自己设置,还是提供了一个很垃圾的缓存有效时间来实现缓存数据的最大更新间隔时间来解决写模式的数据一致性问题,常规数据使用SpringCache主要优势在简化开发、方便缓存管理,像缓存分区这种相关功能都是很好用的,自己实现起来就比较麻烦,对于特殊数据再考虑单独设计
对要求数据强一致性的读多写少场景直接加分布式读写锁
引入Canal感知
mysql的更新去更新缓存读多写多的场景直接去查询数据库
总结
常规数据[读多写少,实时性、缓存数据一致性要求不高的数据],可以直接使用
SpringCache,常规数据的写模式数据一致性通过SpringCache的缓存有效时间简单控制即可特殊数据[实时性、一致性要求高的数据],想要通过加缓存提升速度,还想要保证一致性,就需要特殊设计[比如引入Canal、加读写锁、公平锁、可重入锁、信号量、闭锁等结合业务单独设计]
对于商品分类菜单数据,我们只需要考虑解决读模式下的缓存穿透、雪崩和击穿问题,即使用
SpringCache管理缓存即可
前台检索业务
前台从搜索框或者商品分类框进入检索页面的逻辑均整合在
mall-search模块,检索页面的所有静态资源按照静态资源的路径规则设置为/static/search/区分于首页的静态资源/static/index使用
SwitchHosts修改二级域名search.earlmall.com作为检索服务的域名并映射到虚拟机的nginx中,所有非静态资源请求都统一转到后台网关,后台网关转给对应的search服务
搭建检索页面
细节知识点参考web生态中的
thymeleaf和nginx以及Gateway路由相关知识,这里只演示步骤和搭建逻辑
给
mall-search服务添加thymeleaf的场景启动器,并参考web生态中的thymeleaf做好相应配置,将搜索首页模板放入search服务[默认路径为类路径下的templates/index.html],将静态资源存入nginx做动静分离,开发期间关闭thymeleaf的缓存功能使用
SwitchHosts配置本地域名解析将服务站点的
server_name修改为*.earlmall.com,让所有以earlmall.com作为后缀的二级域名或者earlmall.com都进入一个虚拟主机,让后台请求根据路由匹配全部转发到后台网关网关路由配置
旧的配置
旧配置是只要是域名以
earlmall.com作为二级域名的全部转给商品服务
xxxxxxxxxxspringcloudgatewayroutesidmall_host_routeurilb//mall-productpredicatesHost=**.earlmall.com新配置
都配置成精确匹配,让
earlmall.com转发到商品服务、让search.earlmall.com转发到mall-search服务转发时请求头中的host属性由
nginx的配置proxy_set_header Host $host
xxxxxxxxxxspringcloudgatewayroutesidmall_host_routeurilb//mall-productpredicatesHost=earlmall.comidmall_search_routeurilb//mall-searchpredicatesHost=search.earlmall.com
检索逻辑
从商城首页跳转到检索页面的方式有:
通过顶部搜索框搜索跳转
点击搜索会调用前台页面的
search方法,通过window.location.href="http://search.earlmall.com/list.html?keyword=用户输入值"跳转到检索页面
点击选择商品分类跳转
用户点击商品分类发送请求
http://search.earlmall.com/list.html?catelog3Id=255传参三级商品分类id为255🔎:注意这里的前端组装数据的方式比较复杂,Thymeleaf只是渲染了一级商品分类列表,其余的商品分类列表都是通过前端发起并发请求一次性获取以后自己渲染的[这个前端渲染过程可以好好学习一下],这里的第三级商品分类的超链接的域名地址与我们设置的接口地址不符,解决方法是超链接中的
gmall需要去nginx下的html/static/index/js,把catelogLoader中搜索gmall并替换为earlmall,具体的原理以后对前端深入学习了再追究
检索的逻辑
定义一个商品检索条件实体类用于封装接口
http://search.earlmall.com/list.html前端传参的检索条件,通过检索条件将相关商品从ES服务器中检索出来,涉及到的检索条件如下:检索条件都不是必须传递的,检索条件封装为类SearchParam,使用SpringMVC将页面提交请求查询参数封装成指定的对象的特性来封装检索条件1️⃣:首页搜索框用户输入的全文匹配关键字,对商品名字即
sku名字进行匹配,参数封装为String类型的keyword2️⃣:三级商品分类的id,首页点进某一个商品分类,参数封装为
Long类型的catelog3Id3️⃣:过滤条件如
hasStock=0/1[仅显示有货],skuPrice=1_500/_500/500_[选择价格区间,500表示500以内,500表示500以上],都是可传可不传的参数,参数封装为Integer类型的hasStock、售价封装为String类型的skuPrice弹幕说价格区间使用
String类型能保证精度,为什么不使用BigDecimal呢
4️⃣:排序条件如
saleCount[销量]、hotScore[热度评分]、skuPrice[售价],同一时刻有且只能按照一种方式进行排序,排序参数规则为排序方式_asc为升序、排序方式_desc为降序,排序参数名为sort,比如sort=saleCount_asc就是按照销量升序排序,参数封装为String类型的sort5️⃣:品牌id,而且支持多选,使用List集合来接收传参,传参格式为
brandId=1&brandId=2&brandId=3,参数封装为Long类型的list集合brandIds6️⃣:按照商品分类的属性进行筛选,属性也是可以多选的,传参格式
attrs=1_其他:安卓&attrs=2_5寸:6寸,参数名为attrs表示按照属性进行查询,等号后面的格式为属性id_属性值1:属性值2,支持传递多个属性,每个属性可以传递多个属性值,属性值之间使用冒号进行分隔,参数封装为String类型的list集合attrs7️⃣:商品数据很多,需要对查询到的商品数据进行分页,需要传参
Integer类型的商品数据页码pageNum
前端请求路径拼接的参数示例
catelog3Id=255&keyword=小米&sort=saleCount_asc&hasStock=1&brandId=1&brandId=2&attrs=1_其他:安卓&attrs=2_5寸:6寸xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 检索参数* @创建日期 2024/09/05* @since 1.0.0*/public class SearchParam {/*** 用户检索关键字,该关键字用于匹配SKU名字即商品名字*/private String keyword;/*** 商品第三级分类id*/private Long catelog3Id;/*** 是否还有库存,1表示有库存,0表示没有库存*/private Integer hasStock;/*** 商品价格区间,1_500/_500/500_* _500表示500以内,500_表示500以上*/private String skuPrice;/*** 商品排序,按照saleCount[销量]、hotScore[热度评分]、skuPrice[售价]* 参数格式为saleCount_asc表示按照销量升序、saleCount_desc表示按照销量降序*/private String sort;/*** 所选品牌的品牌id,支持多选,目的是查询出指定品牌的商品数据*/private List<Long> brandIds;/*** 锁选商品属性,传参格式`attrs=属性id1_属性值1:属性值2&attrs=属性id2_属性值1:属性值2`*/private List<String> attrs;/*** 当前商品页页码*/private Integer pageNum;}
响应逻辑
定义一个
SkuSearchResult用来封装根据检索条件查询到的检索结果检索页面对于每个商品分类都会展示相关的品牌数据,品牌名字、品牌图片、品牌Id来供搜素使用
在经过过滤条件筛选以后,检索页面要展示筛选条件和对应条件下的商品以及这些商品包含的属性并集,对属性的封装包含属性id、属性名字、属性允许的所有值,对于没有商品的属性不予展示,对于有商品的属性但是允许的某个属性值下没有商品也不予展示
封装检索页面商品分类信息,包括分类id、分类名字
❓:这个检索条件商品分类用户没有选择商品分类直接进入检索页面,商品分类数据如何展示呢,不可能将所有商品分类都列举在一个选择栏中并列举出所有的商品
🔑:京东的做法是进入一个新的页面,在该页面展示全部的可供选择的商品分类,在一级商品分类下展示三款对应商品分类的热卖爆品,因此我们可以将没有指定商品分类的商品分类处理成对所有商品分类的查询
❓:在已经选择一个三级商品分类的前提下,商品分类列表只展示当前选中的三级商品分类没有意义,看见了也不自然
🔑:京东的做法是在选中三级分类的情况下不再展示商品分类列表,也可以设计成当前检索的所有结果涉及到的商品分类,只有一个分类的情况下前端可以设置为不展示分类数据
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 封装检索页面的检索结果* @创建日期 2024/09/05* @since 1.0.0*/public class SkuSearchResult {/*** 封装从查到ES中所有的商品完整信息*/private List<Product> products;/*** 分页信息-当前页码*/private Integer pageNum;/*** 分页信息-总记录数*/private Long total;/*** 分页信息-总页码数*/private Integer totalPages;/*** 当前检索查询到的结果涉及到的品牌信息*/private List<BrandVo> brands;/*** 当前检索查询到的结果涉及到的能被过滤出商品的所有属性*/private List<AttrVo> attrs;/*** @author Earl* @version 1.0.0* @描述 品牌信息封装类* @创建日期 2024/09/05* @since 1.0.0*/public static class BrandVo {/*** 品牌ID*/private Long brandId;/*** 品牌名*/private String brandName;/*** 品牌logo*/private String brandImg;}/*** @author Earl* @version 1.0.0* @描述 属性信息封装* @创建日期 2024/09/05* @since 1.0.0*/public static class AttrVo {/*** 属性ID*/private String attrId;/*** 属性名*/private String attrName;/*** 属性值*/private List<String> attrValue;}}
业务方法逻辑
searchService.searchSku(SearchParam param)根据用户输入的检索条件从ES服务器中查询并返回所有满足要求的商品数据使用Kibana测试检索商品的逻辑,
192.168.56.10:5601进入Kibana,点击左侧边栏Dev Tools进入Kibana控制台检索关键字匹配
sku标题的查询语句查询语句的语法细节参考整合
ElasticSearch的Query DSL语法,must是必须满足列举的所有条件,match中的条件需要参与评分
xxxxxxxxxxGET product/_search{"query": {"bool": {"must": [{"match": {"skuTitle": "华为"}}]}}}检索商品分类id为指定值以及品牌id为指定值列表的查询语句
过滤的条件不应该参与评分,可以写在
filter语句中,filter会将记录中不满足预设条件的文档记录直接过滤清除掉,满足filter中范围条件的文档记录的_score字段每条记录都为0,这是因为只进行了filter过滤,filter本身不计算得分,如果filter还组合了其他如should、match等条件,得到的记录还是会有相关性评分,但是该评分不会统计filter中的条件,过滤条件写在must语句中也是能完成业务的,但是写在filter中不参与评分会更好term表示精确查询非text字段,terms表示对字段统计分组[按字段的值分布进行聚合,就是筛选出terms中属性满足对应属性值或者属性值列表的记录]
xxxxxxxxxxGET product/_search{"query": {"bool": {"must": [{"match": {"skuTitle": "华为"}}],"filter": [{"term": {"catelogId": 225}},{"terms": {"brandId": ["4","1","9"]}}]}}}查询属性id的属性值为对应属性值列表的记录,
nested数据类型的查询匹配每个商品的属性最初设置的是
nested类型,查询的时候也要使用nested查询语法,nested语法见【nested数据类型】这里一定要注意,每个属性都要对应一个must结构,这样是将每个属性可以取多个属性值,多个属性id不能写进一个terms,这样就变成一个属性名可以匹配别的属性名下的属性值,这样的逻辑是错误的
xxxxxxxxxxGET product/_search{"query": {"bool": {"must": [{"match": {"skuTitle": "华为"}}],"filter": [{"term": {"catelogId": 225}},{"terms": {"brandId": ["4","1","9"]}},{"nested": {"path": "attrs","query": {"bool": {"must": [{"term": {"attrs.attrId": "11"}},{"terms": {"attrs.attrValue": ["海思芯片","以官网信息为准"]}}]}}}}]}}}检索结果按字段进行排序
注意排序
sort语句与query语句是并列的排序指定排序字段,并在
order属性中通过指定desc或者asc分别指定降序或者升序
xxxxxxxxxxGET product/_search{"query": {},"sort": {"skuPrice": {"order": "desc"}}}仅显示有库存
属性既可以通过
"hasStock": {"value": true}[布尔类型参数值不加双引号也是可以的]匹配属性值,也可以通过"hasStock": true匹配属性值
xxxxxxxxxxGET product/_search{"query": {"bool": {"filter": {"term": {"hasStock": {"value": "true"}}}}}}按照价格区间查询
使用
range语句,指定字段,在字段对象中指定gte属性的值表示大于等于某个值,指定lte属性表示小于等于某个值range语句目前必须写在filter中,写在bool中也会报错query语句不支持range
xxxxxxxxxxGET product/_search{"query": {"bool": {"must": [{"match": {}}],"filter": [{"term": {}},{"terms": {}},{"nested": {}},{"range": {"skuPrice": {"gte": 0,"lte": 6000}}}]}},"sort": {}}按照页码分页查记录
from语句表示从第几条记录开始,size语句表示每页数据的最大个数
xxxxxxxxxxGET product/_search{"query": {"bool": {"must": [{"match": {}}],"filter": [{"term": {}},{"terms": {}},{"nested": {}},{"range": {}}}]}},"sort": {},"from": 0,"size": 20}高亮keyword关键字
用户使用关键字对sku名字进行查询,查询结果中的所有记录的名字应该用红颜色进行高亮
field属性指定要高亮的属性,高亮的内容是对应属性中用于匹配的关键字pre_tags表示为对应属性中的匹配关键字加高亮标签前缀post_tags表示为对应属性中的匹配关键字加高亮标签后缀
xxxxxxxxxxGET product/_search{"query": {"bool": {"must": [{"match": {}}],"filter": [{"term": {}},{"terms": {}},{"nested": {}},{"range": {}}}]}},"sort": {},"from": 0,"size": 20,"highlight": {"fields": {"skuTitle": {}},"pre_tags": "<b style='color:red'>","post_tags": "</b>"}}
总结
模糊匹配检索关键字keyword、
按照选中属性、商品分类、品牌、价格区间、有无货过滤记录
记录按照销量、热度、价格排序
分页查询记录
高亮关键字
修改索引product的映射关系并迁移数据
创建新索引
mall_productxxxxxxxxxxPUT mall_product{"mappings": {"properties": {"skuId": {"type": "long"},"spuId": {"type": "keyword"},"skuTitle": {"type": "text","analyzer": "ik_smart"},"skuPrice": {"type": "keyword"},"skuImg": {"type": "keyword"},"saleCount": {"type": "long"},"hasStock": {"type": "boolean"},"hotScore": {"type": "long"},"brandId": {"type": "long"},"catelogId": {"type": "long"},"brandName": {"type": "keyword"},"brandImg": {"type": "keyword"},"catelogName": {"type": "keyword"},"attrs": {"type": "nested","properties": {"attrId": {"type": "long"},"attrName": {"type": "keyword"},"attrValue": {"type": "keyword"}}}}}迁移数据
source是指定数据的原索引、dest是指定数据迁移的目标索引
xxxxxxxxxxPOST _reindex{"source": {"index": "product"},"dest": {"index": "mall_product"}}修改应用程序对应的索引常量为迁移后的索引名称
显然ES服务器中新旧索引不能同名
最难的业务逻辑
根据上述条件检索到的记录动态获取记录的所有属性和可能的所有属性值、品牌、商品分类并且动态变化检索页面的检索条件,这个业务是对查询到的记录进行聚合分析
用
aggs指令做聚合分析,第一个分析所有记录中有哪些品牌,品牌可能有多个可能的值,使用terms聚合对字段统计分组,field表示要聚合分析的属性,size表示最大取聚合分析数据的前size个,brand_agg是我们为该聚合分析取的名字响应结果中聚合数据在
aggregation属性中,聚合的分组数据在buckets桶属性中,其中每个对象中的key属性为一个分组数据的属性值,doc_count属性是对应属性值的记录条数xxxxxxxxxxGET product/_search{"query": {"match_all": {}},"aggs": {"brand_agg": {"terms": {"field": "brandId","size": 100}}}}#响应的聚合分析结果,品牌id有两个,一个是4,记录数是8;还有一个品牌id是7,记录数是4{"aggregations" : {"brand_agg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : 4,"doc_count" : 8},{"key" : 7,"doc_count" : 4}]}}}聚合分析所有检索到的记录的品牌id、商品分类id
这里只是获取到品牌和商品分类的id,如果获取品牌和商品分类的完整信息,有以下两种方法
方法1是根据id再次检索数据库或者缓存去获取完整的信息
方法2是对聚合结果再次进行子聚合,子聚合可以统计分析父聚合的结果,而且可以从聚合结果的数据对应文档中获取父聚合没有获取到的属性值
注意进行聚合的属性的类型的doc_value属性必须设置为true,不能设置为false,只有该属性被设置为true对应属性才能被聚合分析,这里创建映射关系时认为品牌名和商品分类名只需要被展示,不会被聚合所以doc_value被设置为false,这里需要更改索引映射规则
该索引映射需要进行数据迁移,官网规定不能修改映射,所以需要创建新的索引,并设置修改后的映射规则,并将旧数据迁移到新索引下
1️⃣[聚合查询]
对所有记录的品牌id分组聚合的结果继续进行品牌名字、品牌图标分组聚合,对所有记录的商品分类id分组聚合的结果继续进行商品分类名字的分组聚合,对所有记录的属性id分组聚合的结果继续进行属性名字、属性值的分组聚合
xxxxxxxxxxGET mall_product/_search{"query": {"match_all": {}},"aggs": {"brand_agg": {"terms": {"field": "brandId","size": 10},"aggs": {"brand_name_agg": {"terms": {"field": "brandName","size": 10}},"brand_img_agg": {"terms": {"field": "brandImg","size": 10}}}},"catelog_agg": {"terms": {"field": "catelogId","size": 10},"aggs": {"catelog_name_agg": {"terms": {"field": "catelogName","size": 10}}}}}}[响应结果]
xxxxxxxxxx"aggregations" : {"catelog_agg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : 225,"doc_count" : 8,"catelog_name_agg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "手机","doc_count" : 8}]}},{"key" : 255,"doc_count" : 4,"catelog_name_agg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "DVD/电视盒子","doc_count" : 4}]}}]},"brand_agg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : 4,"doc_count" : 8,"brand_img_agg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/03/ca1e4c86-a0f0-4a46-8fa9-db8f92bbc0a1_huawei.png","doc_count" : 8}]},"brand_name_agg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "华为","doc_count" : 8}]}},{"key" : 7,"doc_count" : 4,"brand_img_agg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/03/52b9cc92-6df9-427a-8fcc-c94c413b3e94_apple.png","doc_count" : 4}]},"brand_name_agg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "Apple","doc_count" : 4}]}}]}}
聚合分析所有检索到的记录的nested类型的数据
attrsnested类型的数据进行聚合除了要在一般的聚合分析外面多套一层聚合分析并且用nested对象的path属性指明要被聚合分析的nested类型的字段,如下例所示
[语法格式]
第一个comments是聚合的自定义名字,age_group也是聚合的自定义名字,blogposts也是自定义聚合的名字
xxxxxxxxxxGET /my_index/blogpost/_search{"size" : 0,"aggs": {"comments": {"nested": {"path": "comments"},"aggs": {"age_group": {"histogram": {"field": "comments.age","interval": 10},"aggs": {"blogposts": {"reverse_nested": {},"aggs": {"tags": {"terms": {"field": "tags"}}}}}}}}}}1️⃣[对nested类型数据聚合查询]
xxxxxxxxxxGET mall_product/_search{"query": {"match_all": {}},"aggs": {"brand_agg": {},"catelog_agg": {},"attrs_agg": {"nested": {"path": "attrs"},"aggs": {"attrs_id_agg": {"terms": {"field": "attrs.attrId","size": 10},"aggs": {"attr_name_agg": {"terms": {"field": "attrs.attrName","size": 10}},"attr_value_agg": {"terms": {"field": "attrs.attrValue","size": 10}}}}}}}}[响应结果]
xxxxxxxxxx"aggregations" : {"attrs_agg" : {"doc_count" : 24,"attrs_id_agg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : 3,"doc_count" : 12,"attr_name_agg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "入网型号","doc_count" : 12}]},"attr_value_agg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "LIO-AL00;是;否","doc_count" : 8},{"key" : "LIO-AL00","doc_count" : 4}]}},{"key" : 11,"doc_count" : 12,"attr_name_agg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "CPU品牌","doc_count" : 12}]},"attr_value_agg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "海思芯片","doc_count" : 8},{"key" : "Apple芯片","doc_count" : 4}]}}]}},"catelog_agg" : {},"brand_agg" : {}}
检索页面DSL语句
使用Kibana构建出完整的检索DSL语句
完整的检索页面DSL语句
检索商品名称包含指定关键字、商品分类id为指定值、品牌id为指定值列表、商品属性为指定值且价格范围在指定范围的所有商品记录并按照价格降序排列,对查询到的所有商品记录聚合分析出包含的所有品牌id、品牌名、品牌商标;商品分类id、商品分类名称;所有属性id、属性名称和对应属性id下的全部可能存在的属性值,高亮检索关键字、记录分页
xxxxxxxxxxGET mall_product/_search{"query": {"bool": {"must": [{"match": {"skuTitle": "华为"}}],"filter": [{"term": {"catelogId": 225}},{"terms": {"brandId": ["4","1","9"]}},{"nested": {"path": "attrs","query": {"bool": {"must": [{"term": {"attrs.attrId": "11"}},{"terms": {"attrs.attrValue": ["海思芯片","以官网信息为准"]}}]}}}},{"range": {"skuPrice": {"gte": 0,"lte": 6000}}}]}},"aggs": {"brand_agg": {"terms": {"field": "brandId","size": 10},"aggs": {"brand_name_agg": {"terms": {"field": "brandName","size": 10}},"brand_img_agg": {"terms": {"field": "brandImg","size": 10}}}},"catelog_agg": {"terms": {"field": "catelogId","size": 10},"aggs": {"catelog_name_agg": {"terms": {"field": "catelogName","size": 10}}}},"attrs_agg": {"nested": {"path": "attrs"},"aggs": {"attrs_id_agg": {"terms": {"field": "attrs.attrId","size": 10},"aggs": {"attr_name_agg": {"terms": {"field": "attrs.attrName","size": 10}},"attr_value_agg": {"terms": {"field": "attrs.attrValue","size": 10}}}}}}},"sort": {"skuPrice": {"order": "desc"}},"from": 0,"size": 20,"highlight": {"fields": {"skuTitle": {}},"pre_tags": "<b style='color:red'>","post_tags": "</b>"}}
用Java动态构建DSL
使用Java代码动态构建检索需要的DSL语句
检索方法的基本结构
控制器方法
xxxxxxxxxxpublic class ESSearchController {private ESSearchService esSearchService;/*** @param param* @param model* @return {@link String }* @描述 注意请求路径的参数会自动封装到请求参数列表中,无需添加额外注解* @author Earl* @version 1.0.0* @创建日期 2024/09/06* @since 1.0.0*/("/list.html")public String getSearchPage(SearchParam param, Model model){//1. 根据请求参数去构建DSL语句去ES中检索对应商品SkuSearchResult result = esSearchService.searchProduct(param);//2. 将检索结果添加到ModelAndView中准备渲染检索页面model.addAttribute("searchResult",result);return "list";}}检索方法大结构
整体结构为构建一个
SearchRequest封装检索DSL语句,用RestHighLevelClient使用SearchRequest发送请求执行检索并返回检索结果,将检索结果封装成我们自定义的响应对象构建检索请求对象即构建检索DSL比较复杂,单独抽取成
buildSearchRequest()方法,这方法有100行根据检索结果构建响应对象的过程也比较复杂,单独抽取成
buildSearchResponse()方法
xxxxxxxxxx(topic = "es.search")public class ESSearchServiceImpl implements ESSearchService {private RestHighLevelClient esRESTClient;public SkuSearchResult searchProduct(SearchParam param) {SkuSearchResult result = null;//1. 准备检索请求,但是检索请求太过复杂,我们希望调用一个私有方法来专门构建请求,直接返回检索请求//SearchRequest searchRequest = new SearchRequest();SearchRequest searchRequest = buildSearchRequest(param);try {//2. 通过检索请求执行检索SearchResponse response = esRESTClient.search(searchRequest, MallElasticSearchConfig.COMMON_OPTIONS);//3. 将检索结果封装成我们自定义的响应对象result = buildSearchResponse(response);} catch (IOException e) {e.printStackTrace();}return result;}}构建检索DSL的
buildSearchRequest()方法检索语句的构建需要通过对象
SearchSourceBuilder进行,通过searchRequest.source(searchSourceBuilder)来封装检索条件SearchRequest对象有一个双参构造方法public SearchRequest(String[] indices, SearchSourceBuilder source),第一个参数是指定从哪些索引中检索数据,第二个参数是构建DSL语句的SearchSourceBuilder对象
[基本框架]
封装查询条件需要使用
QueryBuilders对象、封装聚合分析语句需要使用AggregationBuilders,并且通过SearchSourceBuilder对象的query、aggregation方法来分别封装这些builders
xxxxxxxxxx/*** @return {@link SearchRequest }* @描述 通过用户检索传参构建检索请求* 功能包括: 模糊匹配关键字、按照属性值、商品分类、商品品牌、价格区间、库存对检索结果进行过滤,对检索结果进行排序* 、分页、对商品名称中的检索关键字进行高亮,对所有检索结果进行聚合分析* @author Earl* @version 1.0.0* @创建日期 2024/09/06* @since 1.0.0* @param param*/private SearchRequest buildSearchRequest(SearchParam param) {SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();//功能包括: 模糊匹配关键字、按照属性值、商品分类、商品品牌、价格区间、库存对检索结果进行过滤,对检索结果进行排序//、分页、对商品名称中的检索关键字进行高亮,对所有检索结果进行聚合分析SearchRequest searchRequest = new SearchRequest(new String[]{EsConstant.PRODUCT_INDEX}, sourceBuilder);return searchRequest;}[构建query语句]
我这里的
nested语句还是按照上面的DSL语句处理的,雷神的处理方式是在filter语句中创建多个nested语句,导致处理方式变化的原因是nestedBoolQueryBuilder.must()方法无法传参多个QueryBuilders,但是又需要同时包含term语句和terms语句,让term和terms处于不同的must中就剥离了属性id和属性值的与运算;我这里的处理方式是在must中再构建一个query语句,在query语句中,实际上我的处理方法是不行的,细节看must语句的分析通过
searchSourceBuilder.query(boolQueryBuilder)在构建好boolQueryBuilder后再构建最外层的query语句通过
QueryBuilders.matchQuery("skuTitle",param.getKeyword())来构建在属性skuTitle中模糊匹配的关键字keyword的match语句通过
QueryBuilders.termQuery("catelogId",param.getCatelog3Id())构建精确匹配非text属性catelogId的term语句通过
QueryBuilders.termsQuery("brandId",param.getBrandIds())来构建一个属性brandId的多值匹配的terms语句,这个暂时也认为是非text精确匹配通过
QueryBuilders.nestedQuery("attrs",nestedBoolQueryBuilder,ScoreMode.None)来构建nested类型属性attrs的nested匹配语句,nestedBoolQueryBuilder实际就是QueryBuilders.boolQuery(),ScoreMode.None是当前nested类型匹配不计入文档评分,返回通过
QueryBuilders.boolQuery()构建bool语句,返回BoolQueryBuilder,通过该对象的上述方法构建或关系的查询匹配语句通过
QueryBuilders.rangeQuery("skuPrice")构建针对属性skuPrice的range匹配范围语句,通过返回对象的gte方法指定范围区间低值,通过返回对象的lte方法指定范围区间高值,不指定高低值默认为null,分别对应0和无穷大通过
boolQueryBuilder.filter(QueryBuilder queryBuilder)来在同一个filter语句中构建多个子查询语句,这里的queryBuilder一般通过上述方法获取通过
boolQueryBuilder.must(QueryBuilder queryBuilder)来在bool语句下构建must语句,must语句中一般使用term或terms语句,同一个boolQueryBuilder对象多次调用must方法是在同一个must语句中添加子查询语句,这些子查询语句都必须同时满足的记录才会被检索出来
xxxxxxxxxxprivate SearchRequest buildSearchRequest(SearchParam param) {SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();//1. 构建query查询语句BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();//1.1 如果检索关键字不为空,将match_all语句封装到must语句中,将must语句封装到query语句中if (!StringUtils.isEmpty(param.getKeyword())) {boolQueryBuilder.must(QueryBuilders.matchQuery("skuTitle",param.getKeyword()));}//1.2 如果三级商品分类id不为空,将term语句封装到filter语句中,将filter语句封装到query语句中if (param.getCatelog3Id() != null) {boolQueryBuilder.filter(QueryBuilders.termQuery("catelogId",param.getCatelog3Id()));}//1.3 如果品牌id不为空且元素个数大于0,将terms语句封装到filter语句中,将filter语句封装到query语句中if (param.getBrandIds() != null && param.getBrandIds().size()>0) {boolQueryBuilder.filter(QueryBuilders.termsQuery("brandId",param.getBrandIds()));}//1.4 如果属性不为空且元素个数大于0,将term和terms语句封装到must语句中,将must语句封装到bool语句中,将bool语句封装到nested语句中,// 将nested语句封装到filter语句中,将filter语句封装到query语句中if (param.getAttrs() != null && param.getAttrs().size()>0) {/*比较一下和上面最终生成的DSL语句的区别,这段是老师的,如果上面的不对再用老师的试一下*/for (String attr:param.getAttrs()) {//封装属性的query语句BoolQueryBuilder nestedBoolQueryBuilder = QueryBuilders.boolQuery();//对属性进行处理,属性信息格式为attrs=属性id1_属性值1:属性值2String[] attrObject = attr.split("_");String[] attrValue = attrObject[1].split(":");nestedBoolQueryBuilder.must(QueryBuilders.termQuery("attrs.attrId",attrObject[0])).must(QueryBuilders.termsQuery("attrs.attrValue",attrValue));boolQueryBuilder.filter(QueryBuilders.nestedQuery("attrs",nestedBoolQueryBuilder,ScoreMode.None));}}//1.5 如果是否显示有无货不为空,将term语句封装到filter语句中,将filter语句封装到query语句中if (param.getHasStock() != null) {boolQueryBuilder.filter(QueryBuilders.termQuery("hasStock",param.getHasStock()==1));}//1.6 如果价格区间不为空,将range语句封装到filter中,将filter语句封装到query语句中if(!StringUtils.isEmpty(param.getSkuPrice())){String skuPrice = param.getSkuPrice().trim();String[] skuPriceArr = skuPrice.split("_");if(skuPriceArr.length==1){boolQueryBuilder.filter(QueryBuilders.rangeQuery("skuPrice").gte(skuPriceArr[0]));}else {boolQueryBuilder.filter(QueryBuilders.rangeQuery("skuPrice").lte("".equals(skuPriceArr[0])?0:skuPriceArr[0]).gte(skuPriceArr[1]));}}//构建query语句sourceBuilder.query(boolQueryBuilder);SearchRequest searchRequest = new SearchRequest(new String[]{EsConstant.PRODUCT_INDEX}, sourceBuilder);return searchRequest;}[构建排序、分页、高亮]
排序用
searchSourceBuilder.sort(String path,SortOrder order)来设置path属性的排序规则分页用
searchSourceBuilder.from(int fromIndex)设置首条记录的位置,用searchSourceBuilder.size(int size)设置每页记录数,即使没有设置分页参数也要设置默认分页数据让当前页码pageNum为第一页,定义一个每页商品记录数size常量;当用户指定页码后当前页pageNum为用户指定页码,DSL语句中的from=(pageNum-1)*size,size就使用设置的常量即可,这里size设置为2是商品数据量较小,方便查看分页效果高亮只有有
keyword对商品名称进行模糊匹配的时候才能用,通过searchSourceBuilder.highlighter(HighlightBuilder highlightBuilder)传参HighlightBuilder对象,通过HighlightBuilder.field(String field)指定对哪个属性的匹配关键字进行高亮,通过HighlightBuilder.preTags(String preTag)指定高亮标签前缀,通过HighlightBuilder.postTags(String postTag)后缀
xxxxxxxxxxprivate SearchRequest buildSearchRequest(SearchParam param) {SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();//功能包括: 模糊匹配关键字、按照属性值、商品分类、商品品牌、价格区间、库存对检索结果进行过滤,对检索结果进行排序//、分页、对商品名称中的检索关键字进行高亮,对所有检索结果进行聚合分析//1. 构建query查询语句BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();//1.1 如果检索关键字不为空,将match_all语句封装到must语句中,将must语句封装到query语句中if (!StringUtils.isEmpty(param.getKeyword())) {boolQueryBuilder.must(QueryBuilders.matchQuery("skuTitle",param.getKeyword()));}//1.2 如果三级商品分类id不为空,将term语句封装到filter语句中,将filter语句封装到query语句中if (param.getCatelog3Id() != null) {boolQueryBuilder.filter(QueryBuilders.termQuery("catelogId",param.getCatelog3Id()));}//1.3 如果品牌id不为空且元素个数大于0,将terms语句封装到filter语句中,将filter语句封装到query语句中if (param.getBrandIds() != null && param.getBrandIds().size()>0) {boolQueryBuilder.filter(QueryBuilders.termsQuery("brandId",param.getBrandIds()));}//1.4 如果属性不为空且元素个数大于0,将term和terms语句封装到must语句中,将must语句封装到bool语句中,将bool语句封装到nested语句中,// 将nested语句封装到filter语句中,将filter语句封装到query语句中if (param.getAttrs() != null && param.getAttrs().size()>0) {/*比较一下和上面最终生成的DSL语句的区别,这段是老师的,如果上面的不对再用老师的试一下*/for (String attr:param.getAttrs()) {//封装属性的query语句BoolQueryBuilder nestedBoolQueryBuilder = QueryBuilders.boolQuery();//对属性进行处理,属性信息格式为attrs=属性id1_属性值1:属性值2String[] attrObject = attr.split("_");String[] attrValue = attrObject[1].split(":");nestedBoolQueryBuilder.must(QueryBuilders.termQuery("attrs.attrId",attrObject[0])).must(QueryBuilders.termsQuery("attrs.attrValue",attrValue));boolQueryBuilder.filter(QueryBuilders.nestedQuery("attrs",nestedBoolQueryBuilder,ScoreMode.None));}}//1.5 如果是否显示有无货不为空,将term语句封装到filter语句中,将filter语句封装到query语句中if (param.getHasStock() != null) {boolQueryBuilder.filter(QueryBuilders.termQuery("hasStock",param.getHasStock()==1));}//1.6 如果价格区间不为空,将range语句封装到filter中,将filter语句封装到query语句中if(!StringUtils.isEmpty(param.getSkuPrice())){String skuPrice = param.getSkuPrice().trim();String[] skuPriceArr = skuPrice.split("_");if(skuPriceArr.length==1){boolQueryBuilder.filter(QueryBuilders.rangeQuery("skuPrice").gte(skuPriceArr[0]).lte(Long.MAX_VALUE));}else {boolQueryBuilder.filter(QueryBuilders.rangeQuery("skuPrice").gte("".equals(skuPriceArr[0])?0:skuPriceArr[0]).lte(skuPriceArr[1]));}}sourceBuilder.query(boolQueryBuilder);//2. 排序、分页、高亮//2.1 排序if (!StringUtils.isEmpty(param.getSort())) {String[] sortPolicy = param.getSort().split("_");sourceBuilder.sort(sortPolicy[0],"asc".equalsIgnoreCase(sortPolicy[1])? SortOrder.ASC:SortOrder.DESC);}//2.2 分页//from=(pageNum-1)*size,分页即使用户不指定也要有默认设置sourceBuilder.from((param.getPageNum()-1)*EsConstant.PRODUCT_PAGE_SIZE);sourceBuilder.size(EsConstant.PRODUCT_PAGE_SIZE);//2.3 高亮if (!StringUtils.isEmpty(param.getKeyword())) {HighlightBuilder highlightBuilder = new HighlightBuilder().field("skuTitle").preTags("<b style='color:red'>").postTags("</b>");sourceBuilder.highlighter(highlightBuilder);}//3. 聚合分析//打印SearchSourceBuilder即DSL语句System.out.println("构建的DSL语句:"+sourceBuilder);SearchRequest searchRequest = new SearchRequest(new String[]{EsConstant.PRODUCT_INDEX}, sourceBuilder);return searchRequest;}请求测试
请求路径:
http://localhost:12000/list.html?keyword=华为&catelog3Id=225&attrs=11_海思芯片:Apple芯片&attrs=3_LIO-AL00;是;否:LIO-AL00&skuPrice=12_6000上述代码生成的DSL语句
这里第二个
"query"下面的都是默认配置,不加也是一样的默认值
xxxxxxxxxxGET mall_product/_search{"from": 0,"size": 2,"query": {"bool": {"must": [{"match": {"skuTitle": {"query": "华为","operator": "OR","prefix_length": 0,"max_expansions": 50,"fuzzy_transpositions": true,"lenient": false,"zero_terms_query": "NONE","auto_generate_synonyms_phrase_query": true,"boost": 1}}}],"filter": [{"term": {"catelogId": {"value": 225,"boost": 1}}},{"nested": {"query": {"bool": {"must": [{"term": {"attrs.attrId": {"value": "11","boost": 1}}},{"terms": {"attrs.attrValue": ["海思芯片","Apple芯片"],"boost": 1}}],"adjust_pure_negative": true,"boost": 1}},"path": "attrs","ignore_unmapped": false,"score_mode": "none","boost": 1}},{"nested": {"query": {"bool": {"must": [{"term": {"attrs.attrId": {"value": "3","boost": 1}}},{"terms": {"attrs.attrValue": ["LIO-AL00;是;否","LIO-AL00"],"boost": 1}}],"adjust_pure_negative": true,"boost": 1}},"path": "attrs","ignore_unmapped": false,"score_mode": "none","boost": 1}},{"range": {"skuPrice": {"from": "12","to": "6000","include_lower": true,"include_upper": true,"boost": 1}}}],"adjust_pure_negative": true,"boost": 1}},"highlight": {"pre_tags": ["<b style='color:red'>"],"post_tags": ["</b>"],"fields": {"skuTitle": {}}}}响应结果
实际上每种传参情况都验证过了,没有问题
xxxxxxxxxx{"took" : 3,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 4,"relation" : "eq"},"max_score" : 0.5949395,"hits" : [{"_index" : "mall_product","_type" : "_doc","_id" : "5","_score" : 0.5949395,"_source" : {"attrs" : [{"attrId" : 3,"attrName" : "入网型号","attrValue" : "LIO-AL00;是;否"},{"attrId" : 11,"attrName" : "CPU品牌","attrValue" : "海思芯片"}],"brandId" : 4,"brandImg" : "https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/03/ca1e4c86-a0f0-4a46-8fa9-db8f92bbc0a1_huawei.png","brandName" : "华为","catelogId" : 225,"catelogName" : "手机","hasStock" : false,"hotScore" : 0,"saleCount" : 0,"skuId" : 5,"skuImg" : "https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/26//e87743d5-526d-467b-855d-6213f64b0965_0d40c24b264aa511.jpg","skuPrice" : 5699.0,"skuTitle" : "华为 HUAWEI Mate60 Pro 星河银 128G 旗舰新品手机","spuId" : 5},"highlight" : {"skuTitle" : ["<b style='color:red'>华为</b> HUAWEI Mate60 Pro 星河银 128G 旗舰新品手机"]}},{"_index" : "mall_product","_type" : "_doc","_id" : "7","_score" : 0.5949395,"_source" : {"attrs" : [{"attrId" : 3,"attrName" : "入网型号","attrValue" : "LIO-AL00;是;否"},{"attrId" : 11,"attrName" : "CPU品牌","attrValue" : "海思芯片"}],"brandId" : 4,"brandImg" : "https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/03/ca1e4c86-a0f0-4a46-8fa9-db8f92bbc0a1_huawei.png","brandName" : "华为","catelogId" : 225,"catelogName" : "手机","hasStock" : true,"hotScore" : 0,"saleCount" : 0,"skuId" : 7,"skuImg" : "https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/26//41a828f9-1d32-47ab-8254-be59861dc98e_28f296629cca865e.jpg","skuPrice" : 5699.0,"skuTitle" : "华为 HUAWEI Mate60 Pro 亮黑色 128G 旗舰新品手机","spuId" : 5},"highlight" : {"skuTitle" : ["<b style='color:red'>华为</b> HUAWEI Mate60 Pro 亮黑色 128G 旗舰新品手机"]}}]}}
[聚合分析]
不论在何种情况下都要对检索页面展示数据进行聚合分析
对查询到的所有商品记录聚合分析出包含的所有品牌id、品牌名、品牌商标;商品分类id、商品分类名称;所有属性id、属性名称和对应属性id下的全部可能存在的属性值
DSL模板
xxxxxxxxxx{"@WEB API": "GET mall_product/_search","query": {},"aggs": {"brand_agg": {"terms": {"field": "brandId","size": 10},"aggs": {"brand_name_agg": {"terms": {"field": "brandName","size": 10}},"brand_img_agg": {"terms": {"field": "brandImg","size": 10}}}},"catelog_agg": {"terms": {"field": "catelogId","size": 10},"aggs": {"catelog_name_agg": {"terms": {"field": "catelogName","size": 10}}}},"attrs_agg": {"nested": {"path": "attrs"},"aggs": {"attrs_id_agg": {"terms": {"field": "attrs.attrId","size": 10},"aggs": {"attr_name_agg": {"terms": {"field": "attrs.attrName","size": 10}},"attr_value_agg": {"terms": {"field": "attrs.attrValue","size": 10}}}}}}},"sort": {},"from": 0,"size": 20,"highlight": {}}聚合分析Java代码
映射关系
xxxxxxxxxxGET mall_product/_mapping{"mall_product" : {"mappings" : {"properties" : {"attrs" : {"type" : "nested","properties" : {"attrId" : {"type" : "long"},"attrName" : {"type" : "keyword"},"attrValue" : {"type" : "keyword"}}},"brandId" : {"type" : "long"},"brandImg" : {"type" : "keyword"},"brandName" : {"type" : "keyword"},"catelogId" : {"type" : "long"},"catelogName" : {"type" : "keyword"},"hasStock" : {"type" : "boolean"},"hotScore" : {"type" : "long"},"saleCount" : {"type" : "long"},"skuId" : {"type" : "long"},"skuImg" : {"type" : "keyword"},"skuPrice" : {"type" : "keyword"},"skuTitle" : {"type" : "text","analyzer" : "ik_smart"},"spuId" : {"type" : "keyword"}}}}}文档数据
xxxxxxxxxxGET mall_product/_search{"from": 0,"size": 12,"query": {"match_all": {}}}#响应数据{"took":0,"timed_out":false,"_shards":{"total":1,"successful":1,"skipped":0,"failed":0},"hits":{"total":{"value":12,"relation":"eq"},"max_score":1.0,"hits":[{"_index":"mall_product","_type":"_doc","_id":"5","_score":1.0,"_source":{"attrs":[{"attrId":3,"attrName":"入网型号","attrValue":"LIO-AL00;是;否"},{"attrId":11,"attrName":"CPU品牌","attrValue":"海思芯片"}],"brandId":4,"brandImg":"https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/03/ca1e4c86-a0f0-4a46-8fa9-db8f92bbc0a1_huawei.png","brandName":"华为","catelogId":225,"catelogName":"手机","hasStock":false,"hotScore":0,"saleCount":0,"skuId":5,"skuImg":"https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/26//e87743d5-526d-467b-855d-6213f64b0965_0d40c24b264aa511.jpg","skuPrice":5699.0,"skuTitle":"华为 HUAWEI Mate60 Pro 星河银 128G 旗舰新品手机","spuId":5}},{"_index":"mall_product","_type":"_doc","_id":"6","_score":1.0,"_source":{"attrs":[{"attrId":3,"attrName":"入网型号","attrValue":"LIO-AL00;是;否"},{"attrId":11,"attrName":"CPU品牌","attrValue":"海思芯片"}],"brandId":4,"brandImg":"https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/03/ca1e4c86-a0f0-4a46-8fa9-db8f92bbc0a1_huawei.png","brandName":"华为","catelogId":225,"catelogName":"手机","hasStock":true,"hotScore":0,"saleCount":0,"skuId":6,"skuImg":"https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/26//e87743d5-526d-467b-855d-6213f64b0965_0d40c24b264aa511.jpg","skuPrice":6299.0,"skuTitle":"华为 HUAWEI Mate60 Pro 星河银 256G 旗舰新品手机","spuId":5}},{"_index":"mall_product","_type":"_doc","_id":"7","_score":1.0,"_source":{"attrs":[{"attrId":3,"attrName":"入网型号","attrValue":"LIO-AL00;是;否"},{"attrId":11,"attrName":"CPU品牌","attrValue":"海思芯片"}],"brandId":4,"brandImg":"https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/03/ca1e4c86-a0f0-4a46-8fa9-db8f92bbc0a1_huawei.png","brandName":"华为","catelogId":225,"catelogName":"手机","hasStock":true,"hotScore":0,"saleCount":0,"skuId":7,"skuImg":"https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/26//41a828f9-1d32-47ab-8254-be59861dc98e_28f296629cca865e.jpg","skuPrice":5699.0,"skuTitle":"华为 HUAWEI Mate60 Pro 亮黑色 128G 旗舰新品手机","spuId":5}},{"_index":"mall_product","_type":"_doc","_id":"8","_score":1.0,"_source":{"attrs":[{"attrId":3,"attrName":"入网型号","attrValue":"LIO-AL00;是;否"},{"attrId":11,"attrName":"CPU品牌","attrValue":"海思芯片"}],"brandId":4,"brandImg":"https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/03/ca1e4c86-a0f0-4a46-8fa9-db8f92bbc0a1_huawei.png","brandName":"华为","catelogId":225,"catelogName":"手机","hasStock":false,"hotScore":0,"saleCount":0,"skuId":8,"skuImg":"https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/26//41a828f9-1d32-47ab-8254-be59861dc98e_28f296629cca865e.jpg","skuPrice":6299.0,"skuTitle":"华为 HUAWEI Mate60 Pro 亮黑色 256G 旗舰新品手机","spuId":5}},{"_index":"mall_product","_type":"_doc","_id":"9","_score":1.0,"_source":{"attrs":[{"attrId":3,"attrName":"入网型号","attrValue":"LIO-AL00;是;否"},{"attrId":11,"attrName":"CPU品牌","attrValue":"海思芯片"}],"brandId":4,"brandImg":"https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/03/ca1e4c86-a0f0-4a46-8fa9-db8f92bbc0a1_huawei.png","brandName":"华为","catelogId":225,"catelogName":"手机","hasStock":false,"hotScore":0,"saleCount":0,"skuId":9,"skuImg":"https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/26//14351e50-0f05-44c6-8b5f-ca96781ec61d_1f15cdbcf9e1273c.jpg","skuPrice":5699.0,"skuTitle":"华为 HUAWEI Mate60 Pro 翡冷翠 128G 旗舰新品手机","spuId":5}},{"_index":"mall_product","_type":"_doc","_id":"10","_score":1.0,"_source":{"attrs":[{"attrId":3,"attrName":"入网型号","attrValue":"LIO-AL00;是;否"},{"attrId":11,"attrName":"CPU品牌","attrValue":"海思芯片"}],"brandId":4,"brandImg":"https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/03/ca1e4c86-a0f0-4a46-8fa9-db8f92bbc0a1_huawei.png","brandName":"华为","catelogId":225,"catelogName":"手机","hasStock":false,"hotScore":0,"saleCount":0,"skuId":10,"skuImg":"https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/26//14351e50-0f05-44c6-8b5f-ca96781ec61d_1f15cdbcf9e1273c.jpg","skuPrice":6299.0,"skuTitle":"华为 HUAWEI Mate60 Pro 翡冷翠 256G 旗舰新品手机","spuId":5}},{"_index":"mall_product","_type":"_doc","_id":"11","_score":1.0,"_source":{"attrs":[{"attrId":3,"attrName":"入网型号","attrValue":"LIO-AL00;是;否"},{"attrId":11,"attrName":"CPU品牌","attrValue":"海思芯片"}],"brandId":4,"brandImg":"https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/03/ca1e4c86-a0f0-4a46-8fa9-db8f92bbc0a1_huawei.png","brandName":"华为","catelogId":225,"catelogName":"手机","hasStock":false,"hotScore":0,"saleCount":0,"skuId":11,"skuImg":"https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/26//e87743d5-526d-467b-855d-6213f64b0965_0d40c24b264aa511.jpg","skuPrice":5699.0,"skuTitle":"华为 HUAWEI Mate60 Pro 罗兰紫 128G 旗舰新品手机","spuId":5}},{"_index":"mall_product","_type":"_doc","_id":"12","_score":1.0,"_source":{"attrs":[{"attrId":3,"attrName":"入网型号","attrValue":"LIO-AL00;是;否"},{"attrId":11,"attrName":"CPU品牌","attrValue":"海思芯片"}],"brandId":4,"brandImg":"https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/03/ca1e4c86-a0f0-4a46-8fa9-db8f92bbc0a1_huawei.png","brandName":"华为","catelogId":225,"catelogName":"手机","hasStock":false,"hotScore":0,"saleCount":0,"skuId":12,"skuImg":"https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/26//e87743d5-526d-467b-855d-6213f64b0965_0d40c24b264aa511.jpg","skuPrice":6299.0,"skuTitle":"华为 HUAWEI Mate60 Pro 罗兰紫 256G 旗舰新品手机","spuId":5}},{"_index":"mall_product","_type":"_doc","_id":"13","_score":1.0,"_source":{"attrs":[{"attrId":3,"attrName":"入网型号","attrValue":"LIO-AL00"},{"attrId":11,"attrName":"CPU品牌","attrValue":"Apple芯片"}],"brandId":7,"brandImg":"https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/03/52b9cc92-6df9-427a-8fcc-c94c413b3e94_apple.png","brandName":"Apple","catelogId":225,"catelogName":"手机","hasStock":false,"hotScore":0,"saleCount":0,"skuId":13,"skuPrice":5000.0,"skuTitle":"Apple XR 红 128G","spuId":6}},{"_index":"mall_product","_type":"_doc","_id":"14","_score":1.0,"_source":{"attrs":[{"attrId":3,"attrName":"入网型号","attrValue":"LIO-AL00"},{"attrId":11,"attrName":"CPU品牌","attrValue":"Apple芯片"}],"brandId":7,"brandImg":"https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/03/52b9cc92-6df9-427a-8fcc-c94c413b3e94_apple.png","brandName":"Apple","catelogId":225,"catelogName":"手机","hasStock":false,"hotScore":0,"saleCount":0,"skuId":14,"skuPrice":6000.0,"skuTitle":"Apple XR 红 256G","spuId":6}},{"_index":"mall_product","_type":"_doc","_id":"15","_score":1.0,"_source":{"attrs":[{"attrId":3,"attrName":"入网型号","attrValue":"LIO-AL00"},{"attrId":11,"attrName":"CPU品牌","attrValue":"Apple芯片"}],"brandId":7,"brandImg":"https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/03/52b9cc92-6df9-427a-8fcc-c94c413b3e94_apple.png","brandName":"Apple","catelogId":225,"catelogName":"手机","hasStock":false,"hotScore":0,"saleCount":0,"skuId":15,"skuPrice":5000.0,"skuTitle":"Apple XR 黑 128G","spuId":6}},{"_index":"mall_product","_type":"_doc","_id":"16","_score":1.0,"_source":{"attrs":[{"attrId":3,"attrName":"入网型号","attrValue":"LIO-AL00"},{"attrId":11,"attrName":"CPU品牌","attrValue":"Apple芯片"}],"brandId":7,"brandImg":"https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/03/52b9cc92-6df9-427a-8fcc-c94c413b3e94_apple.png","brandName":"Apple","catelogId":225,"catelogName":"手机","hasStock":false,"hotScore":0,"saleCount":0,"skuId":16,"skuPrice":6000.0,"skuTitle":"Apple XR 黑 256G","spuId":6}}]}}请求路径
http://localhost:12000/list.html?keyword=华为&catelog3Id=225&attrs=11_海思芯片:Apple芯片&attrs=3_LIO-AL00;是;否:LIO-AL00&skuPrice=12_6000聚合分析语句的子语句比如term语句、terms语句都由
AggregationBuilders构建,aggregationBuilders.terms(String aggName)是构建自定义聚合aggName下的terms语句,对应的field属性和size属性通过对应的同名方法指定,注意聚合没有term语句[因为term是单属性值匹配,不适合这种对属性值分组分析场景]termsAggregationBuilder.subAggregation(AggregationBuilder aggregationBuilder)是构建子聚合,子聚合的具体内容一般也是通过aggregationBuilders.terms(String aggName)通过terms来做聚合searchSourceBuilder.aggregation(AggregationBuilder aggregationBuilder)可以调用多个将多个聚合操作放在DSL语句中的同一个aggregations语句下
xxxxxxxxxx/*** @return {@link SearchRequest }* @描述 通过用户检索传参构建检索请求* 功能包括: 模糊匹配关键字、按照属性值、商品分类、商品品牌、价格区间、库存对检索结果进行过滤,对检索结果进行排序* 、分页、对商品名称中的检索关键字进行高亮,对所有检索结果进行聚合分析* @author Earl* @version 1.0.0* @创建日期 2024/09/06* @since 1.0.0* @param param*/private SearchRequest buildSearchRequest(SearchParam param) {SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();//功能包括: 模糊匹配关键字、按照属性值、商品分类、商品品牌、价格区间、库存对检索结果进行过滤,对检索结果进行排序//、分页、对商品名称中的检索关键字进行高亮,对所有检索结果进行聚合分析//1. 构建query查询语句BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();//1.1 如果检索关键字不为空,将match_all语句封装到must语句中,将must语句封装到query语句中if (!StringUtils.isEmpty(param.getKeyword())) {boolQueryBuilder.must(QueryBuilders.matchQuery("skuTitle",param.getKeyword()));}//1.2 如果三级商品分类id不为空,将term语句封装到filter语句中,将filter语句封装到query语句中if (param.getCatelog3Id() != null) {boolQueryBuilder.filter(QueryBuilders.termQuery("catelogId",param.getCatelog3Id()));}//1.3 如果品牌id不为空且元素个数大于0,将terms语句封装到filter语句中,将filter语句封装到query语句中if (param.getBrandIds() != null && param.getBrandIds().size()>0) {boolQueryBuilder.filter(QueryBuilders.termsQuery("brandId",param.getBrandIds()));}//1.4 如果属性不为空且元素个数大于0,将term和terms语句封装到must语句中,将must语句封装到bool语句中,将bool语句封装到nested语句中,// 将nested语句封装到filter语句中,将filter语句封装到query语句中if (param.getAttrs() != null && param.getAttrs().size()>0) {/*比较一下和上面最终生成的DSL语句的区别,这段是老师的,如果上面的不对再用老师的试一下*/for (String attr:param.getAttrs()) {//封装属性的query语句BoolQueryBuilder nestedBoolQueryBuilder = QueryBuilders.boolQuery();//对属性进行处理,属性信息格式为attrs=属性id1_属性值1:属性值2String[] attrObject = attr.split("_");String[] attrValue = attrObject[1].split(":");nestedBoolQueryBuilder.must(QueryBuilders.termQuery("attrs.attrId",attrObject[0])).must(QueryBuilders.termsQuery("attrs.attrValue",attrValue));boolQueryBuilder.filter(QueryBuilders.nestedQuery("attrs",nestedBoolQueryBuilder,ScoreMode.None));}}//1.5 如果是否显示有无货不为空,将term语句封装到filter语句中,将filter语句封装到query语句中if (param.getHasStock() != null) {boolQueryBuilder.filter(QueryBuilders.termQuery("hasStock",param.getHasStock()==1));}//1.6 如果价格区间不为空,将range语句封装到filter中,将filter语句封装到query语句中if(!StringUtils.isEmpty(param.getSkuPrice())){String skuPrice = param.getSkuPrice().trim();String[] skuPriceArr = skuPrice.split("_");if(skuPriceArr.length==1){boolQueryBuilder.filter(QueryBuilders.rangeQuery("skuPrice").gte(skuPriceArr[0]).lte(Long.MAX_VALUE));}else {boolQueryBuilder.filter(QueryBuilders.rangeQuery("skuPrice").gte("".equals(skuPriceArr[0])?0:skuPriceArr[0]).lte(skuPriceArr[1]));}}//构建query语句sourceBuilder.query(boolQueryBuilder);//2. 排序、分页、高亮//2.1 排序if (!StringUtils.isEmpty(param.getSort())) {String[] sortPolicy = param.getSort().split("_");sourceBuilder.sort(sortPolicy[0],"asc".equalsIgnoreCase(sortPolicy[1])? SortOrder.ASC:SortOrder.DESC);}//2.2 分页//from=(pageNum-1)*size,分页即使用户不指定也要有默认设置sourceBuilder.from((param.getPageNum()-1)*EsConstant.PRODUCT_PAGE_SIZE);sourceBuilder.size(EsConstant.PRODUCT_PAGE_SIZE);//2.3 高亮if (!StringUtils.isEmpty(param.getKeyword())) {HighlightBuilder highlightBuilder = new HighlightBuilder().field("skuTitle").preTags("<b style='color:red'>").postTags("</b>");sourceBuilder.highlighter(highlightBuilder);}//3. 聚合分析,对查询到的所有商品记录聚合分析出包含的所有品牌id、品牌名、品牌商标;// 商品分类id、商品分类名称;// 所有属性id、属性名称和对应属性id下的全部可能存在的属性值//3.1 聚合分析出所有商品记录的所有品牌id、品牌名、品牌商标TermsAggregationBuilder brand_agg = AggregationBuilders.terms("brand_agg");brand_agg.field("brandId").size(20);//子聚合得到对应品牌id的名字和图标brand_agg.subAggregation(AggregationBuilders.terms("brand_name_agg").field("brandName").size(1));brand_agg.subAggregation(AggregationBuilders.terms("brand_img_agg").field("brandImg").size(1));sourceBuilder.aggregation(brand_agg);//3.2 聚合分析出所有商品记录的所有商品分类id和对应的商品分类名称TermsAggregationBuilder catelog_agg = AggregationBuilders.terms("catelog_agg");catelog_agg.field("catelogId").size(20);//子聚合得到对应商品分类的名字catelog_agg.subAggregation(AggregationBuilders.terms("catelog_name_agg").field("catelogName").size(1));sourceBuilder.aggregation(catelog_agg);//3.3 聚合分析所有商品记录的所有属性值和对应的所有属性值//准备属性聚合对象attrs_agg采用NestedAggregationBuilderNestedAggregationBuilder attrs_agg = AggregationBuilders.nested("attrs_agg", "attrs");//属性聚合对象对属性id子聚合采用TermsAggregationBuilderTermsAggregationBuilder attrs_id_agg = AggregationBuilders.terms("attrs_id_agg").field("attrs.attrId").size(50);//属性id聚合对象对属性名字和可能属性子聚合采用TermsAggregationBuilderattrs_id_agg.subAggregation(AggregationBuilders.terms("attr_name_agg").field("attrs.attrName").size(1));attrs_id_agg.subAggregation(AggregationBuilders.terms("attr_value_agg").field("attrs.attrValue").size(50));//让NestedAggregationBuilder和TermsAggregationBuilder形成父子聚合关系attrs_agg.subAggregation(attrs_id_agg);//把属性聚合加入到DSL检索语句中sourceBuilder.aggregation(attrs_agg);//打印SearchSourceBuilder即DSL语句System.out.println("构建的DSL语句:"+sourceBuilder);SearchRequest searchRequest = new SearchRequest(new String[]{EsConstant.PRODUCT_INDEX}, sourceBuilder);return searchRequest;}对应代码构建的DSL语句
xxxxxxxxxxGET mall_product/_search{"from": 0,"size": 2,"query": {"bool": {"must": [{"match": {"skuTitle": {"query": "华为","operator": "OR","prefix_length": 0,"max_expansions": 50,"fuzzy_transpositions": true,"lenient": false,"zero_terms_query": "NONE","auto_generate_synonyms_phrase_query": true,"boost": 1}}}],"filter": [{"term": {"catelogId": {"value": 225,"boost": 1}}},{"nested": {"query": {"bool": {"must": [{"term": {"attrs.attrId": {"value": "11","boost": 1}}},{"terms": {"attrs.attrValue": ["海思芯片","Apple芯片"],"boost": 1}}],"adjust_pure_negative": true,"boost": 1}},"path": "attrs","ignore_unmapped": false,"score_mode": "none","boost": 1}},{"nested": {"query": {"bool": {"must": [{"term": {"attrs.attrId": {"value": "3","boost": 1}}},{"terms": {"attrs.attrValue": ["LIO-AL00;是;否","LIO-AL00"],"boost": 1}}],"adjust_pure_negative": true,"boost": 1}},"path": "attrs","ignore_unmapped": false,"score_mode": "none","boost": 1}},{"range": {"skuPrice": {"from": "12","to": "6000","include_lower": true,"include_upper": true,"boost": 1}}}],"adjust_pure_negative": true,"boost": 1}},"aggregations": {"brand_agg": {"terms": {"field": "brandId","size": 20,"min_doc_count": 1,"shard_min_doc_count": 0,"show_term_doc_count_error": false,"order": [{"_count": "desc"},{"_key": "asc"}]},"aggregations": {"brand_name_agg": {"terms": {"field": "brandName","size": 1,"min_doc_count": 1,"shard_min_doc_count": 0,"show_term_doc_count_error": false,"order": [{"_count": "desc"},{"_key": "asc"}]}},"brand_img_agg": {"terms": {"field": "brandImg","size": 1,"min_doc_count": 1,"shard_min_doc_count": 0,"show_term_doc_count_error": false,"order": [{"_count": "desc"},{"_key": "asc"}]}}}},"catelog_agg": {"terms": {"field": "catelogId","size": 20,"min_doc_count": 1,"shard_min_doc_count": 0,"show_term_doc_count_error": false,"order": [{"_count": "desc"},{"_key": "asc"}]},"aggregations": {"catelog_name_agg": {"terms": {"field": "catelogName","size": 1,"min_doc_count": 1,"shard_min_doc_count": 0,"show_term_doc_count_error": false,"order": [{"_count": "desc"},{"_key": "asc"}]}}}},"attrs_agg": {"nested": {"path": "attrs"},"aggregations": {"attrs_id_agg": {"terms": {"field": "attrs.attrId","size": 50,"min_doc_count": 1,"shard_min_doc_count": 0,"show_term_doc_count_error": false,"order": [{"_count": "desc"},{"_key": "asc"}]},"aggregations": {"attr_name_agg": {"terms": {"field": "attrs.attrName","size": 1,"min_doc_count": 1,"shard_min_doc_count": 0,"show_term_doc_count_error": false,"order": [{"_count": "desc"},{"_key": "asc"}]}},"attr_value_agg": {"terms": {"field": "attrs.attrValue","size": 50,"min_doc_count": 1,"shard_min_doc_count": 0,"show_term_doc_count_error": false,"order": [{"_count": "desc"},{"_key": "asc"}]}}}}}}},"highlight": {"pre_tags": ["<b style='color:red'>"],"post_tags": ["</b>"],"fields": {"skuTitle": {}}}}Kibana使用自动构建语句响应的检索结果
xxxxxxxxxx{"took" : 7,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 4,"relation" : "eq"},"max_score" : 0.5949395,"hits" : [{"_index" : "mall_product","_type" : "_doc","_id" : "5","_score" : 0.5949395,"_source" : {"attrs" : [{"attrId" : 3,"attrName" : "入网型号","attrValue" : "LIO-AL00;是;否"},{"attrId" : 11,"attrName" : "CPU品牌","attrValue" : "海思芯片"}],"brandId" : 4,"brandImg" : "https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/03/ca1e4c86-a0f0-4a46-8fa9-db8f92bbc0a1_huawei.png","brandName" : "华为","catelogId" : 225,"catelogName" : "手机","hasStock" : false,"hotScore" : 0,"saleCount" : 0,"skuId" : 5,"skuImg" : "https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/26//e87743d5-526d-467b-855d-6213f64b0965_0d40c24b264aa511.jpg","skuPrice" : 5699.0,"skuTitle" : "华为 HUAWEI Mate60 Pro 星河银 128G 旗舰新品手机","spuId" : 5},"highlight" : {"skuTitle" : ["<b style='color:red'>华为</b> HUAWEI Mate60 Pro 星河银 128G 旗舰新品手机"]}},{"_index" : "mall_product","_type" : "_doc","_id" : "7","_score" : 0.5949395,"_source" : {"attrs" : [{"attrId" : 3,"attrName" : "入网型号","attrValue" : "LIO-AL00;是;否"},{"attrId" : 11,"attrName" : "CPU品牌","attrValue" : "海思芯片"}],"brandId" : 4,"brandImg" : "https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/03/ca1e4c86-a0f0-4a46-8fa9-db8f92bbc0a1_huawei.png","brandName" : "华为","catelogId" : 225,"catelogName" : "手机","hasStock" : true,"hotScore" : 0,"saleCount" : 0,"skuId" : 7,"skuImg" : "https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/26//41a828f9-1d32-47ab-8254-be59861dc98e_28f296629cca865e.jpg","skuPrice" : 5699.0,"skuTitle" : "华为 HUAWEI Mate60 Pro 亮黑色 128G 旗舰新品手机","spuId" : 5},"highlight" : {"skuTitle" : ["<b style='color:red'>华为</b> HUAWEI Mate60 Pro 亮黑色 128G 旗舰新品手机"]}}]},"aggregations" : {"attrs_agg" : {"doc_count" : 8,"attrs_id_agg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : 3,"doc_count" : 4,"attr_name_agg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "入网型号","doc_count" : 4}]},"attr_value_agg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "LIO-AL00;是;否","doc_count" : 4}]}},{"key" : 11,"doc_count" : 4,"attr_name_agg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "CPU品牌","doc_count" : 4}]},"attr_value_agg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "海思芯片","doc_count" : 4}]}}]}},"catelog_agg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : 225,"doc_count" : 4,"catelog_name_agg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "手机","doc_count" : 4}]}}]},"brand_agg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : 4,"doc_count" : 4,"brand_img_agg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/03/ca1e4c86-a0f0-4a46-8fa9-db8f92bbc0a1_huawei.png","doc_count" : 4}]},"brand_name_agg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "华为","doc_count" : 4}]}}]}}}
封装检索结果
buildSearchResponse(SearchResponse response)封建检索结果为我们自定义响应对象业务逻辑
封装所有查询到的当前页的商品数据、
封装当前商品涉及到的所有属性聚合信息、品牌信息、商品分类信息
封装分页信息-当前页码和总记录数
检索响应结果对象的结构
Java High Level REST Client API的检索方法SearchResponse response = esRESTClient.search(searchRequest, MallElasticSearchConfig.COMMON_OPTIONS);检索响应结果对象的类型是SearchResponse对象,该对象中的internalResponse属性中封装了全部检索数据searchResponse.internalResponse.hits中封装了检索命中的记录,hits内部的属性和检索结果的结构是完全相同的总记录数
hits.getTotalHits().value获取命中记录的总记录数总页码需要自己根据总记录数和每页记录数自己运算得到,可以通过算法
总页码=(int)(总记录数-1)/每页记录数+1进行计算当前页码需要使用请求参数中的页码数据
所有记录通过
hits.getHits()获取的是每一条记录的元数据+文档信息,其中的_source属性才是真正的文档数据,hits.getHits()获取的列表其中的每个元素hit可以通过hit.getSourceAsString()可以获取到json格式的文档数据字符串,通过fastjson转换为商品对象并加入list集合
xxxxxxxxxx"hits": {"total": {"value": 4,"relation": "eq"},"max_score": 0.5949395,"hits": [{"_index": "mall_product","_type": "_doc","_id": "5","_score": 0.5949395,"_source": {"attrs": [{"attrId": 3,"attrName": "入网型号","attrValue": "LIO-AL00;是;否"},{"attrId": 11,"attrName": "CPU品牌","attrValue": "海思芯片"}],"brandId": 4,"brandImg": "https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/03/ca1e4c86-a0f0-4a46-8fa9-db8f92bbc0a1_huawei.png","brandName": "华为","catelogId": 225,"catelogName": "手机","hasStock": false,"hotScore": 0,"saleCount": 0,"skuId": 5,"skuImg": "https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/26//e87743d5-526d-467b-855d-6213f64b0965_0d40c24b264aa511.jpg","skuPrice": 5699.0,"skuTitle": "华为 HUAWEI Mate60 Pro 星河银 128G 旗舰新品手机","spuId": 5},"highlight": {"skuTitle": ["<b style='color:red'>华为</b> HUAWEI Mate60 Pro 星河银 128G 旗舰新品手机"]}},{}]}searchResponse.internalResponse.aggregations中封装了聚合分析的结果,aggregations内部的属性和检索结果的结构是完全相同的searchResponse.internalResponse.aggregations.aggregations这个ArrayList中封装了多个聚合结果,每个元素都是一个单独的聚合结果,聚合结构元素的类型不同,一般有ParsedLongTerms、ParsedNested、ParseStringTerms通过
searchResponse.getAggregations().get(String customAggregationName)可以获取对应聚合名字的聚合分析结果,注意这里的返回结果类型使用了多态,用了父类型Aggregation类型,但是我们需要子类实现来调用对应的子类方法,因为不同子实现类的聚合结果层级结构不同,父类型方法不够用注意Aggregation子实现类贼多,而且层级复杂,一般要通过打断点观察一下返回聚合结果的具体类型才能确定子实现类的类型
通过
aggregation.getBuckets()获取bucket中的聚合数据ArrayList数组,对数组中的每一个bucket元素通过bucket.getKeyAsString()获取到字符串类型的聚合分组属性值,通过bucket.getKeyAsNumber()获取到long类型的聚合分组属性值,通过bucket.getAggregations().get(String customAggregationName)获取到对应名字的子聚合,子聚合也通过上述方法获取到字符串类型的聚合分组属性值,如果子聚合确定只有一个属性值就不用对子聚合的bucket进行遍历了,可以直接通过aggregation.getBuckets().get(0)来获取bucket的key属性值❓:注意
Aggregation无法调用aggregation.getBuckets(),必须强转为子类才能调用该方法获取到聚合结果,这难道不是设计缺陷吗
xxxxxxxxxx"aggregations" : {"attrs_agg" : {"doc_count" : 8,"attrs_id_agg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : 3,"doc_count" : 4,"attr_name_agg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "入网型号","doc_count" : 4}]},"attr_value_agg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "LIO-AL00;是;否","doc_count" : 4}]}},{"key" : 11,"doc_count" : 4,"attr_name_agg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "CPU品牌","doc_count" : 4}]},"attr_value_agg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "海思芯片","doc_count" : 4}]}}]}},"catelog_agg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : 225,"doc_count" : 4,"catelog_name_agg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "手机","doc_count" : 4}]}}]},"brand_agg" : {}}
检索结果封装代码
这种方式封装的商品标题匹配的检索关键字并没有被高亮,还需要对标题进行单独封装来保证商品名称检索关键字的高亮,要高亮还需要满足检索参数中有用户输入的检索关键字才会封装高亮数据,高亮数据在与source平级的hightlight属性中封装,直接替换掉source中对应的字段即可
xxxxxxxxxx/*** @return {@link SkuSearchResult }* @描述 将检索结果封装成我们自定义的响应对象* 封装检索记录、封装聚合结果,所有记录涉及的属性和属性值、所有记录涉及的品牌、所有记录涉及的商品分类* @author Earl* @version 1.0.0* @创建日期 2024/09/06* @since 1.0.0* @param response* @param pageNum*/private SkuSearchResult buildSearchResponse(SearchResponse response, Integer pageNum) {//准备响应结果的容器SkuSearchResult result = new SkuSearchResult();//1. 封装所有检索记录SearchHit[] hits = response.getHits().getHits();ArrayList<Product> searchProducts = new ArrayList<>(hits.length);for (SearchHit hit : hits) {Product product = JSON.parseObject(hit.getSourceAsString(), Product.class);searchProducts.add(product);}result.setProducts(searchProducts);//2. 封装所有记录涉及到的商品品牌ArrayList<SkuSearchResult.BrandVo> brands = new ArrayList<>();//必须强转为子类才能调用getBuckets方法ParsedLongTerms brand_agg = (ParsedLongTerms) response.getAggregations().get("brand_agg");//2.1 获取商品品牌的idfor (Terms.Bucket bucket : brand_agg.getBuckets()) {SkuSearchResult.BrandVo brand = new SkuSearchResult.BrandVo();brand.setBrandId(Long.parseLong(bucket.getKeyAsString()));//2.2 获取商品品牌的图片ParsedStringTerms brand_img_agg = (ParsedStringTerms) bucket.getAggregations().get("brand_img_agg");brand.setBrandImg(brand_img_agg.getBuckets().get(0).getKeyAsString());//2.3 获取商品品牌的名字ParsedStringTerms brand_name_agg = (ParsedStringTerms) bucket.getAggregations().get("brand_name_agg");brand.setBrandName(brand_name_agg.getBuckets().get(0).getKeyAsString());brands.add(brand);}result.setBrands(brands);//3. 封装所有记录涉及到的商品种类ArrayList<SkuSearchResult.CatelogVo> catelogs = new ArrayList<>();ParsedLongTerms catelog_agg = (ParsedLongTerms) response.getAggregations().get("catelog_agg");//3.1 获取商品分类的idfor (Terms.Bucket bucket : catelog_agg.getBuckets()) {SkuSearchResult.CatelogVo catelog = new SkuSearchResult.CatelogVo();catelog.setCatelogId(Long.parseLong(bucket.getKeyAsString()));//3.2 获取商品分类的名字ParsedStringTerms catelog_name_agg = (ParsedStringTerms) bucket.getAggregations().get("catelog_name_agg");catelog.setCatelogName(catelog_name_agg.getBuckets().get(0).getKeyAsString());catelogs.add(catelog);}result.setCatelogs(catelogs);//4. 封装所有记录涉及到的属性种类ArrayList<SkuSearchResult.AttrVo> attrs = new ArrayList<>();ParsedNested attrs_agg = (ParsedNested) response.getAggregations().get("attrs_agg");ParsedLongTerms attrs_id_agg = (ParsedLongTerms) attrs_agg.getAggregations().get("attrs_id_agg");//4.1 获取商品属性的idfor (Terms.Bucket bucket : attrs_id_agg.getBuckets()) {SkuSearchResult.AttrVo attr = new SkuSearchResult.AttrVo();attr.setAttrId(Long.parseLong(bucket.getKeyAsString()));//4.2 获取商品属性的名字ParsedStringTerms attr_name_agg = (ParsedStringTerms) bucket.getAggregations().get("attr_name_agg");attr.setAttrName(attr_name_agg.getBuckets().get(0).getKeyAsString());//4.3 获取商品属性所有可能的属性值ArrayList<String> attrValues = new ArrayList<>();ParsedStringTerms attr_value_agg = (ParsedStringTerms) bucket.getAggregations().get("attr_value_agg");attr.setAttrValue(attr_value_agg.getBuckets().stream().map(item -> item.getKeyAsString()).collect(Collectors.toList()));attrs.add(attr);}result.setAttrs(attrs);//5. 封装分页信息//5.1 封装总记录数long total = response.getHits().getTotalHits().value;result.setTotal(total);//5.2 封装当前页码result.setPageNum(pageNum);//5.3 封装总页码数result.setTotalPages(((total - 1) / EsConstant.PRODUCT_PAGE_SIZE)+1);return result;}带高亮关键字的检索结果封装代码
xxxxxxxxxx/*** @return {@link SkuSearchResult }* @描述 将检索结果封装成我们自定义的响应对象* 封装检索记录、封装聚合结果,所有记录涉及的属性和属性值、所有记录涉及的品牌、所有记录涉及的商品分类* @author Earl* @version 1.0.0* @创建日期 2024/09/06* @since 1.0.0* @param response* @param pageNum* @param keyword*/private SkuSearchResult buildSearchResponse(SearchResponse response, Integer pageNum, String keyword) {//准备响应结果的容器SkuSearchResult result = new SkuSearchResult();//1. 封装所有检索记录SearchHit[] hits = response.getHits().getHits();ArrayList<Product> searchProducts = new ArrayList<>(hits.length);for (SearchHit hit : hits) {Product product = JSON.parseObject(hit.getSourceAsString(), Product.class);//高亮字段信息存在hits.hits的highlightFields属性中的value属性的fragment数组中if(!StringUtils.isEmpty(keyword)){product.setSkuTitle(hit.getHighlightFields().get("skuTitle").getFragments()[0].string());}searchProducts.add(product);}result.setProducts(searchProducts);//2. 封装所有记录涉及到的商品品牌Aggregations aggregations = response.getAggregations();ArrayList<SkuSearchResult.BrandVo> brands = new ArrayList<>();//必须强转为子类才能调用getBuckets方法ParsedLongTerms brand_agg = (ParsedLongTerms) aggregations.get("brand_agg");//2.1 获取商品品牌的idfor (Terms.Bucket bucket : brand_agg.getBuckets()) {SkuSearchResult.BrandVo brand = new SkuSearchResult.BrandVo();brand.setBrandId(Long.parseLong(bucket.getKeyAsString()));//2.2 获取商品品牌的图片ParsedStringTerms brand_img_agg = (ParsedStringTerms) bucket.getAggregations().get("brand_img_agg");brand.setBrandImg(brand_img_agg.getBuckets().get(0).getKeyAsString());//2.3 获取商品品牌的名字ParsedStringTerms brand_name_agg = (ParsedStringTerms) bucket.getAggregations().get("brand_name_agg");brand.setBrandName(brand_name_agg.getBuckets().get(0).getKeyAsString());brands.add(brand);}result.setBrands(brands);//3. 封装所有记录涉及到的商品种类ArrayList<SkuSearchResult.CatelogVo> catelogs = new ArrayList<>();ParsedLongTerms catelog_agg = (ParsedLongTerms) aggregations.get("catelog_agg");//3.1 获取商品分类的idfor (Terms.Bucket bucket : catelog_agg.getBuckets()) {SkuSearchResult.CatelogVo catelog = new SkuSearchResult.CatelogVo();catelog.setCatelogId(Long.parseLong(bucket.getKeyAsString()));//3.2 获取商品分类的名字ParsedStringTerms catelog_name_agg = (ParsedStringTerms) bucket.getAggregations().get("catelog_name_agg");catelog.setCatelogName(catelog_name_agg.getBuckets().get(0).getKeyAsString());catelogs.add(catelog);}result.setCatelogs(catelogs);//4. 封装所有记录涉及到的属性种类ArrayList<SkuSearchResult.AttrVo> attrs = new ArrayList<>();ParsedNested attrs_agg = (ParsedNested) aggregations.get("attrs_agg");ParsedLongTerms attrs_id_agg = (ParsedLongTerms) attrs_agg.getAggregations().get("attrs_id_agg");//4.1 获取商品属性的idfor (Terms.Bucket bucket : attrs_id_agg.getBuckets()) {SkuSearchResult.AttrVo attr = new SkuSearchResult.AttrVo();attr.setAttrId(Long.parseLong(bucket.getKeyAsString()));//4.2 获取商品属性的名字ParsedStringTerms attr_name_agg = (ParsedStringTerms) bucket.getAggregations().get("attr_name_agg");attr.setAttrName(attr_name_agg.getBuckets().get(0).getKeyAsString());//4.3 获取商品属性所有可能的属性值ArrayList<String> attrValues = new ArrayList<>();ParsedStringTerms attr_value_agg = (ParsedStringTerms) bucket.getAggregations().get("attr_value_agg");attr.setAttrValue(attr_value_agg.getBuckets().stream().map(item -> item.getKeyAsString()).collect(Collectors.toList()));attrs.add(attr);}result.setAttrs(attrs);//5. 封装分页信息//5.1 封装总记录数long total = response.getHits().getTotalHits().value;result.setTotal(total);//5.2 封装当前页码result.setPageNum(pageNum);//5.3 封装总页码数result.setTotalPages(((total - 1) / EsConstant.PRODUCT_PAGE_SIZE)+1);return result;}
前端数据渲染
商品数据渲染
通过浏览器检查元素可以定位到每个元素的具体代码位置,用Thymeleaf修改对应数据即可实现对应位置的数据渲染
th:utext标签让文本内容中的html标签正常渲染
xxxxxxxxxx<div class="rig_tab" ><div th:each="product:${searchResult.getProducts()}"><div class="ico"><i class="iconfont icon-weiguanzhu"></i><a href="#">关注</a></div><p class="da"><a href="#" th:title="${product.skuTitle}"><img th:src="${product.skuImg}" class="dim"></a></p><ul class="tab_im"><li><a href="#" title="黑色"><img th:src="${product.skuImg}"></a></li></ul><p class="tab_R"><span th:text="'¥'+${product.skuPrice}">¥5199.00</span></p><p class="tab_JE"><a href="#" th:title="${product.skuTitle}"th:utext="${product.skuTitle}">Apple iPhone 7 Plus (A1661) 32G 黑色 移动联通电信4G手机</a></p><p class="tab_PI">已有<span>11万+</span>热门评价<a href="#">二手有售</a></p><p class="tab_CP"><a href="#" title="Earl商城华为产品专营店">Earl商城华为产品...</a><a href='#' title="联系供应商进行咨询"><img src="static/search/img/xcxc.png"></a></p><div class="tab_FO"><div class="FO_one"><p>自营<span>Earl商城自营,品质保证</span></p><p>满赠<span>该商品参加满赠活动</span></p></div></div></div></div>品牌数据渲染
xxxxxxxxxx<div class="sl_value"><div class="sl_value_logo"><ul><li th:each="brand:${searchResult.brands}"><a href="#"><img th:src="${brand.brandImg}" alt=""><div th:text="${brand.brandName}">华为(HUAWEI)</div></a></li></ul></div></div>商品属性数据渲染
xxxxxxxxxx<!--商品属性--><div class="JD_pre" th:each="attr:${searchResult.attrs}"><div class="sl_key"><span th:utext="'<b>'+${attr.attrName}+'</b>'">属性名:</span></div><div class="sl_value"><ul><li th:each="attrValue:${attr.attrValue}"><a href="#" th:text="${attrValue}">5.56英寸及以上</a></li></ul></div></div>商品分类数据渲染
xxxxxxxxxx<!--商品分类--><div class="JD_pre" ><div class="sl_key"><span><b>商品分类:</b></span></div><div class="sl_value"><ul><li th:each="catelog:${searchResult.catelogs}"><a href="#" th:text="${catelog.catelogName}">5.56英寸及以上</a></li></ul></div></div>
拼接检索参数
检索页面筛选条件动态拼接
用户点击检索条件后能动态将对应检索条件拼接到请求路径中且保留原来的检索条件
html中双引号的对应字符
",在标签属性的双引号中使用单引号表示字符串,单引号中如果写函数需要传参字符串常量,字符串常量此时直接在单引号中写双引号会报错,前端
location.href就是当前页面的请求路径,对该路径修改就是直接修改当前请求路径,location.href.indexOf("?")是判断字符串中是否有问号,没有匹配到?就返回-1,如果能匹配到返回的就不是-1,前端文档推荐W3School离线手册实现逻辑是定义一个JavaScript函数,该函数的作用是将调用者的参数名和参数值拼接到当前请求路径的后面,在检索参数超链接中调用该函数并传参指定参数名和参数值,这里参数值一般都是通过Thymeleaf语法数据渲染出来的,所以这里在href中使用了th的语法
JavaScript函数
❓:该方法存在幂等性问题,即多次点击检索参数会被拼接多次,如何防止检索参数被多次拼接很关键
🔑:对JS函数进行了优化,没有强制选择新增同名参数就直接替换原来的同名参数的参数值,代码查看优化版本
xxxxxxxxxx//该方法用于在当前请求路径后拼接用户自定义的检索关键字function specifySearchParamKeyword() {specifySearchParam("keyword",$("#keyword_input").val());}//该方法被调用用于指定在当前请求参数后面拼接检索参数function specifySearchParam(paraName,paramValue){let href = location.href;if (href.indexOf("?")!=-1) {location.href=href+"&"+paraName+"="+paramValue;}else{location.href=href+"?"+paraName+"="+paramValue;}}优化版本
xxxxxxxxxx//该方法用于在当前请求路径后拼接用户自定义的检索关键字function specifySearchParamKeyword() {if($("#keyword_input").val()===''){location.href=removeParamFromUri("keyword");}else{location.href=replaceOrAddParamVal(location.href,"keyword",$("#keyword_input").val())//specifySearchParam("keyword",$("#keyword_input").val());}}//替换指定请求路径中的请求参数,如果参数已经存在就直接替换,如果参数不存在就追加参数function replaceOrAddParamVal(url,paramName,replaceVal,forceAdd=false){var oUrl = url.toString();//旧请求路径中有了就进行替换,没有对应参数就添加参数if (oUrl.indexOf(paramName+'=') != -1){if(forceAdd){return addURIParam(oUrl,paramName,replaceVal);}else{var re = eval('/('+paramName+'=)([^&]*)/gi');var nUrl = oUrl.replace(re,paramName+'='+replaceVal);return nUrl;}}else{return addURIParam(oUrl,paramName,replaceVal);}}//新增参数function addURIParam(oUrl,paramName,replaceVal){//添加参数var nUrl="";//检查旧链接中有没有问号,有问号就追加参数,没有就新增问号并添加参数if(oUrl.indexOf("?")!=-1){nUrl = oUrl+"&"+paramName+"="+replaceVal;}else{nUrl = oUrl+"?"+paramName+"="+replaceVal;}return nUrl;}选择品牌检索参数对函数的调用
"是html中的双引号,加这个双引号是为了在渲染以后的html中将第一个参数作为字符串字面值,否则调用函数时会把其识别为一个变量名,控制台报错显示第一个变量未被定义
xxxxxxxxxx<div class="sl_value"><div class="sl_value_logo"><ul><li th:each="brand:${searchResult.brands}"><a th:href="${'javascript:specifySearchParam("brandIds",'+brand.brandId+')'}"><img th:src="${brand.brandImg}" alt=""><div th:text="${brand.brandName}">华为(HUAWEI)</div></a></li></ul></div></div>选择商品属性检索参数对函数的调用
xxxxxxxxxx<!--商品属性--><div class="JD_pre" th:each="attr:${searchResult.attrs}"><div class="sl_key"><span th:utext="'<b>'+${attr.attrName}+'</b>'">属性名:</span></div><div class="sl_value"><ul><li th:each="attrValue:${attr.attrValue}"><a th:href="${'javascript:specifySearchParam("attrs","'+attr.attrId+'_'+attrValue+'")'}" th:text="${attrValue}">5.56英寸及以上</a></li></ul></div></div>选择商品分类检索参数对函数的调用
xxxxxxxxxx<!--商品分类--><div class="JD_pre" ><div class="sl_key"><span><b>商品分类:</b></span></div><div class="sl_value"><ul><li th:each="catelog:${searchResult.catelogs}"><a th:href="${'javascript:specifySearchParam("catelog3Id",'+catelog.catelogId+')'}" th:text="${catelog.catelogName}">5.56英寸及以上</a></li></ul></div></div>
检索关键字请求参数动态拼接
业务逻辑是点击搜索按钮调用JavaScript中自定义的
specifySearchParamKeyword()来通过jQuery获取输入框的值并拼接到当前请求路径后面注意超链接的
href没有指定路径而是指定的方法,会在方法执行结束后以当前的请求路径作为地址发起请求注意使用
jquery需要引入jquery,引入方式为<script src="static/search/js/jquery-1.12.4.js"></script>
搜索框
xxxxxxxxxx<div class="header_form"><input type="text" id="keyword_input" placeholder="手机" th:value="${param.keyword}"/><a href="javascript:specifySearchParamKeyword()">搜索</a></div>脚本函数
xxxxxxxxxx//该方法用于在当前请求路径后拼接用户自定义的检索关键字function specifySearchParamKeyword() {specifySearchParam("keyword",$("#keyword_input").val());}
分页框数据渲染
分页组件
Thymeleaf提供对两个数字之间的所有整数进行遍历的numbers.sequence函数,使用方法是th:each="i:${#numbers.sequence(1,totalPages)}",作用是对数字1和总页数totalPages之间的所有整数进行遍历,i是每次取出的整数这个效果是不完整的,分页数据也不是每一页都展示,可能只展示当前页的前后几页,还要跳转首页、尾页的逻辑没有实现,其中的
page_submit后面再实现;这个分页是原生HTML配合
JQuery和Thymeleaf实现的,其实使用条件是比较苛刻的,要求每次请求的页面数据都要被后端服务器渲染
xxxxxxxxxx<!--分页--><div class="filter_page"><div class="page_wrap"><span class="page_span1"><a class="page_a"th:attr="pn=${searchResult.pageNum - 1}"th:if="${searchResult.pageNum > 1}">< 上一页</a><a class="page_a"th:attr="pn=${i},style=${i == searchResult.pageNum?'border: 0;color:#ee2222;background: #fff':''}"th:each="i:${#numbers.sequence(1,searchResult.totalPages)}"th:if="${searchResult.totalPages > 0}">[[${i}]]</a><a class="page_a"th:attr="pn=${searchResult.pageNum + 1}"th:if="${searchResult.pageNum < searchResult.totalPages}">下一页 ></a></span><span class="page_span2"><em>共<b th:text="${searchResult.getTotalPages()}">169</b>页 到第</em><input type="number" value="1"><em>页</em><a class="page_submit">确定</a></span></div></div>脚本函数
注意
location.href即当前请求路径发生变化页面会自动在当前页重定向到目标请求路径
xxxxxxxxxx//使用JQuery给所有page_a类型标签绑定点击事件,点击事件的目的是将当前请求路径的pageNum参数设置为新的被点击页码的pn属性值//如果请求路径没有pageNum参数就以被点击页码按钮的pn属性值新增该参数$(".page_a").click(function (){var pn=$(this).attr("pn");var href=location.href;if(href.indexOf("pageNum")!=-1){//如果请求路径中有pageNum了就调用replaceParamVal方法替换参数pageNum的值为pn属性的值location.href = replaceParamVal(href,"pageNum",pn)}else{location.href=location.href+"?pageNum="+pn;}return false;});//替换指定请求路径中的请求参数function replaceParamVal(url,paramName,replaceVal){var oUrl = url.toString();var re = eval('/('+paramName+'=)([^&]*)/gi');var nUrl = oUrl.replace(re,paramName+'='+replaceVal);return nUrl;}
请求路径拼接排序参数实现商品排序功能
业务要求为点击销量、价格、热点评分按钮自动生成对应降序升序商品列表并调整排序按钮样式,且根据请求路径的参数对排序按钮样式进行回显
缺陷是每次重新请求以后一面都从顶部展示,能不能记住用户浏览的页面高度位置,比如用户浏览商品,重新请求以后也能自动跳转到商品列表的头部位置
点击排序按钮按钮的样式变换效果
Jquery相关API
$(".sort_a").css(样式的json对象)更改所有同名类选择器的css样式为json对象指定样式$(".sort_a").each(自定义匿名函数)对每一个同名类选择器使用自定义函数做遍历操作$(ele).toggleClass("desc")在class属性追加指定字符串desc,如果class属性已经有了该字符串就去掉指定字符串desc$(ele).hasClass("desc")检查class属性中是否有指定字符串desc,如果有返回true,如果没有返回false$(ele).text()是获取指定组件标签内的文本值,$(ele).text("str")是更改指定标签内的文本值为指定字符串str$(this).attr("sort")通过指定属性名获取对应组件的属性值,属性可以是自定义属性
组件代码
xxxxxxxxxx<div class="filter_top_left"><a class="sort_a" href="#">评论分</a><a class="sort_a" href="#">销量</a><a class="sort_a" href="#">价格</a></div>jquery点击事件
xxxxxxxxxx//点击排序按钮的点击事件$(".sort_a").click(function (){//调用changeSortedBtnStyle(ele)改变所有排序按钮状态changeSortedBtnStyle(this);//禁用组件的默认行为,比如超链接的自动跳转行为return false;});function changeSortedBtnStyle(ele){//凡是排序选项变化就重置所有排序按钮的样式到未选中状态,// 注意$(".sort_a").css()这是Jquery的用法,这些培训班真特么垃圾,这都不讲//这个样式是可以通过浏览器检查元素查看的$(".sort_a").css({"color": "#333","border-color":"#CCC","background": "#FFF"});//对每个排序按钮遍历清空上下箭头样式并在后续重新指定,$(".sort_a").each()Jquery用法$(".sort_a").each(function (){var text = $(this).text().replace("↑","").replace("↓","");$(this).text(text);});//当前选中排序按钮样式变更为被选中的样式$(ele).css({"color": "#FFF","border-color":"#e4393c","background": "#e4393c"});//改变升降序,$(ele).toggleClass()方法的作用是如果样式有对应字符串就删掉对应字符串,没有对应字符串就在class后面添加对应字符串//这里实现的效果是class属性为sort_a时点一下变成sort_a desc,为sort_a desc点一下按钮变成sort_a$(ele).toggleClass("desc");//class属性有desc就是降序排列,没有就是升序排列//如果是降序给按钮加上向下箭头,否则加向上箭头if ($(ele).hasClass("desc")) {$(ele).text($(ele).text()+"↓");}else{$(ele).text($(ele).text()+"↑");}}拼接排序参数到请求路径
这里每次拼接参数后发起请求会将原来更改的class属性从
sort_a desc覆盖成sort_a,即只能实现降序效果,需要根据请求参数对class属性以及按钮的选中状态进行回显组件代码
xxxxxxxxxx<div class="filter_top_left"><a class="sort_a" sort="hotScore" href="#">评论分</a><a class="sort_a" sort="saleCount" href="#">销量</a><a class="sort_a" sort="skuPrice" href="#">价格</a></div>点击事件
xxxxxxxxxx//点击排序按钮的点击事件$(".sort_a").click(function (){//调用changeSortedBtnStyle(ele)改变所有排序按钮状态changeSortedBtnStyle(this);//给请求路径拼接对应的排序参数var sortedAttr = $(this).attr("sort");//获取组件对应的自定义属性名,指定按照哪个属性进行排序sortedAttr=$(this).hasClass("desc")?sortedAttr+"_desc":sortedAttr+"_asc"//给请求路径拼接或者替换排序参数location.href=replaceOrAddParamVal(location.href,"sort",sortedAttr);console.log(location.href)//禁用组件的默认行为,比如超链接的自动跳转行为return false;});//替换指定请求路径中的请求参数,如果参数已经存在就直接替换,如果参数不存在就追加参数function replaceOrAddParamVal(url,paramName,replaceVal){var oUrl = url.toString();//旧请求路径中有了就进行替换,没有对应参数就添加参数if (oUrl.indexOf(paramName) != -1){var re = eval('/('+paramName+'=)([^&]*)/gi');var nUrl = oUrl.replace(re,paramName+'='+replaceVal);return nUrl;}else{//添加参数var nUrl="";//检查旧链接中有没有问号,有问号就追加参数,没有就新增问号并添加参数if(oUrl.indexOf("?")!=-1){nUrl = oUrl+"&"+paramName+"="+replaceVal;}else{nUrl = oUrl+"?"+paramName+"="+replaceVal;}return nUrl;}}根据请求路径回显排序状态
逻辑是根据请求路径使用
Thymeleaf获取到请求参数并通过SpringEL表达式确定排序按钮的回显逻辑,要求根据参数动态调整css样式选中对应的按钮、首次加载按钮不显示对应的排序提示箭头,选择排序以后显示对应的排序提示箭头,选中另一个按钮取消掉原按钮的被选中状态th:class中不允许使用param参数,会报错Access to variable "param" is forbidden in this context并提示可以在th:text中使用,可以通过th:with属性在父标签中取出param参数供子标签使用组件代码
Thymeleaf还是比较牛皮啊,可以在组件里写业务逻辑了都,就是不太好维护th:with自定义变量,该变量可以在子标签中使用注意
style属性不同样式之间必须使用分号隔开,不像$(".sort_a").css(样式json对象)传参json对象用逗号分隔
xxxxxxxxxx<div class="filter_top_left"th:with="sortParam=${param.sort},sortDesc=${ !#strings.isEmpty(param.sort) && #strings.endsWith(param.sort,'desc')},emptySortParam=${#strings.isEmpty(param.sort)},normalStyle=${'color: #FFF;border-color: #e4393c;background: #e4393c'},selectedStyle=${'color: #333;border-color:#CCC;background: #FFF'}"><a sort="hotScore" href="#"th:class="${(emptySortParam || (#strings.startsWith(sortParam,'hotScore') && sortDesc))?'sort_a desc':'sort_a'}"th:attr="style=${(emptySortParam || #strings.startsWith(sortParam,'hotScore'))?normalStyle:selectedStyle}">评论分[[${(emptySortParam ||(!#strings.startsWith(sortParam,'hotScore')))?'':(sortDesc?'↓':'↑')}]]</a><a sort="saleCount" href="#"th:class="${(!emptySortParam && (#strings.startsWith(sortParam,'saleCount') && sortDesc))?'sort_a desc':'sort_a'}"th:attr="style=${(!emptySortParam && #strings.startsWith(sortParam,'saleCount'))?normalStyle:selectedStyle}">销量[[${(emptySortParam ||(!#strings.startsWith(sortParam,'saleCount')))?'':(sortDesc?'↓':'↑')}]]</a><a sort="skuPrice" href="#"th:class="${(!emptySortParam && (#strings.startsWith(sortParam,'skuPrice') && sortDesc))?'sort_a desc':'sort_a'}"th:attr="style=${(!emptySortParam && #strings.startsWith(sortParam,'skuPrice'))?normalStyle:selectedStyle}">价格[[${(emptySortParam ||(!#strings.startsWith(sortParam,'skuPrice')))?'':(sortDesc?'↓':'↑')}]]</a></div>
检索参数添加仅显示有货
组件代码
xxxxxxxxxx<a href="#" th:with="check=${param.hasStock}"><input id="onlyHasStock" type="checkbox" th:checked="${#strings.equals(check,'1')}">仅显示有货</a>复选框change事件
xxxxxxxxxx//切换仅显示有货拼接仅显示有货参数到当前请求路径中$("#onlyHasStock").change(function (){//如果复选框选中就更改当前请求路径参数仅显示有库存的商品,如果复选框没有被选中就去掉请求路径中的对应参数if ($(this).prop('checked')) {location.href=replaceOrAddParamVal(location.href,"hasStock",1)}else{location.href=removeParamFromUri('hasStock');}return false;});//替换指定请求路径中的请求参数,如果参数已经存在就直接替换,如果参数不存在就追加参数function replaceOrAddParamVal(url,paramName,replaceVal){var oUrl = url.toString();//旧请求路径中有了就进行替换,没有对应参数就添加参数if (oUrl.indexOf(paramName+'=') != -1){var re = eval('/('+paramName+'=)([^&]*)/gi');var nUrl = oUrl.replace(re,paramName+'='+replaceVal);return nUrl;}else{//添加参数var nUrl="";//检查旧链接中有没有问号,有问号就追加参数,没有就新增问号并添加参数if(oUrl.indexOf("?")!=-1){nUrl = oUrl+"&"+paramName+"="+replaceVal;}else{nUrl = oUrl+"?"+paramName+"="+replaceVal;}return nUrl;}}//移除请求路径中的指定参数并返回移除后的请求路径,用正则表达式匹配字符串中的子串并替换function removeParamFromUri(paramName){var searchParam = eval('/([&|?]'+paramName+'=)([^&]*)/gi');return (location.href+"").replace(searchParam,'');}
检索参数添加价格区间
组件代码
xxxxxxxxxx<div style="float: left;margin-left:10px;" th:with="price=${param.skuPrice}">¥<input class="priceInput" id="skuPriceFrom" type="number" placeholder="0" th:value="${#strings.isEmpty(price)?'':#strings.substringBefore(price,'_')}">-<input class="priceInput" id="skuPriceTo" type="number" th:value="${#strings.isEmpty(price)?'':#strings.substringAfter(price,'_')}"></div><a id="searchByPriceInterval" style="margin-left: 5px">确定</a><style type="text/css">.priceInput{text-align: center;width: 50px;height: 23px;line-height: 23px;border: 1px solid #CCC;}</style>确定按钮点击事件
xxxxxxxxxx//点击价格区间后面的确定按钮发送按价格区间检索的请求,价格区间都为0则检索全部$("#searchByPriceInterval").click(function (){//当价格区间参数全为0时检索全部价格if(!$("#skuPriceTo").val() && !$("#skuPriceFrom").val()){location.href=removeParamFromUri('skuPrice');}else{//拼接价格区间并拼接对应参数到请求路径var priceInterval = $("#skuPriceFrom").val()+"_"+$("#skuPriceTo").val();location.href=replaceOrAddParamVal(location.href,"skuPrice",priceInterval);}return false;});//替换指定请求路径中的请求参数,如果参数已经存在就直接替换,如果参数不存在就追加参数function replaceOrAddParamVal(url,paramName,replaceVal){var oUrl = url.toString();//旧请求路径中有了就进行替换,没有对应参数就添加参数,这里用参数名判断最好加等号,因为可能参数值中也有参数名,比如按售价排序if (oUrl.indexOf(paramName+'=') != -1){var re = eval('/('+paramName+'=)([^&]*)/gi');var nUrl = oUrl.replace(re,paramName+'='+replaceVal);return nUrl;}else{//添加参数var nUrl="";//检查旧链接中有没有问号,有问号就追加参数,没有就新增问号并添加参数if(oUrl.indexOf("?")!=-1){nUrl = oUrl+"&"+paramName+"="+replaceVal;}else{nUrl = oUrl+"?"+paramName+"="+replaceVal;}return nUrl;}}//移除请求路径中的指定参数并返回移除后的请求路径function removeParamFromUri(paramName){var searchParam = eval('/([&|?]'+paramName+'=)([^&]*)/gi');return (location.href+"").replace(searchParam,'');}
面包屑导航
面包屑导航的特点是从外层属性到内层属性回显检索过滤条件,删除掉某个过滤条件会重新检索不带对应检索条件的商品数据,面包屑导航只筛选spu属性和品牌,不对商品分类做导航,避免商品分类移除导致查询所有商品对应属性的结果
面包屑导航数据在后端封装成一个
NavVo类型的List集合,NavVo类型封装了面包屑导航名字、面包屑导航名字对应的值和取消面包屑导航要跳转的地址,面包屑导航中的属性名字最好单独从商品服务去查,不要直接从检索结果中获取,因为检索可能检索不出数据,检索不出数据就无法获取面包屑导航的名字【弄个Map保存上一次的检索结果也不好,因为存在线程并发安全问题和涉及到服务器保存用户状态信息,这样不好】,但是感觉这个功能前端实现起来更简单而且性能更好
整体逻辑
从请求参数中获取属性id列表,将属性值封装到navVo导航组件中,远程调用商品服务查询所有的属性名信息并以attr:attrId作为key添加缓存,通过属性id将属性名封装到navVo导航组件中,通过对应的属性值匹配
HttpServletRequest.getQueryString()来剔除掉请求参数作为移除面包屑后的请求路径linkForExcluded,品牌id也通过上面的逻辑封装到一个navVo导航组件中,前端用Thymeleaf遍历导航组件,将所有的面包屑导航栏展示成被剔除面包屑后的请求路径作为超链接路径并动态展示超链接的文本,从而实现面包屑的展示和剔除效果;组件通过判断检索参数是否有brandIds参数来使用Thymeleaf判断是否要展示品牌检索组件,在获取请求路径中的属性参数封装navVo的同时将属性id放入attrIds中通过Thymeleaf的#lists.contains(attrIds,attr.id)来判断是否需要隐藏对应的属性检索列表从而实现品牌和属性检索列表与面包屑的联动效果这里面有四个重点,第一是SpringCache的
@Cacheable注解被同一个类的方法调用会导致缓存失效,解决办法是将被调用方法放到另一个service中,只要不在同一个类被调用就行;第二个重点是Java对空格和分号的编码和浏览器对空格和分号的编码结果不同,要进行匹配的时候需要对相应的编码后字段进行替换;第三个重点是Thymeleaf的#lists.contains(attrIds,attr.id)可以判断列表中是否包含某个值,第四个重点是th:with标签的优先级低于th:if,因此自定义变量要在th:if中使用需要将th:with放在外部标签被先执行,优先级可以通过Thymeleaf的官方文档查询
spu属性的面包屑导航面包屑导航栏的数据封装模型,属性
breadcrumb和attrIds,分别做面包屑导航栏的元素列表和属性检索列表的不显示判断列表,品牌和属性的导航栏都封装成NavVoxxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 封装检索页面的检索结果* @创建日期 2024/09/05* @since 1.0.0*/public class SkuSearchResult {/*** 封装从查到ES中所有的商品完整信息*/private List<Product> products;/*** 分页信息-当前页码*/private Integer pageNum;/*** 分页信息-总记录数*/private Long total;/*** 分页信息-总页码数*/private Long totalPages;/*** 当前检索查询到的结果涉及到的品牌信息*/private List<BrandVo> brands;/*** 当前检索查询到的结果涉及到的能被过滤出商品的所有属性*/private List<AttrVo> attrs;/*** 当前检索查询到的结果涉及到的所有商品分类*/private List<CatelogVo> catelogs;/*** 面包屑导航栏元素,包含属性和品牌,这里只在品牌单选一个才显示品牌面包屑,多个品牌仍然以列表的形式展示*/private List<NavVo> breadcrumb=new ArrayList<>();/*** 面包屑筛选属性的属性id集合,用来做检索列表的单属性收起功能,有对应的属性检索条件对应属性列表就不展示了*/private List<Long> attrIds=new ArrayList<>();/*** @author Earl* @version 1.0.0* @描述 面包屑元素封装类,nav是导航的缩写* @创建日期 2024/09/14* @since 1.0.0*/public static class NavVo{/*** 导航id、属性id或者对应的品牌id*/private Long navId;/*** 导航属性名称*/private String navName;/*** 导航属性值*/private String navValue;/*** 被排除时的link*/private String linkForExcluded;}/*** @author Earl* @version 1.0.0* @描述 品牌信息封装类* @创建日期 2024/09/05* @since 1.0.0*/public static class BrandVo {/*** 品牌ID*/private Long brandId;/*** 品牌名*/private String brandName;/*** 品牌logo*/private String brandImg;}/*** @author Earl* @version 1.0.0* @描述 属性信息封装* @创建日期 2024/09/05* @since 1.0.0*/public static class AttrVo {/*** 属性ID*/private Long attrId;/*** 属性名*/private String attrName;/*** 属性值*/private List<String> attrValue;}/*** @author Earl* @version 1.0.0* @描述 商品分类信息封装* @创建日期 2024/09/11* @since 1.0.0*/public static class CatelogVo{/*** 商品分类id*/private Long catelogId;/*** 商品名称*/private String catelogName;}}封装检索属性的逻辑
这里移除URI对应参数的方法是从HttpServletRequest中获取QueryString来匹配移除对应检索条件实现的移除面包屑导航就跳转没有对应检索条件的请求路径,QueryString中的uri是被UTF-8编码过的,参数名没有被编码;要匹配参数就需要使用Java对参数值进行编码,Java对空格和分号的编码和前端不同,Java会将空格编码为加号,将分号解析为
%3B,但是前端会将空格解析为%20,分号维持原样,因此要匹配参数来移除参数还需要将Java编码后的结果把+替换为%20,把%3B替换为;,此外还有其他处理逻辑,都在下面方法里
xxxxxxxxxx/*** @return {@link SkuSearchResult }* @描述 将检索结果封装成我们自定义的响应对象* 封装检索记录、封装聚合结果,所有记录涉及的属性和属性值、所有记录涉及的品牌、所有记录涉及的商品分类* 对检索品牌和检索属性做面包屑导航并与检索列表联动,实现选中单个品牌或者属性,对应的检索栏就不显示* @author Earl* @version 1.0.0* @创建日期 2024/09/06* @since 1.0.0* @param response* @param param*/private SkuSearchResult buildSearchResponse(SearchResponse response, SearchParam param) {//准备响应结果的容器SkuSearchResult result = new SkuSearchResult();//1. 封装所有检索记录SearchHit[] hits = response.getHits().getHits();ArrayList<Product> searchProducts = new ArrayList<>(hits.length);for (SearchHit hit : hits) {Product product = JSON.parseObject(hit.getSourceAsString(), Product.class);//高亮字段信息存在hits.hits的highlightFields属性中的value属性的fragment数组中if(!StringUtils.isEmpty(param.getKeyword())){product.setSkuTitle(hit.getHighlightFields().get("skuTitle").getFragments()[0].string());}searchProducts.add(product);}result.setProducts(searchProducts);//2. 封装所有记录涉及到的商品品牌Aggregations aggregations = response.getAggregations();ArrayList<SkuSearchResult.BrandVo> brands = new ArrayList<>();//必须强转为子类才能调用getBuckets方法ParsedLongTerms brand_agg = (ParsedLongTerms) aggregations.get("brand_agg");//2.1 获取商品品牌的idfor (Terms.Bucket bucket : brand_agg.getBuckets()) {SkuSearchResult.BrandVo brand = new SkuSearchResult.BrandVo();brand.setBrandId(Long.parseLong(bucket.getKeyAsString()));//2.2 获取商品品牌的图片ParsedStringTerms brand_img_agg = (ParsedStringTerms) bucket.getAggregations().get("brand_img_agg");brand.setBrandImg(brand_img_agg.getBuckets().get(0).getKeyAsString());//2.3 获取商品品牌的名字ParsedStringTerms brand_name_agg = (ParsedStringTerms) bucket.getAggregations().get("brand_name_agg");brand.setBrandName(brand_name_agg.getBuckets().get(0).getKeyAsString());brands.add(brand);}result.setBrands(brands);//3. 封装所有记录涉及到的商品种类ArrayList<SkuSearchResult.CatelogVo> catelogs = new ArrayList<>();ParsedLongTerms catelog_agg = (ParsedLongTerms) aggregations.get("catelog_agg");//3.1 获取商品分类的idfor (Terms.Bucket bucket : catelog_agg.getBuckets()) {SkuSearchResult.CatelogVo catelog = new SkuSearchResult.CatelogVo();catelog.setCatelogId(Long.parseLong(bucket.getKeyAsString()));//3.2 获取商品分类的名字ParsedStringTerms catelog_name_agg = (ParsedStringTerms) bucket.getAggregations().get("catelog_name_agg");catelog.setCatelogName(catelog_name_agg.getBuckets().get(0).getKeyAsString());catelogs.add(catelog);}result.setCatelogs(catelogs);//4. 封装所有记录涉及到的属性种类ArrayList<SkuSearchResult.AttrVo> attrs = new ArrayList<>();ParsedNested attrs_agg = (ParsedNested) aggregations.get("attrs_agg");ParsedLongTerms attrs_id_agg = (ParsedLongTerms) attrs_agg.getAggregations().get("attrs_id_agg");//4.1 获取商品属性的idfor (Terms.Bucket bucket : attrs_id_agg.getBuckets()) {SkuSearchResult.AttrVo attr = new SkuSearchResult.AttrVo();attr.setAttrId(Long.parseLong(bucket.getKeyAsString()));//4.2 获取商品属性的名字ParsedStringTerms attr_name_agg = (ParsedStringTerms) bucket.getAggregations().get("attr_name_agg");attr.setAttrName(attr_name_agg.getBuckets().get(0).getKeyAsString());//4.3 获取商品属性所有可能的属性值ArrayList<String> attrValues = new ArrayList<>();ParsedStringTerms attr_value_agg = (ParsedStringTerms) bucket.getAggregations().get("attr_value_agg");attr.setAttrValue(attr_value_agg.getBuckets().stream().map(item -> item.getKeyAsString()).collect(Collectors.toList()));attrs.add(attr);}result.setAttrs(attrs);//5. 封装分页信息//5.1 封装总记录数long total = response.getHits().getTotalHits().value;result.setTotal(total);//5.2 封装当前页码result.setPageNum(param.getPageNum());//5.3 封装总页码数result.setTotalPages(((total - 1) / EsConstant.PRODUCT_PAGE_SIZE)+1);//6. 构建面包屑导航功能//6.1 从请求参数中获取所有的属性检索参数并远程调用商品服务查询出所有的属性检索条件if( param.getAttrs()!=null && param.getAttrs().size() > 0){List<SkuSearchResult.NavVo> breadcrumb = new ArrayList<>();List<Long> attrIds = param.getAttrs().stream().map(attr -> {String[] attrInfo = attr.split("_");SkuSearchResult.NavVo navVo = new SkuSearchResult.NavVo();long attrId = Long.parseLong(attrInfo[0]);navVo.setNavId(attrId);result.getAttrIds().add(attrId);navVo.setNavValue(attrInfo[1]);String newURI = removeParamQueryString(param, "attrs", attr);navVo.setLinkForExcluded(MallConstant.MALL_SEARCH_ADDRESS+(StringUtils.isEmpty(newURI)?"":"?"+newURI));breadcrumb.add(navVo);return attrId;}).collect(Collectors.toList());R res = productFeignClient.getAttrs(attrIds);if (res.getCode() == 0){Map<Long, AttrRespTo> attrsInfo = res.getData(new TypeReference<HashMap<Long, AttrRespTo>>(){});for (SkuSearchResult.NavVo navVo : breadcrumb) {navVo.setNavName(attrsInfo.get(navVo.getNavId()).getAttrName());}result.setBreadcrumb(breadcrumb);}}//6.2 从请求参数中构建品牌的面包屑List<Long> brandIds = param.getBrandIds();if(brandIds!=null && brandIds.size()>0){SkuSearchResult.NavVo nav = new SkuSearchResult.NavVo();nav.setNavName("品牌");R res = productFeignClient.getBrandInfoByIds(brandIds);if(res.getCode() == 0){List<BrandTo> brandToLists = res.getData(new TypeReference<List<BrandTo>>() {});StringBuffer buffer = new StringBuffer();String newURI=null;for (BrandTo brand : brandToLists) {buffer.append(brand.getBrandName()+";");newURI=removeParamQueryString(param,"brandIds",String.valueOf(brand.getBrandId()));}nav.setNavValue(buffer.toString());nav.setLinkForExcluded(MallConstant.MALL_SEARCH_ADDRESS+(StringUtils.isEmpty(newURI)?"":"?"+newURI));}result.getBreadcrumb().add(nav);}return result;}/*** @param param* @param paramName* @param paramValue* @return {@link String }* @描述 根据检索参数名和参数值从httpServletRequest.getQueryString中移除对应的请求参数* @author Earl* @version 1.0.0* @创建日期 2024/09/15* @since 1.0.0*/private String removeParamQueryString(SearchParam param,String paramName,String paramValue){String encode=null;try {//注意这里的编码会将字符串中的空格编码成加号,但是前端传递进来的URI会保留前端对空格的处理结果即%20//11_%E6%B5%B7%E6%80%9D+%E8%8A%AF%E7%89%87// 因此必须将要匹配替换的字符串编码以后得到的字符把加号处理成%20来保证和httpServletRequest.getQueryString()方法获取uri中的空格编码保持一致// 这是Java和前端对空格处理的差异化导致的,即Java编码把空格处理成加号,前端编码把空格处理成%20// 注意Java会把分号编码成%3B,前端不做处理,也需要将%3B替换为;,注意replace方法是替换全部encode = URLEncoder.encode(paramValue, "UTF-8").replace("+","%20").replace("%3B",";");} catch (UnsupportedEncodingException e) {e.printStackTrace();}String newURI = param.getSearchURI().replace(paramName+"="+encode, "").replaceAll("&&","&");if (newURI.startsWith("&")) {newURI=newURI.replaceFirst("&","");}if(newURI.endsWith("&")){newURI=newURI.substring(0,newURI.length()-1);}return newURI;}涉及的数据传输类
以下的
To类都用于封装从商品服务查询出来的属性信息和品牌信息
[
AttrAddTo]xxxxxxxxxxpublic class AttrAddTo {/*** 属性id*/private Long attrId;/*** 属性名*/private String attrName;/*** 是否需要检索[0-不需要,1-需要]*/private Integer searchType;/*** 值类型[0-为单个值,1-可以选择多个值]*/private Integer valueType;/*** 属性图标*/private String icon;/*** 可选值列表[用逗号分隔]*/private String valueSelect;/*** 属性类型[0-销售属性,1-基本属性,2-既是销售属性又是基本属性]*/private Integer attrType;/*** 启用状态[0 - 禁用,1 - 启用]*/private Long enable;/*** 所属分类*/private Long catelogId;/*** 快速展示【是否展示在介绍上;0-否 1-是】,在sku中仍然可以调整*/private Integer showDesc;/*** 属性属于的属性分组*/private Long attrGroupId;}[
AttrRespTo]xxxxxxxxxxpublic class AttrRespTo extends AttrAddTo {/*** 所属商品分类名称*/private String catelogName;/*** 所属属性分组名称*/private String groupName;/*** 所属三级商品分类路径*/private List<Long> catelogPath;}[
BrandTo]xxxxxxxxxxpublic class BrandTo {private Long brandId;private String brandName;}远程调用的接口逻辑
[
ProductFeignClient]xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 商品服务远程调用* @创建日期 2024/09/14* @since 1.0.0*/("mall-product")public interface ProductFeignClient {/*** @param attrIds* @return {@link R }* @描述 通过属性id列表获取所有属性所有的相关信息* @author Earl* @version 1.0.0* @创建日期 2024/09/15* @since 1.0.0*/("product/attr/info/list")R getAttrs( List<Long> attrIds);("product/brand/info/list")R getBrandInfoByIds( List<Long> brandIds);}[
getAttrs(@RequestParam List<Long> attrIds)]这里有个要点是
SpringCache的@Cacheable注解在同一个类中作为同一个类中其他方法的被调用方法会导致因为SpringCache的注解通过AOP实现,通过Spring创建内部类代理缓存方法,类内部的方法调用类内部的缓存方法不会走代理,不会走代理,就不能正常创建缓存,解决办法是把被调用方法移动到其他service中来调用就能正常使用缓存了
xxxxxxxxxx("product/attr")public class AttrController {private AttrService attrService;/*** @param attrIds* @return {@link R }* @描述 通过属性id获取属性所有的相关信息* @author Earl* @version 1.0.0* @创建日期 2024/09/15* @since 1.0.0*/("/info/list")//@RequiresPermissions("product:attr:info")public R getAttrs( List<Long> attrIds){Map<Long,AttrRespTo> attrs = attrService.getAttrInfoByIds(attrIds);return R.ok().put("data", attrs);}}("attrService")public class AttrServiceImpl extends ServiceImpl<AttrDao, AttrEntity> implements AttrService {private AttrAttrgroupRelationService attrAttrgroupRelationService;/*** @param attrIds* @return {@link List }<{@link AttrRespTo }>* @描述 根据属性id列表,* 注意一个方法A调同一个类里的另一个有缓存注解@Cacheable的方法B,这样是不走缓存的,比如同一个service里面两个方法的调用,缓存是不生效的** 为什么缓存没有被正常创建??* 因为@Cacheable 是使用AOP 代理实现的 ,通过创建内部类来代理缓存方法,这样就会导致一个问题,类内部的方法调用类内部的缓存方法不会走代理,不会走代理,就不能正常创建缓存,所以每次都需要去调用数据库。** @Cacheable 的一些注意点* 1、因为@Cacheable 由AOP 实现,所以,如果该方法被其它注解切入,当缓存命中的时候,则其它注解不能正常切入并执行,@Before 也不行,当缓存没有命中的时候,其它注解可以正常工作** 2、@Cacheable 方法不能进行内部调用,否则缓存无法创建** @author Earl* @version 1.0.0* @创建日期 2024/09/14* @since 1.0.0*/public Map<Long,AttrRespTo> getAttrInfoByIds(List<Long> attrIds) {if(attrIds!=null && attrIds.size()>0){Collection<AttrEntity> attrEntities = listByIds(attrIds);return attrEntities.stream().collect(Collectors.toMap(attrEntity -> attrEntity.getAttrId(),attrEntity -> attrAttrgroupRelationService.getAttrInfo(attrEntity)));}return null;}}("attrAttrgroupRelationService")public class AttrAttrgroupRelationServiceImpl extends ServiceImpl<AttrAttrgroupRelationDao, AttrAttrgroupRelationEntity> implements AttrAttrgroupRelationService {private CategoryService categoryService;private AttrAttrgroupRelationService attrAttrgroupRelationService;private AttrGroupDao attrGroupDao;/*** @param attrEntity* @return {@link AttrRespTo }* @描述 根据属性实体类attrEntity获取属性的完整信息* @author Earl* @version 1.0.0* @创建日期 2024/09/14* @since 1.0.0*/(value = "attr",key = "#attrEntity.attrId")public AttrRespTo getAttrInfo(AttrEntity attrEntity){AttrRespTo attrRespVo = new AttrRespTo();BeanUtils.copyProperties(attrEntity,attrRespVo);List<Long> catelogPath = categoryService.getCategoryIdsByAttrGroupId(attrEntity.getCatelogId());attrRespVo.setCatelogPath(catelogPath);if(ProductConstant.AttrTypeEnum.ATTR_TYPE_BASE.getCode() == attrEntity.getAttrType()) {AttrAttrgroupRelationEntity relation = attrAttrgroupRelationService.getOne(new QueryWrapper<AttrAttrgroupRelationEntity>().eq("attr_id", attrEntity.getAttrId()));if (relation != null && relation.getAttrGroupId() != null) {attrRespVo.setAttrGroupId(relation.getAttrGroupId());AttrGroupEntity attrGroup = attrGroupDao.selectById(relation.getAttrGroupId());if (attrGroup != null) {attrRespVo.setGroupName(attrGroup.getAttrGroupName());}}}return attrRespVo;}}[
getBrandInfoByIds(@RequestBody List<Long> brandIds)]xxxxxxxxxx/*** 品牌** @author Earl* @email 18794830715@163.com* @date 2024-01-27 08:45:26*/("product/brand")public class BrandController {private BrandService brandService;/*** @param brandIds* @return {@link R }* @描述 根据请求参数的id列表获取所有的品牌信息* @author Earl* @version 1.0.0* @创建日期 2024/09/15* @since 1.0.0*/("/info/list")//@RequiresPermissions("product:brand:list")public R getBrandInfoByIds( List<Long> brandIds){List<BrandTo> brands=brandService.getBrandInfoByIds(brandIds);return R.ok().put("data", brands);}}("brandService")public class BrandServiceImpl extends ServiceImpl<BrandDao, BrandEntity> implements BrandService {private CategoryBrandRelationService categoryBrandRelationService;/*** @param brandIds* @return {@link List }<{@link BrandTo }>* @描述 根据品牌id列表获取品牌信息* @author Earl* @version 1.0.0* @创建日期 2024/09/15* @since 1.0.0*/public List<BrandTo> getBrandInfoByIds(List<Long> brandIds) {if(brandIds!=null&&brandIds.size()>0){Collection<BrandEntity> brandEntities = listByIds(brandIds);if(brandEntities!=null && brandEntities.size()>0){List<BrandTo> brands = brandEntities.stream().map(brandEntity -> {BrandTo brand = new BrandTo();brand.setBrandId(brandEntity.getBrandId());brand.setBrandName(brandEntity.getName());return brand;}).collect(Collectors.toList());return brands;}}return null;}}[一些用到的常数]
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 商城相关配置* @创建日期 2024/09/15* @since 1.0.0*/public class MallConstant {public static final String MALL_SEARCH_ADDRESS="http://search.earlmall.com/list.html";}[统一响应类]
xxxxxxxxxx/*** 返回数据** @author Mark sunlightcs@gmail.com*/public class R extends HashMap<String, Object> {private static final long serialVersionUID = 1L;public <T> T getData(TypeReference<T> typeReference){//接收到的Object类型里面的对象被自动反序列化成Map了,因为互联网传输过程中使用JSON天然符合Map特性//系统底层默认转成Map是为了更方便数据的读取,R里面data存的数据的数据类型默认是LinkedMap类型的,LinkedMap无法被强转为我们自定义的To类,无法转成To类意味着不能获取到value自动识别出对应的类型,比如数据被封装成HashMap<Long, AttrRespTo>,但是在服务间转换的时候能通过get()方法获取到value,因为Map的Json对象和一般的对象都能正常封装为LinkedMap,但是value值并不是AttrRespTo类型的,甚至必须通过get(String str)传参string类型的key才能获取到value,这里传参Long类型的key无法获取到value,使用long类型的key获取value为null,value强转AttrRespTo语法不会报错,但是不能调用AttrRespTo中的方法,对应方法的返回值还是null,就会导致抛空指针异常,可以通过fastjson解析字符串的方式将对象转成json字符串再转成对应的目标类型,fastjson提供了TypeReference实现,因此可以直接使用TypeReference,自己调用fastjson的API去做也是可以的//需要使用fastjson的TypeReference先将Map转换成json,再用fastjson将json字符串转成通过泛型指定的实体类Object data =get("data");String dataJSONStr = JSON.toJSONString(data);T t = JSON.parseObject(dataJSONStr, typeReference);return t;}public R setData(Object data){put("data",data);return this;}/*** @描述 响应成功的状态码是0* @author Earl* @version 1.0.0* @创建日期 2024/06/02* @since 1.0.0*/public R() {put("code", 0);put("msg", "success");}public static R error() {return error(HttpStatus.SC_INTERNAL_SERVER_ERROR, "未知异常,请联系管理员");}public static R error(String msg) {return error(HttpStatus.SC_INTERNAL_SERVER_ERROR, msg);}public static R error(int code, String msg) {R r = new R();r.put("code", code);r.put("msg", msg);return r;}public static R ok(String msg) {R r = new R();r.put("msg", msg);return r;}public static R ok(Map<String, Object> map) {R r = new R();r.putAll(map);return r;}public static R ok() {return new R();}public R put(String key, Object value) {super.put(key, value);return this;}/*** @return {@link Integer }* @描述 获取响应的响应码判断响应状态* @author Earl* @version 1.0.0* @创建日期 2024/03/26* @since 1.0.0*/public Integer getCode(){return (Integer) this.get("code");}}面包屑前端组件
xxxxxxxxxx<div class="JD_ipone_one c"><!--遍历面包屑--><a th:href="${nav.linkForExcluded}" th:each="nav:${searchResult.breadcrumb}" class="qqq"><span th:text="${nav.navName}"></span>:<span th:text="${nav.navValue}"></span>x<img src="static/search/image/down-@1x.png" alt=""></a></div>品牌和属性检索列表组件与面包屑的联动效果优化
就是加了一个判断,如果请求参数有品牌检索参数,品牌检索列表不展示;如果请求路径中有SPU属性检索条件对应的单个属性检索列表不展示
xxxxxxxxxx<div class="JD_nav_logo" th:with="brandId=${param.brandIds},attrIds=${searchResult.attrIds}"><!--品牌--><div class="JD_nav_wrap" th:if="${#strings.isEmpty(brandId)}"><div class="sl_key"><span><b>品牌:</b></span></div><div class="sl_value"><div class="sl_value_logo"><ul><li th:each="brand:${searchResult.brands}"><a th:href="${'javascript:specifySearchParam("brandIds",'+brand.brandId+')'}"><img th:src="${brand.brandImg}" alt=""><div th:text="${brand.brandName}">华为(HUAWEI)</div></a></li></ul></div></div><div class="sl_ext"><a href="#">更多<i style='background: url("static/search/image/search.ele.png")no-repeat 3px 7px'></i><b style='background: url("static/search/image/search.ele.png")no-repeat 3px -44px'></b></a><a href="#">多选<i>+</i><span>+</span></a></div></div><!--商品属性--><div class="JD_pre" th:each="attr:${searchResult.attrs}" th:if="${!#lists.contains(attrIds,attr.attrId)}"><div class="sl_key"><span th:utext="'<b>'+${attr.attrName}+'</b>'">属性名:</span></div><div class="sl_value"><ul><li th:each="attrValue:${attr.attrValue}"><a th:href="${'javascript:specifySearchParam("attrs","'+attr.attrId+'_'+attrValue+'")'}" th:text="${attrValue}">5.56英寸及以上</a></li></ul></div></div>
商品详情
业务逻辑:
获取sku基本信息、图片信息、促销信息、所有销售属性、规格参数组和组下的规格参数、spu详情,获取的信息多,有些数据还需要远程调用,
检索商品详情请求路径传参的是skuId,通过skuId我们可以异步查出sku的基本信息、图片信息、促销信息;通过sku的基本信息我们才知道当前sku对应哪个spuId、通过spuId异步查出销售属性、规格参数和spu详情
使用
CompletableFuture做异步任务,CompletableFuture中的方法大量使用函数式接口
线程池详解
线程初始化的四种方式:继承Thread类、实现Runnable接口、实现Callable接口[JDK1.5以后加入,使用Callable需要将Callable实现类封装到FutureTask中,将FutureTask封装到Thread中,通过
thread.start()方法来运行,可以通过futureTask.get()方法获取到Callable任务的返回结果,get()方法是阻塞等待]、使用线程池🔎:业务代码中一般前三种方式初始化线程任务都不使用,因为这种方式很容易导致服务器系统资源耗尽,创建非常多的线程;应该统一使用线程池来提交执行异步任务,方便管理线程和控制线程资源数量,避免高并发请求下都去创建新的线程来执行业务导致业务还没执行完系统就因为资源被耗尽系统崩溃了
🔎:阿里编程规范认为JDK自带的线程池都有OOM问题,建议使用自定义线程池,弹幕提示是因为Executors中的线程池有无界队列导致的OOM问题
🔎:而且不要在方法中去创建线程池,应该净量保证整个系统中的线程池数量可控,根据机器的内存、CPU核数等情况来确定系统中的最大线程数量
🔎:
Executors.newFixedThreadPool(10).execute(Runnable task)是给线程池提交一个不需要返回值的任务,Executors.newFixedThreadPool(10).submit()可以传参Runnable或者Callable匿名实现,但是令人好奇的是两者都返回Future对象,为啥没有返回值的Runnable匿名实现也返回Future对象
注意不能使用单元测试类来测试多线程,测不出来效果
线程池的创建方式
Executors.newXxx()Executors.newCachedThreadPool():核心线程数0,最大线程数Integer.MAX_VALUE,最大空闲时间60sExecutors.newFixedThreadPool():核心线程数等于最大线程数等于指定值,即没有救急线程Executors.newScheduledThreadPool():这里的线程池使用的固定线程数量的线程池,只有核心线程,没有应急线程;这里设置的实际是核心线程数目,通过ScheduledExecutorService对象调用schedule方法传参Runnable或者Callable任务对象,传参延时时间和延时单位,认为延时时间是相对于线程开始运行时间[每个定时任务的延迟时间就是相对于每个schedule方法的调用时间,经过验证了如果两个schedule方法之间睡1s,相同延时时间的两个调度任务的执行时间也会相差1s],如过只有一个核心线程,那么就会变成Timer类的执行效果,即必须等待前一个任务执行结束后才会执行,所以同时存在多个任务需要增大线程池的容量来让同一时刻的线程调度任务同时执行;但是这种任务调度线程池即使只有一个线程,发生异常也不会影响后续调度任务的执行,而且发生异常的线程也不会被注销,仍然会继续执行后续的调度任务,且控制台或者日志不会打印任何异常信息,该线程池的scheduleAtFixedRate方法是执行定时任务的api,传参任务对象,初始延时时间、执行间隔时间、时间单位;这个执行间隔时间是以上次开始执行的时间为基准的,但是如果一次任务执行时间大于时间间隔,为了避免任务执行发生重叠,该方法会让一个任务执行完才会立即开始下一个任务,与之相对应的还有一个scheduleWithFixedDelay方法,该方法以上一个方法执行结束为基础时间点计算时间间隔在进行下一次任务任务调度线程池和普通的线程池在执行期间发生异常,既不会抛出异常,也不会在控制台和日志中进行显示和记录,此时需要主动对这些异常进行处理,方法一是主动捕捉异常并对异常进行处理、方法二是传参
Callable接口会返回Futrue对象,使用Futrue对象任务对象必须是Callable接口,Futrue对象被设计成如果线程正常执行就返回执行结果;如果线程执行期间抛出异常就返回异常堆栈信息
Executors.newSingleThreadExecutor():核心线程数和最大线程数都为1,没有救急线程,队列是无界队列,即该线程池是一个单线程线程池,顺序从阻塞队列中获取任务挨个执行,应用场景是分布式情况下,保证双写一致的情况,需要将相同的业务留给同一台服务器或者线程来处理。
new ThreadPoolExecutor()线程池初始化七大参数:
int corePoolSize:核心线程数、核心线程总是存在系统中不会被销毁,除非设置了参数allowCoreThreadTimeOut允许核心线程超时,核心线程在任务提交以后才会创建,在创建以后处于new Thread()状态,当异步任务提交以后就处于thread.start()状态int maximumPoolSize:最大线程数量,最大线程数量等于核心线程数量+救急线程数量long keepAliveTime:救急线程最大空闲时间,救急线程空闲超过指定的时间间隔就自动销毁TimeUnit unit:救急线程最大空闲时间的单位BlockingQueue<Runnable> workQueue:任务阻塞队列,任务会先被核心线程获取并处理,核心线程数满了会将任务保存在阻塞队列中,如果阻塞队列也满了,此时任务会被交给救急线程来执行新添加的任务,救急线程适合处理任务量突发增大,阻塞队列都放不下了,就使用救急线程来救急;救急线程和核心线程最大的区别是救急线程有存活时间,一旦一段时间内没有新任务救急线程就会销毁,核心线程没有生存时间,核心线程执行完后仍然会被保留在线程池中,核心线程只要被创建就会一直存在于线程中;当核心线程、阻塞队列、救急线程都使用同时达到阈值,此时再来任务就会执行拒绝策略,注意使用救急线程的前提是任务队列必须选择有界队列实现,有界队列满且还有任务要入队,就会创建救急线程;如果选用无界队列,那么就只会用核心线程找任务队列中的任务挨个执行,tomcat的线程池对这个设计进行了一些改进和调整 ,通过new LinkedBlockingQueue<>(100000)来创建阻塞队列即可ThreadFactory threadFactory:打印线程名称是依赖线程工厂来实现的,线程工厂有一个默认实现DefaultThreadFactory,Executors.newXxx创建的线程池打印线程名字的方法是Executors类中newFixedThreadPool方法中的ThreadPoolExecutor方法中调用Executors.defaultThreadFactory获取的线程工厂,该方法返回新创建的一个DefaultThreadFactory对象,这个线程工厂对象的实现中指明了名字前缀的格式:namePrefix="pool-"+poolNumber.getAndIncrement()+"-thread-",用原子整形来初始化和保护整形1,调用该原子整形的自增方法来实现创建线程池的编号,调用其他方法生成的线程池对应的线程池编号会增大,线程的编号代码在Excutors类中的第613行对应namePrefix+threadNumber.getAndIncrement(),这个threadNumber也是初始值为1的原子整数,调用新建线程池的方法时来调用threadNumber的自增方法来实现线程的自增,线程池中的线程都被设置为非守护线程[t.setDaemon(false)],即不会随着主线程结束而结束,自定义线程池的名字可以通过Executors.newFixedThreadPool来指定该线程池的线程数量和自己实现一个ThreadFactory对象,实际上就是给自己的线程起一个名字,对应代码实现见JUC的自写笔记文档,这儿放不下这个默认的线程工厂无法通过new直接创建,只能通过
Executors.defaultThreadFactory()方法获取,这个工厂目前只了解到能规定线程池中线程名字的组织规则,暂时没有接触到其他用途
RejectedExecutionHandler handler:当核心线程、阻塞队列、救急线程都使用同时达到阈值,此时再来任务就会执行拒绝策略,JDK提供了四种拒绝策略实现,AbortPolicy让调用者抛出RejectedExecutionException异常,这是默认策略,自定义线程池不指定拒绝策略的情况下默认使用的就是该策略CallerRunsPolicy让调用者运行任务,即向线程池提交任务的线程执行任务,只要线程池没有被关闭,就会直接在当前线程直接调用传参的任务对象的run方法在当前线程直接执行DiscardPolicy放弃本次任务,什么打印信息都没有DiscardOldestPolicy放弃队列中最早的任务,本任务取而代之,抛弃的是最早放入队列中的任务
通过七大参数自定义线程池的代码示例
xxxxxxxxxxThreadPoolExecutor customExecutor = new ThreadPoolExecutor(5,200,10,TimeUnit.SECONDS,new LinkedBlockingDeque<>(100000),Executors.defaultThreadFactory(),new ThreadPoolExecutor.AbortPolicy());线程池的工作逻辑
阻塞队列一般设置为
new LinkedBlockingDeque<>()该阻塞队列的最大容量为Integer.MAX_VALUE,这个容量太大,如果任务量太大就可能导致服务器的内存被阻塞队列占满,因此阻塞队列在初始化时一定要指定满足业务要求的数量,这个数量一般也通过系统压力测试的性能峰值来确定,比如测出来阻塞队列容量为100000性能最好,就通过new LinkedBlockingDeque<>(100000)来指定阻塞队列的任务容量线程池创建以后就准备接收任务,所有的核心线程和救急线程都是懒惰创建的
任务被提交以后,核心线程先执行任务,如果核心线程都被占满,此时再进来任务就会进入阻塞队列,空闲的核心线程会自动从阻塞队列获取任务执行
如果阻塞队列也满了就会创建救急线程来执行新添加的任务,救急线程最大开到最大线程数-核心线程数个,如果救急线程数也满了就会按照线程池的拒绝策略拒绝执行任务
如果救急线程发生空闲且空闲时间超过指定的最大空闲时间,救急线程就会被销毁
面试问题
一个线程池,核心线程数7,最大线程数20,阻塞队列容量50,100个并发任务进来任务是怎么分配的
7个任务不经过阻塞队列会立即被核心线程执行
接着50个任务直接进入队列
再开13个救急线程直接执行添加的任务
剩下30个任务使用拒绝策略拒绝处理
使用线程池的优点
降低系统资源的消耗,利用重复已经创建好的线程降低线程的创建和销毁带来的性能损耗
限制住系统内正在运行的线程数量,避免线程太多导致频繁的线程上下文切换带来的性能损耗
提高对线程的管理能力,比如根据业务类型把业务分成核心业务和非核心业务,非核心任务比如发邮件码,发通知;有需要的时候可以关闭非核心线程池可以释放大量资源
项目中使用到的
CompletableFuture相关API初始化一个异步任务
runAsync:启动一个异步任务,该异步任务没有返回值,没有入参,可以使用指定线程池supplyAsync:启动一个异步任务,该异步任务有返回值,没有入参,可以使用指定线程池
两个异步任务,只要有一个完成,我们就执行任务3
runAfterEitherAsync:不感知异步任务结果,任务3自身也没有返回值acceptEitherAsync:感知异步任务结果,任务3自身也没有返回值,注意因为结果只是在两个异步任务中取其一,必须保证两个异步任务返回的结果类型一致,否则会直接编译报错applyToEitherAsync:感知异步任务结果,任务3自身有返回值,注意因为结果只是在两个异步任务中取其一,必须保证两个异步任务返回的结果类型一致,否则会直接编译报错
组合两个任务
thenCombine:两个异步任务,一个是调用者对应异步任务,一个是参数列表第一个参数对应的异步任务,参数列表2是一个BiFunction接口,当两个异步任务都执行结束后执行BiFunction接口,可以感知到两个异步任务的结果并对两个结果进行消费整合,BiFunction抽象方法传参第一个参数是调用者对应异步任务的结果,第二个参数是第一个参数对应异步任务的结果,该抽象方法的返回值将作为封装到该方法的返回值CompletableFuture对象中thenAcceptBoth:两个异步任务,一个是调用者对应异步任务,一个是参数列表第一个参数对应的异步任务,参数列表2是一个BiConsumer接口,当两个异步任务都执行结束后执行BiConsumer接口,可以感知到两个异步任务的结果并对两个结果进行消费,BiConsumer抽象方法传参第一个参数是调用者对应异步任务的结果,第二个参数是第一个参数对应异步任务的结果thenAfterBoth:两个异步任务,一个是调用者对应异步任务,一个是参数列表第一个参数对应的异步任务,参数列表2是一个Runnable接口,当两个异步任务都执行结束后执行Runnable接口,无法感知到两个异步任务的结果,也不能返回结果,适用于两个异步任务完成后发起一段通知
组合多个任务,阻塞当前线程直到所有任务都执行完或者阻塞当前线程直到第一个任务执行完
CompletableFuture.allOf:阻塞当前线程直到所有任务都执行完,该方法只是阻塞当前线程并不会整合结果,此外还可以通过该方法的返回值开启回调链,结果需要用户自己保存并在回调链进行处理,注意这里阻塞当前线程的说法是错的,PDF里面的笔记认为是allOf方法本身阻塞当前线程,但是实际测试allOf方法并不会阻塞当前线程直到所有异步任务执行结束,必须通过allOf方法返回的CompletableFuture<Void>来调用get方法或者回调方法比如thenRun才能阻塞当前线程,即这个阻塞当前线程的效果实际是通过allOf方法的返回值开启回调链或者get方法尝试获取值实现的效果anyOf:阻塞当前线程直到第一个任务执行完,该方法会返回第一个完成的异步任务并将结果封装到CompletableFuture对象中
异常处理
whenComplete:能感知到调用者异步任务执行结果[执行正常时异常为null]或者异步任务执行期间出现的异常[发生异常时结果为null],但是只能对结果或者异常进行消费,无法对调用者的结果进行修改,即该方法的返回值仍然是调用者原模原样的返回值,即不论是否发生异常都会执行该方法,但是特别注意该方法传参是一个BiConsumer接口,即只消费不返回参数,实际上返回参数是由whenComplete方法内部控制的exceptionally:注意该方法如果回调链发生了异常才会执行,传参是Function接口,该接口接收调用者出现的异常并且可以返回指定值进行兜底,这里传参Function<Throwable, ? extends T>的返回值参数类型继承了调用者封装的参数类型,意味着异常处理返回的兜底参数值需要和异常处理前的调用链的参数类型保持一致handle:该方法接收的传参是BiFunction接口,传参调用者的异步任务执行结果[执行正常时异常为null]或者[发生异常时结果为null],不论调用链是否发生异常都会执行该方法,该参数的返回值将作为handle方法的返回值封装到CompletableFuture对象中,即handle方法不仅能感知到调用者对应异步任务的结果还能对结果进行进一步回调操作并返回参与后续回调链,而且一旦回调链发生异常会直接进入离异常位置最近的handle进行异常处理,handle前面的回调链执行信息将会全部丢失
串行异步任务,两个任务具有依赖关系,后一个异步任务依赖前一个异步任务的结果
thenRun:该方法只要调用者对应异步任务执行结束就开始执行,传参Runnable接口,无法感知调用者对应异步任务的执行结果,该方法返回封装空值的CompletableFuture<Void>对象,适用于异步任务执行结束发起通知thenAccept:该方法在调用者对应异步任务执行结束就开始执行,传参Consumer接口,能够感知到调用者对应异步任务的执行结果并对该结果进行消费,该方法返回封装空值的CompletableFuture<Void>对象,适用于异步任务执行结束发起通知并对异步任务的执行结果进行消费thenApply:该方法在调用者对应异步任务执行结束就开始执行,传参Function接口,能够感知到调用者对应异步任务的执行结果,结果通过Function接口的返回值封装到CompletableFuture<U>对象中,适用于异步任务执行结束对结果进行处理并加入到后续回调链中
业务逻辑
跳转逻辑
让三级域名
item.earlmall.com跳转nginx,nginx携带对应host为三级域名并转发到网关,将该三级域名对应请求也路由到商品服务将详情页拷贝到
template目录下,这个项目的前台部分全是用Thymeleaf做的,这不好,会给服务器造成很大压力,将详情页的静态资源全部上传到nginx服务器上的item目录做动静分离,修改nginx配置将静态资源转发到item目录更改检索页面的商品跳转功能,把商品图片的链接地址指向商品详情页面,链接地址格式
http://item.earlmall.com/{skuId}.html,Thymeleaf在字符串中拼接变量的写法th:href="|http://item.earlmall.com/${product.skuId}.html|"即用两个竖线将字符串框起来
后端逻辑
创建一个VO类
SkuItemVo用来封装商品详情,封装的响应结果包括当前
Sku对应的基本信息,包含商品标题、副标题、价格、默认图片、spuId、商品分类id,对应sku基本信息表pms_sku_info,数据直接封装成skuInfoEntity当前
sku对应的所有图片信息,一个销售属性对应的所有图片[sku对应一个销售属性组合的细分商品,比如黑色商品64G就是一个sku],一个sku的所有图片信息封装成List<SkuImagesEntity>因为我们要在商品详情页展示所有的sku来供用户选择,因此还需要通过spu查询出所有spu下的所有销售属性,并在前端给出组合列表来对应一个skuId,销售属性整合需要自定义封装
我们需要查询到所有销售属性的名字和对应的可选值,我们可以设置一个销售属性VO即
SkuItemSaleAttrVo来封装单个销售属性的id、名字和可选值[可选值使用List<String>来进行封装,销售属性位于表pms_product_attr_value中,一个销售属性可选值和属性id对应一条记录,同一个属性id可能有多条记录],用一个List集合来封装一个商品下的所有销售属性和对应的属性值SQL
注意这里面的
mysql的GROUP_CONCAT函数,可以将多个记录的相同字段的值合并到分组的一条记录,并且以逗号相隔,使用DISTINCT来删除合并过程中重复的字段记录
xxxxxxxxxx<resultMap id="skuItemSaleAttrVo" type="com.earl.mall.product.vo.SkuItemVo$SkuItemSaleAttrVo"><result property="attrId" column="attr_id"/><result property="attrName" column="attr_name"/><result property="attrValues" column="attr_values"/></resultMap><select id="getSaleAttrs" resultMap="skuItemSaleAttrVo">SELECT ssav.attr_id,ssav.attr_name,GROUP_CONCAT(DISTINCT ssav.attr_value) attr_valuesFROM pms_sku_info siLEFT JOIN pms_sku_sale_attr_value ssav ON ssav.sku_id = si.sku_idWHERE si.spu_id = #{spuId}GROUP BY ssav.attr_id,ssav.attr_name</select>
获取spu介绍,一个spu下的所有sku都共享一个spu介绍并展示在商品介绍栏中,对应表
pms_spu_info_desc,spu介绍将介绍信息封装为SpuInfoDescEntity获取spu的基本属性,一个spu下的所有sku共享spu的基本属性并展示在规格与包装栏中,spu基本属性也需要自定义封装,因为页面展示spu基本属性的方式是属性分组--属性名--属性值,最终返回一个
SpuItemBaseAttrVo的list集合我们选择将一个属性分组封装为一个
SpuItemAttrGroupVo,包含String类型的属性分组名,以及封装了属性名和属性值的SpuBaseAttrVo的List集合,属性分组信息在表pms_attr_group,特别注意,这里的属性分组记录关联的是商品三级分类id,我们也可以通过从表pms_sku_info中通过skuId获取到商品所属三级分类id这里根据spuId和商品三级分类Id总共查询出来的字段包含属性分组名称、属性分组id、属性id、属性名称、属性值和spuId;
写SQL封装嵌套属性涉及到内部类的
ResultMap需要使用$内部类替代.内部类,使用后者内部类运行时会报错注意使用
MyBatis时数据封装到嵌套属性com.earl.mall.product.vo.SkuItemVo$SpuItemAttrGroupVo使用$标识的SpuItemAttrGroupVo必须是一个静态内部类,如果使用了$但是这个类如果没加static关键字会报错Error instantiating class com.earl.mall.product.vo.SkuItemVo$SpuItemAttrGroupVo with invalid types (SkuItemVo) or values (主体)
xxxxxxxxxx<!--获取商品属性分组信息,只要数据被封装到嵌套属性中就一定要封装嵌套结果集--><resultMap id="spuAttrGroupInfo" type="com.earl.mall.product.vo.SkuItemVo$SpuItemAttrGroupVo"><result property="attrGroupName" column="attr_group_name"/><collection property="spuBaseAttrs" ofType="com.earl.mall.product.vo.SkuItemVo$SpuBaseAttrVo"><result property="attrName" column="attr_name"/><result property="attrValue" column="attr_value"/></collection></resultMap><select id="getSpuAttrGroupInfo" resultMap="spuAttrGroupInfo">SELECT ag.attr_group_name,ag.attr_group_id,aar.attr_id,pav.attr_name,pav.attr_value,pav.spu_idFROM pms_attr_group agLEFT JOIN pms_attr_attrgroup_relation aar ON aar.attr_group_id=ag.attr_group_idLEFT JOIN pms_product_attr_value pav ON pav.attr_id=aar.attr_idWHERE ag.catelog_id=#{catelogId} AND pav.spu_id=#{spuId}</select>
SpuBaseAttrVo封装基本属性名和基本属性值,一个基本属性只会有一个基本属性值
这个设计还缺乏比如多少人预约、哪个店铺、商品对应的所属商品分类、spu名称、sku名称没有管,有兴趣再补充
xxxxxxxxxxpackage com.earl.mall.product.vo;import com.earl.common.to.SkuStockExistTo;import com.earl.mall.product.entity.SkuImagesEntity;import com.earl.mall.product.entity.SkuInfoEntity;import com.earl.mall.product.entity.SpuInfoDescEntity;import lombok.Data;import java.util.List;/*** @author Earl* @version 1.0.0* @描述 商品详情页封装* @创建日期 2024/09/26* @since 1.0.0*/public class SkuItemVo {/*** 封装sku的基本信息*/private SkuInfoEntity skuInfo;/*** 封装sku下的所有商品图片*/private List<SkuImagesEntity> skuImages;/*** sku对应商品是否有库存*/private SkuStockExistTo stockInfo = new SkuStockExistTo();/*** 封装sku下的所有销售属性和对应的属性值*/private List<SkuItemSaleAttrVo> saleAttrs;/*** 商品spu介绍*/private SpuInfoDescEntity spuInfoDesc;/*** 商品spu基础属性分组和属性分组下的属性名、属性值*/private List<SpuItemAttrGroupVo> spuAttrGroups;/*** @author Earl* @version 1.0.0* @描述 封装sku的一个销售属性* @创建日期 2024/09/26* @since 1.0.0*/public static class SkuItemSaleAttrVo{/*** 销售属性id*/private Long attrId;/*** 销售属性名称*/private String attrName;/*** 所有销售属性值*/private String attrValues;}/*** @author Earl* @version 1.0.0* @描述 封装sku对应的spu的商品属性分组信息* @创建日期 2024/09/26* @since 1.0.0*/public static class SpuItemAttrGroupVo{/*** 属性分组名称*/private String attrGroupName;/*** 当前属性分组下的属性和属性值*/private List<SpuBaseAttrVo> spuBaseAttrs;}/*** @author Earl* @version 1.0.0* @描述 商品基础属性* @创建日期 2024/09/26* @since 1.0.0*/public static class SpuBaseAttrVo{/*** spu基础属性名*/private String attrName;/*** 基本属性值*/private String attrValue;}}[封装数据方法]
xxxxxxxxxx/*** @param skuId* @return {@link SkuItemVo }* @描述 根据商品skuId获取商品详情页的所有商品信息,包含:* 当前`Sku`对应的基本信息,* 当前`sku`对应的所有图片信息,* 查询出所有spu下的所有销售属性* 远程调用库存服务查询商品库存* 获取spu介绍,* 获取spu的基本属性,* @author Earl* @version 1.0.0* @创建日期 2024/09/26* @since 1.0.0*/public SkuItemVo getSkuItemInfo(Long skuId) {//准备封装查询结果的容器SkuItemVo skuItem = new SkuItemVo();//1. 当前`Sku`对应的基本信息SkuInfoEntity skuInfo= skuInfoService.getById(skuId);skuItem.setSkuInfo(skuInfo);//6. 根据skuId获取库存信息,远程调用库存服务List<SkuStockExistTo> skuStockExistTos = null;try{skuStockExistTos = stockFeignClient.isStockExist(Arrays.asList(skuId)).getData(new TypeReference<List<SkuStockExistTo>>() {});}catch (Exception e){log.error("远程调用库存服务异常,原因:{}",e);}if (skuStockExistTos !=null && skuStockExistTos.size()>0){skuItem.setStockInfo(skuStockExistTos.get(0));}//2. 当前`sku`对应的所有图片信息List<SkuImagesEntity> skuImages = skuImagesService.list(new QueryWrapper<SkuImagesEntity>().eq("sku_id", skuId));skuItem.setSkuImages(skuImages);if(skuInfo != null ){Long spuId = skuInfo.getSpuId();//3. 查询出所有spu下的所有销售属性List<SkuItemVo.SkuItemSaleAttrVo> saleAttrs= baseMapper.getSaleAttrs(spuId);skuItem.setSaleAttrs(saleAttrs);//4. 获取spu介绍SpuInfoDescEntity spuInfoDesc = spuInfoDescService.getById(spuId);skuItem.setSpuInfoDesc(spuInfoDesc);//5. 获取spu的基本属性分组和基本属性List<SkuItemVo.SpuItemAttrGroupVo> spuAttrGroups=attrGroupService.getSpuAttrGroupInfo(skuInfo.getCatelogId(),spuId);skuItem.setSpuAttrGroups(spuAttrGroups);}return skuItem;}使用异步任务的方式分别查询出上述信息并封装到
SkuItemVo中
前端页面数据渲染
使用
Thymeleaf和sku基本信息渲染页面标题、副标题、默认大图从sku的基本信息中skuDefaultImg获取[大图放大是前端实现的效果,showbox组件需要使用和默认大图相同的图片]、价格信息[价格默认显示小数点后4个0,使用Thymeleaf的格式化语法,Thymeleaf的Numbers章节的Formatting decimal Numbers展示了格式化api,其中${#numbers.formatDecimal(num,3,2)}表示num整数位保留3位,小数位保留2位,整数位超出3位也能正常显示]、优惠活动链接没有设计,这里就不添加了
xxxxxxxxxx<div class="box-one " th:with="skuInfo=${skuItem.skuInfo},skuImages=${skuItem.skuImages}"><div class="boxx"><div class="imgbox"><div class="probox"><img class="img1" alt="" th:src="${skuInfo.skuDefaultImg}"><div class="hoverbox"></div></div><div class="showbox"><img class="img1" alt="" th:src="${skuInfo.skuDefaultImg}"></div></div><div class="box-lh"><div class="box-lh-one"><ul><li th:each="skuImage:${skuImages}" th:if="${!#strings.isEmpty(skuImage.imgUrl)}"><img th:src="${skuImage.imgUrl}"/></li></ul></div><div id="left"><</div><div id="right">></div></div></div><div class="box-two" ><div class="box-name" th:text="${skuInfo.skuTitle}">华为 HUAWEI Mate 10 6GB+128GB 亮黑色 移动联通电信4G手机 双卡双待</div><div class="box-hide" th:text="${skuInfo.skuSubtitle}">预订用户预计11月30日左右陆续发货!麒麟970芯片!AI智能拍照!</div></div></div>有无货需要单独设置一个默认有货的属性并通过查询数据库得知
xxxxxxxxxx<div class="box-stock"><ul class="box-ul"><li>配送至</li><li><span th:if="${!skuItem.stockInfo.isExist}">无货,此商品暂时售完</span></li></ul></div>遍历大图底部所有的sku图片,图片如果是空数据还要使用th:if来将图片隐藏
xxxxxxxxxx<div class="box-lh-one"><ul><li th:each="skuImage:${skuImages}" th:if="${!#strings.isEmpty(skuImage.imgUrl)}"><img th:src="${skuImage.imgUrl}"/></li></ul></div>遍历销售属性,拿到属性值和属性名
th:each="val:${#strings.listSplit(String str,',')}"将字符串用逗号分隔返回字符串片段数组
xxxxxxxxxx<div class="box-attr-2 clear" th:each="attr:${skuItem.saleAttrs}"><dl><dt>选择[[${attr.attrName}]]</dt><dd th:each="attrValue:${#strings.listSplit(attr.attrValues,',')}"><a href="#" th:text="${attrValue}">标准版</a></dd></dl></div>商品介绍,商品介绍是从spu的desc中取的图片数据,所有的图片都是用逗号分隔的
xxxxxxxxxx<img class="xiaoguo"th:each="desc:${#strings.listSplit(skuItem.spuInfoDesc.decript,',')}"th:src="${desc}"/>spu属性,遍历每个属性组,遍历每个属性组下的属性并进行展示
xxxxxxxxxx<li class="baozhuang actives" id="li2"><div class="guiGebox"><div class="guiGe" th:each="attGroup:${skuItem.spuAttrGroups}"><h3 th:text="${attGroup.attrGroupName}">主体</h3><dl><div th:each="attr:${attGroup.spuBaseAttrs}"><dt th:text="${attr.attrName}">品牌</dt><dd th:text="${attr.attrValue}">华为(HUAWEI)</dd></div></dl></div></div></li>
拓展业务
业务逻辑:在sku对应spu的列表选择一种销售属性组合发起请求渲染对应skuId商品的详情
用倒排索引的思想,让每个销售属性值都封装一个包含对应属性和属性值的
skuId的属性,让页面加载的时候根据销售属性中的skuId列表中是否包含用户检索商品的skuId来判断当前销售属性是否选中属性【一种唯一的销售属性组合是一种sku】,选中的销售属性会给class属性添加checked关键字,我们可以通过该关键字来将属性切换为选中状态xxxxxxxxxxpackage com.earl.mall.product.vo;import com.earl.common.to.SkuStockExistTo;import com.earl.mall.product.entity.SkuImagesEntity;import com.earl.mall.product.entity.SkuInfoEntity;import com.earl.mall.product.entity.SpuInfoDescEntity;import lombok.Data;import java.util.List;/*** @author Earl* @version 1.0.0* @描述 商品详情页封装* @创建日期 2024/09/26* @since 1.0.0*/public class SkuItemVo {/*** 封装sku的基本信息*/private SkuInfoEntity skuInfo;/*** 封装sku下的所有商品图片*/private List<SkuImagesEntity> skuImages;/*** sku对应商品是否有库存*/private SkuStockExistTo stockInfo = new SkuStockExistTo();/*** 封装sku下的所有销售属性和对应的属性值*/private List<SkuItemSaleAttrVo> saleAttrs;/*** 商品spu介绍*/private SpuInfoDescEntity spuInfoDesc;/*** 商品spu基础属性分组和属性分组下的属性名、属性值*/private List<SpuItemAttrGroupVo> spuAttrGroups;/*** @author Earl* @version 1.0.0* @描述 封装sku的一个销售属性* @创建日期 2024/09/26* @since 1.0.0*/public static class SkuItemSaleAttrVo{/*** 销售属性id*/private Long attrId;/*** 销售属性名称*/private String attrName;/*** 所有销售属性值和对应包含该销售属性的skuId列表*/private List<SkuIdInvertIndexOfAttrValue> attrValues;}/*** @author Earl* @version 1.0.0* @描述 skuId关于销售属性值的倒排索引表* @创建日期 2024/09/28* @since 1.0.0*/public static class SkuIdInvertIndexOfAttrValue{/*** 指定销售属性名下的其中一个属性值*/private String attrValue;/*** 包含指定属性值的skuId列表,skuId之间使用逗号分隔*/private String skuIds;}/*** @author Earl* @version 1.0.0* @描述 封装sku对应的spu的商品属性分组信息* @创建日期 2024/09/26* @since 1.0.0*/public static class SpuItemAttrGroupVo{/*** 属性分组名称*/private String attrGroupName;/*** 当前属性分组下的属性和属性值*/private List<SpuBaseAttrVo> spuBaseAttrs;}/*** @author Earl* @version 1.0.0* @描述 商品基础属性* @创建日期 2024/09/26* @since 1.0.0*/public static class SpuBaseAttrVo{/*** spu基础属性名*/private String attrName;/*** 基本属性值*/private String attrValue;}}查询和聚合
skuId列表信息的SQLxxxxxxxxxx<resultMap id="skuItemSaleAttrVo" type="com.earl.mall.product.vo.SkuItemVo$SkuItemSaleAttrVo"><result property="attrId" column="attr_id"/><result property="attrName" column="attr_name"/><collection property="attrValues" ofType="com.earl.mall.product.vo.SkuItemVo$SkuIdInvertIndexOfAttrValue"><result property="attrValue" column="attr_value"/><result property="skuIds" column="sku_ids"/></collection></resultMap><select id="getSaleAttrs" resultMap="skuItemSaleAttrVo">SELECT ssav.attr_id,ssav.attr_name,ssav.attr_value,GROUP_CONCAT(ssav.sku_id) sku_idsFROM pms_sku_info siLEFT JOIN pms_sku_sale_attr_value ssav ON ssav.sku_id = si.sku_idWHERE si.spu_id = #{spuId}GROUP BY ssav.attr_id,ssav.attr_name,ssav.attr_value</select>Thymeleaf的#lists.contains(list,elements)能判断list集合中是够含有某个元素,注意啊,这个elements的类型必须和list中的元素类型保持一致,否则即使Long类型的数字和字符串类型的数字一样也会报错,一般调用elements.toString()就能让数字变成对应的字符串当前商品
skuId对应的销售属性的超链接标签对应的class属性会添加checked关键字来对当前sku的销售属性进行标注,判断依据是当前销售属性值的skuId列表中包含查询当前页面的skuId
xxxxxxxxxx<div class="box-attr-2 clear" th:each="attr:${skuItem.saleAttrs}"><dl><dt>选择[[${attr.attrName}]]</dt><dd th:each="attrValue:${attr.attrValues}"><a href="#"th:text="${attrValue.attrValue}"th:attr="class=${#lists.contains(#strings.listSplit(attrValue.skuIds,','),skuInfo.skuId.toString())?'sku_attr_value checked':'sku_attr_value'},skuIds=${attrValue.skuIds}">标准版</a></dd></dl></div>用
js和JQuery实现页面刚加载完成就去掉所有销售属性的父标签样式,并给被选中的销售属性添加选中样式jquery的${function()}在页面加载完成以后就执行$(".sku_attr_value")和$("a[class='sku_attr_value checked']")都是JQuery中的用法,都是选中指定的组件元素,$(".sku_attr_value")是选中class属性是sku_attr_value的,$("a[class='sku_attr_value checked']")是选中<a>标签中class属性且属性值为sku_attr_value checked的Dom元素,这里面还可以用逻辑判断,比如$("a[!class='sku_attr_value checked']")是选中<a>标签中class属性值不为sku_attr_value checked的Dom元素
xxxxxxxxxx$(function(){$(".sku_attr_value").parent().css({"border":"solid 1px #CCC"});$("a[class='sku_attr_value checked']").parent().css({"border":"solid 1px red"});})当销售属性中的属性值被点击以后调用点击事件
被点击的销售属性给class属性添加checked标识,给原来相同属性的属性值的checked标记取消掉
获取到所有被添加了class添加了checked的销售属性并获取销售属性对应的skuIds列表,对所有的skuIds列表取交集,修改当前请求路径为对应skuId并发起跳转请求
JQuery的$(this).addClass("clicked")能给指定Dom元素的class属性追加关键字clicked,会自动和原来的class属性以空格分隔,JQuery的$(this).removeClass("clicked")能将对应Dom元素的class属性中的子串clicked给移除掉JQuery的$(this).attr("skus")能获取指定Dom元素的skus属性值,一般属性值都是字符串,字符串可以通过js的语法$(this).attr("skus").split(',')用逗号分割为数组JQuery的$(this).find(".sku_attr_value")能获取指定Dom元素下的所有class属性值为sku_attr_value的子Dom元素,注意find方法不是严格要求子Dom元素必须等于sku_attr_value,感觉以空格隔开的整体可以视为一个属性值,但是class属性还是第一个空格前的内容,这里再次学习JQuery的时候再严格辨析JQuery的$("a[class='sku_attr_value checked']").each(function(){...})方法能获取所有<a>标签中class属性值为sku_attr_value checked的Dom元素并在each方法中对每一个获取到的元素执行一段相同的操作JS中数组可以调用
push(元素)方法向数组中添加元素,这个元素可以是数组,我们可以通过skus[0]取到该元素,但是数组中不能保存JQuery对象xxxxxxxxxxvar skus = new Array();skus.push($(this).attr("skus").split(','));JQuery可以通过$(数组)将一个数组包装成JQuery元素,这样我们可以通过JQuery对象的api来对数组进行操作,比如求两个数组的交集并返回交集JQuery对象,注意只有第一个数组filter的调用者才需要封装为JQuery对象,第二个数组作为传参不需要封装为JQuery对象,返回值也是JQuery对象,通过返回值JQuery对象[0]可以取出JQuery对象的元素,我们需要对所有被选中销售属性的对应skuIds数组元素用前两个求交集的结果和后一个skuIds数组求交集的结果直到遍历完所有skuIds数组xxxxxxxxxxvar filterEle = skus[0];for(var i=1;i<skus.length;i++){filterEle=$(filterEle).filter(skus[i]);}console.log(filterEle[0]);
[上述API使用的示例代码]
xxxxxxxxxx$(".sku_attr_value").click(function (){//1. 取消原来的选中属性的选中状态,为点击属性添加选中状态//注意这里找的是孙元素,因此这里不能使用children方法来使用类选择器,而且类选择器只能是第一个空格前面的内容,带上空格后面的内容不会出效果//类选择器必须使用点作为开头,如果没有点也是没有效果的$(this).parent().parent().find(".sku_attr_value").removeClass("checked");$(this).addClass("checked");//2. 遍历所有选中销售属性的skuIds列表,var skuIdsList = new Array();$("a[class='sku_attr_value checked']").each(function (){skuIdsList.push($(this).attr("skuIds").split(','));});//3. 对所有skuIds列表求交集var skuIdObj = skuIdsList[0];for(var i=1;i<skuIdsList.length;i++){skuIdObj=$(skuIdObj).filter(skuIdsList[i]);}//4. 从新发起对新销售属性对应商品的查询location.href="http://item.earlmall.com/"+skuIdObj[0]+".html";});
异步编排
异步编排前的业务逻辑
其中业务1,6,2都可以直接根据
skuId直接异步查,3,4,5需要从1的查询结果中获取spuId和三级商品分类id才能查我们可以让1,6,2一开始就异步执行,让3,4,5等待1执行后再执行
xxxxxxxxxx/*** @param skuId* @return {@link SkuItemVo }* @描述 根据商品skuId获取商品详情页的所有商品信息,包含:* 当前`Sku`对应的基本信息,* 当前`sku`对应的所有图片信息,* 查询出所有spu下的所有销售属性* 获取spu介绍,* 获取spu的基本属性,* @author Earl* @version 1.0.0* @创建日期 2024/09/26* @since 1.0.0*/public SkuItemVo getSkuItemInfo(Long skuId) {long start = System.currentTimeMillis();//准备封装查询结果的容器SkuItemVo skuItem = new SkuItemVo();//1. 当前`Sku`对应的基本信息SkuInfoEntity skuInfo= skuInfoService.getById(skuId);skuItem.setSkuInfo(skuInfo);//6. 根据skuId获取库存信息,远程调用库存服务List<SkuStockExistTo> skuStockExistTos = null;try{skuStockExistTos = stockFeignClient.isStockExist(Arrays.asList(skuId)).getData(new TypeReference<List<SkuStockExistTo>>() {});}catch (Exception e){log.error("远程调用库存服务异常,原因:{}",e);}if (skuStockExistTos !=null && skuStockExistTos.size()>0){skuItem.setStockInfo(skuStockExistTos.get(0));}//2. 当前`sku`对应的所有图片信息List<SkuImagesEntity> skuImages = skuImagesService.list(new QueryWrapper<SkuImagesEntity>().eq("sku_id", skuId));skuItem.setSkuImages(skuImages);if(skuInfo != null ){Long spuId = skuInfo.getSpuId();//3. 查询出所有spu下的所有销售属性List<SkuItemVo.SkuItemSaleAttrVo> saleAttrs= baseMapper.getSaleAttrs(spuId);skuItem.setSaleAttrs(saleAttrs);//4. 获取spu介绍SpuInfoDescEntity spuInfoDesc = spuInfoDescService.getById(spuId);skuItem.setSpuInfoDesc(spuInfoDesc);//5. 获取spu的基本属性分组和基本属性List<SkuItemVo.SpuItemAttrGroupVo> spuAttrGroups=attrGroupService.getSpuAttrGroupInfo(skuInfo.getCatelogId(),spuId);skuItem.setSpuAttrGroups(spuAttrGroups);}System.out.println(System.currentTimeMillis() - start + "ms");return skuItem;}配置自定义线程池
定义线程池参数配置类
xxxxxxxxxxpackage com.earl.mall.product.properties;import lombok.Data;import org.springframework.boot.context.properties.ConfigurationProperties;import org.springframework.stereotype.Component;/*** @author Earl* @version 1.0.0* @描述 线程池配置参数* `@ConfigurationProperties`注解指定配置前缀,这个配置类必须通过@Component注解放在容器中才能生效,* 否则`@ConfigurationProperties`注解会报错* 配置了默认值即使不配置参数线程池初始化也不会出问题* @创建日期 2024/09/29* @since 1.0.0*/(prefix = "earl.mall.thread")public class ThreadPoolProperties {private Integer corePoolSize = 20;private Integer maximumPoolSize = 200;private Integer keepAliveTime = 10;}引入
spring-boot-configuration-processor依赖xxxxxxxxxx<!--使用SpringBoot的@ConfigurationProperties时需要引入该spring-boot-configuration-processor依赖--><!--这是SpringBoot的元数据处理器,以后在配置文件写自定义配置就会提示对应的可配置选项,不加做了配置也是完全可以运行的,只是没有可选配置提示--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-configuration-processor</artifactId><optional>true</optional></dependency>线程池组件
xxxxxxxxxxpackage com.earl.mall.product.config;import com.earl.mall.product.properties.ThreadPoolProperties;import org.springframework.boot.context.properties.EnableConfigurationProperties;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;import java.util.concurrent.Executors;import java.util.concurrent.LinkedBlockingDeque;import java.util.concurrent.ThreadPoolExecutor;import java.util.concurrent.TimeUnit;/*** @author Earl* @version 1.0.0* @描述 自定义线程池配置* @创建日期 2024/09/29* @since 1.0.0*///@EnableConfigurationProperties(ThreadPoolProperties.class)public class CustomThreadPoolConfig {/*** @return {@link ThreadPoolExecutor }* @描述 自定义线程池对象,不指定线程工厂和拒绝策略都是使用与下面相同的默认工厂和默认拒绝策略* 如果配置类已经通过@Component注解添加到容器中我们可以直接在初始化容器组件的参数中获取* 如果配置类没有注入容器中,我们可以通过在配置类上使用注解`@EnableConfigurationProperties(ThreadPoolProperties.class)`* 在该配置类中使用对应的配置类* @author Earl* @version 1.0.0* @创建日期 2024/09/29* @since 1.0.0*/public ThreadPoolExecutor threadPoolExecutor(ThreadPoolProperties poolProperties){return new ThreadPoolExecutor(poolProperties.getCorePoolSize(),poolProperties.getMaximumPoolSize(),poolProperties.getKeepAliveTime(),TimeUnit.SECONDS,new LinkedBlockingDeque<>(100000),Executors.defaultThreadFactory(),new ThreadPoolExecutor.AbortPolicy());}}配置文件配置示例
可选配置提示也没有问题
xxxxxxxxxxearlmallthreadcore-pool-size23maximum-pool-size201keep-alive-time15
异步编排后的业务逻辑
xxxxxxxxxx/*** @param skuId* @return {@link SkuItemVo }* @描述 根据商品skuId获取商品详情页的所有商品信息,包含:* 当前`Sku`对应的基本信息,* 当前`sku`对应的所有图片信息,* 查询出所有spu下的所有销售属性* 获取spu介绍,* 获取spu的基本属性,* 除了第一次450ms,后续都是6-15ms之间,之前都是稳定10ms以上* @author Earl* @version 1.0.0* @创建日期 2024/09/26* @since 1.0.0*/public SkuItemVo getSkuItemInfo(Long skuId) {long start = System.currentTimeMillis();//准备封装查询结果的容器SkuItemVo skuItem = new SkuItemVo();CompletableFuture<Void> stockInfoFuture = CompletableFuture.runAsync(() -> {//6. 根据skuId获取库存信息,远程调用库存服务List<SkuStockExistTo> skuStockExistTos = null;try {skuStockExistTos = stockFeignClient.isStockExist(Arrays.asList(skuId)).getData(new TypeReference<List<SkuStockExistTo>>() {});} catch (Exception e) {log.error("远程调用库存服务异常,原因:{}", e);}if (skuStockExistTos != null && skuStockExistTos.size() > 0) {skuItem.setStockInfo(skuStockExistTos.get(0));}}, threadPoolExecutor);CompletableFuture<Void> imgFuture = CompletableFuture.runAsync(() -> {//2. 当前`sku`对应的所有图片信息List<SkuImagesEntity> skuImages = skuImagesService.list(new QueryWrapper<SkuImagesEntity>().eq("sku_id", skuId));skuItem.setSkuImages(skuImages);}, threadPoolExecutor);CompletableFuture<SkuInfoEntity> skuInfoFuture = CompletableFuture.supplyAsync(() -> {//1. 当前`Sku`对应的基本信息SkuInfoEntity skuInfo = skuInfoService.getById(skuId);skuItem.setSkuInfo(skuInfo);return skuInfo;},threadPoolExecutor);CompletableFuture<Void> saleAttrsFuture = null;CompletableFuture<Void> spuInfoDescFuture = null;CompletableFuture<Void> spuAttrGroupsFuture = null;try {if(skuInfoFuture.get() != null){saleAttrsFuture = skuInfoFuture.thenAcceptAsync(skuInfo -> {//3. 查询出所有spu下的所有销售属性List<SkuItemVo.SkuItemSaleAttrVo> saleAttrs = baseMapper.getSaleAttrs(skuInfo.getSpuId());skuItem.setSaleAttrs(saleAttrs);}, threadPoolExecutor);spuInfoDescFuture=skuInfoFuture.thenAcceptAsync(skuInfo -> {//4. 获取spu介绍SpuInfoDescEntity spuInfoDesc = spuInfoDescService.getById(skuInfo.getSpuId());skuItem.setSpuInfoDesc(spuInfoDesc);}, threadPoolExecutor);spuAttrGroupsFuture=skuInfoFuture.thenAcceptAsync(skuInfo -> {//5. 获取spu的基本属性分组和基本属性List<SkuItemVo.SpuItemAttrGroupVo> spuAttrGroups=attrGroupService.getSpuAttrGroupInfo(skuInfo.getCatelogId(),skuInfo.getSpuId());skuItem.setSpuAttrGroups(spuAttrGroups);}, threadPoolExecutor);}CompletableFuture.allOf(stockInfoFuture,imgFuture,saleAttrsFuture,spuInfoDescFuture,spuAttrGroupsFuture).get();} catch (InterruptedException e) {e.printStackTrace();} catch (ExecutionException e) {e.printStackTrace();}System.out.println(System.currentTimeMillis() - start + "ms");return skuItem;}
认证服务
购物车、支付等功能需要登录,需要加入登录功能,在系统内构建一个OAuth2.0认证中心,凡是涉及到登录操作业务接口,我们都要预先访问该认证中心,认证通过了才允许访问这些接口,初始化一个
mall-auth来创建一个认证服务,集成OAuth2.0社交账号登录、单点登录功能,通过-Xmx100m限制服务的内存占用大小,避免电脑内存不够初始化时添加web、dev-tool功能、因为认证服务需要远程连接用户服务,所以需要OpenFeign来实现远程调用功能,引入我们的基础包构建基础服务,加入Thymeleaf来做页面渲染,将服务注册到注册中心中,开启远程调用功能
服务构建
将登录页面和注册页面放入
Template目录下,将对应的静态文件上传到nginx服务器中做动静分离,认证服务使用三级域名auth.mall.com注意,即便是放在
Template目录下的index页面也不需要使用控制器做路径映射,SpringMVC会自动映射将登录页的图标路由到商城首页,将商城首页的登录页面路由到登录页面,将注册页面路由到注册页面,登录页的注册按钮能直接跳到注册页,注册页的登录按钮能跳到登录页
短信验证码
注册页面需要发送手机验证码来对用户电话号码进行验证
SMS[Short Message Service]
前端短信验证码需求
点击发送验证码,把发送验证码设置为超链接,通过绑定单机事件,点击超链接后会发送一个请求去获取短信验证码,同时页面会出现60s后才能再次点击的倒计时,倒计时结束才能再次点击按钮
弹窗组件使用自定义弹窗组件,因为在
JavaScript中,alert会阻塞代码执行,包括异步的setTimeout方法。这是因为alert是一个同步操作,它会暂停浏览器中的所有其他操作,直到用户点击alert弹窗的确定按钮。即使用alert弹窗来弹出提示消息会把计时异步操作也阻塞掉,所以需要使用自定义弹窗组件[html]
xxxxxxxxxx<!-- 弹窗的HTML结构 --><div id="myModal" class="modal"><!-- 弹窗内容 --><div class="modal-content"><span class="close">×</span><p id="showBox">这是一个非阻塞式的自定义弹窗!</p></div></div>[css]
xxxxxxxxxx<style>/* 弹窗的基本样式 */.modal {display: none; /* 默认隐藏 */position: fixed; /* 固定位置 */z-index: 1; /* 确保弹窗在最上层 */left: 0;top: 0;width: 100%; /* 宽度100% */height: 100%; /* 高度100% */background-color: rgba(0,0,0,0.4); /* 黑色半透明 */}/* 弹窗内容的样式 */.modal-content {position: relative;background-color: #fefefe;margin: auto; /* 居中显示 */border: 1px solid #888;padding: 6px;width: 20%; /* 可以调整宽度 */box-shadow: 0 4px 8px 0 rgba(0,0,0,0.2); /* 添加阴影效果 */height: 3vh; /* 视口高度 */top: 10px;}/* 关闭按钮的样式 */.close {color: #aaa;float: right;font-size: 28px;font-weight: bold;}.close:hover,.close:focus {color: black;text-decoration: none;cursor: pointer;}</style>[js]
我们让请求响应的时候打开弹窗,弹窗打开后四秒自动关闭,同时点击弹窗或者页面也能关闭弹窗,且不会阻塞计时任务的执行
xxxxxxxxxx//打开弹窗modal.style.display = "block";// 点击<span> (x), 关闭弹窗$("#myModal").click(function (){modal.style.display = "none";});// 在用户点击弹窗之外的地方时,关闭弹窗window.onclick = function(event) {if (event.target == modal) {modal.style.display = "none";}}60s倒计时可以通过JavaScript计时来实现,在W3School的JS教程中有一个JS Timing计时API,计时事件有两个关键方法
setTimeout()[在指定时间后再去执行一段代码,注意这个js代码也可以是一段js方法,但是这段js代码使用双引号括起来即传参是字符串]和clearTimeout()[取消掉setTimeout()方法的执行][
setTimeout()语法]xxxxxxxxxxvar t=setTimeout("javascript语句",毫秒);倒计时的逻辑是使用js的定时任务
setTimeout,每隔一秒让数字减1并且使用JQuery的$(this).text(倒计时)来实时来定时更改组件的文字显示内容,当数字减至0让数字重置,让文本再次显示为可发送验证码,点击事件设置一个class属性值disabled,计时任务执行期间disabled一直存在,disabled存在就不允许再倒计时,什么都不做,如果可以倒计时在倒计时前给指定手机号发送验证码点击事件发生后先对手机号码进行校验,检验空和使用正则校验对应的格式并给出相应的判断
JQuery中的$(this).hasClass("disabled")是判断当前Dom组件中的class属性中是否有disabled关键字手机号通过
JQuery的$("#phoneNumber").val()获取可以直接通过
JQuery的$.get("uri")发起get方式的ajax请求,$.get("uri",function(data){对返回值的进一步处理}),data就是我们响应的数据防用户刷新页面再次发送验证码我们查询
redis对应手机号码的有效时间并从提示信息中用正则取出数字,提示用户在有效时间后再次点击获取的同时以该有效时间进行倒计时
[html]
xxxxxxxxxx<div class="register-box"><label for="username" class="other_label">验 证 码<input maxlength="20" type="text" placeholder="请输入验证码" class="caa"></label><a class="smsCode">获取验证码</a><div class="tips"></div></div>[js]
因为我们用jQuery的方式发起发送短信的get请求,这样会直接在浏览器暴露我们的短信发送接口,不法分子可以拿到接口地址攻击我们的短信接口消耗我们的短信资源
该问题我们通过在后端实际限制同一个号码发起两个发短信请求的时间间隔解决
倒计时功能也只是针对当前页面,只要用户重新刷新初始化当前页面,倒计时功能就消失了,此时用户又可以在倒计时结束前再次发起发送短信请求了,因此我们需要针对这两个方面来做短信发送接口的防刷功能
该问题我们也可以通过在后端实际限制同一个号码发起两个发短信请求的时间间隔解决,这个问题我们还通过查询剩余间隔时间提示用户并重新从剩余有效时间开始倒计时,非常的人性化
xxxxxxxxxx//点击获取验证码发送ajax请求到后端获取验证码接口并且前端开始进行一分钟倒计时// 获取弹窗元素和关闭按钮var sendInterval=60;var displayTime=0;var modal = document.getElementById("myModal");function timeoutChangeStyle(time){if(time!=null){sendInterval = time;}if(sendInterval==0){$(".smsCode").text("获取验证码");sendInterval=60;displayTime=0;$(".smsCode").removeClass("disabled");}else{if(displayTime==4){modal.style.display = "none";}$(".smsCode").text(sendInterval+"s 后请再次尝试")sendInterval--;displayTime++;setTimeout("timeoutChangeStyle()",1000);}}//点击获取验证码的点击事件,验证电话号码格式并发送验证码$(".smsCode").click(function (){var phoneNum = $(".phone").val();//手机格式正则var regex = /^1[3-9]\d{9}$/;if (phoneNum.length == 0) {$(".phone").parent().next("div").text("请输入手机号码");$(".phone").parent().next("div").css("color", '#ccc');} else if (!regex.test(phoneNum)) {$(".phone").parent().next("div").text("手机号格式不正确");$(".phone").parent().next("div").css("color", 'red');} else {$(".phone").parent().next("div").text("");//1. 如果class属性没有class属性增加disabled关键字,然后发起ajax请求尝试获取短信验证码,然后就开始进行倒计时if(!$(this).hasClass("disabled")){$(this).addClass("disabled");$.get("/registry/sms/code?phoneNum="+phoneNum,function (data){timeoutChangeStyle(data.msg.match(/\d+/g));if(data.code!=0){modal.style.display = "block";$("#showBox").text(data.msg);}else {modal.style.display = "block";$("#showBox").text(data.data);}})}else{//2. 如果有disabled关键字就什么都不做}}});
视图映射
我们可以通过配置
WebMvcConfigurer的子实现配置类,通过重写addViewControllers(ViewControllerRegistry registry)方法,在该方法中通过多次调用registry.addViewController(String urlPath).setViewName(String viewName)来一次性设置多个视图路径映射关系,这样可以避免在控制器中写一堆只负责请求路径页面跳转的空方法默认使用的都是GET请求的方式来处理视图映射
以下配置了URI
/login.html对视图template/login.html,/registry.html对视图template/registry.html的映射
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 认证服务自定义视图映射器* 默认使用的都是GET请求的方式来处理视图映射* @创建日期 2024/10/01* @since 1.0.0*/public class CustomWebMvcConfigurer implements WebMvcConfigurer {public void addViewControllers(ViewControllerRegistry registry) {registry.addViewController("/login.html").setViewName("login");registry.addViewController("/registry.html").setViewName("registry");}}后端短信验证码业务逻辑
我这里没有使用老师用的第三方厂商接口,自己找了一个国阳云的短信接口实现的
阿里云短信验证码服务
阿里云的发送短信验证码服务都是外包的,有很多商家,可以选择合适的自己进行使用,根据产品文档介绍自己抽取组价使用就行了,主要三个方面,一个是抽取组件注入容器按需使用,第二是凡是需要自己配置的参数全部抽取到配置文件进行配置方便管理和修改,第三是短信发送业务使用服务器来进行请求防止暴露身份验证信息导致出现安全问题
把短信验证码服务放在第三方服务
mall-third-party模块中,提供给其他服务来进行远程调用在
mall-auth服务对第三方服务的短信服务进行调用,用户发送短信太频繁通过抛异常的方式进行处理并提示剩余间隔时间[接口service方法]
用
lua脚本一次性执行三条redis指令,降低网络IO成本,缓存用户间隔电话号码+_restInterval,设置有效期一分钟,只要该键值对存在就返回剩余有效时间并直接抛出异常[异常状态码:15000]提示剩余有效时间;为了避免此前的验证码失效,也为了避免验证码一直续期容易被定时任务攻击,直接每一个验证码都创建一个键值对电话号码+_验证码的记录,设置有效时间15分钟,有效期内任意一个验证码都是可以使用的只要验证通过,使用
CompletableFuture开启异步任务使用自定义线程池远程调用第三方服务发起发送短信请求验证码通过随机UUID截取前6位生成
发送短信第三方接口不需要做返回值处理,如果中间有异常用户没有收到验证码会60s之后自己再尝试发送验证码
将验证码存入
redis中并设置有效时间等待进行验证码的校验防止同一个手机号在60s内再次发送验证码,老师是保存发送验证码的时间戳来进行判断,我觉得不优雅,我考虑使用
setnx指令或者获取有效时间的指令来判断是否能再次发送,而且老师没有考虑一个手机号存储多个验证码以及再次发送验证码过期时间重置的问题
xxxxxxxxxx("registryService")public class RegistryServiceImpl implements RegistryService {StringRedisTemplate redisTemplate;ThirdPartyFeignClient thirdPartyFeignClient;ThreadPoolExecutor threadPoolExecutor;/*** @param phoneNum* @return {@link String }* @描述 生成短信验证码,发送短信验证码,给Redis中存一份,检查发送间隔是否大于预设时间* @author Earl* @version 1.0.0* @创建日期 2024/10/01* @since 1.0.0*/public String checkAndSendSmsCode(String phoneNum) throws RRException {//1. 生成短信验证码String code = UUID.randomUUID().toString().substring(0, 6);//2. 缓存验证码CompletableFuture<Long> restIntervalFuture = CompletableFuture.supplyAsync(() -> cacheSmsCode(phoneNum, code));Long restInterval = null;try {restInterval = restIntervalFuture.get();} catch (Exception e) {e.printStackTrace();}if(restInterval != -2L){throw new RRException("请"+restInterval+"秒后重试!",StatusCode.SMS_SEND_INTERVAL_EXCEPTION.getCode());}//3. 远程调用第三方服务给用户发送短信验证码CompletableFuture.runAsync(()->{thirdPartyFeignClient.sendCode(phoneNum,code,CaptchaConstant.CAPTCHA_EFFECTIVE_TIME/60);},threadPoolExecutor);return "验证码发送成功!";}/*** @param phoneNum* @param code* @return {@link Long }* @描述 缓存短信验证码,如果缓存成功则返回-2,如果还没有到达验证码发送间隔时间60s就返回剩余有效毫秒数* @author Earl* @version 1.0.0* @创建日期 2024/10/01* @since 1.0.0*/private Long cacheSmsCode(String phoneNum,String code){//获取系统当前时间String curTime = String.valueOf(System.currentTimeMillis());String script = "local interval_time = tonumber(ARGV[3])"+"local effective_time = tonumber(ARGV[4])"+"local rest_interval = redis.call('ttl', KEYS[1])" +"if rest_interval == -2 " +"then " +" redis.call('set', KEYS[1], ARGV[1], 'EX', interval_time) " +" redis.call('set', KEYS[2], ARGV[2], 'EX', effective_time) " +" return -2 "+"else " +" return rest_interval " +"end";;return redisTemplate.execute(new DefaultRedisScript<>(script, Long.class),Arrays.asList(phoneNum+"_restInterval", phoneNum+"_"+code),curTime, curTime,CaptchaConstant.CAPTCHA_SEND_INTERVAL.toString(),CaptchaConstant.CAPTCHA_EFFECTIVE_TIME.toString());}}
将短信服务抽取成一个组件注入容器中,以后需要使用直接自动注入,将可选项请求地址、模板编号、签名编号、appcode都做成可配置的属性[直接使用
@ConfigurationProperties注解指定属性值的配置前缀],传参验证码和手机号来发送短信验证码请求[短信发送组件]
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 国阳云短信发送操作客户端,国阳云官网:https://www.guoyangyun.com/webx/sms/default/index.html* HttpUtils请从* https://github.com/aliyun/api-gateway-demo-sign-java/blob/master/src/main/java/com/aliyun/api/gateway/demo/util/HttpUtils.java* 相应的依赖请参照* https://github.com/aliyun/api-gateway-demo-sign-java/blob/master/pom.xml* response的body通过* System.out.println(EntityUtils.toString(response.getEntity()));获取* smsSignId(短信前缀)和templateId(短信模板),可登录国阳云控制台自助申请。参考文档:* http://help.guoyangyun.com/Problem/Qm.html* @创建日期 2024/10/02* @since 1.0.0*/public class GYYSmsSendClient {private String smsSignId ;private String templateId ;private String host ;private String path ;private String appcode ;private String method ;/*** @param phoneNum* @param code* @param effectiveTime* @return {@link HttpResponse }* @描述 给目标手机号发送短信验证码* @author Earl* @version 1.0.0* @创建日期 2024/10/02* @since 1.0.0*/public HttpResponse sendCode(String phoneNum,String code,Integer effectiveTime) throws Exception {Map<String, String> headers = new HashMap<String, String>();//最后在header中的格式(中间是英文空格)为Authorization:APPCODE 83359fd73fe94948385f570e3c139105headers.put("Authorization", "APPCODE " + appcode);Map<String, String> querys = new HashMap<String, String>();querys.put("mobile", phoneNum);querys.put("param", "**code**:"+code+",**minute**:"+effectiveTime);querys.put("smsSignId", smsSignId);querys.put("templateId", templateId);Map<String, String> bodys = new HashMap<String, String>();return HttpUtils.doPost(host, path, method, headers, querys, bodys);}}[短信发送组件配置类]
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 国阳云短信接口配置参数* @创建日期 2024/10/02* @since 1.0.0*/("gyy.sms")public class GYYSmsProperties {private String smsSignId = "默认配置";private String templateId = "默认配置";private String host = "https://gyytz.market.alicloudapi.com";private String path = "/sms/smsSend";private String appcode = "默认配置";private String method = "POST";}[组件注入]
xxxxxxxxxxpublic class SmsClientConfig {public GYYSmsSendClient gyySmsSendClient(GYYSmsProperties properties){return new GYYSmsSendClient(properties.getSmsSignId(),properties.getTemplateId(),properties.getHost(),properties.getPath(),properties.getAppcode(),properties.getMethod());}}[发送短信的代码调用]
xxxxxxxxxx("smsServiceImpl")public class SmsServiceImpl implements SmsService {private GYYSmsSendClient smsSendClient;/*** @param phoneNum 手机号* @param code 短信验证码* @param effectiveTime 验证码有效时间,单位min* @描述 调用第三方短信接口发送短信验证码* @author Earl* @version 1.0.0* @创建日期 2024/10/02* @since 1.0.0*/public void sendCode(String phoneNum, String code,Integer effectiveTime) {try {smsSendClient.sendCode(phoneNum,code,effectiveTime);} catch (Exception e) {e.printStackTrace();}}}
阿里云短信验证码服务
这一块比较随意,自己根据阿里云上不同短信服务提供商的文档搭建即可,大致都是这些流程
阿里云云市场提供了很多比如短信发送、物流查询、实名认证查询等等接口,这些接口需要付费使用,阿里云的发送短信验证码服务都是外包的,有很多商家,可以选择合适的自己进行使用,根据产品文档介绍自己抽取组价使用就行了,主要三个方面,一个是抽取组件注入容器按需使用,第二是凡是需要自己配置的参数全部抽取到配置文件进行配置方便管理和修改,第三是短信发送业务使用服务器来进行请求防止暴露身份验证信息导致出现安全问题
短信接口阿里云有0元五次的短信接口,正常情况下一条短信大概五分钱一次,测试可以使用该免费服务,购买成功可以在管理控制台看到对应的商品信息,购买界面下方有接口使用方法介绍,选择短信验证码接口
这里使用的接口调用地址【GET】
http,通过APPCODE的方式进行调用者的身份权限验证APPCODE在我们管理控制台购买的服务中可以看到对应的AppCode,发起请求时需要携带该AppCode在请求中
AppCode会在请求头信息中的Authorization字段中指定,格式为APPCODE+半角空格+APPCODE值,不添加该请求头信息请求会报错401这种方式意味着直接通过用户客户端发起短信请求不安全,因为用户可以获取到我们的
APPCODE,高频发起请求对我们的短信服务造成金钱攻击,一般的做法是用户向我们的服务器发起请求,我们生成一个随机验证码并通过服务器向短信接口发起请求向用户手机发起指定验证码
请求时需要在请求参数中携带以下四个String类型的参数
GET请求请求参数直接拼接在请求路径后面
名称 描述 是否必须 code 要发送的验证码 必选 phone 接收人的手机号 必选 sign 签名编号
签名是短信抬头括号中的内容,一般用来标记短信的发送者
签名如果默认的编号1对应的签名为消息秘书
这个自定义签名需要添加客服来申请编号和自定义签名的对应关系才能使用自定义签名可选 skin 短信模板编号
短信模板是短信服务提供商提供的一系列短信模板
可以通过skin顺序整数编号来指定用户希望使用的模板可选 短信接口的Java代码示例购买界面的文档中也有
可能需要一些短信服务商的工具类比如
HttpUtils来处理请求参数需要到指定地址下载并拷贝到自己的项目中需要引入的依赖文档中也有
用户注册业务
前端业务逻辑
前端注册表单,
action属性指定提交地址的URI,输入框需要指定和后端接收参数相同的参数名[不提交的表单参数可以不写input标签name属性],请求方式设置为post方式注意如果属性值是常量字符串,比如
action="/registry",此时使用Thymeleaf来处理该属性可能会报错,比如th:action="/registry"此时后端就会报错Thymeleaf渲染出错
注意把原来的前端页面表单提交按钮的单机事件的JS代码注释掉,使用表单的默认行为来提交表单
通过
Thymeleaf来从error这个Map中获取错误校验信息,在没有发生校验错误的情况下error会为null,此时仍然从error中获取错误校验信息就会出现空指针异常,只有在error不为null的情况下才去执行从error中获取对应参数的错误校验信息注意即使
Map类型的error不为null,但是Map中没有指定的属性如username,此时仍然使用error.get("username"),Thymeleaf仍然会报错,即Map不包含指定key的数据但是仍然进行取值Thymeleaf会直接报错,我们还需要通过Thymeleaf对Map处理的API#maps.containsKey(map,key)来判断Map类型的error中是否包含key为username的数据,包含才进行取值,不包含就不取值弹幕说活简单写成这样
th:text="${errors?.get('code')}"就可以了,一会儿试一下
xxxxxxxxxx<form action="/registry/user" method="post" class="one" th:attr="error=${error}"><div class="register-box"><label class="username_label">用 户 名<input name="username" maxlength="20" type="text" placeholder="您的用户名和登录名"th:value="${user!=null?user.username:''}"></label><div class="tips"style="color: red"th:text="${validErrors!=null?(#maps.containsKey(validErrors,'username')?validErrors.username:''):''}"></div></div><div class="register-box"><label class="other_label">设 置 密 码<input name="password" maxlength="20" type="password" placeholder="建议至少使用两种字符组合"th:value="${user!=null?user.password:''}"></label><div class="tips"style="color: red"th:text="${validErrors!=null?(#maps.containsKey(validErrors,'password')?validErrors.password:''):''}"></div></div><div class="register-box"><label class="other_label">确 认 密 码<input maxlength="20" type="password" placeholder="请再次输入密码"></label><div class="tips"></div></div><div class="register-box"><label class="other_label"><span>中国 0086∨</span><input name="phoneNum"class="phone"maxlength="20"type="text"placeholder="建议使用常用手机"th:value="${user!=null?user.phoneNum:''}"></label><div class="tips"style="color: red"th:text="${validErrors!=null?(#maps.containsKey(validErrors,'phoneNum')?validErrors.phoneNum:''):''}"></div></div><div class="register-box"><label class="other_label">验 证 码<input name="code" maxlength="20" type="text" placeholder="请输入验证码" class="caa"th:value="${user!=null?user.code:''}"></label><a class="smsCode">获取验证码</a><div class="tips"style="color: red"th:text="${validErrors!=null?(#maps.containsKey(validErrors,'code')?validErrors.code:''):''}"></div></div><div class="arguement"><input type="checkbox" id="xieyi"> 阅读并同意<a href="#">《谷粒商城用户注册协议》</a><a href="#">《隐私政策》</a><div class="tips"></div><br/><div class="submit_btn"><button type="submit" id="submit_btn">立 即 注 册</button></div></div></form>后端业务逻辑
注册成功后默认重定向到登录页
重定向的写法为
return "redirect:/login.html",此前做了视图映射/login.html对应login视图,重定向的问题在于ModelAndView中的共享数据在请求域中,无法通过重定向传递给指定视图;重定向想要向视图共享数据可以使用SpringMVC提供的RedirectAttributes对象,RedirectAttributes对象通过方法redirectAttributes.addFlashAttribute("errors",errors)来将数据携带传递到重定向视图,防止表单重复提交最好的办法就是重定向视图清空表单数据重定向防表单提交的原理是重定向刷新表单内容,再次提交过不了前端数据校验,一般表单内容前端都会校验,通过前端校验但是服务器校验过不去,不是蓄意攻击就是有意为之,清空数据不过分,成功以后重定向到登录页面也不会出现表单重复提交的现象,也比较合理
重定向只能重定向到一个URI或者URL地址,不能直接重定向到一个视图
注意
return "redirect:/login.html重定向的路径是http:192.168.137.1:20000/login.html,即以当前服务所在端口作为URL的前缀,如果我们想要指定前缀需要使用如下写法return "redirect:http://auth.earlmall.com/login.html",这样在访问静态资源的时候会走nginx,不然静态资源无法从nginx中获取,这种重定向写法也能将RedirectAttributes对象中的数据携带过去,只要地址是我们自己的服务器地址,RedirectAttributes对象能重定向携带数据的原理是重定向时会在cookie中携带一个JSESSIONID,重定向在页面间共享数据可以给session中放数据,我们以前通过HttpSession向session中存放数据来实现跨页面共享数据,RedirectAttributes就是通过这种方式来实现的重定向携带数据,对应的重定向请求的cookie中也携带了session的唯一标识JSESSIONID,该数据共享是通过session的原理来实现共享的,重定向请求的cookie中也有对应的JSESSIONID,重定向到页面中也会从session中取出对应的数据,该数据只要取出来就会被删掉,这种数据组织方式也能实现再次刷新页面页面中对应的校验错误提示就会消失的效果但是注意在分布式系统下使用session一定会遇到分布式下的session问题,这个问题后面专门讲
return "reg"会拼接视图地址前后缀直接找到视图,return "forward:/reg.html"控制器方法中所设置的视图名称以forward:为前缀时,创建InternalResourceView视图,此时的视图名称不会被SpringMVC配置文件中所配置的视图解析器解析,而是会将前缀forward:去掉,剩余部分作为最终路径通过转发的方式实现跳转,相当于通过路径去控制器方法获取视图映射控制器去匹配路径转发到对应的视图,相比于return "reg"效果相同只是饶了一圈注意使用这种方式可能会出现
Request method 'POST' not supported的问题,这种问题通常发生在前端使用POST的方式提交表单,后端也使用POST方式来处理提交请求,但是后端处理完请求以后通过return "forward:/reg.html转发[原来的请求原封不动转给下一个请求路径接口,如果请求是POST请求,但是被转发的接口只接受GET请求,此时就会报这个错误]的方式来跳转页面,一般路径对视图的映射在控制器方法都会设置为Get方法,通过视图映射器来设置的路径视图映射也默认使用GET方式访问的,POST请求被转发到GET请求方式的路径映射接口就会出现该错误,解决办法是不使用路径映射,直接使用return "reg"直接拼接前后缀找到对应的视图注意转发后页面的静态资源会以完整的URL进行拼串,不会只以网段+端口进行拼串
定义VO类
UserRegistryVo接收用户注册传递参数,需要传参String类型的userName、passWord、phoneNum和验证码,校验密码直接前端校验即可,后端不需要接收,使用JSR303的数据校验注解来进行数据校验,如果校验出错将错误校验信息封装到ModelAndView中,直接转发到注册页校验规则
用户名不为空,长度必须在4-20之间
密码不能为空,长度必须在6-20之间
手机号不能为空,且必须满足手机号的格式要求
验证码不能为空,且必须和验证码的格式要求相同
用户名和手机号码必须唯一是要结合数据库来和已有数据进行比对的,因此需要在业务方法中进行校验
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 用户VO类,封装用户注册数据* @创建日期 2024/10/03* @since 1.0.0*/public class UserRegistryVo {/*** 用户名*/(message = "用户名必须是1-20位字符")(min = 1,max = 20,message = "用户名必须是1-20位字符")private String username;/*** 用户密码*/(message = "密码必须是6-18位字符")(min = 6,max = 18,message = "密码必须是6-18位字符")private String password;/*** 手机号码*/(message = "必须填写手机号码")(regexp = "^1[3-9]\\d{9}$",message = "手机号码格式错误")private String phoneNum;/*** 用户注册手机验证码*/(message = "必须填写验证码")(min = 6,max = 6,message = "验证码必须是6位字符")private String code;}封装错误校验信息
校验信息都保存在
BindingResult中,通过该对象的API能够获取发生校验错误的字段和对应的校验错误信息,一般做法是封装成Map添加到直接返回或者封装到ModelAndView中使用模板引擎渲染弹幕说会有重复key的问题,同一个属性上使用俩个验证的话,任何一项不满足,
BindingResult中会封装两个fieldError对象,但是这两个对象的field属性是相同的,但是defaultMessage属性分别是两个校验注解校验错误的对应提示信息,封装到Map中就会出现一个重复key不同value的情况[锤子,HashMap的put方法遇到重复key都是直接覆盖旧Value并返回旧值]后端校验失败直接通过重定向将页面重定向到注册页,这样能清空表单数据防止用户重复提交,通过
SpringMVC提供的RedirectAttributes对象来携带校验错误信息,该数据共享是通过session的原理来实现共享的,重定向请求的cookie中也有对应的JSESSIONID,重定向到页面中也会从session中取出对应的数据,该数据只要取出来就会被删掉,这种数据组织方式也能实现再次刷新页面页面中对应的校验错误提示就会消失的效果xxxxxxxxxx/*** @return {@link R }* @描述 用户注册接口* @author Earl* @version 1.0.0* @创建日期 2024/10/03* @since 1.0.0*/("/user")public String userRegistry( UserRegistryVo user,BindingResult bindingResult,RedirectAttributes attributes){//1. 如果参数校验没通过,直接渲染到注册页并回显存入session的校验错误,// 使用redirectAttributes.addFlashAttribute存入session中的数据被取出一次后会自动删除//1.1 这里不能使用转发或者重定向根据路径去匹配视图,因为这样会去控制器方法匹配请求路径,但是一般路径视图映射都默认// 处理的是get请求,重定向或者转发会将该POST请求原封不动的转给下一个请求路径接口,如果接口只接受GET请求,就会报错// `Request method 'POST' not supported`HashMap<String, String> validErrors = new HashMap<>();if(bindingResult.hasErrors()){bindingResult.getFieldErrors().forEach(fieldError -> {validErrors.put(fieldError.getField(),fieldError.getDefaultMessage());});attributes.addFlashAttribute("user",user);attributes.addFlashAttribute("validErrors",validErrors);//TODO:http->httpsreturn "redirect:http://auth.earlmall.com/registry.html";}//2. 通过校验执行业务方法对用户进行注册String message;try{message=registryService.userRegistry(user);}catch (RRException e){if(e.getCode()== StatusCode.USERNAME_REPEATED_EXCEPTION.getCode()){validErrors.put("username",e.getMsg());}else if(e.getCode()== StatusCode.MOBILE_REPEATED_EXCEPTION.getCode()){validErrors.put("phoneNum",e.getMsg());}else if(e.getCode()==StatusCode.UNKNOWN_EXCEPTION.getCode()){attributes.addFlashAttribute("error",e.getMsg());} else{validErrors.put("code",e.getMsg());}attributes.addFlashAttribute("user",user);attributes.addFlashAttribute("validErrors",validErrors);//TODO:http->httpsreturn "redirect:http://auth.earlmall.com/registry.html";}attributes.addFlashAttribute("tips",message);//TODO:http->httpsreturn "redirect:http://auth.earlmall.com/login.html";}
注册业务逻辑
设置默认会员等级id,表
ums_member_level默认会员等级的default_status被设置为1,根据这个条件将默认等级查出来并给对应用户字段赋值保存用户的用户名、手机号;用户名和手机号必须要唯一,不唯一通过抛出运行时异常来进行提示,给用户一个默认的昵称
检验方法是通过
SELECT COUNT(*) WHERE USERNAME = 'xxx'只要计数不等于0就说明对应的值已经有了,就不满足唯一性要求,就直接抛运行时异常,直接使用count(*),mysql内部做了优化,查询效率最高我这里直接一次性将所有姓名和电话号码的记录全部查出来再检查名字或者电话号码哪个重复,这样减少和数据库的连接开销
存储密码不能明文存储,只能存储密文,
facebook就因为明文存储密码被罚款弹幕说数据安全级别高的需要使用ASE+RSA来加密,该项目使用MD5&MD5盐值加密
MD5[Message Digest algorithm 5],不可逆加密中常用的是MD5加密算法,严格意义上MD5不属于加密算法,也称信息摘要算法,该算法的特点是对任意长度文本,可以根据文本的特征值得到一个固定长度的MD5值,而且该文本只要有一个字节发生变化,这个MD5值就会发生变化,MD5是消息摘要,会损失原数据,不能通过MD5值推断出完整的原数据
MD5算法的优点
压缩性:任意长度的文本数据,算出的MD5值长度都是固定的,只是比较内容是否相同无需保存文本内容
这个特点的应用场景比如百度网盘秒传功能,在上传以前先计算文件的MD5值,因为MD5的强抗碰撞特性,几乎只有内容完全相同的文件才会有一样的MD5值,几乎不可能出现两个MD5值相同的文件文件内容不同的情况,如果待上传文件计算出来的MD5值已经和服务器中的资源相同,就说明服务器中已经有了对应的资源,此时就无需上传,直接把资源引用到对应账户即可
易计算:从原数据算出MD5值很容易
抗修改性:对原数据哪怕一个字节的修改都会得到区别很大的MD5值
强抗碰撞:很难找到两个不同的数据使得两者的MD5值相同
不可逆:不能从MD5值推算出原数据,
注意因为一段数据通过MD5加密得到的MD5值是固定的,因此单纯使用MD5也是不安全的,网上有一个彩虹表的MD5值和原文的对照表,彩虹表就是用MD5天天计算各种文本的MD5值并存入数据库,查询的时候直接通过MD5值就能查到明文,因此MD5不能直接用来对数据进行加密,还是容易通过MD5值查到对应的明文,需要进行盐值加密
盐值加密
盐值加密就是给原文拼接一段字符串,然后整体做MD5加密
Common-lang包有DigestUtils.md5Crypt(Bytes bytes,String salt)可以做盐值加密,但是不使用随机盐值不安全,使用随机盐值数据库还需要保存用户加密时使用的盐值,不方便Spring提供了一个工具类
BCryptPasswordEncoder,可以不指定盐值不记录盐值就能自动使用随机盐进行加密解密,实现原理是能够自动根据加密后的密文推算出加密时使用的盐值,然后通过验证时用户输入的密码拼接该盐值就能计算出一个MD5值,通过比较该MD5值和对应数据库保存的MD5值[这个不是单纯的MD5值,因为得到的值的长度不符合MD5值的结构,估计是spring家对加了盐算得的MD5值还进行了自己的加密算法对盐值进行了加密]因为盐值是随机的,即使两个完全一样的明文,也会因为盐值不同每次都得到完全不同的密文
通过
bCryptPasswordEncoder.encode(String password)来给明文密码加密,通过bCryptPasswordEncoder.match(String password,String encodePassword)来将用户输入的明文和密文进行匹配
[注册服务Service方法]
通过抛出
RRException异常的方式并通过异常状态码来匹配对应的用户名重复、电话号码重复、验证码错误、和未知异常等情况验证码校验成功后通过异步任务不等待删除
redis中的验证码远程调用mall-user服务来实现用户注册任务
xxxxxxxxxx/*** @param user* @return {@link String }* @描述 使用用户提交的注册信息来为用户注册账号* @author Earl* @version 1.0.0* @创建日期 2024/10/03* @since 1.0.0*/public String userRegistry(UserRegistryVo user) throws RRException{//1. 验证验证码是否正确String key = user.getPhoneNum() + "_" + user.getCode().toLowerCase();String codeCreateTime = redisTemplate.opsForValue().get(key);if(StringUtils.isEmpty(codeCreateTime)){throw new RRException(StatusCode.CODE_WRONG_EXCEPTION.getMsg(),StatusCode.CODE_WRONG_EXCEPTION.getCode());}CompletableFuture.runAsync(()->redisTemplate.delete(key));//2. 调用远程服务mall-user来执行用户注册服务R res = userFeignClient.registry(user);if(res!=null){if(res.getCode()==StatusCode.USERNAME_REPEATED_EXCEPTION.getCode()){throw new RRException(StatusCode.USERNAME_REPEATED_EXCEPTION.getMsg(),StatusCode.USERNAME_REPEATED_EXCEPTION.getCode());}else if(res.getCode()==StatusCode.MOBILE_REPEATED_EXCEPTION.getCode()){throw new RRException(StatusCode.MOBILE_REPEATED_EXCEPTION.getMsg(),StatusCode.MOBILE_REPEATED_EXCEPTION.getCode());}else {return res.getData(new TypeReference<String>(){});}}throw new RRException(StatusCode.UNKNOWN_EXCEPTION.getMsg(),StatusCode.UNKNOWN_EXCEPTION.getCode());}[mall-user的注册接口]
xxxxxxxxxx/*** @param user* @return {@link R }* @描述 用户注册接口,验证用户名和手机号的唯一性* @author Earl* @version 1.0.0* @创建日期 2024/10/03* @since 1.0.0*/("/registry")public R registry( UserRegistryTo user){String message = null;try {message=memberService.registry(user);}catch (RRException e){return R.error(e.getCode(),e.getMsg());}return R.ok().setData(message);}[mall-user的注册服务]
用异步任务加速获取默认用户等级的数据库查询
xxxxxxxxxx/*** @param user* @return {@link String }* @描述 根据用户注册输入信息创建用户账号* @author Earl* @version 1.0.0* @创建日期 2024/10/03* @since 1.0.0*/public String registry(UserRegistryTo user) throws RRException {CompletableFuture<MemberLevelEntity> defaultUserLevelFuture = CompletableFuture.supplyAsync(() ->memberLevelService.getOne(new QueryWrapper<MemberLevelEntity>().eq("default_status", UserConstant.UserDefaultLevelStatus.DEFAULT_STATUS.getCode())));//1. 验证用户名和手机号是否唯一,不唯一直接抛异常并提示用户名或者手机号重复List<MemberEntity> existedUsers = list(new QueryWrapper<MemberEntity>().eq("username", user.getUsername()).or().eq("mobile", user.getPhoneNum()));if(existedUsers!=null){for (MemberEntity existedUser : existedUsers) {if(user.getUsername().equals(existedUser.getUsername())){throw new RRException(StatusCode.USERNAME_REPEATED_EXCEPTION.getMsg(),StatusCode.USERNAME_REPEATED_EXCEPTION.getCode());}else{throw new RRException(StatusCode.MOBILE_REPEATED_EXCEPTION.getMsg(),StatusCode.MOBILE_REPEATED_EXCEPTION.getCode());}}}//2. 手机号和用户名唯一则执行注册业务MemberEntity member = new MemberEntity();member.setUsername(user.getUsername());member.setMobile(user.getPhoneNum());member.setPassword(new BCryptPasswordEncoder().encode(user.getPassword()));try {MemberLevelEntity defaultUserLevel = defaultUserLevelFuture.get();member.setLevelId(defaultUserLevel.getId());member.setIntegration(0);//md5对用户密码进行随机盐加密member.setGrowth(defaultUserLevel.getCommentGrowthPoint());} catch (InterruptedException e) {e.printStackTrace();} catch (ExecutionException e) {e.printStackTrace();}member.setStatus(1);save(member);return "注册成功!";}
用户登录
账号密码或者手机号密码登录
社交登录和单点登录
账号/手机+密码登录
前端业务逻辑
登录页面表单提交用户名或者手机号和密码,以
Post方式用默认行为提交,登录失败提示用户名或者账户密码错误,后端入参校验出问题也进行提示xxxxxxxxxx<div class="si_bom1 tab" style="display: none;" th:with="loginInfo=${loginInfo},validErrors=${validErrors},errors=${errors}"><div class="error"><div>请输入账户名和密码</div></div><div class="error" th:if="${errors!=null?#maps.containsKey(errors,'error'):false}"><div th:text="${errors.error}"></div></div><form action="/login/default" method="post"><ul><li class="top_1"><img src="static/login/JD_img/user_03.png" class="err_img1"/><input type="text" name="username" placeholder=" 邮箱/用户名/已验证手机" class="user"th:value="${loginInfo!=null?loginInfo.username:''}"/><div class="tips"style="color: red"th:text="${validErrors!=null?(#maps.containsKey(validErrors,'username')?validErrors.username:''):''}"></div><div class="tips"style="color: red"th:text="${errors!=null?(#maps.containsKey(errors,'username')?errors.username:''):''}"></div></li><li><img src="static/login/JD_img/user_06.png" class="err_img2"th:value="${loginInfo!=null?loginInfo.password:''}"/><input type="password" name="password" placeholder=" 密码" class="password"/><div class="tips"style="color: red"th:text="${validErrors!=null?(#maps.containsKey(validErrors,'password')?validErrors.password:''):''}"></div><div class="tips"style="color: red"th:text="${errors!=null?(#maps.containsKey(errors,'password')?errors.password:''):''}"></div></li><li class="bri"><a href="">忘记密码</a></li><li class="ent"><button class="btn2"><a class="a">登 录</a></button></li></ul></form></div>
后端业务逻辑
获取用户提交的用户名或者手机号查出对应的记录,使用用户输入的密码和查出记录的密码使用``进行比对匹配,查不到记录就响应用户输入的账号不存在,密码不匹配就输出用户的密码错误,用异常的方式来抛出错误信息
这里之前的注册服务存在问题,因为这里使用的是手机号码或者用户名来作为用户登录的账号凭证,有可能出现一个用户使用另一个用户的手机号做用户名,在这种情况下,用户登录时根据输入内容同时匹配手机号或者用户名等于账户入参的记录就可能查出多条,此时如果两个用户的密码还相同就会发生多个账号同时登录的情况
解决办法是在用户注册时就限制用户名不能为纯数字,前端校验同时后端也做对应的校验,后端校验使用
JSR303完成,可以使用正则表达式的@Pattern注解,也可以使用自定义注解,自定义注解应该越少越好,像此前解决入参只能是可选值的数据校验注解@ListValue[应用场景比如限制商品的展示状态入参只能有两个可选值,0表示隐藏商品,1表示展示商品],或者正则注解不能使用的场景[比如@Pattern注解不能标注在Integer类型的字段上],此时才考虑使用自定义注解,降低项目的复杂度,这里已经实现了自定义注解,因此就列出自定义注解的方式来限制用户注册时用户名不能为纯数字自定义校验注解
[自定义注解
@NotPureNumber]xxxxxxxxxxpackage com.earl.common.validate.annotation;import com.earl.common.validate.validator.NotPureNumberConstraintValidator;import javax.validation.Constraint;import javax.validation.Payload;import java.lang.annotation.*;/*** @author Earl* @version 1.0.0* @描述 非纯数字JSR303校验注解* @创建日期 2024/10/17* @since 1.0.0*/(validatedBy = {NotPureNumberConstraintValidator.class})({ElementType.METHOD, ElementType.FIELD, ElementType.ANNOTATION_TYPE, ElementType.CONSTRUCTOR, ElementType.PARAMETER, ElementType.TYPE_USE})(RetentionPolicy.RUNTIME)public @interface NotPureNumber {String message() default "{com.earl.common.validate.annotation.NotPureNumber.message}";Class<?>[] groups() default {};Class<? extends Payload>[] payload() default {};// 定义正则表达式,匹配非纯数字的字符串String regexp() default "^[^\\d]+$";}[自定义非纯数字校验注解校验器]
xxxxxxxxxxpackage com.earl.common.validate.validator;import com.earl.common.validate.annotation.NotPureNumber;import javax.validation.ConstraintValidator;import javax.validation.ConstraintValidatorContext;/*** @author Earl* @version 1.0.0* @描述 非纯数字校验器,注解@NotPureNumber只能标注在String类型的字段上* @创建日期 2024/10/17* @since 1.0.0*/public class NotPureNumberConstraintValidator implements ConstraintValidator<NotPureNumber, String> {private NotPureNumber constraintAnnotation;public void initialize(NotPureNumber constraintAnnotation) {this.constraintAnnotation=constraintAnnotation;}public boolean isValid(String value, ConstraintValidatorContext context) {if (value == null) {return true;}return value.matches(constraintAnnotation.regexp());}}[自定义校验注解的使用]
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 用户VO类,封装用户注册数据* @创建日期 2024/10/03* @since 1.0.0*/public class UserRegistryVo {/*** 用户名*/(message = "用户名必须是1-20位字符")(min = 1,max = 20,message = "用户名必须是1-20位字符")private String username;/*** 用户密码*/(message = "密码必须是6-18位字符")(min = 6,max = 18,message = "密码必须是6-18位字符")private String password;/*** 手机号码*/(message = "必须填写手机号码")(regexp = "^1[3-9]\\d{9}$",message = "手机号码格式错误")private String phoneNum;/*** 用户注册手机验证码*/(message = "必须填写验证码")(min = 6,max = 6,message = "验证码必须是6位字符")private String code;}
限制了用户名不可能为纯数字就能避免掉数据库中一个用户的用户名是另一个用户手机号的情况,此时使用用户的账户入参匹配手机号或者用户名就永远只能查出一条记录
通过用户提交的账户名入参远程调用用户服务查询账户名或者手机号码匹配的对应记录并响应给
auth服务如果用户记录不存在通过抛异常的方式结束并封装异常信息该账户不存在
如果用户记录存在则封装用户数据并返回给
auth服务代码示例
[控制器方法]
xxxxxxxxxx/*** @param usernameOrMobile* @return {@link R }* @描述 根据用户手机号或者账户密码检查用户是否存在并返回用户实体类* @author Earl* @version 1.0.0* @创建日期 2024/10/17* @since 1.0.0*/("/login")public R getByUsernameOrMobile( String usernameOrMobile){MemberEntity user = null;try {user = memberService.getByUsernameOrMobile(usernameOrMobile);}catch (RRException e){return R.error(e.getCode(),e.getMsg());}return R.ok().put("user",user);}[实现方法]
xxxxxxxxxx/*** @param usernameOrMobile* @return {@link MemberEntity }* @描述 通过用户名或者手机号来获取用户实体类* @author Earl* @version 1.0.0* @创建日期 2024/10/17* @since 1.0.0*/public MemberEntity getByUsernameOrMobile(String usernameOrMobile) throws RRException{MemberEntity user = getOne(new QueryWrapper<MemberEntity>().eq("username", usernameOrMobile).or().eq("mobile", usernameOrMobile));if(user!=null){return user;}throw new RRException(StatusCode.USER_ABSENT_EXCEPTION.getMsg(),StatusCode.USER_ABSENT_EXCEPTION.getCode());}
如果用户不存在直接抛异常并封装异常信息,如果用户存在验证用户输入的密码和存储的密文是否匹配,如果匹配封装用户基本信息并返回,如果匹配失败直接抛异常并封装用户密码错误的异常信息
[账号密码登录控制器方法]
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 本平台原生登录方式登录* @创建日期 2024/10/17* @since 1.0.0*/("/login")public class LoginController {private LoginService loginService;("/default")public String loginDefault( UserLoginVo user,BindingResult bindingResult,RedirectAttributes attributes){if(bindingResult.hasErrors()){HashMap<String, String> validErrors = new HashMap<>();bindingResult.getFieldErrors().forEach(fieldError -> {validErrors.put(fieldError.getField(),fieldError.getDefaultMessage());});attributes.addFlashAttribute("loginInfo",user);attributes.addFlashAttribute("validErrors",validErrors);//TODO:http->httpsreturn "redirect:http://auth.earlmall.com/login.html";}try{UserBaseInfoVo userInfo = loginService.loginDefault(user);//注意,这个session只要跳转了域名或者跳转了服务,原生默认session中的数据就取不出了attributes.addFlashAttribute("userInfo",userInfo);return "redirect:http://earlmall.com";}catch (RRException e){HashMap<String, String> errors = new HashMap<>();if(e.getCode()== StatusCode.USER_ABSENT_EXCEPTION.getCode()){errors.put("username",e.getMsg());}else if(e.getCode()==StatusCode.PASSWORD_WRONG_EXCEPTION.getCode()){errors.put("password",e.getMsg());}else {errors.put("error",e.getMsg());}attributes.addFlashAttribute("loginInfo",user);attributes.addFlashAttribute("errors",errors);return "redirect:http://auth.earlmall.com/login.html";}}}[封装登录账号密码入参和参数校验]
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 用户登录数据封装* @创建日期 2024/10/17* @since 1.0.0*/public class UserLoginVo {(message = "用户名必须是1-20位字符")(min = 1,max = 20,message = "用户名必须是1-20位字符")private String username;(message = "密码必须是6-18位字符")(min = 6,max = 18,message = "密码必须是6-18位字符")private String password;}[
auth服务执行登录操作的业务实现]xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 用户登录服务实现类* @创建日期 2024/10/17* @since 1.0.0*/("loginService")public class LoginServiceImpl implements LoginService {private UserFeignClient userFeignClient;/*** @param user* @return {@link UserBaseInfoVo }* @描述 商城自身的默认账号密码登录* @author Earl* @version 1.0.0* @创建日期 2024/10/17* @since 1.0.0*/public UserBaseInfoVo loginDefault(UserLoginVo user) throws RRException{//1. 根据用户输入的账户信息远程调用用户服务查询出用户记录R res = userFeignClient.getByUsernameOrMobile(user.getUsername());//如果查询不到记录就直接抛出异常,在控制器中去将异常信息封装到视图层中if(res.getCode() != 0){throw new RRException(StatusCode.USER_ABSENT_EXCEPTION.getMsg(),StatusCode.USER_ABSENT_EXCEPTION.getCode());}//如果查询到记录直接获取用户记录UserTo userEntity = res.get("user", new TypeReference<UserTo>() {});//2. 检查用户密码//如果用户输入的密码与密文匹配就封装用户数据准备返回,否则抛异常用户输入的密码错误if (new BCryptPasswordEncoder().matches(user.getPassword(),userEntity.getPassword())) {UserBaseInfoVo userInfo = new UserBaseInfoVo();BeanUtils.copyProperties(userEntity,userInfo);return userInfo;}throw new RRException(StatusCode.PASSWORD_WRONG_EXCEPTION.getMsg(),StatusCode.PASSWORD_WRONG_EXCEPTION.getCode());}}
社交登录
一些社交网站比如QQ、微信、微博、GitHub拥有大量的用户,用户可能很多时候认为我们我们的注册登录流程太麻烦,希望使用社交账号直接扫码一键注册登录
社交登录的跳转逻辑流程
点击第三方社交账号登录会跳转到社交平台提供的用户信息授权页,用户通过输入第三方社交账号的账号密码或者扫码登录来授权第三方社交账号提供用户信息给正在注册账号的平台来创建账号并跳转回到注册账号平台的目的地址
这个流程遵循的就是开放授权标准OAuth2.0,原来的OAuth1.0已经不用了
一般注册平台会从社交账号获取用户的开放API[猜测是用户社交账号部分可以被公开搜索的信息]头像、用户昵称
OAuth2.0流程
基本流程图
这个图有误解的成分,网上的图全是这样的,这里用户授权时登录第三方社交平台是直接将请求发送到第三方社交平台的认证服务去验证用户身份了,用户授权并没有经过我们自己的服务器,也不是我们的服务器代替用户去请求第三方社交平台的认证接口
Client:用户注册平台,想要找第三方社交平台来获取注册用户的开放API信息来创建账号登录对应的应用平台
Resource Owner:用户本人
Authorization Server:第三方社交平台认证服务
Resource Server:第三方社交平台的用户信息资源服务器

基本流程
这个流程和上图有部分区别,是网上流传的图有问题
注册平台首先将多种授权请求Authorization Request[即第三方社交平台提供的授权请求接口]提供给用户,用户在对应第三方社交平台提供的授权平台对社交账号进行登录来进行授权,登录操作的请求是用户直接发给第三方社交平台的认证接口,授权页面也是第三方社交平台提供的,登录操作的请求从用户客户端直接发送给第三方社交平台的认证接口,第三方认证接口返回响应结果给用户客户端的同时请求头中携带一个重定向给注册平台的请求,重定向的时候会在请求路径后面携带一个code授权码,该授权码关联了发起登录操作的用户的开放API信息
注册平台拿着这个授权码由服务器发起请求携带授权码去第三方社交平台的资源服务器去获取用户的开放API受保护信息
微博社交平台登录流程
1️⃣:进入微博开发平台申微博登录权限,有权限了才能做微博登录,登录微博开发平台后点击微连接--网站接入--立即接入,指定应用名称,点击创建应用
2️⃣:进入我的应用,在基本信息中能看到应用名称、App Key、App Secret,在高级信息中还要填写两个回调地址,一个是授权回调页[用户授权成功后跳转回注册平台的哪个页面],一个是取消授权回调页[用户授权失败后跳转的注册平台的哪个页面],微博在应用未上线期间不用走审核上线流程,也可以走通测试流程,但是应用上线需要提供公司的资质信息,测试期间应用最多关联15个微博测试账号
🔎:使用个人账号注册用户,必须注册用户才能创建应用,个人用户只需要提供身份证,企业用户还需要提供经营许可
3️⃣:在文档选项卡下面有个OAuth2.0授权认证,里面有不同客户端平台的授权方式,其中Web网站的授权一栏就是网站的授权方式
微博的OAuth2.0登录授权流程
这是微博授权获取用户开放API信息流程相对于Oauth2.0的设计变化
Client:注册平台;User Agent:用户客户端比如浏览器;Resource Owner:用户信息服务器;Authorization Server:微博用户认证服务器
A:注册平台给用户客户端发送授权页面链接,用户客户端会携带注册平台的标识和重定向URI以及用户的授权信息
注册平台的ClientId是注册平台对应应用的APP Key,是注册平台发给用户超链接时URI中携带的,除此以外还携带了重定向URL,重定向地址要使用在微博开发平台中设置的
B:将用户授权信息和认证平台的信息提交给微博的认证服务器并同时去用户信息资源服务器获取用户开放API受保护的信息
用户点击注册平台提供的页面登录验证成功后会在返回的授权页面得到正在获取用户信息的注册平台信息以及要获取的信息,点击授权就能就能重定向到注册平台要求重定向的页面并在URI中携带授权码,参数名为code
C:认证服务器给用户客户端返回一个授权码,客户端通过重定向将授权码发送给注册平台
D:平台通过用户客户端获取的授权码和重定向地址去认证服务器获取用户信息访问令牌
注册平台获取到URI中的授权码、注册平台的App Key、APP Secret、授权码和重定向地址并请求认证服务指定地址来获取访问令牌,该接口的请求方式是POST,只要响应数据中有access_token字段就是换取授权码成功,因为这个参数中有APP Secret,这个APP Secret一定不能泄露,因此这个请求一定不能在页面中进行,防止APP Secret泄露
返回授权码不直接返回访问令牌是因为网络数据传输不安全,浏览器都可以直接看到授权码,在知道授权码的前提下还要APP Secret才能获取到访问令牌
授权码换取访问令牌的操作只有一次机会,换过就授权码就不能使用了,但是访问令牌在过期时间内可以一直使用,而且同一个注册平台同一个用户在有效期间内的访问令牌无论换取多少次都是相同的
E:认证服务器响应给注册平台访问令牌,以后注册平台可以拿着访问令牌去获取用户的开放API信息
在微博开发平台我的应用中接口管理中的已有权限中能看到通过访问令牌能访问到的用户信息全部接口,比如根据微博id获取用户单条微博内容,
users/show是根据用户id获取用户信息,还有对应的请求参数传参接口文档都有对应的说明,微博真狠啊,暴露的信息还挺多,省市都能查出来;还能通过访问令牌获取到用户的UID
注意微博的接口请求方式可以在文档中的接口文档部分查看,比较傻逼,还专门在一个地方写,使用到的地方却不说,万一没看到接口文档都不知道请求方式是什么

微博社交登录流程图

微博社交登录代码实现
前端根据微博文档--微博登录接入--Web端的验证授权文档向用户提供微博授权页面URL如下:
https://api.weibo.com/oauth2/authorize?client_id=2368824446&response_type=code&redirect_uri=http://auth.earlmall.com/weibo/auth/success注意这里的参数
redirect_uri要携带域名,不是单纯意义上的uri,而且需要与微博开放平台上授权回调页预设值一样授权成功直接重定向到
http://auth.earlmall.com/weibo/auth/success?code=8201f31b73ab99efa8f0180f64893b5d,其中code参数就是用户授权成功的授权码,我们让这个重定向访问我们自己的接口处理用户注册或者登录信息并且保存用户的授权信息
xxxxxxxxxx<ul><li><a href=""><img src="static/login/JD_img/weixin.png"/><span>微信</span></a></li><li class="f4"> |</li><li><a href="https://api.weibo.com/oauth2/authorize?client_id=2368824446&response_type=code&redirect_uri=http://auth.earlmall.com/auth/weibo/success"><img src="static/login/JD_img/weibo.png"/><span>微博</span></a></li></ul>创建对应回调接口,使用短信的
HttpUtils工具类来在服务端发起请求,通过用户的授权码获取用户访问令牌对应的响应结果httpResponse实例短信提供的
HttpUtils工具类xxxxxxxxxxpackage com.earl.mall.auth.utils;import org.apache.commons.lang.StringUtils;import org.apache.http.HttpResponse;import org.apache.http.NameValuePair;import org.apache.http.client.HttpClient;import org.apache.http.client.entity.UrlEncodedFormEntity;import org.apache.http.client.methods.HttpDelete;import org.apache.http.client.methods.HttpGet;import org.apache.http.client.methods.HttpPost;import org.apache.http.client.methods.HttpPut;import org.apache.http.conn.ClientConnectionManager;import org.apache.http.conn.scheme.Scheme;import org.apache.http.conn.scheme.SchemeRegistry;import org.apache.http.conn.ssl.SSLSocketFactory;import org.apache.http.entity.ByteArrayEntity;import org.apache.http.entity.StringEntity;import org.apache.http.impl.client.DefaultHttpClient;import org.apache.http.message.BasicNameValuePair;import javax.net.ssl.SSLContext;import javax.net.ssl.TrustManager;import javax.net.ssl.X509TrustManager;import java.io.UnsupportedEncodingException;import java.net.URLEncoder;import java.security.KeyManagementException;import java.security.NoSuchAlgorithmException;import java.security.cert.X509Certificate;import java.util.ArrayList;import java.util.List;import java.util.Map;public class HttpUtils {/*** get** @param host* @param path* @param method* @param headers* @param querys* @return* @throws Exception*/public static HttpResponse doGet(String host, String path, String method,Map<String, String> headers,Map<String, String> querys)throws Exception {HttpClient httpClient = wrapClient(host);HttpGet request = new HttpGet(buildUrl(host, path, querys));for (Map.Entry<String, String> e : headers.entrySet()) {request.addHeader(e.getKey(), e.getValue());}return httpClient.execute(request);}/*** post form** @param host* @param path* @param method* @param headers* @param querys* @param bodys* @return* @throws Exception*/public static HttpResponse doPost(String host, String path, String method,Map<String, String> headers,Map<String, String> querys,Map<String, String> bodys)throws Exception {HttpClient httpClient = wrapClient(host);HttpPost request = new HttpPost(buildUrl(host, path, querys));for (Map.Entry<String, String> e : headers.entrySet()) {request.addHeader(e.getKey(), e.getValue());}if (bodys != null) {List<NameValuePair> nameValuePairList = new ArrayList<NameValuePair>();for (String key : bodys.keySet()) {nameValuePairList.add(new BasicNameValuePair(key, bodys.get(key)));}UrlEncodedFormEntity formEntity = new UrlEncodedFormEntity(nameValuePairList, "utf-8");formEntity.setContentType("application/x-www-form-urlencoded; charset=UTF-8");request.setEntity(formEntity);}return httpClient.execute(request);}/*** Post String** @param host* @param path* @param method* @param headers* @param querys* @param body* @return* @throws Exception*/public static HttpResponse doPost(String host, String path, String method,Map<String, String> headers,Map<String, String> querys,String body)throws Exception {HttpClient httpClient = wrapClient(host);HttpPost request = new HttpPost(buildUrl(host, path, querys));for (Map.Entry<String, String> e : headers.entrySet()) {request.addHeader(e.getKey(), e.getValue());}if (StringUtils.isNotBlank(body)) {request.setEntity(new StringEntity(body, "utf-8"));}return httpClient.execute(request);}/*** Post stream** @param host* @param path* @param method* @param headers* @param querys* @param body* @return* @throws Exception*/public static HttpResponse doPost(String host, String path, String method,Map<String, String> headers,Map<String, String> querys,byte[] body)throws Exception {HttpClient httpClient = wrapClient(host);HttpPost request = new HttpPost(buildUrl(host, path, querys));for (Map.Entry<String, String> e : headers.entrySet()) {request.addHeader(e.getKey(), e.getValue());}if (body != null) {request.setEntity(new ByteArrayEntity(body));}return httpClient.execute(request);}/*** Put String* @param host* @param path* @param method* @param headers* @param querys* @param body* @return* @throws Exception*/public static HttpResponse doPut(String host, String path, String method,Map<String, String> headers,Map<String, String> querys,String body)throws Exception {HttpClient httpClient = wrapClient(host);HttpPut request = new HttpPut(buildUrl(host, path, querys));for (Map.Entry<String, String> e : headers.entrySet()) {request.addHeader(e.getKey(), e.getValue());}if (StringUtils.isNotBlank(body)) {request.setEntity(new StringEntity(body, "utf-8"));}return httpClient.execute(request);}/*** Put stream* @param host* @param path* @param method* @param headers* @param querys* @param body* @return* @throws Exception*/public static HttpResponse doPut(String host, String path, String method,Map<String, String> headers,Map<String, String> querys,byte[] body)throws Exception {HttpClient httpClient = wrapClient(host);HttpPut request = new HttpPut(buildUrl(host, path, querys));for (Map.Entry<String, String> e : headers.entrySet()) {request.addHeader(e.getKey(), e.getValue());}if (body != null) {request.setEntity(new ByteArrayEntity(body));}return httpClient.execute(request);}/*** Delete** @param host* @param path* @param method* @param headers* @param querys* @return* @throws Exception*/public static HttpResponse doDelete(String host, String path, String method,Map<String, String> headers,Map<String, String> querys)throws Exception {HttpClient httpClient = wrapClient(host);HttpDelete request = new HttpDelete(buildUrl(host, path, querys));for (Map.Entry<String, String> e : headers.entrySet()) {request.addHeader(e.getKey(), e.getValue());}return httpClient.execute(request);}private static String buildUrl(String host, String path, Map<String, String> querys) throws UnsupportedEncodingException {StringBuilder sbUrl = new StringBuilder();sbUrl.append(host);if (!StringUtils.isBlank(path)) {sbUrl.append(path);}if (null != querys) {StringBuilder sbQuery = new StringBuilder();for (Map.Entry<String, String> query : querys.entrySet()) {if (0 < sbQuery.length()) {sbQuery.append("&");}if (StringUtils.isBlank(query.getKey()) && !StringUtils.isBlank(query.getValue())) {sbQuery.append(query.getValue());}if (!StringUtils.isBlank(query.getKey())) {sbQuery.append(query.getKey());if (!StringUtils.isBlank(query.getValue())) {sbQuery.append("=");sbQuery.append(URLEncoder.encode(query.getValue(), "utf-8"));}}}if (0 < sbQuery.length()) {sbUrl.append("?").append(sbQuery);}}return sbUrl.toString();}private static HttpClient wrapClient(String host) {HttpClient httpClient = new DefaultHttpClient();if (host.startsWith("https://")) {sslClient(httpClient);}return httpClient;}private static void sslClient(HttpClient httpClient) {try {SSLContext ctx = SSLContext.getInstance("TLS");X509TrustManager tm = new X509TrustManager() {public X509Certificate[] getAcceptedIssuers() {return null;}public void checkClientTrusted(X509Certificate[] xcs, String str) {}public void checkServerTrusted(X509Certificate[] xcs, String str) {}};ctx.init(null, new TrustManager[] { tm }, null);SSLSocketFactory ssf = new SSLSocketFactory(ctx);ssf.setHostnameVerifier(SSLSocketFactory.ALLOW_ALL_HOSTNAME_VERIFIER);ClientConnectionManager ccm = httpClient.getConnectionManager();SchemeRegistry registry = ccm.getSchemeRegistry();registry.register(new Scheme("https", 443, ssf));} catch (KeyManagementException ex) {throw new RuntimeException(ex);} catch (NoSuchAlgorithmException ex) {throw new RuntimeException(ex);}}}httpResponse.getEntity()能获取到响应的响应体,Apache提供了一个工具类EntityUtils.toString(httpResponse.getEntity())能将响应体处理成一个json字符串,我们可以通过第三方接口的响应体json对象通过在线工具处理成对应的实体类,通过Fastjson这种工具类来将json字符串转换成对应的实体类实例微博响应的内容
json字符串的参数如下,其中access_token是用户与注册平台建立唯一映射关系并识别用户登录授权状态的唯一标识;expires_in是access_token的生命周期,单位是秒;remind_in也是access_token的生命周期,但是这个参数即将被废弃;uid是授权用户的UID,这个字段只是方便开发者减少一次user/show接口调用而返回的,注册平台不能使用UID来替代access_token,但是在一个平台这个UID是唯一的,我们一方面可以通过该UID验证用户是否使用该微博账号注册过,一方面我们还可以通过该UID外加平台标识作为用户身份的唯一标识
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 封装微博访问令牌数据* @创建日期 2024/10/17* @since 1.0.0*/public class WeiBoAccessTokenTo {/*** 微博用户授权的访问令牌*/private String access_token;private String remind_in;private String expires_in;private String uid;private String isRealName;}
控制器方法
xxxxxxxxxx/*** @param code* @return {@link String }* @描述 微博登录用户成功授权后的回调接口* 通过社交平台的UID检查用户是否注册过,如果没注册过为用户注册账号并登录账户,如果用户注册过直接登录* 都需要保存用户的访问令牌和令牌有效时间* @author Earl* @version 1.0.0* @创建日期 2024/10/16* @since 1.0.0*/("/weibo/success")public String weiboAuthSuccessThen(String code, RedirectAttributes attributes){try {UserBaseInfoVo user = authService.weiboAuthSuccessThen(code);attributes.addFlashAttribute(user);return "redirect:http://earlmall.com";}catch (RRException e){attributes.addFlashAttribute("error",e.getCode()+":"+e.getMsg());return "redirect:http://auth.earlmall.com/login.html";}}业务方法
处理访问令牌的逻辑
获取到
response,拿到授权访问令牌根据返回的参数
UID判断数据库中该用户是否已经注册,如果已经注册过了我们就将该用户的access_token和expires_in字段进行更新,并且返回用户实例,如果没有注册我们就执行社交账号注册流程给数据库用户表添加一个
social_uid字段,字段不能设置非空,因为注册平台注册的用户该字段为空,但是社交账号注册的用户有这个字段,我们可以通过该字段来判断用户的社交登录是需要进行注册还是进行登录同时因为
access_token只能获取一次,需要注册平台自己保存用户的访问凭证方便在有效时间内来获取用户的开放API信息,给用户表添加一个访问令牌access_token字段;这个数据选择放在数据库的原因是redis里面存的数据应该是高频访问,或者是小数据很短时间就失效了,这个token不是给用户用的也不是来验证用户身份的,使用频率也很低,而且有效时间也不是很短给用户表添加一个
expires_in字段表示访问令牌剩余有效时间,这里处理成保存过期时间的毫秒数
[数据库表添加额外三个字段]
xxxxxxxxxx/*** 会员** @author Earl* @email 18794830715@163.com* @date 2024-01-27 11:47:58*/("ums_member")public class MemberEntity implements Serializable {private static final long serialVersionUID = 1L;/*** id*/private Long id;/*** 会员等级id*/private Long levelId;/*** 用户名*/private String username;/*** 密码*/private String password;/*** 昵称*/private String nickname;/*** 手机号码*/private String mobile;/*** 邮箱*/private String email;/*** 头像*/private String header;/*** 性别*/private Integer gender;/*** 生日*/private Date birth;/*** 所在城市*/private String city;/*** 职业*/private String job;/*** 个性签名*/private String sign;/*** 用户来源*/private Integer sourceType;/*** 积分*/private Integer integration;/*** 成长值*/private Integer growth;/*** 启用状态*/private Integer status;/*** 用户社交平台的uid和平台标识*/private String social_uid;/*** 用户的授权访问令牌*/private String access_token;/*** 访问令牌的有效时间*/private Long expires_in;/*** 注册时间*/(fill = FieldFill.INSERT)private Date createTime;}
社交账号注册流程
使用
access_token调用社交账号的API接口https://api.weibo.com/2/users/show.json获取用户的社交账户信息,请求头和请求参数都需要使用Map来作为调用网络接口的入参传递使用
JSON.parseObject(jsonStr)将响应结果转成JSONObject对象,从对象中获取社交账号的昵称、性别、社交账户的uid[为了避免社交账户uid重复还要给对应的社交平台用一个标识符前缀进行标识],用户信息访问令牌,令牌有效时间等信息保存到用户表中,这个注册实际上是用户的uid对应社交账号上的信息绑定上我们用户表的主键id,以后系统对用户的各种操作比如积分累计,查询物流地址,订单等等操作都是根据用户的id来进行的为了避免远程调用接口的信息过于敏感直接对外部暴露[比如查询用户密码密文],可能需要对一些远程调用接口做权限控制,只允许特定的用户角色访问,常用的限制方式参考文档通用解决方案
注册或者登录成功除了返回用户信息还要返回友好的弹窗提示,前端可以根据用户信息判断欢迎谁谁谁
❓:首页的域名是
earlmall.com,登录页面的域名是auth.earlmall.com,登录页登录或者注册成功要跳转首页,首页要在用户没登录前显示请登录,用户登录后要显示欢迎谁谁谁替代请登录,从一个域名跳转到另一个域名要携带数据这一块又是一个大问题
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 第三方社交平台授权成功回调服务实现类* @创建日期 2024/10/16* @since 1.0.0*/("authService")public class AuthServiceImpl implements AuthService {private UserFeignClient userFeignClient;/*** @param code* @return {@link UserBaseInfoVo }* @描述 微博授权成功后的用户登录或注册* @author Earl* @version 1.0.0* @创建日期 2024/10/18* @since 1.0.0*/public UserBaseInfoVo weiboAuthSuccessThen(String code) throws RRException{System.out.println(code);//1, 通过用户授权码去获取用户的访问令牌和用户的uidHashMap<String, String> header = new HashMap<>();HashMap<String, String> query =new HashMap<>();query.put("client_id",WeiBoAuthConstant.CLIENT_ID);query.put("client_secret",WeiBoAuthConstant.CLIENT_SECRET);query.put("grant_type","authorization_code");query.put("redirect_uri",WeiBoAuthConstant.REDIRECT_URI);query.put("code",code);WeiBoAccessTokenTo accessTokenInfo=null;try {HttpResponse res = HttpUtils.doPost(WeiBoAuthConstant.WEIBO_API_HOST,WeiBoAuthConstant.ACCESS_TOKEN_URI,"POST", header, query, "");accessTokenInfo=JSON.parseObject(EntityUtils.toString(res.getEntity()),new TypeReference<WeiBoAccessTokenTo>(){});} catch (Exception e) {throw new RRException(StatusCode.ACCESS_TOKEN_OBTAIN_EXCEPTION.getMsg(),StatusCode.ACCESS_TOKEN_OBTAIN_EXCEPTION.getCode());}//2. 根据用户的UID去数据库检查该社交账号是否在本系统注册过,如果注册过更新用户的授权信息AccessTokenTo accessToken = new AccessTokenTo();BeanUtils.copyProperties(accessTokenInfo,accessToken);R res = userFeignClient.getBySocialUid(accessToken);//4. 如果注册过就直接保存用户访问令牌信息并返回用户基础信息直接进行登录if (res.getCode() == 0) {UserBaseInfoVo userInfo = new UserBaseInfoVo();BeanUtils.copyProperties(res.get("user", new TypeReference<UserTo>() {}),userInfo);return userInfo;}//3. 如果没有注册过就检索用户社交平台信息用户注册并保存用户的访问令牌信息并直接登录返回用户基础信息HashMap<String, String> userQuery = new HashMap<>();userQuery.put("access_token", accessTokenInfo.getAccess_token());userQuery.put("uid", accessTokenInfo.getUid());WeiBoUserInfoTo weiboUserInfo = null;try {HttpResponse userInfoResp = HttpUtils.doGet(WeiBoAuthConstant.WEIBO_API_HOST,WeiBoAuthConstant.USER_INFO_URI, "GET", new HashMap<>(), userQuery);weiboUserInfo = JSON.parseObject(EntityUtils.toString(userInfoResp.getEntity()),new TypeReference<WeiBoUserInfoTo>(){});} catch (Exception e) {throw new RRException(StatusCode.SOCIAL_ACCOUNT_PULL_EXCEPTION.getMsg(),StatusCode.SOCIAL_ACCOUNT_PULL_EXCEPTION.getCode());}UserTo userTo = new UserTo();userTo.setSocial_uid(WeiBoAuthConstant.UID_PREFIX+weiboUserInfo.getId());userTo.setUsername(WeiBoAuthConstant.UID_PREFIX+weiboUserInfo.getId());userTo.setCity(weiboUserInfo.getLocation());userTo.setAccess_token(accessTokenInfo.getAccess_token());userTo.setExpires_in(System.currentTimeMillis()+Long.parseLong(accessTokenInfo.getExpires_in())*1000);userTo.setNickname(weiboUserInfo.getName());userTo.setHeader(weiboUserInfo.getAvatar_hd());userTo.setGender("m".equals(weiboUserInfo.getGender())?1:0);UserBaseInfoVo userInfo = new UserBaseInfoVo();R resp = userFeignClient.registryBySocialAccount(userTo);if(resp.getCode()!=0){throw new RRException(StatusCode.ACCOUNT_CREATE_EXCEPTION.getMsg(),StatusCode.ACCOUNT_CREATE_EXCEPTION.getCode());}BeanUtils.copyProperties(resp.get("user", new TypeReference<UserTo>(){}),userInfo);return userInfo;}}封装第三方社交平台用户信息的实体类
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 封装微博/users/show.json返回的接口数据* @创建日期 2024/10/18* @since 1.0.0*/public class WeiBoUserInfoTo {/*** 用户UID*/private long id;/*** 用户昵称*/private String screen_name;/*** 友好显示名称*/private String name;/*** 用户所在省级ID*/private int province;/*** 用户所在城市ID*/private int city;/*** 用户所在地*/private String location;/*** 用户个人描述*/private String description;/*** 用户博客地址*/private String url;/*** 用户头像地址(中图),50×50像素*/private String profile_image_url;/*** 用户的微博统一URL地址*/private String profile_url;/*** 用户的个性化域名*/private String domain;/*** 用户的微号*/private String weihao;/*** 性别,m:男、f:女、n:未知*/private String gender;/*** 粉丝数*/private int followers_count;/*** 关注数*/private int friends_count;/*** 微博数*/private int statuses_count;/*** 收藏数*/private int favourites_count;/*** 用户创建(注册)时间*/private String created_at;/*** 暂未支持*/private boolean following;/*** 是否允许所有人给我发私信,true:是,false:否*/private boolean allow_all_act_msg;/*** 是否允许标识用户的地理位置,true:是,false:否*/private boolean geo_enabled;/*** 是否是微博认证用户,即加V用户,true:是,false:否*/private boolean verified;/*** 用户的最近一条微博信息字段 详细*/private Status status;/*** 是否允许所有人对我的微博进行评论,true:是,false:否*/private boolean allow_all_comment;/*** 用户头像地址(大图),180×180像素*/private String avatar_large;/*** 用户头像地址(高清),高清头像原图*/private String avatar_hd;/*** 认证原因*/private String verified_reason;/*** 该用户是否关注当前登录用户,true:是,false:否*/private boolean follow_me;/*** 用户的在线状态,0:不在线、1:在线*/private int online_status;/*** 用户的互粉数*/private int bi_followers_count;/*** 用户当前的语言版本,zh-cn:简体中文,zh-tw:繁体中文,en:英语*/private String lang;public class Status {private Date created_at;private long id;private String text;private String source;private boolean favorited;private boolean truncated;private String in_reply_to_status_id;private String in_reply_to_user_id;private String in_reply_to_screen_name;private String geo;private String mid;private List<String> annotations;private int reposts_count;private int comments_count;}}
远程调用接口
[控制器方法]
xxxxxxxxxx/*** @param accessToken* @return {@link R }* @描述 根据用户的社交平台UID来查询用户记录,如果有对应的记录更新对应的访问令牌信息* @author Earl* @version 1.0.0* @创建日期 2024/10/18* @since 1.0.0*/("/social/uid")public R getBySocialUid( AccessTokenTo accessToken){try{MemberEntity user = memberService.getBySocialUid(accessToken.getUid(),accessToken.getAccess_token(),accessToken.getExpires_in());return R.ok().put("user",user);}catch (RRException e){return R.error(e.getCode(),e.getMsg());}}/*** @param userEntity* @return {@link R }* @描述 通过社交平台账号注册用户账号* @author Earl* @version 1.0.0* @创建日期 2024/10/18* @since 1.0.0*/("/registry/social")public R registryBySocialAccount( MemberEntity userEntity){MemberEntity user = memberService.registryBySocialAccount(userEntity);return R.ok().put("user",user);}[对应业务实现]
xxxxxxxxxx/*** @param socialUid* @return {@link MemberEntity }* @描述 通过用户的社交账号id来获取用户记录* @author Earl* @version 1.0.0* @创建日期 2024/10/18* @since 1.0.0*/public MemberEntity getBySocialUid(String socialUid,String access_token,String expires_in) throws RRException {MemberEntity user = getOne(new QueryWrapper<MemberEntity>().eq("social_uid", socialUid));if(user==null){throw new RRException(StatusCode.USER_ABSENT_EXCEPTION.getMsg(),StatusCode.USER_ABSENT_EXCEPTION.getCode());}user.setAccess_token(access_token);user.setExpires_in(System.currentTimeMillis()+Long.parseLong(expires_in)*1000);update(user, new UpdateWrapper<MemberEntity>().eq("id", user.getId()));return user;}/*** @param user* @return boolean* @描述 通过社交账号平台注册用户账号* @author Earl* @version 1.0.0* @创建日期 2024/10/18* @since 1.0.0*/public MemberEntity registryBySocialAccount(MemberEntity user) {if(defaultUserLevel==null){defaultUserLevel = memberLevelService.getOne(new QueryWrapper<MemberLevelEntity>().eq("default_status", UserConstant.UserDefaultLevelStatus.DEFAULT_STATUS.getCode()));}user.setLevelId(defaultUserLevel.getId());user.setIntegration(0);user.setGrowth(defaultUserLevel.getCommentGrowthPoint());save(user);return user;}还有一些问题没有解决,比如账户名不能直接使用社交账户的名字,可能别人已经占用了,不同社交平台可能冲突,账户合并问题,授权过期的问题感觉不用管,浏览器的授权信息过期会自动要求用户重新授权,如果授权有效期没过,浏览器保存着用户的授权信息会直接跳过用户授权步骤直接进入微博的验证授权步骤[浏览器没关会保留微博的授权信息,像Chrome这种即使浏览器关了也会保存微博的账户信息],微博生成新的授权码直接进入回调逻辑,此时用户感知不到微博授权的过程,这样能实现用户如果在浏览器其他地方进行了微博账户登录且浏览器没有清空用户的登录状态信息,用户能直接跳过输入账户密码或者扫码直接一键登录或者注册账号
不同浏览器的行为不同,Chrome对社交平台的账号登录状态保持很久,即使浏览器关闭了一段时间内还可以继续保持登录状态,只有手动注销账号清空登录信息才能比较安全的退出登录状态
这里留意一下老师是怎么手动清空登录状态的,这里当时没做记录
使用
SpringSession来实现用户登录成功以后保存用户基本信息到session中并实现用户基本数据在session中的跨实例、服务跨域共享,用户登录后跳转首页欢迎用户的昵称并隐藏请登录的超链接,如果用户已经登录过了,我们要实现用户通过链接访问登录页时自动让其自动跳转到首页登录状态,此时不能再使用视图映射器做路径视图匹配,需要使用控制器方法从session中获取用户数据来对用户的登录状态做出判断这里感觉用拦截器实现更好,有时间可以探索一下
不只是登录页,商品详情页和检索页面反正一切不需要登录就能访问的页面都要实现该功能,即用户已经登录过了,session中有用户信息就要
注意
Thymeleaf可以直接使用${session.loginUser}从HttpServletSession中获取指定key的value,使用了SpringSession也可以直接取出来注意服务中对应的session数据必须设置相同的前缀,否则
Thymeleaf无法从session中获取
xxxxxxxxxx<ul><li th:if="${session.user==null}"><a href="http://auth.earlmall.com/login.html">你好,请登录</a></li><li th:unless="${session.user==null}">[[${session.user.nickname}]]</li><li th:if="${session.user==null}"><a href="http://auth.earlmall.com/registry.html" class="li_2">免费注册</a></li><span>|</span><li><a href="#">我的订单</a></li></ul>
微信开放平台
因为微博开放平台的运维水平太次,用微信的,微信的即使个人的也要填表手动签名,更麻烦,切换成微博使用个人账号注册成功[注册企业账号需要提供企业经营许可,也比较麻烦],注意邮箱验证连接要在电脑浏览器中点开,手机点开是没有验证效果的,还是使用微博的,微博还行啊,除了服务器拉胯,邮箱验证必须用浏览器,客服不得劲儿,其他都还行,测试不需要严格审核,项目也不需要审核,创建项目就能直接开始开发
单点登录
对于多生态的超大系统,比如尚硅谷[
atguigu.com]旗下有尚硅谷在线教育[gulixueyuan.com]、有尚硅谷电子商城[gulimall.com]、众筹系统[gulifunding.com]等等,如果我们每个小系统都设置一个账号,用户使用旗下的每个产品都需要注册一个账号,这样用户使用体验非常不好在这种超大型系统中,我们希望专门抽取一个认证中心专门来处理用户登录业务,只要用户在一个小系统中进行了登录,任何其他系统都能保持用户的登录状态,在任何一个小系统中登出,就在整个系统中的其他应用也登出,而且这些小系统的顶级域名还可以不一样,这就是单点登录
这种单点登录是不能使用session来解决不同系统中用户登录状态的识别问题,因为下发cookie的作用域最大只能放大到一级域名即顶级域名,只要请求访问的顶级域名变化了就无法携带其他顶级域名和子域服务下发的cookie,就没法拿着这个cookie去验证用户的登录状态
开源项目
开源的单点登录demo
码云搜索徐雪里/xxl-sso,这是一个XXL社区提供的分布式单点登录框架,下载压缩包或者克隆到本地
项目目录结构
xxl-sso-core是核心包xxl-sso-server是登录中心服务器xxl-sso-samples是一些简单的例子,有基于cookie和session的xxl-sso-web-sample-springboot,也有基于token的xxl-sso-token-sample-springboot,这两个就是下面使用逻辑的客户端

认证中心配置文件解析[配置文件在目录
xxl-sso-server中,后面没有特殊说明都在该目录下]xxxxxxxxxx### webserver.port=8080 #服务器的端口是8080server.servlet.context-path=/xxl-sso-server #访问路径为8080/xxl-sso-server### resourcesspring.mvc.servlet.load-on-startup=0spring.mvc.static-path-pattern=/static/**spring.resources.static-locations=classpath:/static/### freemarkerspring.freemarker.templateLoaderPath=classpath:/templates/spring.freemarker.suffix=.ftlspring.freemarker.charset=UTF-8spring.freemarker.request-context-attribute=requestspring.freemarker.settings.number_format=0.############# xxl-ssoxxl.sso.redis.address=redis://127.0.0.1:6379 #配置了redis,我们需要将其改成自己的redis服务器配置xxl.sso.redis.expire.minute=1440测试目录
xxl-sso-samples下客户端的配置文件解析[
xxl-sso-web-sample-springboot]使用命令
mvn clean package -Dmaven.skip.test=true,如果单独对这个子项目打包,注意这个子项目依赖核心包xxl-sso-core,在对xxl-sso-web-sample-springboot进行打包的时候会去本地仓库找对应的核心包依赖,只打包当前项目是不会安装到本地仓库的,因此需要先在核心包xxl-sso-core的pom.xml所在目录下使用命令mvn install将该核心包安装到本地仓库中,这种自定义的所有被依赖包必须在本地仓库有了才能对当前项目进行打包我们可以直接在父项目
pom.xml所在使用命令mvn clean package -Dmaven.skip.test=true一次性将所有的子项目都打包好,这个就是谷粒商城的手动打包方式,如果是整体打包,打包子项目就不需要单独将被依赖的包安装到本地仓库中
使用命令
java -jar xxl-sso-web-sample-springboot-1.1.1-SNAPSHOT.jar --server.port=8081来启动测试实例项目注意可以在配置文件更改服务的端口,也可以在启动命令中更改服务实例的端口
使用命令
java -jar xxl-sso-web-sample-springboot-1.1.1-SNAPSHOT.jar --server.port=8082来启动测试实例项目
xxxxxxxxxx### webserver.port=8081server.servlet.context-path=/xxl-sso-web-sample-springboot #访问路径默认是8081/xxl-sso-web-sample-springboot### resourcesspring.mvc.servlet.load-on-startup=0spring.mvc.static-path-pattern=/static/**spring.resources.static-locations=classpath:/static/### freemarkerspring.freemarker.templateLoaderPath=classpath:/templates/spring.freemarker.suffix=.ftlspring.freemarker.charset=UTF-8spring.freemarker.request-context-attribute=requestspring.freemarker.settings.number_format=0.############# xxl-ssoxxl.sso.server=http://xxlssoserver.com:8080/xxl-sso-server #这个是认证中心的地址,这个地址需要和实际认证中心的地址保持一致xxl.sso.logout.path=/logoutxxl-sso.excluded.paths=xxl.sso.redis.address=redis://127.0.0.1:6379 #配置redis将redis改成我们自己的服务器配置
框架业务使用示例和逻辑
我们准备三个顶级域名
ssoserver.com、client1.com、client2.com,我们将ssoserver作为登录认证服务器,将client1.com和client2.com作为我们的小系统,用来模拟跨顶级域名的单点登录测试效果,小系统就是上面说的xxl-sso-samples目录下使用
SwitchHost更改三个域名都映射到本机,如果不使用SwitchHost需要更改路径C:\windows\System32\drivers\etc\hosts启动服务
xxl-sso-server,我们在启动的时候需要将源文件打包,pom.xml中直接聚合了三个目录,我们可以一次性将整个项目都打包了,在pom.xml所在目录打开cmd窗口,使用命令mvn clean package -Dmaven.skip.test=true清包打包跳过Maven测试[即使没有打过包的也要进行清包,其他项目也是如此,避免出现莫名其妙的问题],打完包直接使用java -jar命令启动xxxxxxxxxx<modules><module>xxl-sso-core</module><module>xxl-sso-server</module><module>xxl-sso-samples</module></modules>通过请求路径
http://ssoserver.com:8080/xxl-sso-server访问认证中心分别使用两个端口启动项目
xxl-sso-web-sample-springboot,注意把配置文件给改对了,要保证redis服务器的地址和认证中心的地址正确分别通过请求路径
http://client1.com:8081/xxl-sso-web-sample-springboot和http://client2.com:8082/xxl-sso-web-sample-springboot访问一个测试服务两个服务实例验证任意一个认证中心登录,所有不同顶级域名的服务实例都登录,任意一个服务实例登出,所有不同顶级域名的服务实例都登出
业务实现
业务需求
配置一个中央认证服务器
ssoserver.com,其他系统要登录都要去中央认证服务器ssoserver.com进行登录,登录成功就跳转回来只要有一个系统进行过登录,其他的系统都不用进行登录,这些域名的顶级域名可能都不相同
全系统统一一个cookie来做登录校验,该cookie的名称为
sso-sessionid
单点登录业务逻辑
浏览器发送请求访问一个受保护的资源,服务器接收到请求后需要判断用户是否处于登录状态
判断用户是否处于登录状态还是从session中根据key获取用户信息,如果用户信息为null,即用户没有登录,就使用重定向发起请求到认证服务器去做用户登录,重定向是通过给响应头添加Location参数指定重定向地址来命令浏览器进行重定向
认证服务器做登录的接口登录成功就跳转回之前的页面,注意这个之前的页面不是固定的,这里的跳转逻辑很有意思
卧槽这太暴力了,直接把要求重定向到认证服务的服务接口地址作为参数传递给认证服务,认证服务登录通过后根据参数来重定向到原来的页面
注意因为登录页和登录业务接口实际上都是认证服务的接口,返回给用户的登录页也要携带用户最初做登录请求的页面并作为登录请求参数来携带给认证服务,即认证服务首先要提供登录页,登录页等用户输入完信息提交时需要处理用户的登录请求,因此认证服务包含两个接口,一个返回登录页,一个验证用户的账号密码,这两个接口访问期间都需要携带原来的发起登录请求的页面地址来作为登录成功的重定向地址
好奇这个重定向地址能不能放在认证服务的session中
注意因为受保护的资源访问是根据session中是否含有指定key的数据来判断是否需要跳转认证服务进行登录的,因此一定要保证认证服务登录成功一定要去公共的第三方存储对应的用户session数据,如果session数据没存储上或者压根没有存储数据,那么跳转受保护的资源的时候因为获取不到session中用户的数据就又会跳转认证服务,这就陷入了死循环
这块用户登录成功我们可以随机生成uuid作为key,以用户信息作为value,将用户信息存入redis;并在重定向地址中添加对应的key即uuid作为参数来让保护资源能根据该UUID去获取用户的登录状态信息,我们将该UUID的参数名定义为token,token不是必要的参数,我们可以通过注解
@RequestParam(value="token",required=false)来限制该参数不是必须的,只要登录成功跳转回受保护的资源就回携带token参数这样uuid就相当于token,但是这种方式明显不安全,token直接明文写在地址栏里而且没有进行加密
受保护的资源通过认证服务返回的token去获取认证服务获取用户信息并保存在自身的session中,以此作为用户登录状态的标识,这样受保护的资源会给当前浏览器下发JSESSIONID,不论用户请求多少次受保护的资源或者直接访问登录页面都会直接显示登录状态,但是目前仍然存在一个问题,其他系统直接访问受保护资源因为顶级域名不同所以请求无法携带JSESSIONID,又因为没有token,所以又会跳转认证服务做登录
我感觉这里不存在问题,认证服务也要保持对浏览器登录状态的识别,也需要下发cookie,其他系统做登录的时候携带该cookie就完事了,认证服务一看cookie有对应的用户数据直接返回用户信息
注意啊,一个顶级域名下发的cookie只要浏览器发起对应域名的请求就会自动携带其下发的所有cookie,不会受到此前页面的影响
实际上老师的做法也就是认证服务器登录成功给浏览器下发cookie的方式
response.addCookie(new Cookie("sso_token",uuid))其他系统只要有登录需求就会跳转认证服务器,只要当前浏览器在认证服务器上登录过,就会给当前浏览器下发一个cookie,此时就会携带cookie,我们可以在认证服务器中返回登录页面前根据该cookie从redis或者session中获取到对应的用户信息,能获取到就说明用户处于登录状态,此时就可以直接跳转回受保护的资源处;如果没有该cookie直接跳转登录页
SpringMVC的控制器方法的参数列表获取cookie中的参数注解用法@CookieValue(value="sso_token",required=false) String sso_token,该示例的意思是获取cookie中名为sso_token的请求头中的cookie,返回被保护资源的服务器时也需要带上对应的cookie参数作为token参数来保存在资源服务器的session中
核心是所有登录请求都跳转认证服务器,认证服务器一旦登录成功重定向到原页面并下发一份作用域为认证服务器的cookie给浏览器,作用域为认证服务器的域名,只要能根据cookie查到用户信息就是已登录,否则就进入用户登录授权流程,以后再次访问认证服务器只要已经登录过就会自动进行登录并跳转到对应的受保护资源,并且在子系统的session中保存对应的token,子系统可以只根据子系统中的session来获取认证服务的用户信息并判断用户的登录状态
认证服务器登录成功给浏览器下发作用域为认证服务器的cookie留下可校验的登录痕迹
认证服务器登录成功后要将登录痕迹或者说token信息携带在URL地址上一起重定向到受保护的资源页面
其他系统因为
session中没有用户登录信息就会访问认证服务器,认证服务器成功登录被重定向到当前页面并携带token参数,其他系统用token去认证服务器获取对应的用户信息保存到应用服务器自己的session中注意这个远程调用认证服务不能使用
Feign来进行调用,因为这个认证服务可能是拿PHP写的,不是拿Java写的,需要使用发送Http请求的工具类来发起网络请求去使用token获取用户的基本信息
单点登录的流程后面自己跟着老师的课自己画一个,老师的代码演示不是很严谨,相当于
Demo级别的基础功能实现,后面看要不要实现一下吧,这个项目是单顶级域名的系统,使用SpringSession就能解决用户登录问题这个
Demo实现是老师在讲解单点登录的原理,这个开源项目可以作为原理的实现来学习,这个学习思路很妙啊
分布式session共享
Session的使用问题
session的原理
原理图
用户登录成功可以将用户相关信息保存到以Map作为底层的
session中,并指定浏览器保存一个属性名为JSESSIONID的cookie,以后浏览器访问服务器会携带包含该参数的cookie,直到浏览器关闭才会清除该cookie,该JSESSIONID作为服务器识别用户身份的标识,通过该ID来查询用户在服务器中保存的特定状态信息

传统session存在的问题
1️⃣:在集群环境下,一个服务会被复制多份,但是运行过程中集群中不同运行实例上的
session信息无法被同步,即在一台服务器上被存入session的数据在另一台服务器或者运行实例上无法被取出2️⃣:在分布式环境下,不同服务间的
session不能共享,比如我在认证服务进行的数据认证并需要在跳转首页时验证用户的登录状态并传递用户信息到首页,但是首页在商品服务,我在认证服务存入session的数据无法被共享到商品服务的session中
3️⃣:
cookie的默认的作用域[就是下图的Domain字段]是同一个三级域名下,域名不一样,在发起请求时cookie无法被携带这里登录页面的
cookie可以在原理图中看到,请求域名发生变化,cookie并没有被携带,也无法通过cookie中的JSESSIONID来匹配用户会话状态信息

集群session共享
注意以下所有的方案解决的是同二级域名情况下,即同二级域名下浏览器发起请求携带完整的cookie数据,一旦二级域名发生变化,即使同一个客户端向同一台服务器发起请求也不会携带对应的cookie信息,这属于子域session共享问题
方案一:网关负载均衡同一个用户前后请求到不同的服务实例上,我们希望用户请求不管被负载到哪一台服务器上都能访问到同一个用户在系统中完整的
session数据,要实现该目的我们可以使用session复制[同步]方案session复制[同步]方案的原理是两个服务实例之间互相同步session,取两个服务实例session数据的并集这种方式的优点是Tomcat服务器原生支持,只需要修改Tomcat配置文件就能让多个Tomcat服务器之间互相复制Session
缺点也非常明显
session同步是网络IO过程,数据同步存在延迟,占用大量系统网络带宽,降低系统业务处理能力
真正的致命缺陷是session存储在内存中,任意一台服务实例都保存的是session全量数据,每增加一台服务实例,session数据就要增加一份,有N个服务实例相较于默认的单份session设计session同步带来的内存开销会增加N倍,小型系统服务实例数量少,用户少可以这么玩,大型分布式集群系统,这种方式不可取,会带来巨量的额外内存开销,内存贵而且上限低,服务器内存一大就会带动主板甚至整个服务器的更新换代,非常的昂贵
方案二:服务端不存储session,服务端设置保存session数据到客户端的cookie中,用户每次请求都携带完整的cookie信息,服务器从cookie中读取希望在session中共享的数据,相当于用户自己整理一个档案袋,走到哪里都携带这个档案袋。这种方式也全是缺点,实际开发中不会使用这种方式
session数据存放在cookie中,存在巨大的泄露、篡改和窃取等安全隐患,cookie中的数据在浏览器中可以直接看见,而且还可以直接手动修改,这个是不能用的核心原因
cookie中数据的总长度有限制,一般是4K,不能保存大量数据
每次请求都会携带完整cookie信息,对网络带宽资源是严重的浪费
方案三:使用哈希一致性,只要访问者的IP是同一个,我们就永远将来自该IP的请求转发到同一台服务器上,包括四层代理
ip_hash方案、七层代理业务字段hash方案这种方式也存在问题,比如某一台服务器宕机,而且现在运营商分配的IP地址也不一定是固定的,特别是移动互联网,用户的位置随时可能会变换
因为IP的不稳定因素,我们可以使用一个标识用户身份的字段比如用户id来做哈希运算,将一个用户的所有请求分配到同一台服务器上
优点
只需要更改
nginx或者网关的配置,不需要更改代码,因为哈希运算保证了运算的离散性,只要保证做哈希运算字段的数据离散性就能保证正常的负载均衡
支持服务器集群的大量水平扩容,这一点
session复制不行
缺点
session仍然存在于服务器中,服务器宕机或者重启可能会导致部分session丢失,影响到业务,比如用户登录状态信息丢失导致用户需要重新登录服务器水平扩展的时候,哈希取模以后用户请求的服务器会重新分布,但是想要将
session也转移到对应的服务器上难度比较高
方案四:统一在一个公共第三方存储session数据,把session数据存到数据库或者
Redis等一些NoSQL中间件中优点:
数据没有安全隐患,只要保证第三方存储设备中的数据安全,就没有人能篡改session中的数据
服务器水平扩容很方便
服务器重启或者扩容都不会有session丢失
缺点:
增加一次网络调用,而且使用该方案需要修改原来使用
session的代码,将从session中获取数据的代码改为从redis中获取数据,从redis中获取数据比直接从session中获取数据慢很多
Spring从这个方案入手推出了SpringSession方案来解决session共享的问题
子域session共享
子域
auth.earlmall.com对应请求下发的cookie,如果我们将作用域的范围手动设置成更大的顶级域名earlmall.com,这样子域auth.earlmall.com请求中下发的cookie在更大的顶级域名请求中仍然能正常携带完成的cookie信息,且子域名之间也可以共享同一个cookie,即一个父域名下的所有子域可以共享一个作用域Domain字段为父域名的cookie,这是浏览器的策略决定的,浏览器在发起指定作用域下的请求时会自动将cookie信息携带在请求头中,携带的形式是cookie: JSESSIONID=XXXXXXX比如cookie中保存了用户的
JSESSIONID,默认情况下该cookie的作用域Domain字段为对应的二级域名auth.earlmall.com,此时子域名变化了即使访问同一台服务器也不会携带cookie信息;我们可以在服务器下发cookie的时候手动设置为earlmall.com,这样就能实现即使访问其他子域名或者访问顶级域名时都会携带子域名auth.earlmall.com下发的cookie[因为登录服务是子域auth.earlmall.com实现的,JSESSIONID也是通过此处使用session下发的]
为了在一个顶级域名下的所有子域名和顶级域名间共享cookie,服务器在下发cookie的时候一定要将cookie的作用域设置为顶级域名,
下发cookie的时候调用的是
httpServletResponse.addCookie(new Cookie(String name,String value))来下发的cookie,这个cookie对象有一个setDomain(String domain)方法可以设置cookie的作用域,该作用域默认域名是当前请求的二级域名,因此我们下发cookie的时候需要将作用域更改为顶级域名,但是一些默认cookie的下发是由Tomcat本身来控制的,比如第一次使用session时Tomcat就会给cookie中下发一个JSESSIONID的cookie,如果我们自己来调整这段逻辑还是非常麻烦的SpringSession也考虑了这个问题并封装了对cookie的Domain操作,来解决session在一个顶级域名下的所有子域共享的问题
分布式集群session解决方案
浏览器访问认证服务进行登录,登录后我们将用户的登录信息存入
Redis,并给浏览器下发JSESSIONID的cookie,将该cookie的Domain作用域从子域名auth.earlmall.com改为顶级域名earlmall.com来放大作用域实现cookie在同一个顶级域名下所有请求共享,所有的服务都使用JSESSIONID从Redis中取出session中共享的数据,实现后端统一第三方存储session,前端拿着用户凭证JSESSIONID去各个服务从第三方中获取session中的数据使用
SpringSession来简化将session数据统一存储到第三方Redis以及解决session跨域共享问题的开发SpringSession项目官网通过spring官网--Projects--SpringSession--Learn可以找到SpringSession的官方文档,其中章节Samples and Guides示例和向导是SpringSession的快速上手指南,章节HttpSession Integration是SpringSession基于各种第三方存储介质的整合
SpringBoot基于Redis整合SpringSession解决session跨域跨服务共享问题🔎:在Samples and Guides中找到并点击HttpSession with Redis,可以找到对应的使用引导
引入依赖
xxxxxxxxxx<dependency><groupId>org.springframework.session</groupId><artifactId>spring-session-data-redis</artifactId></dependency>检查一下
SpringSession操作redis需不需要引入org.springframework.boot:spring-boot-starter-data-redis,经过验证,SpringSession依赖于org.springframework.data:spring-data-redis,所以无需再额外引入xxxxxxxxxx<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId></dependency>为了性能我们可以把默认的
lettuce-core排除掉使用最新的io.lettuce:lettuce-core:5.2.0.RELEASE,老版本对内存管理存在问题,并发量一高就会大量抛异常xxxxxxxxxx<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId><exclusions><exclusion><groupId>io.lettuce</groupId><artifactId>lettuce-core</artifactId></exclusion></exclusions></dependency><!-- https://mvnrepository.com/artifact/io.lettuce/lettuce-core --><dependency><groupId>io.lettuce</groupId><artifactId>lettuce-core</artifactId><version>5.2.0.RELEASE</version></dependency>
SpringBoot对SpringSession的配置选择
session的存储介质为redis[必选]xxxxxxxxxxspring.session.store-type=redis配置
session的超时时间[可选,默认配置是30分钟] [默认单位是秒,要指定分钟可以指定成如下格式30m]xxxxxxxxxxserver.servlet.session.timeout=30m配置
redis中session的刷新策略[可选]xxxxxxxxxxspring.session.redis.flush-mode=on-save配置
redis中session存储的前缀[可选] [SpringSession创建的缓存也和使用SpringCache创建的缓存一样会创建相应的目录来管理]xxxxxxxxxxspring.session.redis.namespace=spring:session
SpringBoot配置Redis的连接信息这个一般在项目中使用
Redis就会主动配置
xxxxxxxxxxspring.redis.host = localhost #redis服务器主机IP地址spring.redis.password = xxxx #redis服务器的登录密码spring.redis.port = 6379 #redis服务器的端口号Servlet容器初始化原理SpringBoot配置好了一个名为SpringSessionRepositoryFilter的组件,该组件实现了Filter接口,相当于该组件具备过滤器的功能,这个SpringSessionRepositoryFilter将原生HttpSession替换成我们Spring的自定义的session实现,在该实现中
配置组件
xxxxxxxxxxpublic class Config {public LettuceConnectionFactory connectionFactory(){return new LettuceConnectionFactory();}}组件
RedisConnectionFactory已经被SpringBoot自动注入到IoC容器中,我们只需要在配置类或者启动类上添加注解
@EnableRedisHttpSession开启整合Redis作为session存储的功能
卧槽这么牛皮,
Spring用自定义session取代了原来Tomcat自带的HttpSession,我们原来操作session都是直接在控制器方法的参数列表指定HttpSession,Spring容器自动进行注入tomcat原生的HttpSession,我们使用Tomcat原生的HttpSession的API来操作Session,现在Spring使用自定义的SpringSessionRepositoryFilter来替换Tomcat原生的HttpSession,我们在控制器方法注入HttpSession时会自动注入SpringSessionRepositoryFilter,而且SpringSessionRepositoryFilter操作session的api和HttpSession是一样的,这意味着我们可以不需要更改代码只需要配置SpringSession就能丝滑使用SpringSession替代Tomcat的原生HttpSession,原来对session的操作一样生效,只是更换了方法的具体实现,把session存到redis中去了,下发cookie的时候也将对应的作用域设置为了顶级域名,这个就是Java中多态的思想,猜测HttpSession是一个接口,Tomcat的原生HttpSession只是其中一个实现类经过确认,确实如此,
javax.servlet.http.HttpSession是tomcat-embed-core:9.0.24中的包下的一个接口,下面有多个实现类,Tomcat默认使用的是StandardSession
做完以上的步骤,在执行操作
session的方法时仍然会报错SerializationException,原因是在执行session操作的时候无法进行序列化,这是因为我们要操作一个对象,将对象从当前服务器内存中保存到第三方存储介质中,这个过程涉及到IO过程,暂时认为所有的IO过程都要对内存中的对象进行序列化后才能传输,序列化的目的是将一个内存中的对象序列化为二进制流或者串,我这里先肤浅地认为只有二进制流或者串才能执行IO操作,具体的原理以前讲的很浅,后面看JavaIO中有没有补充核心就是要使用
SpringSession操作的数据因为要存储到第三方公共存储介质中,需要被操作的数据能够被序列化,SpringSession默认使用JDK序列化,JDK的默认序列化需要被序列化的对象对应的类实现序列化接口才能将对应的对象进行序列化注意
RedisTemplate的序列化实现好像使用的是注入序列化器来对缓存的数据专门进行序列化,那个好像没有专门要求被缓存的数据需要实现序列化接口
xxxxxxxxxxpackage com.earl.common.vo;import lombok.Data;import java.io.Serializable;import java.util.Date;/*** @author Earl* @version 1.0.0* @描述 用户基础信息* @创建日期 2024/10/17* @since 1.0.0*/public class UserBaseInfoVo implements Serializable {/*** id*/private Long id;/*** 会员等级id*/private Long levelId;/*** 用户名*/private String username;/*** 昵称*/private String nickname;/*** 头像*/private String header;/*** 性别*/private Integer gender;/*** 个性签名*/private String sign;/*** 积分*/private Integer integration;/*** 成长值*/private Integer growth;/*** 注册时间*/private Date createTime;}
SpringSession在第一次执行session操作后,会给客户端下发一个名为SESSION的cookie,该SESSION令牌会替代原来的JSESSIONID令牌注意默认情况下,
SpringSession设置的作用域也是当前二级域名;同时,跨服务使用
SpringSession基于Redis来共享session,两个服务都需要引入spring-session-data-redis❓:我们在
mall-auth和mall-product两个服务都引入spring-session-data-redis,并将在mall-auth即请求域名为auth.earlmall.com下发的cookie的作用域手动改成earlmall.com,但是此时我们在mall-product中获取mall-auth存入的session数据仍然报错SerializationException,🔑:经过分析,这是因为我们在
mall-product中要从redis中获取被序列化的数据,并且要将该数据反序列化为对象,结果在反序列化的过程中在mall-product中找不到数据对应的类,即SerializationException是由ClassNotFoundException导致的,因此需要在分布式集群中进行session共享的类最好放在common包下;同时数据对象在被序列化的时候,会在序列化结果中保存序列化前的对象对应的全限定类名,因此直接将对应的类向使用
session数据的目标服务拷贝一份也是不行的,因为全限定类名不同,直接放在common包下最保险,而且缓存中的全限定类名与实际类名不同,反序列化也会失败,实体类的全限定类名发生了变化一定要清空缓存
❓:目前使用
SpringSession基于公共第三方Redis存储session数据解决了session跨服务共享的问题,但是目前存在两个问题,第一个问题是下发cookie的作用域仍然是对应下发cookie请求的二级域名,无法解决子域session共享问题,第二个问题是SpringSession默认使用的是JDK自带的序列化器,我们希望能够使用字符串序列化器将对象序列化为json对象存储在Redis中,这样也方便我们自己查看一些出问题的session数据🔑:我们可以通过自定义
SpringSession来解决该问题
自定义SpringSession
主要是配置
JSON序列化器和修改下发cookie的作用域使用
JSON序列化器来序列化存储的数据的快速使用文档参考章节Samples and Guides示例和向导中的HttpSession with Redis JSON serialization,查看配置文件发现没有多余的配置,给的代码中的SessionConfig.java是SpringSession使用JSON序列化器的相关配置更改下发
cookie的作用域需要使用CookieSerializer,相关的参考文档在spring官网--Projects--SpringSession--Learn--API Documentation的最后一个Using CookieSerializer,这个文档有点东西啊,唉,怎么这么累啊;改作用域相当于需要自定义cookie,通过暴露CookieSerializer作为容器组件,这里没讲清楚CookieSerializer系列化器与设置cookie参数的关系,先记着吧,迟早要读文档的
SessionConfig.java通过给容器中注入
RedisSerializer替换掉SpringSession默认的序列化机制就能把原来使用JDK默认的序列化器换成JSON序列化器使用了自定义
JSON序列化器,不使用JDK默认的序列化器,实体类可以无需实现Serializable接口
xxxxxxxxxx/* * Copyright 2014-2019 the original author or authors. * * Licensed under the Apache License, Version 2.0 (the "License"); * you may not use this file except in compliance with the License. * You may obtain a copy of the License at * * https://www.apache.org/licenses/LICENSE-2.0 * * Unless required by applicable law or agreed to in writing, software * distributed under the License is distributed on an "AS IS" BASIS, * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. * See the License for the specific language governing permissions and * limitations under the License. */
package sample.config;
import com.fasterxml.jackson.databind.ObjectMapper;import org.springframework.beans.factory.BeanClassLoaderAware;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;import org.springframework.data.redis.serializer.GenericJackson2JsonRedisSerializer;import org.springframework.data.redis.serializer.RedisSerializer;import org.springframework.security.jackson2.SecurityJackson2Modules;
/** * @author jitendra on 3/3/16. */// tag::class[]public class SessionConfig implements BeanClassLoaderAware {
private ClassLoader loader;
public RedisSerializer<Object> springSessionDefaultRedisSerializer() { return new GenericJackson2JsonRedisSerializer(objectMapper()); }
/** * Customized {@link ObjectMapper} to add mix-in for class that doesn't have default * constructors * @return the {@link ObjectMapper} to use */ private ObjectMapper objectMapper() { ObjectMapper mapper = new ObjectMapper(); mapper.registerModules(SecurityJackson2Modules.getModules(this.loader)); return mapper; }
/* * @see * org.springframework.beans.factory.BeanClassLoaderAware#setBeanClassLoader(java.lang * .ClassLoader) */ public void setBeanClassLoader(ClassLoader classLoader) { this.loader = classLoader; }
}// end::class[]实际上雷神没有像上面一样配置的这么麻烦,下面是雷神配置示例
弹幕说:序列化不生效的注意,新版本需要将bean的方法名改为
springSessionDefaultRedisSerializer
xxxxxxxxxxpublic class EarlmallSessionConfig{public RedisSerializer<Object> springSessionDefaultRedisSerializer() {return new GenericJackson2JsonRedisSerializer();}}
配置
CookieSerializer配置
cookie的最大有效时间[默认配置是Session,即浏览器一关cookie就失效]xxxxxxxxxxcookieSerializer.setCookieMaxAge(int cookieMaxAge)配置
cookie的作用域为顶级域名[默认配置是二级域名,我们手动扩大这个作用域来实现session跨域共享]xxxxxxxxxxserializer.setDomainNamePattern("^.+?\\.(\\w+\\.[a-z]+)$");配置第一次使用
session默认下发cookie的名字xxxxxxxxxxserializer.setCookieName("JSESSIONID");这个待补充
xxxxxxxxxxserializer.setCookiePath("/");
配置示例
SpringSession基于Redis的配置比较麻烦啊,因为SpringSession要使用Redis,但是有些服务不需要使用Redis。所以需要使用Session数据的服务就需要搭建SpringSession和Redis的环境,如果直接配置在Common包下也会显得比较臃肿
xxxxxxxxxxpublic class EarlmallSessionConfig{public CookieSerializer cookieSerializer() {DefaultCookieSerializer cookieSerializer = new DefaultCookieSerializer();cookieSerializer.setCookieName("EARLSESSIONID");cookieSerializer.setDomainNamePattern("earlmall.com");return cookieSerializer;}public RedisSerializer<Object> springSessionDefaultRedisSerializer() {return new GenericJackson2JsonRedisSerializer();}}
SpringSession核心原理
@EnableRedisHttpSession的原理使用
SpringSession除了能非侵入性实现分布式跨服务跨域session共享外还考虑了很多边缘问题,比如只要session中的数据被使用了就会自动为session中对应的数据自动续期
@EnableRedisHttpSession注意:在
spring-session 2.2.1版本的时候,放入的不是RedisOperationsSessionRepository了,而是RedisIndexedSessionRepository核心原理是
@EnableRedisHttpSession注解导入配置类RedisHttpSessionConfiguration,该配置类给IoC容器中注入了一个基于Redis增删改查session的持久化层组件RedisOperationsSessionRepository,该配置类还继承自类SpringHttpSessionConfiguration,在该父配置类中给容器注入了一个SessionRepositoryFilter即session存储过滤器,该组件的父类OncePerRequestFilter实现了Filter接口,该session存储过滤器在构造完成时就会将RedisOperationsSessionRepository注入成为属性完成初始化,通过父类OncePerRequestFilter实现的doFilter()方法调用SessionRepositoryFilter自己实现的doFilterInterval()方法,在该方法中即前置过滤器链中将RedisOperationsSessionRepository放到本次请求的请求域中,并将原生的HttpServletRequest和HttpServletResponse和应用上下文ServletContext包装成相应的请求包装类SessionRepositoryFilter<S>.SessionRepositoryRequestWrapper和响应包装类SessionRepositoryFilter.SessionRepositoryResponseWrapper,并在放行过滤器链的filterChain.doFilter(wrappedRequest, wrappedResponse);方法中传参对应的请求和响应包装类,即后续的过滤器链和业务方法都是处理的请求和响应的包装类,我们在控制器方法中获取的HttpSession组件本质是Spring通过httpServletRequest.getSession()方法获取的session对象,当我们使用SpringSession并使用注解@EnableRedisHttpSession开启SpringSession功能后就在前置过滤器链中将原生的HttpServletRequest替换成了同样实现了HttpServletRequest接口的包装类SessionRepositoryFilter<S>.SessionRepositoryRequestWrapper,实际上调用的getSession方法是包装类实现的,在该方法中通过持久化层组件RedisOperationsSessionRepository来实现对session的基于Redis的持久化操作并最终得到session对象持久化层
SessionRepository也是一个接口,我们使用的第三方存储介质是redis,而且导入的是基于redis的SpringSession场景启动器spring-session-data-redis,因此默认使用的是子接口FindByIndexNameSessionRepository下的唯一实现类RedisOperationsSessionRepository,此外还有直接实现类MapSessionRepository使用内存来保存session;此外如果我们导入基于JDBC的SpringSession场景启动器还可以使用数据库来保存session,如果导入基于MongoDB的SpringSession场景启动器我们也可以使用MongoDB来保存session,也会有相应的数据库持久层以上原理就是典型的装饰者模式的应用,实现代码的非侵入性修改
xxxxxxxxxx(RetentionPolicy.RUNTIME)({ElementType.TYPE})({RedisHttpSessionConfiguration.class})//1️⃣ @EnableRedisHttpSession注解为容器导入了配置类RedisHttpSessionConfigurationpublic @interface EnableRedisHttpSession {int maxInactiveIntervalInSeconds() default 1800;String redisNamespace() default "spring:session";RedisFlushMode redisFlushMode() default RedisFlushMode.ON_SAVE;String cleanupCron() default "0 * * * * *";}1️⃣public class RedisHttpSessionConfiguration extends SpringHttpSessionConfiguration implements BeanClassLoaderAware, EmbeddedValueResolverAware, ImportAware, SchedulingConfigurer {//1️⃣-1️⃣ 配置类RedisHttpSessionConfiguration继承了SpringHttpSessionConfiguration...//向容器中添加组件RedisOperationsSessionRepository,这个组件从名字上能看出是基于Redis操作Session的数据化持久层,相当于基于Redis操作session的DAO,这个就是session增删改查的封装类,这里面定义了大量类似于getSession获取session,findById查找session,deleteById删除session的操作redis的大量增删改查方法public RedisOperationsSessionRepository sessionRepository() {RedisTemplate<Object, Object> redisTemplate = this.createRedisTemplate();RedisOperationsSessionRepository sessionRepository = new RedisOperationsSessionRepository(redisTemplate);sessionRepository.setApplicationEventPublisher(this.applicationEventPublisher);if (this.defaultRedisSerializer != null) {sessionRepository.setDefaultSerializer(this.defaultRedisSerializer);}sessionRepository.setDefaultMaxInactiveInterval(this.maxInactiveIntervalInSeconds);if (StringUtils.hasText(this.redisNamespace)) {sessionRepository.setRedisKeyNamespace(this.redisNamespace);}sessionRepository.setRedisFlushMode(this.redisFlushMode);int database = this.resolveDatabase();sessionRepository.setDatabase(database);return sessionRepository;}...}1️⃣-1️⃣public class SpringHttpSessionConfiguration implements ApplicationContextAware {...//该@PostConstruct注解的意思是只要类SpringHttpSessionConfiguration调用构造方法实例化以后就会立即执行该方法,该方法的作用是初始化cookieSerializer对象,如果我们自定义了cookieSerializer就使用我们自定义的,如果没有自定义就使用默认的CookieSerializerpublic void init() {CookieSerializer cookieSerializer = this.cookieSerializer != null ? this.cookieSerializer : this.createDefaultCookieSerializer();this.defaultHttpSessionIdResolver.setCookieSerializer(cookieSerializer);}//SessionEventHttpSessionListenerAdapter是监听器,监听session相关的各种事件,比如服务器停机session的序列化和反序列化public SessionEventHttpSessionListenerAdapter sessionEventHttpSessionListenerAdapter() {return new SessionEventHttpSessionListenerAdapter(this.httpSessionListeners);}//1️⃣-1️⃣-1️⃣ 给容器中注入一个SessionRepositoryFilter即session存储过滤器,该过滤器实现了Servlet中的Filter接口,每个请求都会经过该过滤器进行相应请求处理public <S extends Session> SessionRepositoryFilter<? extends Session> springSessionRepositoryFilter(SessionRepository<S> sessionRepository) {SessionRepositoryFilter<S> sessionRepositoryFilter = new SessionRepositoryFilter(sessionRepository);sessionRepositoryFilter.setServletContext(this.servletContext);sessionRepositoryFilter.setHttpSessionIdResolver(this.httpSessionIdResolver);return sessionRepositoryFilter;}...}1️⃣-1️⃣-1️⃣(-2147483598)//SessionRepositoryFilter继承了OncePerRequestFilter,OncePerRequestFilter实现了Filter接口,在OncePerRequestFilter中实现的doFilter方法中调用了抽象方法doFilterInternal,该方法被子类SessionRepositoryFilter实现,SpringSession的核心就是这个doFilterInternal方法public class SessionRepositoryFilter<S extends Session> extends OncePerRequestFilter {...public SessionRepositoryFilter(SessionRepository<S> sessionRepository) {//sessionRepositoryFilter在构造的时候就自动注入上述操作session的持久化组件RedisOperationsSessionRepositoryif (sessionRepository == null) {throw new IllegalArgumentException("sessionRepository cannot be null");} else {this.sessionRepository = sessionRepository;}}...//SpringSession的核心原理就是该方法,即SessionRepositoryFilter中的doFilterInternal方法protected void doFilterInternal(HttpServletRequest request, HttpServletResponse response, FilterChain filterChain) throws ServletException, IOException {request.setAttribute(SESSION_REPOSITORY_ATTR, this.sessionRepository);//给请求域中存放操作session的持久层组件sessionRepository即此前的RedisOperationsSessionRepository,给请求域存在的数据可以在当次请求处理期间被到处共享SessionRepositoryFilter<S>.SessionRepositoryRequestWrapper wrappedRequest = new SessionRepositoryFilter.SessionRepositoryRequestWrapper(request, response, this.servletContext);//将原生的请求、响应和servlet应用上下文包装成SessionRepositoryFilter<S>.SessionRepositoryRequestWrapper即一个包装请求对象,这是一个典型的装饰者模式SessionRepositoryFilter.SessionRepositoryResponseWrapper wrappedResponse = new SessionRepositoryFilter.SessionRepositoryResponseWrapper(wrappedRequest, response);//将包装后的请求对象和原生的响应对象包装成一个包装响应对象SessionRepositoryFilter.SessionRepositoryResponseWrappertry {filterChain.doFilter(wrappedRequest, wrappedResponse);//1️⃣-1️⃣-1️⃣-1️⃣ 特别注意此处调用filterChain的doFilter方法放行的时候,传参不是原生的request和response,而是包装过的包装请求对象wrappedRequest和包装响应对象,整个过滤器链执行到此处,此前的过滤器链都是对原生的请求和响应进行处理,而后面的过滤器链包括业务方法都是对包装后的请求和响应进行处理,即将包装后的请求和响应对象全部应用到了整个执行链,这里直接跳过中间过程到控制器方法对包装请求和响应的处理} finally {wrappedRequest.commitSession();}}...private final class SessionRepositoryRequestWrapper extends HttpServletRequestWrapper {...private final class SessionCommittingRequestDispatcher implements RequestDispatcher {...}private final class HttpSessionWrapper extends HttpSessionAdapter<S> {...}}private final class SessionRepositoryResponseWrapper extends OnCommittedResponseWrapper {...}}1️⃣-1️⃣-1️⃣-1️⃣("/weibo/success")public String weiboAuthSuccessThen(String code,HttpSession session,RedirectAttributes attributes,HttpServletRequest request){//实际上Spring向控制器方法中自动注入的HttpSession就是httpServletRequest.getSession(),即我们要获取session就会从请求中去获取session,但是我们的请求已经在过滤器链中被包装成了SessionRepositoryFilter<S>.SessionRepositoryRequestWrapper,因此Spring在使用SpringSession的情况下调用request.getSession()获取session实际上调用的包装类SessionRepositoryFilter<S>.SessionRepositoryRequestWrapper的getSession方法try {UserBaseInfoVo user = authService.weiboAuthSuccessThen(code);HttpSession session1 = request.getSession();//1️⃣-1️⃣-1️⃣-1️⃣-1️⃣ 这里在使用SpringSession的时候实际调用的是wrappedRequest.getSession()session.setAttribute("user",user);return "redirect:http://earlmall.com";}catch (RRException e){attributes.addFlashAttribute("error",e.getCode()+":"+e.getMsg());return "redirect:http://auth.earlmall.com/login.html";}}1️⃣-1️⃣-1️⃣-1️⃣-1️⃣private final class SessionRepositoryRequestWrapper extends HttpServletRequestWrapper {//SessionRepositoryRequestWrapper继承了HttpServletRequestWrapper,HttpServletRequestWrapper实现了HttpServletRequest...//这个就是SessionRepositoryRequestWrapper的getSession方法,public SessionRepositoryFilter<S>.SessionRepositoryRequestWrapper.HttpSessionWrapper getSession(boolean create) {SessionRepositoryFilter<S>.SessionRepositoryRequestWrapper.HttpSessionWrapper currentSession = this.getCurrentSession();//先通过getCurrentSession()获取当前的session即currentSession,如果能获取到则直接返回,猜测这里是懒惰初始化,第一次使用的时候创建对应的对象if (currentSession != null) {return currentSession;} else {//如果此前没有创建过session,即currentSession获取不到,则会调用getRequestedSession()方法S requestedSession = this.getRequestedSession();if (requestedSession != null) {if (this.getAttribute(SessionRepositoryFilter.INVALID_SESSION_ID_ATTR) == null) {requestedSession.setLastAccessedTime(Instant.now());this.requestedSessionIdValid = true;currentSession = new SessionRepositoryFilter.SessionRepositoryRequestWrapper.HttpSessionWrapper(requestedSession, this.getServletContext());currentSession.setNew(false);this.setCurrentSession(currentSession);return currentSession;}} else {if (SessionRepositoryFilter.SESSION_LOGGER.isDebugEnabled()) {SessionRepositoryFilter.SESSION_LOGGER.debug("No session found by id: Caching result for getSession(false) for this HttpServletRequest.");}this.setAttribute(SessionRepositoryFilter.INVALID_SESSION_ID_ATTR, "true");}if (!create) {return null;} else {if (SessionRepositoryFilter.SESSION_LOGGER.isDebugEnabled()) {SessionRepositoryFilter.SESSION_LOGGER.debug("A new session was created. To help you troubleshoot where the session was created we provided a StackTrace (this is not an error). You can prevent this from appearing by disabling DEBUG logging for " + SessionRepositoryFilter.SESSION_LOGGER_NAME, new RuntimeException("For debugging purposes only (not an error)"));}S session = SessionRepositoryFilter.this.sessionRepository.createSession();session.setLastAccessedTime(Instant.now());currentSession = new SessionRepositoryFilter.SessionRepositoryRequestWrapper.HttpSessionWrapper(session, this.getServletContext());this.setCurrentSession(currentSession);return currentSession;}}}...private S getRequestedSession() {if (!this.requestedSessionCached) {List<String> sessionIds = SessionRepositoryFilter.this.httpSessionIdResolver.resolveSessionIds(this);Iterator var2 = sessionIds.iterator();while(var2.hasNext()) {String sessionId = (String)var2.next();if (this.requestedSessionId == null) {this.requestedSessionId = sessionId;}S session = SessionRepositoryFilter.this.sessionRepository.findById(sessionId);//这里调用sessionRepository即RedisOperationsSessionRepository,因此SpringSession对session的增删改查全部是通过Redis完成的if (session != null) {this.requestedSession = session;this.requestedSessionId = sessionId;break;}}this.requestedSessionCached = true;}return this.requestedSession;}...}
购物车服务
服务集成
Spring Boot DevTools、Lombok、Spring Web、Thymeleaf、OpenFeign将所有的购物车服务放在三级域名
cart.earlmall.com下,将购物车的静态资源和两个页面整合到项目中,配置好动静分离配置端口号,服务名、配置配置中心,注册中心,排除数据库的自动配置[因为Common服务中引入了],开启Feign的远程服务调用功能
Template目录下的index.html就是/的默认映射视图,无需额外配置视图映射,配置网关,如果网关配置正确,访问http://cart.earlmall.com/会自动跳转购物车服务
页面跳转
前端页面完善
点击商城图标和首页图标能跳转到商城首页
购物车需求分析
商品添加购物车成功,即使用户没有登录购物车也有相应的商品,浏览器关闭再打开购物车中的内容仍然保留,即离线或者游客购物车功能
不同的浏览器的离线购物车的商品不同,只要用户登录两个浏览器上的商城就会取两个离线购物车的并集作为登录用户的购物车商品列表,此时用户再次退出一个浏览器的登录离线购物车的商品会清空
京东的购物车在对两个购物车进行操作,
用户在登录状态下操作用户购物车/在线购物车,
最大特点是登录以后会将临时购物车的数据全部合并到用户购物车并清空临时购物车
用户购物车数据只要存在就会一直存在,适合使用
mysql进行存储,但是因为购物车的操作是一个读写高并发操作,如果直接对数据库操作,数据库会存在很高的压力,购物车里面存储的都是文档数据[一个个对象],我们可以使用一个NOSQL数据库MongoDB,性能比SQL数据库稍微强一些,但是性能相比于数据库不会有特别大的提升Redis,Redis也是NOSQL数据结构内存库,数据结构好组织,Redis拥有极高的读写并发性能,我们在安装Redis的时候可以指定Redis的持久化策略来避免Redis因为宕机导致的数据丢失,虽然会损失一定的性能,但是性能仍然比Mysql高很多
用户在未登录状态下操作游客购物车/离线购物车/离线购物车
最大特点是浏览器即使关闭,下次再进入浏览器,临时购物车的数据也还在
临时购物车的存储介质有以下几种
LocalStorage:LocalStorage是浏览器技术,客户端所有添加的购物车数据我们都可以让浏览器自己的LocalStorage保存,除非浏览器卸载,否则该数据会一直存在,相当于客户端存储,浏览器不存储,优点是后台压力小,缺点是在大数据背景下我们需要用户的购物车数据来实现即使在用户没有登录的情况下也要根据用户的离线购物车数据来分析推荐一些个性化商品来促销,因此我们趋向于将有价值的数据都存储在后端方便随时用大数据进行分析Redis:基于大数据分析需求,我们仍然决定将离线购物车的数据放在Redis中
购物车功能分析
要能查询当前用户的购物车商品
给购物车添加商品
更改购物车的某个商品数量
删除购物车里的商品
是否选中商品
展示购物车的商品优惠信息
提示购物车的商品价格变化,比如购物车商品降价
后端
Redis商品文档数据结构分析购物车的每个商品的就称为一个购物项
我们给购物车添加的每个购物项都添加的是
sku信息
购物项的字段包含
skuId商品默认图片
商品名字
商品的销售属性
商品的销售属性可能展示多个属性,需要封装成
List<String>集合
商品单价
价格使用
BigDecimal
商品数量
一个商品的总价
这个总价是根据商品单价和商品数量计算出来的,通过
Setter方法计算,因此这个类需要全部自定义getter和setterbigDecimal.multiply(new BigDecimal(""+this.count))是BigDecimal总价的计算方式bigDecimal.add(bigDecimal)是BigDecimal类型的加法bigDecimal.subtract(bigDecimal)是BigDecimal类型的减法
有优惠要计算商品优惠下的总价
商品的选中状态
当浏览器关闭再打开仍要能显示商品的选中状态
商品销售属性对象
skuSaleVO
购物车中的购物项不止一条数据,需要使用一个
json格式的数组组织所有数据
Redis数据结构分析每个用户有至少两个购物车,一个是临时购物车,一个是用户购物车[没有考虑浏览器多开离线购物车]
每个购物车我们可以对应
Redis中一个List集合数据类型,以cart:用户标识作为指定用户购物车数据,以单条json数据作为一个购物项目前第一个问题,如果快速定位和修改某一条购物项,即快速找到某个购物项对应的文档数据
List底层的数据结构是一个快速链表
quickList,列表元素较少是使用连续的内存存储,该结构式ziplist,即压缩列表,分配的是连续内存,元素多起来将多个ziplist组合成双向链表的形式,因为普通链表的形式每个节点还带额外prev和next属性,很浪费空间,同时查询效率比较低;而且使用List集合一旦要更改某个购物项的数据,我们需要遍历整个购物车匹配对应的购物项,浪费性能因此为了快速检索来做修改,我们使用Hash数据类型来替换List数据类型,我们让Hash的key定义为
cart:用户标识,field保存购物项的skuId,value存储单条购物项文档数据;这样我们要修改某一条数据,我们可以直接拿着用户标识和被修改的商品的skuId直接找到对应的文档记录直接修改,无需再遍历匹配
最终
Redis中存储所有购物车的数据结构对应Java为Map<String k1,Map<String k2,CartItemInfo>>,其中k1为用户标识,k2为每个购物项的skuId我们将所有的购物车数据都存入一个
Hash,filed保存用户的标识,value保存一个Hash,value中的field保存购物项的skuId,value保存购物项
Java数据封装
[购物项封装]
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 购物项* @创建日期 2024/10/25* @since 1.0.0*/public class CartItem {/*** 商品的skuId*/private Long skuId;/*** 购物车中的被选中状态*/private Boolean selected;/*** 商品的名字*/private String skuName;/*** 商品的默认图片*/private String skuDefaultImage;/*** 商品销售属性列表*/private List<String> skuAttrValues;/*** 商品单价*/private BigDecimal unitPrice;/*** 商品数量*/private Integer goodsNum = 0;/*** 商品总价*/private BigDecimal totalPrice;public Long getSkuId() {return skuId;}public void setSkuId(Long skuId) {this.skuId = skuId;}public Boolean getSelected() {return selected;}public void setSelected(Boolean selected) {this.selected = selected;}public String getSkuName() {return skuName;}public void setSkuName(String skuName) {this.skuName = skuName;}public String getSkuDefaultImage() {return skuDefaultImage;}public void setSkuDefaultImage(String skuDefaultImage) {this.skuDefaultImage = skuDefaultImage;}public List<String> getSkuAttrValues() {return skuAttrValues;}public void setSkuAttrValues(List<String> skuAttrValues) {this.skuAttrValues = skuAttrValues;}public BigDecimal getUnitPrice() {return unitPrice;}public void setUnitPrice(BigDecimal unitPrice) {this.unitPrice = unitPrice;}public Integer getGoodsNum() {return goodsNum;}public void setGoodsNum(Integer goodsNum) {this.goodsNum = goodsNum;}public BigDecimal getTotalPrice() {return unitPrice.multiply(new BigDecimal(""+goodsNum));}}[购物车封装类]
items是所有的购物项
List<CartItem>商品种数
countType,不是商品数量商品数量
countNum,商品数量购物车选中商品总价
totalPrice,总价默认为0,通过计算得到选中商品减免价格
reducePrice,减免价格默认设置为0所有的字段信息都需要先进行计算才能得到,因此也需要自己定义
setter和getter
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 购物车* @创建日期 2024/10/25* @since 1.0.0*/public class Cart {/*** 购物项*/private List<CartItem> items;/*** 商品种类计数*/private Integer countType;/*** 商品数量计数*/private Integer countNum;/*** 被选中商品数量*/private Integer countSelectedNum;/*** 被选中商品总价*/private BigDecimal totalPrice ;/*** 折扣价格*/private BigDecimal reducePrice = new BigDecimal("0.00") ;public List<CartItem> getItems() {return items;}public void setItems(List<CartItem> items) {this.items = items;}public Integer getCountType() {return items.size();}public Integer getCountNum() {countNum=0;if(items!=null && items.size()>0){for(CartItem item: items){countNum+=item.getPurchaseQuantity();}}return countNum;}public Integer getCountSelectedNum(){countSelectedNum=0;if(items!=null && items.size()>0){for(CartItem item: items){if(item.getSelected()){countNum+=item.getPurchaseQuantity();}}}return countNum;}public BigDecimal getTotalPrice() {totalPrice=new BigDecimal("0");//计算购物车总价if(items!=null && items.size()>0){for(CartItem item: items){if(item.getSelected()){totalPrice.add(item.getTotalPrice());}}}//减去优惠总价totalPrice.subtract(getReducePrice());return totalPrice;}public BigDecimal getReducePrice() {return reducePrice;}public void setReducePrice(BigDecimal reducePrice) {this.reducePrice = reducePrice;}}在
cart服务中引入redis的依赖线上一般都是专门一个
redis负责购物车,这里先不管,看后面运维篇会不会更改整合
SpringSession来获取session中的用户信息
提供跳转购物车列表页的接口,即
cartList.html处理用户登录状态
根据用户登录状态判断是获取临时购物车数据还是用户购物车数据
临时购物车的保持,京东的做法是给浏览器下发一个名为
user-key的cookie,有效时间一个月,通过该cookie来识别用户的浏览器,如果用户没有该cookie,第一次访问购物车就会下发一个该cookie,只要该cookie被删除了,离线购物车的数据就找不到了,我们可以学习京东的做法,用户如果没有登录就点击购物车给浏览器下发一个有效时间一个月名为user-key的cookie来标识用户身份,为此我们定义cookie的逻辑如下如果用户已经登录,
session中有用户信息,我们为用户提供用户购物车如果用户没有登录,用户第一次访问购物车我们给用户下发一个有效时间一个月的名为
user-key的cookie来标识用户身份,只要用户没有登录我们就根据user-key给用户分配一个临时购物车为了实现判断用户的登录状态,我们编写一个拦截器来实现上述功能
使用一个数据传输类
UserInfoTo来封装用户的userId、userKey、tempUser信息,分别封装用户登录状态的userId、用户的临时身份标识、请求中是否携带名为user-key的cookie[如果有就不再给客户端下发cookie,该字段作为是否给客户端下发cookie的标识,避免每次请求都更新客户端名为user-key的cookie]
[拦截器]
拦截器是一个组件,需要标注
@Component注解,同时该组件必须实现HandlerInterceptor接口过滤器基于函数回调、拦截器基于反射、AOP基于动态代理
这里使用拦截器是因为购物车的功能都要判断用户的登录状态,因此对通过购物车的所有请求都要对登录状态进行判断,所以设置成拦截器,感觉设置成过滤器一样好使
拦截器需要实现
HandlerInterceptor接口的以下方法preHandle(HttpServletRequest request,HttpServletResponse response,Object handler)方法,该方法的执行时机是在控制器方法执行之前,该方法返回true就是放行当前请求,该方法返回false就是拦截不放行当前请求拦截器业务逻辑为从
session中获取用户数据,如果用户数据不为null,设置用户id作为传输类UserInfoTo的UserId字段通过
request.getCookies()从用户请求中获取全部的cookie信息,如果有cookie信息就遍历cookie,将名为user-key的cookie设置到userInfoTo的userKey属性中即能获取到用户登录信息就设置用户id,如果请求
cookie中携带了名为user-key的cookie就将该cookie值放在userInfoTo中,处理完全部放行去控制器方法
如果用户是第一次点击购物车,此时还没有登录,cookie中也没有携带名为
user-key的cookie,此时我们就要为服务器下发一个名为user-key的cookie,使用UUID来作为cookie的值,在控制器方法执行前我们生成一个临时用户身份设置到userInfoTo的userKey属性中
postHandle(HttpServletRequest request,HttpServletResponse response,Object handler)方法,该方法的执行时机是控制器方法执行之后,我们从
userInfoTo中获取userKey属性并使用response.addCookie(cookie)为浏览器下发标识临时用户身份的名为user-key的cookie,cookie的作用域设置为顶级域名cookie.setDomain(String domain),cookie的有效时间设置为cookie.setMaxAge(int expiry)该方法默认以秒作为单位注意
ThreadLocal用完需要调用threadLocal.remove()进行清空,老师没有清空
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 用户状态判断拦截器,购物车服务需要判断用户的登录状态* @创建日期 2024/10/25* @since 1.0.0*/public class UserStatusInterceptor implements HandlerInterceptor {public static ThreadLocal<UserInfoTo> threadLocal=new ThreadLocal<>();/*** @param request* @param response* @param handler* @return boolean* @描述 从session中获取用户数据,如果用户数据存在,封装用户的id信息* @author Earl* @version 1.0.0* @创建日期 2024/10/25* @since 1.0.0*/public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {UserInfoTo userInfo = new UserInfoTo();UserBaseInfoVo userBaseInfo = (UserBaseInfoVo)request.getSession().getAttribute(MallConstant.SESSION_USER_LOGIN_STATUS_KEY);if(userBaseInfo!=null){userInfo.setUserId(userBaseInfo.getId());}Cookie[] cookies = request.getCookies();if(cookies!=null && cookies.length>0){for (Cookie cookie : cookies) {if(CartConstant.USER_TEMP_IDENTITY.equals(cookie.getName())){userInfo.setUserKey(cookie.getValue());userInfo.setTempUser(true);}}}if(!userInfo.getTempUser()){userInfo.setUserKey(UUID.randomUUID().toString());}threadLocal.set(userInfo);return true;}/*** @param request* @param response* @param handler* @param modelAndView* @描述 如果cookie中没有名为user-key的cookie就添加该cookie* @author Earl* @version 1.0.0* @创建日期 2024/10/25* @since 1.0.0*/public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) throws Exception {UserInfoTo userInfo = threadLocal.get();if(!userInfo.getTempUser()){response.addCookie(new Cookie(CartConstant.USER_TEMP_IDENTITY,userInfo.getUserKey()));}threadLocal.remove();}}拦截器要工作还必须进行注册,只作为组件放在容器中是不行的,
SpringBoot要给Web服务器添加一些定制化配置可以通过实现WebMvcConfigurer接口,WebMvcConfigurer接口中的addInterceptors(InterceptorRegistry registry)方法向拦截器注册列表中添加拦截器,如果在这里像下面一样创建了拦截器实例就不需要给容器注入相应的拦截器组件了xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 定制化Web服务器配置* @创建日期 2024/10/01* @since 1.0.0*/public class CustomWebMvcConfigurer implements WebMvcConfigurer {/*** @param registry* @描述 配置拦截器* addPathPatterns("/**")是配置拦截器具体拦截的请求路径,这个表示拦截所有请求* @author Earl* @version 1.0.0* @创建日期 2024/10/24* @since 1.0.0*/public void addInterceptors(InterceptorRegistry registry) {registry.addInterceptor(new UserStatusInterceptor()).addPathPatterns("/**");}}
我们希望在控制器方法中快速获取用户信息,包括用户的标识id和用户的user-key的cookie值,我们可以使用JDK给我们提供的
ThreadLocal来实现在同一个线程内共享数据注意
Tomcat每个请求进来,从拦截器--控制器方法--service--dao,从始至终都是同一个线程,我们希望在方法间共享数据就可以使用ThreadLocal,ThreadLocal的核心原理就是一个Map<Thread,Object> threadLocal,即以当前线程作为key,以共享数据作为value,弹幕说这是JDK1.8以前的原理,JDK1.8改成了ThreadLocal作为key,这里可以深入学习一下,老杜以前讲的是前者
我们通过
ThreadLocal<UserInfoTo>来封装用户信息,通过threadLocal.set(userInfoTo)将用户信息放入拦截器的threadLocal静态属性中,注意ThreadLocal是共享的,但是对当前线程的value操作是原子性的,线程之间访问的数据是隔离开的,因此不存在线程并发安全问题,静态属性我们可以直接通过类名.属性来进行调用获取,通过threadLocal.get()方法获取其中共享的用户信息
获取购物车
用户鼠标移动到购物车显示购物项
用户在首页点击我的购物车跳转购物车列表页面,在购物车页面点击首页能跳转到商城首页
前端业务逻辑
用户点击我的购物车跳转购物车列表,展示购物车中的所有购物项,并展示总价等信息,如果用户登录了合并清空临时购物车并展示用户购物车中的所有购物项,如果用户没登录就展示临时购物车中的所有购物项
xxxxxxxxxx<div class="header_gw"><img src="static/index/img/img_15.png"/><span><a href="http://cart.earlmall.com/cart/cartList.html">我的购物车</a></span><span>0</span></div>遍历展示购物车列表前端组件
如果购物车没有商品就展示购物车还没有商品,去购物跳转商城首页
如果购物车有商品就使用
th:each遍历展示所有商品展示商品的选中状态、商品名称、商品销售属性、商品价格[商品价格需要格式化,参考商品详情页的价格格式化]、商品数量、商品总价[需要格式化]、优惠价格[需要格式化]
如果用户没有登录要提示用户登录后会将商品自动同步到用户购物车并给出登录链接
xxxxxxxxxx<div class="One_BdyShop"><div class="OneBdy_box" th:if="${cart==null}"><div class="success-lcol"><br><br><div class="success-top"><b class="succ-icon"></b><h3 class="one_left_link">购物车中无商品</h3></div><br><a href="http://earlmall.com" style="color: red;">去购物</a></div></div><div class="OneBdy_box" th:if="${cart!=null}"><div class="One_tabTop"><div class="One_Topleft"><span>全部商品 </span></div></div><div class="One_ShopTop"><ul><li><input type="checkbox" class="allCheck">全选</li><li>商品</li><li>单价</li><li>数量</li><li>小计</li><li>操作</li></ul></div><div class="One_ShopCon"><ul><li th:each="cartItem:${cart.items}"><div style="height: 2px"></div><div><ol><li><input type="checkbox" th:checked="${cartItem.selected?'ckecked':''}" th:attr="skuId=${cartItem.skuId}" class="check" onchange="checkSku(this)"/></li><li><dt><img th:src="${cartItem.skuDefaultImage}" alt=""></dt><dd><p><span th:each="skuSaleAttr:${cartItem.skuAttrValues}" th:text="${skuSaleAttr}">TCL 55A950C 55英寸32核</span></p><p th:text="${cartItem.skuName}"></p></dd></li><li><p th:text="|¥${#numbers.formatDecimal(cartItem.unitPrice,1,2)}|" class="dj">¥4599.00</p></li><li><p><span>-</span><span th:text="${cartItem.purchaseQuantity}">5</span><span>+</span></p></li><li style="font-weight:bold"><p th:text="|¥${#numbers.formatDecimal(cartItem.totalPrice,1,2)}|" class="zj">¥22995.00</p></li><li><p>删除</p></li></ol></div></li></ul></div><div class="One_ShopFootBuy fix1"><div><ul><li><input type="checkbox" class="allCheck"><span>全选</span></li><li>删除选中的商品</li><li>移到我的关注</li><li>清除下柜商品</li></ul></div><div><font style="color:#e64346;font-weight:bold;" class="sumNum"> </font> <ul><li><img src="/static/cart/img/buyNumleft.png" alt=""></li><li><img src="/static/cart/img/buyNumright.png" alt=""></li></ul></div><div><ol><li>总价:<span style="color:#e64346;font-weight:bold;font-size:16px;"class="fnt"th:text="|¥${cart==null?'0.00':#numbers.formatDecimal(cart.totalPrice,1,2)}|">¥0.00</span></li></ol></div><div><button onclick="toTrade()" type="button">去结算</button></div></div></div></div>
后端业务逻辑
使用拦截器根据
session中是否含有用户信息来判断用户获取的是用户购物车还是离线购物车并封装用户信息xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 用户状态判断拦截器,购物车服务需要判断用户的登录状态* @创建日期 2024/10/25* @since 1.0.0*/public class UserStatusInterceptor implements HandlerInterceptor {public static ThreadLocal<UserInfoTo> threadLocal=new ThreadLocal<>();/*** @param request* @param response* @param handler* @return boolean* @描述 从session中获取用户数据,如果用户数据存在,封装用户的id信息* @author Earl* @version 1.0.0* @创建日期 2024/10/25* @since 1.0.0*/public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {UserInfoTo userInfo = new UserInfoTo();UserBaseInfoVo userBaseInfo = (UserBaseInfoVo)request.getSession().getAttribute(MallConstant.SESSION_USER_LOGIN_STATUS_KEY);if(userBaseInfo!=null){userInfo.setUserId(userBaseInfo.getId());}Cookie[] cookies = request.getCookies();if(cookies!=null && cookies.length>0){for (Cookie cookie : cookies) {if(CartConstant.USER_TEMP_IDENTITY_COOKIE_NAME.equals(cookie.getName())){userInfo.setUserKey(cookie.getValue());userInfo.setCookieExist(true);}}}if(!userInfo.getCookieExist()){userInfo.setUserKey(UUID.randomUUID().toString());}threadLocal.set(userInfo);return true;}/*** @param request* @param response* @param handler* @param modelAndView* @描述 如果cookie中没有名为user-key的cookie就添加该cookie* @author Earl* @version 1.0.0* @创建日期 2024/10/25* @since 1.0.0*/public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) throws Exception {UserInfoTo userInfo = threadLocal.get();if(!userInfo.getCookieExist()){response.addCookie(new Cookie(CartConstant.USER_TEMP_IDENTITY_COOKIE_NAME,userInfo.getUserKey()));}threadLocal.remove();}}如果用户没登录
抽取一个根据
user-key获取临时购物车的方法,并抽取一个根据用户id获取用户购物车的方法通过
List<Object> ---> boundHashOperations.values()获取到该用户临时购物车中的所有购物项遍历所有购物项将购物项封装到购物车中
返回购物车对象
如果用户登录了
判断用户临时购物车中有没有数据,临时购物车有数据就获取临时购物
获取用户购物车数据,将用户购物车与临时购物车的数据合并,如果临时购物车的商品用户购物车已经存在就累加数量,如果用户购物车没有对应的商品就添加新的购物项
更新用户购物车数据、删除临时购物车数据并返回购物车
使用
redisTemplate.delete(String key)就能直接清空购物车,弹幕说不要这么删,key太大会直接卡死,如果当前key下有几百个商品信息,直接删除,会出现阻塞redis的现象,导致其他请求缓存无法访问的情况格式化
(1,2)中的1是小数点前面的保留的最小位数,应该指定为0,这样优惠价格为0的时候会显示为0.00给标题一个宽度,能让标题自动换行,避免标题栏一行过长影响样式
这里的总价和优惠价要注意一定只能计算被选中状态的购物项,不然选中和不选中商品的总价和优惠价格不会发生变化
[控制器方法]
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 购物车控制器* @创建日期 2024/10/25* @since 1.0.0*/("/cart")public class CartController {private CartService cartService;/*** @return {@link String }* @描述 获取购物车列表视图* @author Earl* @version 1.0.0* @创建日期 2024/10/27* @since 1.0.0*/("/cartList.html")public String getCart(Model model){Cart cart = cartService.getCart();model.addAttribute("cart",cart);return "cartList";}}
[业务实现类]
xxxxxxxxxx /** * @author Earl * @version 1.0.0 * @描述 购物车业务实现类 * @创建日期 2024/10/25 * @since 1.0.0 */ ("cartService") public class CartServiceImpl implements CartService { private StringRedisTemplate redisTemplate; /** * @return {@link Cart } * @描述 获取用户的购物车数据,没有购物项返回空,有购物项返回购物车对象 * @author Earl * @version 1.0.0 * @创建日期 2024/10/27 * @since 1.0.0 */ public Cart getCart() { UserInfoTo userInfo = UserStatusInterceptor.threadLocal.get(); List<CartItem> tempCartItems = getCartItem(getTempCartOperation().values()); if(userInfo.getUserId()!=null){ //1. 用户已经登录,合并用户临时购物车,清空临时购物车,封装返回用户购物车 //获取临时购物车 BoundHashOperations<String, Object, Object> cartOperation = getCartOperation(); List<CartItem> userCartItems = getCartItem(cartOperation.values()); Map<Long, CartItem> userCartItemsMap = userCartItems.stream().collect(Collectors.toMap(CartItem::getSkuId, cartItem -> cartItem)); if(tempCartItems==null){ //如果临时购物车为空直接返回用户购物车 return userCartItems==null?null:new Cart(userCartItems); } //如果临时购物车有数据合并临时购物车 Map<String, String> tempCart = tempCartItems.stream().collect(Collectors.toMap( cartItem -> cartItem.getSkuId().toString(), cartItem -> { CartItem userCartItem = userCartItemsMap.get(cartItem.getSkuId()); if (userCartItem != null) { cartItem.setPurchaseQuantity(cartItem.getPurchaseQuantity() + userCartItem.getPurchaseQuantity()); } userCartItemsMap.put(cartItem.getSkuId(),cartItem); return JSON.toJSONString(cartItem); })); cartOperation.putAll(tempCart); redisTemplate.delete(CartConstant.USER_CART_IDENTITY_PREFIX+userInfo.getUserKey()); List<CartItem> cartItems = userCartItemsMap.values().stream().collect(Collectors.toList()); return new Cart(cartItems); } //2. 用户没有登录,封装返回临时购物车 return tempCartItems==null?null:new Cart(tempCartItems); } /** * @param items * @return {@link List }<{@link CartItem }> * @描述 将Redis中查询出来的字符串购物项封装成CartItem集合,方便后续取值 * @author Earl * @version 1.0.0 * @创建日期 2024/10/27 * @since 1.0.0 */ private List<CartItem> getCartItem(List<Object> items){ if(items==null || items.size()==0){ return null; } ArrayList<CartItem> cartItems = new ArrayList<>(); for (Object item : items) { cartItems.add(JSON.parseObject(JSON.parse(JSON.toJSONString(item)).toString(), CartItem.class)); } return cartItems; } /** * @return {@link BoundHashOperations }<{@link String }, {@link Object }, {@link Object }> * @描述 获取用户购物车,如果用户已登录获取用户购物车,如果用户没有登录获取用户临时购物车 * @author Earl * @version 1.0.0 * @创建日期 2024/10/25 * @since 1.0.0 */ private BoundHashOperations<String, Object, Object> getCartOperation(){ UserInfoTo userInfo = UserStatusInterceptor.threadLocal.get(); if(userInfo.getUserId()!=null){ return redisTemplate.boundHashOps(CartConstant.USER_CART_IDENTITY_PREFIX + userInfo.getUserId()); } BoundHashOperations<String, Object, Object> cartOperation = redisTemplate.boundHashOps(CartConstant.USER_CART_IDENTITY_PREFIX + userInfo.getUserKey()); cartOperation.expire(CartConstant.TEMP_CART_EXPIRE, TimeUnit.SECONDS); return cartOperation; } /** * @return {@link BoundHashOperations }<{@link String }, {@link Object }, {@link Object }> * @描述 获取用户的临时购物车 * @author Earl * @version 1.0.0 * @创建日期 2024/10/27 * @since 1.0.0 */ private BoundHashOperations<String, Object, Object> getTempCartOperation(){ UserInfoTo userInfo = UserStatusInterceptor.threadLocal.get(); return redisTemplate.boundHashOps(CartConstant.USER_CART_IDENTITY_PREFIX+userInfo.getUserKey()); } }
添加购物车
在商品详情页点击添加到购物车能将商品添加到购物车中
用户将商品添加到购物车跳转添加购物车成功页面
success.html,成功页面点击首页能跳转过去,去购物车结算按钮是跳转购物车列表页,点击查看商品详情按钮跳转商品详情页
前端业务逻辑
添加商品到购物车入参需要商品的
skuId和商品数量,前端点击添加到购物车设置成超链接,给超链接设置点击事件,使用return false来禁用超链接默认行为,使用location.href来指定超链接跳转的页面商品数量是靠
input标签设置的,我们可以通过$("#goodsNum").val()来获取商品的
skuId可以从视图中获取并设置为该超链接的自定义属性,我们可以通过$(this).attr("skuId")来获取
xxxxxxxxxx<div class="box-btns-two"><a href="#" id="addCart" th:attr="skuId=${skuInfo.skuId}">添加购物车</a></div><script type="text/javascript">$("#addCart").click(function (){location.href="http://cart.earlmall.com/cart/item/add?skuId="+$(this).attr("skuId")+"&purchaseQuantity="+$("#purchaseQuantity").val();return false;});</script>添加购物车成功后端封装商品数据到
success.html视图中将商品数据渲染到
success.html中,比如商品名字,商品图片、商品超链接跳转位置点击商品名称或者点击查看商品详情都会跳转商品详情页
xxxxxxxxxx<div class="mc success-cont" th:if="${cartItem!=null}"><div class="success-lcol"><div class="success-top"><b class="succ-icon"></b><h3 class="ftx-02">商品已成功加入购物车</h3></div><div class="p-item"><div class="p-img"><a href="/javascript:;" target="_blank"><img style="height:60px;width:60px;"th:src="${cartItem.skuDefaultImage}"></a></div><div class="p-info"><div class="p-name"><a th:href="'http://item.earlmall.com/'+${cartItem.skuId}+'.html'" th:text="${cartItem.skuName}">TCL 55A950C 55英寸32核人工智能 HDR曲面超薄4K电视金属机身(枪色)</a></div><div class="p-extra"><span class="txt" th:text="'数量:'+${cartItem.purchaseQuantity}"> 数量:1</span></div></div><div class="clr"></div></div></div><div class="success-btns success-btns-new"><div class="success-ad"><a href="/#none"></a></div><div class="clr"></div><div class="bg_shop"><a class="btn-tobback" th:href="'http://item.earlmall.com/'+${cartItem.skuId}+'.html'">查看商品详情</a><a class="btn-addtocart" href="http://cart.earlmall.com/cartList"id="GotoShoppingCart"><b></b>去购物车结算</a></div></div></div><div class="mc success-cont" th:if="${cartItem==null}"><div class="success-lcol"><div class="success-top"><b class="succ-icon"></b><h3 class="ftx-02">购物车中无该商品</h3></div><a href="http://earlmall.com">去购物</a></div></div>
后端业务逻辑
根据用户登录状态,为购物车指定具体的前缀
earlmall:cart:用户标识id,这个用户标识id如果用户登录了就使用用户的身份id,如果用户没有登录就使用系统为用户下发的cookie即user-key后端使用前缀
redisTemplate.opsForHash().get("earlmall:cart:用户标识id","1"),这样操作比较繁杂,我们使用BoundHashOperations<String,Object,Object> ---> redisTemplate.boundHashOps("earlmall:cart:用户标识id")来绑定一个操作对象和一个用户标识id,返回的操作对象BoundHashOperations<String,Object,Object>都是对key为earlmall:cart:用户标识id的键值对进行操作,这个对象BoundHashOperations<String,Object,Object>是专门对指定key的Hash进行操作的对象boundHashOperations.put(String field,String value)是将field和value放到指定key的Hash中
我们查询商品服务通过
skuId查询对应的SkuInfoEntity我们创建一个购物项,通过查询出来的
SkuInfoEntity将购物项信息封装到购物项中,其中设置销售属性组合需要远程查询sku的销售属性组合信息查询销售属性组合通过
skuId查询销售属性值的List集合进行返回,这个List集合直接封装到购物项的属性中,封装成List<String>[控制器方法]
xxxxxxxxxx("/sku/attrs/{skuId}")public List<String> getSkuSaleAttrValues(("skuId") Long skuId){return skuSaleAttrValueService.getSkuSaleAttrValues(skuId);}[查询商品销售属性组合的SQL]
xxxxxxxxxx<select id="getValueListBySkuId" resultType="java.lang.String">SELECT CONCAT(attr_name,": ",attr_value)FROM `pms_sku_sale_attr_value`WHERE sku_id=#{skuId}</select>
查询商品信息和销售属性组合都需要远程查询两张表,我们可以使用线程池和
CompletableFuture发起异步任务来实现异步任务一定要满足同步异步关系,不然很容易发生由于任务执行顺序导致的各种比如空指针问题
如果用户已经添加过该商品,则无需生成购物项,直接从
Redis中获取数据并累加到商品数量上并使用boundHashOperations.put(String field,String value)方法更新商品数据[控制器方法]
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 购物车控制器* @创建日期 2024/10/25* @since 1.0.0*/("/cart")public class CartController {private CartService cartService;("/item/add")public String addCartItem(("skuId") Long skuId,("purchaseQuantity") Integer purchaseQuantity,Model model){CartItem cartItem=cartService.addCartItem(skuId,purchaseQuantity);model.addAttribute("cartItem",cartItem);return "success";}}[业务实现类]
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 购物车业务实现类* @创建日期 2024/10/25* @since 1.0.0*/("cartService")public class CartServiceImpl implements CartService {private StringRedisTemplate redisTemplate;private ProductFeignClient productFeignClient;/*** @param skuId* @param purchaseQuantity* @return {@link CartItem }* @描述 添加购物项* @author Earl* @version 1.0.0* @创建日期 2024/10/25* @since 1.0.0*/public CartItem addCartItem(Long skuId, Integer purchaseQuantity) {BoundHashOperations<String, Object, Object> cartOperation = getCartOperation();String field = String.valueOf(skuId);//1. 检查Redis中是否有对应的购物项,如果有直接累加购物项的商品数量CartItem cartItem = JSON.parseObject((String) cartOperation.get(field), new TypeReference<CartItem>() {});if(cartItem != null){cartItem.setPurchaseQuantity(cartItem.getPurchaseQuantity()+purchaseQuantity);}else{//2. 调用商品服务根据skuId获取商品的基本信息和商品的基本属性信息cartItem = productFeignClient.getCartItemBySkuId(skuId).get("cartItem", new TypeReference<CartItem>() {});cartItem.setPurchaseQuantity(purchaseQuantity);cartItem.setSelected(true);}cartOperation.put(field, JSON.toJSONString(cartItem));return cartItem;}/*** @return {@link BoundHashOperations }<{@link String }, {@link Object }, {@link Object }>* @描述 获取用户购物车,如果用户已登录获取用户购物车,如果用户没有登录获取用户临时购物车* @author Earl* @version 1.0.0* @创建日期 2024/10/25* @since 1.0.0*/private BoundHashOperations<String, Object, Object> getCartOperation(){UserInfoTo userInfo = UserStatusInterceptor.threadLocal.get();if(userInfo.getUserId()!=null){return redisTemplate.boundHashOps(CartConstant.USER_CART_IDENTITY_PREFIX + userInfo.getUserId());}BoundHashOperations<String, Object, Object> cartOperation = redisTemplate.boundHashOps(CartConstant.USER_CART_IDENTITY_PREFIX + userInfo.getUserKey());cartOperation.expire(CartConstant.TEMP_CART_EXPIRE, TimeUnit.SECONDS);return cartOperation;}}
接口幂等性
添加商品成功页面的请求地址仍然是添加商品的接口地址,此时用户刷新商品添加成功页面,会重复向购物车添加同等数量的该商品
我们可以通过重定向到成功页面来改变地址栏的请求地址来避免添加商品反复提交的情况,京东也是这样实现的,京东的添加购物车的链接反复提交会累积商品数量,但是重定向以后的地址不会累计商品数量
根本解决方式,重要接口自身做好权限及数据校验防止漏洞,普通接口采用重定向,前端按钮禁用等
代码示例
重定向时,
ModelAndView中的数据会自动拼接在请求链接后面,RedirectAttribute也有该功能经过验证
ModelAndView是不行的,只有RedirectAttribute在重定向的时候会自动在重定向路径后面拼接参数
老师的做法是重定向以后让后端再次查询一遍对应
skuId的商品数据,再放到ModelAndView中
[控制器方法]
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 购物车控制器* @创建日期 2024/10/25* @since 1.0.0*/("/cart")public class CartController {private CartService cartService;("/item/add")public String addCartItem(("skuId") Long skuId,("purchaseQuantity") Integer purchaseQuantity,RedirectAttributes attributes){cartService.addCartItem(skuId,purchaseQuantity);attributes.addAttribute("skuId",skuId);return "redirect:http://cart.earlmall.com/cart/add/success";}("/add/success")public String addCartSuccess(("skuId") Long skuId, Model model){CartItem cartItem = cartService.getCartItem(skuId);model.addAttribute("cartItem",cartItem);return "success";}("/sku/list")public String listCart(){return "cartList";}}[业务实现类]
xxxxxxxxxx/*** @param skuId* @return {@link CartItem }* @描述 通过skuId从Redis中获取对应购物项,如果没有对应购物项返回null* @author Earl* @version 1.0.0* @创建日期 2024/10/26* @since 1.0.0*/public CartItem getCartItem(Long skuId) {BoundHashOperations<String, Object, Object> cartOperation = getCartOperation();String field = String.valueOf(skuId);CartItem cartItem = JSON.parseObject((String) cartOperation.get(field), new TypeReference<CartItem>() {});return cartItem;}/*** @return {@link BoundHashOperations }<{@link String }, {@link Object }, {@link Object }>* @描述 获取用户购物车,如果用户已登录获取用户购物车,如果用户没有登录获取用户临时购物车* @author Earl* @version 1.0.0* @创建日期 2024/10/25* @since 1.0.0*/private BoundHashOperations<String, Object, Object> getCartOperation(){UserInfoTo userInfo = UserStatusInterceptor.threadLocal.get();if(userInfo.getUserId()!=null){return redisTemplate.boundHashOps(CartConstant.USER_CART_IDENTITY_PREFIX + userInfo.getUserId());}BoundHashOperations<String, Object, Object> cartOperation = redisTemplate.boundHashOps(CartConstant.USER_CART_IDENTITY_PREFIX + userInfo.getUserKey());cartOperation.expire(CartConstant.TEMP_CART_EXPIRE, TimeUnit.SECONDS);return cartOperation;}
更改购物项
更改购物项选中状态
前端逻辑
给复选框一个属性封装当前商品的
skuId,复选框被选中checked属性就是checked,我们可以通过JQUERY的attr("checked")获取到属性值checked,也可以使用JQUERY的prop("checked")方法来判断属性值是否为指定值,通过这两个属性值我们可以知道商品的skuId和选中状态,将两个参数封装到请求路径中老师这里把前端的参数true转换成1来传参的,为什么不直接传参true呢
[复选框组件]
xxxxxxxxxx<li><input type="checkbox" th:checked="${cartItem.selected}" th:attr="skuId=${cartItem.skuId}" class="check" onchange="checkSku(this)"/></li>[
JavaScript脚本]xxxxxxxxxxfunction checkSku(chkbox) {var skuId = $(chkbox).attr("skuId");var checked = $(chkbox).prop("checked");var isCheckedFlag = "0";if (checked) {isCheckedFlag = "1";}$.ajax({url: "check/status",type: 'POST',data:JSON.stringify({ skuId: skuId, isChecked: isCheckedFlag }),success:function (data) {sumSumPrice();},dataType: "json",contentType: "application/json"});}//封装总价钱函数function sumSumPrice() {console.log("计算总价");var zzj = 0;$(".check").each(function () {if ($(this).prop("checked")) {console.log("check!!" + $(this).parents("ol").find(".zj").html());var zj = $(this).parents("ol").find(".zj").html().substring(1);console.log(" 价格:" + zj);zzj = zzj + parseFloat(zj);}$(".fnt").html("¥" + zzj + ".00")})}
后端逻辑
后端更改购物项状态,重定向到购物车页面,购物车列表页会自动重新统计购物车汇总数据
根据
skuId获取某个购物项,根据用户传参选中状态更改购物项的选中状态更新
redis中的购物项
[VO类]
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 封装购物项更新数据* @创建日期 2024/10/28* @since 1.0.0*/public class CartItemVo {private Long skuId;private Integer isChecked;}[控制器方法]
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 购物车控制器* @创建日期 2024/10/25* @since 1.0.0*/("/cart")public class CartController {private CartService cartService;/*** @param item* @return {@link R }* @描述 根据skuId和购物项选中状态更新购物车* @author Earl* @version 1.0.0* @创建日期 2024/10/28* @since 1.0.0*/("/check/status")public R updateCheckStatus( CartItemVo item){try {CartItem cartItem = cartService.updateCheckStatus(item);return R.ok().put("cartItem",cartItem);}catch (RRException e){return R.error(e.getCode(),e.getMsg());}}}[实现类]
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 购物车业务实现类* @创建日期 2024/10/25* @since 1.0.0*/("cartService")public class CartServiceImpl implements CartService {private StringRedisTemplate redisTemplate;private ProductFeignClient productFeignClient;/*** @param skuId* @return {@link CartItem }* @描述 通过skuId从Redis中获取对应购物项,如果没有对应购物项返回null* @author Earl* @version 1.0.0* @创建日期 2024/10/26* @since 1.0.0*/private CartItem getCartItem(Long skuId,BoundHashOperations<String, Object, Object> cartOperation) throws RRException {String field = String.valueOf(skuId);CartItem cartItem = JSON.parseObject((String) cartOperation.get(field), new TypeReference<CartItem>() {});if(cartItem==null){throw new RRException(StatusCode.CART_ITEM_NOT_EXIT_EXCEPTION.getMsg(),StatusCode.CART_ITEM_NOT_EXIT_EXCEPTION.getCode());}return cartItem;}/*** @param item* @return {@link CartItem }* @描述 根据skuId和购物项被选中状态更新购物项的选中状态* @author Earl* @version 1.0.0* @创建日期 2024/10/28* @since 1.0.0*/public CartItem updateCheckStatus(CartItemVo item) throws RRException{BoundHashOperations<String, Object, Object> cartOperation = getCartOperation();CartItem cartItem = getCartItem(item.getSkuId(), cartOperation);cartItem.setSelected(item.getIsChecked() == CartConstant.CartItemCheckStatus.CHECKED.getCode());putCartItem(item.getSkuId(),cartItem,cartOperation);return cartItem;}private void putCartItem(Long skuId,CartItem cartItem,BoundHashOperations<String, Object, Object> cartOperation){cartOperation.put(skuId.toString(), JSON.toJSONString(cartItem));}/*** @return {@link BoundHashOperations }<{@link String }, {@link Object }, {@link Object }>* @描述 获取用户购物车,如果用户已登录获取用户购物车,如果用户没有登录获取用户临时购物车* @author Earl* @version 1.0.0* @创建日期 2024/10/25* @since 1.0.0*/private BoundHashOperations<String, Object, Object> getCartOperation(){UserInfoTo userInfo = UserStatusInterceptor.threadLocal.get();if(userInfo.getUserId()!=null){return redisTemplate.boundHashOps(CartConstant.USER_CART_IDENTITY_PREFIX + userInfo.getUserId());}BoundHashOperations<String, Object, Object> cartOperation = redisTemplate.boundHashOps(CartConstant.USER_CART_IDENTITY_PREFIX + userInfo.getUserKey());cartOperation.expire(CartConstant.TEMP_CART_EXPIRE, TimeUnit.SECONDS);return cartOperation;}}[拦截器]
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 用户状态判断拦截器,购物车服务需要判断用户的登录状态* @创建日期 2024/10/25* @since 1.0.0*/public class UserStatusInterceptor implements HandlerInterceptor {public static ThreadLocal<UserInfoTo> threadLocal=new ThreadLocal<>();/*** @param request* @param response* @param handler* @return boolean* @描述 从session中获取用户数据,如果用户数据存在,封装用户的id信息* @author Earl* @version 1.0.0* @创建日期 2024/10/25* @since 1.0.0*/public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {UserInfoTo userInfo = new UserInfoTo();UserBaseInfoVo userBaseInfo = (UserBaseInfoVo)request.getSession().getAttribute(MallConstant.SESSION_USER_LOGIN_STATUS_KEY);if(userBaseInfo!=null){userInfo.setUserId(userBaseInfo.getId());}Cookie[] cookies = request.getCookies();if(cookies!=null && cookies.length>0){for (Cookie cookie : cookies) {if(CartConstant.USER_TEMP_IDENTITY_COOKIE_NAME.equals(cookie.getName())){userInfo.setUserKey(cookie.getValue());userInfo.setCookieExist(true);}}}if(!userInfo.getCookieExist()){userInfo.setUserKey(UUID.randomUUID().toString());}threadLocal.set(userInfo);return true;}/*** @param request* @param response* @param handler* @param modelAndView* @描述 如果cookie中没有名为user-key的cookie就添加该cookie* @author Earl* @version 1.0.0* @创建日期 2024/10/25* @since 1.0.0*/public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) throws Exception {UserInfoTo userInfo = threadLocal.get();if(!userInfo.getCookieExist()){response.addCookie(new Cookie(CartConstant.USER_TEMP_IDENTITY_COOKIE_NAME,userInfo.getUserKey()));}threadLocal.remove();}}
更改购物项数量
前端逻辑
给增减按钮绑定单机事件,增减是假按钮,给假按钮组件相同的class绑定单机事件,点击事件发生获取紧挨着的框的值,我们可以给增减按钮的父元素绑定当前商品的skuId,通过父元素获取商品skuId和父元素下的指定class的商品数量框的值,即传参商品
skuId和商品数量$(this).parent("p").attr("skuId")拿到当前增减按钮的商品skuId这里是限定父标签为p标签[不指定标签也是可以的],注意HTML中的属性名不区分大小写
$(this).parent().find(".countOpsNum").text()是获取商品数量组件的本文值
[前端组件]
xxxxxxxxxx<li><p th:attr="skuId=${cartItem.skuId}"><span class="count_minus">-</span><span class="count" th:text="${cartItem.purchaseQuantity}">5</span><span class="count_add">+</span></p></li>[
JavaScript脚本]xxxxxxxxxx//更改购物项的数量$(".count_add").click(function (){var skuId = $(this).parent("p").attr("skuId");var purchaseQuantity = $(this).parent().find(".count").text();purchaseQuantity++;$(this).parent().find(".count").html(purchaseQuantity);//总价var dj = $(this).parent().parent().prev().children(".dj").html().substring(1);var sl = $(this).prev("span").html();$(this).parent().parent().parent().children("li:nth-child(5)").children(".zj").html("¥" + dj * sl + ".00")$.ajax({url: "purchase/quantity",type: 'POST',data:JSON.stringify({ skuId: skuId, purchaseQuantity: purchaseQuantity }),success:function (data) {console.log(data)sumSumPrice();},dataType: "json",contentType: "application/json"});})$(".count_minus").click(function (){var skuId = $(this).parent("p").attr("skuId");var purchaseQuantity = $(this).parent().find(".count").text();purchaseQuantity--;$(this).parent().find(".count").html(purchaseQuantity);//总价var dj = $(this).parent().parent().prev().children(".dj").html().substring(1);var sl = $(this).next("span").html();$(this).parent().parent().parent().children("li:nth-child(5)").children(".zj").html("¥" + dj * sl + ".00")$.ajax({url: "purchase/quantity",type: 'POST',data:JSON.stringify({ skuId: skuId, purchaseQuantity: purchaseQuantity }),success:function (data) {console.log(data)sumSumPrice();},dataType: "json",contentType: "application/json"});})//封装总价钱函数function sumSumPrice() {console.log("计算总价");var zzj = 0;$(".check").each(function () {if ($(this).prop("checked")) {console.log("check!!" + $(this).parents("ol").find(".zj").html());var zj = $(this).parents("ol").find(".zj").html().substring(1);console.log(" 价格:" + zj);zzj = zzj + parseFloat(zj);}$(".fnt").html("¥" + zzj + ".00")})}后端逻辑
根据前端传参
skuId和新的商品数量更改Redis中的购物项,当商品数量减成0的时候直接删除购物项重定向到购物车页面[我用Ajax做的,更优雅]
[VO类]
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 封装购物项更新数据* @创建日期 2024/10/28* @since 1.0.0*/public class CartItemVo {/*** 商品skuId*/private Long skuId;/*** 购物项的被选中状态*/private Integer isChecked;/*** 购物项选中状态*/private Integer purchaseQuantity;}[控制器方法]
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 购物车控制器* @创建日期 2024/10/25* @since 1.0.0*/("/cart")public class CartController {private CartService cartService;/*** @param item* @return {@link R }* @描述 根据skuId和购物项的采购数量更新购物车* @author Earl* @version 1.0.0* @创建日期 2024/10/28* @since 1.0.0*/("/purchase/quantity")public R updatePurchaseQuantity( CartItemVo item){try {CartItem cartItem = cartService.updatePurchaseQuantity(item);return R.ok().put("cartItem",cartItem);}catch (RRException e){return R.error(e.getCode(),e.getMsg());}}}[实现类]
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 购物车业务实现类* @创建日期 2024/10/25* @since 1.0.0*/("cartService")public class CartServiceImpl implements CartService {private StringRedisTemplate redisTemplate;private ProductFeignClient productFeignClient;/*** @param skuId* @return {@link CartItem }* @描述 通过skuId从Redis中获取对应购物项,如果没有对应购物项返回null* @author Earl* @version 1.0.0* @创建日期 2024/10/26* @since 1.0.0*/private CartItem getCartItem(Long skuId,BoundHashOperations<String, Object, Object> cartOperation) throws RRException {String field = String.valueOf(skuId);CartItem cartItem = JSON.parseObject((String) cartOperation.get(field), new TypeReference<CartItem>() {});if(cartItem==null){throw new RRException(StatusCode.CART_ITEM_NOT_EXIT_EXCEPTION.getMsg(),StatusCode.CART_ITEM_NOT_EXIT_EXCEPTION.getCode());}return cartItem;}/*** @param item* @return {@link CartItem }* @描述 根据skuId更新购物项的商品数量* @author Earl* @version 1.0.0* @创建日期 2024/10/28* @since 1.0.0*/public CartItem updatePurchaseQuantity(CartItemVo item) throws RRException{BoundHashOperations<String, Object, Object> cartOperation = getCartOperation();CartItem cartItem = getCartItem(item.getSkuId(), cartOperation);cartItem.setPurchaseQuantity(item.getPurchaseQuantity());putCartItem(item.getSkuId(),cartItem,cartOperation);return cartItem;}private void putCartItem(Long skuId,CartItem cartItem,BoundHashOperations<String, Object, Object> cartOperation){cartOperation.put(skuId.toString(), JSON.toJSONString(cartItem));}/*** @return {@link BoundHashOperations }<{@link String }, {@link Object }, {@link Object }>* @描述 获取用户购物车,如果用户已登录获取用户购物车,如果用户没有登录获取用户临时购物车* @author Earl* @version 1.0.0* @创建日期 2024/10/25* @since 1.0.0*/private BoundHashOperations<String, Object, Object> getCartOperation(){UserInfoTo userInfo = UserStatusInterceptor.threadLocal.get();if(userInfo.getUserId()!=null){return redisTemplate.boundHashOps(CartConstant.USER_CART_IDENTITY_PREFIX + userInfo.getUserId());}BoundHashOperations<String, Object, Object> cartOperation = redisTemplate.boundHashOps(CartConstant.USER_CART_IDENTITY_PREFIX + userInfo.getUserKey());cartOperation.expire(CartConstant.TEMP_CART_EXPIRE, TimeUnit.SECONDS);return cartOperation;}}[拦截器]
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 用户状态判断拦截器,购物车服务需要判断用户的登录状态* @创建日期 2024/10/25* @since 1.0.0*/public class UserStatusInterceptor implements HandlerInterceptor {public static ThreadLocal<UserInfoTo> threadLocal=new ThreadLocal<>();/*** @param request* @param response* @param handler* @return boolean* @描述 从session中获取用户数据,如果用户数据存在,封装用户的id信息* @author Earl* @version 1.0.0* @创建日期 2024/10/25* @since 1.0.0*/public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {UserInfoTo userInfo = new UserInfoTo();UserBaseInfoVo userBaseInfo = (UserBaseInfoVo)request.getSession().getAttribute(MallConstant.SESSION_USER_LOGIN_STATUS_KEY);if(userBaseInfo!=null){userInfo.setUserId(userBaseInfo.getId());}Cookie[] cookies = request.getCookies();if(cookies!=null && cookies.length>0){for (Cookie cookie : cookies) {if(CartConstant.USER_TEMP_IDENTITY_COOKIE_NAME.equals(cookie.getName())){userInfo.setUserKey(cookie.getValue());userInfo.setCookieExist(true);}}}if(!userInfo.getCookieExist()){userInfo.setUserKey(UUID.randomUUID().toString());}threadLocal.set(userInfo);return true;}/*** @param request* @param response* @param handler* @param modelAndView* @描述 如果cookie中没有名为user-key的cookie就添加该cookie* @author Earl* @version 1.0.0* @创建日期 2024/10/25* @since 1.0.0*/public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) throws Exception {UserInfoTo userInfo = threadLocal.get();if(!userInfo.getCookieExist()){response.addCookie(new Cookie(CartConstant.USER_TEMP_IDENTITY_COOKIE_NAME,userInfo.getUserKey()));}threadLocal.remove();}}
删除购物项
前端逻辑
点击购物项的删除按钮,会弹框确认用户是否真的要删除,点击弹框的删除按钮,给删除按钮绑定单机事件,让第一个删除按钮组件设置属性保存商品的skuId,该按钮单击时将要删除的商品的skuId保存在一个全局变量中来供删除确认按钮的单机事件使用
[前端组件]
xxxxxxxxxx<li><p class="delete_confirm" th:attr="skuId=${cartItem.skuId}">删除</p></li><div class="One_isDel"><p><span>删除</span><span><img src="/static/cart/img/错误.png" alt=""></span></p><div><dl><dt><img src="/static/cart/img/感叹三角形 (2).png" alt=""></dt><dd><li>删除商品?</li><li>您可以选择移到关注,或删除商品。</li></dd></dl></div><div><button type="button" class="delete">删除</button></div></div>[
JavaScript脚本]xxxxxxxxxxvar deletedSkuId=-1;$(".delete_confirm").click(function (){deletedSkuId=$(this).attr("skuId");});$(".delete").click(function (){location.href="http://cart.earlmall.com/cart/delete/"+deletedSkuId;})后端逻辑
删除一个购物项可以使用
boundHashOperations.delete(skuId.toString())删除以后直接重定向到购物车页面
[控制器方法]
xxxxxxxxxx/*** @param skuId* @return {@link String }* @描述 根据skuId删除指定购物项* @author Earl* @version 1.0.0* @创建日期 2024/10/29* @since 1.0.0*/("/delete/{skuId}")public String deleteCartItemBySkuId(("skuId") Long skuId,RedirectAttributes attributes){try {cartService.deleteBySkuId(skuId);}catch (RRException e){attributes.addFlashAttribute("error",e.getMsg());}return "redirect:http://cart.earlmall.com/cart/cartList.html";}[业务实现类]
xxxxxxxxxx/*** @param skuId* @描述 根据skuId删除购物车数据* @author Earl* @version 1.0.0* @创建日期 2024/10/29* @since 1.0.0*/public void deleteBySkuId(Long skuId) {getCartOperation().delete(skuId.toString());}/*** @return {@link BoundHashOperations }<{@link String }, {@link Object }, {@link Object }>* @描述 获取用户购物车,如果用户已登录获取用户购物车,如果用户没有登录获取用户临时购物车* @author Earl* @version 1.0.0* @创建日期 2024/10/25* @since 1.0.0*/private BoundHashOperations<String, Object, Object> getCartOperation(){UserInfoTo userInfo = UserStatusInterceptor.threadLocal.get();if(userInfo.getUserId()!=null){return redisTemplate.boundHashOps(CartConstant.USER_CART_IDENTITY_PREFIX + userInfo.getUserId());}BoundHashOperations<String, Object, Object> cartOperation = redisTemplate.boundHashOps(CartConstant.USER_CART_IDENTITY_PREFIX + userInfo.getUserKey());cartOperation.expire(CartConstant.TEMP_CART_EXPIRE, TimeUnit.SECONDS);return cartOperation;}
消息队列
生产者向消息代理发送消息,消息代理保证消息按一定规则传递到指定目的地
典型队列是从队首进元素,从队尾取元素,这是FIFO先进先出队列
从对首进元素,从队首取元素,这是先进后出队列,这就是典型的栈结构
如果队列两头都可以放数据取数据,这就是双端队列
Java中有相应队列的实现,但是这种队列是进程级别的,一个队列中的数据只能在一台机器内部使用,分布式环境下我们需要一个公共的队列来共享并有序处理队列中的数据,各种业务场景需要的队列类型也不一样,消息中间件就作为这个公共的队列来让各个微服务获取消息进行消费
消息中间件两个概念
消息代理:理解为安装了消息中间件的服务器,生产者向消息代理发送消息,消费者从消息代理获取消息
目的地:消息消费者,消息队列中主要有两种形式目的地
队列:点对点式的消息通信模型,生产者发送消息给消息代理中的一个FIFO队列,最终只有一个消费者从消息代理中获取消息,消息被读取后移出队列;这种点对点的模式只能有一个消息生产者和一个消息代理,但是可以有多个消息消费者同时监听该队列,但是最终只有一个消费者获取消费一条消息
主题:发布订阅的消息通信模式,生产者发送消息给消息代理中的一个主题,多个消息消费者同时监听主题,消息到达队列尾时,所有消息消费者都能获取到消息,发布订阅模式相较于队列模式的区别就是能所有订阅了主题的消费者都能获取并消费消息
应用场景
异步处理:假如用户需要注册,用户注册向数据库写入数据,然后需要发送注册邮件、发送短信,每个步骤都需要耗时50ms,总耗时150ms;如果我们让发送邮件和发送短信的两个过程采用异步的方式,用户只需要100ms就能收到响应;实际上发送短信和邮件不需要很高的时效性,我们可以将用户注册成功的事件写入消息中间件,这个过程是向内存写数据,相较于将用户数据写入数据库的50ms来说是非常快的,可能只需要5ms甚至更快,消息存入消息中间件后立即响应结果给用户,由发送邮件和短信的服务异步去异步读取消息中间件的用户注册消息来给用户发送邮件和短信,对于这种时效性不严格的场景,我们可以将异步处理的思路扩展到服务协作上

应用解耦:按照一般的逻辑,用户下完订单的同时,订单服务直接去调用库存服务进行后续处理,一旦库存服务的API发生变化,订单服务的代码就需要修改;但是我们通过消息中间件来进行通信,订单系统只关心要生成的订单信息,不需要关注库存系统具体的API,库存系统也只需要考虑修改后的代码能否适配消息中间件中的订单信息,不需要关心订单服务有没有更改库存服务被调用的API,因为库存服务的API没有被订单服务进行调用
流量控制:类似秒杀这种大流量场景,对于瞬时百万的并发,业务处理流程复杂处理过程会比较慢,大量请求一直在后台阻塞等待,最终可能导致服务器资源耗尽,机器宕机;对于秒杀这种高并发场景,我们不着急立即处理订单业务,我们可以先判断用户是否秒杀成功,然后直接将秒杀成功的用户信息写入消息中间件,写入成功直接响应成功的信息给用户,后续业务的服务去订阅消息队列中的秒杀请求,在后台挨个处理秒杀成功的订单业务,无需担心机器因为资源耗尽导致的宕机问题,实现将瞬时流量存储到消息队列中,后台根据处理能力来进行消费处理,也称流量削峰,避免峰值流量太大占满服务器资源导致的机器宕机

消息中间件的相关规范和协议
JMS[Java Message Service],Java消息服务,这是SUN公司制定的基于JVM消息代理的规范,ActiveMQ、HornetMQ都是基于JMS的实现
使用JMS规范的产品,可以通过Java平台提供的API直接对不同产品和不同版本的产品进行直接调用,切换产品和版本无需修改Java代码,类似于JDBC规范和各数据库厂家的数据库驱动,即用户只需要面向接口编程,实际运行切换不同的实现类即可
缺点是只能支持Java平台,不支持跨语言
JMS提供了Peer-2-Peer[点对点队列模型]、Pub/Sub[发布订阅主题模型]两种消息通信模型
Java平台支持的对象类型比较多,支持TextMessage[纯文本消息]、MapMessage[Map消息]、BytesMessage[字节数据消息]、StreamMessage[流消息]、ObjectMessage[对象消息]、Message[只有消息头和属性的简单消息]
AMQP[Advanced Message Queuing Protocol],高级消息队列协议,也是一个兼容JMS的消息代理规范,RabbitMQ是基于AMQP的实现
AMQP是一种网络线级协议,类似于HTTP网络通信协议,因为是类似于JSON的一种协议,AMQP定义了wire-level层的协议标准,天然支持跨语言和跨平台
AMQP提供了Direct Exchange[]、Fanout Exchange[]、Topic Exchange[]、HEADERS Exchange[]、SYSTEM Exchange[],其中Direct Exchange是对点对点队列模式的实现、其他的都是对发布订阅模式的实现,因此一般都是点对点队列模式和发布订阅主题模式两种实现
AMQP只支持一种byte[]字节流消息,网络通信传输的是字节流,支持字节流的消息其实就是什么类型的消息都支持,像Java一个对象想要作为消息传输出去,我们只需要使用序列化器将对象序列化为一个字符串,将字符串以流的方式传输出去
规范选择
如果系统只使用Java开发,我们可以首选JMS的实现,这样我们可以方便切换产品和产品版本而不需要修改源代码
如果订单系统是Java开发的,但是库存系统是基于第三方PHP实现的,我们就可以引入跨语言的AMQP的实现
注意AMQP是兼容JMS的,因此对应的实现比如RabbitMQ支持跨语言还支持JMS相关接口,此外RabbitMQ还支持MQTT协议
RabbitMQ的设计非常标准,也带来了非常复杂且多的概念,其他的消息中间件的复杂概念比RabbitMQ少的多
大公司使用RabbitMQ的也非常多
Spring对消息队列的支持
spring-jms提供了对JMS规范的支持,spring-rabbit提供了对AMQP协议特别是RabbitMQ的支持
注意RabbitMQ、Spring全系列框架、VMWare虚拟机都是一家公司VMWare公司的产品,Spring框架由Pivotal Software公司和Spring IO社区共同维护,VMWare公司是Pivotal Software公司的拥有者,但是Spring框架是由一个独立的开源社区维护,VMWare旗下的公司只是作为其中的一个维护者;RabbitMQ的研发公司在2009年被SpringSource收购,SpringSource后来成为Pivotal Software公司的一部分,Pivotal Software公司于2019年被VMWare公司收购,因此RabbitMQ也成为了VMWare的一部分,卧槽2023年Broadcom以610亿美元的价格收购了VMWare
Spring通过连接工厂来实现对消息代理的连接,在
SpringBoot中引入消息中间件依赖连接工厂是自动配置的Spring抽取了两个Template,即
JmsTemplate和RabbitTemplate来操作处理消息;抽取了两个注解即@JmsListener[JMS]、@RabbitListener[AMQP]注解通过标注在方法上来监听消息代理发布的消息,只需要这两个注解就能从消息代理中拿到消息Spring还提供了两个注解
@EnableJms、@EnableRabbit来快速开启消息中间件功能
SpringBoot对消息中间件的自动配置
自动配置类为
JmsAutoConfiguration、RabbitAutoConfiguration
市面上最火爆的消息中间件产品
ActiveMQ、RabbitMQ、RocketMQ、Kafka
RabbitMQ
生产者发送消息给消息代理[RabbitMQ服务器]并指定消息的路由键,根据该路由key找到指定虚拟主机中的指定交换器,根据交换器和队列的绑定关系决定将消息保存到哪些队列,消费者通过监听对应队列,队列尾的内容被消费者通过信道实时拿到
概念介绍
Publisher消息生产者:是向交换器发布消息的客户端应用程序
Message消息:消息由消息头和消息体构成,
消息头中有很多的配置项
route-key路由键:priority:相较于其他消息的优先权delivery-mode:配置消息是否需要持久性存储
消息体中是真正的消息内容
Broker消息服务器:也就是上面说的消息代理
Exchange交换器:这个交换器用来接收生产者传递过来的消息并将这些消息路由给服务器中的各种队列,交换器有4种类型,不同交换机转发消息的策略有区别,这个类似于网络交换机,一个消息服务器中可能存在多个不同类型的交换器,交换器接收生产者传递来的消息并按照既定策略将消息路由到指定的队列中,一个消息代理中可能含有多个消息队列,消息队列和交换器之间有预设的绑定关系Binding
Direct[默认]:直接交换器
其中Direct和Headers都是JMS中点对点通信模型的实现,Headers匹配AMQP消息的消息头而不是路由键,Headers交换器和Direct交换器除了匹配路由不同其他都完全一致,但是Headers的性能比较低下,一般都不讨论,也几乎不用;主要讨论Direct、Fanout和Topic
Direct Exchange直接交换器:该交换器将消息交给一个指定的队列,消息中的路由键
routing key只能唯一匹配与Bingding中bingding key完全相同的队列,比如一个路由键为dog的消息只会被直接交换机路由到绑定关系中binding key为dog的队列,核心是routing key和绑定关系中的binding key一模一样才能进行匹配,这也叫完全匹配、单播模式,也称为点对点模式

Fanout:扇出交换器
Fanout和Topic都是发布订阅模式的实现,这种是广播模式的实现,无条件将消息发给所有与交换器绑定的队列
Fanout Exchange扇出交换器:这种交换器根本不关心交换器的路由键是什么,一个扇出交换器可以绑定多个队列,每个发送到扇出交换器的消息都会被广播到与扇出交换器绑定的所有队列上,很像子网广播,每台子网内的主机都会获得一份复制的消息,Fanout交换器转发消息是最快的
给扇出交换器发送的消息不指定
routing key也是可以的,所有和扇出交换器绑定的队列都能接收到消息;指定了路由键也不会对路由键进行判断处理

Topic:主题交换器,对应发布订阅模式,主题交换器对应的是根据路由键将消息路由到模式匹配的一个或者多个与交换器绑定的队列
一个主题交换器绑定多个队列,每个
Bingding中都有一个模式bingding key,这个模式由两个通配符#和*以及单词和点构成,其中通配符#匹配0个或者多个单词,注意不能使用#匹配字母;通配符*匹配一个单词即被匹配的路由键对应位置必须有一个单词,单词之间使用点进行分隔,只有路由键匹配对应绑定关系的bingding key消息才会被转发到对应的一个或者多个队列上比如
bingding key=usa.#即匹配rounting key以单词usa开头的,bingding key=#.news匹配routing key以news作为后缀的

Headers:
Queue队列:是消息的容器,用于保存消息直到消费者连接该队列将该消息取走,一个消息可以投入一个或者多个队列
Binding绑定:用户关联消息队列和交换器,绑定是基于路由键将交换器和消息队列关联起来的路由规则,可以将交换器理解成一个由绑定构成的路由表,交换器和队列的绑定关系是多对多关系
Connection连接:每个客户端都只会和消息中间件建立一条长连接来收发消息,长连接就是一直保持连接状态的连接,连接类型是TCP连接,消费者可以通过该一条连接同时接收来自多个队列的消息
Consumer消费者:从消息队列中取得消息的客户端应用程序
Channel信道:Java的NIO中也有信道的概念,信道是多路复用连接中的一条独立的双向数据流通道,信道是建立在真实的TCP连接内的虚拟连接,AMQP命令、发布消息、订阅队列或者接收消息都是通过信道完成的,通过在一条长连接上开辟多条信道,每条信道负责各自的收发消息通信,接收消息是使用信道来接收指定队列的消息,对于操作系统来说建立和销毁TCP连接都是非常昂贵的开销,通过信道来实现对一条TCP连接的复用
同时通过长连接,一旦消费者宕机导致连接中断,我们的消息代理能够实时感知到消费者下线,消息无法被消费者获取,就会立即将消息存储起来不再向外派发,不会造成消息大面积丢失;如果消息代理不能实时识别消费者的连接状态,消费者宕机的情况下仍然将消息发送给消费者并删除对应消息,消息就丢失了
Virtual Host虚拟主机:虚拟主机标识一批交换器、消息队列和相关对象,虚拟主机的作用是将多个交换器、多个队列作为一个整体和其他的虚拟主机隔离开,避免一个虚拟主机由于一套系统的突发情况导致消息队列中间件崩溃同时影响到使用另一套虚拟主机的其他系统
虚拟主机以路径作为标识,不同的虚拟主机位于同一个消息服务器即Broker中,不同的虚拟主机相互隔离,在使用上就像在机器上安装了另外一台RabbitMQ服务器

Docker安装RabbitMQ
这里老师用的是
RabbitMQ3.8.2
安装步骤
使用命令
docker run -d --name rabbitmq -p 5671:5671 -p 5672:5672 -p 4369:4369 -p 25672:25672 -p 15671:15671 -p 15672:15672 rabbitmq:management安装RabbitMQ,其中4369、25672端口是Erlang发现端口和集群端口,RabbitMQ是用Erlang语言编写的5672、5671是AMQP端口15672是web管理后台端口61613、61614是STOMP协议端口,开启了STOMP协议才需要开放该端口1883、8883是MQTT协议端口,开启了MQTT协议才需要开放该端口RabbitMQ的RabbitMQ官方文档对这些端口有具体说明
使用命令
docker update rabbitmq --restart=always让容器随着Docker启动自动启动使用命令
docker exec -it rabbitmq /bin/bash进入容器rabbitmq的bash命令控制台,无需停止rabbitmq直接使用命令rabbitmq-plugins enable rabbitmq_management,也无需重启容器后台管理系统
http://192.168.56.10:15672的默认账号和登录密码都是guest,如果不执行上述步骤只能打开登录页无法登录进入首页如何在docker内部使用命令停止
rabbitmq没学过,使用原生rpm安装的的Rabbitmq命令提示找不到对应服务
WEB界面简介
界面简介
Overview:RabbitMQ服务器的运行状况概览,Web管理界面的数据每5秒刷新一次,默认访问的是所有虚拟主机,有一个默认的虚拟主机/totals:包含Queued messages[消息队列中的消息]、Currently idle[当前消息服务器中的空闲信息]、Message rates[消息的收发速率]、Global counts[监控的全局属性,包括有多少条连接,多少个信道、多少交换器、多少个队列以及多少个消费者]Node:列举RabbitMQ的节点信息,因为当前不是集群,因此只列举了一个节点,展示了节点的内存、磁盘空间占用Churn statics:以图表的形式列举静态统计数据,每秒有多少个链接、多少个信道、多少个队列Ports and contexts:展示RabbitMQ的监听端口[比如客户端使用高级消息队列协议连接消息代理收发消息就要使用AMQP协议的通信端口5672、集群端口25672和Web端的端口15672,注意Web上下文的端口也是15672,绑定了IP地址0.0.0.0[意思是所有人都可以访问该Web端口]Export definitions:可以做老RabbitMQ服务器配置迁移,比如我们新装的RabbitMQ想使用已有配置可以直接在该选项中下载消息服务器配置下载相应配置文件Import definitions:可以在该选项卡中通过上传从别的RabbitMQ集群中下载的配置文件,一键将已有配置应用到新的RabbitMQ集群中来让多个集群或者机器保持相同的配置
Connections:该选项卡监控当前RabbitMQ服务器有多少个客户端和服务器建立了连接,注意一个客户端只会和一个服务器建立一个连接Channels:一条连接会有多条信道,所有的信道都会在该选项卡中展示出来Exchanges:该选项卡会列举RabbitMQ中所有的交换器,默认的交换器有7个,并展示所有交换器的名字、类型、交换器特性、消息进出交换器的速率Add a new exchange:我们可以通过该选项卡创建新的自定义交换器Publish message:Web客户端实际上就是一个消息队列客户端,我们可以在web界面该选项卡直接发消息,Routing key是消息的路由键,Payload是消息具体内容
Queues:该选项卡列举RabbitMQ中的所有队列,Ready是队列中准备被消费的消息数量、Unacked是队列中还没有收到消费者消息确认的消息数量队列列表中的
Features字段表示队列的配置信息,D即Durable表示当前队列是持久化的,DLX表示当前队列设置了死信交换器,DLK表示当前队列的死信消息被设置了路由键,Args是当前队列被设置的其他参数比如x-message-ttl,TTL表示当前队列设置了消息的存活时间Add a new queue:我们可以通过该选项卡创建自定义的队列点进具体的队列使用选项卡Get Message能使用Web客户端获取指定队列中的消息Ack Mode:回复模式,选择Nack message requeue true是当前Web客户端拿到消息后不告诉服务器自己拿到消息了,RabbitMQ会将消息重新入队列,其中Nack表示收到消息不回复,message requeue true表示开启消息重新入队列
Admin:这是RabbitMQ的管理设置功能,我们可以通过选择右侧的选项卡在这里设置用户信息、虚拟主机信息[显示虚拟主机的消息、客户端、消息的获取派发速率等数据]、特性标识、配置策略、Limits[对虚拟主机的连接限制,可以设置RabbitMQ的最大连接数和最大队列数]、Cluster展示和配置集群信息Add a user:我们可以通过该选项卡添加新的用户Add a new virtual host:虚拟主机是通过路径来区分的,我们可以通过该选项卡来添加新的虚拟主机,通过点击虚拟主机的名字我们还可以对虚拟主机进行更细致的配置[比如删除虚拟主机]
底部的选项卡会列举
RabbitMQ的一些官方文档和不太重要的信息,我们一般使用该界面来管理RabbitMQ中的交换器和队列

基本用法
这里主要介绍交换器和队列的使用方法
RabbitMQ的运行机制
一个交换器可能和多个队列都有绑定关系,一个队列也可以被多个交换器绑定;生产者将消息发布到交换器上,交换器根据绑定关系和消息的路由键决定将消息发送到指定的队列上,整个过程就是消息路由的过程
注意消息是发送给交换器,监听消息是监听交换器
默认交换器
RabbitMQ默认有七个交换器,其中两个直接交换器,一个扇出交换器、两个Headers交换器和两个主题交换器

创建交换器
创建交换器指定交换器的名字,交换器的类型、交换机是否持久化或者设置为临时,持久化的交换器在RabbitMQ服务器重启以后仍然存在,但是临时交换器只要RabbitMQ一重启就没了,
自动删除设置为YES当交换器没有任何队列绑定在该交换器上该交换器就会自动删除
Internal设置为yes即表示当前交换器为内部交换器,客户端不能给该交换器转发消息,内部交换器只是供RabbitMQ内部转发路由使用的
一般自动删除和内部交换器都设置为默认的
No

通过交换器列表的名字点进交换器我们可以查看交换器更详细的绑定信息、消息发布信息,设置交换器的绑定关系
交换器可以和交换器进行绑定,交换器也可以和队列进行绑定,通过这种机制可以实现交换器绑定交换器再绑定到队列,实现多层路由
配置绑定关系指定的
routing key就是上面说的Binding中的binding key

创建队列
创建队列,指定队列名字、指定队列是否持久化
如果队列自动删除设定为yes,只要没有消费者连接监听该队列,队列就会自动删除

将交换器与队列进行绑定并指定
binding key向交换器发送消息
延时队列
使用RabbitMQ的延时队列可以实现定时任务的效果
场景
📜:下订单如果三十分钟以后没有支付就关单,锁定库存成以后四十分钟如果订单没有创建成功或者订单被取消就释放被锁定的库存
💡:方案一是系统使用定时任务每隔1分钟就去扫描数据库检查哪些订单还没有支付,如果其中有订单到期了就将订单删除;锁定库存四十分钟仍然有锁库存记录且订单没有被支付或者订单没有被创建就解锁库存
缺点:定时任务消耗系统内存,每隔一段时间就要全盘扫描一次增加数据库压力,定时任务最大的问题是有较大的时间误差,即我们开启定时任务的根据不是以每个业务作为起点的,而是以每个服务的某个系统时间作为起点的,但是业务的创建时间是随机的,我们只能通过逻辑判断业务是否在定时任务时刻满足到期条件,这不可避免地会导致业务实际到期时间出现偏差,偏差越小我们的定时任务就越频繁,定时任务对系统内存和数据库的压力就越大
💡:方案二是使用RabbitMQ的延时队列,延时队列是结合消息的存活时间
TTL和死信路由Exchange来结合实现的,我们创建订单成功可以给延时队列中存放一条消息,消息到达指定时间后被转发给监听队列的服务,即延时队列的消息最大的特点是消息在指定时间后才能被消费者接收到;锁顶库存成功了我们就给另一个延时时间40分钟的延时队列也发送一条锁定库存成功的消息,延时时间到了以后再给库存服务发送消息,库存服务拿到消息检查订单如果没有支付或者订单压根没有成功创建就去解锁被锁定的库存延时队列实现的定时任务能解决系统定时任务带来的大量业务的时效性问题,延时队列的时效性只会因为网络波动重试等差上几秒钟,但是系统定时任务不仅占用系统和数据库资源,还会存在巨大的业务时效性问题
延时队列
消息的
TTL[Time To Live]:消息的存活时间,RabbitMQ可以给队列和消息都分别设置存活时间,不论给队列还是消息设置存活时间,存活时间的含义都是从消息进入队列开始到达存活时间消息仍然没有被消费者消费,消息就会变成死信,RabbitMQ服务器会默认将死信直接丢弃对队列设置TTL是没有消费者连接时消息在队列中的最大保留时间
如果队列设置了TTL、同时消息也设置了TTL,会选取两者中小的TTL作为当前消息的TTL,这也意味着如果一个消息被路由到不同的队列中,这些消息的存活时间可能不会相同
消息的存活时间设置:通过设置消息的
expiration字段或者x-message-ttl属性来设置消息的TTL,两种设置方式的效果是相同的
死信
一个消息满足以下条件就会进入一个死信路由,这个死信路由可以对应很多队列
消息被消费者拒收,并且手动消息确认时有一个
reject方法中的重新入队参数requeue为false,即消费者收到消息但是拒签消息而且标记了不让消息重新入队列消息的存活时间到了,消息过期
队列的长度限制满了。排在前面的消息会被丢弃或者扔到死信路由上
死信交换器
Dead letter Exchange就是一种普通的交换器,只是一个队列设置了死信交换器,一旦消息过期就会自动触发消息转发到死信交换器中
延时队列的实现是设置一个队列中的消息存活时间为指定值,队列不能让任何消费者监听,让队列在消息有效时间内一直保存消息,消息一过期,让消息进入死信交换器,死信交换器再将消息路由到绑定了指定消费者的队列直接将消息转发给消费者,相当于在正常的消息转发路径上添加了一个没有消费者监听的队列来在指定时间内等待消息自动失效被死信队列转发
延时队列实现1:
消息生产者以
deal.message作为路由键发送消息给交换器x将消息路由到延迟队列delay Sm queue,该队列相较于普通队列多了三项设置[队列消息存活时间x-message-ttl:300000,单位是毫秒;设置死信交换器x-dead-letter-exchange:delay exchange为交换器delay exchange,即队列中的消息过期了自动转发给死信交换器delay exchange;设置死信转发给死信交换器的路由键x-dead-letter-rounting-key:delay message为delay message,死信交换器会根据该路由键将死信转发到对应绑定键的队列test queue中,并将消息发送给消费者]

延时队列实现2:
这个实现其实就是将上面给队列设置消息过期时间改成了单独给每个消息设置过期时间,消息生产者发送消息是给消息的
expiration字段设置expiration:300000,将延迟队列delay Sm queue设置死信交换器为delay exchange,将路由键设置为delay.message;消息过期以后将消息的路由键设置为delay.message并转发给死信交换器delay exchange,死信交换器根据路由键和绑定键将消息转发给消息队列test queue,消息队列将消息发送给消费者

一般我们会采用给队列设置消息过期即方案1的方式,因为RabbitMQ采用的是惰性检查机制,也叫作懒检查,懒检查就是RabbitMQ只会在队列头消息过期的时间点来检查头节点的有效时间是否过期,过期了就将该消息作为死信;此时才会检查下一个消息是否过期,如果下一个消息早就过期了才会将消息设置为死信,但是给整个队列设置同一个过期时间就不会出现这种问题,因为是以消息到达队列时开始计算相同的过期时间,即消息头的节点没过期后续的节点永远不会过期
延时队列实现3:
在实现1的基础上我们可以简化为如下实现,即将两个交换器合并为一个交换器,根据消息前后的路由键不同由一个交换器将同一条消息分别路由到两个不同的消息队列中

以延时队列3为例通过向Spring容器中注入组件的方式来创建延时队列
一个交换器绑定多个队列使用路由键模糊匹配一般都使用主题交换器
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 自定义RabbitMQ配置* 1. 使用@Bean注解注入容器的队列、交换器、绑定关系如果在RabbitMQ服务器中没有SpringBoot会自动在RabbitMQ服务器中进行创建* @创建日期 2024/11/26* @since 1.0.0*/public class CustomRabbitMQConfig {/*** @return {@link Queue }* @描述 订单延迟队列延时队列* @author Earl* @version 1.0.0* @创建日期 2024/11/26* @since 1.0.0*/public Queue orderDelayQueue(){Map<String, Object> arguments = new HashMap<>();arguments.put("x-dead-letter-exchange","order-event-exchange");arguments.put("x-dead-letter-routing-key","order.release.order");arguments.put("x-message-ttl",60000);return new Queue("order.delay.queue", true, false, false, arguments);}/*** @return {@link Queue }* @描述 订单延迟队列路由队列* @author Earl* @version 1.0.0* @创建日期 2024/11/26* @since 1.0.0*/public Queue orderReleaseOrderQueue(){return new Queue("order.release.order.queue",true,false,false);}/*** @return {@link Exchange }* @描述 订单服务通用主题交换器* @author Earl* @version 1.0.0* @创建日期 2024/11/26* @since 1.0.0*/public Exchange orderEventExchange(){return new TopicExchange("order-event-exchange",true,false);}/*** @return {@link Binding }* @描述 延迟队列的延时队列order.delay.queue和订单服务通用交换器order-event-exchange的绑定关系* @author Earl* @version 1.0.0* @创建日期 2024/11/26* @since 1.0.0*/public Binding orderCreateOrderBinding(){return new Binding("order.delay.queue",Binding.DestinationType.QUEUE,"order-event-exchange","order.create.order",null);}/*** @return {@link Binding }* @描述 延迟队列的路由队列order.release.order.queue和订单服务通用交换器order-event-exchange的绑定关系* @author Earl* @version 1.0.0* @创建日期 2024/11/26* @since 1.0.0*/public Binding orderReleaseOrderBinding(){return new Binding("order.release.order.queue",Binding.DestinationType.QUEUE,"order-event-exchange","order.release.order",null);}}
测试延时队列
[消息生产者]
xxxxxxxxxxpublic class HelloController{RabbitTemplate rabbitTemplate;("/test/createOrder")public String createOrderTest(){//1. 创建订单OrderEntity entity = new OrderEntity();entity.setOrderSn(UUID.randomUUID().toString());entity.setModifyTime(new Date());//2. 给消息队列发送订单消息rabbitTemplate.convertAndSend("order-event-exchange","order.create.order",entity);return "ok";}}[消息消费者]
注意因为此前我们在订单服务的配置文件中使用了配置
spring.rabbitmq.listener.simple.acknowledge-mode=manual开启了消息消费者接收消息手动确认模式,因此这里我们获取到信息以后一定要拿到信道通过信道手动应答该延时队列的效果是发送消息一分钟后消费者收到消息
xxxxxxxxxxpublic class CustomRabbitMQConfig{(queues="order.release.order.queue")public void listener(OrderEntity entity,Channel channel,Message message){System.out.println("收到已成功创建的订单信息,准备检查处理订单状态"+entity.getOrderSn());channel.basicAck(message.getMessageProperties().getDeliveryTag(),false);}}
SpringBoot整合RabbitMQ
SpringBoot抽取了一个高级消息队列协议场景启动器spring-boot-starter-ampq,只需要引入该场景启动器就能快速使用RabbitMQ相关的内容我们在订单服务中整合使用
spring-boot-starter-ampq,订单服务有数据库表,是由renren-generator快速生成的
整合流程
引入依赖
xxxxxxxxxx<!--引入amqp场景启动器使用RabbitMQ--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-amqp</artifactId></dependency>开启使用RabbitMQ的功能
在配置类上使用注解
@EnableRabbit开启RabbitMQ的相关功能
配置RabbitMQ服务器信息
xxxxxxxxxx#配置RabbitMQ服务器地址spring.rabbitmq.host=192.168.56.10#配置RabbitMQ服务器的AMQP通信协议端口spring.rabbitmq.port=5672#配置RabbitMQ服务器的虚拟主机,只有一个虚拟主机就使用默认的/spring.rabbitmq.virtual-host=/#用户名和密码如果自己没有设置都会使用默认的guest
自动配置原理
自动配置原理
引入
amqp场景启动器自动配置类RabbitAutoConfiguration会自动生效,该自动配置类会自动给容器注入组件CachingConnectionFactory、RabbitTemplate、AmqpAdmin、RabbitMessagingTemplate
[
RabbitAutoConfiguration]xxxxxxxxxx({ RabbitTemplate.class, Channel.class })(RabbitProperties.class)(RabbitAnnotationDrivenConfiguration.class)public class RabbitAutoConfiguration {(ConnectionFactory.class)protected static class RabbitConnectionFactoryCreator {//这个是给Spring容器中放入RabbitMQ的连接工厂组件来获取与RabbitMQ服务器的连接public CachingConnectionFactory rabbitConnectionFactory(RabbitProperties properties,ObjectProvider<ConnectionNameStrategy> connectionNameStrategy) throws Exception {PropertyMapper map = PropertyMapper.get();CachingConnectionFactory factory = new CachingConnectionFactory(getRabbitConnectionFactoryBean(properties).getObject());map.from(properties::determineAddresses).to(factory::setAddresses);//连接工厂从properties即RabbitProperties中找到所有的连接信息,所有关于RabbitMQ连接信息都在RabbitProperties中封装着map.from(properties::isPublisherConfirms).to(factory::setPublisherConfirms);map.from(properties::isPublisherReturns).to(factory::setPublisherReturns);RabbitProperties.Cache.Channel channel = properties.getCache().getChannel();map.from(channel::getSize).whenNonNull().to(factory::setChannelCacheSize);map.from(channel::getCheckoutTimeout).whenNonNull().as(Duration::toMillis).to(factory::setChannelCheckoutTimeout);RabbitProperties.Cache.Connection connection = properties.getCache().getConnection();map.from(connection::getMode).whenNonNull().to(factory::setCacheMode);map.from(connection::getSize).whenNonNull().to(factory::setConnectionCacheSize);map.from(connectionNameStrategy::getIfUnique).whenNonNull().to(factory::setConnectionNameStrategy);return factory;}private RabbitConnectionFactoryBean getRabbitConnectionFactoryBean(RabbitProperties properties)throws Exception {PropertyMapper map = PropertyMapper.get();RabbitConnectionFactoryBean factory = new RabbitConnectionFactoryBean();map.from(properties::determineHost).whenNonNull().to(factory::setHost);map.from(properties::determinePort).to(factory::setPort);map.from(properties::determineUsername).whenNonNull().to(factory::setUsername);map.from(properties::determinePassword).whenNonNull().to(factory::setPassword);map.from(properties::determineVirtualHost).whenNonNull().to(factory::setVirtualHost);map.from(properties::getRequestedHeartbeat).whenNonNull().asInt(Duration::getSeconds).to(factory::setRequestedHeartbeat);RabbitProperties.Ssl ssl = properties.getSsl();if (ssl.isEnabled()) {factory.setUseSSL(true);map.from(ssl::getAlgorithm).whenNonNull().to(factory::setSslAlgorithm);map.from(ssl::getKeyStoreType).to(factory::setKeyStoreType);map.from(ssl::getKeyStore).to(factory::setKeyStore);map.from(ssl::getKeyStorePassword).to(factory::setKeyStorePassphrase);map.from(ssl::getTrustStoreType).to(factory::setTrustStoreType);map.from(ssl::getTrustStore).to(factory::setTrustStore);map.from(ssl::getTrustStorePassword).to(factory::setTrustStorePassphrase);map.from(ssl::isValidateServerCertificate).to((validate) -> factory.setSkipServerCertificateValidation(!validate));map.from(ssl::getVerifyHostname).to(factory::setEnableHostnameVerification);}map.from(properties::getConnectionTimeout).whenNonNull().asInt(Duration::toMillis).to(factory::setConnectionTimeout);factory.afterPropertiesSet();return factory;}}(RabbitConnectionFactoryCreator.class)protected static class RabbitTemplateConfiguration {private final RabbitProperties properties;private final ObjectProvider<MessageConverter> messageConverter;private final ObjectProvider<RabbitRetryTemplateCustomizer> retryTemplateCustomizers;public RabbitTemplateConfiguration(RabbitProperties properties,ObjectProvider<MessageConverter> messageConverter,ObjectProvider<RabbitRetryTemplateCustomizer> retryTemplateCustomizers) {this.properties = properties;this.messageConverter = messageConverter;this.retryTemplateCustomizers = retryTemplateCustomizers;}//给Spring容器中放入RabbitTemplate组件(ConnectionFactory.class)public RabbitTemplate rabbitTemplate(ConnectionFactory connectionFactory) {PropertyMapper map = PropertyMapper.get();RabbitTemplate template = new RabbitTemplate(connectionFactory);MessageConverter messageConverter = this.messageConverter.getIfUnique();//这个MessageConverter就是给消息对象做序列化的,会优先使用容器中获取MessageConverter类型的组件作为MessageConverter,如果容器中没有就会默认自己实例化一个SimpleMessageConverter对象来做序列化,消息转换器SimpleMessageConverter会对消息进行判断,如果消息对象是String类型,直接获取String类型的bytes数组,如果不是String类型且实现了Serializable接口就使用序列化工具SerializationUtils的serialize(object)将对象转换成bytes数组,即实际上序列化是MessageConverter在起作用if (messageConverter != null) {template.setMessageConverter(messageConverter);}template.setMandatory(determineMandatoryFlag());RabbitProperties.Template properties = this.properties.getTemplate();if (properties.getRetry().isEnabled()) {template.setRetryTemplate(new RetryTemplateFactory(this.retryTemplateCustomizers.orderedStream().collect(Collectors.toList())).createRetryTemplate(properties.getRetry(), RabbitRetryTemplateCustomizer.Target.SENDER));}map.from(properties::getReceiveTimeout).whenNonNull().as(Duration::toMillis).to(template::setReceiveTimeout);map.from(properties::getReplyTimeout).whenNonNull().as(Duration::toMillis).to(template::setReplyTimeout);map.from(properties::getExchange).to(template::setExchange);map.from(properties::getRoutingKey).to(template::setRoutingKey);map.from(properties::getDefaultReceiveQueue).whenNonNull().to(template::setDefaultReceiveQueue);return template;}private boolean determineMandatoryFlag() {Boolean mandatory = this.properties.getTemplate().getMandatory();return (mandatory != null) ? mandatory : this.properties.isPublisherReturns();}//给容器中添加AmqpAdmin组件(ConnectionFactory.class)(prefix = "spring.rabbitmq", name = "dynamic", matchIfMissing = true)public AmqpAdmin amqpAdmin(ConnectionFactory connectionFactory) {return new RabbitAdmin(connectionFactory);}}(RabbitMessagingTemplate.class)(RabbitMessagingTemplate.class)(RabbitTemplateConfiguration.class)protected static class MessagingTemplateConfiguration {//给容器中注入一个RabbitMessagingTemplate(RabbitTemplate.class)public RabbitMessagingTemplate rabbitMessagingTemplate(RabbitTemplate rabbitTemplate) {return new RabbitMessagingTemplate(rabbitTemplate);}}}[
RabbitProperties]所有关于RabbitMQ的配置都以
spring.rabbitmq作为前缀
xxxxxxxxxx(prefix = "spring.rabbitmq")public class RabbitProperties {/*** RabbitMQ host.*/private String host = "localhost";/*** RabbitMQ port.*/private int port = 5672;/*** Login user to authenticate to the broker.*/private String username = "guest";/*** Login to authenticate against the broker.*/private String password = "guest";/*** SSL configuration.*/private final Ssl ssl = new Ssl();/*** Virtual host to use when connecting to the broker.*/private String virtualHost;/*** Comma-separated list of addresses to which the client should connect.*/private String addresses;/*** Requested heartbeat timeout; zero for none. If a duration suffix is not specified,* seconds will be used.*/(ChronoUnit.SECONDS)private Duration requestedHeartbeat;/*** Whether to enable publisher confirms.*/private boolean publisherConfirms;/*** Whether to enable publisher returns.*/private boolean publisherReturns;/*** Connection timeout. Set it to zero to wait forever.*/private Duration connectionTimeout;/*** Cache configuration.*/private final Cache cache = new Cache();/*** Listener container configuration.*/private final Listener listener = new Listener();private final Template template = new Template();private List<Address> parsedAddresses;...}
AmqpAdmin
该对象可以帮助我们创建、销毁交换器、队列、绑定关系,简言之所有WEB管理客户端能做的操作都可以通过该对象实现,即使用Java代码创建删除交换器、队列并且为两者创建绑定关系
除了使用
AmqpAdmin来创建队列、交换器、绑定关系,SpringBoot还自动实现了当容器中使用@Bean注解注入队列、交换器、绑定关系组件如果RabbitMQ服务中没有就会自动创建,用户只需要向容器中注入对应的组件,无需再通过AmqpAdmin来创建队列、交换器或者绑定关系但是特别注意:通过将队列、交换器、绑定关系注入容器通过
SpringBoot自动在RabbitMQ服务器中创建的队列、交换器和绑定,一旦执行过一次在RabbitMQ服务器中有了同名的队列、交换器或者绑定关系,这些组件即使在SpringBoot中的配置发生了变化,比如更改了持久化策略、消息有效时间等配置参数,在系统重启初始化组件的时候不会对RabbitMQ中的同名队列、交换器或者绑定关系进行修改,RabbitMQ中的对应组件仍然会维持第一次创建时的配置,除非我们将RabbitMQ中的这些已经存在的同名队列、交换器、绑定关系手动删除再启动SpringBoot项目,系统才会重新在RabbitMQ服务器中创建更改了配置的队列、交换器和绑定关系,注意SpringBoot在RabbitMQ中创建容器组件对应的队列、交换器和绑定关系的时机是SpringBoot第一次连接开启消息监听的时候,注意只要有监听队列就会检查创建所有的容器组件中的队列、交换器和绑定关系,没有发送消息和接收消息只要绑定了监听队列就会将容器组件中所有的队列、交换器和绑定关系全部检查并创建出来注意RabbitMQ中手动删除队列、队列相关的绑定关系也会自动删除
API
void ---> amqpAdmin.declareExchange(Exchange exchange)功能解析:在RabbitMQ服务器中创建一个交换器
使用示例:
xxxxxxxxxx(SpringRunner.class)public class MallOrderApplicationTests {AmqpAdmin amqpAdmin;public void createExchange() {DirectExchange directExchange = new DirectExchange("mall-direct-exchange", true, false);amqpAdmin.declareExchange(directExchange);log.info("Exchange[{}]创建成功","mall-direct-exchange");}}示例含义:在RabbitMQ服务器中创建一个名为
mall-direct-exchange的直接交换器
补充说明:
交换器Exchange是一个接口,有一个抽象子类
AbstractExchange,该抽象子类有五个子实现类,分别为下列所示,通过这五个子实现类来创建对应类型的交换器DirectExchange:直接交换器全参构造为
public DirectExchange(String name, boolean durable, boolean autoDelete, Map<String, Object> arguments),分别表示交换器的名字、交换器是否设置为持久化、交换器是否自动删除以及为交换器指定键值对形式的参数,如果无需指定参数可以使用不带该参数的重载构造方法,默认也是创建的持久化交换器和非自动删除的交换器
HeadersExchange:Headers交换器FanoutExchange:扇出交换器TopicExchange:主题交换器CustomExchange:自定义交换器
void ---> amqpAdmin.declareQueue(Queue queue)功能解析:在RabbitMQ服务器中创建一个队列
使用示例:
xxxxxxxxxx(SpringRunner.class)public class MallOrderApplicationTests {AmqpAdmin amqpAdmin;public void createQueue() {Queue queue = new Queue("mall-hello-queue",true,false,false);amqpAdmin.declareQueue(queue);log.info("Queue[{}]创建成功","mall-hello-queue");}}示例含义:在RabbitMQ服务器中创建一个名为
mall-hello-queue的队列
补充说明:
队列Queue只是一个类,不是接口也没有子类,我们直接通过实例化Queue对象就能声明一个队列,注意这个Queue不是
java.util包下的,是org.springframework.amqp.core包下的队列全参构造
public Queue(String name, boolean durable, boolean exclusive, boolean autoDelete, Map<String, Object> arguments),参数分别为队列的名字、是否持久化、是否排他[排他是指该队列只能被一条连接独占,只要有一条连接连上了该队列,其他连接都连不上该队列,实际开发队列不应该是排他的,我们更希望多个客户端来连接同一条队列,只是最终只有一个客户端获取到消息],是否自动删除,为队列配置一些参数,如果不需要指定参数可以使用不带该参数的重载构造方法,注意这里的参数是队列的相关配置,参数示例列举如下队列中消息的最大存活时间,
队列的死信交换器,
死信消息的路由键等
void ---> amqpAdmin.declareBinding(Binding binding)功能解析:在RabbitMQ服务器中创建一个绑定关系
使用示例:
xxxxxxxxxx(SpringRunner.class)public class MallOrderApplicationTests {AmqpAdmin amqpAdmin;public void createBinding() {Binding binding = new Binding("mall-hello-queue",Binding.DestinationType.QUEUE,"mall-direct-exchange","hello rabbitmq",null);amqpAdmin.declareBinding(binding);log.info("Binding[{}]创建成功","mall-hello-binding");}}示例含义:在交换器
mall-direct-exchange和队列mall-hello-queue之间创建一个绑定关系
补充说明:
Binding也是一个类,没有子类
Binding的全参构造
public Binding(String destination, DestinationType destinationType, String exchange, String routingKey,Map<String, Object> arguments)参数
destination是目的地名字[这个目的地可以是队列名字也可以是交换器名字]DestinationType是目的地类型[目的地类型可以是交换器也可以是队列,这个DestinationType是一个枚举]exchange是我们要进行绑定的交换器名字RountingKey就是绑定关系中对应的Binding key要匹配消息的RoutingKey注意
Binding的构造不传参自定义参数必须要指定为null,没有对应不含该参数的构造
RabbitTemplate
该对象可以帮助我们向RabbitMQ服务器中发送消息,也可以从RabbitMQ服务器中获取消息
API
void ---> rabbitTemplate.convertAndSend(String exchange,String routingKey,Object object)功能解析:该方法将我们传入的object对象转换成字节流数据发送给RabbitMQ服务器中指定的交换器
使用示例:
xxxxxxxxxx(topic = "test.rabbitmq")(SpringRunner.class)public class MallOrderApplicationTests {RabbitTemplate rabbitTemplate;public void sendMessage(){OrderReturnReasonEntity returnReason = new OrderReturnReasonEntity();returnReason.setId(1L);returnReason.setCreateTime(new Date());returnReason.setName("guest");rabbitTemplate.convertAndSend("mall-direct-exchange","hello.rabbitmq",returnReason);log.info("消息[{}]发送成功",returnReason);}}示例含义:在RabbitMQ服务器中创建一个名为
mall-direct-exchange的直接交换器
补充说明:
rabbitTemplate有原生的send方法也可以发送消息,但是该方法需要传参被封装成Message类型的消息参数
exchange是交换机的名字,参数rounting key是消息的路由键,参数object是消息本身RabbitMQ队列中存储的消息的内容是被编码过的,默认的消息类型是
application/x-java-serialized-object即默认是使用的Java序列化器来进行的编码,这要求作为消息发送的对象对应的类必须实现了序列化接口Serializable序列化实际上是
amqp包下的MessageConverter在起作用,MessageConverter是一个接口,在抽象类AbstractMessageConverter中有一个子实现类AbstractJackson2JsonMessageConverter[注意Jackson2Json意思是通过Jackson转成json,2是to的谐音],注意AbstractMessageConverter中还有一个子实现类WhiteListDeserializingMessageConverter,默认配置的SimpleMessageConverter是WhiteListDeserializingMessageConverter的一个子类,要自定义序列化机制就要给容器注入一个MessageConverter组件,我们想将消息序列化成一个json对象就可以通过向容器注入一个AbstractJackson2JsonMessageConverter来实现这个感觉设计的很糟糕,该方法不返回任何值,发送消息失败比如没有创建绑定关系消息无法入队列不会报错没有返回值也不会抛异常,出了问题都不知道
定制消息序列化器
默认的序列化使用的是Java的序列化,需要消息对象实现了Serializable接口,这种序列化通过web管理控制台看起来不直观,也不跨语言平台,我们一般希望将消息对象序列化为json对象,这样能实现跨语言平台通信
原理
RabbitTemplate中的messageConverter就是给消息对象做序列化的,在自动配置类
RabbitAutoConfiguration中会优先从容器中获取MessageConverter类型的组件作为RabbitTemplate的MessageConverter,如果容器中没有就会默认自己实例化一个SimpleMessageConverter对象来做序列化,消息转换器SimpleMessageConverter会对消息进行判断,如果消息对象是String类型,直接获取String类型的bytes数组,如果不是String类型且实现了Serializable接口就使用序列化工具SerializationUtils的serialize(object)将对象转换成bytes数组,即序列化实际上是
amqp包下的MessageConverter在起作用,MessageConverter是一个接口,在抽象类AbstractMessageConverter中有一个子实现类AbstractJackson2JsonMessageConverter[注意Jackson2Json意思是通过Jackson转成json,2是to的谐音],注意AbstractMessageConverter中还有一个子实现类WhiteListDeserializingMessageConverter,默认配置的SimpleMessageConverter是WhiteListDeserializingMessageConverter的一个子类,要自定义序列化机制就要给容器注入一个
MessageConverter组件,我们想将消息序列化成一个json对象就可以通过向容器注入一个AbstractJackson2JsonMessageConverter来实现
配置步骤
向容器中注入
AbstractJackson2JsonMessageConverter来替代默认的SimpleMessageConverter来将消息对象序列化成json对象注意使用
AbstractJackson2JsonMessageConverter,在web管理端界面我们获取到消息后能观察到消息的content_type由原来的application/x-java-serialized-object变成了application/json而且在消息头中还有一个
_TypeId_字段,记录者消息的全限定类名
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 RabbitMQ客户端自定义配置* @创建日期 2024/11/01* @since 1.0.0*/public class MallRabbitConfig {/*** @return {@link MessageConverter }* @描述 给容器中注入一个使用Jackson将消息对象序列化为json对象的消息转换器* @author Earl* @version 1.0.0* @创建日期 2024/11/01* @since 1.0.0*/public MessageConverter messageConverter(){return new Jackson2JsonMessageConverter();}}
@RabbitListener
RabbitListener意思是RabbitMQ消息的监听器,作用是监听队列,该注解的属性queues是一个String类型的数组,可以指定要监听的必须存在的一个或者多个队列,只要队列中有消息,我们就可以获取到该消息注意该注解必须在主启动类上使用了注解
@EnableRabbit开启了RabbitMQ的相关功能才能正常使用,因为该注解的使用必须有@EnableRabbit注解相关的功能支持,而且目标队列必须存在实际上只是想给RabbitMQ创建交换器、队列、绑定关系、发消息可以不标注
@EnableRabbit注解,但是一旦想要监听队列中的消息就必须在配置类上添加@EnableRabbit注解该注解必须标注在容器组件的方法上才能起作用[验证一下是否必须标注在
@Service注解标注的类上],经过验证只要是组件就行,只要队列一有消息就会自动接收到消息并自动封装到参数列表中名为message的Object类型的参数中
监听消息并获取消息头和消息体
Body就是消息本身
messageProperties是消息属性,就是消息头中的属性值[即消息类型ID、消息内容类型等等]
这里我们用Object接受消息,实际上message的真正类型是
org.springframework.amqp.core.Message,因此我们直接将Object类型改成Message类型我们可以通过
byte[] body=message.getBody()获取消息体的内容,通过MessageProperties properties=message.getMessageProperties()获取消息头的属性
这种方式获取的消息体实际上是一个字节数组,我们要将其转换成指定对象需要使用FastJson这样的将JSON对象转换成实体类的解析工具
xxxxxxxxxx(queues = {"mall-hello-queue"})public void getMessage(Object message){System.out.println(message);//(Body:'{"id":1,"name":"guest","sort":null,"status":null,"createTime":1730433030106}' MessageProperties [headers={__TypeId__=com.earl.mall.order.entity.OrderReturnReasonEntity}, contentType=application/json, contentEncoding=UTF-8, contentLength=0, receivedDeliveryMode=PERSISTENT, priority=0, redelivered=false, receivedExchange=mall-direct-exchange, receivedRoutingKey=hello.rabbitmq, deliveryTag=1, consumerTag=amq.ctag-JWa106mr53fwD8CC1wmpmQ, consumerQueue=mall-hello-queue])System.out.println(message.getBody());//[B@6917b84fSystem.out.println(message.getMessageProperties());}监听消息并将消息体自动转换成消息对应类型
我们还可以参数列表通过指定消息的实际类型,让
Spring自动将消息体转换为对应的类型,因为消息头中保存了消息体的全限定类名,但是这个转换方法很有意思,应该不是使用的fastjson,我们对fastjson很熟悉,但是对这个转换方法不太清楚
xxxxxxxxxx(queues = {"mall-hello-queue"})public void getMessage(Message message, OrderReturnReasonEntity messageContent){byte[] body = message.getBody();MessageProperties messageProperties = message.getMessageProperties();System.out.println(messageContent);//OrderReturnReasonEntity(id=1, name=guest, sort=null, status=null, createTime=Fri Nov 01 12:11:12 CST 2024)}监听消息并获取信道
获取当前传输数据的信道,每个客户端只会与RabbitMQ建立一个连接,但是可以在一个连接内创建多个信道,该信道一般用在可靠性投递场景中
xxxxxxxxxx(queues = {"mall-hello-queue"})public void getMessage(Message message,OrderReturnReasonEntity messageContent,Channel channel){byte[] body = message.getBody();MessageProperties messageProperties = message.getMessageProperties();System.out.println(messageContent);//OrderReturnReasonEntity(id=1, name=guest, sort=null, status=null, createTime=Fri Nov 01 12:11:12 CST 2024)}注意
一个队列可以被很多个客户端监听,但是最后只有一个客户端能收到消息,只要有一个客户端收到消息队列就会删除消息,而且还会保证只能有一个客户端成功获取该消息
如果上述代码因为多个服务实例以上代码同时在三个服务实例中生效三个服务实例中的上述代码同时监听一个队列中的消息,最后也只会有一个服务实例成功获取到消息,弹幕说这个过程还可以应用负载均衡策略
卧槽,单元测试相当于新开一个服务实例,如果我们使用单元测试发送消息,消息发送出去单元测试的服务实例还没来得及销毁也会在期间监听并获取到消息
一个服务实例的一个监听消息方法获取消息的过程是加了锁的,只有当前服务实例获取到消息并完成执行完被标注方法才会释放锁,当前服务实例才能获取监听队列中的下一个消息并加锁执行被标注方法,即只有获取到一个消息并将被标注方法执行完,当前方法才能继续获取下一个消息
@RabbitListener除了标注在方法上还可以被标注在类上,但是@RabbitHandler只能标注在方法上实际开发中一般
@RabbitListener和@RabbitHandler一起使用,将@RabbitListener标注在类上依赖指明要监听的所有队列,将@RabbitHandler标注在方法上用来指明消息将要执行的方法,通过参数列表的参数封装类型和消息头中的全限定类名来匹配为同一个队列的不同封装类型的消息执行不同的指定业务方法,也可以实现不同的队列去执行各自消息封装类型作为参数的方法[实际我感觉这么用是多此一举,我完全可以在多个方法上都标注@RabbitListener注解嘛,这里在开发中再细细体会],不过@RabbitHandler标注在自定义重载方法上只是区分不同的消息封装类型处理方法倒也有点意思注意这里有个坑!必须给消息对象的封装类型提供一个无参构造器!否则会报错!
可靠性投递
RabbitMQ的消息确认是为了保证消息的可靠抵达,分布式集群系统中,多个微服务连接RabbitMQ收发消息,可能会出现由于网络闪断、运行实例和RabbitMQ服务器宕机都可能导致消息丢失[比如生产者发送消息由于网络波动RabbitMQ没收到消息、或者RabbitMQ收到消息但是消费者由于网络波动没有收到消息];因此在一些关键消息环节,我们都需要使用合适的方法来保证消息不会丢失,比如订单消息引起的对库存、积分、优惠计算、物流等等,这些消息千万不能丢,一丢就会导致经济纠纷,不论是生产者发送消息可靠抵达RabbitMQ,也不论是消费者接收消息都要保证消息的可靠抵达,如果出现了错误我们也必须要能知道哪些消息丢失
方案一:使用事务消息,我们可以设置连接中的信道是事务模式,只有消息从发出到消费者收到消息完整响应以后消息的发送才算成功,但是事务消息会导致性能的严重下降,官方文档描述性能会下降250倍,在
RabbitMQ-v3-12官方文档-英文的服务端文档下的Reliable Delivery可靠投递的Acknowledgements and Confirms的Publisher confirms发送者确认中提到使用标准AMQP协议,可以使用事务来保证消息不会丢失,事务的作用是让整个信道变成事务化的信道,每个消息的发布提交都是完整的事务,这是没必要的过重消耗,会导致吞吐量降低250倍,为了解决这种事务化通道导致的性能骤降,在AMQP协议中已有的ACK应答机制上发展出来发布者确认回调机制方案二:为了在分布式集群高并发系统下能快速确认哪些消息成功发送,哪些消息发送失败,我们引入了消息确认机制,在
RabbitMQ-v3-12官方文档-英文的服务端文档下的Reliable Delivery可靠投递,官方文档介绍可靠投递的作用是确保消息即使出现了任何错误信息我们也能感知到并保证消息总是被成功送达,可靠投递要同时保证生产者的消息可靠达到RabbitMQ服务器,RabbitMQ服务器发出的消息要可靠达到消费者,我们可以使用消息确认机制来高性能保证消息的可靠抵达
可靠性投递的消息投递流程
生产者发送消息给RabbitMQ服务器,RabbitMQ服务器收到消息后将消息交给交换器,交换器根据投递策略将消息传递给各个队列,这就是整个发送消息过程,在发送消息过程我们有两个发送者的确认回调[在消息投递的不同时机触发的回调函数]来保证消息的可靠发送
如果生产者的消息成功到达Broker就会触发生产者的确认回调
confirmCallback方法到达Broker的消息在交换器投递给队列的过程中也可能出现投递失败的情况,当消息被交换器没有成功投递到队列中时会触发第二个生产者的确认回调
returnCallback方法,如果成功投递给队列就不会触发该回调方法
被消费者监听的队列,只要队列收到消息后就会向消费者发送消息,从队列发出消息到消费者成功获取到消息这个过程就是消息接收过程,在消息接收过程我们有一个ack机制[acknowledge,就是消息确认应答机制]来保证接收消息的可靠抵达
ack机制能保证RabbitMQ服务器知道哪些消息都被消费者正确地接收到,如果消费者正确接收到消息,队列就会将对应的消息从队列中删除,如果消费者没有正确接收到消息,队列可能会采用将消息重新投递等兜底措施

confirmCallback开启生产者确认回调:通过创建
connectionFactory时设置PublisherConfirms(true)来设置开启confirmCallback回调,我们可以通过在配置文件中配置spring.rabbitmq.publisher-confirms=true来实现该功能,该配置项默认是false消息只要被Broker接收到就会执行
confirmCallback方法,如果是cluster即RabbitMQ集群模式,需要所有的Broker都接收到才会调用生产者的confirmCallback方法,这个回调类似于Ajax的回调是成功后自动回调回来的,即使当前系统没有任何消费者监听任何队列只要消息发出被RabbitMQ服务器成功接收就会触发该回调并执行回调对象confirmCallback的confirm方法,但是这同时意味着所有消息的发送确认回调执行方法都是一样的该回调只是保证消息成功到达
RabbitMQ服务器,并不能保证消息一定会被成功投递到目标队列也不能保证消息能被成功投递到消费者注意
ConfirmCallback实际上是RabbitTemplate中的一个接口,该接口中有一个confirm方法,当消息被RabbitMQ服务器成功接收就会执行用户自定义的回调方法confirm,该方法的参数列表中的correlationData是每个消息的唯一标识,ack表示消息是否被RabbitMQ服务器正确收到[true表示收到,false表示未被收到],cause表示消息没有被正常收到RabbitMQ服务器返回的原因;rabbitTemplate中有一个非空私有属性confirmCallback就是该接口的实例化对象,我们只要使用注解@PostConstruct在IoC容器初始化时将自定义的ConfirmCallback匿名实现实例化对象并调用rabbitTemplate的setConfirmCallback(ConfirmCallback confirmCallback)方法来将自定义的消息可靠发送确认回调设置到rabbitTemplate的属性confirmCallback中@PostConstruct注解标注的方法在该注解所在类对应的组件对象被实例化以后立即执行被该注解标注的方法correlationData:用来表示当前消息的唯一性,CorrelationData是一个类,里面用来标识唯一性的主要就是其中的id属性,我们发送消息时可以指定消息的唯一id,一般都是使用UUID,发送消息时我们可以调用rabbitTemplate.convertAndSend("mall-direct-exchange","hello.rabbitmq",returnReason);的重载方法void ---> rabbitTemplate.convertAndSend(String exchange,String rountingKey,Object message,CorrelationData correlationData)发送消息通过第四个参数指定消息的唯一标识,该标识将会被封装到发送端消息抵达确认的回调中作为消息的唯一标识,CorrelationData的单参构造就是封装其中的String类型的id属性,我们一般直接传参UUID,如果发送消息时没有指定CorrelationData回调时的参数CorrelationData就是null,实际开发中的用法一般是以上一步处理保存的数据与消息的关联关系的唯一标识作为消息的唯一标识,一旦发送消息过程消息丢失可以根据该标识再次组织消息重新发送或者定时扫描数据库哪些消息没有成功到达消息队列再重新发送
保证消息可靠性的方式之一,数据库日志记录,通过状态判断,投递失败的消息通过定时任务重新发布
开启步骤
1️⃣:配置配置项
spring.rabbitmq.publisher-confirms=true开启发送端消息抵达RabbitMQ服务器确认2️⃣:为
rabbitTemplate在容器初始化时配置我们自定义的ConfirmCallback实例化对象xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 RabbitMQ客户端自定义配置* @创建日期 2024/11/01* @since 1.0.0*/public class MallRabbitConfig {private RabbitTemplate rabbitTemplate;public void initRabbitTemplate(){/*1. 设置RabbitMQ服务器收到消息后的确认回调ConfirmCallback配置配置项spring.rabbitmq.publisher-confirms=true为rabbitTemplate设置回调实例化对象confirmCallback*/rabbitTemplate.setConfirmCallback(new RabbitTemplate.ConfirmCallback() {/*** @param correlationData 当前消息的唯一关联标识,里面的id就是消息标识的唯一id* @param ack 消息是否成功收到* @param cause 消息发送失败的原因* @描述 1. 只要消息抵达Broker就会触发该回调,与消费者和消息是否入队列无关* @author Earl* @version 1.0.0* @创建日期 2024/11/02* @since 1.0.0*/public void confirm(CorrelationData correlationData, boolean ack, String cause) {log.info("message confirm: {correlationData:"+correlationData+"ack:"+ack+"cause:"+cause+"}");}});}}
returnCallback消息正确抵达
RabbitMQ中的队列就会触发该回调,如果消息的路由键写错了无法匹配到队列、队列被删了、RabbitMQ集群是镜像集群,每个从节点的数据都是从主节点复制同步过来的,消息正常投递要求集群中的每个节点都得投递成功才行,只要有一个节点投递不成功投递也是失败的开启步骤
1️⃣:配置配置项
spring.rabbitmq.publisher-returns=true开启发送端消息抵达队列确认,注意是没有成功抵达队列才会触发该回调2️⃣:配置配置项
spring.rabbitmq.template.mandatory=true,该配置项的意思是只要消息没有成功抵达队列,以异步发送的方式优先回调returnConfirm,突出一个异步3️⃣:为
rabbitTemplate在容器初始化时配置我们自定义的ReturnConfirm实例化对象xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 RabbitMQ客户端自定义配置* @创建日期 2024/11/01* @since 1.0.0*/public class MallRabbitConfig {private RabbitTemplate rabbitTemplate;public void initRabbitTemplate(){/*2.设置RabbitMQ队列没有收到消息的确认回调ReturnCallback配置配置项spring.rabbitmq.publisher-returns=true配置配置项spring.rabbitmq.template.mandatory=true为rabbitTemplate设置回调实例化对象returnCallback* */rabbitTemplate.setReturnCallback(new RabbitTemplate.ReturnCallback() {/*** @param message 投递失败的消息本身的详细信息* @param replyCode 导致消息投递失败的错误状态码* @param replyText 导致消息投递失败的错误原因* @param exchange 当时该消息发往的具体交换器* @param routingKey 当时该消息的具体路由键* @描述* @author Earl* @version 1.0.0* @创建日期 2024/11/03* @since 1.0.0*/public void returnedMessage(Message message, int replyCode, String replyText, String exchange, String routingKey) {log.info("message lose: {message:"+message+"replyCode:"+replyCode+"replyText:"+replyText+"exchange:"+exchange+"routingKey"+routingKey);}});}}
returnCallback消费者消息可靠抵达的Ack消息确认机制,该机制的原理是一旦消费者从队列中获取到消息就会自动给RabbitMQ回复确认收到消息,该机制是AMQP协议中的机制,默认该机制就是开启的,一旦消费者收到消息就会自动给RabbitMQ服务器回复确认,RabbitMQ服务器收到确认队列中的消息就会被移除
❓:注意这种自动应答Ack的消息确认机制存在很严重的问题,假如队列中有5条消息,我们通过打断点的方式只处理一条消息,注意这里老师的意思是消息接收和处理是独立过程,消息是一次性被消费者接收并且只要接收到就自动回复了[
这里我不太理解,之前讲消息监听和接收时讲过一个服务实例只有在完整执行完标注了注解就只能解释为只要有多个服务实例,RabbitMQ会自动决定哪些消息去往那些消费者,不会根据消息者的实际处理情况来判断下一条消息去往那个消费者。除非消息没有成功到达消费者才会重新把消息入队列再次将消息发送给其中一个消费者,感觉这也很合理,比如限制接口的QPS,频率太高的请求会自动被拒绝处理,根本到不了接收消息的那一步,也就不会有Ack应答。而对消息的处理的串行化实际上是服务内部对处理消息的方法单独上锁,这个锁并不影响消息的接收],这里把消息的负载均衡看做是RabbitMQ服务器的内部决策,消息是只要服务器有接收能力就直接发送给服务器,不会等到上一条消息被处理完再发送下一条消息,消息处理的串行化是消费者运行实例内部的处理,只要消息一到达消费者,不管消息是否被处理,都会立即Ack应答RabbitMQ服务器,RabbitMQ会直接将队列中的消息直接删除,但是消费者对同一条队列的消息是串行化处理的,一旦消费者出现问题比如宕机、该服务实例无法处理该消息等原因,还没有被处理的消息就会因为没来得及处理直接丢失,此时消息队列无法收到消息还没有被处理的通知,队列中的消息也已经删了,就算收到了通知也无济于事@RabbitListener或者@RabbitHandler的方法以后才会接收处理下一个消息,试验也证明当前消息处理期间下一个消息不会被处理,多个服务实例消息会自动被负载均衡到其他服务实例,❓:弹幕指出打断点然后停止服务,断点后的代码还是会执行,需要使用
taskkill指令杀死进程,同时指出使用taskkill指令消息不会被自动确认,仍然留在消息队列中[这个确认时机还需要进一步明确]🔑:这里老师后面也发生了,确实手动停止服务,断点后面的代码还是会执行完,IDEA会把进程做完才关掉进程,因此这里服务器宕机会不会导致消息丢失还需要等明确自动Ack的应答时机才能确认
🔑:因为自动确认只要消息接收到了就会自动Ack应答即消息还没处理就应答,一旦消息处理过程中出现了服务实例自身没法解决的问题消息就会丢失[比如服务器宕机,当前服务由于外部问题无法根本无法处理某个消息],我们的解决办法是关闭Ack自动应答,采用Ack手动应答的方式在当前服务实例成功处理了某个消息在发起Ack成功应答删除队列中的消息;如果处理失败我们就Ack应答失败让队列重新投递消息或者直接丢弃消息
配置配置项关闭Ack应答的自动确认,开启Ack应答的手动确认
注意只是配置该配置项没有设置确认方法一条消息都不会确认,如果服务器此时宕机连接断开,这些处于
Unacked状态的消息会重新进入Ready状态,即手动确认是只要我们没有明确告诉RabbitMQ消息已经被签收,这些消息会一直处于Unacked状态,只要消费者和队列的连接断开,这些消息就会重新入队列,重新变成Ready状态
xxxxxxxxxx#手动ack消息spring.rabbitmq.listener.simple.acknowledge-mode=manual手动签收消息
channel.basicAck(long deliveryTag,boolean multiple)方法deliveryTag是当前消息的派发标签,是一个long类型的数字,这个数字从消息头MessageProperties的deliveryTag属性中,即message.getMessageProperties().getDeliveryTag()获取的,这个属性值最大的特点是在当前信道内是自增的,用来标识一条信道内传输的的消息multiple表示设置当前应答是批量应答还是只应答当前消息,为true表示批量应答[会一次性应答deliveryTag小于等于当前消息的所有消息],为false表示只应答当前消息该方法可能抛出异常,发生异常的原因是网络连接中断了
一般这个方法都在对消息的监听处理方法中通过参数列表获取
channel通过channel进行调用
手动拒绝签收消息
channel.basicNack(long deliveryTag,boolean multiple,boolean requeue)deliveryTag当前消息的派发标签,是Channel中消息的唯一凭证multiple是否批量应答,true会应答当前消息以前的所有消息requeue参数的意思是当前消息是否重新入队,即消息被手动拒收以后消息是否重新发回RabbitMQ,让RabbitMQ重新放到队列中,如果该参数设置为true即消息重新入队列,如果该参数设置为false消息会被直接丢弃,直接丢弃相当于Ack拒收队列中的消息也会直接删除没有调用签收或者拒绝签收方法的消息会一直处于
UnAcked状态,如果此时感知到与消费者连接中断,不管消费者将要对消息采取的拒绝策略是直接丢弃还是重新入队列,都是直接重新入队列
手动拒绝签收消息
channel.basicReject(long deliveryTag,boolean requeue)这个方法和
channel.basicNack(long deliveryTag,boolean multiple,boolean requeue)的效果是一样的,只是上面的方法可以选择是否批量拒绝,这个不能选择
订单服务
页面环境
4个订单相关页面、一个第三方支付页面
页面环境跳转
点击购物车的去结算按钮跳转订单确认页
在订单确认页点击提交订单跳转支付页
在支付页选择支付方式点击立即支付就会跳转支付页面
在个人用户中心能打开订单详情页和用户所有的订单列表页
页面逻辑
订单详情页逻辑
展示订单信息和订单状态
展示送货方式和物流信息
展示收货人信息、配送信息、付款信息
订单列表页
展示一段时间内的所有订单
每个订单展示订单的时间、订单号、商家信息、商品信息、收货人信息、支付金额、订单状态和订单可选操作[比如确认收货、催单和取消订单]
订单确认页
展示派送地址、收货人信息
可选支付方式[在线支付、货到付款]
送货商家、预计到达时间、商品详情
发票信息
可选优惠卡
结算金额
支付页
展示支付金额
选择支付方式点击支付跳转对应的支付页面
支付页面
第三方提供的支付页面,搭建对应的支付环境来实现
页面搭建
将页面和静态资源上传服务器并做好动静分离
完善页面跳转功能
配置本地域名解析
将订单服务相关的域名都设置到
order.earlmall.com,跳转到Nginx被转发到Gateway网关并被路由到mall-order服务[Nginx早就配置了所有除了静态资源的请求都被转发到网关]
写一个根据URL后缀动态跳转页面的接口,这个写法很秀啊
配置开发期间禁用
Thymeleaf的缓存功能,将订单服务加入注册中心,配置nacos为配置中心所有订单相关操作都会使用用户的登录状态,没有登录先去认证服务进行登录,通过
SpringSession从session中获取用户的登录信息来判断用户的登录状态,在订单服务中整合SpringSession即spring-session-data-redis,配置cookie序列化器和redis序列化器更改所有订单相关页面通过
Thymeleaf从分布式session取出用户的登录信息并展示在前端注意能访问订单相关页面用户一定是登录过的,否则会要求进行登录
配置线程池来调度所有异步代码。注意整个系统的线程池配置是相同的,即核心线程20个,最大线程200个,救急线程最大空闲时间10s
修改页面跳转逻辑
专门写一个web包来存放前台相关控制器
首页的我的订单跳转到订单列表页
购物车列表点击去结算跳转订单确认页
订单中心
电商系统涉及三种流,对应信息流[商品数据、优惠数据等等]、资金流[汇款兑款各种资金操作]、物流[货物的发货退货各种状态],订单的作用就是整合三种流的信息,把具有特定信息的意向商品查询到并生成付款单、付款单计算商品支付价格、发起一个物流发货过程,订单系统承载着对整个过程的梳理功能,业务比较复杂,也比较重要,需要从多个模块中获取数据,汇总这些数据进行加工再将加工结果流向下一个环节,实际上不要把订单看做下单时刻的瞬时动作,订单是用户购物车结算到用户收货确认的整个过程
完整的订单中心功能
订单中心需要整合的信息包含
用户信息:用户账号、会员等级、收货信息
订单信息:订单的下单信息,订单支付、物流、售后状态信息,父子订单[一个订单涉及到不同商家,需要分成多个物流来进行配送]
商品信息:商品销售属性、店铺信息、购买数量和价格信息
物流信息:商品物流公司、配送方式、物流单号和物流状态
支付信息:支付单号、支付状态、总支付金额、运费、优惠券信息、总优惠金额和实付金额
促销信息:促销活动、优惠券信息、虚拟币抵扣

订单服务相关的数据库表都在数据库
mall_oms中
订单状态
待付款:订单创建出来是待付款状态,用户在一定时间内可以发起付款,待付款状态下订单会对库存进行锁定,如果超过一定时间订单没有支付,订单会被自动取消,订单变成关闭状态;防止用户支付以后商品没货了引起经济纠纷
已付款:待付款的订单只要用户支付成功就变成已付款状态,已付款的订单需要记录订单支付时间、支付流水单号方便对账,已付款的订单需要和仓库系统联动,仓库进行调货、配货、分拣、出库等物流操作都要根据订单系统来决定,并在商品出库前一直处于已支付的状态
待收货:仓库将商品出库后订单进入物流环节,从此时开始订单就变成待收货状态,这个状态下的订单系统要同步物流信息,一旦用户确认收货,订单状态机会变成已完成状态
已完成:用户确认收货后订单交易完成,如果订单存在问题再进入售后状态
已取消:付款之前取消订单,包括用户超时未支付或者用户主动点击取消订单都会导致订单进入取消状态
售后状态:用户付款后申请退款,或者商家发货以后用户申请退换货,注意售后类似于一个完整的订单流程,称为售后订单,售后订单状态包含待审核、等待商家审核、商家审核通过订单状态变成待退货,等用户商品寄回以后售后订单状态变成待退款,退款到用户原账户后订单状态更新为订单完成
订单流程
订单的流程比较复杂,订单产生到订单完成牵扯到非常多的系统间的交互,包括与商品系统、优惠活动系统、用户系统、仓库系统、物流系统、支付系统、客服系统和评价系统;订单的业务类型也可能不同,有些订单是实物订单,有些订单是虚拟订单[比如冲话费],订单类型不同牵扯到的大流程也不同,但是一个订单必要的流程是购买商品和退换货流程。包括订单生成--订单支付--卖家发货--用户确认收货--交易成功,每个流程背后订单如何在系统间交互流转可以参考下图
这只是每个流程的核心环节,不是最详细的流程

订单生成
用户下单时我们还需要去商品中心查询商品的价格库存等信息、去营销中心去看商品有没有优惠信息、去会员中心查看用户有没有积分权益、去库存系统锁定库存[就是去占一个商品,相当于12306占个座],在订单待付款到已付款期间要保证该商品不会被其他人购买,库存锁定以后去物流服务计算运费,整合以上信息生成订单
生成订单以后,如果超时未支付或者支付失败要解锁库存,如果订单支付成功进入出库签收流程
出库签收
用户支付成功相当于给仓库系统下一个出库单,当商品真正出了库存以后才从库存中扣减对应商品数量的库存,此时物流服务接管商品的物流状态信息,订单系统实时同步这些物流状态信息,一旦用户签收且不退货,用户进入结单评论商品完成订单,如果用户要退货进入售后服务流程
售后服务
用户申请退货,客服审核退货申请,用户退货到仓库,确实到库以后更新库存,售后状态变成待退款,实时同步退款进程,退款完成售后结束
售后状态也比较复杂,可能是七天无理由退货,也可能保修,可能价保,可能维修等等状态,卧槽老师说这个系统不加入售后流程
幂等性处理
订单系统一定要特别注意幂等性处理,这个后面会详细介绍,就是防表单重复提交,实际上整个系统都要注意幂等性提交的问题
登录拦截
所有订单服务相关请求都必须判断用户是否登录过
配置拦截器
对订单服务下的所有请求的登录状态都进行判断
如果登录了就放行进行业务处理,如果用户登录了就从session中获取用户信息,将用户信息存入
ThreadLocal中来实现本次请求用户登录数据的线程内共享如果没登录就重定向登录界面进行登录操作,拦截器
return false是拦截当前请求,在拦截当前请求前先调用response.sendRedirect(),并给出提示信息放在session中
[拦截器]
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 用户登录状态拦截器* @创建日期 2024/11/09* @since 1.0.0*/public class LoginStatusInterceptor implements HandlerInterceptor {public static ThreadLocal<UserBaseInfoVo> loginUser=new ThreadLocal<>();public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {UserBaseInfoVo attribute = (UserBaseInfoVo)request.getSession().getAttribute(MallConstant.SESSION_USER_LOGIN_STATUS_KEY);if(attribute!=null){loginUser.set(attribute);return true;}else{request.getSession().setAttribute("tip","请先登录");response.sendRedirect("http://auth.earlmall.com/login.html");return false;}}}[注册拦截器]
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 定制化web服务器配置* @创建日期 2024/11/09* @since 1.0.0*/public class CustomWebMvcConfigurer implements WebMvcConfigurer {public void addInterceptors(InterceptorRegistry registry) {registry.addInterceptor(new LoginStatusInterceptor()).addPathPatterns("/**");}}
订单确认页
页面信息
收货人信息:收货人所有的收货地址列表、用户选择了收货地址以后需要展示用户地址
支付方式写死货到付款或者在线支付,实际上这里的支付只实现了一种方式
送货清单:送货清单显示用户订单中的所有商品和商品的最新价格,而不是商品加到购物车中的价格
发票信息不做
优惠抵扣信息做一个当前用户的积分抵扣,优惠信息需要查询优惠系统
封装页面视图数据
List<MemberAddressVo>封装所有收货地址列表,该数据从数据库mall_ums中的ums_member_receive_address表中按照会员id查询获取,每条数据都封装到MemberAddressVo中List<SelectedCartItemVo>封装了所有被选中商品的购物项信息,商品清单数据来源于购物车中被选中的商品,需要去购物车服务查询所有被选中的购物项,每个购物项的数据封装到SelectedCartItemVo,这个购物项的属性直接拷贝购物车列表中每个购物项的封装属性,注意啊,这里面的所有属性从购物车服务查询的时候就计算了总价数据,我们这里可以直接用@Data直接取值无需再次计算封装优惠券信息
优惠券信息这里整合一个会员积分,每一个用户数据库表中都保存着一个会员积分,直接用一个
Integer类型存储用户积分
封装价格明细
订单总价格[BigDecimal]
订单优惠总额[BigDecimal]
订单应付总额[BigDecimal]
[订单确认页视图数据封装]
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 订单结算页视图数据封装* @创建日期 2024/11/09* @since 1.0.0*/public class OrderStatementVo {/*** 用户所有可选择的地址列表*/private List<UserAddressVo> userAddresses;/*** 用户购物车中被选中的商品*/private List<SelectedCartItemVo> cartItems;/*** 用户积分*/private Integer userCredits;/*** 商品总价*/private BigDecimal totalPrice;/*** 优惠抵扣*/private BigDecimal discount=new BigDecimal("0.00");/*** 应付价格*/private BigDecimal payablePrice;/*** 采购数量*/private Integer purchaseQuantity;public BigDecimal getTotalPrice() {totalPrice=new BigDecimal("0.00");if(cartItems!=null){for (SelectedCartItemVo cartItem:cartItems){totalPrice=totalPrice.add(cartItem.getTotalPrice());}}return totalPrice;}public BigDecimal getPayablePrice(){payablePrice=totalPrice.subtract(discount);return payablePrice;}public Integer getPurchaseQuantity(){purchaseQuantity=0;if(cartItems!=null){for (SelectedCartItemVo cartItem:cartItems){purchaseQuantity+=cartItem.purchaseQuantity;}}return purchaseQuantity;}/*** 会员收货地址** @author Earl* @email 18794830715@163.com* @date 2024-01-27 11:47:58*/public static class UserAddressVo{/*** id*/private Long id;/*** member_id*/private Long memberId;/*** 收货人姓名*/private String name;/*** 电话*/private String phone;/*** 邮政编码*/private String postCode;/*** 省份/直辖市*/private String province;/*** 城市*/private String city;/*** 区*/private String region;/*** 详细地址(街道)*/private String detailAddress;/*** 省市区代码*/private String areacode;/*** 是否默认*/private Integer defaultStatus;}public static class SelectedCartItemVo {/*** 商品的skuId*/private Long skuId;/*** 商品的名字*/private String skuName;/*** 商品的默认图片*/private String skuDefaultImage;/*** 商品销售属性列表*/private List<String> skuAttrValues;/*** 商品单价*/private BigDecimal unitPrice;/*** 商品数量*/private Integer purchaseQuantity = 0;/*** 商品是否有货*/private Boolean hasStock = false;/*** 商品总价*/private BigDecimal totalPrice;}}
编写后端业务逻辑
逻辑流程图

调用用户服务来查询用户的收货地址列表
入参用户id,根据用户id查询所有符合的记录,查询结果封装为
List<MemberReceiveAddressEntity>
调用购物车服务获取用户购物车所有被选中的购物项
如果用户没有登录,直接返回
null,或者购物车服务有了获取临时购物车购物项的需求再实现,这里只实现用户登录以后的获取用户购物车中所有被选中的购物项数据要特别注意,这个购物项的价格不一定是最新的价格,因为这个购物项可能是用户几天前,甚至用户加了购物车看了几个月的价格,因此在生成订单的时候
这里实际上有缺陷,购物车的价格数据也不应该太陈旧,不过购物车不可能实时更新,所以生成订单的时候还是有必要实时查询商品的实时价格,避免出现经济纠纷
购物车服务通过远程调用商品服务传参商品的skuId列表,获取相应的商品最新单价,直接封装成实体类的List集合,暂时不要考虑特别不是像循环查库一样的炸裂性能问题,只要性能不是太炸裂,性能暂时都不要考虑
卧槽,这是个问题啊,
feign发起的网络请求如果不手动携带cookie,怎么使用用户的cookie,这里是根据商品的skuId查询商品最新价格无需用户的登录状态,但是购物车服务需要通过cookie从session中获取用户信息,远程Feign调用是如何携带请求头中的cookie的
用户积分,这个积分是直接从用户的登录信息中获取的,这也有点炸裂,万一用户几天浏览器没关过呢,管他呢,有人用再考虑
封装价格
总价通过遍历购物项,使用价格乘以数量
Lombok的
@Setter和@Getter注解可以直接标注在属性上,需要自定义getter方法的属性可以不标注注解自己重写,其他属性标注@Setter和@Getter注解
应付价格通过总价减去优惠价格
这里还没有做优惠价格计算,直接再次调用了一次总价计算
注意订单结算要调用第三方接口,假如网络很慢,导致用户以为卡了一直点击结算按钮发起多次结算请求,就会导致多次发起结算请求,为了防止用户多次提交结算请求,我们给用户的单次结算请求携带一个令牌来防重,直接给视图数据封装类封装一个
String类型的防重令牌属性orderToken防止支付请求重复提交,在讲幂等性的时候再仔细说
[订单登录状态检查拦截器]
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 用户登录状态拦截器* @创建日期 2024/11/09* @since 1.0.0*/public class LoginStatusInterceptor implements HandlerInterceptor {public static ThreadLocal<UserBaseInfoVo> loginUser=new ThreadLocal<>();public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {UserBaseInfoVo attribute = (UserBaseInfoVo)request.getSession().getAttribute(MallConstant.SESSION_USER_LOGIN_STATUS_KEY);if(attribute!=null){loginUser.set(attribute);return true;}else{request.getSession().setAttribute("tip","请先登录");response.sendRedirect("http://auth.earlmall.com/login.html");return false;}}}/*** @author Earl* @version 1.0.0* @描述 定制化web服务器配置* @创建日期 2024/11/09* @since 1.0.0*/public class CustomWebMvcConfigurer implements WebMvcConfigurer {public void addInterceptors(InterceptorRegistry registry) {registry.addInterceptor(new LoginStatusInterceptor()).addPathPatterns("/**");}}[控制器方法]
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 前台订单控制器* @创建日期 2024/11/09* @since 1.0.0*/public class OrderWebController {private OrderWebService orderWebService;("/statement.html")public String getOrderStatement(Model model){OrderStatementVo orderStatement=orderWebService.getOrderStatement();model.addAttribute("orderStatement",orderStatement);return "statement";}}[业务实现类]
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 订单前台业务实现类* @创建日期 2024/11/10* @since 1.0.0*/("orderWebService")public class OrderWebServiceImpl implements OrderWebService {private CartFeignClient cartFeignClient;private MemberFeignClient memberFeignClient;private ThreadPoolExecutor executor;/*** @return {@link OrderStatementVo }* @描述 获取封装订单确认页数据* @author Earl* @version 1.0.0* @创建日期 2024/11/10* @since 1.0.0*/public OrderStatementVo getOrderStatement() {UserBaseInfoVo userBaseInfo = LoginStatusInterceptor.loginUser.get();//6. 获取请求信息,准备在异步远程调用任务中给异步线程封装请求信息RequestAttributes requestAttributes = RequestContextHolder.getRequestAttributes();//3. 准备异步封装数据OrderStatementVo orderStatement = new OrderStatementVo();//1. 获取用户表中所有地址CompletableFuture<Void> addressFuture = CompletableFuture.runAsync(() -> {RequestContextHolder.setRequestAttributes(requestAttributes);List<OrderStatementVo.UserAddressVo> userAddresses = memberFeignClient.listByUserId(userBaseInfo.getId());orderStatement.setUserAddresses(userAddresses);},executor);//2. 获取用户购物车中被选中的购物项CompletableFuture<Void> cartFuture = CompletableFuture.runAsync(() -> {RequestContextHolder.setRequestAttributes(requestAttributes);List<OrderStatementVo.SelectedCartItemVo> selectedCartItems = cartFeignClient.getSelectedCartItem(userBaseInfo.getId());orderStatement.setCartItems(selectedCartItems);},executor);//4. 设置用户积分orderStatement.setUserCredits(userBaseInfo.getIntegration());//5. 等待异步任务执行完try {CompletableFuture.allOf(addressFuture,cartFuture).get();} catch (Exception e) {e.printStackTrace();}return orderStatement;}}[会员服务Feign远程调用客户端]
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 会员服务远程调用客户端* @创建日期 2024/11/11* @since 1.0.0*/("mall-user")public interface MemberFeignClient {/*** @return {@link R }* @描述 根据用户id查询用户所有收货地址* @author Earl* @version 1.0.0* @创建日期 2024/11/11* @since 1.0.0*/("user/memberreceiveaddress/get")List<OrderStatementVo.UserAddressVo> listByUserId(("userId") Long userId);}[购物车服务远程调用客户端]
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 购物车远程调用客户端* @创建日期 2024/11/10* @since 1.0.0*/("mall-cart")public interface CartFeignClient {/*** @param userId* @return {@link List }<{@link OrderStatementVo.SelectedCartItemVo }>* @描述 根据userId获取用户购物车中被选中的购物项* @author Earl* @version 1.0.0* @创建日期 2024/11/10* @since 1.0.0*/("/cart/selected/item")List<OrderStatementVo.SelectedCartItemVo> getSelectedCartItem(("userId") Long userId);}[远程调用数据传输封装类]
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 订单结算页视图数据封装* @创建日期 2024/11/09* @since 1.0.0*/public class OrderStatementVo {/*** 用户所有可选择的地址列表*/private List<UserAddressVo> userAddresses;/*** 用户购物车中被选中的商品*/private List<SelectedCartItemVo> cartItems;/*** 用户积分*/private Integer userCredits;/*** 商品总价*/private BigDecimal totalPrice;/*** 优惠抵扣*/private BigDecimal discount=new BigDecimal("0.00");/*** 应付价格*/private BigDecimal payablePrice;/*** 采购数量*/private Integer purchaseQuantity;public BigDecimal getTotalPrice() {totalPrice=new BigDecimal("0.00");if(cartItems!=null){for (SelectedCartItemVo cartItem:cartItems){totalPrice=totalPrice.add(cartItem.getTotalPrice());}}return totalPrice;}public BigDecimal getPayablePrice(){payablePrice=totalPrice.subtract(discount);return payablePrice;}public Integer getPurchaseQuantity(){purchaseQuantity=0;if(cartItems!=null){for (SelectedCartItemVo cartItem:cartItems){purchaseQuantity+=cartItem.purchaseQuantity;}}return purchaseQuantity;}/*** 会员收货地址** @author Earl* @email 18794830715@163.com* @date 2024-01-27 11:47:58*/public static class UserAddressVo{/*** id*/private Long id;/*** member_id*/private Long memberId;/*** 收货人姓名*/private String name;/*** 电话*/private String phone;/*** 邮政编码*/private String postCode;/*** 省份/直辖市*/private String province;/*** 城市*/private String city;/*** 区*/private String region;/*** 详细地址(街道)*/private String detailAddress;/*** 省市区代码*/private String areacode;/*** 是否默认*/private Integer defaultStatus;}public static class SelectedCartItemVo {/*** 商品的skuId*/private Long skuId;/*** 商品的名字*/private String skuName;/*** 商品的默认图片*/private String skuDefaultImage;/*** 商品销售属性列表*/private List<String> skuAttrValues;/*** 商品单价*/private BigDecimal unitPrice;/*** 商品数量*/private Integer purchaseQuantity = 0;/*** 商品是否有货*/private Boolean hasStock = false;/*** 商品总价*/private BigDecimal totalPrice;}}[远程调用请求拦截器]
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 自定义Feign远程调用配置* @创建日期 2024/11/12* @since 1.0.0*/public class CustomFeignConfig {("requestInterceptor")public RequestInterceptor requestInterceptor(){return template -> {/*这个从请求上下文保持器中获取请求对象的代码需要放在RequestInterceptor的apply方法中,否则从请求上下文保持器中获取请求的时候请求还没有来在服务初始化时获取不到请求对象会导致发生异常导致RequestInterceptor初始化失败进而导致Feign客户端初始化失败*/ServletRequestAttributes requestAttributes =(ServletRequestAttributes) RequestContextHolder.getRequestAttributes();HttpServletRequest request = requestAttributes.getRequest();template.header("cookie",request.getHeader("cookie"));};}}会员服务远程调用接口
[控制器方法]
xxxxxxxxxx/*** 会员收货地址** @author Earl* @email 18794830715@163.com* @date 2024-01-27 11:47:58*/("user/memberreceiveaddress")public class MemberReceiveAddressController {private MemberReceiveAddressService memberReceiveAddressService;/*** @return {@link R }* @描述 根据用户id查询用户所有收货地址* @author Earl* @version 1.0.0* @创建日期 2024/11/11* @since 1.0.0*/("/get")public List<MemberReceiveAddressEntity> listByUserId(Long userId){return memberReceiveAddressService.listByUserId(userId);}}[业务实现类]
xxxxxxxxxx("memberReceiveAddressService")public class MemberReceiveAddressServiceImpl extends ServiceImpl<MemberReceiveAddressDao, MemberReceiveAddressEntity> implements MemberReceiveAddressService {/*** @param userId* @描述 根据用户id查询用户所有的地址列表* @author Earl* @version 1.0.0* @创建日期 2024/11/11* @since 1.0.0*/public List<MemberReceiveAddressEntity> listByUserId(Long userId) {return list(new QueryWrapper<MemberReceiveAddressEntity>().eq("member_id", userId));}}购物车服务远程调用接口
[请求拦截器]
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 用户状态判断拦截器,购物车服务需要判断用户的登录状态* @创建日期 2024/10/25* @since 1.0.0*/public class UserStatusInterceptor implements HandlerInterceptor {public static ThreadLocal<UserInfoTo> threadLocal=new ThreadLocal<>();/*** @param request* @param response* @param handler* @return boolean* @描述 从session中获取用户数据,如果用户数据存在,封装用户的id信息* @author Earl* @version 1.0.0* @创建日期 2024/10/25* @since 1.0.0*/public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {UserInfoTo userInfo = new UserInfoTo();UserBaseInfoVo userBaseInfo = (UserBaseInfoVo)request.getSession().getAttribute(MallConstant.SESSION_USER_LOGIN_STATUS_KEY);if(userBaseInfo!=null){userInfo.setUserId(userBaseInfo.getId());}Cookie[] cookies = request.getCookies();if(cookies!=null && cookies.length>0){for (Cookie cookie : cookies) {if(CartConstant.USER_TEMP_IDENTITY_COOKIE_NAME.equals(cookie.getName())){userInfo.setUserKey(cookie.getValue());userInfo.setCookieExist(true);}}}if(!userInfo.getCookieExist()){userInfo.setUserKey(UUID.randomUUID().toString());}threadLocal.set(userInfo);return true;}/*** @param request* @param response* @param handler* @param modelAndView* @描述 如果cookie中没有名为user-key的cookie就添加该cookie* @author Earl* @version 1.0.0* @创建日期 2024/10/25* @since 1.0.0*/public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) throws Exception {UserInfoTo userInfo = threadLocal.get();if(!userInfo.getCookieExist()){response.addCookie(new Cookie(CartConstant.USER_TEMP_IDENTITY_COOKIE_NAME,userInfo.getUserKey()));}threadLocal.remove();}}[控制器方法]
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 购物车控制器* @创建日期 2024/10/25* @since 1.0.0*/("/cart")public class CartController {private CartService cartService;/*** @param userId* @return {@link List }<{@link CartItem }>* @描述 根据userId获取用户购物车中被选中的购物项* @author Earl* @version 1.0.0* @创建日期 2024/11/10* @since 1.0.0*/("/selected/item")public List<CartItem> getSelectedCartItem(Long userId){List<CartItem> selectedCartItem = cartService.getSelectedCartItem(userId);return selectedCartItem;}}[业务实现类]
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 购物车业务实现类* @创建日期 2024/10/25* @since 1.0.0*/("cartService")public class CartServiceImpl implements CartService {private StringRedisTemplate redisTemplate;private ProductFeignClient productFeignClient;private StockFeignClient stockFeignClient;private ThreadPoolExecutor executor;/*** @param userId* @return {@link List }<{@link CartItem }>* @描述 获取用户购物车中被选中的购物项,并调用商品服务和库存服务获取最新的价格和库存信息* @author Earl* @version 1.0.0* @创建日期 2024/11/10* @since 1.0.0*/public List<CartItem> getSelectedCartItem(Long userId) {UserInfoTo userInfo = UserStatusInterceptor.threadLocal.get();//1. 如果用户没有登录或者登录用户与查询用户不同直接返回空值if(userInfo.getUserId()==null || !userInfo.getUserId().equals(userId)){return null;}//2. 用户已经登录获取用户购物车数据BoundHashOperations<String, Object, Object> cartOperation = getCartOperation();List<CartItem> cartItems = getCartItem(cartOperation.values());List<CartItem> selectedCartItems = cartItems.stream().filter(cartItem -> cartItem.getSelected()).collect(Collectors.toList());//获取被选中商品的skuId列表List<Long> skuIds = selectedCartItems.stream().map(cartItem -> cartItem.getSkuId()).collect(Collectors.toList());//远程异步调用商品服务根据商品的skuId列表查询商品最新单价CompletableFuture<Void> priceFuture = CompletableFuture.runAsync(() -> {R priceRes = productFeignClient.getPriceOfSkuIds(skuIds);Map<Long, BigDecimal> priceOfSkuIds = priceRes.get("priceOfSkuIds", new TypeReference<Map<Long, BigDecimal>>() {});selectedCartItems.forEach(cartItem -> {cartItem.setUnitPrice(priceOfSkuIds.get(cartItem.getSkuId()));});},executor);//远程异步调用库存服务根据商品的skuId列表查询商品是否有货CompletableFuture<Void> stockFuture = CompletableFuture.runAsync(() -> {R stockRes = stockFeignClient.getStockStatusBySkuIds(skuIds);Map<Long, Boolean> stockStatusOfSkuIds = stockRes.get("stockStatusBySkuIds", new TypeReference<Map<Long, Boolean>>() {});//向被选中的购物项封装最新价格和库存状态selectedCartItems.forEach(cartItem -> {cartItem.setHasStock(stockStatusOfSkuIds.get(cartItem.getSkuId()));});},executor);try {//必须要带上get方法,没有get方法不会阻塞等待CompletableFuture.allOf(priceFuture,stockFuture).get();} catch (Exception e) {e.printStackTrace();}return selectedCartItems;}/*** @param items* @return {@link List }<{@link CartItem }>* @描述 将Redis中查询出来的字符串购物项封装成CartItem集合,方便后续取值* @author Earl* @version 1.0.0* @创建日期 2024/10/27* @since 1.0.0*/private List<CartItem> getCartItem(List<Object> items){if(items==null || items.size()==0){return null;}ArrayList<CartItem> cartItems = new ArrayList<>();for (Object item : items) {cartItems.add(JSON.parseObject(JSON.parse(JSON.toJSONString(item)).toString(), CartItem.class));}return cartItems;}/*** @return {@link BoundHashOperations }<{@link String }, {@link Object }, {@link Object }>* @描述 获取用户购物车,如果用户已登录获取用户购物车,如果用户没有登录获取用户临时购物车* @author Earl* @version 1.0.0* @创建日期 2024/10/25* @since 1.0.0*/private BoundHashOperations<String, Object, Object> getCartOperation(){UserInfoTo userInfo = UserStatusInterceptor.threadLocal.get();if(userInfo.getUserId()!=null){return redisTemplate.boundHashOps(CartConstant.USER_CART_IDENTITY_PREFIX + userInfo.getUserId());}BoundHashOperations<String, Object, Object> cartOperation = redisTemplate.boundHashOps(CartConstant.USER_CART_IDENTITY_PREFIX + userInfo.getUserKey());cartOperation.expire(CartConstant.TEMP_CART_EXPIRE, TimeUnit.SECONDS);return cartOperation;}}[商品服务价格查询远程调用接口]
xxxxxxxxxx/*** @param skuIds* @return {@link R }* @描述 根据商品的skuId列表获取商品的价格参数* @author Earl* @version 1.0.0* @创建日期 2024/11/10* @since 1.0.0*/("/batch/price")public R getPriceOfSkuIds(("skuIds") List<Long> skuIds){Map<Long, BigDecimal> priceOfSkuIds=skuInfoService.getPriceOfSkuIds(skuIds);return R.ok().put("priceOfSkuIds",priceOfSkuIds);}("skuInfoService")public class SkuInfoServiceImpl extends ServiceImpl<SkuInfoDao, SkuInfoEntity> implements SkuInfoService {/*** @param skuIds* @return {@link HashMap }<{@link Long }, {@link BigDecimal }>* @描述 根据商品的skuId列表获取商品的价格* @author Earl* @version 1.0.0* @创建日期 2024/11/10* @since 1.0.0*/public Map<Long, BigDecimal> getPriceOfSkuIds(List<Long> skuIds) {List<SkuInfoEntity> skuInfos = list(new QueryWrapper<SkuInfoEntity>().in("sku_id", skuIds));Map<Long, BigDecimal> priceOfSkuIds = skuInfos.stream().collect(Collectors.toMap(SkuInfoEntity::getSkuId, SkuInfoEntity::getPrice));for (Long skuId : skuIds) {if (priceOfSkuIds.get(skuId)==null) {priceOfSkuIds.put(skuId,null);}}return priceOfSkuIds;}}[库存服务库存状态查询远程调用接口]
xxxxxxxxxx/*** 商品库存** @author Earl* @email 18794830715@163.com* @date 2024-01-27 11:37:35*/("stock/waresku")public class WareSkuController {private WareSkuService wareSkuService;/*** @param skuIds* @return {@link R }* @描述 通过skuId列表* @author Earl* @version 1.0.0* @创建日期 2024/11/10* @since 1.0.0*/("/skuIds/status")public R getStockStatusBySkuIds( List<Long> skuIds){Map<Long,Boolean> stockStatusBySkuIds = wareSkuService.getStockStatusBySkuIds(skuIds);return R.ok().put("stockStatusBySkuIds",stockStatusBySkuIds);}}("wareSkuService")public class WareSkuServiceImpl extends ServiceImpl<WareSkuDao, WareSkuEntity> implements WareSkuService {private ProductFeignClient productFeignClient;/*** @param skuIds* @return {@link Map }<{@link Long }, {@link Boolean }>* @描述* @author Earl* @version 1.0.0* @创建日期 2024/11/10* @since 1.0.0*/public Map<Long, Boolean> getStockStatusBySkuIds(List<Long> skuIds) {List<WareSkuEntity> wareSkuInfos = list(new QueryWrapper<WareSkuEntity>().in("sku_id", skuIds));Map<Long, Boolean> stockStatusBySkuIds = wareSkuInfos.stream().collect(Collectors.toMap(WareSkuEntity::getSkuId,wareSkuEntity -> wareSkuEntity.getStock() != null && wareSkuEntity.getStock() > 0));for (Long skuId : skuIds) {if(stockStatusBySkuIds.get(skuId)==null){stockStatusBySkuIds.put(skuId,false);}}return stockStatusBySkuIds;}}
Feign远程调用携带cookie
众所周知,
Feign接口被自动注入的实现类是一个代理对象比如$Proxy101@8988,调用接口中的方法实际上调用的是Feign接口反射类ReflectiveFeign的invoke方法,具体执行见下面的源码解析
Feign远程调用源码解析以下只是
Feign远程调用会自己使用RequestTemplate构造请求,使用各种拦截器对请求进行增强,默认情况下RequestTemplate中的TreeMap类型的headers属性的大小是0,即根本不带任何请求头参数,用户请求的请求头信息一个都不会带,这样就导致了默认无法携带浏览器请求的请求头中携带的用于标识用户登录状态cookie,已经登录了的用户在远程调用中无法访问需要登录才能访问的远程接口通过打断点和分析源码我们知道,默认请求下,请求模板
RequestTemplate的请求头是空的,加强请求模板的拦截器集合也是空的,在构造请求前会遍历所有请求拦截器,挨个调用请求拦截器的apply(template)方法来对请求模板进行增强,然后再通过target.apply(template)来构造请求,这个拦截器是在构造Feign.Builder调用Builder中的实例方法requestInterceptor(RequestInterceptor requestInterceptor)传参requestInterceptor来构造的,因此我们只需要自定义一个RequestInterceptor[接口]的请求拦截器实现类,实现apply方法,为请求模板的headers属性添加请求头参数调用
synchronousMethodHandler.targetRequest(template)并在其中调用拦截器的apply方法的线程实际上就是处理当前用户请求的线程,我们想在当前用户请求线程中使用HttpServletRequest可以通过在控制器方法或者拦截器中将HttpServletRequest放在ThreadLocal中,通过ThreadLocal来取HttpServletRequest拿到请求头中的cookie或者其他请求头信息实际上
Spring考虑到了这个问题,专门抽取了一个RequestContextHolder请求上下文环境保持器,通过保持器的静态方法RequestContextHolder.getRequestAttributes()或者RequestContextHolder.currentRequestAttributes()可以拿到当前请求的所有属性[所有请求属性被封装成了RequestAttributes],实际上RequestContextHolder就是利用了ThreadLocal,而且其中很多个属性的类型都是Threadlocal我们将
RequestAttributes强转为ServletRequestAttributes,通过servletRequestAttributes.getRequest()方法可以获取到HttpServletRequest对象,我们可以通过该对象获取到所有的请求头数据并将请求的所有头数据同步到Feign远程调用构建的请求的头信息中,通过String cookie=httpServletRequest.getHeader("Cookie");取出老请求的cookie数据,通过requestTemplate.header("Cookie",cookie)给Feign远程调用请求的请求头中同步老请求的请求头中的cookie数据拦截器中有没有请求属性,请求属性中有没有请求都要进行判断,有才能同步
Feign的请求,否则什么都不要做,因为所有Feign请求都会执行这些操作,而且Feign请求还可能发起异步任务[不同的远程调用需要设置的数据类型不同,比如购物车服务需要登录状态,但是库存查询有无货不需要登录状态],情况很复杂,要做好冗余判断,通用的做法是让有对应数据的线程才给请求做对应的拦截配置,没有对应的数据就直接跳过对应的配置
xxxxxxxxxxReflectiveFeign.feignInvocationHandlerprivate final Map<Method, MethodHandler> dispatch;SynchronousMethodHandlerprivate final Target<?> target;private final List<RequestInterceptor> requestInterceptors;//上面这个拦截器列表属性是直接在SynchronousMethodHandler的构造器方法参数列表中传入的private SynchronousMethodHandler(Target<?> target, Client client, Retryer retryer,List<RequestInterceptor> requestInterceptors, Logger logger,Logger.Level logLevel, MethodMetadata metadata,RequestTemplate.Factory buildTemplateFromArgs, Options options,Decoder decoder, ErrorDecoder errorDecoder, boolean decode404,boolean closeAfterDecode, ExceptionPropagationPolicy propagationPolicy) {this.target = checkNotNull(target, "target");this.client = checkNotNull(client, "client for %s", target);this.retryer = checkNotNull(retryer, "retryer for %s", target);this.requestInterceptors =checkNotNull(requestInterceptors, "requestInterceptors for %s", target);this.logger = checkNotNull(logger, "logger for %s", target);this.logLevel = checkNotNull(logLevel, "logLevel for %s", target);this.metadata = checkNotNull(metadata, "metadata for %s", target);this.buildTemplateFromArgs = checkNotNull(buildTemplateFromArgs, "metadata for %s", target);this.options = checkNotNull(options, "options for %s", target);this.errorDecoder = checkNotNull(errorDecoder, "errorDecoder for %s", target);this.decoder = checkNotNull(decoder, "decoder for %s", target);this.decode404 = decode404;this.closeAfterDecode = closeAfterDecode;this.propagationPolicy = propagationPolicy;}//这个构造器是被SynchronousMethodHandler中的静态内部类Factory调用实例方法create创建的,create方法传参的是Factory中的requestInterceptors属性,是在构造Factory对象时传入的,而这个Factory对象是Feign.Builder在调用build方法时传参Builder类中的requestInterceptors属性传入的Feign.Builderprivate final List<RequestInterceptor> requestInterceptors = new ArrayList<RequestInterceptor>();//这个拦截器属性是通过调用Feign.Builder的requestInterceptor(RequestInterceptor requestInterceptor)方法传入的,这个requestInterceptor是从容器中获取的,因此我们只需要给容器中注入一个requestInterceptor组件就会将拦截器设置自动设置在每个Feign远程调用请求上---------------------------------------------------------------------------------------------------------ReflectiveFeign.feignInvocationHandler.invoke()public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {if ("equals".equals(method.getName())) {//检查被调用方法的方法名是不是Object类中继承来的equals、hashCode、toString方法,如果是就直接执行ReflectiveFeign类中的equals、hashCode、toString方法try {Object otherHandler =args.length > 0 && args[0] != null ? Proxy.getInvocationHandler(args[0]) : null;return equals(otherHandler);} catch (IllegalArgumentException e) {return false;}} else if ("hashCode".equals(method.getName())) {return hashCode();} else if ("toString".equals(method.getName())) {return toString();}return dispatch.get(method).invoke(args);1️⃣ //如果被远程调用方法的方法名不是equals、hashCode、toString方法,就执行dispatch.get(method)的invoke方法,dispatch.get(method)就是获取当前Feign客户端远程调用的方法}1️⃣ synchronousMethodHandler.invoke(args)public Object invoke(Object[] argv) throws Throwable {//这个参数argv就是我们远程调用方法的入参RequestTemplate template = buildTemplateFromArgs.create(argv);Retryer retryer = this.retryer.clone();//拿到重试器retryer,如果调用超时就会不断地重试,这个重试有最大次数while (true) {try {return executeAndDecode(template);1️⃣-1️⃣ //重试中调用的是同一个类的executeAndDecode(template)方法} catch (RetryableException e) {try {retryer.continueOrPropagate(e);} catch (RetryableException th) {Throwable cause = th.getCause();if (propagationPolicy == UNWRAP && cause != null) {throw cause;} else {throw th;}}if (logLevel != Logger.Level.NONE) {logger.logRetry(metadata.configKey(), logLevel);}continue;}}}1️⃣-1️⃣ synchronousMethodHandler.executeAndDecode(template)Object executeAndDecode(RequestTemplate template) throws Throwable {//template是事先准备的请求模板Request request = targetRequest(template);1️⃣-1️⃣-1️⃣ //通过模板构造出远程调用请求,Feign在远程调用前需要构造请求,构造请求需要调用很多的拦截器if (logLevel != Logger.Level.NONE) {logger.logRequest(metadata.configKey(), logLevel, request);}Response response;long start = System.nanoTime();try {response = client.execute(request, options);} catch (IOException e) {if (logLevel != Logger.Level.NONE) {logger.logIOException(metadata.configKey(), logLevel, e, elapsedTime(start));}throw errorExecuting(request, e);}long elapsedTime = TimeUnit.NANOSECONDS.toMillis(System.nanoTime() - start);boolean shouldClose = true;try {if (logLevel != Logger.Level.NONE) {response =logger.logAndRebufferResponse(metadata.configKey(), logLevel, response, elapsedTime);}if (Response.class == metadata.returnType()) {if (response.body() == null) {return response;}if (response.body().length() == null ||response.body().length() > MAX_RESPONSE_BUFFER_SIZE) {shouldClose = false;return response;}// Ensure the response body is disconnectedbyte[] bodyData = Util.toByteArray(response.body().asInputStream());return response.toBuilder().body(bodyData).build();}if (response.status() >= 200 && response.status() < 300) {if (void.class == metadata.returnType()) {return null;} else {Object result = decode(response);shouldClose = closeAfterDecode;return result;}} else if (decode404 && response.status() == 404 && void.class != metadata.returnType()) {Object result = decode(response);shouldClose = closeAfterDecode;return result;} else {throw errorDecoder.decode(metadata.configKey(), response);}} catch (IOException e) {if (logLevel != Logger.Level.NONE) {logger.logIOException(metadata.configKey(), logLevel, e, elapsedTime);}throw errorReading(request, response, e);} finally {if (shouldClose) {ensureClosed(response.body());}}}1️⃣-1️⃣-1️⃣ synchronousMethodHandler.targetRequest(template)//使用拦截器构造远程调用请求Request targetRequest(RequestTemplate template) {//这个RequestTemplate请求模版中有一个queries属性和headers属性,headers属性是一个TreeMap集合,就是我们构造远程请求的请求头和请求参数,在没有做任何设置的情况下,这个请求头的大小是0,即默认情况下Feign远程调用的请求,请求头中没有参数,自然也不会携带原始用户请求的cookie,也就在系统内部调用的时候无法携带cookie等请求参数for (RequestInterceptor interceptor : requestInterceptors) {//注意这个拦截器对Feign功能增强,如果没有对请求增强的功能,这个拦截器集合的大小为0,要增强的功能越多,这个拦截器集合中的拦截器数量也会越多interceptor.apply(template);//遍历请求拦截器,挨个调用拦截器的apply方法来设置请求模板}return target.apply(template);//使用拦截器设置好请求模板后,调用target.apply(template)方法来构造远程调用请求}
远程调用异步编排
异步编排Feign远程调用功能会出现的问题
使用我们的自定义线程池和
CompletableFuture异步编排我们的远程调用任务查询出订单确认页需要的各种信息注意这里异步编排
Feign远程调用又会出问题,这个异步导致执行远程调用的线程变了,同一个线程下共享请求数据的RequestContextHolder变成不同线程下不共享了,会导致拦截器中从RequestContextHolder请求上下文保持器中获取请求直接获取到空,从空的请求中获取请求头数据直接报空指针异常,这就是换了线程池的线程来执行异步任务无法从线程池中的线程获取到最初用户请求放入ThreadLocal中的请求信息,当前线程都不同了,也没有向ThreadLocal中添加过对应当前线程的请求属性,自然什么都取不到
解决办法
解决办法是在主线程中使用
RequestContextHolder.getRequestAttributes()获取请求属性,异步编排任务中,再执行一次RequestContextHolder.setRequestAttributes()给异步任务所在线程设置主线程的请求属性,即把之前主线程共享的数据在所有异步线程中都共享一次,但是没有说也没有做怎么移除异步线程的共享数据但是还有问题,设置请求属性是我们手动设置的,而且线程池中的线程肯定会复用,线程对应的
RequestContextHolder中的请求属性是否需要清除呢?或者每次执行异步任务重新设置会直接覆盖掉旧的请求属性呢controller远程被调用的方法一定要加上@ResponseBody或者直接加@RestController。就是返回对象一定要加@ResponseBody注解或者@RestController注解
代码示例
[配置请求拦截器携带cookie]
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 自定义Feign远程调用配置* @创建日期 2024/11/12* @since 1.0.0*/public class CustomFeignConfig {("requestInterceptor")public RequestInterceptor requestInterceptor(){return template -> {/*这个从请求上下文保持器中获取请求对象的代码需要放在RequestInterceptor的apply方法中,否则从请求上下文保持器中获取请求的时候请求还没有来在服务初始化时获取不到请求对象会导致发生异常导致RequestInterceptor初始化失败进而导致Feign客户端初始化失败*/ServletRequestAttributes requestAttributes =(ServletRequestAttributes) RequestContextHolder.getRequestAttributes();HttpServletRequest request = requestAttributes.getRequest();template.header("cookie",request.getHeader("cookie"));};}}[异步线程远程调用携带cookie的远程调用示例]
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 订单前台业务实现类* @创建日期 2024/11/10* @since 1.0.0*/("orderWebService")public class OrderWebServiceImpl implements OrderWebService {private CartFeignClient cartFeignClient;private MemberFeignClient memberFeignClient;private ThreadPoolExecutor executor;/*** @return {@link OrderStatementVo }* @描述 获取封装订单确认页数据* @author Earl* @version 1.0.0* @创建日期 2024/11/10* @since 1.0.0*/public OrderStatementVo getOrderStatement() {UserBaseInfoVo userBaseInfo = LoginStatusInterceptor.loginUser.get();//6. 获取请求信息,准备在异步远程调用任务中给异步线程封装请求信息RequestAttributes requestAttributes = RequestContextHolder.getRequestAttributes();//3. 准备异步封装数据OrderStatementVo orderStatement = new OrderStatementVo();//1. 获取用户表中所有地址CompletableFuture<Void> addressFuture = CompletableFuture.runAsync(() -> {RequestContextHolder.setRequestAttributes(requestAttributes);List<OrderStatementVo.UserAddressVo> userAddresses = memberFeignClient.listByUserId(userBaseInfo.getId());orderStatement.setUserAddresses(userAddresses);},executor);//2. 获取用户购物车中被选中的购物项CompletableFuture<Void> cartFuture = CompletableFuture.runAsync(() -> {RequestContextHolder.setRequestAttributes(requestAttributes);List<OrderStatementVo.SelectedCartItemVo> selectedCartItems = cartFeignClient.getSelectedCartItem(userBaseInfo.getId());orderStatement.setCartItems(selectedCartItems);},executor);//4. 设置用户积分orderStatement.setUserCredits(userBaseInfo.getIntegration());//5. 等待异步任务执行完try {CompletableFuture.allOf(addressFuture,cartFuture).get();} catch (Exception e) {e.printStackTrace();}return orderStatement;}}
页面数据渲染
遍历每一个地址列表并展示在收货人信息栏中
在每个地址的最前面显示收货人姓名,在姓名后面显示对应的住址,姓名已经在数据库表中的姓名字段中保存了,数据库表中还有一个字段标识默认地址
默认选中地址才高亮选中,否则不进行高亮,用户也可以自己选中,选中才高亮,我们给每个标签一个属性,属性值直接取数据库的默认地址,只有属性值为1的标签才进行高亮,高亮就是让p标签的边框变成红色,不高亮是灰色
$(".addr-item p").css("border":"2px soild gray")是选中所有class属性值以addr-item结尾的所有P标签,默认让所有标签在页面初始化时都是灰色,然后让$(".addr-item p[def='1']").css("border":"2px soild red")让所有class属性值以addr-item结尾的所有P标签中def属性值为1的标签的边框都变成红色,在文档加载完成时即$(document).ready(function(){})中调用对应的方法让其执行给所有地址标签设置点击事件,点击事件发生将原来被选中标签的
def属性设置成0[直接$(this).attr("def",0)把所有标签的def属性都设置为0],使用$(this).attr("def",1)被点击的标签的def属性设置为1,然后调用上面的设置标签样式的方法
[组件代码]
xxxxxxxxxx<!--地址--><div class="top-3 addr-receive" th:each="addressInfo:${orderStatement.userAddresses}"><p th:text="${addressInfo.name}"th:attr="selectedStatus=${addressInfo.defaultStatus},addrId=${addressInfo.id}" >家里</p><span>[[${addressInfo.name}]] [[${addressInfo.province}]] [[${addressInfo.city}]] [[${addressInfo.region}]] [[${addressInfo.detailAddress}]] [[${addressInfo.phone}]]</span></div><p class="yfze_b">寄送至: 北京 朝阳区 三环到四环之间 朝阳北路复兴国际大厦23层麦田房产 IT-中心研发二部 收货人:赵存权 188****5052</p>[对应的
JavaScript脚本]xxxxxxxxxx$(document).ready(function () {highlightAddress();queryFare();});function highlightAddress(){$(".addr-receive p").css({"border":"1px solid #E3E4E5"});$(".addr-receive p[selectedStatus='1']").css({"border":"2px solid red"});}$(".addr-receive p").click(function (){$(".addr-receive p[selectedStatus='1']").attr("selectedStatus",0);$(this).attr("selectedStatus",1);highlightAddress();queryFare();});function queryFare(){$.get("http://earlmall.com/api/ware/wareordertask/calculate/fare?addrId="+$(".addr-receive p[selectedStatus='1']").attr("addrId"),function (data){var userAddress = data.fare.userAddress;$(".yfze_b").text("寄送至: "+userAddress.province+" "+userAddress.city+" "+userAddress.region+" "+userAddress.detailAddress+" 收货人:"+userAddress.name+" "+userAddress.phone);calculateFareAndPayablePrice(data.fare.fare);})}function calculateFareAndPayablePrice(fare){$("#fare").text("¥ "+fare*1+".00");$(".hq").text("¥ "+([[${orderStatement.payablePrice}]]*1+fare*1)+".00");}点击事件发生我们调用后端接口来计算一下运费
给地址标签添加一个
addrId属性,通过被点击标签的addrId属性获取地址,实际上是通过用户的地址计算运费,但是老师这个实现太扯了,计算运费不只需要客户地址,还需要订单中的所有商品的skuId和件数,老师这里只传参了用户地址库存服务通过会员服务通过地址Id查询出用户具体的地址实体类
运费的结算需要调用快递公司的第三方接口,这个项目没有去实现,直接将用户手机号的最后一个数字作为快递费卧槽
发送Ajax请求来查询运费接口
xxxxxxxxxx$.get("http://earlmall.com/api/ware/warefare/fare?addrId="+addrId,function(data){console.log(data);})将选中地址对应运费展示在页面上
应付总额也应该加上用户的运费,我们通过
[[${orderConfirmData.total}]*1+data.data*1]来计算总费用,注意页面初始化也应该getFare($(".addr-item p[def='1']").attr("attrId"))调用物流接口算默认地址的运费,通过$("#payPriceEle").text([[${orderConfirmData.total}]*1+data.data*1])来显示总价格
xxxxxxxxxxfunction queryFare(){ $.get("http://earlmall.com/api/ware/wareordertask/calculate/fare?addrId="+$(".addr-receive p[selectedStatus='1']").attr("addrId"),function (data){ var userAddress = data.fare.userAddress; $(".yfze_b").text("寄送至: "+ userAddress.province+" "+ userAddress.city+" "+ userAddress.region+" "+ userAddress.detailAddress+" 收货人:"+ userAddress.name+" "+ userAddress.phone); calculateFareAndPayablePrice(data.fare.fare); }) } function calculateFareAndPayablePrice(fare){ $("#fare").text("¥ "+fare*1+".00"); $(".hq").text("¥ "+([[${orderStatement.payablePrice}]]*1+fare*1)+".00"); }遍历订单中的每个购物项展示每个商品
显示商品的标题、价格、数量,商品的有货状态[这个有无货应该在购物车就应该查询展示],查询价格的同时返回商品是否有货
有货无货设置为基本数据类型
boolean默认值是false,如果设置成Boolean类型是一个对象,不指定值是null弹幕提示可以使用
xxl-job来查询每个商品是否有货无货,有无货是通过查询库存系统查出来的,不是通过查询商品服务查出来的,以前写过这个接口,可以直接用,封装了一个VO类包含商品SkuId和有无货的Boolean标识,直接封装到视图数据对象的Map类型的属性中,直接从Map中通过key即skuId获取商品有货还是无货,Thymeleaf的写法是[[${orderConfirmData.stocks[item.skuId]?"有货":"无货"}]]
显示商品的重量,这个没做,实际上录入商品的时候就应该显示重量,方便物流统计,这里没做,只是展示常量值
xxxxxxxxxx<!--图片--><div class="yun1" th:each="product:${orderStatement.cartItems}"><!--<img style="width: 90px;height: 90px;margin: 10px;" th:src="${product.skuDefaultImage}" class="yun"/>--><img th:src="${product.skuDefaultImage}" class="yun"/><div class="mi"><p class="tui-1"><span th:text="${product.skuName}"> 小米(MI)小米手环2 智能运动 心率检测 来 </span><span style="color: red;" th:text="|¥ ${#numbers.formatDecimal(product.unitPrice,1,2)}|"> ¥ 149.00</span><span th:text="|x${product.purchaseQuantity}|"></span></p><p class="tui-1"><span th:text="${product.hasStock==true?'有货':'无货'}">有货</span><span>0.095kg</span></p><p class="tui-1"><img src="/static/order/statement/img/i_07.png"/>支持7天无理由退货</p></div></div>展示商品件数和各种价格
商品件数统计所有商品的件数之和
展示总金额
展示应付金额
根据前面选中的地址和收货人在这里展示被选中的地址和收货人
显示的地址直接用上面的Ajax请求查询的地址和收件人,雷神是直接将送货实体类整体作为一个属性封装到VO类了,包含了地址信息和收货人信息等
[组件]
xxxxxxxxxx<div class="qian"><p class="qian_y"><span th:text="${orderStatement.purchaseQuantity}">1</span><span>件商品,总商品金额:</span><span class="rmb" th:text="|¥ ${#numbers.formatDecimal(orderStatement.totalPrice,1,2)}|">¥28.90</span></p><p class="qian_y"><span>运费: </span><span class="rmb" id="fare">   ¥0.00</span></p></div><div class="yfze"><p class="yfze_a"><span class="z">应付总额:</span><span class="hq" th:text="|¥ ${#numbers.formatDecimal(orderStatement.payablePrice,1,2)}|">¥28.90</span></p></div>[计算运费和应付总价的脚本]
xxxxxxxxxxfunction calculateFareAndPayablePrice(fare){$("#fare").text("¥ "+fare*1+".00");$(".hq").text("¥ "+([[${orderStatement.payablePrice}]]*1+fare*1)+".00");}
提交订单
用户在订单确认页提交订单以后会在系统中生成一份订单,如果用户与服务器之间的网络不行,用户可能多次点击提交订单按钮导致生成多份订单,这样就可能导致一个用户一次确认订单导致生成多个内容相同的待支付订单,我们要避免用户这种因为多次提交导致和一次提交最后产生的结果不同的现象,即接口幂等性问题
接口幂等性问题的核心是要保证用户提交一次和提交一百次,最终产生的结果都是一样的,放在订单提交业务中就是用户不论点击多少次提交订单,最终系统中只会为本次订单确认生成一份订单;即用户对同一操作发起一次请求或者多次请求最终的结果是一致的;这种接口幂等性要求在支付场景会被高度重视,避免因为网络等各种问题用户多次点击按钮导致多次扣款;在系统的关键核心操作接口我们一定要保证幂等
无论是用户对接口的访问还是系统内部接口的远程调用,都可能导致接口的多次执行,比如用户点击了多次提交,系统内部远程调用一次不成功多次远程重试。
有些场景是天然幂等的,比如查询请求因为不写数据,查一次和查若干次查到的接口都是一样的;将某个确定内存的数据更新为固定值也是天然幂等的;删除某个确定内存的数据因为数据只有一份也是天然幂等性的;向某个确定内存插入相同数据也是天然幂等的,比如向一个主键插入数据执行多次,第二次及以后的插入操作会因为主键唯一数据库直接报错及后续操作无法执行也能保证天然幂等性
有些场景是不具备天然幂等性的,比如更新插入删除数据时数据内存的物理位置可能发生变化的情形
接口幂等性要防止多次提交的场景
用户多次点击提交按钮
用户页面回退再提交[提交成功后页面重定向,用户点击回退按钮再次点击提交]
微服务间的相互调用,比如由于网络问题导致请求失败[老师这里解释是不知道失败的原因是远程接口执行成功但是由于网络问题没有成功返回数据导致的重试还是远程接口没有执行导致的重试,如果远程接口执行成功但是由于网络问题没有成功返回数据导致的额重试就会存在接口幂等性问题],Feign触发重试机制
订单提交幂等性设计
方案一:让数据库
mall_oms的订单表oms_order的订单号字段order_sn添加唯一键索引,我们在生成订单前就指定订单号,让订单在数据库级别只会对同一块物理内存进行写操作,在数据库设计层面让订单是写操作幂等性的
接口幂等性方案
方案一:Token令牌机制
最常见的场景是验证码场景,比如买票锁定座位12306需要我们输入验证码,请求中只有验证码正确的情况下才能锁定座位成功,而且验证码使用一次就失效
应用在提交订单业务上我们可以在给用户响应订单确认页的同时下发一个Token令牌,服务器存储了该令牌,用户提交订单的时候携带该令牌,只要提交订单的请求携带了该令牌,我们就验证通过创建订单,只要一次验证令牌通过服务器就删除该令牌,用户的多次提交最终只有一个请求能验证通过
如何比较完美地执行验证令牌操作才能尽可能保证不出错,主要考虑是先删令牌再创建订单还是先创建订单再删除令牌,
如果是后删令牌问题非常大,前一个请求处于创建订单期间第二个请求就开始执行令牌验证操作,由于前一个请求订单还没创建令牌还没来得及删除,第二个请求会验证通过,此时第二个请求也会开始创建订单,因此我们一般首选先删令牌
如果是先删令牌
可能存在订单没有成功创建服务器宕机导致订单创建失败的问题;
同时分布式场景下服务器的令牌不会直接存在本地缓存,一般都是存在redis中,从Redis中存取数据就会存在延迟,此时如果两个请求间隔时间很短,两个请求都成功从Redis中获取到令牌,同时验证成功,也会发生接口的幂等性问题;因此我们一般会要求验证令牌时获取令牌、验证令牌和删除令牌三个操作是一个原子性操作,我们可以使用lua脚本
if redis.call('get',KEYS[1])==ARGV[1] then return redis.call('del',KEYS[1]) else return 0 end来保证三步操作的原子性,让验证操作直接在Redis中原子性一步执行
方案二:锁机制
数据库悲观锁
select * from xxx where id=1 for update;来使用数据库行级锁,悲观锁一般结合事务一起使用,定位记录的查询条件一定要设置成主键或者唯一键索引,否则很容易造成锁表,锁表处理起来非常麻烦
数据库乐观锁
数据库乐观锁
update t_goods set count=count-1,version=version+1 where goodId=2 and version=1;更适合更新场景,给数据库表添加一个版本字段,只有获取的数据版本和更新时的数据版本相同更新操作才会成功,更新操作会单增数据版本,只要一次数据成功更新,多次请求中后续到达的请求就无法再修改数据了[这种场景很适合库存数据的更新,比如第一次操作库存服务更新了库存数据并更新了版本号,但是操作库存数据的请求响应给订单服务时出现了网络问题,订单服务再次调用库存服务,但是订单服务最初获取的库存数据版本是旧的,库存数据的版本已经发生了更新,后续的重试不论执行多少遍都不会成功,我们可以使用额外信息来判断更新操作的具体订单,乐观锁适合读多写少的业务场景]
分布式锁
多台服务实例执行相同的写操作,我们对被操作对象上分布式锁,拿到锁的机器执行写操作,写的同时给数据一个标志位,当其他机器拿到锁以后先检查标志位发现数据已经发生了写操作就直接释放锁不再执行写操作了
方案三:唯一约束
唯一键索引:比如给用户的订单确认页下发唯一标识并保留在服务器内部,给该唯一标识对应的字段添加唯一索引,生成订单向数据库插入该唯一标识,只有第一次生成的订单数据因为唯一键索引能成功写入数据库,后续插入订单记录因为唯一键约束就会插入失败
Redis的set防重:数据只能被处理一次,我们可以在处理数据时计算数据的MD5并将MD5密文存入Redis的set中,每次处理数据前先检查一下数据的MD5是否已经存在,如果已经存在就不处理了,百度网盘的秒传功能就是这样的
方案四:防重表
上面的
Redis防重也算防重表的一种比如建立一个去重表,使用订单号
orderNo作为去重表的唯一键索引,将订单号插入去重表再做业务处理,保证订单号插入去重表和业务处理在同一个事务中;这样因为去重表中有订单号作为唯一键索引,多次提交的后续请求就会因为无法向去重表插入数据导致请求失败,业务处理不会执行;同时即使去重表数据插入成功,只要业务处理失败因为事务也会将去重表的数据回滚,让订单的后续重试能够继续进行因为要保证去重表和业务表的整体事务,需要将去重表和业务表放在同一个数据库中
方案五:给请求下发全局唯一标识ID
调用接口时我们可以给请求指定一个全局唯一的ID,接口处理该请求的时候将全局唯一的请求ID存储到Redis中,处理业务请求的时候如果发现该请求标识已经存在了我们就不再对该请求进行处理直接返回成功
这种请求全局唯一标识ID还可以做服务调用链路追踪,追踪请求经过了哪些服务
Nginx给每个请求分配唯一Id的配置
proxy_set_header X-Request-Id $request_id;,这个一般做链路追踪,不能做防重处理,因为Nginx给每个请求分配的全局唯一ID都是不一样的,即重复提交的每个请求Nginx都会给请求分配一个全局的唯一ID;我们自定义的请求可以参考这种思路给请求头设置一个全局唯一的请求标识ID,特别是做Feign的远程调用请求,重试的请求请求头中的唯一标识ID都是一样的
订单提交幂等性问题
我们采用
Token令牌机制来给订单确认页返回一个唯一令牌,并将该令牌存入Redis中,感觉存到session中最好,这样可以天然避免第三方恶意操作用户的订单token令牌
前端业务逻辑
我们给订单确认页返回一个
Token令牌,这里为了简单直接使用UUID,用一个type属性值为hidden的input框以token作为输入框的值来保存该Token令牌,这样能直接在表单提交时自动作为参数上传给分布式
session中即Redis中存放该Token令牌,这里为了避免发生恶意对Token令牌乱用,同时session自动就有有效时间,用户不关浏览器但是一段时间不操作Token令牌就会自动失效,用户没有确认订单关闭了浏览器Token令牌也会直接失效,老师是使用session中存储的用户id加token的名字的方式作为key存储的,value存储token本身xxxxxxxxxx//7. 设置用户提交订单的校验令牌String orderSubmitToken = UUID.randomUUID().toString().replace("-", "");redisTemplate.opsForValue().set(OrderConstant.ORDER_SUBMIT_TOKEN_PREFIX+":"+userBaseInfo.getId(),orderSubmitToken,OrderConstant.ORDER_SUBMIT_TOKEN_TTL,TimeUnit.MINUTES);orderStatement.setToken(orderSubmitToken);封装提交订单时上传的数据[为了防止前端数据上传恶意篡改导致的数据错误引起问题纠纷],给提交订单按钮做一个
form表单,所有要提交的数据都做成隐藏的input框,实际上该项目只提交了收货地址、订单最后价格、防重令牌封装用户收货地址的ID,页面初始化或者用户切换收货地址的时候将输入框的值进行回填
$("#addrIdInput").val(addrId)封装用户的支付方式
Integer商品无需提交,再去购物车获取一遍商品[京东也是这样做的,这样可以避免确认订单请求被恶意篡改,就是我们先调出订单确认页,此时已经计算了购物车中的选中商品价格,我们再修改购物车被选中商品,此时总价肯定发生了变化,我们在原来的订单确认页点击提交订单,我们发现最新的价格变成了购物车选中商品后的价格,这说明两个情况,第一是京东提交订单以后是重新获取购物车数据来计算最终价格的,第二是京东没有对订单确认页的商品金额做验价],重新计算金额
防重令牌,做接口幂等性校验,页面模板引擎渲染时赋值
封装订单确认页总价,提交订单后重新获取购物车商品数据计算价格以后对价格进行校验,如果校验通过说明购物车中被选中的商品在订单确认期间没有发生变化,如果校验没通过说明购物车中的商品发生了变化,我们可以通知用户购物车商品发生了变化,让用户注意一下,计算应付总价时赋值
订单备注信息,这个这里没实现,有需要再实现
xxxxxxxxxx<form method="post" action="/order/order/submit"><input type="hidden" name="addrId" id="addr-id"><input type="hidden" name="totalPrice" id="total-price"><input type="hidden" name="token" th:value="${orderStatement.token}"><button type="submit" class="tijiao">提交订单</button></form><script>function queryFare(){$.get("http://earlmall.com/api/ware/wareordertask/calculate/fare?addrId="+$(".addr-receive p[selectedStatus='1']").attr("addrId"),function (data){var userAddress = data.fare.userAddress;$(".yfze_b").text("寄送至: "+userAddress.province+" "+userAddress.city+" "+userAddress.region+" "+userAddress.detailAddress+" 收货人:"+userAddress.name+" "+userAddress.phone);$("#addr-id").val(userAddress.id);calculateFareAndPayablePrice(data.fare.fare);})}function calculateFareAndPayablePrice(fare){$("#fare").text("¥ "+fare*1+".00");$(".hq").text("¥ "+([[${orderStatement.payablePrice}]]*1+fare*1)+".00");$("#total-price").val([[${orderStatement.payablePrice}]]*1+fare*1);}</script>
后端创建订单逻辑
验证令牌,创建用户订单,校验价格,锁订单库存
下单成功跳转支付页
下单失败跳回订单确认页重新确认订单
创建订单逻辑
整体逻辑


视图逻辑
页面数据封装
订单信息
OrderEntity失败信息[重复提交请求、验价失败、库存不足]
Integer,我感觉抛异常更好将请求数据放到
ThreadLocal中可以在多个方法中线程安全地共享
创建订单失败重定向到订单确认页
创建订单重定向到
pay.html页面防止表单重复提交,订单数据存一份到session中方便用户随时取来支付
xxxxxxxxxx/*** @param orderParam* @return {@link String }* @描述 创建用户订单* @author Earl* @version 1.0.0* @创建日期 2024/11/30* @since 1.0.0*/("/order/submit")public String createOrder(OrderSubmitParamVo orderParam, HttpSession session, RedirectAttributes attributes){try{PayVo pay = orderWebService.createOrder(orderParam);session.setAttribute("pay",pay);return "redirect:http://order.earlmall.com/pay.html";}catch (RRException e){attributes.addFlashAttribute("error",e.getMsg());return "redirect:http://order.earlmall.com/statement.html";}}("/pay.html")public String getViewPage(){return "pay";}创建订单逻辑
主业务
[拦截器]
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 用户登录状态拦截器* @创建日期 2024/11/09* @since 1.0.0*/public class LoginStatusInterceptor implements HandlerInterceptor {public static ThreadLocal<UserBaseInfoVo> loginUser=new ThreadLocal<>();public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {UserBaseInfoVo attribute = (UserBaseInfoVo)request.getSession().getAttribute(MallConstant.SESSION_USER_LOGIN_STATUS_KEY);if(attribute!=null){loginUser.set(attribute);return true;}else{request.getSession().setAttribute("tip","请先登录");response.sendRedirect("http://auth.earlmall.com/login.html");return false;}}}[创建订单主业务]
xxxxxxxxxx/*** @param orderParam* @return {@link PayVo }* @描述 创建订单* @author Earl* @version 1.0.0* @创建日期 2024/11/30* @since 1.0.0*/public PayVo createOrder(OrderSubmitParamVo orderParam) throws RRException{UserBaseInfoVo userBaseInfo = LoginStatusInterceptor.loginUser.get();String orderSn = IdWorker.getTimeId();Long userId = userBaseInfo.getId();//1. 校验订单提交令牌,校验失败抛出表单重复提交异常if(!verifyOrderSubmitToken(userId,orderParam.getToken())){throw new RRException(StatusCode.FORM_REPEAT_EXCEPTION.getMsg(),StatusCode.FORM_REPEAT_EXCEPTION.getCode());}//2. 创建订单OrderEntity order = createOrder(userId, orderParam.getAddrId(),orderSn);//3. 创建订单项列表//远程调用购物车服务通过用户id获取购物车被选中的购物项List<OrderStatementVo.SelectedCartItemVo> selectedCartItems = cartFeignClient.getSelectedCartItem(userId);if(selectedCartItems==null || selectedCartItems.size()<=0){throw new RRException(StatusCode.NO_CART_ITEM_EXCEPTION.getMsg(),StatusCode.NO_CART_ITEM_EXCEPTION.getCode());}List<OrderItemEntity> orderItems = createOrderItems(orderSn,selectedCartItems);//4. 计算订单价格calculateOrderAmount(order,orderItems);//7. 验价if (Math.abs(order.getPayAmount().subtract(orderParam.getTotalPrice()).doubleValue())>=0.01) {throw new RRException(StatusCode.PRICE_VERIFY_EXCEPTION.getMsg()+"核算金额: ¥"+orderParam.getTotalPrice()+",实际金额: ¥"+order.getPayAmount(),StatusCode.PRICE_VERIFY_EXCEPTION.getCode());}//5. 保存订单记录和订单项记录orderService.save(order);//seata目前在AT模式下不支持批量插入记录,https://blog.csdn.net/qq_33240556/article/details/140790581,反正我们后面要换成软性事务,后面再换成批量插入for (OrderItemEntity orderItem : orderItems) {orderItemService.save(orderItem);}//orderItemService.saveBatch(orderItems);//6. 锁定库存LockStockTo lockStock = new LockStockTo();lockStock.setOrderId(order.getId());lockStock.setOrderSn(orderSn);lockStock.setConsignee(order.getReceiverName());lockStock.setConsigneeTel(order.getReceiverPhone());lockStock.setDeliveryAddress(order.getReceiverDetailAddress());lockStock.setPaymentWay(1);lockStock.setOrderItems(orderItems);R res = stockFeignClient.lockStock(lockStock);if (res.getCode()!=0) {throw new RRException((String) res.get("msg"),res.getCode());}PayVo pay = new PayVo();OrderVo orderVo = new OrderVo();BeanUtils.copyProperties(order,orderVo);List<OrderItemVo> orderItemVos = orderItems.stream().map(orderItem -> {OrderItemVo orderItemVo = new OrderItemVo();BeanUtils.copyProperties(orderItem, orderItemVo);return orderItemVo;}).collect(Collectors.toList());pay.setOrder(orderVo);pay.setOrderItems(orderItemVos);pay.setFare(order.getFreightAmount());pay.setPayablePrice(order.getPayAmount());return pay;}验证令牌
从
Redis中获取Token从
Redis中获取的令牌不为空,且该令牌和前端表单传参令牌相同则令牌校验通过令牌验证不通过直接返回
null令牌验证通过执行创建订单操作
验证通过首先从Redis中删除令牌
但是这种方式容易发生连续两次点击。第一次获取令牌速度慢,第二次获取令牌速度快,第二次请求在第一次请求还没来得及删除令牌前就获取到了令牌,第二次请求验证令牌也能成功;因此必须保证获取令牌、验证令牌以及删除令牌三步操作的原子性
我们通过Lua脚本
if redis.call('get',KEYS[1])==ARGV[1] then return redis.call('del',KEYS[1]) else return 0 end;如果指定令牌的值等于我们传递的值,就会将令牌删除并返回删除令牌的结果,删成功返回1,删失败或者对应令牌不存在返回0,如果令牌不相等直接返回0redisTemplate.execute(new DefaultRedisScript<Long>(script,Long.class),Arrays.asList(key1,key2),Object... val)在Redis中执行Lua脚本来保证原子验证令牌
xxxxxxxxxx/*** @param token* @return {@link Long }* @描述 校验并删除提交订单的令牌* @author Earl* @version 1.0.0* @创建日期 2024/11/30* @since 1.0.0*/private boolean verifyOrderSubmitToken(Long userId,String token){String key = OrderConstant.ORDER_SUBMIT_TOKEN_PREFIX + ":" + userId;String script = "if redis.call('get',KEYS[1])==ARGV[1] then return redis.call('del',KEYS[1]) else return 0 end";return redisTemplate.execute(new DefaultRedisScript<Long>(script, Long.class),Arrays.asList(key), token)==1;}令牌验证成功后创建订单记录
创建订单
创建封装订单关联订单表的相关所有数据的
OrderRelatedTo订单实体类
OrderEntity订单中的所有订单项
List<OrderItemEntity>,每个OrderItemEntity是订单中的一个商品订单应付总价
BigDecimal运费
BigDecimal
[远程调用获取订单物流信息]
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 库存远程调用服务* @创建日期 2024/11/30* @since 1.0.0*/("mall-stock")public interface StockFeignClient {/*** @param addrId* @return {@link R }* @描述 根据用户地址查询运费* @author Earl* @version 1.0.0* @创建日期 2024/12/01* @since 1.0.0*/("stock/wareordertask/calculate/fare")R calculateFare(("addrId") Long addrId);}/*** 库存工作单** @author Earl* @email 18794830715@163.com* @date 2024-01-27 11:37:35*/("stock/wareordertask")public class WareOrderTaskController {private WareOrderTaskService wareOrderTaskService;/*** @return {@link R }* @描述 计算运费* @author Earl* @version 1.0.0* @创建日期 2024/11/13* @since 1.0.0*/("/calculate/fare")public R calculateFare(Long addrId){FareVo fare = wareOrderTaskService.calculateFare(addrId);return R.ok().put("fare",fare);}}/*** @param addrId* @return {@link FareVo }* @描述 这里只是简单地假装算了一下运费,实际上的运费计算需要调用第三方接口* @author Earl* @version 1.0.0* @创建日期 2024/11/13* @since 1.0.0*/public FareVo calculateFare(Long addrId) {//准备封装返回数据的对象FareVo fare = new FareVo();//1. 调用远程服务根据收货地址id查询用户收货地址R res = userFeignClient.info(addrId);FareVo.UserAddressVo userAddress = res.get("memberReceiveAddress", new TypeReference<FareVo.UserAddressVo>() {});fare.setUserAddress(userAddress);//2,计算运费String phone = userAddress.getPhone();fare.setFare(new BigDecimal(phone.charAt(phone.length()-1)+".00"));return fare;}/*** @author Earl* @version 1.0.0* @描述 用户服务远程客户端* @创建日期 2024/11/13* @since 1.0.0*/("mall-user")public interface UserFeignClient {("user/memberreceiveaddress/info/{id}")R info(("id") Long id);}/*** 会员收货地址** @author Earl* @email 18794830715@163.com* @date 2024-01-27 11:47:58*/("user/memberreceiveaddress")public class MemberReceiveAddressController {/*** 信息*/("/info/{id}")////@RequiresPermissions("user:memberreceiveaddress:info")public R info(("id") Long id){MemberReceiveAddressEntity memberReceiveAddress = memberReceiveAddressService.getById(id);return R.ok().put("memberReceiveAddress", memberReceiveAddress);}}public class ServiceImpl<M extends BaseMapper<T>, T> implements IService<T> {public T getById(Serializable id) {return baseMapper.selectById(id);}}生成订单实体类
使用
MyBatis的IdWorker.getTimeId()生成一个唯一的商品订单ID,该订单ID是Time+ID把数据库
oms_order表的order_sn字段的长度设置为64位,因为订单号字符比较长,32位字符不够
将订单状态信息抽取为枚举类,在订单实体类中保存当前的订单状态为待付款
xxxxxxxxxxpackage com.atguigu.gulimall.order.enume;public enum OrderStatusEnum {CREATE_NEW(0,"待付款"),PAYED(1,"已付款"),SENDED(2,"已发货"),RECIEVED(3,"已完成"),CANCLED(4,"已取消"),SERVICING(5,"售后中"),SERVICED(6,"售后完成");private Integer code;private String msg;OrderStatusEnum(Integer code, String msg) {this.code = code;this.msg = msg;}public Integer getCode() {return code;}public String getMsg() {return msg;}}将当前用户Id存储到订单表的
member_id字段,auto_confirm_day自动确认收货间隔int类型字段设置为7设置订单的删除状态为0,0表示未删除
收货人和地址信息,这些信息来源于用户服务的用户地址
根据用户的地址Id远程调用用户服务得到订单收货人的地址信息和物流费用
设置订单物流的运费
收货人城市、详细地址、收货人名字、收货人手机号、邮编、省、区、
xxxxxxxxxx/*** @param userId* @param addrId* @return {@link OrderEntity }* @描述 创建订单实体类* @author Earl* @version 1.0.0* @创建日期 2024/11/30* @since 1.0.0*/private OrderEntity createOrder(Long userId,Long addrId,String orderSn){OrderEntity order = new OrderEntity();order.setOrderSn(orderSn);order.setStatus(OrderConstant.OrderStatus.CREATE_NEW.getCode());order.setMemberId(userId);R res = stockFeignClient.calculateFare(addrId);FareVo fare = res.get("fare", new TypeReference<FareVo>() {});order.setFreightAmount(fare.getFare());FareVo.UserAddressVo userAddress = fare.getUserAddress();order.setReceiverCity(userAddress.getCity());order.setReceiverDetailAddress(userAddress.getDetailAddress());order.setReceiverName(userAddress.getName());order.setReceiverPhone(userAddress.getPhone());order.setReceiverPostCode(userAddress.getPostCode());order.setReceiverProvince(userAddress.getProvince());order.setReceiverRegion(userAddress.getRegion());order.setAutoConfirmDay(OrderConstant.AUTO_SIGNED_CONFIRM_DAY);order.setDeleteStatus(0);return order;}生成订单项列表
远程调用购物车服务获取所有被选中的购物项数据
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 购物车远程调用客户端* @创建日期 2024/11/10* @since 1.0.0*/("mall-cart")public interface CartFeignClient {/*** @param userId* @return {@link List }<{@link OrderStatementVo.SelectedCartItemVo }>* @描述 根据userId获取用户购物车中被选中的购物项* @author Earl* @version 1.0.0* @创建日期 2024/11/10* @since 1.0.0*/("/cart/selected/item")List<OrderStatementVo.SelectedCartItemVo> getSelectedCartItem(("userId") Long userId);}/*** @author Earl* @version 1.0.0* @描述 购物车控制器* @创建日期 2024/10/25* @since 1.0.0*/("/cart")public class CartController {private CartService cartService;/*** @param userId* @return {@link List }<{@link CartItem }>* @描述 根据userId获取用户购物车中被选中的购物项* @author Earl* @version 1.0.0* @创建日期 2024/11/10* @since 1.0.0*/("/selected/item")public List<CartItem> getSelectedCartItem(Long userId){List<CartItem> selectedCartItem = cartService.getSelectedCartItem(userId);return selectedCartItem;}}/*** @param userId* @return {@link List }<{@link CartItem }>* @描述 获取用户购物车中被选中的购物项,并调用商品服务和库存服务获取最新的价格和库存信息,这是复用方法,中间过程略掉* @author Earl* @version 1.0.0* @创建日期 2024/11/10* @since 1.0.0*/public List<CartItem> getSelectedCartItem(Long userId) {UserInfoTo userInfo = UserStatusInterceptor.threadLocal.get();//1. 如果用户没有登录或者登录用户与查询用户不同直接返回空值if(userInfo.getUserId()==null || !userInfo.getUserId().equals(userId)){return null;}//2. 用户已经登录获取用户购物车数据BoundHashOperations<String, Object, Object> cartOperation = getCartOperation();List<CartItem> cartItems = getCartItem(cartOperation.values());List<CartItem> selectedCartItems = cartItems.stream().filter(cartItem -> cartItem.getSelected()).collect(Collectors.toList());//获取被选中商品的skuId列表List<Long> skuIds = selectedCartItems.stream().map(cartItem -> cartItem.getSkuId()).collect(Collectors.toList());//远程异步调用商品服务根据商品的skuId列表查询商品最新单价CompletableFuture<Void> priceFuture = CompletableFuture.runAsync(() -> {R priceRes = productFeignClient.getPriceOfSkuIds(skuIds);Map<Long, BigDecimal> priceOfSkuIds = priceRes.get("priceOfSkuIds", new TypeReference<Map<Long, BigDecimal>>() {});selectedCartItems.forEach(cartItem -> {cartItem.setUnitPrice(priceOfSkuIds.get(cartItem.getSkuId()));});},executor);//远程异步调用库存服务根据商品的skuId列表查询商品是否有货CompletableFuture<Void> stockFuture = CompletableFuture.runAsync(() -> {R stockRes = stockFeignClient.getStockStatusBySkuIds(skuIds);Map<Long, Boolean> stockStatusOfSkuIds = stockRes.get("stockStatusBySkuIds", new TypeReference<Map<Long, Boolean>>() {});//向被选中的购物项封装最新价格和库存状态selectedCartItems.forEach(cartItem -> {cartItem.setHasStock(stockStatusOfSkuIds.get(cartItem.getSkuId()));});},executor);try {//必须要带上get方法,没有get方法不会阻塞等待CompletableFuture.allOf(priceFuture,stockFuture).get();} catch (Exception e) {e.printStackTrace();}return selectedCartItems;}如果获取到的购物项数据不为
null且集合大小大于0,遍历购物项数据,封装订单项数据,每条订单项数据分别包含订单号、当前订单项商品对应的spu信息[spuId、spuName、品牌Id、商品分类id],sku信息[skuId、skuName、sku图片、sku价格、商品购买数量、商品销售属性组合]、购买商品获取的成长值[gift_growth]或者积分[gift_integration,都应该使用当前商品所有数量对应的总价],所属订单号OrderSn、订单项的促销价格promotionAmount[设置为0]、商品使用的优惠券优惠价格couponAmount[设置为0]、积分优惠integrationAmount[设置为0]、商品总价realAmount[设置为sku单价乘以商品数量减去三种优惠价格]sku信息直接从购物车服务的被选中的购物项中直接获取,销售属性组合是集合的形式,可以通过String.join(";",cartItem.getSkuAttrValues())或者StringUtils.collectionToDelimitedString(cartItem.getSkuAttrValues(),";")我们直接把价格的整数部分作为成长值和积分
根据
skuId列表去调用远程服务查询商品对应的所有spu信息[去skuInfo表查询skuId对应的spuId,再根据spuId去spuInfo表查询spu信息],老师这里循环Feign远程调用,每个调用里面去两次查询数据库,非常要命xxxxxxxxxx<select id="getSpuInfoBySkuIds" resultType="com.earl.mall.product.to.OrderItemSpuTo">SELECT skui.sku_id,skui.spu_id,spui.catelog_id,spui.brand_id,spui.spu_name,b.name as brand_nameFROM pms_sku_info skuiLEFT JOIN pms_spu_info spui on skui.spu_id = spui.idLEFT JOIN pms_brand b on skui.brand_id = b.brand_idWHERE skui.sku_id in<foreach collection="skuIds" item="sku_id" separator="," open="(" close=")">#{sku_id}</foreach>Group BY sku_id</select>
优惠只使用了积分,其他优惠信息不做
xxxxxxxxxx/*** @param orderParam* @return {@link PayVo }* @描述 创建订单* @author Earl* @version 1.0.0* @创建日期 2024/11/30* @since 1.0.0*/public PayVo createOrder(OrderSubmitParamVo orderParam) throws RRException{UserBaseInfoVo userBaseInfo = LoginStatusInterceptor.loginUser.get();String orderSn = IdWorker.getTimeId();Long userId = userBaseInfo.getId();...//3. 创建订单项列表//远程调用购物车服务通过用户id获取购物车被选中的购物项List<OrderStatementVo.SelectedCartItemVo> selectedCartItems = cartFeignClient.getSelectedCartItem(userId);if(selectedCartItems==null || selectedCartItems.size()<=0){throw new RRException(StatusCode.NO_CART_ITEM_EXCEPTION.getMsg(),StatusCode.NO_CART_ITEM_EXCEPTION.getCode());}List<OrderItemEntity> orderItems = createOrderItems(orderSn,selectedCartItems);...}/*** @param orderSn* @return {@link List }<{@link OrderItemEntity }>* @描述 创建订单项数据* @author Earl* @version 1.0.0* @创建日期 2024/12/01* @since 1.0.0*/private List<OrderItemEntity> createOrderItems(String orderSn,List<OrderStatementVo.SelectedCartItemVo> selectedCartItems) throws RRException{List<Long> skuIds = selectedCartItems.stream().map(OrderStatementVo.SelectedCartItemVo::getSkuId).collect(Collectors.toList());//根据skuId列表查询spu信息列表Map<Long, OrderItemSpuTo> spuInfo = productFeignClient.getSpuInfoBySkuIds(skuIds).stream().collect(Collectors.toMap(OrderItemSpuTo::getSkuId, OrderItemSpuTo -> OrderItemSpuTo));return selectedCartItems.stream().map(cartItem -> {OrderItemEntity orderItem = new OrderItemEntity();orderItem.setOrderSn(orderSn);OrderItemSpuTo spu = spuInfo.get(cartItem.getSkuId());orderItem.setSpuId(spu.getSpuId());orderItem.setSpuName(spu.getSpuName());orderItem.setSpuBrand(spu.getBrandName());orderItem.setCategoryId(spu.getSpuId());orderItem.setSkuId(cartItem.getSkuId());orderItem.setSkuName(cartItem.getSkuName());orderItem.setSkuPic(cartItem.getSkuDefaultImage());orderItem.setSkuPrice(cartItem.getUnitPrice());orderItem.setSkuQuantity(cartItem.getPurchaseQuantity());//orderItem.setSkuAttrsVals(String.join(",",cartItem.getSkuAttrValues()));orderItem.setSkuAttrsVals(StringUtils.collectionToDelimitedString(cartItem.getSkuAttrValues(), ";"));orderItem.setGiftGrowth(cartItem.getTotalPrice().intValue());orderItem.setGiftIntegration(cartItem.getTotalPrice().intValue());orderItem.setPromotionAmount(new BigDecimal("0"));orderItem.setCouponAmount(new BigDecimal("0"));orderItem.setIntegrationAmount(new BigDecimal("0"));BigDecimal realAmount = orderItem.getSkuPrice().multiply(new BigDecimal(orderItem.getSkuQuantity())).subtract(orderItem.getPromotionAmount()).subtract(orderItem.getCouponAmount()).subtract(orderItem.getIntegrationAmount());orderItem.setRealAmount(realAmount);return orderItem;}).collect(Collectors.toList());}计算订单价格
创建订单订单表需要的价格数据是
total_amount[订单总额]、pay_amount[应付总额]、freight_amount[运费金额]订单总额
totalAmount累加每个订单项的商品总价realAmount数据应付总额
payAmount,设置为订单总额totalAmount加运费freight_amount运费总额
freight_amount,这个总额在生成订单实体类时已经设置过了订单中所有商品的促销价格总和
promotionAmount、优惠券价格总和couponAmount、积分优惠价格总和integrationAmountintegration订单总共能获取到的积分,注意积分和成长值类型都要设置为int类型growth订单总共能获取到的成长值
xxxxxxxxxx/*** @param order* @param orderItems* @描述 计算订单总价和优惠价格* @author Earl* @version 1.0.0* @创建日期 2024/12/01* @since 1.0.0*/private void calculateOrderAmount(OrderEntity order,List<OrderItemEntity> orderItems){BigDecimal totalAmount = new BigDecimal("0.00");BigDecimal promotionAmount = new BigDecimal("0.00");BigDecimal couponAmount = new BigDecimal("0.00");BigDecimal integrationAmount = new BigDecimal("0.00");for (OrderItemEntity orderItem : orderItems) {totalAmount.add(orderItem.getRealAmount());promotionAmount.add(orderItem.getPromotionAmount());couponAmount.add(orderItem.getCouponAmount());integrationAmount.add(orderItem.getIntegrationAmount());}order.setTotalAmount(totalAmount);order.setPayAmount(order.getTotalAmount().add(order.getFreightAmount()));order.setPromotionAmount(promotionAmount);order.setCouponAmount(couponAmount);order.setIntegrationAmount(integrationAmount);}
订单验价
我们从订单表中获取应付总价
pay_amount并和订单确认页提交的总价比较,如果价格一样就是验价成功了,而且只需要保证两个金额的小数点后两位相同即可Math.abs(payAmount.subtract(payPrice).doubleValue())<0.01为true就说明验价成功,价格校验失败抛异常返回,价格校验成功说明订单有效,订单有效就开始执行保持订单数据的操作
xxxxxxxxxx//7. 验价if (Math.abs(order.getPayAmount().subtract(orderParam.getTotalPrice()).doubleValue())>=0.01) {throw new RRException(StatusCode.PRICE_VERIFY_EXCEPTION.getMsg()+"核算金额: ¥"+orderParam.getTotalPrice()+",实际金额: ¥"+order.getPayAmount(),StatusCode.PRICE_VERIFY_EXCEPTION.getCode());}
保存订单数据
保存数据到订单表
OrderEntity设置订单记录的自动注入修改时间的功能
保存数据到订单项表
orderItemDao将订单项数据搜集成一个List集合,使用
MyBatisPlus的baseMapper.saveBatch()方法批量保存订单项数据❓:seata目前在AT模式下不支持批量插入记录,https://blog.csdn.net/qq_33240556/article/details/140790581,反正我们后面要换成软性事务,后面再换成批量插入
xxxxxxxxxx//5. 保存订单记录和订单项记录orderService.save(order);//seata目前在AT模式下不支持批量插入记录,https://blog.csdn.net/qq_33240556/article/details/140790581,反正我们后面要换成软性事务,后面再换成批量插入for (OrderItemEntity orderItem : orderItems) {orderItemService.save(orderItem);}//orderItemService.saveBatch(orderItems);库存锁定
业务逻辑流程图

订单数据一旦保存在用户支付之前就要锁定库存,否则用户支付以后没有库存就尴尬了,而且锁库存方法出现任何问题都要回滚此前的创建订单操作,我们可以给创建订单方法添加单机事务注解
@Transactional,一旦锁库存出现问题,我们就抛出异常库存数据都保存在表
wms_ware_sku中,保存了商品的skuId,在哪些仓库有,库存量、skuName、现在库存已经被锁定了多少stock_locked,锁库存就是给stock_locked字段累加直到该字段会超过stock库存量字段锁库存需要知道订单号[万一将来订单出了问题比如支付失败或者放弃订单,我们可以根据订单号来释放被锁住的库存],商品需要锁几件、商品的
skuId、skuName,商品抽象出一个类来封装一个订单项的数据[老师的做法是直接使用订单项来封装商品数据],使用List集合来封装所有订单项数据,单独一个字段封装订单号数据,即封装请求数据准备远程调用库存服务锁定相关商品的库存对库存的原子性操作是通过事务来实现的
锁定库存逻辑
返回商品和对应库存是否锁成功的信息,创建一个
LockStockResultTo类封装锁定库存的结果,字段包含锁定的商品skuId、锁定了几件商品、是否锁定成功,返回List<LockStockResultTo>远程调用发起
Post请求,用请求体封装请求参数,只要响应状态码是0就表示锁库存成功,响应状态码不为0表示锁定库存失败查询有对应商品库存的仓库,根据传参的商品锁库存要求
List<OrderItemVo>来查询仓库sku信息表ware_sku表,查询的每条结果封装成skuId和商品有货的所在仓库Id列表,同时封装商品要锁定的库存件数采用自定义SQL来进行查询
SELECT ware_id FROM wms_ware_sku WHERE sku_id=#{skuId} AND stock-stock_locked>0
[封装参数准备发起锁库存接口调用以及响应数据处理]
xxxxxxxxxxpublic PayVo createOrder(OrderSubmitParamVo orderParam) throws RRException{...//6. 锁定库存LockStockTo lockStock = new LockStockTo();lockStock.setOrderId(order.getId());lockStock.setOrderSn(orderSn);lockStock.setConsignee(order.getReceiverName());lockStock.setConsigneeTel(order.getReceiverPhone());lockStock.setDeliveryAddress(order.getReceiverDetailAddress());lockStock.setPaymentWay(1);lockStock.setOrderItems(orderItems);R res = stockFeignClient.lockStock(lockStock);if (res.getCode()!=0) {throw new RRException((String) res.get("msg"),res.getCode());}...}[自定义接口方法]
xxxxxxxxxx/*** @param skuIds* @return {@link List }<{@link WareIdsOfSkuIdTo }>* @描述 根据skuId列表查询哪些仓库有货* @author Earl* @version 1.0.0* @创建日期 2024/12/01* @since 1.0.0*/List<WareIdsOfSkuIdTo> getWareBySkuIds(("skuIds") List<Long> skuIds);[SQL]
xxxxxxxxxx<select id="getWareBySkuIds" resultType="com.earl.mall.stock.to.WareIdsOfSkuIdTo">SELECT sku_id,GROUP_CONCAT(ware_id) as ware_idsFROM sms_ware_sku WHERE sku_id in<foreach collection="skuIds" item="sku_id" separator="," open="(" close=")">#{sku_id}</foreach>AND stock-stock_locked>0GROUP BY sku_id;</select>根据查询商品的结果来锁定库存
遍历每个商品
skuId,根据wareIds属性的长度判断仓库是否有货,如果当前商品没有任何仓库有库存直接抛库存不足异常,如果商品有货挨个遍历仓库锁定库存直到商品锁定成功注意修改
wms_ware_sku的字段stock_locked的默认值为0,不要让默认值为null自定义锁库存
sql语句UPDATE wms_ware_sku SET stock_locked=stock_locked+#{lockAmount} WHERE sku_id=#{} AND ware_id=#{wareId} AND stock-stock_locked>=#{lockAmount}当单个仓库剩余未锁定库存大于等于购买量的时候库存可以锁定成功,当单个仓库剩余未锁定库存小于购买量的时候库存无法锁定成功,更新语句更新成功返回1,否则就是锁库存失败;设置一个标识锁库存成功的标志位,锁成功了修改标志位,使用break跳出当前锁库存循环,如果当前仓库没有锁成功,就换一个仓库继续锁库存
不需要跨仓库,单仓库给你发,一个仓库货不够就换个仓库,所有仓库都没货那你还买什么,我剩下一个两个给只买一个两个的用户不行吗,就算要跨仓库发货我也可以单仓库不够再进入跨仓库逻辑,只增不改代码
如果遍历完所有仓库都没有锁住,就直接抛出库存不足异常,该订单就失败了,其他商品也不需要往下执行了,只有所有商品都锁定成功了才继续执行创建订单逻辑
老师讲锁定库存方法的返回值改为了表示锁全部库存成功或者失败的布尔标志位
[自定义接口方法]
xxxxxxxxxx/*** @param wareId* @param skuId* @param buyCount* @return {@link Integer }* @描述 尝试锁定库存* @author Earl* @version 1.0.0* @创建日期 2024/12/01* @since 1.0.0*/Integer tryLockStock(("wareId") String wareId,("skuId") Long skuId,("lockCount") Integer lockCount);[SQL]
xxxxxxxxxx<update id="tryLockStock">UPDATE sms_ware_sku SET stock_locked=stock_locked+#{lockCount}WHERE sku_id=#{skuId} AND ware_id=#{wareId} AND stock-stock_locked>=#{lockCount}</update>给锁库存的方法添加
@Transactional注解来添加单体事务,只要出现运行时异常所有锁库存操作就回滚锁定成功直接返回
R.ok(),没有锁定成功返回错误状态码和错误信息
xxxxxxxxxx/*** @param lockStock* @return {@link List }<{@link LockStockResultTo }>* @描述 根据订单和订单项数据锁定库存* @author Earl* @version 1.0.0* @创建日期 2024/12/01* @since 1.0.0*/public List<LockStockResultTo> lockStock(LockStockTo lockStock) {List<LockStockTo.OrderItem> orderItems = lockStock.getOrderItems();List<Long> skuIds = orderItems.stream().map(LockStockTo.OrderItem::getSkuId).collect(Collectors.toList());Map<Long, Integer> buyQuantityOfSku = orderItems.stream().collect(Collectors.toMap(LockStockTo.OrderItem::getSkuId, LockStockTo.OrderItem::getSkuQuantity));//查询商品所在的全部仓库List<WareIdsOfSkuIdTo> wareIdsOfSkuIdTos=baseMapper.getWareBySkuIds(skuIds);if(wareIdsOfSkuIdTos.size()!=skuIds.size()){throw new RRException(StatusCode.NO_STOCK_EXCEPTION.getMsg(),StatusCode.NO_STOCK_EXCEPTION.getCode());}ArrayList<LockStockResultTo> lockStockResults = new ArrayList<>();for (WareIdsOfSkuIdTo wareIdsOfSkuIdTo : wareIdsOfSkuIdTos) {Long skuId = wareIdsOfSkuIdTo.getSkuId();String[] wareIds = wareIdsOfSkuIdTo.getWareIds().split(",");Boolean skuLocked = false;for (String wareId : Arrays.asList(wareIds)) {if(baseMapper.tryLockStock(wareId,skuId,buyQuantityOfSku.get(skuId))==1){LockStockResultTo lockStockResult = new LockStockResultTo();skuLocked = true;lockStockResult.setLocked(true);lockStockResult.setLockQuantity(buyQuantityOfSku.get(skuId));lockStockResult.setWareId(Long.parseLong(wareId));lockStockResult.setSkuId(skuId);lockStockResults.add(lockStockResult);break;}}if(!skuLocked){throw new RRException("商品"+skuId+StatusCode.NO_STOCK_EXCEPTION.getCode(),StatusCode.NO_STOCK_EXCEPTION.getCode());}}return lockStockResults;}
库存锁定成功返回页面数据给控制器方法,锁定失败了提示失败原因并返回页面数据给控制器方法,给视图中存放订单数据,如果订单相关操作没有问题,状态码就是默认的0,我们根据状态码判断响应逻辑;我这里直接通过异常机制实现的各种报错和响应错误验证码,效果比老师的好
付款页渲染
视图层处理
[视图数据封装]
xxxxxxxxxxpublic PayVo createOrder(OrderSubmitParamVo orderParam) throws RRException{...//封装视图数据,注意存入分布式session的数据对应实体类最好全部放在common包下,session中有的数据不论其他服务能否用到,// 其他服务必须包含session中所有数据的对应类型,否则其他服务即使没有使用对应的session也会直接报错PayVo pay = new PayVo();OrderVo orderVo = new OrderVo();BeanUtils.copyProperties(order,orderVo);List<OrderItemVo> orderItemVos = orderItems.stream().map(orderItem -> {OrderItemVo orderItemVo = new OrderItemVo();BeanUtils.copyProperties(orderItem, orderItemVo);return orderItemVo;}).collect(Collectors.toList());pay.setOrder(orderVo);pay.setOrderItems(orderItemVos);pay.setFare(order.getFreightAmount());pay.setPayablePrice(order.getPayAmount());return pay;}[控制器视图处理]
xxxxxxxxxx/*** @param orderParam* @return {@link String }* @描述 创建用户订单* @author Earl* @version 1.0.0* @创建日期 2024/11/30* @since 1.0.0*/("/order/submit")public String createOrder(OrderSubmitParamVo orderParam, HttpSession session, RedirectAttributes attributes){try{PayVo pay = orderWebService.createOrder(orderParam);session.setAttribute("pay",pay);return "redirect:http://order.earlmall.com/pay.html";}catch (RRException e){attributes.addFlashAttribute("error",e.getMsg());return "redirect:http://order.earlmall.com/statement.html";}}渲染数据
订单号、应付金额
xxxxxxxxxx<div class="Jdbox_BuySuc"><dl><dt><img src="/static/order/pay/img/saoyisao.png" alt=""></dt><dd><span th:text="|订单提交成功,请尽快付款!订单号:${session.pay.order.orderSn}|"></span><span>应付金额<font th:text="${session.pay.order.payAmount}">28.90</font>元</span></dd><dd><span>推荐使用</span><span>扫码支付请您在<font>30分钟</font>内完成支付,否则订单会被自动取消(库存紧订单请参见详情页时限)</span><span>订单详细</span></dd></dl></div>创建订单失败重定向到订单确认页并根据错误状态码给出错误信息
xxxxxxxxxxString msg="下单失败;";switch(responseVo.getCode()){case 1: msg+="订单信息过期,请刷新页面重新提交订单";break;case 2: msg+="订单商品价格发生变化,请确认价格后重新提交订单";break;case 3: msg+="商品库存不足,库存锁定失败";break;}错误信息提示组件
SpringBoot默认给session中放的数据给请求域中也放了,因此session前缀都不需要Thymeleaf就能直接从请求域中取出session中的同名数据
xxxxxxxxxx<p class="p1">填写并核对订单信息<span style="color:red" th:if="${session.msg!=null}" th:text="${msg}"></span></p>我自己实现了一个组件来提示所有错误
xxxxxxxxxx<div><p class="p1">填写并核对订单信息<span style="border-radius: 5px;margin: 10px 0;padding: 2px;background-color: #f2dede;color: #a94442;border: 1px solid #ebccd1;" th:if="${error!=null}" th:text="${error}">填写并核对订单信息</span></p><div id="error-message" class="error-message"><p id="error-text"></p></div></div>
本地事务
本地事务
数据库事务的特性[ACID]:
原子性[一系列操作整体性不可拆分,即要么整体成功、要么整体失败]、
一致性[整体数据操作前后守恒]、
隔离性[或独立性,事务之间相互隔离,一个业务操作失败回滚不会影响其他业务操作]、
持久性[事务一旦成功提交,数据就一定会落盘到数据库,认为是先落盘再提示事务成功提交]
本地事务的应用场景是单体应用连接一个数据库,没有多个数据库、没有涉及服务拆分、也没有涉及服务间的远程调用
Spring提供的本地事务注解
@Transactional注解Spring框架提供了一个
@Transactional注解来使用本地事务隔离级别:隔离级别是SQL数据库规定的一些规范
READ UNCOMMITTED[读未提交]:设置该隔离级别的事务可以读到其他未提交事务的数据,这会导致脏读现象[比如读未提交的数据被回滚了,但是其他操作已经拿到回滚前的数据进行后续的计算]
READ COMMITTED[读已提交]:设置该隔离级别的事务可以读取已经提交事务的数据,这是
Oracle和SqlServer的隔离级别,特点是每次读取都读取的是实际值,同一系列操作中两次读取的数据不同都是实际值REPEATABLE READ[可重复读]:设置该隔离级别的事务读取到的数据是事务开始时的数据,事务期间读取的数据都是相同的,这是MYSQL默认的隔离级别,特点是存在幻读现象,即实际数据在业务处理期间已经发生变化,但仍然使用的事务开启时的数据
mysql的InnoDB引擎可以通过next-key locks即行锁算法机制来避免幻读
SERIALIZABLE[序列化]:设置该隔离级别的事务全是串行顺序执行的,
MySQL数据库的InnoDB引擎会给读操作隐式加一把读共享锁,避免脏读、不可重复读、幻读问题,但是这也意味着使用这种隔离级别数据库操作就失去了并发能力🔎:通过
@Transactional(isolation=Isolation.READ_COMMITTED)可以指定当前事务的隔离级别
事务传播行为[Spring中的事务管理行为]:事务的传播行为就是指被调用方法的事务和调用方法的事务之间的关系,比如a方法需要开启一个事务,b方法也需要开启一个事务,a方法调用b方法,那么a,b方法开启的事务之间的关系
PROPAGATION_REQUIRED:如果当前业务操作还没有事务,就创建一个新事务;如果当前业务操作已经存在事务就加入该事务,一旦事务中任何一处失败事务中的所有操作都回滚一旦b方法的事务设置成
PROPAGATION_REQUIRED,如果b方法被开启了事务的a方法调用,b方法的事务配置就会完全失效,比如b方法单独设置了代码执行超过7s就会回滚@Transactional(propagation=Propagation.REQUIRED,timeout=7),a方法设置了代码执行超过30s就会回滚,b方法被a方法调用,那么b方法的事务配置就会直接失效,即a事务的设置会自动传播到和a方法共用一个事务的方法
PROPAGATION_REQUIRED_NEW:不论当前业务操作有没有事务,都为被@Transactional注解标注的方法创建一个新的事务,该方法出现问题只会回滚该方法的业务操作,其他事务出问题不会影响该方法的事务行为PROPAGATION_SUPPORTS:如果当前业务操作已经存在事务就加入该事务,如果当前业务操作还没有事务就以非事务的方式执行PROPAGATION_MANDATORY:如果当前业务操作已经存在事务就加入该事务,如果当前业务操作还没有事务就直接抛出异常PROPAGATION_NOT_SUPPORTED:以非事务的方式执行当前被标注方法,如果当前业务操作已经存在事务,就将当前事务挂起PROPAGATION_NEVER:以非事务的方式执行当前被标注方法,如果当前业务操作已经存在事务,就直接抛出异常PROPAGATION_NESTED:如果当前业务操作已经存在事务,被标注方法会在当前事务内部创建一个子事务,子事务的特点是会在子事务开启的时刻创建一个保存点,子事务失败只会回退到该保存点,不会回滚整个事务,父事务中的其他操作仍然能正常执行;但是如果父事务回滚,子事务也会一起回滚;如果当前业务操作还没有事务就为被标注方法创建一个全新的事务这个事务传播行为和
PROPAGATION_REQUIRED_NEW很像,被标注方法的事务失败不会影响业务操作的其他事务,主要区别如下;PROPAGATION_REQUIRES_NEW会挂起当前事务,并创建一个全新的事务,这意味着新事务与原事务完全独立,事务成功或者失败不会相互影响。而PROPAGATION_NESTED则是在当前事务内部创建一个子事务,如果父事务被回滚,子事务也会被回滚,但子事务的回滚不会影响到父事务。
SpringBoot中的本地事务SpringBoot中也是默认使用Spring的本地事务注解@TransactionalSpringBoot中使用@Transactional注解的坑❓:在
SpringBoot中,如果a方法、b方法、c方法是同一个Service中的方法,三个方法都标注了@Transactional注解且都做了个性化配置,比如都各自配置了不同的事务传播行为和超时时间,此时如果a方法调用了b方法和c方法,b方法和c方法的任何事物配置都不会生效,包括事物传播行为,都是和a方法共用同一个事务🔑:这是
AOP的问题,在之前SpringCache中就出现过,那儿老师没有解释,事务注解是通过AOP实现的,事务是通过代理对象orderService来控制的,如果直接调用同一个类中的实例方法本质上相当于跳过代理对象直接通过方法名调用同一个类中的方法,就类似于代码的复制粘贴,被调用的方法事务注解不会生效;根本原因就是绕过了代理对象,这一块不太熟,后面复习的时候深入理解一下,a方法是通过代理对象调用的,但是b方法和c方法只是单纯地将代码复制粘贴过来,我们通过orderService来调用被标注了基于AOP实现的事务或者缓存注解的方法对应的注解会生效,但是同一个类下的代码的相互调用是类似于直接复制拷贝代码的形式,通过this来调用也是没用的,this也会被处理成同一个对象从而直接复制拷贝被调用方法的代码,只有通过代理对象类似于orderService.a()来调用事务注解或者缓存注解才会生效,总之基于AOP实现的注解都需要通过代理对象来调用才会生效,通过this调用也是不生效的;而且一定不要企图在orderService中自动注入orderService来通过代理对象调用b方法或者c方法,这相当于orderService依赖于orderService,在构造orderService将其注入容器时会发现构造orderService自身有一个属性需要注入orderService,会造成循环依赖的问题,系统启动的时候就要爆炸🔑:同一个对象内基于AOP实现的注解标注方法相互调用注解功能失效的解决办法,核心是要使用代理对象来调用标注了基于AOP实现的注解的方法
引入Spring的AOP动态代理场景启动器
spring-boot-starter-aop,引入该场景启动器的目的是使用其依赖的aspectjweaver,这个动态代理更加强大在配置类上使用注解
@EnableAspectJAutoProxy开启Aspectj动态代理,不使用该注解默认使用的是JDK默认的按照接口自动生成的动态代理,使用该注解所有的动态代理都是Aspectj创建的,使用Aspectj的好处是即使没有接口也可以创建动态代理;在@EnableAspectJAutoProxy中指定exposeProxy属性为true即@EnableAspectJAutoProxy(exposeProxy=true)来对外暴露代理对象只要设置了通过
Aspectj创建代理对象,我们就可以在任何地方通过org.springframework.aop.framework.AopContext即AOP上下文的AopContext.currentProxy()拿到当前代码所在对象对应的代理对象[Object类型,需要强转为当前代码所在对象的类型来调用所在对象的b方法或者c方法],直接通过代理对象来调用b方法或者c方法,这样b方法和c方法的事务注解包括此前的缓存注解才会生效,示例方法如下所示:xxxxxxxxxx(timeout=30)public void a(){OrderServiceImpl orderService = (OrderServiceImpl)AopContext.currentProxy();orderService.b();orderService.c();}(propagation=Propagation.REQUIRED,timeout=2)public void b(){}(propagation=Propagation.REQUIRES_NEW,timeout=20)public void b(){}
分布式环境下本地事务存在问题
虽然我们给创建订单和锁定库存都分别添加了
@Transactional本地事务注解来各自开启单体事务,但是因为订单服务和库存服务处在不同的服务实例,因此事务不能跨服务生效,订单成功创建但是库存没有成功扣减,只会回滚库存成功锁定商品的记录,无法回滚已经创建订单记录,这是单体事务的局限解决办法,我们直接根据远程调用的结果判断,在创建订单记录的服务中判断锁库存的状态,如果锁库存失败,我们直接在订单服务抛异常来让订单服务的事务进行回滚,这样也能控住分布式事务,让多个数据库一起回滚
但是通过抛出异常和单体事务结合的方案不能完美解决事务问题
被调用服务成功执行,调用服务可能由于网络中断、调用超时导致被调用服务成功执行,调用服务回滚[这种情况叫远程服务假失败]。因为被调用服务本身可能不会出现异常正常执行,但是由于网络中断,系统卡死导致响应超时等都会导致在调用方抛出异常,这样就会导致远程调用成功添加记录,但是调用方由于网络,远程调用超时而抛出异常来回滚,导致订单相关数据没有一起回滚;比如锁定库存服务响应慢,库存锁定成功了,但是订单服务远程调用超时,订单服务感知到远程调用出问题了抛异常事务回滚,但是远程服务正常执行不会进行回滚,就会出现订单取消了,但是库存给锁定了
已经被调用并成功执行的远程服务在订单创建失败的情况下无法自动进行回滚。远程服务调用期间没有出现问题,方法执行结束事务就已经结束了,后续订单服务运行期间出现任何问题导致需要回滚,已经执行完毕的远程服务无法自动进行事务回滚,我们想要手动回滚还需要专门写释放对应库存记录的方法
本地事务在分布式系统下只能控制住本地连接的事务回滚,控制不了其他服务和连接的事务回滚,在分布式系统下,本地事务控制不住事务的根本原因是网络中断+不同数据库+服务实例集群,而本地事务只能控制一个连接内的事务
分布式系统定理
CAP定理:一个分布式系统中,以下三个要素最多只能同时实现两个,不可能三者兼顾
一致性[Consistency]:同一时刻对分布式系统中的任意一个节点的某个数据进行访问,一定是获取的最新的相同的值,形象地说就是任意一个数据节点更新某个数据完成时间点以后,访问任意一个数据节点都获取的是更新后的数据或者数据副本,注意这个一致性说的是强一致性,即任何时间点访问任何机器上的数据都是确定相同的值
从客户端角度,多进程并发访问时,更新过的数据在不同进程中的获取策略决定了不同的一致性,对于关系型数据库不同的一致性要求如下
强一致性:更新成功的数据能够被后续所有请求唯一访问
弱一致性:更新成功的数据,系统能够容忍后续部分请求或者全部请求都访问不到
最终一致性:更新成功的数据,经过一段时间弱一致性后所有的请求都能唯一访问,即我们能忍受一段时间的弱一致性
分布式事务就是围绕我们想要系统维持什么样的一致性来设计的不同的几种方案
可用性[Availability]:集群中部分节点故障后,集群仍然能响应客户端的读写请求;不可用就是系统某个环节出现了需要等待节点修复以后才能使用的情况
分区容错性[Partition tolerance]:不同节点上的服务相互通信需要通过网络,只要网络通信出现了故障就可以认为发生了分区错误,专业的角度来说,一个分布式系统分布在多个子网络上,每个子网络就是一个区;分区容错的意思是区之间的通信可能会失败,比如中国的网络是一个区,美国的网络是一个区,两个区的网络可能无法通信
举一个例子说明CAP理论:
假如一个MySQL主从集群,A节点是主节点,B节点和C节点是从节点,一旦A节点和C节点之间发生网络分区故障,主节点的数据更新就无法同步到从节点上,如果此时还要保证C节点的可用性,就会发生从C节点上读取到的数据都是错误数据的情况,从而导致系统一致性得不到保证;
在分布式系统中我们永远要满足分区容错性,因为网络通信肯定会出现问题,网络出现问题我们还要保证系统运行就是满足分区容错,因此我们就只能选择满足一致性或者选择满足可用性,当发生分区故障,导致不同数据不一致,我们需要根据业务场景选择是牺牲一致性满足可用性[允许部分数据不一致]还是牺牲可用性满足一致性[不允许部分数据不一致而让数据不一致的服务不可用或者直接让系统不可用来代替单个节点的不可用]
因为分区容错无法避免,可以认为分布式系统下CAP理论的P总是成立[因为无法保证网络不中断,除非单体应用且数据库
Redis等都装在一台机器中],CAP理论指出在保证分区容错的情况下,一致性和可用性无法同时做到,只可能同时满足CP或者AP满足AP即满足分区容错的前提下满足可用性,即让三个节点都正常运行,取到数据不一致无所谓,业务正常执行
满足CP即满足分区容错的前提下满足一致性,即让系统不可用或者让数据错误的节点不可用
分布式系统下实现一致性的
Raft算法、paxos算法
CAP定理在实际开发中面临的普遍问题是
大型互联网应用场景,主机众多,部署分散,集群规模越来越大;节点故障和网络故障是常态,对商用服务还要充分保障可用性,系统不可用特别像阿里这种基础服务设施短时间的不可用就是特大事故,因此我们还需要保证系统的可用性达到N个9,在很多时候都要保证分区容错和可用性,舍弃掉强一致性;
此时就从CAP理论延伸出BASE理论,核心思想即使我们在保证分区容错和可用性的前提下无法做到强一致性,但是我们可以适当地采取弱一致性,弱一致性就是最终一致性
Base理论
基本可用[Basically Avaliable]:基本可用是指分布式系统在出现故障时,允许损失诸如响应时间、部分功能这样的部分可用性,来保证整个系统的可用性
响应时间损失:正常情况下系统0.5s内响应客户查询请求,在系统部分机房断点或断网的情况下,查询响应时间可以增加到1-2s
功能上损失:电商网站在购物高峰期为了保护系统的稳定性,部分消费者可能会被引导到一个降级页面[服务降级页面,比如一个错误页,Sentinel学过;这个思路学Nginx的时候听说过,秒杀抢购活动实际上早就决定好了哪些请求失败,因为一般这种流量都会提前打开对应活动界面,在活动界面埋点就能预测具体请求数量甚至直接在前端就决定哪些请求直接失败,到时刻以后直接跳转错误页,只有很少的流量到达了上游服务器]
软状态[Soft State]:软状态是相对于强一致状态而言的,强一直是业务操作中的每个操作要么整体成功、要么整体失败,软状态是整个业务操作正在同步中;
典型应用场景就是分布式存储中一份数据一般会有多个副本,允许不同副本的延时同步就是软状态的体现。
Mysql的异步复制即mysql replication就是软状态的一种体现
最终一致性[Eventual Consistency]:最终一致性是指系统中所有的数据副本经过一定时间后最终能够达到一致的状态[注意核心概念是能够,像不同节点获取到不同的数据并使用该数据继续一泻千里最终得到完全混沌的数据是不能经过一段时间达到一致状态的]
比如在我们的订单服务中,我们使用单体事务控制分布式系统的远程调用事务,库存服务成功扣减库存,但是订单回滚,库存服务无法回滚,我们可以不要求强一致性,即订单创建失败就必须让库存也回滚,我们可以在订单出现异常回滚前的时刻给消息中间件发送一条消息,指定要解锁的库存数量,一段时间后库存服务接收到消息释放解锁对应库存即可
我们可以使用各种手段来保证最终一致性,事缓则圆嘛
Raft算法Raft是一种协议,可以保证分布式系统下的一致性,Raft的原理演示流程查看http://thesecretlivesofdata.com/raft/配合老师的课程会理解的更清晰,作用是即使网络出现了分区故障,系统的一致性仍然能得到保障分布式系统一致性:当数据库只有一个节点时一致性非常容易满足,只需要一个节点更新数据成功后读取到的数据就是最新的数据;关键是在数据库集群场景下如何保证数据库集群整体的数据一致性
主节点选举:
Raft算法把系统中的每个节点分成三种状态,follower从节点、candidate候选者、leader主节点;数据库集群启动时每个节点都是以从节点的状态启动的,如果从节点在一定时间内没有监听到主节点发送来的心跳包就会主动变成候选者状态[变成候选者是为了准备当主节点];候选者会给集群中的每个节点都发起一个投票请求,集群中每个收到请求的从节点都会投票给该候选者,而且从节点只要投过一次票在一次心跳时间内就不会再给后续的投票请求投票;候选者只要收到包含自己在内的大多数节点的同意投票就会变成主节点状态,这就是主节点的选举过程;Raft中有两个超时时间用来控制主节点选举过程,一个是选举超时时间[超过指定时间没有收到主节点的心跳包当前节点就会成为候选节点,让其他从节点选举候选节点做主节点,选举超时时间一般是150-300ms,也称节点的自旋时间,节点的自旋时间是随机的],一个是心跳超时时间[主节点向从节点发送心跳包的间隔时间,该心跳超时时间一般远小于每个节点的自选时间,只要从节点收到主节点的心跳包就会重置各自的自旋时间来避免成为候选节点],节点内部有一个Term属性记录当前节点发起投票的轮数,候选者也会给自己投一票并且将投票轮数递增1[注意投票轮数从集群启动开始设置为0,只要发起一次投票就会累加1,不会出现重置的情况],其他从节点如果还没有投票就会将票投给该候选者并重置自身的自旋时间,后续的投票请求不会同意投票,只要主节点收到绝大多数从节点的同意投票就会变成主节点,主节点开始给所有从节点通过心跳包发送追加日志,并周期性地向所有从节点发送心跳包,一直维持该状态直到主节点宕机[准确地说是有一个从节点变成了候选者节点,就是有一个节点超过自旋时间没有接收到心跳包],此时又开始重复主节点选举流程,此时新的主节点的数据和旧的主节点数据是一致的
节点宕机必然导致集群内的节点数量变成偶数,此时就可能存在两个节点成为候选节点并只都获取到半数投票[实际上可能存在N个候选节点,且N个候选节点都没有获取到半数以上的投票,概率小,因为自旋时间比较长,远超内网通信时间],此时因为没有候选者节点获取到半数以上投票将无法选举出主节点,注意节点在自旋时间结束后新的自旋周期开启时发起投票请求并重新开始自旋时间计时,各个节点会因为自旋时间内没有成为主节点和没有收到主节点的心跳包而在自旋时间结束后再次发起投票,重复上述过程直到某个节点成功获取到大多数节点的投票,因为必须要获取到大多数节点的投票才能成为主节点,因此系统内只可能存在一个主节点;只可能在网络分区故障多个分区之间无法通信,此时才会存在集群分裂和多个主节点的现象
日志复制:一旦主节点选出来以后,所有对该集群系统的更新都会通过给主节点发送请求来实现,从节点自身不具备更新功能;主节点每一个数据写操作都会被追加为一个节点日志,生成日志时主节点的更新操作还没有提交,此时客户端访问主节点的数据仍然获取的是更新前的数据;主节点生成节点日志后复制节点日志给所有的从节点,从节点收到日志并更新了本地数据后会响应更新成功状态给主节点;主节点只要确认大多数节点更新成功就会直接提交本次更新并再次向所有从节点发起提交请求
每个日志都是通过主节点的心跳包发送出去的,主节点发生写操作追加更新日志,会统一在下一个心跳包中奖日志携带给各个从节点,从节点同步日志并回复主节点,只要大多数节点回复主节点成功同步主节点就会直接提交更新结果并同时将更新成功的状态响应给客户端,在下一个心跳包中向所有从节点发起提交请求,所有从节点提交更新结果并将提交状态响应给主节点
网络分区故障Raft保障数据一致性的原理
假设A、B两个节点处于一个网络分区,C、D、E三个节点处于一个网络分区,两个网络分区发生了网络分区故障,两个分区之间节点的网络通信断掉了;假如原来5个节点的主节点是B节点,一旦出现网络分区,B主节点和另一个网络分区的从节点无法通信,但是因为B主节点所在网络分区和从节点可以正常通信,因此B主节点的状态不会发生变化;C、D、E三个从节点因为收不到主节点的心跳包重新选举主节点,假如选举出主节点E,此时所有节点的数量就变成了3,特别注意此时旧的主节点B因为仍然维持主节点状态,所有节点的数量仍然维持5,只有在选举成为主节点时才会更新集群中的节点数量;
此时相当于两个分区的节点分裂成两个集群,主节点所在集群仍然维持旧的主节点,另一个全是从节点的分区重新选举主节点,旧的主节点可能因为所在分区节点数小于成为主节点时节点数的一半,从而导致旧的主节点所在分区永远无法正确响应客户端的请求,但是另一个分区因为重新选举了主节点重新确定了集群节点数量因此会正常处理所有客户端请求并在一个分区中维持数据一致性
当网络分区故障恢复以后,此时会出现两个主节点,两个主节点都会互相给对方发送心跳包,当主节点发现对方的选举轮数Term的值比自己大,就会皇帝退位,即旧的主节点B发现对方的选举轮数比自己多就会变成从节点,原来B主节点所在分区节点收到两个心跳包并发现有轮数更大的主节点就会将轮数更大的主节点视为新的主节点,B主节点所在分区的节点会将没有提交的数据全部回滚并重新同步新的主节点E的更新日志,此时网络故障恢复,整个集群又处于一致性状态了
这个演示只适合旧的主节点所在网络分区的节点数小于绝大多数节点的情况,此时旧的主节点无法提交更新数据因而整个分区无法处理用户请求从而保障系统数据一致性;但是如果旧的主节点所在网络分区的节点数大于绝大多数节点要求那岂不是也可以提交更新的数据,那岂不是会变成两个集群[因为这种思路逻辑有问题,对上面的情形换一种思路理解,即集群总的节点数量在集群启动时就确定,网络分区一般发生在两个分区之间,两个分区会将可通信的节点数量分成两份,一方节点数量大于一半另一方的节点数量就必然小于一半,即始终只有一个一个集群能成功提供服务,另一个集群因为节点数小于一半而无法提交更新结果从而无法提供服务;但是这也存在问题,因为两个网络分区的存活节点数也可能刚好相同,那这种情况岂不是两个集群都无法对外提供服务系统直接崩溃,这里需要看一下相关论文确认]
raft.github.io也有一个动画演示,但是都没有展示两个网络分区节点数各占一半情况下由于不满足半数以上节点同步更新导致无法各分区主节点无法提交导致整个系统无法对外提供服务的情况,看论文可能会有收获这个问题老师后面提了,说这正是CAP定理对Raft算法的约束,即要保证集群的一致性,当两个集群的节点数目无法达到半数以上,虽然基本上节点都存活着,但是此时集群因为主节点无法获取大多数节点的响应而无法提交更新后的数据因此整个集群都无法为客户端提供服务,保证一致性并降低对可用性的影响
分布式事务
业务太大,系统性能、安全和可伸缩性要求太高,我们需要将系统拆分为分布式集群,分布式系统经常会出现机器宕机、网络异常、消息丢失、消息乱序、数据错误、不可靠的TCP、存储数据丢失;
在本项目中,我们拆分出来的服务还单独操作自己的数据库,每个服务还会部署在不同的服务器上,服务之间的远程调用调用方只有获取到被调用方的响应结果以后才能得知远程调用的执行结果,这就可能导致远程被调用服务执行完但是响应的时候出问题,比如执行完响应前的一刻被调用服务的服务器宕机,数据永远无法成功响应,但是实际远程调用已经成功;又比如消息刚发出网络就中断了;又比如系统引入了很多中间件比如消息中间件也可能引入比如消息丢失、类型无法进行转换等等额外的问题;此时调用方不仅不知道远程服务器是否执行成功,甚至要查询远程服务器对应的落盘数据都很困难,因此只要有一个被调用服务出现问题,要在整个业务操作同步状态非常困难
只要是微服务架构系统,分布式事务是每一个分布式系统架构无法避开的东西
分布式事务要实现的一致性是保证多个业务操作的一致性,一个操作失败所有操作失败,所有操作成功整个操作才算成功,而且一个数据库集群中的所有节点都要保持一致性状态
分布式事务常见的解决方案包括2PC模式、
2PC模式[2 phase commit,也称二阶段提交]
2PC模式也叫XA Transactions,MySQL从5.5版本开始支持、SQL Server从SQL Server 2005开始支持、Oracle从Oracle 7开始支持
二阶段提交协议的思想是将事务拆分成两个阶段,其中涉及两个对象事务管理器和本地资源管理器[本地资源管理器可以视为每个服务的事务管理器],这里把本地资源管理器看成两个功能不同服务的事务管理器
二阶段提交是将事务分成两个阶段,第一个阶段是准备提交阶段,事务管理器对业务相关的每一个微服务的事务管理器发起请求要求各事务管理器检查本地的事务提交就绪状态[本地数据是否准备好、数据库连接是否正常以及能否正常提交数据],如果各个服务都能正常提交每个服务都会响应就绪状态给事务管理器
第二个阶段是提交阶段,如果事务管理器都成功接收到业务操作涉及到的本地资源管理器的就绪状态确认,就会给每个本地资源管理器发起提交请求,所有本地资源管理器统一提交事务并响应成功状态给事务管理器;一旦有任何一个数据库在预备阶段否决此次提交、所有相关数据库都会被要求回滚本次事务中的那部分数据,事务管理器就会要求所有的本地资源管理器全部进行回滚

XA协议最大的特点是简单,而且基本上商用的数据库都实现了XA协议,使用分布式事务的成本很低;但是注意
mysql数据库对XA协议的支持不是很好,mysql的XA实现没有记录预备阶段[prepare]的日志,主备数据库切换会导致主库和备库的数据不一致XA协议最大的问题是性能不理想,特别是交易下单这种并发量很高的服务调用链路,XA协议无法满足高并发场景;很多NoSQL数据库也没有支持XA协议,这就使得XA协议的应用场景变得非常狭隘
除了二阶段提交还有三阶段提交,额外引入了超时机制,无论无论是事务管理器还是本地资源管理器,向对方发起请求后,超过一定时间没有收到回应会执行兜底处理[这里老师说的三阶段提交是将预备阶段分成两个阶段,第一个阶段询问各个本地资源管理器能否正常提交,第二个阶段是本地资源管理器准备数据,第三个阶段就是正常的提交阶段]
XA协议在应用中能解决一些问题,但是应用的不多,主要是了解
柔性事务[TCC模式,也称TCC事务补偿型方案]
这个方案在分布式事务中经常使用,柔性事务是一类保证最终一致性的方案的统称
刚性事务:遵循数据库ACID原则的强一致性要求的事务
柔性事务:遵循BASE理论的最终一致性要求的事务,柔性事务允许一定时间内不同节点的数据不一致,但是最终各个节点内的数据一致
柔性事务流程图
假如有两个数据库,一个数据库对应订单服务,另一个数据库对应库存服务,每个数据库都由对应的服务来进行操作
TCC模式要求开发人员在编写代码的时候在服务中实现三个方法
Try[该方法是准备要提交的数据]、Confirm[该方法是用于提交数据]、Cancel[该方法是回滚准备提交的数据,老师这里说的是开发人员前面提交了数据比如数据加2,这个取消方法就要将数据减2]作为可能被回调的方法第一个阶段,主业务服务[调用各个远程服务的大业务所在服务]命令各个服务调用开发者编写的Try方法来准备数据,同时启动业务活动管理器记录业务操作、并通过业务活动管理器控制提交和回滚业务活动
第二阶段,业务活动管理器命令各个服务调用Confirm方法提交数据
第三个阶段,只要提交过程有任何一个远程调用服务或者主业务服务执行失败,业务活动管理器就会命令所有的远程服务触发开发者自己编写的Cancel方法来做手动回滚补偿,已经成功提交的数据我们再手动进行恢复

这种模式在电商项目中使用的非常多,基于TCC模式实现的事务框架也非常多,只需要按照框架的接口规范把业务方法拆分成三个部分,分别实现数据准备、提交数据、回滚数据的三个方法,框架会自动在特定的节点对三种方法进行调用,这个方案的核心就是出现问题对已经成功提交的数据采用手动补偿的方式来实现回滚
TCC模式相当于3PC模式的手动版,3PC相当于自动准备提交的数据、自动进行提交和自动进行回滚,TCC相当于程序员自己实现准备提交数据、提交、回滚的逻辑
柔性事务[最大努力通知型方案]
主业务比如创建订单业务远程调用库存服务锁库存成功,远程调用订单服务保存订单数据成功,但是比价的时候失败了,此时订单创建失败,注意此时订单数据和库存数据都已经提交;我们可以让主业务给消息队列中的主题交换器发送消息给队列,让所有相关服务都来订阅消息队列,库存服务收到消息去解锁库存,订单服务收到消息去解锁订单
我们害怕消息发出去了但是消息丢失,我们可以逐渐拉长时间间隔给消息队列中发送消息,设置最大消息通知次数,达到最大通知次数就不再发送订单创建失败消息通知;或者服务手动回滚即释放库存即删除订单数据成功了就将消息响应给主业务服务,此时主业务服务收到回滚确认以后就不再向消息队列发送消息
这种多次通知、主业务确认手动回滚的特点也是最大努力通知型方案命名的原因
这种方式适合使用在与第三方系统通讯的场景,比如调用微信或者支付宝支付后的结果通知,各大交易平台间的商户通知、多次通知,查询校对、对账文件、支付宝支付成功后的异步回调等;支付宝付款就是支付成功以后会多次给我们的服务器发送支付成功的消息给我们的订单业务
通过消息队列来实现延时回滚的策略都是通知型方案,保证最终一致性来提升系统的可用性,实际生产中也常使用第三和第四种结合消息队列多次失败通知回滚数据并回复消息生产者的方案
柔性事务[可靠消息+最终一致性方案,也称异步确保型]
这个讲的不清楚,说后面会补充案例说明
大体意思是业务事务提交前,会实时给消息服务保存一份消息数据,但是消息数据在得到确认发送的指令前不会发送给远程调用服务,只有在业务事务提交后才会消息服务发出确认发送指令,这里讲的不清楚,后面结合场景理解一下
老师在这里的解释和上面第三种是一样的,大业务失败给消息队列发送消息,被调用服务收到消息就回滚数据
方案优缺点分析
第三和第四种方案的好处是可以支持大并发场景,订单服务失败只需要发送消息给消息中间件,无需等待其他服务数据回滚就能直接响应用户请求,通过多次发送和回滚验证确认接口来等待远程服务的回滚状态确认,一旦得到确认就停止消息的发送来实现最大努力通知
Seata分布式事务
Seata分布式事务框架实际是2PC协议[二阶段提交协议]的一个变形,实际上Seata为用户提供了多种AT[Auto Transaction自动事务模式]、TCC[手动事务补偿模式]、SAGA、XA[两阶段提交]事务模式,这里只演示了AT模式的用法,其他模式的用法可以通过https://github.com/apache/incubator-seata-samples对应的文件目录下找到对应模式的使用示例和使用步骤说明Seata默认的AT模式是二阶段提交协议的一个演变,和原来的二阶段提交XA模式的区别是,XA模式第一个阶段是准备数据阶段,只会在第二个阶段再提交事务;但是AT模式是第一个阶段业务数据和回滚日志记录就在同一个本地事务中提交并释放本地锁和连接资源,而且各个分支事务提交是异步化的,第二个阶段是回滚的时候通过一阶段提交的回滚日志进行反向补偿注意导入了
Seata的依赖必须将Seata服务器的registry.conf和file.conf两个文件拷贝到项目的类路径下,否则项目启动会直接报错,因此没有使用Seata的服务最好不要导入或者排除该依赖
Seata分布式事务控制原理术语
TC:事务协调者,作用是维护全局和分支事务状态,驱动全局事务提交或者回滚,通过TC协调各个远程服务是否一起提交事务或者回滚事务,这个TC就类似于XA二阶段协议的事务管理器,主要是作为全局的协调者
TM:事务管理器,定义全局事务范围,开始全局事务、提交或回滚全局事务
RM:资源管理器,资源管理器位于各个服务中,直接和当前服务对应数据库交互,就是类似于单体Spring中使用的
@Transactional三者的整体关系是事务管理器负责开启全局事务,TC事务协调者负责协调全局事务中牵扯的各个分支事务,
工作流程
创建订单业务的事务管理器准备开启一个全局事务,向事务协调者声明开启一个全局事务,事务协调者响应收到;
订单业务所在服务调用远程服务的时候,远程服务的RM资源管理器会向事务协调者声明一个分支事务并且需要实时报告分支事务状态,无论任意一个分支事务提交还是回滚,事务协调者都会实时知道;注意分支事务是在订单业务调用远程服务执行业务代码时开启的,而且调用结束分支事务就已经提交了
远程调用时任意一个分支事务回滚,事务协调器会直接命令其他已经提交过的分支事务也回滚
使用注解
@GlobalTransactional标注在业务方法上即可使用seata分布式事务

Seata的使用方法1️⃣:如果我们使用
Seata的AT自动事务模式需要创建一张数据库表UNDO_LOG表[回滚日志表],因为自动事务模式下数据的回滚由
Seata进行控制,每个分支事务在远程调用结束前分支事务就已经提交了,回滚只能通过反向补偿的方式重置数据;使用TCC模式是自己来定义反向补偿的代码,TA自动事务模式就是该代码由Seata实现和调用,Seata需要在每一个数据库中都要额外准备一个回滚日志表,回滚日志表记录着此前给哪个数据库表的哪个记录做了什么更新,恢复以前的状态就是对以前的更新操作进行反向补偿,这种方式叫魔改数据库
[回滚日志表]
给每个数据库都要创建下面这张回滚日志表
xxxxxxxxxx-- 注意此处0.3.0+ 增加唯一索引 ux_undo_logCREATE TABLE `undo_log` (`id` bigint(20) NOT NULL AUTO_INCREMENT,`branch_id` bigint(20) NOT NULL,`xid` varchar(100) NOT NULL,`context` varchar(128) NOT NULL,`rollback_info` longblob NOT NULL,`log_status` int(11) NOT NULL,`log_created` datetime NOT NULL,`log_modified` datetime NOT NULL,`ext` varchar(100) DEFAULT NULL,PRIMARY KEY (`id`),UNIQUE KEY `ux_undo_log` (`xid`,`branch_id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;2️⃣:从地址
https://github.com/seata/seata/releases下载Seata服务器软件包,Seata服务器就是负责全局协调的事务协调者TC老师下载的是windows的
seata-server-0.7.1.zip,老师说1.0.0版本的用法和0.x.x版本的用法不一样
3️⃣:在
pom.xml中导入依赖com.alibaba.cloud:spring-cloud-starter-alibaba-seata在IDEA项目的
External Libraries中存放着我们引入的第三方依赖,其中的com.alibaba.cloud:spring-cloud-starter-alibaba-seata即seata的源码中的GlobalTransactionAutoConfiguration是seata全局事务配置com.alibaba.cloud:spring-cloud-starter-alibaba-seata依赖于io.seata:seata-all,这个就是seata的TC事务协调器对应的依赖,这个依赖的版本必须和seata的TC服务器[就是seata-server]版本保持一致,com.alibaba.cloud:spring-cloud-starter-alibaba-seata:2.1.0.RELEASE对应io.seata:seata-all:0.7.1
xxxxxxxxxx<!--seata--><dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-alibaba-seata</artifactId></dependency>4️⃣:在windows本机解压
seata-server-0.7.1.zip得到seata-server-0.7.1,目录结构如下bin:seata-server的命令行目录seata-server.bat:双击启动windows上的事务协调器,seata-server在注册中心上的服务名是serverAddr[新版本或者docker中叫seata-server],注意seata-server对JDK的版本有要求,JDK版本不对CMD启动会直接报错
conf:seata-server配置目录,用户能自定义配置的两个文件是file.conf和registry.confdb_store.sql:使用seata相关功能涉及到的所有数据库表sqlregistry.conf:注册中心相关配置[有这个配置文件是因为seata服务器也想把自身注册到注册中心里面作为系统的一部分,registry是配置注册中心信息的,config是对seata服务器进行配置]registry支持的注册中心类型被列举在
type字段上方,包含file 、nacos 、eureka、redis、zk、consul、etcd3、sofa默认是file,我们使用的是nacos,需要修改为nacosserverAddr:指定nacos的注册中心服务器地址
config支持的配置方式都被列举在
type字段上方,包含file 、nacos 、eureka、redis、zk、consul、etcd3、sofa,file表示使用本地的配置根目录下的file.conf做seata相关配置,nacos表示使用配置中心上的配置文件来做配置,其他的依次代表使用对应配置中心上的配置文件来做seata服务器的配置,我们使用file.conf直接在seata服务器本地的file.conf做seata服务器的相关配置
xxxxxxxxxxregistry {# file 、nacos 、eureka、redis、zk、consul、etcd3、sofa指定注册中心type = "file"nacos {serverAddr = "localhost"namespace = "public"cluster = "default"}eureka {serviceUrl = "http://localhost:1001/eureka"application = "default"weight = "1"}redis {serverAddr = "localhost:6379"db = "0"}zk {cluster = "default"serverAddr = "127.0.0.1:2181"session.timeout = 6000connect.timeout = 2000}consul {cluster = "default"serverAddr = "127.0.0.1:8500"}etcd3 {cluster = "default"serverAddr = "http://localhost:2379"}sofa {serverAddr = "127.0.0.1:9603"application = "default"region = "DEFAULT_ZONE"datacenter = "DefaultDataCenter"cluster = "default"group = "SEATA_GROUP"addressWaitTime = "3000"}file {name = "file.conf"}}config {# file、nacos 、apollo、zk、consul、etcd3指定配置中心type = "file"nacos {serverAddr = "localhost"namespace = "public"cluster = "default"}consul {serverAddr = "127.0.0.1:8500"}apollo {app.id = "seata-server"apollo.meta = "http://192.168.1.204:8801"}zk {serverAddr = "127.0.0.1:2181"session.timeout = 6000connect.timeout = 2000}etcd3 {serverAddr = "http://localhost:2379"}file {name = "file.conf"}}file.conftransport是seata的数据传输配置,type="TCP"表示使用TCP传输协议,server="NIO"服务器采用NIO的数据传输模式,heartbeat=true表示开启服务器心跳,thread-factory是线程工厂配置service是client是seata客户端配置store是事务日志存储配置,mode="file"表示使用的配置方式,默认支持file[事务日志文件存储在seata服务器,store中的file标签配置事务日志文件存储的目录dir和日志文件大小]和db[事务日志文件存储在数据库中,store中的db标签配置事务日志文件存储的数据库地址url,用户名user和密码password,全局事务日志表名global.table、分支事务表名branch.table和锁表名lock-table,这三张表就是db_store.sql中的三张表],使用数据库存储需要去数据库创建对应三张表,我们这里图方便直接在seata服务器本地存储事务日志文件,什么都不需要管很方便
xxxxxxxxxxtransport {# tcp udt unix-domain-sockettype = "TCP"#NIO NATIVEserver = "NIO"#enable heartbeatheartbeat = true#thread factory for nettythread-factory {boss-thread-prefix = "NettyBoss"worker-thread-prefix = "NettyServerNIOWorker"server-executor-thread-prefix = "NettyServerBizHandler"share-boss-worker = falseclient-selector-thread-prefix = "NettyClientSelector"client-selector-thread-size = 1client-worker-thread-prefix = "NettyClientWorkerThread"# netty boss thread size,will not be used for UDTboss-thread-size = 1#auto default pin or 8worker-thread-size = 8}shutdown {# when destroy server, wait secondswait = 3}serialization = "seata"compressor = "none"}service {#vgroup->rgroupvgroup_mapping.my_test_tx_group = "default"#only support single nodedefault.grouplist = "127.0.0.1:8091"#degrade current not supportenableDegrade = false#disabledisable = false#unit ms,s,m,h,d represents milliseconds, seconds, minutes, hours, days, default permanentmax.commit.retry.timeout = "-1"max.rollback.retry.timeout = "-1"}client {async.commit.buffer.limit = 10000lock {retry.internal = 10retry.times = 30}report.retry.count = 5}## transaction log storestore {## store mode: file、dbmode = "file"## file storefile {dir = "sessionStore"# branch session size , if exceeded first try compress lockkey, still exceeded throws exceptionsmax-branch-session-size = 16384# globe session size , if exceeded throws exceptionsmax-global-session-size = 512# file buffer size , if exceeded allocate new bufferfile-write-buffer-cache-size = 16384# when recover batch read sizesession.reload.read_size = 100# async, syncflush-disk-mode = async}## database storedb {## the implement of javax.sql.DataSource, such as DruidDataSource(druid)/BasicDataSource(dbcp) etc.datasource = "dbcp"## mysql/oracle/h2/oceanbase etc.db-type = "mysql"url = "jdbc:mysql://127.0.0.1:3306/seata"user = "mysql"password = "mysql"min-conn = 1max-conn = 3global.table = "global_table"branch.table = "branch_table"lock-table = "lock_table"query-limit = 100}}lock {## the lock store mode: local、remotemode = "remote"local {## store locks in user's database}remote {## store locks in the seata's server}}recovery {committing-retry-delay = 30asyn-committing-retry-delay = 30rollbacking-retry-delay = 30timeout-retry-delay = 30}transaction {undo.data.validation = trueundo.log.serialization = "jackson"}## metrics settingsmetrics {enabled = falseregistry-type = "compact"# multi exporters use comma dividedexporter-list = "prometheus"exporter-prometheus-port = 9898}
lib:
5️⃣:给需要使用分布式事务的业务方法标注全局事务注解
@GlobalTransactional[注意只有调用远程方法的业务方法才需要标注全局事务注解,只是作为被调用方法只需要标注本地事务即可],注意每个服务内部的方法本地控制事务仍然要标注本地事务注解@Transactional老师说的只要给分布式大事务标注全局事务注解
@GlobalTransactional注解就行,每个远程小事务都使用本地事务注解@Transactional,但是我这里有疑问,如果远程调用方法调用了远程服务,那么这个远程服务是否还需要标注全局事务注解@GlobalTransactional@GlobalTransactional注解中配置了事务超时时间timeoutMills,要回滚的异常rollbackFor,无需回滚的异常noRollbackFor其他步骤按照文档地址
https://seata.apache.org/zh-cn/docs/user/quickstart/补足剩余操作,在
https://github.com/apache/incubator-seata-samples/tree/master/at-sample中有seata与各种场景下比如dubbo、MyBatis、springcloud-jpa-seata的整合示例,在每个服务实例中的README.md中是对应应用场景的使用方法介绍,以springcloud-jpa-seata即springcloud-jpa应用场景整合seata为例除去介绍的在快速开始已经完成的准备工作,还需要额外注入一个
DataSourceProxy容器组件,该组件是seata的代理数据源,seata想要控制住事务需要通过seata包装默认的数据源让seata来代理数据源才能实现使用seata控制事务的目的
6️⃣:所有使用
seata分布式事务的微服务都需要使用seata的DataSourceProxy代理默认的数据源具体实现是手动给数据库注入一个默认要使用的数据源,然后通过该数据源组件再创建注入一个数据源代理对象
DataSourceProxy组件,并使用@Primary注解将数据源代理对象作为主数据源,注意下面这个配置在SpringBoot低版本可用,但是在SpringBoot2.0以后容易引起循环引入异常注意:在
Seata0.9版本以后,提供了DataSource默认代理的功能,并且默认是开启的,不用再手动的去把DataSource放入到DataSourceProxy中了
xxxxxxxxxxpublic class DataSourceConfig {(prefix = "spring.datasource")public DruidDataSource druidDataSource() {return new DruidDataSource();}/*** 需要将 DataSourceProxy 设置为主数据源,否则事务无法回滚** @param druidDataSource The DruidDataSource* @return The default datasource*/("dataSource")public DataSource dataSource(DruidDataSource druidDataSource) {return new DataSourceProxy(druidDataSource);}}SpringBoot默认数据源配置DataSourceAutoConfigurationxxxxxxxxxx/*** {@link EnableAutoConfiguration Auto-configuration} for {@link DataSource}.** @author Dave Syer* @author Phillip Webb* @author Stephane Nicoll* @author Kazuki Shimizu* @since 1.0.0*/({ DataSource.class, EmbeddedDatabaseType.class })//@ConditionalOnClass注解表示只要系统内有数据源DataSource的子实现类就会默认开启数据源的自动配置(DataSourceProperties.class)//@EnableConfigurationProperties表示开启属性配置类DataSourceProperties的属性绑定功能,并将该配置类注入到容器({ DataSourcePoolMetadataProvidersConfiguration.class, DataSourceInitializationConfiguration.class })public class DataSourceAutoConfiguration {(EmbeddedDatabaseCondition.class)({ DataSource.class, XADataSource.class })(EmbeddedDataSourceConfiguration.class)protected static class EmbeddedDatabaseConfiguration {}//@Import是导入配置文件,SpringBoot默认就是使用的Hikari数据源,SpringBoot默认就是通过这里的DataSourceConfiguration.Hikari.class导入的数据源配置(PooledDataSourceCondition.class)({ DataSource.class, XADataSource.class })({ DataSourceConfiguration.Hikari.class, DataSourceConfiguration.Tomcat.class,DataSourceConfiguration.Dbcp2.class, DataSourceConfiguration.Generic.class,DataSourceJmxConfiguration.class })1️⃣ //默认的数据源配置类会通过@Import注解给SpringBoot默认的数据源HikariDataSource做配置protected static class PooledDataSourceConfiguration {}/*** {@link AnyNestedCondition} that checks that either {@code spring.datasource.type}* is set or {@link PooledDataSourceAvailableCondition} applies.*/static class PooledDataSourceCondition extends AnyNestedCondition {PooledDataSourceCondition() {super(ConfigurationPhase.PARSE_CONFIGURATION);}(prefix = "spring.datasource", name = "type")static class ExplicitType {}(PooledDataSourceAvailableCondition.class)static class PooledDataSourceAvailable {}}/*** {@link Condition} to test if a supported connection pool is available.*/static class PooledDataSourceAvailableCondition extends SpringBootCondition {public ConditionOutcome getMatchOutcome(ConditionContext context, AnnotatedTypeMetadata metadata) {ConditionMessage.Builder message = ConditionMessage.forCondition("PooledDataSource");if (getDataSourceClassLoader(context) != null) {return ConditionOutcome.match(message.foundExactly("supported DataSource"));}return ConditionOutcome.noMatch(message.didNotFind("supported DataSource").atAll());}/*** Returns the class loader for the {@link DataSource} class. Used to ensure that* the driver class can actually be loaded by the data source.* @param context the condition context* @return the class loader*/private ClassLoader getDataSourceClassLoader(ConditionContext context) {Class<?> dataSourceClass = DataSourceBuilder.findType(context.getClassLoader());return (dataSourceClass != null) ? dataSourceClass.getClassLoader() : null;}}/*** {@link Condition} to detect when an embedded {@link DataSource} type can be used.* If a pooled {@link DataSource} is available, it will always be preferred to an* {@code EmbeddedDatabase}.*/static class EmbeddedDatabaseCondition extends SpringBootCondition {private final SpringBootCondition pooledCondition = new PooledDataSourceCondition();public ConditionOutcome getMatchOutcome(ConditionContext context, AnnotatedTypeMetadata metadata) {ConditionMessage.Builder message = ConditionMessage.forCondition("EmbeddedDataSource");if (anyMatches(context, metadata, this.pooledCondition)) {return ConditionOutcome.noMatch(message.foundExactly("supported pooled data source"));}EmbeddedDatabaseType type = EmbeddedDatabaseConnection.get(context.getClassLoader()).getType();if (type == null) {return ConditionOutcome.noMatch(message.didNotFind("embedded database").atAll());}return ConditionOutcome.match(message.found("embedded database").items(type));}}}1️⃣/*** Actual DataSource configurations imported by {@link DataSourceAutoConfiguration}.** @author Dave Syer* @author Phillip Webb* @author Stephane Nicoll*/abstract class DataSourceConfiguration {("unchecked")protected static <T> T createDataSource(DataSourceProperties properties, Class<? extends DataSource> type) {return (T) properties.initializeDataSourceBuilder().type(type).build();//在实例化数据源的时候内部类会通过方法名来调用DataSourceConfiguration的createDataSource方法,实际调用的是数据源配置绑定类中的实例方法dataSourceProperties.initializeDataSourceBuilder().type(type).build()来创建的,并且在type方法中传参要实例化的数据源对象类型,我们可以学习这个方法直接抄这个数据源初始化代码来自己创建一个数据源组件,并使用该数据源组件在系统启动时做一些额外的操作,比如将我们创建的数据源用一个数据源代理对象来进行包装进而控制分布式全局事务}/*** Tomcat Pool DataSource configuration.*/(proxyBeanMethods = false)(org.apache.tomcat.jdbc.pool.DataSource.class)(DataSource.class)(name = "spring.datasource.type", havingValue = "org.apache.tomcat.jdbc.pool.DataSource",matchIfMissing = true)static class Tomcat {(prefix = "spring.datasource.tomcat")org.apache.tomcat.jdbc.pool.DataSource dataSource(DataSourceProperties properties) {org.apache.tomcat.jdbc.pool.DataSource dataSource = createDataSource(properties,org.apache.tomcat.jdbc.pool.DataSource.class);DatabaseDriver databaseDriver = DatabaseDriver.fromJdbcUrl(properties.determineUrl());String validationQuery = databaseDriver.getValidationQuery();if (validationQuery != null) {dataSource.setTestOnBorrow(true);dataSource.setValidationQuery(validationQuery);}return dataSource;}}/*** Hikari DataSource configuration.*/(proxyBeanMethods = false)(HikariDataSource.class)//@ConditionalOnClass在项目中有HikariDataSource这个类才会执行该配置类(DataSource.class)//@ConditionalOnMissingBean注解的意思是当容器中没有数据源的时候才会执行该配置类给容器注入Hikari数据源(name = "spring.datasource.type", havingValue = "com.zaxxer.hikari.HikariDataSource",matchIfMissing = true)static class Hikari {//给容器中添加数据源组件HikariDataSource,组件的所有配置都以spring.datasource.hikari作为前缀,配置项和配置类DataSourceProperties绑定(prefix = "spring.datasource.hikari")HikariDataSource dataSource(DataSourceProperties properties) {HikariDataSource dataSource = createDataSource(properties, HikariDataSource.class);//默认数据源是通过DataSourceConfiguration的createDataSource(properties, HikariDataSource.class);方法创建的,注意啊,静态内部类可以直接通过方法名调用外部类的静态方法,这个写法以前总结过if (StringUtils.hasText(properties.getName())) {dataSource.setPoolName(properties.getName());}//创建数据源以后判断属性绑定类中是否有name属性,如果有name属性就使用该name属性给数据源池设置名字,我们也模仿这种方式来自定义一个数据源组件return dataSource;}}/*** DBCP DataSource configuration.*/(proxyBeanMethods = false)(org.apache.commons.dbcp2.BasicDataSource.class)(DataSource.class)(name = "spring.datasource.type", havingValue = "org.apache.commons.dbcp2.BasicDataSource",matchIfMissing = true)static class Dbcp2 {(prefix = "spring.datasource.dbcp2")org.apache.commons.dbcp2.BasicDataSource dataSource(DataSourceProperties properties) {return createDataSource(properties, org.apache.commons.dbcp2.BasicDataSource.class);}}/*** Generic DataSource configuration.*/(proxyBeanMethods = false)(DataSource.class)(name = "spring.datasource.type")static class Generic {DataSource dataSource(DataSourceProperties properties) {return properties.initializeDataSourceBuilder().build();}}}通过模仿
SpringBoot初始化数据源的方式来初始化数据源并使用seata的数据源代理对象来包装数据源组件注意导入了数据源代理对象,该代理对象中保存了数据源
HikariDataSource的信息,因为系统中有了DataSource,因此默认的HikariDataSource组件不会再自动注入了
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 自定义seata配置* @创建日期 2024/11/24* @since 1.0.0*/public class CustomSeataConfig {public DataSource dataSource(DataSourceProperties properties){HikariDataSource dataSource = properties.initializeDataSourceBuilder().type(HikariDataSource.class).build();if(StringUtils.hasText(properties.getName())){dataSource.setPoolName(properties.getName());}return new DataSourceProxy(dataSource);}}
7️⃣:将
seata服务器下的conf目录下的registry.conf和file.conf给每个服务的类路径下都拷贝一份将
file.conf文件中的service.vgroup_mapping配置更改成和当前服务的spring.application.name保持一致即service.vgroup_mapping.mall-order-fescar-service-group="default"[在org.springframework.cloud:spring-cloud-starter-alibaba-seata的org.springframework.cloud.alibaba.seata.GlobalTransactionAutoConfiguration类中,默认会使用${spring.application.name}-fescar-service-group作为服务名注册到Seata-Server上,如果和file.conf中的配置不一致,会提示no available server to connect错误,我们也可以通过配置spring.cloud.alibaba.seata.tx-service-group修改这个默认后缀,但是该配置必须和file.conf中的配置service.vgroup_mapping.xxx这个xxx保持一致]
Seata的局限性Seata的AT模式不适用于高并发场景,适合使用在保存商品信息这种并发量不高的场景,保存商品信息需要远程调用库存服务、优惠券服务;此时就适合使用Seata来做分布式事务控制;就是Seata的AT模式适合用在后台管理系统这种并发量不太高的场景做分布式事务控制像下单这种典型的高并发场景就不适合使用
Seata的AT模式,Seata的AT模式在事务进行期间要获取全局锁、会将全局事务的业务变成串行执行,所有人都需要等待上一个订单创建完才能执行创建下一个订单,这样系统就没法使用了,因此高并发场景下一般不考虑使用XA二阶段提交模式,也不会考虑TCC手动事务补偿模式;高并发场景下更多的考虑基于可靠消息投递加最终一致性的异步确保型的最大努力通知型方案,因此我们的订单服务不使用
Seata分布式事务解决方案,而选择使用柔性事务中的可靠消息投递+最终一致性的异步确保型方案即使用
Seata来控制分布式事务提交回滚效率极低,为了保证高并发,我们下订单通过软一致性让订单创建服务出现问题由本地事务控制回滚,在出现异常回滚的同时我们给消息中间件发送消息通知库存服务对锁定的库存通过反向补偿的方式进行回滚,订单服务只需要给消息队列发送消息,无需等待多个远程调用回滚完毕,即订单创建服务的性能损失几乎没有我们给库存服务专门设置一个解锁库存的业务,库存解锁发起方给消息中间件对应库存服务的专门存储解锁库存消息的队列发送解锁库存消息,库存服务监听到解锁库存消息就在后台自己去慢慢地解锁库存,无需保证强一致,只需要保证一段时间后最终一致即可
❓:seata目前在AT模式下不支持批量插入记录,也不支持MP的addBatch方法,AT模式下只能一条一条数据循环遍历来插入,很消耗数据库性能https://blog.csdn.net/qq_33240556/article/details/140790581
异步确保型方案
这种方案不仅能保证分布式系统下的最终一致性,还能保证并发性能,还能适应异构服务系统下的业务协作
订单业务逻辑


带回滚的锁库存逻辑
数据库
mall-sms中的表sms_stock_order_task记录着当前那个订单正在锁库存,在表sms_stock_order_task_detail表中记录着商品id、锁定库存的数量、锁定库存所在仓库id、订单任务号;即锁库存的时候先给数据库保存要锁定的库存记录,然后再锁定库存;只要锁定库存成功,库存相关的三张表因为本地事务都会成功保存锁库存记录;如果锁失败了数据库因为事务不会有锁库存记录,库存也不会锁定成功这样库存锁定表中存在的就是下单成功锁定库存的记录和下单失败但是锁定库存成功的记录,我们可以考虑使用一个定时任务,每隔一段时间就扫描一次数据库,检查一下哪些订单没有创建但是有锁定库存的记录,把这些锁定库存记录拿出来重新把库存补偿回滚一下,但是使用定时任务来定期扫描整个数据库表是很麻烦的一件事,我们通过引入延时消息队列来实现定时功能
延时队列的原理是当库存锁定成功以后我们将库存锁定成功的消息发送给延时队列,但是在一定时间内消息被暂存在延时队列中不要往外发送,即锁定库存成功的消息暂存在延时队列中一段时间,在订单支付时间过期以后我们将该消息发送给解锁库存服务,解锁库存服务去检查订单是否被取消,如果订单根本没有创建或者因为订单未支付而被自动取消了就去数据库根据对应的锁库存记录将库存解锁,即锁定的库存在订单最大失效时间以后才固定进行解锁,通过延时消息队列来控制这个定时功能
延时队列锁库存的业务流程
1️⃣:创建订单锁定库存成功后,给主题交换器
stock-event-exchange发送库存工作单消息,消息的路由键stock.locked,被主题交换器路由到队列stock.delay.queue中等待50分钟过期时间2️⃣:库存工作单在消息存活时间到期以后,队列将消息的路由键更改为
stock.release,通过主题交换器stock-event-exchange将消息路由到队列stock.release.stock.queue,由该队列将消息转发给消费者库存服务3️⃣:消费者库存服务收到库存工作单消息,检查订单服务对应订单的状态,如果订单未被成功创建或者订单未支付就解锁被锁定的库存
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 库存服务RabbitMQ配置* @创建日期 2024/12/02* @since 1.0.0*/public class StockRabbitMQConfig {/*** @return {@link MessageConverter }* @描述 给容器中注入一个使用Jackson将消息对象序列化为json对象的消息转换器* @author Earl* @version 1.0.0* @创建日期 2024/11/01* @since 1.0.0*/public MessageConverter messageConverter(){return new Jackson2JsonMessageConverter();}/*** @return {@link Queue }* @描述 库存延迟队列延时队列* @author Earl* @version 1.0.0* @创建日期 2024/11/26* @since 1.0.0*/public Queue stockDelayQueue(){Map<String, Object> arguments = new HashMap<>();arguments.put("x-dead-letter-exchange","stock-event-exchange");arguments.put("x-dead-letter-routing-key","stock.release");arguments.put("x-message-ttl",120000);return new Queue("stock.delay.queue", true, false, false, arguments);}/*** @return {@link Queue }* @描述 库存延迟队列路由队列* @author Earl* @version 1.0.0* @创建日期 2024/11/26* @since 1.0.0*/public Queue stockReleaseStockQueue(){return new Queue("stock.release.stock.queue",true,false,false);}/*** @return {@link Exchange }* @描述 库存服务通用主题交换器* @author Earl* @version 1.0.0* @创建日期 2024/11/26* @since 1.0.0*/public Exchange stockEventExchange(){return new TopicExchange("stock-event-exchange",true,false);}/*** @return {@link Binding }* @描述 延迟队列的延时队列stock.delay.queue和库存服务通用交换器stock-event-exchange的绑定关系* @author Earl* @version 1.0.0* @创建日期 2024/11/26* @since 1.0.0*/public Binding orderCreateOrderBinding(){return new Binding("stock.delay.queue",Binding.DestinationType.QUEUE,"stock-event-exchange","stock.locked",null);}/*** @return {@link Binding }* @描述 延迟队列的路由队列stock.release.stock.queue和库存服务通用交换器stock-event-exchange的绑定关系* @author Earl* @version 1.0.0* @创建日期 2024/11/26* @since 1.0.0*/public Binding orderReleaseOrderBinding(){return new Binding("stock.release.stock.queue",Binding.DestinationType.QUEUE,"stock-event-exchange","stock.release.#",null);}}解锁库存逻辑
需要解锁库存的场景:
创建订单成功,订单过期没有支付被系统自动取消或者订单被用户手动取消时需要解锁库存
创建订单过程中,远程调用库存服务锁定库存成功,但是调用其他服务时出现异常导致创建订单整个业务回滚,之前成功锁定的库存就需要自动解锁来实现回滚,使用
Seata分布式事务性能太差,不适合下单这种高并发场景;基于柔性事务的可靠消息加最终一致性的分布式事务方案,在保证分布式事务下的性能同时,允许一定时间内的软一致性并确保库存数据的最终一致性
只要库存锁定成功就给RabbitMQ中对应的库存延迟队列发送库存工作单消息,使用
RabbitTemplate.convertAndSend()发送锁定库存消息,同时锁定库存以前我们要保存库存工作单信息[对应表wms_ware_order_task,保存订单Id、订单号],锁定存库成功以后要保存库存工作单详情[对应表wms_ware_order_task_detail,给该表添加bigint类型字段ware_id锁定库存所在仓库id;int类型的lock_status,其中1表示已锁定、2表示已解锁、3表示已扣减;注意MP更改了字段需要更改相应的Mapper文件中的resultMap标签;保存商品sku、商品数量、库存工作单id、锁定库存所在仓库id、默认锁定状态是已锁定1],锁定库存前先保存库存工作单,保存库存工作单是为了追溯锁定库存信息给消息队列发送的消息实体类直接写在common包下,该消息对象
StockLockedTo保存库存工作单id、该工作单下所有工作单详情id列表,老师这里发送消息的时机错了,所有商品都锁定成了才给消息队列发送消息,否则本地事务会自动回滚,老师是锁定一个商品就发送一条消息,如果事务回滚了发出去的消息就撤不回来了,而且老师这里发送的消息是全量的库存工作单详情数据
[消息]
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 库存被成功锁定消息* @创建日期 2024/12/02* @since 1.0.0*/public class StockLockedMessage {/*** 库存工作单*/private WareOrderTaskEntity wareOrderTask;/*** 库存工作单详情列表*/private List<WareOrderTaskDetailEntity> wareOrderTaskDetail;}[锁定库存保存库存工作单并发送消息]
xxxxxxxxxx/*** @param lockStock* @return {@link List }<{@link LockStockResultTo }>* @描述 根据订单和订单项数据锁定库存* @author Earl* @version 1.0.0* @创建日期 2024/12/01* @since 1.0.0*/public List<LockStockResultTo> lockStock(LockStockTo lockStock) throws RRException{//2. 锁定库存前创建库存工作单WareOrderTaskEntity wareOrderTask = new WareOrderTaskEntity();BeanUtils.copyProperties(lockStock,wareOrderTask);wareOrderTaskService.save(wareOrderTask);//1. 锁定库存List<LockStockTo.OrderItem> orderItems = lockStock.getOrderItems();List<Long> skuIds = orderItems.stream().map(LockStockTo.OrderItem::getSkuId).collect(Collectors.toList());Map<Long, LockStockTo.OrderItem> orderItemOfSku = orderItems.stream().collect(Collectors.toMap(LockStockTo.OrderItem::getSkuId, orderItem -> orderItem));//查询商品所在的全部仓库List<WareIdsOfSkuIdTo> wareIdsOfSkuIdTos=baseMapper.getWareBySkuIds(skuIds);if(wareIdsOfSkuIdTos.size()!=skuIds.size()){throw new RRException(StatusCode.NO_STOCK_EXCEPTION.getMsg(),StatusCode.NO_STOCK_EXCEPTION.getCode());}ArrayList<LockStockResultTo> lockStockResults = new ArrayList<>();ArrayList<WareOrderTaskDetailEntity> wareOrderTaskDetails = new ArrayList<>();for (WareIdsOfSkuIdTo wareIdsOfSkuIdTo : wareIdsOfSkuIdTos) {Long skuId = wareIdsOfSkuIdTo.getSkuId();String[] wareIds = wareIdsOfSkuIdTo.getWareIds().split(",");Boolean skuLocked = false;for (String wareId : Arrays.asList(wareIds)) {if(baseMapper.tryLockStock(wareId,skuId,orderItemOfSku.get(skuId).getSkuQuantity())==1){//准备锁定库存的响应数据LockStockResultTo lockStockResult = new LockStockResultTo();skuLocked = true;lockStockResult.setLocked(true);lockStockResult.setLockQuantity(orderItemOfSku.get(skuId).getSkuQuantity());lockStockResult.setWareId(Long.parseLong(wareId));lockStockResult.setSkuId(skuId);lockStockResults.add(lockStockResult);//准备库存工作单详情WareOrderTaskDetailEntity wareOrderTaskDetail = new WareOrderTaskDetailEntity();wareOrderTaskDetail.setTaskId(wareOrderTask.getId());wareOrderTaskDetail.setSkuId(skuId);wareOrderTaskDetail.setSkuName(orderItemOfSku.get(skuId).getSkuName());wareOrderTaskDetail.setSkuNum(orderItemOfSku.get(skuId).getSkuQuantity());wareOrderTaskDetail.setWareId(Long.parseLong(wareId));wareOrderTaskDetails.add(wareOrderTaskDetail);break;}}if(!skuLocked){throw new RRException("商品"+skuId+StatusCode.NO_STOCK_EXCEPTION.getMsg(),StatusCode.NO_STOCK_EXCEPTION.getCode());}}//for (WareOrderTaskDetailEntity wareOrderTaskDetail : wareOrderTaskDetails) {// wareOrderTaskDetailService.save(wareOrderTaskDetail);//}wareOrderTaskDetailService.saveBatch(wareOrderTaskDetails);StockLockedMessage stockLockedMessage = new StockLockedMessage();stockLockedMessage.setWareOrderTask(wareOrderTask);stockLockedMessage.setWareOrderTaskDetail(wareOrderTaskDetails);rabbitTemplate.convertAndSend("stock-event-exchange","stock.locked",stockLockedMessage);return lockStockResults;}使用
@RabbitHandler监听锁定库存消息队列,获取到消息对象,按以下情况执行解锁库存逻辑1️⃣:创建订单过程中,库存锁定成功,但是接下来创建订单出现问题,整个订单回滚,被锁定的库存需要自动解锁
只要库存工作单详情存在,就说明库存锁定成功,此时我们就要看订单状态来判断是否需要解锁库存,如果订单都没有说明订单没有被成功创建,此时就要使用库存工作单详情来解锁库存
如果有订单查看订单状态,如果订单已经被取消就解锁库存,只要订单没有被取消就不能解锁库存,订单被取消字段
status等于4根据库存工作单的id去订单服务查询订单实体类,如果订单不存在或者订单的
status字段为4就调用unLockStock方法解锁库存
2️⃣:订单创建失败是由于库存锁定失败导致的
库存工作单数据没有是库存本地事务整体回滚导致的,库存工作单记录不会创建,锁定库存操作也会全部自动回滚,这种情况无需解锁
解锁库存需要知道商品的
skuId、锁定库存所在仓库id、锁定库存数量、库存工作单详情id,解锁就是将原来的增加的锁定库存的字段再减掉UPDATE wms_ware_sku SET stock_locked = stock_locked + #{num} WHERE sku_id=#{skuId} AND ware_id = #{wareId}🚁:自动应答的消息队列,一旦在消息的消费过程中出现异常导致消息无法被正常消费,消息就丢失了,比如Feign远程调用网络闪断,或者远程服务的Feign调用必须携带用户的登录状态但是实际请求没有携带用户登录状态被远程服务拦截,抛出异常终止后续方法执行,此时消息就彻底丢失了
📓:使用配置
spring.rabbitmq.listener.simple.acknowledge-mode=manual开启消息接收手动应答,在订单解锁成功以后使用方法channel.basicAck(message.getMessageProperties().getDeliveryTag(),false)来做消息接收手动应答,解锁成功立马手动应答,无需解锁什么也不用做立马手动应答,只要在应答后发生异常也不会导致消息丢失;如果远程调用没有成功返回在库存解锁以前出现问题,我们使用方法channel.basicReject(message.getMessageProperties().getDeliveryTag(),true)来手动拒绝消息并将消息重新放到队列中,给别人继续消费消息解锁库存的机会,比如由于分区故障为了保证一致性部分服务不可用
❓:订单服务所有远程调用请求都要求有登录状态,但是我们的消息队列监听方法的远程调用不可能带用户登录状态,因此我们需要在订单服务的拦截器中放行所有消息队列监听方法调用的订单服务远程接口,特别注意,这个需要被放行的请求路径还拼接了请求参数导致请求路径是动态的
🔑:我们通过在拦截器中放行指定URI的请求来实现这个目的,对于URI是变化的我们使用
Spring提供的boolean match = AntPathMatcher.match("/order/order/status/**",request.getRequestURI())[HttpServletRequest.getRequestURI()是获取请求路径的URI,HttpServletRequest.getRequestURL()是获取请求路径的URL],如果请求URI匹配我们需要的格式就直接通过拦截器的return true放行,无需再进行用户登录状态检查
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 用户登录状态拦截器* @创建日期 2024/11/09* @since 1.0.0*/public class LoginStatusInterceptor implements HandlerInterceptor {public static ThreadLocal<UserBaseInfoVo> loginUser=new ThreadLocal<>();public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {AntPathMatcher antPathMatcher = new AntPathMatcher();if(antPathMatcher.match("/order/order/get/**", request.getRequestURI())){return true;}UserBaseInfoVo attribute = (UserBaseInfoVo)request.getSession().getAttribute(MallConstant.SESSION_USER_LOGIN_STATUS_KEY);if(attribute!=null){loginUser.set(attribute);return true;}else{request.getSession().setAttribute("tip","请先登录");response.sendRedirect("http://auth.earlmall.com/login.html");return false;}}}专门抽取一个消息队列的监听器Service来处理消息队列中的消息
在类上标注
@RabbitListener(queues="stock.release.stock.queue")来监听指定队列,在类上标注@Service注解将该类的实例化对象作为容器组件,在具体的方法上标注注解@RabbitHandler,在该方法中调用库存服务实现的解锁库存逻辑,解锁库存的方法出现任何异常都手动拒绝消息并重新入队列,只要解锁库存方法成功调用就手动应答接收消息,远程调用如果状态码不是0说明没有查到对应订单的实体类,此时直接抛异常执行拒绝接收消息的逻辑
[监听队列消息]
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 库存释放队列监听器* @创建日期 2024/12/02* @since 1.0.0*/(queues = "stock.release.stock.queue")public class StockReleaseQueueListenerImpl extends ServiceImpl<MessageDao, MessageEntity> implements StockReleaseQueueListener {private WareSkuService wareSkuService;/*** @param message* @param stockLockedMessage* @param channel* @描述 根据到期的锁定库存消息释放库存* @author Earl* @version 1.0.0* @创建日期 2024/12/02* @since 1.0.0*/public void tryReleaseStock(Message message, StockLockedMessage stockLockedMessage, Channel channel) {try{wareSkuService.tryReleaseStock(stockLockedMessage.getWareOrderTask().getOrderSn());channel.basicAck(message.getMessageProperties().getDeliveryTag(),false);}catch (Exception e){try {channel.basicReject(message.getMessageProperties().getDeliveryTag(),true);} catch (Exception exception) {MessageEntity messageLog = new MessageEntity();messageLog.setMessageStatus(2);messageLog.setClassType(stockLockedMessage.getClass().getTypeName());messageLog.setRoutingKey(message.getMessageProperties().getReceivedRoutingKey());messageLog.setToExchange(message.getMessageProperties().getReceivedExchange());messageLog.setContent(JSON.toJSONString(stockLockedMessage));save(messageLog);}}}}[解锁库存]
xxxxxxxxxx/*** @param orderSn* @描述 根据库存锁定消息尝试解锁库存* @author Earl* @version 1.0.0* @创建日期 2024/12/02* @since 1.0.0*/public void tryReleaseStock(String orderSn) {//1. 根据订单号远程查询订单服务对应的订单状态,如果订单不存在或者订单状态不是已关闭就不解锁库存R res = orderFeignClient.getOrderByOrderSn(orderSn);OrderTo order = res.get("order", new TypeReference<OrderTo>() {});if(order==null && order.getStatus()==4){return;}//2. 根据订单号查询库存工作单idWareOrderTaskEntity wareOrderTaskEntity = wareOrderTaskService.getOne(new QueryWrapper<WareOrderTaskEntity>().eq("order_sn", orderSn));if(wareOrderTaskEntity==null){return;}List<WareOrderTaskDetailEntity> wareOrderTaskDetails = wareOrderTaskDetailService.list(new QueryWrapper<WareOrderTaskDetailEntity>().eq("task_id", wareOrderTaskEntity.getId()));for (WareOrderTaskDetailEntity wareOrderTaskDetail : wareOrderTaskDetails) {//检索库存工作单状态,只有库存工作单状态为未解锁时才解锁库存,如果不为未解锁本条库存不解锁if(wareOrderTaskDetail.getLockStatus()!=2){baseMapper.releaseStock(wareOrderTaskDetail.getSkuNum(),wareOrderTaskDetail.getSkuId(),wareOrderTaskDetail.getWareId());//解锁后将库存工作单状态更改为已解锁wareOrderTaskDetail.setLockStatus(2);wareOrderTaskDetailService.updateById(wareOrderTaskDetail);}}}解锁库存成功后通过库存工作单详情id将库存工作单详情的状态
lock_status更改为已解锁2,增加前面解锁库存的条件只有库存工作单详情为已锁定状态且需要解锁时才能解锁库存
带回滚的锁库存实现
给库存服务
mall-ware引入、配置RabbitMQ并在主启动类上标注@EnableRabbit开启RabbitMQ功能配置
RabbitMQ的消息的JSON序列化机制给库存服务添加一个默认交换器
stock-event-exchange交换器使用
Topic交换器类型,因为该交换器需要绑定多个队列,而且还需要使用对不同消息的路由键进行模糊匹配的功能
给库存服务添加一个释放库存队列
stock.release.stock.queue,支持持久化,不支持排他和自动删除,普通队列不需要设置参数给库存服务添加一个延迟库存工作单消息的队列
stock.delay.queue,给该延时队列设置死信交换器stock-event-exchange,设置死信的路由键为stock.release,设置队列的消息存活时间为120秒[方便测试用的,比验证订单创建的延迟队列多一分钟],支持持久化,不支持排他和自动删除给库存服务的库存释放队列和交换器添加一个绑定关系,绑定目的地
stock.release.stock.queue,交换器stock-event-exchange,绑定键stock.release.#给库存服务的库存延时队列和交换器添加一个绑定关系,绑定目的地
stock.delay.queue,交换器stock-event-exchange,绑定键stock.delay.#监听一个队列让以上所有容器组件都通过
SpringBoot自动去RabbitMQ中检查创建取消订单逻辑
订单服务队列和交换器组件和绑定关系
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 自定义RabbitMQ配置* 1. 使用@Bean注解注入容器的队列、交换器、绑定关系如果在RabbitMQ服务器中没有SpringBoot会自动在RabbitMQ服务器中进行创建* @创建日期 2024/11/26* @since 1.0.0*/public class CustomRabbitMQConfig {/*** @return {@link Queue }* @描述 订单延迟队列延时队列* @author Earl* @version 1.0.0* @创建日期 2024/11/26* @since 1.0.0*/public Queue orderDelayQueue(){Map<String, Object> arguments = new HashMap<>();arguments.put("x-dead-letter-exchange","order-event-exchange");arguments.put("x-dead-letter-routing-key","order.release.order");arguments.put("x-message-ttl",60000);return new Queue("order.delay.queue", true, false, false, arguments);}/*** @return {@link Queue }* @描述 订单延迟队列路由队列* @author Earl* @version 1.0.0* @创建日期 2024/11/26* @since 1.0.0*/public Queue orderReleaseOrderQueue(){return new Queue("order.release.order.queue",true,false,false);}/*** @return {@link Exchange }* @描述 订单服务通用主题交换器* @author Earl* @version 1.0.0* @创建日期 2024/11/26* @since 1.0.0*/public Exchange orderEventExchange(){return new TopicExchange("order-event-exchange",true,false);}/*** @return {@link Binding }* @描述 延迟队列的延时队列order.delay.queue和订单服务通用交换器order-event-exchange的绑定关系* @author Earl* @version 1.0.0* @创建日期 2024/11/26* @since 1.0.0*/public Binding orderCreateOrderBinding(){return new Binding("order.delay.queue",Binding.DestinationType.QUEUE,"order-event-exchange","order.create.order",null);}/*** @return {@link Binding }* @描述 延迟队列的路由队列order.release.order.queue和订单服务通用交换器order-event-exchange的绑定关系* @author Earl* @version 1.0.0* @创建日期 2024/11/26* @since 1.0.0*/public Binding orderReleaseOrderBinding(){return new Binding("order.release.order.queue",Binding.DestinationType.QUEUE,"order-event-exchange","order.release.order",null);}public Binding orderReleaseStockBinding(){return new Binding("stock.release.stock.queue",Binding.DestinationType.QUEUE,"order-event-exchange","order.release.other.#",null);}}订单创建成功就给交换器
order-event-exchange发送消息,消息路由键order.create.order,保存的消息是OrderCreateTO.getOrder(),消息会被交换器路由到order.delay.queue[队列中的消息延时时间为30min],消息变成死信后路由键配置成order.release.order并将消息转发到order-event-exchange路由到order.release.order.queue被订单服务监听,订单服务监听接收取消订单并将消息转发以路由键order.release.other通过交换器order-event-exchange,队列将消息转发给订单服务[订单服务创建订单发起消息]
xxxxxxxxxx/*** @param orderParam* @return {@link PayVo }* @描述 创建订单* @author Earl* @version 1.0.0* @创建日期 2024/11/30* @since 1.0.0*///@GlobalTransactionalpublic PayVo createOrder(OrderSubmitParamVo orderParam) throws RRException{UserBaseInfoVo userBaseInfo = LoginStatusInterceptor.loginUser.get();String orderSn = IdWorker.getTimeId();Long userId = userBaseInfo.getId();//1. 校验订单提交令牌,校验失败抛出表单重复提交异常if(!verifyOrderSubmitToken(userId,orderParam.getToken())){throw new RRException(StatusCode.FORM_REPEAT_EXCEPTION.getMsg(),StatusCode.FORM_REPEAT_EXCEPTION.getCode());}//2. 创建订单OrderEntity order = createOrder(userId, orderParam.getAddrId(),orderSn);//3. 创建订单项列表//远程调用购物车服务通过用户id获取购物车被选中的购物项List<OrderStatementVo.SelectedCartItemVo> selectedCartItems = cartFeignClient.getSelectedCartItem(userId);if(selectedCartItems==null || selectedCartItems.size()<=0){throw new RRException(StatusCode.NO_CART_ITEM_EXCEPTION.getMsg(),StatusCode.NO_CART_ITEM_EXCEPTION.getCode());}List<OrderItemEntity> orderItems = createOrderItems(orderSn,selectedCartItems);//4. 计算订单价格calculateOrderAmount(order,orderItems);//7. 验价if (Math.abs(order.getPayAmount().subtract(orderParam.getTotalPrice()).doubleValue())>=0.01) {throw new RRException(StatusCode.PRICE_VERIFY_EXCEPTION.getMsg()+"核算金额: ¥"+orderParam.getTotalPrice()+",实际金额: ¥"+order.getPayAmount(),StatusCode.PRICE_VERIFY_EXCEPTION.getCode());}//5. 保存订单记录和订单项记录orderService.save(order);//seata目前在AT模式下不支持批量插入记录,https://blog.csdn.net/qq_33240556/article/details/140790581,反正我们后面要换成软性事务,后面再换成批量插入//for (OrderItemEntity orderItem : orderItems) {// orderItemService.save(orderItem);//}orderItemService.saveBatch(orderItems);//6. 锁定库存LockStockTo lockStock = new LockStockTo();lockStock.setOrderId(order.getId());lockStock.setOrderSn(orderSn);lockStock.setConsignee(order.getReceiverName());lockStock.setConsigneeTel(order.getReceiverPhone());lockStock.setDeliveryAddress(order.getReceiverDetailAddress());lockStock.setPaymentWay(1);lockStock.setOrderItems(orderItems);R res = stockFeignClient.lockStock(lockStock);if (res.getCode()!=0) {throw new RRException((String) res.get("msg"),res.getCode());}// 8.给消息队列发送消息OrderCreatedMessage orderCreatedMessage = new OrderCreatedMessage();orderCreatedMessage.setOrderSn(orderSn);rabbitTemplate.convertAndSend("order-event-exchange","order.create.order",orderCreatedMessage);//封装视图数据,注意存入分布式session的数据对应实体类最好全部放在common包下,session中有的数据不论其他服务能否用到,// 其他服务必须包含session中所有数据的对应类型,否则其他服务即使没有使用对应的session也会直接报错PayVo pay = new PayVo();OrderVo orderVo = new OrderVo();BeanUtils.copyProperties(order,orderVo);List<OrderItemVo> orderItemVos = orderItems.stream().map(orderItem -> {OrderItemVo orderItemVo = new OrderItemVo();BeanUtils.copyProperties(orderItem, orderItemVo);return orderItemVo;}).collect(Collectors.toList());pay.setOrder(orderVo);pay.setOrderItems(orderItemVos);pay.setFare(order.getFreightAmount());pay.setPayablePrice(order.getPayAmount());return pay;}[订单服务接收消息取消订单并向库存服务发送消息]
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 库存释放队列监听器* @创建日期 2024/12/02* @since 1.0.0*/(queues = "order.release.order.queue")public class OrderReleaseQueueListenerImpl extends ServiceImpl<MessageDao,MessageEntity> implements OrderReleaseQueueListener {RabbitTemplate rabbitTemplate;OrderService orderService;/*** @param message* @param orderCreatedMessage* @param channel* @描述 根据到期的锁定库存消息释放库存* @author Earl* @version 1.0.0* @创建日期 2024/12/02* @since 1.0.0*/public void trySendMessageReleaseStock(Message message, OrderCreatedMessage orderCreatedMessage, Channel channel) {orderService.cancelOrder(orderCreatedMessage.getOrderSn());try{rabbitTemplate.convertAndSend("order-event-exchange","order.release.other",orderCreatedMessage);channel.basicAck(message.getMessageProperties().getDeliveryTag(),false);}catch (Exception e){try {channel.basicReject(message.getMessageProperties().getDeliveryTag(),true);} catch (Exception exception) {try {channel.basicAck(message.getMessageProperties().getDeliveryTag(),false);} catch (IOException ioException) {ioException.printStackTrace();}MessageEntity messageLog = new MessageEntity();messageLog.setMessageStatus(2);messageLog.setClassType(orderCreatedMessage.getClass().getTypeName());messageLog.setRoutingKey(message.getMessageProperties().getReceivedRoutingKey());messageLog.setToExchange(message.getMessageProperties().getReceivedExchange());messageLog.setContent(JSON.toJSONString(orderCreatedMessage));save(messageLog);}}}}订单服务收到消息根据订单id查询数据库对应的订单状态,如果订单状态为订单创建对应的状态码,将订单状态更改为取消订单对应状态码
xxxxxxxxxx/*** @param orderSn* @描述 根据订单号关闭订单* @author Earl* @version 1.0.0* @创建日期 2024/12/03* @since 1.0.0*/public void cancelOrder(String orderSn) {OrderEntity order = getOne(new QueryWrapper<OrderEntity>().eq("order_sn", orderSn));order.setStatus(OrderConstant.OrderStatus.CANCELLED.getCode());updateById(order);}通过监听消息队列消息在取消订单或者订单创建失败的情况下解锁库存
[消息队列监听]
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 库存释放队列监听器* @创建日期 2024/12/02* @since 1.0.0*/(queues = "stock.release.stock.queue")public class StockReleaseQueueListenerImpl extends ServiceImpl<MessageDao, MessageEntity> implements StockReleaseQueueListener {private WareSkuService wareSkuService;/*** @param message* @param stockLockedMessage* @param channel* @描述 根据到期的锁定库存消息释放库存* @author Earl* @version 1.0.0* @创建日期 2024/12/02* @since 1.0.0*/public void tryReleaseStock(Message message, StockLockedMessage stockLockedMessage, Channel channel) {String orderSn = stockLockedMessage.getWareOrderTask().getOrderSn();tryReleaseStock(orderSn,message,channel,JSON.toJSONString(stockLockedMessage),stockLockedMessage.getClass().toString());}/*** @param message* @param orderCreatedMessage* @param channel* @描述 取消订单自动解锁库存* @author Earl* @version 1.0.0* @创建日期 2024/12/03* @since 1.0.0*/public void tryReleaseStock(Message message, OrderCreatedMessage orderCreatedMessage,Channel channel){String orderSn = orderCreatedMessage.getOrderSn();tryReleaseStock(orderSn,message,channel,JSON.toJSONString(orderCreatedMessage),orderCreatedMessage.getClass().toString());}/*** @param orderSn* @param message* @param channel* @param messageContent* @param messageClassType* @描述 解锁库存方法* @author Earl* @version 1.0.0* @创建日期 2024/12/03* @since 1.0.0*/private void tryReleaseStock(String orderSn,Message message,Channel channel,String messageContent,String messageClassType){try{wareSkuService.tryReleaseStock(orderSn);channel.basicAck(message.getMessageProperties().getDeliveryTag(),false);}catch (Exception e){try {channel.basicReject(message.getMessageProperties().getDeliveryTag(),true);} catch (Exception exception) {try {MessageEntity messageLog = new MessageEntity();messageLog.setMessageStatus(2);messageLog.setClassType(messageClassType);messageLog.setRoutingKey(message.getMessageProperties().getReceivedRoutingKey());messageLog.setToExchange(message.getMessageProperties().getReceivedExchange());messageLog.setContent(JSON.toJSONString(messageContent));save(messageLog);channel.basicAck(message.getMessageProperties().getDeliveryTag(),false);} catch (Exception excep) {excep.printStackTrace();}}}}}[解锁库存]
xxxxxxxxxx/*** @param orderSn* @描述 根据库存锁定消息尝试解锁库存* @author Earl* @version 1.0.0* @创建日期 2024/12/02* @since 1.0.0*/public void tryReleaseStock(String orderSn) {//1. 根据订单号远程查询订单服务对应的订单状态,如果订单不存在或者订单状态不是已关闭就不解锁库存R res = orderFeignClient.getOrderByOrderSn(orderSn);OrderTo order = res.get("order", new TypeReference<OrderTo>() {});if(order==null && order.getStatus()==4){return;}//2. 根据订单号查询库存工作单idWareOrderTaskEntity wareOrderTaskEntity = wareOrderTaskService.getOne(new QueryWrapper<WareOrderTaskEntity>().eq("order_sn", orderSn));if(wareOrderTaskEntity==null){return;}List<WareOrderTaskDetailEntity> wareOrderTaskDetails = wareOrderTaskDetailService.list(new QueryWrapper<WareOrderTaskDetailEntity>().eq("task_id", wareOrderTaskEntity.getId()));for (WareOrderTaskDetailEntity wareOrderTaskDetail : wareOrderTaskDetails) {//检索库存工作单状态,只有库存工作单状态为未解锁时才解锁库存,如果不为未解锁本条库存不解锁if(wareOrderTaskDetail.getLockStatus()!=2){baseMapper.releaseStock(wareOrderTaskDetail.getSkuNum(),wareOrderTaskDetail.getSkuId(),wareOrderTaskDetail.getWareId());//解锁后将库存工作单状态更改为已解锁wareOrderTaskDetail.setLockStatus(2);wareOrderTaskDetailService.updateById(wareOrderTaskDetail);}}}❓:我们这里是用库存解锁时间大于取消订单时间来实现解锁库存只要订单的状态为已取消或者订单没有成功创建,就释放已经锁定的库存,但是这种方式存在很严重的问题;比如订单创建成功,但是由于各种原因,消息延迟了很久才发给消息队列,但是库存一锁定成功就将消息发送给消息队列了,导致解锁库存的消息比取消订单的消息先到期,这时候就会导致解锁库存的消息被消费,库存因为订单处于新建状态无法解锁,即使后续订单被解锁了库存也无法被解锁了;即一旦发生意外导致解锁库存的消息比取消订单的消息先到,就会发生被锁定的库存永远无法解锁的情况
🔑:让订单服务取消订单后再发一个消息路由键为
order.release.other给交换器order-event-exchange,我们为交换器order-event-exchange和队列stock.release.stock.queue设定绑定关系,绑定关系设定为order.release.other.#,让取消订单的消息被队列stock.release.stock.queue发送给消费者库存服务。库存服务用@RabbitListener(queues="stock.release.stock.queue")监听同一个队列stock.release.stock.queue,用@RabbitHandler标注的方法监听消息类型为OrderTo,在原来解锁库存的逻辑中判断,当前库存是否解锁过,没解锁过就解锁,解锁过就不用解锁了,老师的逻辑是根据订单号查询库存工作单,根据库存工作单找到所有没有解锁的库存工作单详情调用此前解锁库存的方法进行解锁,感觉这里老师的实现不好,自己实现这部分代码
实际上解锁库存是订单取消的时候解锁一次,锁定库存成功以后一定时间再解锁一次
消息可靠性投递
影响消息可靠性的因素
消息丢失:消息丢失在电商系统中是一个非常可怕的操作,比如订单消息丢失可能会影响到后续一连串比如商家确认、解锁库存、物流等等各种信息,消息可能发生丢失的原因如下:
消息从生产者发送出去,但是由于网络问题抵达RabbitMQ服务器失败,或者因为异常根本没有发送成功
这时候可以用
try...catch语句块来发送消息,发送失败在catch语句块中设置重试策略同时给数据库创建一张消息数据库表
mq_message,建表语句如下xxxxxxxxxxCREATE TABLE `mq_message` (`message_id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '消息id',`content` text COMMENT '消息内容',#序列化为json`to_exchange` varchar(255) DEFAULT NULL COMMENT '投递交换器',`routing_key` varchar(255) DEFAULT NULL COMMENT '路由键',`class_type` varchar(255) DEFAULT NULL COMMENT '消息类型的全限定类名',`message_status` int(1) DEFAULT '0' COMMENT '0-新建 1-已发送 2-错误抵达 3-已抵达',`create_time` datetime DEFAULT NULL COMMENT '消息日志创建时间',`update_time` datetime DEFAULT NULL COMMENT '消息日志更新时间',PRIMARY KEY (`message_id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4只要消息发送失败就给数据库存上这么一条日志,定期扫描数据库来检查消息日志状态来重新发送消息
消息到达Broker,消息只有被投递给队列才算持久化完成,一旦消息还没有到达队列,RabbitMQ服务器宕机消息就会因为还没有来得及持久化而发生丢失
开启生产者消息抵达队列确认,只要消息没有成功抵达队列就会触发生产者的
returnCallback回调,消息不能成功抵达应该设置消息重试发送和向数据库记录消息日志开启生产者消息确认回调,只要消息成功抵达RabbitMQ服务器就触发该回调
自动ACK的状态,消费者收到消息,但是消息没有被成功消费,比如消费消息或者消费消息前出现异常或者服务器宕机,自动应答的消息会直接丢失
开启手动ACK,消息成功消费以后再手动应答接收消息,消息消费失败就手动拒绝消息让消息重新入队列,注意消息没有被应答即没有手动拒绝RabbitMQ没有收到应答的消息也会默认重新入队列再次发送
🔎:防消息丢失的核心就是做好消息生产者和消息消费者两端的消息确认机制,主要策略就是生产者的消息抵达确认回调和消费者的手动应答,凡是消息不能成功抵达服务端和消费端的消息都做好消息日志记录,定期扫描数据库,将发送失败的消息定期重新发送
消息重复:就是因为各种原因导致的消息重新投递
消息消费成功,事务已经提交,但是手动Ack的时候机器宕机或者网络连接中断导致手动Ack没有进行,RabbitMQ的消息因为没有收到应答自动将消息重新入队列并将消息状态从
Unack状态变成ready状态,并再次将消息发送给消费者消息消费过程中消费失败又再次重试发送消息,注意啊,虽然我们让消息消费失败消息拒绝重新入队列
解决办法是业务消息消费接口设计成幂等性接口,比如解锁库存要判断库存工作单详情的状态位,消息消费成功修改对应状态位
使用redis或者mysql防重表,将消息和业务通过唯一标识联系起来,业务被成功处理过的消息就不用再处理了
RabbitMQ的每个消息都有一个
redelivered消息属性字段,每个消息都可以通过Boolean redelivered = message.getMessageProperties().getRedelivered()判断当前消息是否被第二次或者第N次重新投递过来的,这个一般做辅助判断,因为谁也不能保证消息在第几次消费被消费成功
消息积压:消息队列中的消息积压太多,导致消息队列的性能下降
消费者宕机导致消息积压
消费者消费能力不足,比如活动高峰期,比如消费者宕机导致的消费者集群消费能力不足,有服务完全不可用消息反复重入队列消息肯定会积压,应该设置重试次数,投递达到重试次数消息就被专门的服务处理比如存入数据库离线处理
注意消费者没有应答消费消息,队列中的消息处于
Unack状态,生产者会不停报错,让CPU飚高,非常消耗系统性能,这个问题要想办法防一下
发送者发送消息的流量太大,超出消费者的消费能力
限制发送者的流量,让服务限流业务进不来就能限制发送者的流量,不过只是因为消息中间件或者消费者能力有限就限制业务有点得不偿失
上线更多的消费者增强消息的消费能力
上线专门的消息队列消息消费服务,将消息批量从消息队列中取出来,直接写入数据库,缓解消息队列压力,然后再缓慢离线从数据库中获取消息离线处理
消息队列集群
一般都是把消息中间件专门做成一个服务,叫数据中台,负责消息发送和自动记录消息日志,消息发送失败自动进行重试,将消息发送的所有功能都考虑周到,其他服务通过调用该服务来实现消息的发送,看老师的意思,一般消息发送成功也得记录日志,这个可以作为防止消息丢失更进一步的手段,毕竟会影响性能
生产者抵达确认带数据库保存失败消息
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 RabbitMQ客户端自定义配置* @创建日期 2024/11/01* @since 1.0.0*/public class MallRabbitConfig {private RabbitTemplate rabbitTemplate;/*** @return {@link MessageConverter }* @描述 给容器中注入一个使用Jackson将消息对象序列化为json对象的消息转换器* @author Earl* @version 1.0.0* @创建日期 2024/11/01* @since 1.0.0*/public MessageConverter messageConverter(){return new Jackson2JsonMessageConverter();}public void initRabbitTemplate(){/*1. 设置RabbitMQ服务器收到消息后的确认回调ConfirmCallback配置配置项spring.rabbitmq.publisher-confirms=true为rabbitTemplate设置回调实例化对象confirmCallback*/rabbitTemplate.setConfirmCallback(new RabbitTemplate.ConfirmCallback() {/*** @param correlationData 当前消息的唯一关联标识,里面的id就是消息标识的唯一id* @param ack 消息是否成功收到* @param cause 消息发送失败的原因* @描述 1. 只要消息抵达Broker就会触发该回调,与消费者和消息是否入队列无关* @author Earl* @version 1.0.0* @创建日期 2024/11/02* @since 1.0.0*/public void confirm(CorrelationData correlationData, boolean ack, String cause) {log.info("message confirm: {correlationData:"+correlationData+"ack:"+ack+"cause:"+cause+"}");}});/*2.设置RabbitMQ队列没有收到消息的确认回调ReturnCallback配置配置项spring.rabbitmq.publisher-returns=true配置配置项spring.rabbitmq.template.mandatory=true为rabbitTemplate设置回调实例化对象returnCallback* */rabbitTemplate.setReturnCallback(new RabbitTemplate.ReturnCallback() {/*** @param message 投递失败的消息本身的详细信息* @param replyCode 导致消息投递失败的错误状态码* @param replyText 导致消息投递失败的错误原因* @param exchange 当时该消息发往的具体交换器* @param routingKey 当时该消息的具体路由键* @描述* @author Earl* @version 1.0.0* @创建日期 2024/11/03* @since 1.0.0*/public void returnedMessage(Message message, int replyCode, String replyText, String exchange, String routingKey) {log.info("message lose: {message:"+message+"replyCode:"+replyCode+"replyText:"+replyText+"exchange:"+exchange+"routingKey"+routingKey);}});}}消费者手动ACK
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 库存释放队列监听器* @创建日期 2024/12/02* @since 1.0.0*/(queues = "stock.release.stock.queue")public class StockReleaseQueueListenerImpl extends ServiceImpl<MessageDao, MessageEntity> implements StockReleaseQueueListener {private WareSkuService wareSkuService;/*** @param message* @param stockLockedMessage* @param channel* @描述 根据到期的锁定库存消息释放库存* @author Earl* @version 1.0.0* @创建日期 2024/12/02* @since 1.0.0*/public void tryReleaseStock(Message message, StockLockedMessage stockLockedMessage, Channel channel) {String orderSn = stockLockedMessage.getWareOrderTask().getOrderSn();tryReleaseStock(orderSn,message,channel,JSON.toJSONString(stockLockedMessage),stockLockedMessage.getClass().toString());}/*** @param message* @param orderCreatedMessage* @param channel* @描述 取消订单自动解锁库存* @author Earl* @version 1.0.0* @创建日期 2024/12/03* @since 1.0.0*/public void tryReleaseStock(Message message, OrderCreatedMessage orderCreatedMessage,Channel channel){String orderSn = orderCreatedMessage.getOrderSn();tryReleaseStock(orderSn,message,channel,JSON.toJSONString(orderCreatedMessage),orderCreatedMessage.getClass().toString());}/*** @param orderSn* @param message* @param channel* @param messageContent* @param messageClassType* @描述 解锁库存方法* @author Earl* @version 1.0.0* @创建日期 2024/12/03* @since 1.0.0*/private void tryReleaseStock(String orderSn,Message message,Channel channel,String messageContent,String messageClassType){try{wareSkuService.tryReleaseStock(orderSn);channel.basicAck(message.getMessageProperties().getDeliveryTag(),false);}catch (Exception e){try {channel.basicReject(message.getMessageProperties().getDeliveryTag(),true);} catch (Exception exception) {try {MessageEntity messageLog = new MessageEntity();messageLog.setMessageStatus(2);messageLog.setClassType(messageClassType);messageLog.setRoutingKey(message.getMessageProperties().getReceivedRoutingKey());messageLog.setToExchange(message.getMessageProperties().getReceivedExchange());messageLog.setContent(JSON.toJSONString(messageContent));save(messageLog);channel.basicAck(message.getMessageProperties().getDeliveryTag(),false);} catch (Exception excep) {excep.printStackTrace();}}}}}使用MP数据库消息日志记录
同时给数据库创建一张消息数据库表
mq_message,建表语句如下xxxxxxxxxxCREATE TABLE `mq_message` (`message_id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '消息id',`content` text COMMENT '消息内容',#序列化为json`to_exchange` varchar(255) DEFAULT NULL COMMENT '投递交换器',`routing_key` varchar(255) DEFAULT NULL COMMENT '路由键',`class_type` varchar(255) DEFAULT NULL COMMENT '消息类型的全限定类名',`message_status` int(1) DEFAULT '0' COMMENT '0-新建 1-已发送 2-错误抵达 3-已抵达',`create_time` datetime DEFAULT NULL COMMENT '消息日志创建时间',`update_time` datetime DEFAULT NULL COMMENT '消息日志更新时间',PRIMARY KEY (`message_id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4MP插入消息记录
[实体类]
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 库存服务消息实体* @创建日期 2024/12/02* @since 1.0.0*/("sms_message")public class MessageEntity implements Serializable {private static final long serialVersionUID = 1L;/*** 消息id*/private Long messageId;/*** 消息内容*/private String content;/*** 投递交换器*/private String toExchange;/*** 路由键*/private String routingKey;/*** 消息类型的全限定类名*/private String classType;/*** 0-新建 1-已发送 2-错误抵达 3-已抵达*/private Integer messageStatus;/*** 消息日志创建时间*/(fill = FieldFill.INSERT)private Date createTime;/*** 消息日志更新时间*/(fill = FieldFill.INSERT_UPDATE)private Date updateTime;}[持久化接口]
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 库存服务消息* @创建日期 2024/12/02* @since 1.0.0*/public interface MessageDao extends BaseMapper<MessageEntity> {}[持久化接口对应xml]
xxxxxxxxxx<mapper namespace="com.earl.mall.stock.dao.MessageDao"><!-- 可根据自己的需求,是否要使用 --><resultMap type="com.earl.mall.stock.entity.MessageEntity" id="messageMap"><result property="messageId" column="message_id"/><result property="content" column="content"/><result property="toExchange" column="to_exchange"/><result property="routingKey" column="routing_key"/><result property="classType" column="class_type"/><result property="messageStatus" column="message_status"/><result property="createTime" column="create_time"/><result property="updateTime" column="update_time"/></resultMap></mapper>[业务实现类]
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 库存释放队列监听器* @创建日期 2024/12/02* @since 1.0.0*/(queues = "stock.release.stock.queue")public class StockReleaseQueueListenerImpl extends ServiceImpl<MessageDao, MessageEntity> implements StockReleaseQueueListener {private WareSkuService wareSkuService;/*** @param message* @param stockLockedMessage* @param channel* @描述 根据到期的锁定库存消息释放库存* @author Earl* @version 1.0.0* @创建日期 2024/12/02* @since 1.0.0*/public void tryReleaseStock(Message message, StockLockedMessage stockLockedMessage, Channel channel) {String orderSn = stockLockedMessage.getWareOrderTask().getOrderSn();tryReleaseStock(orderSn,message,channel,JSON.toJSONString(stockLockedMessage),stockLockedMessage.getClass().toString());}/*** @param message* @param orderCreatedMessage* @param channel* @描述 取消订单自动解锁库存* @author Earl* @version 1.0.0* @创建日期 2024/12/03* @since 1.0.0*/public void tryReleaseStock(Message message, OrderCreatedMessage orderCreatedMessage,Channel channel){String orderSn = orderCreatedMessage.getOrderSn();tryReleaseStock(orderSn,message,channel,JSON.toJSONString(orderCreatedMessage),orderCreatedMessage.getClass().toString());}/*** @param orderSn* @param message* @param channel* @param messageContent* @param messageClassType* @描述 解锁库存方法* @author Earl* @version 1.0.0* @创建日期 2024/12/03* @since 1.0.0*/private void tryReleaseStock(String orderSn,Message message,Channel channel,String messageContent,String messageClassType){try{wareSkuService.tryReleaseStock(orderSn);channel.basicAck(message.getMessageProperties().getDeliveryTag(),false);}catch (Exception e){try {channel.basicReject(message.getMessageProperties().getDeliveryTag(),true);} catch (Exception exception) {try {MessageEntity messageLog = new MessageEntity();messageLog.setMessageStatus(2);messageLog.setClassType(messageClassType);messageLog.setRoutingKey(message.getMessageProperties().getReceivedRoutingKey());messageLog.setToExchange(message.getMessageProperties().getReceivedExchange());messageLog.setContent(JSON.toJSONString(messageContent));save(messageLog);channel.basicAck(message.getMessageProperties().getDeliveryTag(),false);} catch (Exception excep) {excep.printStackTrace();}}}}}
支付业务
常见支付方式:支付宝支付
支付宝支付
站点目录,找不到的直接右上角搜索,阿里是这样的,文档非常复杂而且经常变动,给开发者带来很大的困扰
生产环境
接入流程
正常的接入流程要按照接入准备的流程接入准备文档]
1️⃣:创建应用[创建一个已经上线的应用]
2️⃣:在应用列表下添加要接入的功能
3️⃣:设置接口加密方式、IP白名单和网关等开发设置
4️⃣:接入功能签约[需要营业执照]
沙箱环境
沙箱环境
沙箱环境是一个支付宝内部的安全环境,模拟了所有的支付宝开放平台的功能,正式接入需要提供营业执照和已经上线的业务进行审核,应用没有上线前可以使用沙箱环境来进行调试,相当于支付宝给每个开发人员创建的一个应用
配置沙箱环境
通过沙箱环境文档链接
https://opendocs.alipay.com/common/02kkv7搜索沙箱控制台点击进入沙箱控制台,里面可以看到当前开发人员沙箱环境对应的配置信息配置参数
APPID:沙箱环境的应用ID支付宝网关地址
gatewayUrl:支付需要调用的支付宝网关接口地址,实际生产项目需要将沙箱网关切换为支付宝的线上网关,支付宝沙箱网关https://openapi-sandbox.dl.alipaydev.com/gateway.do会在alipay后面加一个devmerchant_private_key:商户私钥,也叫应用私钥,现在是直接支付宝开放平台线上生成好的,无需像以前一样下载支付宝开放平台开发助手来生成,老师那时候还是下载该应用手动生成的,以前应用公钥在本地生成以后还要上传到支付宝开放平台,现在也不需要管了alipay_public_key:支付宝公钥,线上支付宝开放平台直接生成好的
沙箱账号:这是一个付款账号,支付宝支付需要使用该沙箱账号进行支付,该沙箱账号有100w余额,就是支付环境的买家测试账号,还可以给沙箱账号充值
买家账号:该沙箱环境只能使用该买家账号登录支付宝进行付款
登录密码:买家支付宝账户的登录密码
支付密码:买家支付宝账户的支付密码
页面跳转地址
return_url:页面跳转同步通知页面路径,支付宝支付成功以后用户要跳转的页面地址,DEMO中的地址为http://localhost:8080/alipay.trade.page.pay-JAVA-UTF-8/return_url.jspnotify_url:服务器异步通知页面路径,支付宝支付成功以后会每隔几秒给服务器该接口地址发送一条支付成功的消息来通知服务器用户支付成功了,服务器接收到消息可以根据支付信息对订单进行后续处理http://localhost:8080/alipay.trade.page.pay-JAVA-UTF-8/notify_url.jsp
设置全局的编码格式为UTF-8,避免因为文件编码格式错误导致支付宝返回页总是报错签名错误等各种错误
内网穿透
我们的服务希望被世界上任何一个人都能访问到,正常的实现方式是为服务分配一个公网IP,给公网IP绑定一个域名
earlmall.com,并给域名备案,只要任何一个人访问earlmall.com,公网上的域名解析器DNS服务器通过域名获取到服务器的公网IP地址;但是这种方式实现起来比较麻烦ping jd.com,我们发现返回数据中有京东的公网IP地址111.12.149.108我们可以访问公网,但是公网是无法直接访问到我们的电脑的,我们和别人聊QQ把消息发送给别人电脑实际上是QQ服务器与别人电脑上的软件建立起的连接,是通过QQ服务器中转的,即还是客户端请求服务端响应那一套,我们无法直接和QQ用户的电脑直接建立连接
我们可以使用内网穿透技术让世界上的任何一个人都访问到我们的当前电脑,
原理
内网穿透服务商会要求在我们的电脑上下载一个服务商软件,该软件可以和服务商服务器建立长连接,内网穿透服务商会为我们电脑上的服务商软件分配一个随机的无需备案的域名[这个域名可能很丑很难看]
临时分配的域名一般是内网穿透服务商的二级或者三级域名,只要内网穿透服务商的顶级域名备了案,子域名无需再备案
别人访问临时域名如
haha.hello.com会先到达内网穿透服务商,服务商根据域名找到分配对应域名的服务软件,通过软件与服务器间建立的长连接通道将请求直接转发到我们的电脑同理其他电脑也可以通过这种方式让我们能正常访问其他的电脑
最终效果就是使用内网穿透服务商分配的域名实现在公网上通过域名访问我们的主机的效果

使用场景
开发测试,比如微信和支付宝的开发调试
智慧互联,我们在外面无法直接通过公网访问到我们的家用电脑和智能设备,但是我们可以通过内网穿透服务商给路由器分配一个域名,我们可以在任何地方通过该域名找到路由器并给路由器发送命令控制内网中的设备,做智慧家庭云系统
私有云,家庭系统中添加一个远程访问的私有存储数据设备
使用流程
下载服务商软件,这里用
natapp演示
电脑网站支付
电脑网站支付SDK
使用SDK前最好在本地搭建运行一下支付宝电脑网站支付SDK提供的DEMO,方便熟悉支付的整个流程
DEMO演示
下载DEMO压缩包
alipay.trade.page.pay-JAVA-UTF-8.zip注意该项目解压以后是一个典型的Eclipse应用,只是一个普通工程,不是Maven工程
在Eclipse左侧菜单栏右键--Import--General/Existing Projects into Workspace--Browse选择刚解压的文件夹--选中要引入的项目--设置Options为Copy projects into workspace--Finish将项目导入Eclipse
该项目运行需要Tomcat服务器,项目导入以后会在
Servers界面提示No servers are available,选择Tomcat来创建一个server服务器,老师选择的是Tomcat 8.5
项目代码
src目录下只有一个配置类AliPayConfig,使用支付宝电脑网站支付需要在AliPayConfig中做很多的配置,只有清除每一个配置的含义才能把项目搭建起来,配置如下xxxxxxxxxxpackage com.alipay.config;import java.io.FileWriter;import java.io.IOException;/* **类名:AlipayConfig*功能:基础配置类*详细:设置帐户有关信息及返回路径*修改日期:2017-04-05*说明:*以下代码只是为了方便商户测试而提供的样例代码,商户可以根据自己网站的需要,按照技术文档编写,并非一定要使用该代码。*该代码仅供学习和研究支付宝接口使用,只是提供一个参考。*/public class AlipayConfig {//↓↓↓↓↓↓↓↓↓↓请在这里配置您的基本信息↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓// 应用ID,您的APPID,收款账号既是您的APPID对应支付宝账号public static String app_id = "";// 商户私钥,您的PKCS8格式RSA2私钥public static String merchant_private_key = "";// 支付宝公钥,查看地址:https://openhome.alipay.com/platform/keyManage.htm 对应APPID下的支付宝公钥。public static String alipay_public_key = "";// 服务器异步通知页面路径 需http://格式的完整路径,不能加?id=123这类自定义参数,必须外网可以正常访问public static String notify_url = "http://工程公网访问地址/alipay.trade.page.pay-JAVA-UTF-8/notify_url.jsp";// 页面跳转同步通知页面路径 需http://格式的完整路径,不能加?id=123这类自定义参数,必须外网可以正常访问public static String return_url = "http://工程公网访问地址/alipay.trade.page.pay-JAVA-UTF-8/return_url.jsp";// 签名方式public static String sign_type = "RSA2";// 字符编码格式public static String charset = "utf-8";// 支付宝网关public static String gatewayUrl = "https://openapi.alipay.com/gateway.do";// 支付宝网关public static String log_path = "C:\\";//↑↑↑↑↑↑↑↑↑↑请在这里配置您的基本信息↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑/*** 写日志,方便测试(看网站需求,也可以改成把记录存入数据库)* @param sWord 要写入日志里的文本内容*/public static void logResult(String sWord) {FileWriter writer = null;try {writer = new FileWriter(log_path + "alipay_log_" + System.currentTimeMillis()+".txt");writer.write(sWord);} catch (Exception e) {e.printStackTrace();} finally {if (writer != null) {try {writer.close();} catch (IOException e) {e.printStackTrace();}}}}}该DEMO的所有代码都在
WebContent目录下,所有的代码包括前端代码都被统一放在JSP页面中了,要做支付直接把对应JSP的代码复制粘贴处理成我们自己的页面即可
核心概念
身份:
app_id:使用支付宝需要创建应用,创建的应用在管理中心的网页和移动应用列表,在应用列表中可以看到每个应用列表的APPID,在每个应用详情的图标下方也会显示应用的APPID,作为当前应用的唯一标识
加密:服务器和支付宝之间会传递金融数据,对网络传输的加密要求比较高,我们在配置文件中配置的就是非对称加密算法的客户端的请求加密密钥和响应解密密钥
🔎:根据非对称加密算法支付宝和一个客户端之间总共有两对即四把密钥,RSA算法一次生成一对密钥,一把公钥、一把私钥;
加密过程:商户保存商户公钥,发起请求时结合请求参数和商户请求标识使用商户公钥加密生成一个签名,该签名只要请求参数发生变化签名就会发生变化[比如一个藏在签名中的本次操作标识拼接请求参数整体做MD5加密用商户公钥做成签名,网络传输过程中不法组织没有商户私钥获取不到签名中的本次操作标识无法伪造签名,也无法使用以往签名替代本次签名,我们就可以通过签名来验证用户参数是否发生过篡改,即使不法组织直接用请求参数密文替换当前的请求参数对应密文签名验证也无法通过],服务器接收数据验证签名后处理业务,业务处理完成使用支付宝私钥结合本次操作标识和响应参数生成签名,该签名可以在网络传输过程被泄露的支付宝公钥解密[如果能被篡改可以根据客户端的逻辑比如操作失败用户可能还会继续选择重试],但是不法组织即使篡改了数据也因为没有私钥无法为篡改后的数据加密,也无法用以往交易的唯一标识结合错误响应结果的签名来替换本次的响应密文,因此请求和响应数据都是安全的,响应数据到达客户端以后使用支付宝公钥来解密响应密文
这里老师的逻辑是有漏洞的,因为签名也是可以替换的,除非服务器和客户端在发起请求以前有公共的唯一标识,这个唯一标识第三方还无法破解才能保证签名对应的密文不会被替换[这里结合JWT的思路可能会更清晰,使用随机数是不行的,因为随机数就算存在签名中无法被获取,但是签名也能整体被替换,只要把以前的请求参数和签名密文整体换掉就验不出来,除非交易前客户端和服务端都保存了标识本次交易的唯一标识并用该标识生成签名]
注意这里有歧义,支付宝的加密是私钥进行加密,公钥进行解密;不是保存在生产者中的是私钥
注意只有支付宝私钥是没有人能看到的,其他的所有3把密钥商户都能看到,反正只要不知道支付宝私钥,整个通信过程就是安全的
merchant_private_key:商户私钥,也叫应用私钥,现在是直接支付宝开放平台线上生成好的,无需像以前一样下载支付宝开放平台开发助手来生成,老师那时候还是下载该应用手动生成的,以前应用公钥在本地生成以后还要上传到支付宝开放平台,现在也不需要管了alipay_public_key:支付宝公钥,线上支付宝开放平台直接生成好的
沙箱账号:这是一个付款账号,支付宝支付需要使用该沙箱账号进行支付,该沙箱账号有100w余额,就是支付环境的买家测试账号,还可以给沙箱账号充值
买家账号:该沙箱环境只能使用该买家账号登录支付宝进行付款
登录密码:买家支付宝账户的登录密码
支付密码:买家支付宝账户的支付密码
页面跳转地址
return_url:页面跳转同步通知页面路径,支付宝支付成功以后用户要跳转的页面地址,DEMO中的地址为http://localhost:8080/alipay.trade.page.pay-JAVA-UTF-8/return_url.jspnotify_url:服务器异步通知页面路径,支付宝支付成功以后会每隔几秒给服务器该接口地址发送一条支付成功的消息来通知服务器用户支付成功了,服务器接收到消息可以根据支付信息对订单进行后续处理http://localhost:8080/alipay.trade.page.pay-JAVA-UTF-8/notify_url.jsp
设置全局的编码格式为UTF-8,避免因为文件编码格式错误导致支付宝返回页总是报错签名错误等各种错误
整合支付宝支付功能
页面跳转
点击支付宝付款发起POST请求跳转地址
alipay.trade.page.pay.jspalipay.trade.page.pay.jspxxxxxxxxxx<html><head><meta http-equiv="Content-Type" content="text/html; charset=utf-8"><title>付款</title></head><% page language="java" contentType="text/html; charset=utf-8" pageEncoding="utf-8"%><% page import="com.alipay.config.*"%><% page import="com.alipay.api.*"%><% page import="com.alipay.api.request.*"%><%//使用配置类AlipayConfig中配置的各种配置构造初始化的AlipayClient对象AlipayClient alipayClient = new DefaultAlipayClient(AlipayConfig.gatewayUrl, AlipayConfig.app_id, AlipayConfig.merchant_private_key, "json", AlipayConfig.charset, AlipayConfig.alipay_public_key, AlipayConfig.sign_type);//构造支付请求并设置页面跳转参数AlipayTradePagePayRequest alipayRequest = new AlipayTradePagePayRequest();alipayRequest.setReturnUrl(AlipayConfig.return_url);alipayRequest.setNotifyUrl(AlipayConfig.notify_url);//从index.jsp的名为alipayment的标签发起的请求中获取订单号、付款金额、订单名称、商品描述,并将这些参数设置到bizContent参数中//商户订单号,商户网站订单系统中唯一订单号,必填String out_trade_no = new String(request.getParameter("WIDout_trade_no").getBytes("ISO-8859-1"),"UTF-8");//付款金额,必填String total_amount = new String(request.getParameter("WIDtotal_amount").getBytes("ISO-8859-1"),"UTF-8");//订单名称,必填String subject = new String(request.getParameter("WIDsubject").getBytes("ISO-8859-1"),"UTF-8");//商品描述,可空String body = new String(request.getParameter("WIDbody").getBytes("ISO-8859-1"),"UTF-8");alipayRequest.setBizContent("{\"out_trade_no\":\""+ out_trade_no +"\","+ "\"total_amount\":\""+ total_amount +"\","+ "\"subject\":\""+ subject +"\","+ "\"body\":\""+ body +"\","+ "\"product_code\":\"FAST_INSTANT_TRADE_PAY\"}");//若想给BizContent增加其他可选请求参数,以增加自定义超时时间参数timeout_express来举例说明//alipayRequest.setBizContent("{\"out_trade_no\":\""+ out_trade_no +"\","// + "\"total_amount\":\""+ total_amount +"\","// + "\"subject\":\""+ subject +"\","// + "\"body\":\""+ body +"\","// + "\"timeout_express\":\"10m\","// + "\"product_code\":\"FAST_INSTANT_TRADE_PAY\"}");//请求参数可查阅【电脑网站支付的API文档-alipay.trade.page.pay-请求参数】章节//使用AlipayClient客户端发起请求获取响应体数据并输出String result = alipayClient.pageExecute(alipayRequest).getBody();//这个输出是直接输出到客户端页面out.println(result);%><body></body></html>
整合流程
1️⃣:引入支付宝支付SDK,即
com.alipay.sdk:alipay-sdk-java,版本与老师保持一致xxxxxxxxxx<!--导入com.alipay.sdk:alipay-sdk-java支付宝的电脑网站支付开发工具包SDK--><!-- https://mvnrepository.com/artifact/com.alipay.sdk/alipay-sdk-java --><dependency><groupId>com.alipay.sdk</groupId><artifactId>alipay-sdk-java</artifactId><version>4.9.28.ALL</version></dependency>2️⃣:将DEMO中的支付请求发起逻辑代码和支付宝支付配置类
AliPayConfig封装成一个工具类AlipayTemplate支付宝的响应内容即
result的内容如下响应的是一个表单,该表单封装了用户支付的所有数据,用户浏览器只要一收到该表单,就会执行脚本
document.forms[0].sumbit()直接提交该表单给支付宝,支付宝会直接响应给用户对应的收银页面因此我们直接将支付宝返回的响应体直接返回给用户,用户客户端就会直接提交表单给支付宝,然后支付宝直接向用户客户端响应收银页面
要特别注意,因为我们响应给用户的数据是支付宝发过来的表单数据,不是一个
json数据,@ResponseBody是将对象转换成json格式数据响应并更改响应头中的数据类型为application/json,因此在使用@ResponseBody响应字符串对象的同时我们还要通过@GetMapping(value="/order/pay",produces="text/html")或者@GetMapping(value ="/order/pay", produces = MediaType.TEXT_HTML_VALUE)来指定响应数据的类型为text/html,这样浏览器就不会将数据作为application/json数据展示,而是直接作为HTML页面开始渲染
xxxxxxxxxx<form name="punchout_form" method="post" action="https://openapi.alipaydev.com/gateway.do?charset=utf-8&method=alipay.trade.page.pay&sign=gvzA31MGat6of4f49TEAEEhpBmhwSkO699g3imrIuM3qogRfGzpNS3T5JyX9JhxF%2B1BDdZ0%2F3mR3K%2FR2QkhoCpATRxaSk9JWbPoZxsZxLvlb%2F9Ld%2BofXN4FmXfD82es%2BkFmlnxQ6BosznJNtV6eh4hdcoSyAt1YtXpGU%2ByOZKWImoZlrD1vuCY6mN9KyehfIy6hq531oUYVixn81%2FlXRnZ6Ffq%2BXaKMWHhOICeWgXRm25c4AJDnHmwmijCYr6%2FG%2F2HyQbY%2FpjLfmD2EQn7CUSIAOOpOYUQQCM1rXtINYZPoPZCdVOqhdGphi0IbLw2VQRZV%2FXxlRYfmJieFbBHrxJg%3D%3D&return_url=http%3A%2F%2Forder.earlmall.com%2Fpaid%2Fnotify¬ify_url=http%3A%2F%2Fuser.earlmall.com%2Fuser%2Forder%2Flist.html&version=1.0&app_id=9021000142643535&sign_type=RSA2×tamp=2024-12-05+23%3A54%3A18&alipay_sdk=alipay-sdk-java-dynamicVersionNo&format=json"><input type="hidden" name="biz_content" value="{"out_trade_no":"202412052346288201864697859702534145","total_amount":"12004.00","subject":"华为 HUAWEI Mate60 Pro 星河银 128G","body":"颜色: 星河银;内存: 128G","product_code":"FAST_INSTANT_TRADE_PAY","time_expire":"2024-12-05 08:16:29"}"><input type="submit" value="立即支付" style="display:none" ></form><script>document.forms[0].submit();</script>
[AlipayTemplate]
xxxxxxxxxxpackage com.earl.mall.order.config;import com.alipay.api.AlipayApiException;import com.alipay.api.AlipayClient;import com.alipay.api.DefaultAlipayClient;import com.alipay.api.internal.util.AlipaySignature;import com.alipay.api.request.AlipayTradePagePayRequest;import com.earl.mall.order.vo.AlipayVo;import lombok.Data;import org.springframework.boot.context.properties.ConfigurationProperties;import org.springframework.stereotype.Component;import javax.servlet.http.HttpServletRequest;import java.util.HashMap;import java.util.Iterator;import java.util.Map;/*** @author Earl* @version 1.0.0* @描述 通过注解`@ConfigurationProperties(prefix = "alipay")`将该组件中的属性都绑定到配置文件前缀alipay上* @创建日期 2024/12/04* @since 1.0.0*/(prefix = "alipay")public class AlipayTemplate {/*** 在支付宝创建的应用的id*/private String app_id = "9021000142643535";/*** 商户私钥,您的PKCS8格式RSA2私钥*/private String merchant_private_key = "XXX";/*** 支付宝公钥,查看地址:https://openhome.alipay.com/platform/keyManage.htm 对应APPID下的支付宝公钥。*/private String alipay_public_key = "XXX";/*** 服务器[异步通知]页面路径 需http://格式的完整路径,不能加?id=123这类自定义参数,必须外网可以正常访问支付宝会悄悄的给我们发送一个请求,告诉我们支付成功的信息*/private String notify_url="http://b4qi64.natappfree.cc/paid/notify";/*** 页面跳转同步通知页面路径 需http://格式的完整路径,不能加?id=123这类自定义参数,必须外网可以正常访问同步通知,支付成功,一般跳转到成功页*/private String return_url="http://user.earlmall.com/user/order/list.html";/*** 签名方式*/private String sign_type = "RSA2";/*** 字符编码格式*/private String charset = "utf-8";/*** 支付宝网关; https://openapi.alipaydev.com/gateway.do*/private String gatewayUrl = "https://openapi-sandbox.dl.alipaydev.com/gateway.do";public String pay(AlipayVo vo) throws AlipayApiException {//AlipayClient alipayClient = new DefaultAlipayClient(AlipayTemplate.gatewayUrl, AlipayTemplate.app_id, AlipayTemplate.merchant_private_key, "json", AlipayTemplate.charset, AlipayTemplate.alipay_public_key, AlipayTemplate.sign_type);//1、根据支付宝的配置生成一个支付客户端AlipayClient alipayClient = new DefaultAlipayClient(gatewayUrl,app_id, merchant_private_key, "json",charset, alipay_public_key, sign_type);//2、创建一个支付请求 //设置请求参数AlipayTradePagePayRequest alipayRequest = new AlipayTradePagePayRequest();alipayRequest.setReturnUrl(return_url);alipayRequest.setNotifyUrl(notify_url);//商户订单号,商户网站订单系统中唯一订单号,必填String out_trade_no = vo.getOut_trade_no();//付款金额,必填String total_amount = vo.getTotal_amount();//订单名称,必填String subject = vo.getSubject();//商品描述,可空String body = vo.getBody();//绝对关单时间String time_expire = vo.getTime_expire();alipayRequest.setBizContent("{\"out_trade_no\":\""+ out_trade_no +"\","+ "\"total_amount\":\""+ total_amount +"\","+ "\"subject\":\""+ subject +"\","+ "\"body\":\""+ body +"\","+ "\"product_code\":\"FAST_INSTANT_TRADE_PAY\","+ "\"time_expire\":\""+ time_expire +"\"}");String result = alipayClient.pageExecute(alipayRequest).getBody();//会收到支付宝的响应,响应的是一个页面,只要浏览器显示这个页面,就会自动来到支付宝的收银台页面//System.out.println("支付宝的响应:"+result);return result;}/*** @param request* @return boolean* @描述 验证支付宝异步回调的支付宝签名* @author Earl* @version 1.0.0* @创建日期 2024/12/06* @since 1.0.0*/public boolean verifySignature(HttpServletRequest request) throws AlipayApiException {//获取支付宝POST过来反馈信息,将支付宝返回的所有请求参数都封装到一个Map集合Map<String,String> params = new HashMap<String,String>();Map<String,String[]> requestParams = request.getParameterMap();for (Iterator<String> iter = requestParams.keySet().iterator(); iter.hasNext();) {String name = (String) iter.next();String[] values = (String[]) requestParams.get(name);String valueStr = "";for (int i = 0; i < values.length; i++) {valueStr = (i == values.length - 1) ? valueStr + values[i]: valueStr + values[i] + ",";}//乱码解决,这段代码在出现乱码时使用,注意这行代码只能在乱码的时候再执行//valueStr = new String(valueStr.getBytes("ISO-8859-1"), "utf-8");params.put(name, valueStr);}//调用alipaySignature.rsaCheckV1()方法来进行验签,这里面使用了AlipayConfig配置文件中的属性,我们是单独封装了一个AlipayTemplate,注意进行替换,验签会返回验证的结果,如果验签成功signVerified为true说明这是支付宝发回来的数据可以执行业务方法,如果验签失败说明signVerified为false说明这个数据有问题,不是支付宝返回的数据不能执行业务方法return AlipaySignature.rsaCheckV1(params, alipay_public_key, charset, sign_type); //调用SDK验证签名}}3️⃣:准备VO类封装支付参数
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 支付宝收银页参数* @创建日期 2024/12/05* @since 1.0.0*/public class AlipayVo {/*** 商户订单号 必填*/private String out_trade_no;/*** 订单名称 必填*/private String subject;/*** 付款金额 必填*/private String total_amount;/*** 商品描述 可空*/private String body;/*** 绝对关单时间*/private String time_expire;}4️⃣:在支付页给支付宝图片设置一个超链接,超链接的跳转地址
th:href="'http://order.earlmall.com/order/pay?orderSn='+${pay.orderSn}"xxxxxxxxxx<a th:href="'order/alipay/'+${session.pay.order.orderSn}"><img src="/static/order/pay/img/zhifubao.png" style="weight:auto;height:30px;" alt="">支付宝</a>5️⃣:处理支付逻辑
支付只需要调用
alipayTemplate.pay(payVo)传参PayVo封装的支付参数即可,需要传参订单号,订单备注、订单主题[订单主题会在用户付款页显示]、订单金额;前端传参只传了订单号,我们希望从数据库中查询出对应的订单以上信息实际上这里还应该校验订单的支付状态,支付过了就不允许支付了,避免用户重复支付
注意支付宝要求支付金额必须精确为两位小数,小数位多了少了都会直接报错,通过
bigDecimal.setScale(2)设置小数位数为2位,取两位小数时我们可以通过bigDecimal.setScale(2,BigDecimal.ROUND_UP)让金额最后一位向上取值,而且注意支付宝要求的支付金额数据类型是String类型,可以通过bigDecimal.toString()将BigDecimal类型数据转换成String类型数据老师的订单主题是直接拿订单项列表的第一个的商品
sku名称作为支付订单的主题,这有点low订单备注老师也是直接拿第一个订单项的销售属性来糊弄的
响应的是一个表单,该表单封装了用户支付的所有数据,用户浏览器只要一收到该表单,就会执行脚本
document.forms[0].sumbit()直接提交该表单给支付宝,支付宝会直接响应给用户对应的收银页面因此我们直接将支付宝返回的响应体直接返回给用户,用户客户端就会直接提交表单给支付宝,然后支付宝直接向用户客户端响应收银页面
要特别注意,因为我们响应给用户的数据是支付宝发过来的表单数据,不是一个
json数据,@ResponseBody是将对象转换成json格式数据响应并更改响应头中的数据类型为application/json,因此在使用@ResponseBody响应字符串对象的同时我们还要通过@GetMapping(value="/order/pay",produces="text/html")或者@GetMapping(value ="/order/pay", produces = MediaType.TEXT_HTML_VALUE)来指定响应数据的类型为text/html,这样浏览器就不会将数据作为application/json数据展示,而是直接作为HTML页面开始渲染我们模拟用户支付的时候必须使用沙箱账户支付
电商网站用户成功支付以后已经跳转用户的支付列表页,也就是上面用户同步通知页
return_url
[控制器方法]
xxxxxxxxxx/*** @param orderSn* @return {@link String }* @描述 验证订单状态并调用支付宝接口响应收银页* @author Earl* @version 1.0.0* @创建日期 2024/12/05* @since 1.0.0*/(value = "/order/alipay/{orderSn}",produces = MediaType.TEXT_HTML_VALUE)public String orderAlipay(("orderSn") String orderSn){String result = orderWebService.orderAlipay(orderSn);return result;}[业务实现类]
xxxxxxxxxx/*** @param orderSn* @return {@link String }* @描述 检查订单状态并调用支付宝接口响应收银页* @author Earl* @version 1.0.0* @创建日期 2024/12/05* @since 1.0.0*/public String orderAlipay(String orderSn) throws RRException{//1. 检查订单状态OrderEntity order = orderService.getOrderByOrderSn(orderSn);//订单状态不是未支付直接抛出异常if(order.getStatus()!=0){throw new RRException(StatusCode.ORDER_PAY_STATUS_EXCEPTION.getMsg()+orderSn+OrderConstant.OrderStatus.getMsgByCode(order.getStatus()),StatusCode.ORDER_PAY_STATUS_EXCEPTION.getCode());}//封装支付参数AlipayVo alipayParams = new AlipayVo();alipayParams.setOut_trade_no(orderSn);alipayParams.setTotal_amount(order.getPayAmount().setScale(2, BigDecimal.ROUND_UP).toString());List<OrderItemEntity> orderItems = orderItemService.list(new QueryWrapper<OrderItemEntity>().eq("order_sn", orderSn));alipayParams.setSubject(orderItems.get(0).getSkuName());alipayParams.setBody(orderItems.get(0).getSkuAttrsVals());//格式化关单绝对时间DateTimeFormatter dtf = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");alipayParams.setTime_expire(order.getTimeExpire().format(dtf));String result = null;//调用支付方法发起支付请求try {result = alipayTemplate.pay(alipayParams);} catch (AlipayApiException e) {e.printStackTrace();}return result;}6️⃣:支付成功跳转
用户支付成功我们希望跳转用户的订单列表页,我们把订单列表页做在会员系统中,设置支付的
return_url=http://user.earlmall.com/user/order/list.html,当用户支付成功以后支付宝会重定向回商户的该界面,并且会在该地址后面拼接用户支付的订单号以及支付的签名,我们可以在响应该重定向页面的同时拿着订单号和支付宝签名验证用户支付状态并修改订单状态,主要是验证支付宝签名,只有支付宝签名正确的情况下才说明订单号是正确的,用户确实完成了支付,但是我们有更好的实现方法[如果靠用户浏览器重定向更改订单状态如果用户支付以后立即关闭浏览器我们就收不到用户浏览器发起的重定向请求,因此这种方式更改订单状态不可靠]
7️⃣:异步通知更改订单状态
用户成功支付以后支付宝会每隔几秒就给我们提供的服务器异步通知路径
notify_url发起POST请求,将支付结果作为参数通知商户,所有的参数和介绍都在https://opendocs.alipay.com/open/270/105902?pathHash=d5cd617e程序执行完毕本次请求必须给支付宝响应字符串
success这七个字符[不能响应页面,只能响应字符串对象],否则支付宝会不断发起该请求,会在25小时内发起8次请求,发送时间间隔分别为4m、10m、10m、1h、2h、6h、15h,这种事务就是跨系统间的分布式事务,支付宝负责最大努力通知我们支付成功,我们用软一致性还保证数据的最终一致性,支付宝采取商户手动应答的策略来确保消息不容易丢失,这是最大努力通知型方案,不是一定保证最终一致性的方案因为支付宝要访问我们的接口,因此我们必须保证自己的接口能在外网访问,因此必须使用内网穿透的网址来让支付宝能在公网上访问到我们的接口地址
notify_url=http://内网穿透域名/order/paid/notify,把内网穿透域名配置成内网主机域名order.earlmall.com,端口设置成80端口,让请求内网穿透到本机的虚拟机上的nginx上,但是内网穿透不是浏览器发起的请求,没有携带请求头,或者就算携带了请求头也是携带的内网穿透服务商分配的域名,
nginx无法从请求头中获取我们指定的Host信息order.earlmall.com,给内网穿透域名商配置的也只是为了让内网穿透域名商找到内网IP和对应服务端口,Nginx无法根据请求的域名来路由用户请求到网关[因为外网请求实际访问的是域名服务商分配的域名],我们可以在Nginx中做一个精确配置[Nginx优先进行精确匹配],让指定URI为/payed/的所有支付宝请求直接转发到商城网关,请求经过nginx不再携带原来的Host地址,选择使用自定义的Host地址proxy_set_header Host order.earlmall.com;经过验证,内网穿透内网穿透服务商只是转发原来的用户请求,原来用户请求的HOSt就是域名服务商分配的二级域名,域名服务商并没有将其改成我们自己的内网域名或者IP
同时
server_name还要配置请求的域名为内网穿透域名,试一下不配置会不会报错
接口必须为POST方式,必须使用
@ResponseBody或者@RestController响应字符串对象拦截器放行对应接口,不检查登录状态
用户同步通知页
就是用户订单列表页面搭建在用户服务中
部署页面[老艺能,不多说,闭着眼睛都能搞]
动静分离
Thymeleaf渲染视图页面跳转
配置本地域名映射,商城网关对域名
user.earlmall.com的跳转把所有订单页面按钮路由到订单列表页
为用户服务配置用户登录拦截器并将拦截器注册到容器组件中
用户状态是使用
SpringSession来协调存储的,要用拦截器必须要引入SpringSession,否则无法从本地session中获取到用户的登录状态还要把Session的相关配置比如
json序列化器、session过期时间等拷贝到用户服务中配置
redis计算运费的时候调用了用户服务,而且那个是做收货地址的地址查询不需要做用户登录检查,在烂机器中排除掉对应的接口地址
编写后端接口远程调用订单服务分页查询用户所有的订单数据
renren-fast生成的分页查询接口太粗糙,需要对该功能进行扩展,查询条件包括用户ID等于当前登录用户的id
用户服务设置Feign请求拦截器,将当前登录用户的cookie设置到远程调用请求的请求头中
查询到的订单数据按照订单自增id降序排列,这样总是能拿到最新的订单数据
只有订单数据不够,还需要订单下的所有订单项数据,订单数据封装在IPage的records属性中,是一个list集合,我们可以取出每个订单数据按照订单号查出每个订单下的所有订单项并重新封装覆盖原来的records属性
分页参数使用
Map<String,Object>进行封装,传参当前页码,没有传参当前页码就默认第一页;用户服务将查询到的数据放到
ModelAndView请求域中注意请求数据要使用
@RequestBody来从请求体中获取必须使用POST请求方式,可以使用@PostMapping,也可以使用@RequestMapping[检验一下@GetMapping能不能用@RequestBody]给数据库表对应实体类添加数据库没有的字段需要使用注解
@TableField(exist=false)表示数据库内没有该字段要获取到分页数据的总记录数和总页数,需要配置
MyBatisPlus的拦截器[就是MyBatisPlus的分页插件],这一块可以完全参考以前的多条件检索分页查询的接口做,包括拦截器也直接参考那个,老师这里没有做多条件查询匹配,其实做的并不好
页面渲染
将订单数据渲染到
table列表组件中第一个
tr标签是订单信息订单号
商城名称写死
第二个
tr标签是订单项信息sku图片sku名称注意这个用法,设置段落宽度,文字内容超过指定宽度自动换行
xxxxxxxxxx<p style="width: 242px;height: auto;overflow: auto">[[${item.skuName}]]</p>商品购买数量
收货人姓名
交易总金额,支付方式
订单状态
遍历显示列表,有些数据比如收货人姓名,交易总额,支付方式、订单状态等只需要显示一次,遍历的时候会导致每行都显示,我们可以通过如下设置来让部分内容跨几个订单项只显示一次
th:each="item,itemStatus:order.items"的itemStatus可以拿到当前标签的数据遍历状态,其中变量index表示当前正在遍历第几个元素,从0开始;count是已经遍历的元素计数,从1开始;size表示元素总共有几个;我们让只需要展示一遍的数据第一遍遍历的时候显示th:if="${itemStatus.index==0}",第一行的数据直接跨所有的列进行展示th:rowspan="${itemStatus.size}",后续遍历对应组件因为index不为0就不会展示了右边框掉了,我们通过设置
td标签的style属性即style="border-right: 1px solid #ccc"来设置右边框边界线
业务实现
相关自定义工具类
[
Query]注意
IPage类是MP下的
xxxxxxxxxx/*** 查询参数** @author Mark sunlightcs@gmail.com*/public class Query<T> {public IPage<T> getPage(Map<String, Object> params) {return this.getPage(params, null, false);}public IPage<T> getPage(Map<String, Object> params, String defaultOrderField, boolean isAsc) {//分页参数long curPage = 1;long limit = 10;if(params.get(Constant.PAGE) != null){curPage = Long.parseLong((String)params.get(Constant.PAGE));}if(params.get(Constant.LIMIT) != null){limit = Long.parseLong((String)params.get(Constant.LIMIT));}//分页对象Page<T> page = new Page<>(curPage, limit);//分页参数params.put(Constant.PAGE, page);//排序字段//防止SQL注入(因为sidx、order是通过拼接SQL实现排序的,会有SQL注入风险)String orderField = SQLFilter.sqlInject((String)params.get(Constant.ORDER_FIELD));String order = (String)params.get(Constant.ORDER);//前端字段排序if(StringUtils.isNotEmpty(orderField) && StringUtils.isNotEmpty(order)){if(Constant.ASC.equalsIgnoreCase(order)) {return page.addOrder(OrderItem.asc(orderField));}else {return page.addOrder(OrderItem.desc(orderField));}}//没有排序字段,则不排序if(StringUtils.isBlank(defaultOrderField)){return page;}//默认排序if(isAsc) {page.addOrder(OrderItem.asc(defaultOrderField));}else {page.addOrder(OrderItem.desc(defaultOrderField));}return page;}}[
PageUtils]xxxxxxxxxx/*** 分页工具类** @author Mark sunlightcs@gmail.com*/public class PageUtils implements Serializable {private static final long serialVersionUID = 1L;/*** 总记录数*/private int totalCount;/*** 每页记录数*/private int pageSize;/*** 总页数*/private int totalPage;/*** 当前页数*/private int currPage;/*** 列表数据*/private List<?> list;/*** 分页* @param list 列表数据* @param totalCount 总记录数* @param pageSize 每页记录数* @param currPage 当前页数*/public PageUtils(List<?> list, int totalCount, int pageSize, int currPage) {this.list = list;this.totalCount = totalCount;this.pageSize = pageSize;this.currPage = currPage;this.totalPage = (int)Math.ceil((double)totalCount/pageSize);}/*** 分页*/public PageUtils(IPage<?> page) {this.list = page.getRecords();this.totalCount = (int)page.getTotal();this.pageSize = (int)page.getSize();this.currPage = (int)page.getCurrent();this.totalPage = (int)page.getPages();}public int getTotalCount() {return totalCount;}public void setTotalCount(int totalCount) {this.totalCount = totalCount;}public int getPageSize() {return pageSize;}public void setPageSize(int pageSize) {this.pageSize = pageSize;}public int getTotalPage() {return totalPage;}public void setTotalPage(int totalPage) {this.totalPage = totalPage;}public int getCurrPage() {return currPage;}public void setCurrPage(int currPage) {this.currPage = currPage;}public List<?> getList() {return list;}public void setList(List<?> list) {this.list = list;}}[控制器方法]
xxxxxxxxxx/*** @return {@link R }* @描述 根据用户id获取用户订单列表* @author Earl* @version 1.0.0* @创建日期 2024/12/06* @since 1.0.0*/("/get/order/list/{userId}")public R getOrderListByUserId(("userId") Long userId,(value = "page",defaultValue = "1") String page,(value = "limit",defaultValue = "10") String limit){HashMap<String, Object> params = new HashMap<>();params.put("page",page);params.put("limit",limit);PageUtils pageUtils=orderService.getOrderListByUserId(userId,params);return R.ok().put("page",pageUtils);}[业务实现类]
xxxxxxxxxx/*** @param userId* @return {@link PageUtils }* @描述 根据用户id分页查询获取订单列表* @author Earl* @version 1.0.0* @创建日期 2024/12/06* @since 1.0.0*/public PageUtils getOrderListByUserId(Long userId,Map<String, Object> params) {QueryWrapper<OrderEntity> wrapper = new QueryWrapper<>();IPage<OrderEntity> page = this.page(new Query<OrderEntity>().getPage(params),wrapper.eq("member_id",userId).orderByDesc("id"));List<OrderEntity> orderEntities = page.getRecords();List<String> orderSns = orderEntities.stream().map(OrderEntity::getOrderSn).collect(Collectors.toList());List<OrderItemEntity> orderItems = orderItemService.list(new QueryWrapper<OrderItemEntity>().in("order_sn", orderSns));List<OrderItemVo> orderItemVos = orderItems.stream().map(orderItemEntity -> {OrderItemVo orderItem = new OrderItemVo();BeanUtils.copyProperties(orderItemEntity, orderItem);return orderItem;}).collect(Collectors.toList());HashMap<String, List<OrderItemVo>> orderItemsOfOrderSns = new HashMap<>();for (OrderItemVo orderItem : orderItemVos) {if(orderItemsOfOrderSns.get(orderItem.getOrderSn())==null){ArrayList<OrderItemVo> orderItemsOfOrderSn = new ArrayList<>();orderItemsOfOrderSns.put(orderItem.getOrderSn(),orderItemsOfOrderSn);}orderItemsOfOrderSns.get(orderItem.getOrderSn()).add(orderItem);}SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");List<OrderVo> orders = orderEntities.stream().map(orderEntity -> {OrderVo order = new OrderVo();BeanUtils.copyProperties(orderEntity, order);order.setOrderCreateTime(sdf.format(orderEntity.getCreateTime()));return order;}).collect(Collectors.toList());orders.sort((o1, o2) -> Long.compare(o2.getId(),o1.getId()));for (OrderVo order : orders) {order.setOrderItems(orderItemsOfOrderSns.get(order.getOrderSn()));}Page<OrderVo> orderPage = new Page<>(page.getCurrent(), page.getSize(), page.getTotal());orderPage.setRecords(orders);return new PageUtils(orderPage);}[数据渲染]
xxxxxxxxxx<table class="table" th:each="order:${page.list}"><tr><td colspan="7" style="background:#F7F7F7" ><span style="color:#AAAAAA" th:text="${order.orderCreateTime}">2017-12-09 20:50:10</span><span><ruby style="color:#AAAAAA">订单号:</ruby> <span th:text="${order.orderSn}">70207298274</span></span><span>Earl商城官方旗舰店<i class="table_i"></i></span><i class="table_i5 isShow"></i></td></tr><tr class="tr" th:each="orderItem,itemStatus:${order.orderItems}"><td colspan="3"><img style="width: 60px;height: 60px;" th:src="${orderItem.skuPic}" alt="" class="img"><div><p style="width: 242px;height: auto;overflow: auto;" th:text="${orderItem.skuName}">MUXIWEIERPU皮手套男冬季加绒保暖户外骑车开车触摸屏全指防寒全指手套 黑色 均码</p><div><i class="table_i4"></i>找搭配</div></div><div style="margin-left:15px;" th:text="'x'+${orderItem.skuQuantity}">x1</div><div style="clear:both"></div></td><td th:text="${order.receiverName}" th:if="${itemStatus.index==0}" th:rowspan="${itemStatus.size}">张三<i><i class="table_i1"></i></i></td><td style="padding-left:10px;color:#AAAAB1;" th:if="${itemStatus.index==0}" th:rowspan="${itemStatus.size}"><p style="margin-bottom:5px;" th:text="'总额 ¥'+${order.payAmount}">总额 ¥26.00</p><hr style="width:90%;"><p>在线支付</p></td><td th:if="${itemStatus.index==0}" th:rowspan="${itemStatus.size}"><ul><li style="color:#71B247;" th:if="${order.status==0}">待付款</li><li style="color:#71B247;" th:if="${order.status==1}">待发货</li><li style="color:#71B247;" th:if="${order.status==2}">已发货</li><li style="color:#71B247;" th:if="${order.status==3}">已完成</li><li style="color:#71B247;" th:if="${order.status==4}">已关闭</li><li style="color:#71B247;" th:if="${order.status==5}">无效订单</li><li class="tdLi">订单详情</li></ul></td><td><button>确认收货</button><p style="margin:4px 0; ">取消订单</p><p>催单</p></td></tr></table>[分页组件]
xxxxxxxxxx<div class="order_btm"><div><button class="page_a" th:attr="pn=${page.currPage - 1}"th:if="${page.currPage > 1}">上一页</button><span class="page_a" th:attr="pn=${i},style=${i == page.currPage?'color: red;':'color: black;'}"th:each="i:${#numbers.sequence(1,page.totalPage)}"th:if="${page.totalPage > 0}"th:text="${i}">1</span><button class="page_a" th:attr="pn=${page.currPage + 1}"th:if="${page.currPage < page.totalPage}">下一页</button></div></div><script>$(".page_a").click(function (){var pn=$(this).attr("pn");location.href = replaceOrAddParamVal(location.href,"page",pn);return false;});//替换指定请求路径中的请求参数,如果参数已经存在就直接替换,如果参数不存在就追加参数function replaceOrAddParamVal(url,paramName,replaceVal,forceAdd=false){var oUrl = url.toString();//旧请求路径中有了就进行替换,没有对应参数就添加参数if (oUrl.indexOf(paramName+'=') != -1){if(forceAdd){return addURIParam(oUrl,paramName,replaceVal);}else{var re = eval('/('+paramName+'=)([^&]*)/gi');var nUrl = oUrl.replace(re,paramName+'='+replaceVal);return nUrl;}}else{return addURIParam(oUrl,paramName,replaceVal);}}//新增参数function addURIParam(oUrl,paramName,replaceVal){//添加参数var nUrl="";//检查旧链接中有没有问号,有问号就追加参数,没有就新增问号并添加参数if(oUrl.indexOf("?")!=-1){nUrl = oUrl+"&"+paramName+"="+replaceVal;}else{nUrl = oUrl+"?"+paramName+"="+replaceVal;}return nUrl;}</script>
服务器异步通知
一般用户同步通知还没有到服务器的异步通知就到了
异步通知的参数
用户成功支付以后支付宝会每隔几秒就给我们提供的服务器异步通知路径
notify_url发起POST请求,将支付结果作为参数通知商户,所有的参数和介绍都在https://opendocs.alipay.com/open/270/105902?pathHash=d5cd617etrade_status:交易状态,交易状态包括TRADE_SUCCESS[交易支付成功]、TRADE_CLOSED[未付款交易关闭或支付后全额退款]、TRADE_FINISHED[交易结束,不可退款]、WAIT_BUYER_PAY[交易创建,等待买家付款]out_trade_no:订单号trade_no:支付宝交易号,相当于支付宝为此次交易设置的订单号
使用Vo类封装支付宝的服务端响应参数
注意请求参数会被自动封装到对应的VO类中,除此以外我们还可以通过
httpServletRequest.getParameterMap()来从请求中直接获取参数集合注意支付宝返回的
notify_time数据类型为String类型,直接将该数据类型转成Date类型会报错,我们需要在配置文件中配置spring.mvc.date-format=yyyy-MM-dd HH:mm:ss日期类型才能将指定格式的时间字符串格式化为Date类型;此外我们还可以在对应属性上使用注解@DateTimeFormat(pattern = "yyyy-MM-dd HH:mm:ss"),SpringBoot2.4以上版本叫spring.mvc.format.date
xxxxxxxxxxpackage com.atguigu.gulimall.order.vo.pay;import lombok.Data;import lombok.ToString;import java.util.time.Date;public class PayAsyncVo {private String gmt_create;private String charset;private String gmt_payment;private Date notify_time;private String subject;private String sign;private String buyer_id;//支付者的idprivate String body;//订单的信息private String invoice_amount;//支付金额private String version;private String notify_id;//通知idprivate String fund_bill_list;private String notify_type;//通知类型; trade_status_syncprivate String out_trade_no;//订单号private String total_amount;//支付的总额private String trade_status;//交易状态 TRADE_SUCCESSprivate String trade_no;//流水号private String auth_app_id;//private String receipt_amount;//商家收到的款private String point_amount;//private String app_id;//应用idprivate String buyer_pay_amount;//最终支付的金额private String sign_type;//签名类型private String seller_id;//商家的id}处理支付宝的支付返回结果
1️⃣:在数据库表
oms_payment_info记录了订单支付流水,字段包括order_sn[订单号]、alipay_trade_no[支付宝交易号]、total_amount[支付金额]、subject[订单主题]、payment_status[支付状态],callbackTime[异步通知回调时间]记录流水的作用是每隔一个月就可以和支付宝的支付流水进行一个对照,第一步就是根据支付宝的返回结果直接保存一份支付流水这里限制了一个订单只有一个流水,限制了
id为主键、order_sn订单号为唯一键索引、alipay_trade_no支付宝交易号为唯一键索引把数据库表订单号的长度更改为64
2️⃣:验证支付宝签名,作用是确保该请求是支付宝给我们发送的数据,验签流程可以参考支付宝的DEMO中的
notify_url.jsp[
notify_url.jsp]xxxxxxxxxx<% page language="java" contentType="text/html; charset=utf-8"pageEncoding="utf-8"%><% page import="java.util.*"%><% page import="java.util.Map"%><% page import="com.alipay.config.*"%><% page import="com.alipay.api.*"%><% page import="com.alipay.api.internal.util.*"%><%/* ** 功能:支付宝服务器异步通知页面* 日期:2017-03-30* 说明:* 以下代码只是为了方便商户测试而提供的样例代码,商户可以根据自己网站的需要,按照技术文档编写,并非一定要使用该代码。* 该代码仅供学习和研究支付宝接口使用,只是提供一个参考。*************************页面功能说明************************** 创建该页面文件时,请留心该页面文件中无任何HTML代码及空格。* 该页面不能在本机电脑测试,请到服务器上做测试。请确保外部可以访问该页面。* 如果没有收到该页面返回的 success* 建议该页面只做支付成功的业务逻辑处理,退款的处理请以调用退款查询接口的结果为准。*///获取支付宝POST过来反馈信息,将支付宝返回的所有请求参数都封装到一个Map集合Map<String,String> params = new HashMap<String,String>();Map<String,String[]> requestParams = request.getParameterMap();for (Iterator<String> iter = requestParams.keySet().iterator(); iter.hasNext();) {String name = (String) iter.next();String[] values = (String[]) requestParams.get(name);String valueStr = "";for (int i = 0; i < values.length; i++) {valueStr = (i == values.length - 1) ? valueStr + values[i]: valueStr + values[i] + ",";}//乱码解决,这段代码在出现乱码时使用//注意这行代码只能在乱码的时候再执行//valueStr = new String(valueStr.getBytes("ISO-8859-1"), "utf-8");params.put(name, valueStr);}//调用alipaySignature.rsaCheckV1()方法来进行验签,这里面使用了AlipayConfig配置文件中的属性,我们是单独封装了一个AlipayTemplate,注意进行替换,验签会返回验证的结果,如果验签成功signVerified为true说明这是支付宝发回来的数据可以执行业务方法,如果验签失败说明signVerified为false说明这个数据有问题,不是支付宝返回的数据不能执行业务方法boolean signVerified = AlipaySignature.rsaCheckV1(params, AlipayConfig.alipay_public_key, AlipayConfig.charset, AlipayConfig.sign_type); //调用SDK验证签名//——请在这里编写您的程序(以下代码仅作参考)——/* 实际验证过程建议商户务必添加以下校验:1、需要验证该通知数据中的out_trade_no是否为商户系统中创建的订单号,2、判断total_amount是否确实为该订单的实际金额(即商户订单创建时的金额),3、校验通知中的seller_id(或者seller_email) 是否为out_trade_no这笔单据的对应的操作方(有的时候,一个商户可能有多个seller_id/seller_email)4、验证app_id是否为该商户本身。*/if(signVerified) {//验证成功//商户订单号String out_trade_no = new String(request.getParameter("out_trade_no").getBytes("ISO-8859-1"),"UTF-8");//支付宝交易号String trade_no = new String(request.getParameter("trade_no").getBytes("ISO-8859-1"),"UTF-8");//交易状态String trade_status = new String(request.getParameter("trade_status").getBytes("ISO-8859-1"),"UTF-8");if(trade_status.equals("TRADE_FINISHED")){//判断该笔订单是否在商户网站中已经做过处理//如果没有做过处理,根据订单号(out_trade_no)在商户网站的订单系统中查到该笔订单的详细,并执行商户的业务程序//如果有做过处理,不执行商户的业务程序//注意://退款日期超过可退款期限后(如三个月可退款),支付宝系统发送该交易状态通知}else if (trade_status.equals("TRADE_SUCCESS")){//判断该笔订单是否在商户网站中已经做过处理//如果没有做过处理,根据订单号(out_trade_no)在商户网站的订单系统中查到该笔订单的详细,并执行商户的业务程序//如果有做过处理,不执行商户的业务程序//注意://付款完成后,支付宝系统发送该交易状态通知}out.println("success");}else {//验证失败out.println("fail");//调试用,写文本函数记录程序运行情况是否正常//String sWord = AlipaySignature.getSignCheckContentV1(params);//AlipayConfig.logResult(sWord);}//——请在这里编写您的程序(以上代码仅作参考)——%>[业务方法]
这里只要验签成功就更改订单状态
xxxxxxxxxx//获取支付宝POST过来反馈信息,将支付宝返回的所有请求参数都封装到一个Map集合Map<String,String> params = new HashMap<String,String>();Map<String,String[]> requestParams = request.getParameterMap();for (Iterator<String> iter = requestParams.keySet().iterator(); iter.hasNext();) {String name = (String) iter.next();String[] values = (String[]) requestParams.get(name);String valueStr = "";for (int i = 0; i < values.length; i++) {valueStr = (i == values.length - 1) ? valueStr + values[i]: valueStr + values[i] + ",";}//乱码解决,这段代码在出现乱码时使用valueStr = new String(valueStr.getBytes("ISO-8859-1"), "utf-8");params.put(name, valueStr);}//调用alipaySignature.rsaCheckV1()方法来进行验签,这里面使用了AlipayConfig配置文件中的属性,我们是单独封装了一个AlipayTemplate,注意进行替换,验签会返回验证的结果,如果验签成功signVerified为true说明这是支付宝发回来的数据可以执行业务方法,如果验签失败说明signVerified为false说明这个数据有问题,不是支付宝返回的数据不能执行业务方法boolean signVerified = AlipaySignature.rsaCheckV1(params, AlipayConfig.alipay_public_key, AlipayConfig.charset, AlipayConfig.sign_type); //调用SDK验证签名3️⃣:修改订单状态,支付状态
payment_status中的状态TRADE_SUCCESS的通知触发条件是商户签约的产品支持退款功能且买家付款成功,状态TRADE_FINISHED的通知触发条件是商户签约产品不支持退款功能且买家付款成功,只要支付状态是这两种状态,我们就将用户的订单状态修改为已支付代码实现
[控制器方法]
xxxxxxxxxx/*** @return {@link String }* @描述 支付宝支付回调* @author Earl* @version 1.0.0* @创建日期 2024/12/05* @since 1.0.0*/("/paid/notify")public String paidNotify( AlipayAsyncVo alipayAsync, HttpServletRequest request){System.out.println("notify");try {orderWebService.paidNotify(alipayAsync,request);return "success";} catch (AlipayApiException e) {e.printStackTrace();}return "failed";}[业务方法]
xxxxxxxxxx/*** @param alipayAsync* @描述 支付宝异步回调通知业务方法* @author Earl* @version 1.0.0* @创建日期 2024/12/06* @since 1.0.0*/public void paidNotify(AlipayAsyncVo alipayAsync, HttpServletRequest request) throws AlipayApiException {//1. 验证支付宝异步回调签名,验签不通过直接抛异常if(!alipayTemplate.verifySignature(request)){throw new RRException(StatusCode.ALIPAY_NOTIFY_SIGNATURE_VERIFY_EXCEPTION.getMsg(),StatusCode.ALIPAY_NOTIFY_SIGNATURE_VERIFY_EXCEPTION.getCode());}//2. 记录支付流水PaymentInfoEntity paymentInfoEntity = new PaymentInfoEntity();paymentInfoEntity.setOrderSn(alipayAsync.getOut_trade_no());paymentInfoEntity.setAlipayTradeNo(alipayAsync.getTrade_no());paymentInfoEntity.setTotalAmount(new BigDecimal(alipayAsync.getTotal_amount()));paymentInfoEntity.setSubject(alipayAsync.getSubject());paymentInfoEntity.setPaymentStatus(alipayAsync.getTrade_status());paymentInfoEntity.setCallbackTime(alipayAsync.getNotify_time());paymentInfoService.save(paymentInfoEntity);//3. 更改订单状态if(alipayAsync.getTrade_status().equals(OrderConstant.AlipayTradeStatus.TRADE_SUCCESS.getMsg())||alipayAsync.getTrade_status().equals(OrderConstant.AlipayTradeStatus.TRADE_FINISHED.getMsg())){orderService.updateOrderStatus(alipayAsync.getOut_trade_no());}}
收单
我们自己的系统超时未支付就会自动关闭订单并且释放库存,但是我们无法控制用户的支付行为,也无法控制支付宝的收款行为,就可能发生商户订单已经关闭,库存已经解锁;但是此时用户直接打开支付宝的收银页面并且支付了,此时支付宝仍然能异步回调我们的接口并验签成功更改订单状态,但是此时我们已经关闭了订单,库存也释放掉了,万一库存没有了,此时订单支付成功就会导致纠纷
支付宝提供了收单功能,一旦超出我们设定的时间用户没有支付,支付宝就会将对用户的收银功能关闭掉
在支付宝的API列表中可以看到支付宝的可调用接口,点进统一收单下单并支付页面接口可以查看接口的详细信息,包括可以携带的参数和参数说明
在该参数表中可以传参一个
time_expire,参数说明为绝对超时时间,格式为yyyy-MM-dd HH:mm:ss,只要到了指定的绝对时间以后订单都无法再支付该参数列表还可以传参一个
timeout_express,参数说明为相对超时时间,可取值返回是1分钟到15天,单位有m分钟、h小时、d天、1c当天[1C的含义是无论交易在当天何时创建都会在0点关闭],注意该参数值不接收小数,我们使用该参数设置关单时间为1m,与订单关闭时间相同,感觉这种实现不好,还是创建订单就指定绝对支付时间比较靠谱
有可能订单最后一刻支付,订单在服务器异步通知的过程中商户订单关闭库存解锁后,异步通知才到;为了避免这个问题,支付宝提供了手动收单功能,用户只要在关闭订单的同时向支付宝发起收单请求,支付宝就会支付失败,怪不得用户同步通知页面比服务器通知页面慢很多,只要服务器通知没到,用户同步通知就到不了,收单的代码示例在DEMO中的
alipay.trade.close.jsp中[
alipay.trade.close.jsp]xxxxxxxxxx<html><head><meta http-equiv="Content-Type" content="text/html; charset=utf-8"><title>交易关闭</title></head><% page language="java" contentType="text/html; charset=utf-8" pageEncoding="utf-8"%><% page import="com.alipay.config.*"%><% page import="com.alipay.api.*"%><% page import="com.alipay.api.request.*"%><%//获得初始化的AlipayClientAlipayClient alipayClient = new DefaultAlipayClient(AlipayConfig.gatewayUrl, AlipayConfig.app_id, AlipayConfig.merchant_private_key, "json", AlipayConfig.charset, AlipayConfig.alipay_public_key, AlipayConfig.sign_type);//设置请求参数AlipayTradeCloseRequest alipayRequest = new AlipayTradeCloseRequest();//商户订单号,商户网站订单系统中唯一订单号String out_trade_no = new String(request.getParameter("WIDTCout_trade_no").getBytes("ISO-8859-1"),"UTF-8");//支付宝交易号String trade_no = new String(request.getParameter("WIDTCtrade_no").getBytes("ISO-8859-1"),"UTF-8");//请二选一设置alipayRequest.setBizContent("{\"out_trade_no\":\""+ out_trade_no +"\"," +"\"trade_no\":\""+ trade_no +"\"}");//执行收单请求String result = alipayClient.execute(alipayRequest).getBody();//输出out.println(result);%><body></body></html>[设置
AlipayTemplate收单方法]老师没做手动收单功能,用的只是自动收单,不是线上要测试出这个效果都难
每天晚上闲时调用支付宝的交易查询接口,该接口DEMO中也有,也可以查看支付宝提供的API列表查看,下载支付宝对账单,对当天支付订单一一对账
加密算法
常见的加密算法:对称加密、非对称加密、
对称加密
原理示意图

原理:客户端使用密钥A对明文加密生成密文,服务端使用同一把密钥A对密文解密生成明文
核心:加密和解密使用的是同一把密钥
方案:
DES、3DES[TripleDES]、AES、RC2、RC4、RC5、BlowFish缺陷:一旦密钥被截取或者破解,网络传输中就能随意获取篡改用户请求明文来更改服务端数据,既然知道加密规则就一定能通过密文获取到明文,即便加密解密过程不同也可以通过彩虹表暴力匹配
应用场景
这种加密方式非常不安全,在金融领域根本不能使用
非对称加密
原理示意图

原理:客户端使用密钥A对明文进行加密生成密文,密文只有在服务器中使用密钥B才能解密出明文,使用密钥A无法再解密出明文;服务端的响应数据使用密钥C加密生成密文,客户端使用密钥D解密生成明文,只有使用密钥C加密的密文才能使用密钥D解密,使用密钥D加密的密文无法被密钥D解密,这样即使第三方截取响应内容篡改以后加密的密文无法被客户端正常解密;密钥B和密钥C都只存在服务器内,不存在丢失的风险
非对称加密算法中,公钥私钥是相对于密钥的生成者来说的,存放在生产者手里只提供给生产者使用的就是私钥,发布出去给各个客户端使用的就是公钥[这里有歧义,复习Nginx的时候确认一下,我查了一下网上是发布出去给客户端使用的就是公钥,但是支付宝的加密模型中是加密的是私钥,解密的是公钥]
注意请求到响应两个过程一共是两对密钥四把钥匙,RSA算法一次生成的密钥就是一对
核心:请求和响应使用不同的两对密钥,加密密钥加密的密文只能被解密密钥解密,解密密钥只能解密加密密钥加密的密文
方案:
RSA[SHA1金融领域非常常用的非对称加密算法]、Elgamal、RSA2[SHA256]缺陷:
非对称加密算法仍然存在缺陷,一些不法组织可能给用户弄一个自己的客户端模拟实际的客户端,用户将服务器需要的数据直接明文传递给不法组织的服务器,不法组织的服务器拿着用户的数据篡改以后来代替用户向实际的服务器发起请求,收到响应以后解密篡改响应数据并响应给用户
不法组织可以直接获取到密文,可以在用户发起请求的同时用已知的参数对应密文替换掉当前请求的参数密文[比如在用户的支付金额后面加两个0来让用户多转一点钱]
这种替换参数密文的问题可以通过商户公钥结合请求参数和时间戳等参数通过摘要算法生成一个加密的签名,通过该签名可以验证用户的请求参数是否在网络传输过程中被篡改过[这里要考虑不法组织能否获取到商户的公钥,但是老师显然是不考虑这个问题的],老师的意思就是直接传递参数密文可以直接通过密文来替换参数,我们通过商户特有参数和请求参数通过商户公钥加密,在服务端收到密文解密以后获取到请求参数后还能检验请求参数是否被篡改过,比如使用MD5算法来检查请求参数是否被篡改过
秒杀业务
一般首页会展示商家不定期上架的秒杀打折商品,秒杀购买流程和普通购买流程的区别是秒杀购买流程瞬时流量非常大,普通购买流程的流量随时间分布比较均匀,秒杀一般是活动从某个时间点开始,时间一到大量的流量会立刻涌入,而且都是流向一个接口,非常考验系统对峰值流量的应对能力,针对这个特点必须引入限流+异步+缓存[资源静态化]+独立部署[独立部署的意思是给秒杀系统创建一个独立的微服务,主要是为了避免秒杀系统把服务资源拉满,服务的其他接口无法正常处理业务了]
将秒杀服务单独抽取一个服务,秒杀服务最大的特点就是瞬时的高并发流量,对于这种业务必须要单独设置一个微服务独立部署,不和其他服务混写,这样即使瞬时高并发流量进来,系统承担不住也只是当前微服务或者集群压不住,不会影响到其他服务的正常运行
后台系统
业务逻辑
秒杀业务参考京东,首页点击秒杀可以进入秒杀页面,秒杀页面有每天的秒杀场次,每隔两小时一个秒杀场次,还没有开始的场次可以预览商品,商品正常购买的价格和秒杀价格不一样
我们可以使用后台管理系统的每日秒杀中新增每天的秒杀场次,指定场次名称,每日的开始时间和结束时间,以及启用状态,秒杀场次对应数据库表
sms_seckill_session;在每日秒杀的每个项目的关联商品中可以新增每个秒杀场次中的秒杀商品信息,对应数据库表
sms_seckill_sku_relation,字段promotion_session_id对应秒杀场次的id,sku_id对应商品的id,seckill_price对应商品的秒杀价格,seckill_count是商品参与秒杀的库存数量,seckill_limit是每个用户购买数量限制,seckill_sort是秒杀商品的排序点击每日秒杀场次的关联商品,会发起请求
http://localhost:88/api/coupon/seckillskurelation/list?t=1733675172328&page=1&limit=10&key=&promotionSessionId=1,除了传递时间戳、分页参数还额外传参一个promotionSessionId指定当前的每日秒杀场次的id对应的后端接口也需要改写成如果不带
promotionSessionId就查所有记录,如果带了promotionSessionId就查promotion_session_id等于对应参数值的记录关联商品点击新增,活动场次id会自动填充当前商品所在秒杀场次的id,需要设置商品的
skuId,设置秒杀商品的库存量,设置每个用户的限购数量,设置商品的排序序号,后台接口的前端页面是自己实现的,后端增删改查接口是renren-generator直接生成的
业务实现
秒杀系统的前端代码直接用的老师提供的,接口直接使用
renren-generator自动生成的增删改查接口对分页查询接口进行修改,把接口改成如果不带
promotionSessionId就查所有记录,如果带了promotionSessionId就查promotion_session_id等于对应参数值的记录
后端设计
单独设置一个微服务,添加
dev-tools、Lombok、Spring Web、spring-data-redis、openFeign;引入我们自定义的Common包并排除seata依赖配置应用名称、服务端口、
nacos相关配置、redis相关配置、在启动类上标注@EnableFeignClient开启OpenFeign远程调用功能,在@SpringBootApplication中排除掉数据源的相关配置
秒杀商品上架
业务逻辑
秒杀商品因为瞬时流量大,不能每次请求都去查询数据库,这样太慢了,而且存在压垮数据库的风险,要提前把每个秒杀场次的商品放入缓存中,秒杀商品的库存更新操作也不能放在数据库中,也只在缓存中直接进行更新操作
业务流程图
我们每天晚上12点设置定时任务将第二天参与秒杀的商品全部缓存到
redis中检索未来三天将要参与秒杀活动的所有商品
将所有商品信息保存到
redis中

业务实现
配置定时调度任务配置
在配置类
SecheduledConfig上标注注解@EnableAsync和注解@EnableScheduling,注意这两个注解只要在任意配置类上标注了即可
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 商城定时任务配置* @创建日期 2024/12/11* @since 1.0.0*/public class MallScheduleConfig {}秒杀服务凌晨会比较空闲,我们可以在每天晚上三点上架最近三天需要进行秒杀的商品,上架最近三天的原因是一件商品我们可以在正常出售的时候,如果该商品最近三天有秒杀活动可以在普通商品详情页面进行预告
因为每天都要上架后三天的商品,必然存在被重复上架的商品,如果遇到重复上架的商品则无需任何处理,注意秒杀活动还未开始前秒杀商品还能继续添加到系统中,并在每天凌晨三点自动上架,使用
SpringBoot自带的@Scheduled(cron="0 0 3 * * ?")注解来设置定时任务远程调用优惠系统去数据库扫描最近三天的秒杀活动,查询结果为表
sms_seckill_session中的记录的List集合,查询SQL为SELECT * FROM sms_seckill_session WHERE start_time>='2020-02-19 00:00:00' AND end_time<='2020-02-19 02:00:00'或者SELECT * FROM sms_seckill_session WHERE start_time BETWEEN '2020-02-19 00:00:00' AND '2020-02-21 23:59:59',对应MP的queryWrapper.between("start_time",countStartTime,countEndTime)方法来构建检索条件时间参数要进行处理,使用
LocalDate.now()获取当天日期,使用localDate.plus(Duration.ofDays(1))来给当前时间加一天,注意localDate.plusDays(2)方法的效果也是一样的,注意LocalDate的toString()默认就是2020-02-21这种日期格式,通过这种方式我们可以得到最近三天的日期,我们分别得到当天日期拼接每天时间的最小值作为最小时刻,得到两天后的日期拼接每天时间的最大值作为最大时刻得到日期还要拼接时间,时间分别为
00:00:00和23:59:59,我们可以通过常量LocalTime.MIN和LocalTime.MAX来获取该一天中的最小时间和最大时间,注意该常量的默认值分别为LocalTime类型的00:00和23:59:59.999999999使用
LocalDateTime.of(LocalDate date,LocalTime time)将日期和时间组合在一起返回LocalDateTime时间,LocalDateTime的默认格式为2020-02-21T00:00,使用localDateTime.format(DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"))将日期格式化为指定格式🔎:弹幕说
Hutool工具包里面有工具类可以处理这种情况
根据秒杀活动
id查询参与该场秒杀活动的所有商品并封装成List集合,将商品数据封装到秒杀场次中,返回所有秒杀场次的List集合从优惠服务查询到所有的秒杀商品后准备执行上架业务,上架就是将商品保存到
redis中,redis中要缓存两部分内容,第一个个是最近三天的所有秒杀活动,秒杀活动的key是seckill:sessions:开始时间_结束时间,val值是当前活动关联的所有商品;第二个是缓存活动的关联商品的详细信息,从秒杀场次信息中取出
LocalDateTime类型的开始时间和秒杀活动结束时间,通过localDateTime.getTime()将时间装换为Long类型的毫秒时间,收集单个秒杀场次的skuId集合,用活动开始结束时间拼接出第一个缓存数据,注意StringRedisTemplate两个参数必须都为String类型,像Long类型的skuIds也得转成String类型列表,使用一个list数据类型保存所有的秒杀活动数据,使用redisTemplate.opsForList().leftPushAll(key,collect)将每个元素存入list数据类型中[这里检查一下有没有一次保存list中所有元素的api]用
list太der了,商品后续添加根本无法更新数据,我这里直接用redisTemplate.opsForValue(),每次都自动更新数据
秒杀商品详情使用
seckill:skus作为key,使用skuId作为field,封装一个类保存秒杀商品的详细信息[调用商品服务接口来通过skuId列表获取商品的基本信息]、所在秒杀场次的Long类型毫秒开始时间和结束时间,秒杀信息以及一个商品随机码[引入商品随机码是为了避免有坏人使用工具在秒杀开始时攻击我们的秒杀接口,事先不知道随机码不好预先攻击接口,只有秒杀开始才把随机码暴露出来,这也不安全啊,我用工具截取随机码再拼接发起请求还是一样快,防止接口提前暴露防黄牛脚本,直接使用UUID生成,必须要带随机码的请求才能成功秒杀],将该对象转换成json字符串保存到redis中
设置秒杀商品的分布式信号量作为库存扣减信息,这个就是讲分布式锁时
Redisson中的RSemaphore信号量,只要进来一个请求就扣减一个计数,直到与秒杀库存相等的计数扣减完,只要能成功扣减的请求才进入后续业务操作去数据库扣减库存,扣减失败的直接响应失败,让失败的线程尽可能短时间的阻塞,不要再去执行无意义地业务操作,而且信号量的key要设置为seckill:stock:#(商品随机码),只能按照商品随机码来扣减信号量,不能按照商品的skuIds来扣减信号量引入
redisson:3.12.0,自动注入redissonClient,通过redissonClient.getSemaphore("seckill:stock:商品随机码")获取信号量,同时通过信号量的rSemaphore.trySetPermits(商品秒杀库存)方法设置信号量计数这里信号量的作用就是限流,只限制商品库存的流量能进入系统,其他的请求全部快速失败避免长时间阻塞占用系统资源
[定时任务类]
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 定时商品上架服务* @创建日期 2024/12/11* @since 1.0.0*/("scheduleSkuUpServiceImpl")public class ScheduleSkuUpServiceImpl {private CouponFeignClient couponFeignClient;private StringRedisTemplate redisTemplate;private RedissonClient redissonClient;(cron = "0 0 3 * * ?")public void seckillRelatedSkusUpNextThreeDays(){log.info("定时任务秒杀商品上架");RLock lock = redissonClient.getLock("seckill_sku_up_lock");lock.lock(10, TimeUnit.SECONDS);try {upSkus();}finally {lock.unlock();}}private void upSkus(){//1. 拼接时间范围参数//拼接其实时间LocalDate today = LocalDate.now();LocalDateTime from = LocalDateTime.of(today, LocalTime.MIN);//拼接结束时间LocalDate twoDaysLater = today.plusDays(2);LocalDateTime to = LocalDateTime.of(twoDaysLater, LocalTime.MAX);//封装时间参数SeckillSessionStartTimeRange seckillSessionStartTimeRange = new SeckillSessionStartTimeRange();seckillSessionStartTimeRange.setFrom(from);seckillSessionStartTimeRange.setTo(to);//2. 调用coupon服务查询秒杀场次和商品信息List<SeckillSessionTo> sessions = couponFeignClient.getSeckillSessionByStartTimeRange(seckillSessionStartTimeRange);//如果没有秒杀场次直接结束方法执行if(sessions==null || sessions.size()==0){return;}//3. 如果有秒杀场次直接redis缓存相应的秒杀商品数据BoundHashOperations<String, Object, Object> operations = redisTemplate.boundHashOps(SecKillConstant.SEC_KILL_SKU_CACHE_PREFIX);//缓存秒杀场次信息for (SeckillSessionTo session : sessions) {List<String> sessionSkus = new ArrayList<>();for (SeckillSessionTo.SeckillRelatedSku seckillRelatedSku : session.getSeckillRelatedSkus()) {String sessionSkuStr = session.getId() + "_" + seckillRelatedSku.getSkuId();sessionSkus.add(sessionSkuStr);//缓存关联商品信息if(!operations.hasKey(session.getId()+"_"+seckillRelatedSku.getSkuId())){seckillRelatedSku.setRandomCode(UUID.randomUUID().toString().replaceAll("-",""));String skuJSONStr = JSON.toJSONString(seckillRelatedSku);operations.put(session.getId()+"_"+seckillRelatedSku.getSkuId(),skuJSONStr);//缓存商品秒杀库存信号量RSemaphore semaphore = redissonClient.getSemaphore(SecKillConstant.SEC_KILL_SKU_STOCK_PREFIX + seckillRelatedSku.getRandomCode());semaphore.trySetPermits(seckillRelatedSku.getSeckillCount().intValue());}}String sessionKey = SecKillConstant.SEC_KILL_SESSION_CACHE_PREFIX + session.getStartTime().getTime() + "_" + session.getEndTime().getTime();Long skuSize = redisTemplate.opsForList().size(sessionKey);if(!skuSize.equals(session.getSeckillRelatedSkus().size())){redisTemplate.delete(sessionKey);redisTemplate.opsForList().leftPushAll(sessionKey,sessionSkus);}}}}[远程调用优惠服务的业务方法]
xxxxxxxxxxpublic List<SeckillSessionTo> getSeckillSessionByStartTimeRange(SeckillSessionStartTimeRange range) {//1. 查询指定开始时间范围内List<SeckillSessionEntity> seckillSessions = list(new QueryWrapper<SeckillSessionEntity>().between("start_time", range.getFrom(), range.getTo()));List<SeckillSessionTo> seckillSessionTos = seckillSessions.stream().map(seckillSessionEntity->{SeckillSessionTo seckillSession = new SeckillSessionTo();BeanUtils.copyProperties(seckillSessionEntity, seckillSession);return seckillSession;}).collect(Collectors.toList());Map<Long, SeckillSessionTo> seckillSessionToMap = seckillSessionTos.stream().collect(Collectors.toMap(SeckillSessionTo::getId, to ->to ));//2. 如果场次不为空,查询每场秒杀活动的关联商品if(seckillSessions!=null & seckillSessions.size()>0){List<Long> sessionIds = seckillSessions.stream().map(SeckillSessionEntity::getId).collect(Collectors.toList());List<SeckillSkuRelationEntity> skuRelations = seckillSkuRelationService.list(new QueryWrapper<SeckillSkuRelationEntity>().in("promotion_session_id", sessionIds));List<Long> skuIds = skuRelations.stream().map(SeckillSkuRelationEntity::getSkuId).distinct().collect(Collectors.toList());System.out.println(skuIds);R res = productFeignClient.getSkuInfoListBySkuIds(skuIds);Map<Long, SeckillSessionTo.SeckillRelatedSku> skus = res.get("skus", new TypeReference<Map<Long, SeckillSessionTo.SeckillRelatedSku>>() {});for (SeckillSkuRelationEntity skuRelation : skuRelations) {SeckillSessionTo.SeckillRelatedSku seckillRelatedSku = new SeckillSessionTo.SeckillRelatedSku();//BeanUtils.copyProperties方法中,如果source中没有target中的属性,即使target中相应属性已经有值了,仍然会被重置null,非常傻逼,除非在第三个参数指定要忽略的属性BeanUtils.copyProperties(skus.get(skuRelation.getSkuId()),seckillRelatedSku);seckillRelatedSku.setId(skuRelation.getId());seckillRelatedSku.setSkuId(skuRelation.getSkuId());seckillRelatedSku.setPromotionSessionId(skuRelation.getPromotionSessionId());seckillRelatedSku.setPromotionId(skuRelation.getPromotionId());seckillRelatedSku.setSeckillPrice(skuRelation.getSeckillPrice());seckillRelatedSku.setSeckillCount(skuRelation.getSeckillCount());seckillRelatedSku.setSeckillLimit(skuRelation.getSeckillLimit());seckillRelatedSku.setSeckillSort(skuRelation.getSeckillSort());SeckillSessionTo seckillSessionTo = seckillSessionToMap.get(skuRelation.getPromotionSessionId());if(seckillSessionTo.getSeckillRelatedSkus()==null){seckillSessionTo.setSeckillRelatedSkus(new ArrayList<>());}seckillSessionTo.getSeckillRelatedSkus().add(seckillRelatedSku);}}return seckillSessionTos;}[远程调用商品服务的业务方法]
xxxxxxxxxxpublic Map<Long, SeckillSessionTo.SeckillRelatedSku> getSkuInfoListBySkuIds(List<Long> skuIds) {List<SkuInfoEntity> sku = list(new QueryWrapper<SkuInfoEntity>().in("sku_id", skuIds));Map<Long, SeckillSessionTo.SeckillRelatedSku> skuInfoEntityMap = new HashMap<>();if(sku!=null & sku.size()>0){skuInfoEntityMap = sku.stream().collect(Collectors.toMap(SkuInfoEntity::getSkuId, skuInfoEntity -> {SeckillSessionTo.SeckillRelatedSku seckillRelatedSku = new SeckillSessionTo.SeckillRelatedSku();BeanUtils.copyProperties(skuInfoEntity,seckillRelatedSku);return seckillRelatedSku;}));}return skuInfoEntityMap;}
定时任务
Cron表达式
定时任务需要确定任务的执行时刻,我们可以使用
Cron表达式来指定任务的执行时刻,时刻最小只能精确到秒刻度Cron表达式介绍:Cron Trigger Tutorial
语法
🔎:
cron表达式是一个由6-7个通过空格分隔的属性组成的字符串,属性包含以下几个值,注意cron表达式中属性是按下列顺序排列的,以空格作为标识来识别属性:[秒 分 时 天 月 周几 年]
Seconds:秒时刻,必要参数,参数范围[0-59]Minutes:分钟时刻,必要参数,参数范围[0-59]Hours:小时时刻,必要参数,参数范围[0-23]Day of month:每个月的第几天,必要参数,参数范围[1-31]Month:月份时刻,必要参数,参数范围[1-12|JAN-DEC]Day of week:每周的第几天,必要参数,参数范围[1-7|SUN-SAT]Year:年时刻,非必要参数[注意Spring不支持识别年时刻单位,年这种写法一般也用不到,正常写一半就只需要以上6位属性]
特殊字符:🔎特殊字符可以在上面的属性中作为属性值使用
*:表示指定属性的任意一个刻度定时任务都会生效,比如在分钟属性处标注一个*,表示每分钟的指定秒时刻都会触发,:表示指定属性取值范围内的几个枚举值,在这些值表示的时刻上定时任务都会生效,比如(cron="7,9,23 * * * * ?"),表示任意时刻的7,9,23秒会执行该定时调度任务-:表示指定属性取值范围内的一段连续范围内的每个刻度都会执行一次,比如(cron="7-20 * * * * ?"),表示每分钟的第7-20秒之间的每秒都会执行一次定时调度任务/:表示指定属性的以/前的指定值作为启动时刻并以/后的指定值作为时刻步长,启动时刻和每间隔一个步长时刻调度任务就会执行一次,比如(cron="7/5 * * * * ?")表示最近的第7秒启动,每隔5秒运行一次🔎:注意可以搭配其他特殊字符使用,比如
(cron="*/5 * * * * ?")表示任意秒启动,每隔5秒钟执行一次调度任务
?:可以出现在属性Day of month和Day of week的位置,这个特殊符号的作用主要是为了防止每月的第几日和每周的第几日发生冲突,比如(cron="* * * 1 * SUN")表示每周的周日且当天是每月的1号才能执行定时调度任务,如果我们想要每月1号都执行一次定时调度任务,可以写成(cron="* * * 1 * ?"),这样就不会管每月1号是周几的配置🔎:注意不能两个位置都写问号
L:可以出现在属性Day of month和Day of week的位置,是last的缩写,表示每月最后一个或者每周最后一个,比如(cron="* * * ? 3L")表示每月的最后一个周二,注意1表示周日,2表示周一,3表示周二,依次类推W:可以出现在属性Day of month的位置,这个特殊符号的作用是表示每个月的工作日,比如(cron="* * * W * ?")表示每个月的工作日触发,该特殊字符可以和L连用,比如(cron="* * * LW * ?")表示每个月的最后一个工作日触发#:可以出现在属性Day of week的位置,用#后面的数字表示每个月的第几个周,比如(cron="* * * ? * 5#2")表示每个月的第二个周四
Cron表达式有在线生成器,直接百度搜索cron就能搜到,通过描述定时任务的执行时刻来自动生成对应的cron表达式
常用
cron表达式(cron="0 0 12 * * ?"):每天12:00pm都执行定时调度任务(cron="0 15 10 ? * *"):每天10:15am都执行定时调度任务(cron="0 15 10 * * ?"):每天10:15am都执行定时调度任务(cron="* 15 10 * * ? *"):每天10:15am都执行定时调度任务(cron="0 15 10 * * ? 2005"):在2005年的每天10:15am都执行定时调度任务(cron="0 * 14 * * ?"):每天14点期间每一分钟执行一次定时调度任务(cron="0 0/5 14 * * ?"):每天14点期间0分钟开始执行,每五分钟执行一次cron="0 0/5 14,18 * * ?":每天14和18点期间分钟开始执行,每五分钟执行一次cron="0 0-5 14 * * ?":每天14点期间0-5分钟内0分钟开始执行,每分钟执行一次cron="0 15 10 ? * 6L":每月的最后一个周五的10:15am执行定时调度任务cron="0 15 10 ? * 6#3":每个月的第三个周五的10:15am执行定时调度任务
SpringBoot整合定时任务
SpringBoot自带定时任务整合流程在定时任务类上使用注解
@EnableScheduling开启定时任务,使用注解@Component将组件放在容器中在定时任务方法上使用注解
@Scheduled(cron="")来开启方法的定时调度,SpringBoot的cron表达式和Quartz的cron表达式语法都是一样的
SpringBoot自带定时任务特点🔎:注意
SpringBoot中默认的@Scheduled定时任务不是整合的Quartz,是SpringBoot自己实现的定时任务,但是cron表达式和Quartz是一样的,区别就是SpringBoot的cron表达式不能写年属性[写了项目启动就会报错],但是Quartz可以,而且SpringBoot中周一到周日和数字1-7一一对应,而Quartz中周一到周日对应数字2-7,也可以写MON-SUN[这个和Quartz是一样的]SpringBoot自带定时任务默认是阻塞式的,即认为如果所有定时任务在一个线程上执行,下一个定时任务必须等上一个定时任务执行完毕以后才能执行,且带有间隔时间的定时任务,间隔开始计时的时间是上一个定时任务的执行结束时间,因此拉起定时任务的线程不应该被阻塞,为了避免定时任务阻塞我们有以下方法1️⃣:一般在定时任务拉起方法中我们不直接执行耗时较长的定时任务,而选择使用
CompletableFuture提交线程池的方式拉起异步线程的方式执行某个任务,示例如下:xxxxxxxxxxpublic class HelloSchedule {(cron = "* * * ? * 5")public void hello(){CompletableFuture.runAsync(()->{xxxService.hello();},executor);}}2️⃣:
@Scheduled注解支持线程池,定时任务的自动配置类为TaskSchedulingAutoConfiguration[
TaskSchedulingAutoConfiguration]xxxxxxxxxx(ThreadPoolTaskScheduler.class)(TaskSchedulingProperties.class)1️⃣ //定时任务的自动配置绑定了属性配置类TaskSchedulingProperties(TaskExecutionAutoConfiguration.class)public class TaskSchedulingAutoConfiguration {(name = TaskManagementConfigUtils.SCHEDULED_ANNOTATION_PROCESSOR_BEAN_NAME)({ SchedulingConfigurer.class, TaskScheduler.class, ScheduledExecutorService.class })public ThreadPoolTaskScheduler taskScheduler(TaskSchedulerBuilder builder) {return builder.build();}public TaskSchedulerBuilder taskSchedulerBuilder(TaskSchedulingProperties properties,ObjectProvider<TaskSchedulerCustomizer> taskSchedulerCustomizers) {TaskSchedulerBuilder builder = new TaskSchedulerBuilder();builder = builder.poolSize(properties.getPool().getSize());builder = builder.threadNamePrefix(properties.getThreadNamePrefix());builder = builder.customizers(taskSchedulerCustomizers);return builder;}}1️⃣ TaskSchedulingProperties("spring.task.scheduling")public class TaskSchedulingProperties {private final Pool pool = new Pool();//这个就是执行定时任务的线程池/*** Prefix to use for the names of newly created threads.*/private String threadNamePrefix = "scheduling-";public Pool getPool() {return this.pool;}public String getThreadNamePrefix() {return this.threadNamePrefix;}public void setThreadNamePrefix(String threadNamePrefix) {this.threadNamePrefix = threadNamePrefix;}public static class Pool {/*** Maximum allowed number of threads.*/private int size = 1;//默认线程池中只有一个线程,这就解释了为什么上一个定时任务没有执行完下一个定时任务总是无法启动的原因,用户可以通过配置spring.task.scheduling.pool.size来指定定时任务线程池的线程数量比如spring.task.scheduling.pool.size=5,但是这个设置不好使,定时任务仍然是单线程执行,太特么搞笑了,老师说有些SpringBoot版本是好使的,弹幕补充2.3.12好使,弹幕补充说要开启注解@EnableAsync和注解@Async才可以实现定时任务线程池的多个线程配置生效,弹幕扯淡的,这是老师说的第三种方法异步任务public int getSize() {return this.size;}public void setSize(int size) {this.size = size;}}}3️⃣:开启定时任务的异步任务功能
默认的
SpringBoot定时任务是单线程完成所有任务,上一个定时任务会阻塞下一个定时任务的执行,我们使用第三种方式定时任务加异步任务的方式来实现定时任务不阻塞的功能在异步任务类的类名上使用
@EnableAsync注解开启定时任务的异步任务功能,在定时任务方法名上标注@Async注解来标注要执行异步任务的方法异步任务注解
@EnableAsync和@Async注解并不是只能标注在定时任务上面,比如AService调用BService中标注了@Async注解的方法也是使用单独的线程来异步执行,这个异步执行也是默认将任务提交给一个默认的线程池,异步任务的线程池自动配置类是TaskExecutionAutoConfiguration[
TaskExecutionAutoConfiguration]xxxxxxxxxx/*** {@link EnableAutoConfiguration Auto-configuration} for {@link TaskExecutor}.** @author Stephane Nicoll* @author Camille Vienot* @since 2.1.0*/(ThreadPoolTaskExecutor.class)(TaskExecutionProperties.class)//1️⃣ 异步任务自动配置类的属性绑定在配置类TaskExecutionProperties中public class TaskExecutionAutoConfiguration {/*** Bean name of the application {@link TaskExecutor}.*/public static final String APPLICATION_TASK_EXECUTOR_BEAN_NAME = "applicationTaskExecutor";private final TaskExecutionProperties properties;private final ObjectProvider<TaskExecutorCustomizer> taskExecutorCustomizers;private final ObjectProvider<TaskDecorator> taskDecorator;public TaskExecutionAutoConfiguration(TaskExecutionProperties properties,ObjectProvider<TaskExecutorCustomizer> taskExecutorCustomizers,ObjectProvider<TaskDecorator> taskDecorator) {this.properties = properties;this.taskExecutorCustomizers = taskExecutorCustomizers;this.taskDecorator = taskDecorator;}public TaskExecutorBuilder taskExecutorBuilder() {TaskExecutionProperties.Pool pool = this.properties.getPool();TaskExecutorBuilder builder = new TaskExecutorBuilder();builder = builder.queueCapacity(pool.getQueueCapacity());builder = builder.corePoolSize(pool.getCoreSize());builder = builder.maxPoolSize(pool.getMaxSize());builder = builder.allowCoreThreadTimeOut(pool.isAllowCoreThreadTimeout());builder = builder.keepAlive(pool.getKeepAlive());builder = builder.threadNamePrefix(this.properties.getThreadNamePrefix());builder = builder.customizers(this.taskExecutorCustomizers);builder = builder.taskDecorator(this.taskDecorator.getIfUnique());return builder;}//这个TaskExecutorBuilder组件可以给容器中添加一个`ThreadPoolTaskExecutor`组件(name = { APPLICATION_TASK_EXECUTOR_BEAN_NAME,AsyncAnnotationBeanPostProcessor.DEFAULT_TASK_EXECUTOR_BEAN_NAME })(Executor.class)public ThreadPoolTaskExecutor applicationTaskExecutor(TaskExecutorBuilder builder) {return builder.build();}//我们可以通过继承结构发现ThreadPoolTaskExecutor实现了JUC的Executor接口,即ThreadPoolTaskExecutor就是SpringBoot自定义的一个线程池}1️⃣ TaskExecutionProperties("spring.task.execution")//可以通过比如spring.task.execution.pool.core-size=5设置核心线程数为5,可以通过比如spring.task.execution.pool.max-size=50设置最大线程数为50,可以通过比如spring.task.execution.pool.queue-capacity设置阻塞队列的容量,可以通过spring.task.execution.pool.keep-alive=60s设置空闲线程的最大空闲时间为60s,我们可以直接通过注入该线程池组件来直接使用Spring默认给我们注入的线程池,线程池的类型ThreadPoolTaskExecutor,默认线程池名字applicationTaskExecutorpublic class TaskExecutionProperties {private final Pool pool = new Pool();/*** Prefix to use for the names of newly created threads.*/private String threadNamePrefix = "task-";public Pool getPool() {return this.pool;}public String getThreadNamePrefix() {return this.threadNamePrefix;}public void setThreadNamePrefix(String threadNamePrefix) {this.threadNamePrefix = threadNamePrefix;}public static class Pool {/*** Queue capacity. An unbounded capacity does not increase the pool and therefore* ignores the "max-size" property.*/private int queueCapacity = Integer.MAX_VALUE;/*** Core number of threads.*/private int coreSize = 8;//线程池的默认大小是8/*** Maximum allowed number of threads. If tasks are filling up the queue, the pool* can expand up to that size to accommodate the load. Ignored if the queue is* unbounded.*/private int maxSize = Integer.MAX_VALUE;//可以设置的最大线程数是Integer类型的最大值/*** Whether core threads are allowed to time out. This enables dynamic growing and* shrinking of the pool.*/private boolean allowCoreThreadTimeout = true;/*** Time limit for which threads may remain idle before being terminated.*/private Duration keepAlive = Duration.ofSeconds(60);public int getQueueCapacity() {return this.queueCapacity;}public void setQueueCapacity(int queueCapacity) {this.queueCapacity = queueCapacity;}public int getCoreSize() {return this.coreSize;}public void setCoreSize(int coreSize) {this.coreSize = coreSize;}public int getMaxSize() {return this.maxSize;}public void setMaxSize(int maxSize) {this.maxSize = maxSize;}public boolean isAllowCoreThreadTimeout() {return this.allowCoreThreadTimeout;}public void setAllowCoreThreadTimeout(boolean allowCoreThreadTimeout) {this.allowCoreThreadTimeout = allowCoreThreadTimeout;}public Duration getKeepAlive() {return this.keepAlive;}public void setKeepAlive(Duration keepAlive) {this.keepAlive = keepAlive;}}}
分布式场景
集群部署下,我们可能只需要一个服务执行定时任务,如果不对定时任务的调用进行限制,集群中的每个服务都会执行一次定时任务
我们可以设置一把分布式锁,执行上架代码需要获取锁,获取到锁以后保存每个数据前都需要调用
redisTemplate.hasKey(key)来判断redis总对应的key是否存在,如果有对应的key就不保存了,如果没有则保存对应的数据注意
redisTemplate.countExistingKeys()可以获取redis中现有key的数量
特别是秒杀业务代码,不能商品已经秒杀结束了,定时任务因为一些问题导致秒杀结束了才开始执行,重新设置信号量,最后导致秒杀的商品被多卖一倍,因此还需要判断
redis中对应的信号量的key是否存在,但是这里商品的随机码每个微服务都不一样,我们可以将信号量的上架和商品数据的上架放在一起判断,如果商品数据需要上架,信号量也需要设置,如果商品数据已经存在了,则商品数据和信号量都无需上架[每个场次的商品都存在一个list中,判断商品是否需要上架是对一个list中的每个元素进行判断的,因此后续增添的商品因为redis中不存在也会进行上架;这里还有问题啊,不能根据skuId判断是否上架商品信息以及设置信号量,因为不同秒杀场次可能都秒杀同一件商品,最好将key设置为场次id_skuId,把这个key作为整体来判断是否还需要给redis中缓存商品和对应的信号量数据,]上锁调用的是
rLock.lock(10,TimeUnit.SECONDS)
所有实现在上面的秒杀商品上架业务代码中,后面二刷再整理,我累了
查询秒杀商品
业务逻辑
📜:前段在首页点击秒杀选项卡发送
ajax的GET请求,请求URL为http://seckill.earlmall.com/currentSeckillSkus,查询当前时间所在秒杀场次关联的所有商品,将商品渲染到首页的秒杀栏中这里面有一个ajax请求动态渲染数据的解决方案,通过
js代码直接拼接出列表组件字符串再赋值到Dom元素中进行渲染$(<li></li>).append($("<p></p>"))是向<li>标签中追加标签<p>,注意只有$(<li></li>).append()才是向标签内添加标签,仍然返回标签对象$(<li></li>)本身,$(<li></li>).appendTo("#seckillSkuContent")是将当前jQuery对象追加到id为seckillSkuContent的对象中使用
js的遍历语法resp,data.forEach(function(item){})每遍历一个元素就生成一个<li>标签
xxxxxxxxxx<div class="swiper-slide"><ul id="seckill_sku_content"></ul></div><script>$.get("http://seckill.earlmall.com/seckill/current/skus",function(resp){if(resp.seckillRelatedSkus.length > 0){resp.seckillRelatedSkus.forEach(function(sku){$("<li onclick='toSkuItem("+sku.skuId+")'></li>").append($("<img style='width: 130px;height: 130px;' src='"+sku.skuDefaultImg+"'/>")).append($("<p>"+ sku.skuName+"</p>")).append($("<span>¥"+sku.seckillPrice+"</span>")).append($("<s>¥"+sku.price+"</s>")).appendTo($("#seckill_sku_content"));})}});function toSkuItem(skuId){location.href="http://item.earlmall.com/"+skuId+".html";}</script>
📜:商品详情页加载完成以后发送
ajax请求查询当前商品是否参与最近秒杀活动来进行预告
首页查询当前秒杀场次商品
确定当前时间所在秒杀场次
在
Redis中使用命令keys seckill:session:*可以查询到满足该模板的所有key,对应Set<String> keys = redisTemplate.keys("seckill:session:*")得到所有秒杀场次的
key以后遍历从key中取出每个秒杀场次的开始时间和结束时间,只要找到当前时间所在秒杀场次直接break跳出当前循环,在跳出循环前使用方法List<String> skuKeys = redisTemplate.opsForList().range(key,-100,100)[range方法实际上是使用的redis的lrange指令,数据取出顺序对应redis的list数据类型的rightPutAll的插入顺序,LRANGE mylist 0 0是取出队列中从左到右下标第0个数据到第0个数据,包含最后一个取出的数据;LRANGE mylist -100 100]从当前秒杀场次的list数据类型中获取索引范围内的关联商品skuId,如果所有的数据索引范围小于这个范围就获取所有数据,如果不在这个范围内就不会获取到任何数据
获取秒杀场次关联的所有商品数据
使用
List<Object> skuInfos=boundHashOperations<String,Object,Object>.multiGet(Collections.singleton(range))[range是一个List<String>类型的数据,注意该方法可能返回空,API上有@Nullable注解表示当检索到没有对应key集合的数据是返回null]获取range集合中所有的元素作为filed的Hash中的所有value数据,将每个商品的json字符串转成实体类封装成list集合直接返回给前端进行渲染即可注意封装数据的时候一定不能将随机码字段封装进去暴露给前端,这样就会被别人知道商品的购买接口预先使用脚本来攻击接口[但是这个接口只暴露给当前秒杀场次的请求用,因此可以携带随机码]
List<Object> skuInfos=boundHashOperations<String,Object,Object>.multiGet(Collections.singleton(range))会直接报错java.util.ArrayList cannot be cast to java.lang.String,multiGet方法需要传参Collection<HK>类型数据,List<String>类型的key的集合就行,List<Object> skuInfos=boundHashOperations<String,Object,Object>.multiGet(Collections.singleton(range))这种写法是错的,原来报错的原因我们传参List<String>,需要把boundHashOperations的类型也相应设置为BoundHashOperations<String,String,Object>,为什么Object不行的具体原因后面再分析注意数据库的默认时区是UTC,最好在系统一开始就在数据库
URL中指定时区为东八区serverTimezone=Asia/Shanghai或者直接在数据库使用命令set global time_zone = ‘+8:00’;将数据库时区设置为东八区
xxxxxxxxxxpublic SeckillSessionTo getCurrentSecKillSessionInfo() {long now = System.currentTimeMillis();//1. 确定当前时间所在的秒杀场次Set<String> keys = redisTemplate.keys(SecKillConstant.SEC_KILL_SESSION_CACHE_PREFIX + "*");BoundHashOperations<String, String, String> ops = redisTemplate.boundHashOps(SecKillConstant.SEC_KILL_SKU_CACHE_PREFIX);for (String key : keys) {String sessionTimeInterval = key.replace(SecKillConstant.SEC_KILL_SESSION_CACHE_PREFIX, "");String[] interval = sessionTimeInterval.split("_");long from = Long.parseLong(interval[0]);long to = Long.parseLong(interval[1]);if(now >= from & now < to){//找到当前秒杀场次,获取对应场次的上架商品,将秒杀场次信息封装并返回List<String> sessionSkuId = redisTemplate.opsForList().range(key, -100, 100);List<String> skuStrs = ops.multiGet(sessionSkuId);if(skuStrs != null && skuStrs.size() >0){List<SeckillSessionTo.SeckillRelatedSku> skus = skuStrs.stream().map(skuStr -> {SeckillSessionTo.SeckillRelatedSku seckillRelatedSku = JSON.parseObject(skuStr, new TypeReference<SeckillSessionTo.SeckillRelatedSku>(){});seckillRelatedSku.setRandomCode(null);return seckillRelatedSku;}).collect(Collectors.toList());SeckillSessionTo seckillSession = new SeckillSessionTo();seckillSession.setSeckillRelatedSkus(skus);seckillSession.setStartTime(new Date(from));seckillSession.setEndTime(new Date(to));return seckillSession;}}}return null;}
商品详情页查询商品秒杀活动信息
在商品详情页请求处理逻辑中添加查询商品是否参与秒杀活动的业务逻辑
在秒杀服务编写一个通过
skuId查询商品是否参与秒杀活动,如果有返回必要的秒杀活动信息在
Hash中获取所有的key,通过Set<String> keys=boundHashOperation.keys()获取所有的key,用正则表达式String regx="\\d_"+skuId;[\d表示匹配任意数字],使用Pattern.matches(regx,key)来匹配正则表达式和被匹配的字符串,遍历所有key,当当前关联的所有秒杀商品的skuId和当前商品的skuId相同时获取Hash数据结构中的value并将其转换成实体类返回给商品服务注意此时商品的返回值中有秒杀随机码,但是此时并没有到达商品秒杀时间,因此不能返回商品的秒杀随机码,只有当前时间处在秒杀时间内才返回随机码,否则将随机码置空
使用异步的方式远程调用秒杀服务查询结果,把秒杀优惠数据也封装到商品详情方法的返回值中
前端渲染秒杀预告信息
Thymeleaf会将以下代码渲染成Sat Feb 22 08:00:00 CST 2020xxxxxxxxxx<li style="color:red" th:if=${item.seckillInfo!=null}>[[${new java.util.Date(item.seckillInfo.startTime)}]]</li>使用
Thymealf的时间格式化工具来格式化Java中Date类型的时间xxxxxxxxxx<li style="color:red" th:if=${item.seckillInfo!=null}>[[${#dates.format(new java.util.Date(item.seckillInfo.startTime),"yyyy-MM-dd HH;mm:ss")}]]</li>实现如果当前时间正在秒杀,我们提示正在秒杀并给出秒杀价格,如果还没有到秒杀时间则显示秒杀活动的时间
xxxxxxxxxx<li style="color:red" th:if=${item.seckillInfo!=null}><span th:if="${#dates.createNow(),getTime()<item.seckillInfo.startTime}">商品将会在[[${#dates.format(new java.util.Date(item.seckillInfo.startTime),"yyyy-MM-dd HH;mm:ss")}]]进行秒杀</span><span th:if="${#dates.createNow(),getTime()>=item.seckillInfo.startTime && #dates.createNow().getTime()<item.seckillInfo.endTime}">秒杀价[[${#numbers.formatDecimal(item.seckillInfo.seckillPrice,1,2)}]]</span></li>更改首页秒杀商品添加点击事件,一点击就跳转该商品的商品详情页
xxxxxxxxxxfunction toSkuItem(skuId){location.href="http://item.earlmall.com/"+skuId+".html";}$.get("http://seckill.earlmall.com/current/seckill/skus",function(resp){if(resp.data.length > 0){resp.data.forEach(function(item){$("<li onclick='toSkuItem("+item.skuId+")'></li>").append($("<img style='width: 130px;height: 130px;' src='"+item.skuInfo.skuDefaultImg+"'/>")).append($("<p>"+ item.seckillPrice+"</p>")).append($("<span>"+item.seckillPrice+"</span>")).append($("<s>"+item.skuInfo.price+"</s>")).appendTo("#seckill_sku_content");})}});
更改前端商品详情页的接口业务,添加是否秒杀商品判断;如果当前时间处在当前商品的秒杀场次内,展示为立即抢购按钮并向秒杀服务接口发起请求,如果当前时间;如果当前时间小于秒杀场次开始时间或者当前时间大于等于秒杀场次结束时间,展示为加入购物车向商品服务接口发起请求
带了商品随机码的目的是防止用户伪造随机码穷举重试,用秒杀场次码和随机码一起只有当前秒杀场次的随机码和商品
skuId三者一一对应商品秒杀才会成功
xxxxxxxxxx<div class="box-btns-two" th:if="${item.seckillInfo!=null && (#dates.createNow().getTime()>=item.seckillInfo.startTime && #dates.createNow().getTime()<=item.seckillInfo.endTime)}"><a href="#" id="seckill" th:attr="skuId=${item.info.skuId},sessionId=${item.seckillInfo.promotionSessionId},randomCode=${item.seckillInfo.randomCode}">立即抢购</a></div><div class="box-btns-two" th:if="${item.seckillInfo!=null || (#dates.createNow().getTime()<item.seckillInfo.startTime || #dates.createNow().getTime()>item.seckillInfo.endTime)}"><a href="#" id="addToCart" th:attr="skuId=${item.info.skuId}">加入购物车</a></div><script>$("#seckill").click(function(){var killId=$(this).attr("sessionid")+"_"+$(this).attr("skuid");var key=$(this).attr("code");var num=$("#numInput").val();location.href="http://seckill.earlmall.com/kill?killId="+killId+"&key="+key+"&num="+num;return false;});</script>用户点击秒杀抢购时直接在前端验证用户的登录状态,如果前端页面没有用户信息说明用户没有登录前端直接跳转登录页进行登录[这里还要设置登录后跳转页面效果最好,没有做这个功能,登录以后跳转回来比较麻烦],如果有用户信息说明用户登录了直接访问秒杀服务
高并发系统设计
业务流程
京东的秒杀流程:把秒杀视为一种优惠,还是在商品详情页将商品添加购物车,在购物车中以秒杀价格进行结算
小米的秒杀流程:立即抢购也是将商品加入购物车,加入购物车以后选择去购物车结算,购物车中商品的价格是秒杀价格
流程基本是一致的,就是正常购物车结算的流程,要考虑的是如何设计一个承载高并发的系统
高并发系统设计
独立部署:服务单一原则,目的是秒杀服务即使自己扛不住压力挂了不要影响其他服务
秒杀连接加密:防止秒杀接口提前暴露,坏人写一个脚本向接口发起高频请求,也防工作人员提前秒杀商品,比如生成一个商品随机码,只有秒杀开始的时候随机码才响应给用户
库存预热,库存快速扣减,商品数据提前缓存,通过在
redis中占有信号量来限制秒杀流量,只有拿到信号量的请求才去处理后续订单付款业务,其他请求一律快速失败,避免请求长时间阻塞占用系统资源这里也存在
redis扛不住高并发请求的问题,一台单机redis的吞吐量也就两万到三万左右,应对这种高并发请求一般要构建redis集群,做十几台redis的集群能扛住百万级别的并发请求
动静分离:所有的静态资源全部都保存在
nginx中,我们可以搭建Nginx集群,使用keepalived技术来负载均衡和rsync来同步静态资源,只有动态请求才会转发到上游服务器线上环境最好使用CDN全网资源分发网络[比如阿里云的CDN网络],用户访问静态资源还没有到Nginx阿里云CDN网络就会选择距离用户最近的节点返回对应的静态资源
恶意请求拦截:恶意请求一般包含恶意脚本给接口发送高频请求来参与秒杀活动,可以根据用户请求的频率来进行拦截,正常请求不可能这么高的频率;此外还有伪造的请求,比如正常请求都会携带令牌,但是一些伪造的请求没有携带令牌,我们可以提前在网关就将这些请求拦截下来,只让正常的请求放行到上游服务器
流量错峰:将可能出现的一秒上百万的请求分散到几秒钟的时间里
小米的方案是用户点击秒杀以后输入一个验证码,一方面验证用户是否是机器人,一方面不同用户输入验证码的速度不同,可以将上百万的用户请求分散到几秒钟上
此外像京东的立即抢购点击是加入购物车,加入了购物车用户还需要去购物车选择商品进行点击结算,这又能分散几秒钟时间
限流、熔断、降级:秒杀服务本身自身流量就非常大,同时秒杀系统还要调用其他服务,因此限流很重要,能避免秒杀服务和其他服务被流量打垮
前端限流:前端点击立即选购以后过一秒才能点击第二下,或者前端点一下以后就不能再点击
后端限流:在网关就识别用户的正常行为和恶意行为,用户恶意行为直接拦截;在网关层面对请求总量进行限制,如果秒杀系统的峰值处理能力是
10W个请求,网关处发现秒杀请求吞吐量超过10w就等上两秒,两秒以后再将请求转发给上游服务器熔断降级:秒杀可能会调用其他业务,如果中间一个服务调用经常失败要对该调用过程做一个断路保护,如果一段时间内某个服务高频调用失败那么后续请求不再继续尝试远程调用,直接服务降级快速释放,避免远程调用失败所有请求都去等待几秒钟才被释放,我们给秒杀系统加入熔断机制,只要调用链任何一个出现了问题,我们一致对外服务熔断降级为快速失败,保证整个调用链是快速返回的不会在某个环节阻塞,避免远程服务调用失败请求一直被阻塞占用系统资源,同时避免每个请求都到该环节阻塞一段时间导致后续积压的请求越来越多
服务降级:一个服务的流量太大,一段时间内直接将请求引导到降级页面,比如说当前服务太忙,请稍后再访问
队列消峰:杀手锏,拿到信号量的请求不进行实际的业务处理,直接发送一个消息给消息队列然后响应结果给用户,订单服务在后台慢慢创建订单处理后续业务,用户可能刷个几十秒,但是最后都能支付成功。像淘宝双十一,有一百万个商品,每个商品都有100个库存,一百万个用户来买这些商品,这就是一亿的流量,此时消息队列的作用就非常明显,一般场景下没这么大的流量消息队列的作用不是特别突出
🔎:秒杀服务只是高并发系统的代表,我们这里实现了服务单一部署,对秒杀接口加密[用随机码来进行加密,只有通过系统在秒杀开始暴露随机码才能获取信号量来抢夺库存],商品库存预热[商品数据和库存扣减都在
redis中,商品数据甚至可以资源静态化到Nginx中,把库存的更新操作放在redis中的信号量中],动静分离、流量错峰通过抢购秒杀商品将商品加入购物车在手动点击结算将瞬时流量分散到一定时间范围内,后续要着重处理的是恶意请求拦截、特别是限流、熔断和服务降级、队列消峰,拿到信号量将整个抢购请求消息放在队列中,订单服务监听消息队列来慢慢创建订单
秒杀流程
业务逻辑
整合
SpringSession判断用户登录状态,编写拦截器,只有秒杀请求才拦截进行登录状态判断,其他请求不拦截直接放行
秒杀流程1:
这种情况秒杀请求会直接拉起购物车服务和订单服务,很难保证多个系统都能同时应对这么大的流量,除非流量非常分散,因此我们可以使用消息队列对复杂业务调用进行流量消峰,只把高并发压力限制在
redis和秒杀服务方便之处在于这种方案的整个流程实际上就是原来正常订单业务把价格改为秒杀价格的流程,做起来很方便


秒杀流程2:
点击立即抢购,请求发给秒杀系统做登录状态校验,校验秒杀请求是否正常[校验秒杀请求的时间、随机码、
skuId和秒杀场次id是否一一对应,接口幂等性校验],请求校验正常尝试获取信号量,成功获取信号量快速创建秒杀订单消息[包含用户、订单号、商品信息]并将消息发送给消息队列[订单服务监听队列消息],同时响应客户端用户秒杀成功,正在为您准备订单,等订单服务创建好订单以后给用户返回支付页,用户选择收货地址并进行支付这种方式的优点是秒杀服务处理秒杀请求到返回给用户页面的过程中没有操作过任何一次数据库,没有发起一次远程调用,要使用的数据全部都在缓存中
这种方式的缺点是秒杀服务拿到信号量会立即响应客户,让客户等待订单服务创建订单完成并进行支付,但是一旦订单服务扛不住压力整个订单服务不可用,用户就无法支付,出现这种情况我们还需要进行兜底处理,因此我们还得在秒杀系统中加入一些与常规支付不同的业务处理逻辑

流程2业务实现
后端秒杀服务接口入参秒杀场次
id、商品的sessionId_skuId、秒杀商品的购买数量根据
sessionId_skuId获取秒杀商品信息,获取不到商品信息直接返回null,获取到商品详细信息校验请求合法性请求合法性校验
判断服务器内部时间是否处在秒杀时间段内,如果不在秒杀时间段内直接返回
null校验随机码和商品场次
id和skuId是否一一匹配验证用户的购物数量是否小于等于限制数量
用户请求幂等性处理:防脚本刷单,让一个用户只能购买一次商品,只要用户购买成功,我们就以
用户id_秒杀场次id_skuId作为key,以用户秒杀商品的数量作为value将键值对存入redis,以当前时间到秒杀场次结束时间作为该键值对的有效时间,使用redisTemplate.opsForValue().setIfAbsent()来为当前用户设置占位,如果能插入说明用户是第一次在秒杀时段购买该商品,可以购买;如果插入不了返回false,说明以前买过,直接返回null
校验通过
rSemaphore.acquire(秒杀商品用户抢购数量)获取分布式信号量,但是不应该使用acquire方法,因为该方法是只要没获取到信号量就会阻塞自旋重试,这会阻塞当前线程,非常不好;使用rSemaphore.tryAcquire(num,100,TimeUnit.MILLISECOND)在一定时间内允许重试,该方法能正常正常获取到信号量会返回true,无法获取到信号量会返回false注意秒杀失败将占位标识删除
注意这里的逻辑有缺陷,只要用户购买数量没有超过限制,应该允许用户多次参与秒杀,不过还有更大的问题,用户秒杀数量达到上限以后应该将商品变成普通价格
如果一个商品流量实在太大,我们甚至不需要给
tryAcquire(num,100,TimeUnit.MILLISECOND)设置一个尝试时间,直接tryAcquire(num)尝试一次就走
获取信号量成功使用
IdWorker.getTimeId()创建一个订单号,直接给消息队列发送一条秒杀成功消息并将订单号返回给用户假设一个秒杀请求的处理算上数据网络传输只需要50ms,每秒单个线程就能支持20的吞吐量,如果让Tomcat同时运行500个线程,单机就能达到一万的吞吐量;如果一旦阻塞,单个线程就要执行3秒,即使Tomcat有500个线程处理请求,吞吐量也只有200不到,老师的设计秒杀服务单个完整请求程序执行时长12ms,单个线程吞吐量就能100,500个Tomcat线程处理请求吞吐量就能达到5万,整20个机器组成集群就能处理上百万的秒杀流量,实际上每秒成功获取信号量秒杀成功的请求可能也就几万,这几万还用了消息队列消峰,因此抗住百万级别流量的并发是可行的
消息队列设计
订单创建成功就使用路由键
order.seckill.order给交换器order-event-exchange发送消息,消息被转发到order.seckill.order.queue,订单服务监听该队列中的内容来慢慢创建订单,该队列的最大作用是流量消峰,避免每个秒杀成功的请求都来实时调用订单服务

消息队列业务实现
引入
RabbitMQ依赖spring-boot-starter-amqp,配置RabbitMQ的虚拟主机地址,配置RabbitMQ的Host地址自定义
RabbitMQ的消息转换器,注意只是发送消息不需要添加@EnableRabbit注解,只有需要监听RabbitMQ消息的时候才需要添加消息中的数据内容包括,订单号
orderSn、秒杀场次id、商品skuId、秒杀价格、购买数量、购买用户id在订单服务创建一个普通队列作为消峰队列、持久化、不排他、不自动删除;创建绑定关系;交换器订单业务已经创建过了
订单服务监听秒杀消峰队列,创建订单保存订单的订单号、用户id、订单改为新建状态,设置订单的应付价格为秒杀价格乘以秒杀数量, 保存订单实体类
保存订单项信息:订单项只有一个秒杀商品、保存订单号、应付价格、购买数量,保存订单项实体类
返回秒杀成功页面提示给用户,然后给一个按钮给用户让用户去选择寄送地址支付即可,这里拖个十秒订单也就被创建出来了
秒杀成功页面直接加入购物车成功页面改, 把添加购物车成功页面加到秒杀服务中,添加
Thymeleaf依赖准备进行页面数据渲染给
ModelAndView中封装当前的订单号,将当前页面的静态资源请求全部换成购物车服务的静态资源请求地址
提示秒杀成功并展示用户的订单号,提示订单正在准备,
10s以后自动跳转支付,支付地址${http://order.earlmall.com/payOrder?orderSn='+orderSn},实际上老师没做自动跳转,还是用户点击去支付跳转支付页面如果订单号为
null就提示手气不好,秒杀失败,请下次再来
实际上秒杀商品上架商品的库存就应该锁定,避免发生货卖出去了但是没货的现象,老师没有做这个业务逻辑,只是将秒杀系统的主业务逻辑实现了,主要就是上面的高并发系统设计原则的实现和重点消息队列流量消峰
线上每个秒杀商品的上架时间都应该有过期时间,这里老师为了测试方便没有做,收货地址的业务处理也没有做,老师不做我也不想做,我累了
后端总览
后端模块
mall-common基础服务
引入公共依赖:
mybatisPlus、Lombok、httpcore、commons-lang、mysql驱动[mysql-connector-java]、servlet-api
mall-coupon优惠券模块
数据库:
mall_cms,改名前为gulimall_smsmall-user用户系统
数据库:
mall_umsmall-order订单系统
数据库:
mall_omsmall-stock库存系统
数据库:
mall_sms,改名前为gulimall_wmsmall-product商品系统
数据库:
mall_pmsrenren-fast后台管理系统
数据库:
mall_adminrenren-generator后端模块代码生成器
mall-gateway后端网关
GateWay网关不是使用tomcat做的,使用的是Netty做的,Netty的网络性能很高mall-third-party后端第三方服务模块
提供包含OSS直传服务端签名服务
mall-search后端操作ES服务器的模块,提供数据操作和检索服务
mall-auth后端认证服务,集成OAuth2.0社交账号注册登录、单点登录功能、原生平台登录注册功能、session共享
数据库:
mall_umsmall-cart购物车服务
项目框架
框架图
用户的所有请求都访问
nginx,nginx转发后端请求到网关,网关主要负责统一的鉴权认证和限流等功能,用这套架构实现资源的动静分离,把静态资源【以实际文件的形式存在的资源】的响应全部放在nginx,后端主要负责处理动态请求实现每一个微服务都可以独立部署、运行、升级和独立自治【技术自治,微服务的技术栈不一定只局限于Java、还可以使用其他任意语言】

分布式架构
SpringCloud官网要求SpringCloud Alibaba的版本也需要和SpringCloud和SpringBoot配合,当前版本下需要使用SpringCloud Alibaba 2.1.X RELEASE版本
SpringCloud Alibaba Nacos-配置中心、注册中心
服务注册、服务发现、服务的配置中心和配置的动态自动批次更新
注意服务调用和负载均衡是由OpenFeign实现的,负载均衡是由OpenFeign中的Ribbon实现的,并不是注册中心的作用
使用配置分组来区分环境,使用命名空间来区分服务;命令空间和配置分组都可以理解为是一种区分手段,即类似java的包管理,可以灵活应用
使用模块名作为命名空间对配置文件进行配置隔离,命名空间分别包含
public|mall-coupon|mall-order|mall-product|mall-gateway|mall-stock|mall-user
SpringCloud GateWay-API网关
鉴权、过滤、路由,限流,日志输出;比zuul更灵活,功能更丰富,是zuul团队新一代网关破产【内部矛盾】的基础上自研出来的第二代网关框架GATEWAY,设计优秀,性能强悍;
后台管理系统和前台界面会向各个服务发起请求,不可能直接把服务的ip和端口写死在前端代码中,这样一旦服务宕机、扩缩容还需要改前端代码,让前端所有的请求都去到API网关,利用API网关来实现请求的路由,将请求转发到各个微服务中;
用户的鉴权如果写在每个微服务中会增加很多的额外开发,让这些重复的工具由网关负责,上游服务不再处理这些重复业务;
网上的测试数据:GATEWAY的QPS是三万二左右,zuul第一代产品是两万左右,zuul第二代产品的性能也非常高;非常流行的Linkerd网关的QPS大概28000左右
在Spring5支持响应式编程、和SpringBoot2的基础上开发的,支持使用任何请求属性【请求头或者请求参数,uri】来进行路由匹配【功能强大】、每种路由规则都有自己独特的断言规则和过滤链【在请求到达上游服务器前或者响应响应给客户前,请求和响应数据都能被修改】, 能无缝整合Hystrix做服务熔断、降级、限流;整合服务发现做负载均衡;URL重写和自定义断言和自定义过滤器
断言是Java8中的断言函数
核心逻辑是请求来到网关,网关根据断言对请求进行匹配,断言为真就根据对应的过滤器链对请求进行处理,然后路由转发到上游服务器处理,处理完成后回来经过一系列过滤器链被网关拿到响应返回给用户
OpenFeign服务调用、负载均衡
OpenFeign整合了feign和Ribbon;同时拥有服务调用功能和Ribbon的负载均衡功能
OpenFeign的逻辑是去注册中心中找到对应的服务集群,从服务集群中根据自身的负载均衡策略由OpenFeign挑一台服务实例进行调用
OpenFeign是声明式的HTTP服务远程调用组件,即通过声明接口的方式对服务进行调用,提高Feign的性能主要手段就是使用连接池代替默认的URLConnection
SpringCloud Feign在Hoxton.M2 RELEASED版本之后不再使用Ribbon而是使用spring-cloud-loadbalancer
SpringCloud Alibaba Sentinel服务容错【限流、降级、熔断】
SpringCloud Sleuth 调用链监控
整合Zipkin来组件调用链路的可视化界面
SpringCloud Alibaba Seata 分布式事务
前身是Fescar,也是Alibaba开源的老框架
部分组件选用SpringCloud Alibaba的原因
SpringCloud原生组件注册中心Eureka、配置中心SpringCloud Config、消息总线BUS、网关Zuul、服务熔断Hystrix等部分组件停止维护和更新,环境搭建复杂、没有完善的可视化界面、需要大量的二次开发和定制;配置复杂,部分配置非常细致和繁杂,而且功能不够强大
SpringCloud Alibaba性能经过长期的考验,有完善的可视化界面,配置也很简单,功能还很丰富
Redisson做分布式锁、分布式对象解决方案
前端总览
ES6
JS语法的ES6版本
ES中的使用Promise对象对异步嵌套操作的处理和对Promise对象的封装,就是axios的原理,这个好好看,可以拿出来吹牛逼的,谷粒学院没有对这个进行说明,导致很多的前端代码的
.then和.catch看不懂Node.js
主要使用Node自带的包管理工具npm
Vue
类似于java中的SpringMVC
Babel
Babel是JS编译器,会自动将ES6语法转成ES5代码,用户可以不用考虑浏览器对ES6语法的兼容问题
Webpack
打包前端项目的工具
renren-fast-vue
后台管理系统前端,提供菜单管理、用户管理和权限管理,由用户自己扩展后台服务组件;renren-gennerator根据后端数据库表可以逆向生成每个表对应前端的表格组件和对应的接口,这些表格组件可以直接在前端使用
技术设计亮点
数据库设计
数据库表设计所有的表关系再复杂都不建立外键约束,电商系统数据量庞大,建立外键关联非常耗费数据库性能,假如每张表都有几十万几百万数据,每删除一条数据,数据库都要对外键进行检查来保证数据库的一致性和完整性,
不允许使用多表连接查询
端口设计
使用5000、6000、7000等作为第一个微服务的端口,后续复制出来的同种类型服务的微服务集群都能在该端口的基础上向后延伸成如5001、5002端口,保证一种服务独占一块区域的端口
依赖引入
在SpringBoot中使用Servlet相关的东西【如ServletRequest】需要在项目中引入依赖servlet-api,但是tomcat自带了servlet-api依赖,将scope改为provided,表示目标环境已经存在
mysql数据库对于5.7*版本驱动选择5.1或者8.0版本的都行,这两个版本是全适配的,官方推荐驱动8.0版本,课程使用的是8.0.17版本
判断库存不足的算法设计
判断库存满了以后,会修正当前购物车的数量,如果根据监听器的当前值给出库存满了的提示,即便发生了库存超限给出了库存超限提示还是会因为把商品数量改的合理导致错误提示信息还没来得及渲染就被重置正常了,发生库存超限修正商品数量导致提示信息重置和单纯数据变正常提示信息重置的区别是旧值是不是等于3,只有旧值等于4且新值等于3的情况才是库存超限被修正的情况;可以通过vue中的监听器,根据旧值和新值同时不满足等于三作为条件来清空错误提示信息,设置当商品数量超过库存限制修正商品数量,只有当超限时商品数量被修正才会提示库存数量超限,其他情况提示信息被重置来避免超限修正提示信息导致提示信息无法被展示的问题
但是还有问题,这里的库存信息不是实时的,最好用户添加购物车改变数量的同时发起请求查询库存数量,同时顾客添加了购物车不一定购买,此时最好设计成购物车不限制数量,改成添加购物车查询库存展示库存信息不限制购物车数量,结算时发起请求限制购买数量并展示库存信息并加锁,用户订单失效再释放锁
【无法正常更新库存超限提示的代码】
xxxxxxxxxxwatch:{num1:function(newNum,oldNum){if(newNum<0){this.num1=0}if(newNum>3){//在监听器中对变量进行限制要对原变量this.num1直接操作,不能对newNum或者oldNum进行操作,效果不会显示在页面中this.msg="库存超出限制"this.num1=3}else{this.msg=""}}}【优化后代码】
xxxxxxxxxxwatch:{num1:function(newNum,oldNum){this.msg=''if(newNum<0){this.num1=0}if(newNum>3){this.num1=3}if(oldNum==4&&newNum==3){this.msg="库存超出限制"}}}
问题解决方案
高版本用junit5,低版本用junit4,低版本这里单元测试要用的话,必Test类和测试方法上加上public,否则测试方法不会出现可运行的图标!还要加@RunWith(SpringRunner.class)注解
项目前端设计
路由策略
详见:项目搭建流程--商品分类管理--树形列表组件--前端路由规则
重点:前端菜单创建和页面路由规则
前端接口请求和响应结果处理的方式
详见:项目搭建流程--商品分类管理--请求数据
重点:
请求URL处理
ES6的Promise对象对ajax请求和响应结果处理的封装原理
商品分类树形列表设计
分类数据封装
详见:项目搭建流程--商品分类管理--分类数据封装
重点:
树形列表封装逻辑和实现、
mybatis的二级缓存对响应处理的加速
1000条商品分类记录首次请求在200ms,后续请求因为缓存只需要20ms
树形列表组件
详见:项目搭建流程--商品分类管理--树形列表组件--树形列表
重点:
树形列表组件设计和优化
mybatis的二级缓存对响应处理的加速
1000条商品分类记录首次请求在200ms,后续请求因为缓存只需要20ms
跨域解决方法
CORS:跨源资源共享
跨域问题解决方案
详见:项目搭建流程--商品分类管理--请求数据--请求跨域问题
重点:
跨域问题的原理和方案
renren-fast后台服务对跨域问题的处理和统一使用网关对跨域问题的处理
逻辑删除
使用MyBatisPlus实现逻辑删除
详见:项目搭建流程--商品分类管理--逻辑删除
重点:
配置MyBatisPlus实现逻辑删除
逻辑删除的原理
树形控件展开优化【重点】
对删除增加树形列表节点后的节点展开效果进行优化,实现节点展开完全由用户手动控制,页面数据刷新不会对节点展开状态造成任何影响,同时能有效地向用户展示节点删除和增加的效果
详见:项目搭建流程--商品分类管理--逻辑删除--前端实现--树形控件展开优化
重点:
发现查阅文档一步步优化的效果和逻辑
对树形列表的节点进行拖拽优化
详见:项目搭建流程--商品分类管理--节点拖拽
重点:
当前节点允许拖拽到目标位置的逻辑判断
节点拖拽成功后统计要修改记录的逻辑,包含当前节点的兄弟节点、当前节点,可能包含当前节点的子节点
新增和修改数据
修改数据时回显的数据要实时获取,避免因为用户长时间停留在列表界面突然点击编辑按钮导致回显的是旧数据,实际数据可能已经被别的用户修改过了,新增和修改主要在业务逻辑上能说清楚即可
业务逻辑
新增和修改都是在树形节点上添加按钮实现,新增和修改按钮点击都会触发category初始化,新增的业务为一二级商品分类节点可以添加子节点,三级节点不能添加子节点【按钮通过v-if配合节点的目录层级进行判断是否显示】;修改按钮每个节点上都有;添加子节点的逻辑是点击添加按钮弹出element-ui的对话框组件,对话框中嵌套element-ui的表单组件可以修改商品分类的名字、图标和计件单位信息,商品的分级信息、父id信息由新增点击事件自动为category对象赋值;对话框的标题由一个布尔类型的参数isAdd进行控制,点击新增按钮isAdd为true,显示新增分类;点击编辑按钮isAdd设置为false,通过单向绑定写js代码的方式显示修改分类;对话框点击确认请求新增分类接口还是请求修改接口也由isAdd参数确定;新增请求响应成功通过element-ui的弹窗js代码弹窗提示信息并关闭对话框并重置category对象并重新请求树形列表数据
修改分类打开对话框实时查询回显单条分类数据【避免长时间停留在列表界面导致回显老数据,有可能期间数据已经被其他用户修改了】,回显数据能修改的只有部分数据,使用解构表达式获取能被修改的数据属性和主键Id传给后端接口进行修改,属性值为null的字段修改时会自动跳过,修改成功后弹窗提示信息、关闭对话框、重置category对象并重新请求树形列表数据
请求参数校验
element-ui表单组件浏览器入参校验和服务端的注解参数校验、服务端参数校验异常的局部异常处理和全局异常处理、服务端入参分组校验和服务端自定义校验注释,内容在商品品牌管理--对话框再优化
AOP的应用场景
对全局异常的处理
@ControllerAdvice注解结合@ExceptionHandler注解对指定控制器指定异常的全局处理
跨域问题【在预检请求的响应头添加指定信息允许跨域】
@Transactional单体事务注解实际开发中用注解通过AOP对方法上锁解锁来使用分布式锁
通过AOP思想使用注解来实现对方法结果的缓存功能
MP分页查询
MP分页查询属性分组,和封装Page类和PageUtils类,这个MP分页查询不使用插件,直接用原生的page方法查
MP的分页查询需要引入分页插件,否则返回的对象中没有当前页、总记录条数等信息
Object规范
PO【Persistant object】-- 持久对线
PO对应数据库表中的一条记录,多个记录可以使用PO的集合
Java中的Entity/POJO就是PO
DO【Domain Object】-- 领域对象
从业务中抽取出来的概念形成的对象都可以称为领域对象
TO【Transfer Object】-- 数据传输对象
不同服务间相互调用封装数据的对象,调用其他服务的服务需要将数据对象转成json传递给其他服务,其他服务又将json转回成对象,所以TO对象一般都放在Common包下
DTO【Data Transfer Object】-- 数据传输对象
泛指用于展示层与服务层间的数据传输对象
这个概念来源于 J2EE 的设计模式, 原来的目的是为了 EJB 的分布式应用提供粗粒度的数据实体, 以减少分布式调用的次数, 从而提高分布式调用的性能和降低网络负载
VO【value object】-- 值对象
通常用于业务层之间的数据传递, 和 PO 一样也是仅仅包含数据而已。 但应是抽象出 的业务对象 , 可以和表对应 , 也可以不 , 这根据业务的需要 。
一般这个也叫view Object,被称为视图对象
作用可以是接收前端页面传递来的请求参数,将请求参数封装成对应的vo对象
比如一次提交的数据关联几张表,需要多表操作存储一次提交的信息,此时就可以使用vo类
也可以将业务处理完成的对象封装成页面需要的数据
VO类属性的类型也一定要和实体类的类型对应,否则使用BeanUtils对拷对应字段会直接失败
BO【business object】-- 业务对象
作用是把业务逻辑封装成一个对象,这个对象可以包括一个或多个其它的对象。 比如一个简 历, 有教育经历、 工作经历、 社会关系等等。 我们可以把教育经历对应一个 PO , 工作经 历对应一个 PO , 社会关系对应一个 PO 。 建立一个对应简历的 BO 对象处理简历, 每 个 BO 包含这些 PO 。 这样处理业务逻辑时, 我们就可以针对 BO 去处理。
POJO【plain ordinary java object】-- 简单无规则java对象
传统意义的 java 对象。 就是说在一些 Object/Relation Mapping 工具中, 能够做到维护 数据库表记录的 persisent object 完全是一个符合 Java Bean 规范的纯 Java 对象, 没有增 加别的属性和方法。
就是最基本的JavaBean,只有属性字段及setter和getter方法,POJO 是 DO/DTO/BO/VO 的统称。
DAO【data access object】-- 数据访问对象
J2EE设计模式中,有个接口就是DAO,专门负责持久化操作,为业务层提供接口,该对象通常和PO结合使用访问数据库,包含各种数据库CRUD操作方法;
SPU和SKU
概念,数据库表设计、前端页面设计,后端接口实现逻辑,商品新增保存服务是重点,分步保存商品信息的处理和所有商品信息的表结构
VO类的数据类型与实体类的数据类型不一致会导致使用BeanUtils.copyProperties时拷贝数据对应字段数据拷贝不进去,BigDecimal类型对应数据库的数据类型是Decimal
ES节点启动报错
ES集群更改节点端口号以后节点启动报错,第一是排除端口占用【更改节点端口占用也是这个目的】,第二是更改任意一个节点的端口配置文件,ES集群的每个节点的data目录要删掉,否则启动报错
docker无法拉取镜像
因为DNS服务器地址的默认配置问题,修改文件/etc/resolv.conf为以下内容,即配置如下DNS地址即可,注意该文件重启网络或者系统就会被覆写,如果想每次拉取前都不需要修改需要将文件权限修改为只读
/etc/resolv.confxxxxxxxxxx[root@localhost vagrant]# cat /etc/resolv.conf# Generated by NetworkManagersearch localdomainnameserver 114.114.114.114nameserver 8.8.8.8nameserver 223.5.5.5
ES文档映射设计
ES文档product索引数据映射设计考虑冗余设计,避免带来过大的网络传输压力
ES映射关系中数组类型的字段使用nested数据类型避免数组扁平化处理导致检索发生错误的问题
响应类R解决服务调用端类型自动转换问题
服务间调用响应结果转换成json,json再转换成对象的过程中会将List
对象自动转换成List ,这是因为json对象天然符合Map的键值对结构,这是为了方便数据的读取,但是LinkedHashMap无法在服务调用端强转为自定义的TO类,通过以下方式可以解决这个问题
方案一是创建一个数据类型为泛型的私有属性,这种方式服务端调用在响应结果中会自动将私有属性封装成对应类型的数据,而不会使用底层为了方便将json对象直接转成LinkedMap的问题,而linkedMap无法被强转为用户的自定义类型
以下这种实现方式并不成功,因为继承了HashMap的实体类中自定义带泛型的私有属性,响应过程不会显示私有属性的内容【这点非常神奇,还没有搞清楚为什么;继承了HashMap的实体类的私有化属性无法在网络中转换为json进行传输】,更神奇的是通过打断点得知在向R中setData的时候数据是成功赋值给data的,而且使用
r.getData()能获取到属性和属性值,但是打断点看R里面是没有该属性的,而且也不会在响应中被转换成json,
xxxxxxxxxx/** * 返回数据 * * @author Mark sunlightcs@gmail.com */public class R<T> extends HashMap<String, Object> {
private T data;
private static final long serialVersionUID = 1L;
public T getData() { return data; }
public void setData(T data) { this.data = data; } public R() { put("code", 0); put("msg", "success"); } public static R error() { return error(HttpStatus.SC_INTERNAL_SERVER_ERROR, "未知异常,请联系管理员"); } public static R error(String msg) { return error(HttpStatus.SC_INTERNAL_SERVER_ERROR, msg); } public static R error(int code, String msg) { R r = new R(); r.put("code", code); r.put("msg", msg); return r; }
public static R ok(String msg) { R r = new R(); r.put("msg", msg); return r; } public static R ok(Map<String, Object> map) { R r = new R(); r.putAll(map); return r; } public static R ok() { return new R(); }
public R put(String key, Object value) { super.put(key, value); return this; }
/** * @return {@link Integer } * @描述 获取响应的响应码判断响应状态 * @author Earl * @version 1.0.0 * @创建日期 2024/03/26 * @since 1.0.0 */ public Integer getCode(){ return (Integer) this.get("code"); }}方案2是不使用私有属性,使用fastjson的TypeReference指定要转换的数据类型,先将Map转换成json,再用fastjson将json字符串转成通过泛型指定的实体类
xxxxxxxxxx/*** 返回数据** @author Mark sunlightcs@gmail.com*/public class R extends HashMap<String, Object> {private static final long serialVersionUID = 1L;//使用泛型需要声明泛型,方法中使用的泛型在方法名前面声明<T> Tpublic <T> T getData(TypeReference<T> typeReference){//接收到的Object类型里面的对象被自动反序列化成Map了,因为互联网传输过程中使用JSON天然符合Map特性//系统底层默认转成Map是为了更方便数据的读取,R里面data存的数据的数据类型默认是LinkedMap类型的,LinkedHashMap无法被强转为我们自定义的To类//需要使用fastjson的TypeReference先将Map转换成json,再用fastjson将json字符串转成通过泛型指定的实体类Object data =get("data");String dataJSONStr = JSON.toJSONString(data);T t = JSON.parseObject(dataJSONStr, typeReference);return t;}public R setData(Object data){put("data",data);return this;}public R() {put("code", 0);put("msg", "success");}public static R error() {return error(HttpStatus.SC_INTERNAL_SERVER_ERROR, "未知异常,请联系管理员");}public static R error(String msg) {return error(HttpStatus.SC_INTERNAL_SERVER_ERROR, msg);}public static R error(int code, String msg) {R r = new R();r.put("code", code);r.put("msg", msg);return r;}public static R ok(String msg) {R r = new R();r.put("msg", msg);return r;}public static R ok(Map<String, Object> map) {R r = new R();r.putAll(map);return r;}public static R ok() {return new R();}public R put(String key, Object value) {super.put(key, value);return this;}/*** @return {@link Integer }* @描述 获取响应的响应码判断响应状态* @author Earl* @version 1.0.0* @创建日期 2024/03/26* @since 1.0.0*/public Integer getCode(){return (Integer) this.get("code");}}
商品库存返回值处理
商品库存是由库存字段和被锁库存字段通过SUM聚合函数相减得到的,可能存在两个字段没有值的情况,此时返回值可能为null【可能商品已经创建但是还没有采购入库,商品的库存是采购入库后自动添加的】,需要使用Long类型接收,并且判断是否有库存的逻辑先判断该字段是否为null,如果为null直接返回false表示没有库存;在判断不为null的条件下再判断对应的值是否大于0【
count>0】,对应的判断结果作为是否有库存的结果
Nginx携带客户端的请求头
Nginx代理会丢带请求头信息,比如Host请求头,这些头信息在后端服务器可能会用到,比如使用客户端的Host头信息来做网关的路由转发,还有很多其他头信息,参考nginx笔记,需要在nginx中配置携带对应的头信息
注意网关要优先匹配更加精细的URI再匹配Host,这样设计匹配规则更精细也更容易控制,需要把Host路由放在URI匹配的后面,这也是GATEWAY网关的设计理念,精确匹配优先生效【总的效果满足,uri为/api/***,转发到对应的服务模块;如果满足域名子域名且没有被uri精确匹配的转发到商品服务,比如前台页面请求】
JMeter压测大量异常的问题
注意这个只是可能出现问题,实际不一定会出现该问题,我这里完全一样的配置跑了28w都没有出问题,虽然老师的一跑就异常
为了避免Jmeter出现相关问题,使用Jmeter一律还是进行以下设置
JMeter报错Address Already in use
问题描述:Jmeter访问测试本机127.0.0.1的端口服务,在无限请求的情况下请求产生大量异常,异常率迅速飙升超过50%,响应体报错,提示信息
Address already in use原因分析:该问题实际是windows的问题,windows本身提供给TCP/IP的端口是1024-5000,且需要四分钟才会循环回收这些端口,短时间内跑大量的请求会将端口占满
解决办法:修改windows的注册文件,windows官方文档中指出当尝试大于5000的TCP端口连接时会收到大量错误,可以通过以下方案来解决
在win+r打开窗口中使用命令
regedit打开注册表选择
计算机\HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters右击
parameters,新建--DWORD32位,修改对应名字为MaxUserPort,点击该MaxUserPort,在弹出窗口将数值改为65534,基数为十进制【这是设置最大可用端口数量】右击
parameters,新建--DWORD32位,修改对应名字为TCPTimedWaitDelay,点击该TCPTimedWaitDelay,在弹出窗口将数值改为30,基数为十进制【这是】设置windows回收关闭端口的等待时间为30s退出注册表编辑器,重启计算机配置才能生效
Jvisualvm更改插件地址
项目中还需要监控内存的垃圾回收等信息,jvisualvm默认是不带该功能的,需要安装插件,点击工具--插件,点击可用插件--检查最新版本来测试是否报错无法连接到VisualVM插件中心,如果报错,原因是需要指定插件中心的版本【修改插件中心的地址】,按照以下方式解决
打开插件中心的网址
https://visualvm.github.io/pluginscenters.html使用命令
java -version查看本机的jdk版本java version "1.8.0_101",重点关注小版本号101在插件中心的网址中找到小版本所在对应的版本号区间,拷贝对应版本区间的插件更新地址【点进该地址,复制页面最顶上的地址】
在
jvisualvm中点击设置--编辑Java VisualVM插件中心,将地址粘贴到弹出框的URL栏中,点击确定后会自动进行更新此时就可以直接使用可用插件菜单的插件了
性能优化策略
中间件优化
调整中间件的性能,让中间件本身的性能增加
使用更先进的网卡网线,更先进的数据传输技术、传输协议等等来增加网络传输性能
业务优化
数据库的查询速度优化
Mysql优化高级课中讲解了很多优化手段,到时候学习一下
该项目中的数据库优化
查询使用的是cat_level字段从1425条记录中进行查询,非主键,查询没走索引,查询比较慢,首次查询一级商品分类耗时基本200ms【数据库一千条数据,查询到的数据二十多条和查询一千多条不走索引差不多都是200ms】往上,后续查询时间会降低到3-6ms左右【老师的时间比这个时间长多了第一次1432ms,第二次6ms】;在navicat中右键表选择管理索引,给对应的查询字段添加索引,索引类型为Normal,首次查询178ms,后续每次2-4ms,2和3ms的出现频率比原来更频繁;日志级别为debug即控制台打印sql,压测从原来的1212.6提升为2173;日志级别设置为error即控制台不打印sql的情况下,压测吞吐量从2173提升至2399【由此可以看出,打印日志和数据库走索引对接口性能都有影响,其中以数据库查询走索引对接口性能提升极大,接近80%的提升,不打印sql提升约10%】,特别注意添加索引对mybatis有了缓存以后仍然有效啊,查询速度几乎可以提升一半,可能是像浏览器缓存一样发送请求验证数据是否被更改
模板的渲染数据
开发期间模版引擎一般要看到实时效果,所以一般在配置文件是关闭了缓存功能的,上线后一定要打开缓存,数据渲染吃CPU,开了Thymeleaf的缓存功能吞吐量从1212.7提升到了1287,提升有限,不过还是有接近约6.2%的提升【主要的限制还是在数据库上,这里在控制台打印SQL日志也是有影响的】
静态资源的响应速度【tomcat本身的并发不高,响应静态资源还需要分出线程资源,整个吞吐量就会下去很多】
一次动态请求返回的静态页面特别是大型网站会并发发起几十到上百个并发请求请求静态资源,tomcat的本身支持的并发就不高,处理静态资源分出的线程资源极大,占用处理动态请求的线程资源,整个吞吐量就会下降很多,tomcat直接变成系统瓶颈,解决办法是做动静分离,把静态文件前置nginx或者CDN,开启浏览器的静态资源缓存功能,让tomcat把几乎全部的资源拿来处理动态请求,将静态资源中非模版的部分文件夹index全部上传nginx的指定站点目录html下的static目录下,nginx返回的静态资源响应头中Server字段会带nginx的版本;做了动静分离后jmeter能全量压测了,不像之前直接卡死,测出来吞吐量为13【比老师的结果11稍好】,老师的jmeter更给力啊,可能是他的服务不给力【循环查库查二三级分类的数吞吐量很低,这个数据一个响应就是69K的数据,我这个接口的吞吐量还可以,可能jmeter处理不了这么多数据,最后的效果是jmeter页面卡死,看不到数据,但是服务器一直在响应压测,直到若干分钟后手动关闭了jmeter,而且整个过程的FGC非常少,老师的FGC太多也可能是循环查库造成的,我这儿只有几个Map对象比较大】,jmeter没有接收到很多响应,我这儿服务器效果还行
集中修改首页中对静态资源的超链接方法【给所有静态资源的uri添加前缀static】:
href="替换为href="/static,<script src="替换为<script src="static/,<img src="替换为<img src="static/<src="index替换为<src="static/index
修改nginx配置将静态资源站点修改至nginx的挂载目录
xxxxxxxxxxserver {listen 80;server_name earlmall.com;location /static {root /usr/share/nginx/html;}location / {proxy_set_header Host $host;proxy_pass http://gateway;}error_page 500 502 503 504 /50x.html;location = /50x.html {root /usr/share/nginx/html;}}
调高日志打印级别,控制台打印日志也会影响吞吐量,大约10%的提升
提升JVM内存
全量压测【即自动发起响应中的并发请求】,老师的接口中JVM中的老年代区域的FGC和YGC变得频繁【可能是因为他的循环查库,我这儿FCG只有个位数,我还以为Jvisualvm出问题了】,增大JVM内存也能提升性能
【老师的全量压测数据】
提升并发请求量比如增加用户数到200,吞吐量也会提升,老师的压测数据从11来到三四十了,最后因为频繁地FGC导致JVM内存爆满溢出导致他的商品服务直接崩溃了【他这里压的是localhost,请求根本就没走nginx,全走的tomcat,静态资源也走的tomcat,但是之前他是将tomcat中的静态资源全部剪切到nginx的,所以他的静态资源请求会全部快速失败,因此jmeter不会有这么多的静态数据需要处理,说白了就是在压首页渲染和二三级分类数据两个接口,而且二三级分类接口还是循环查库,因此jmeter的压力才这么小,我改成和他一样的配置以后jmeter也没有崩过了,但是这样测出来的数据是不对的,因为tomcat还分担了线程处理静态资源,只是全部快速失败而已】
【压力测试首页且静态资源请求tomcat,200用户全量并发的情况】
100mJVM内存的情况下,Jmeter没有数据报告而且没卡死,说明第一个请求都没有处理完,Jvisualvm中显示情况为伊甸园区和老年代区的内存全部直接飙满且没有GC过程,FGC的时间飙到两分钟,卡死以后老年代内存缓慢增加到满内存,老年代内存满了以后控制台开始打印线程异常
【老年代内存爆满后控制台抛线程异常】
【商城首页直接崩溃】
感觉崩溃的原因主要还是带上静态资源请求并发量太高,上千的并发直接瞬间把tomcatJVM内存压满,连GC都无法进行,老年代内存满了以后控制台开始抛异常,服务直接不可用
修改JVM参数
-Xmx1024m -Xms1024m -Xmn512m增加JVM内存空间,并给新生代的JVM空间调整到512M【伊甸园区分配384M,两个幸存者区分别64M】,原来新生代只有54M,老年代67M,200的用户并发,吞吐量只有11,但是没有发生内存爆满溢出和服务崩溃的问题,更改内存后即使384M的伊甸园区也是频繁YGC,几乎一秒左右就一次【这里不能用jmeter直接压nginx,响应的资源太多会直接把jmeter压垮卡死,不显示数据,无法正常停止,单压tomcat即使返回69K的数据jmeter还是能显示数据,静态资源光文件夹就有10M】,JVM内存增加到1024M,即使200用户,再加上所有快速失败的巨多静态资源请求,只是伊甸园区内存频繁约每秒一次的GC,老年代并没有频繁GC,增长的也比较慢,没有服务崩溃的风险
缓存操作对象问题
这个首页商品二三级分类的优化很多啊,比较重要,吞吐量也比较有代表性
异常情况
Jmeter压测过程中发生了大量异常【异常一度飙升至50%-90%不等】,异常响应内容如下
异常信息:
Redis exception; nested exception is io.lettuce.core.RedisException: io.netty.util.internal.OutOfDirectMemoryError: failed to allocate 499122176 byte(s) of direct memory (used: 511705088, max: 1006632960)",,浏览器访问发现服务已经崩了;
后台控制台连续抛出大量异常
io.netty.util.internal.OutOfDirectMemoryError: failed to allocate 499122176 byte(s) of direct memory (used: 511705088, max: 1006632960)原因分析:
抛出异常的信息为:lettuce在io使用netty操作时出现了
OutOfDirectMemoryError异常,专业术语对外内存溢出,只要使用当前版本及以前版本的lettuce就会出现该问题,即使现在没出现问题,上线以后也依然会出现该问题,出现该问题的原因是内存不够【弹幕说就是直接内存,接触netty和网络编程就会知道】,不使用压测就浏览器访问测试一点问题没有,但是使用压测或者服务上线后,并发量一上来就发生了该错误,报错说是内存问题,设置JVM的堆内存为-Xmx100m,但是使用Jvisualvm分析堆内存情况发现堆内存一切正常,YGC频繁正常进行,老年代缓慢增长,metaspace没什么变化;SpringBoot2.0【2.1.8.RELEASE】【据说2.3.2.REALEASE不会爆该异常】以后整合的操作redis的客户端是lettuce【5.1.8.RELEASE】,该客户端使用netty【4.1.38.Final】和redis进行网络通信,因为Luttuce配合netty进行网络操作时做的不到位,导致netty的堆外内存溢出【我们本机的内存32G完全是够用的,但是还是爆堆外内存】,通过控制台的错误日志发现,爆该异常的原因是要要分配的堆外内存【直接内存】加已经使用的直接内存大于最大的堆外内存,但是我们并没有设置过堆外内存,只是设置了JVM的内存-Xmx100m,对该值,300m和1G都发生了该异常,经过研究发现netty没有指定堆外内存,会默认使用-Xmx100m作为堆外内存,在并发处理过程中,获取数据的量特别大【一次就是69K】,数据在传输、转换过程中都需要占用内存,导致内存分配不足,出现堆外内存溢出问题;当-Xmx调大成1G的时候,发现不会瞬间发生堆外内存溢出,甚至还能测出吞吐量好一会儿以后才会发生该异常;即使将该值调整到很大的值,也只能延迟该堆外内存溢出的情况,但是该异常永远都会出现,根本原因是源码中netty在运行过程中会判断需要使用多少内存,计数一旦超过常量DIRECT_MEMORY_LIMIT【直接内存限制】就会抛OutOfDirectMemoryError异常,调用操作完以后应该还要调用释放内存的方法并计数释放的内存使用量,但是在操作的过程中没有及时地调用减去已释放内存导致报错堆外内存溢出,直接内存限制使用的是虚拟机运行参数设置-Dio.netty.maxDirectMemory,该问题在线上也会出现,到时候线上演示如何通过日志定位该问题并进行操作
解决方案:
不能只调大虚拟机参数
-Dio.netty.maxDirectMemory来调大虚拟机内存,因为经过多段测试,调大内存只会延缓出现该异常的时间,延缓时间也非常有限,长久运行后也会直接爆堆外内存,根本的解决方案有两个,lettuce和jedis都是操作redis的最底层客户端,其中封装了操作redis的api,SpringBoot的RedisTemplate又对这俩客户端进一步进行了封装,在RedisAutoConfiguration中也使用@Import注解引入了这俩的ConnectionConfiguration,在该ConnectionConfiguration中会给容器中放入连接工厂RedisConnectionFactory的实现类,由该工厂对象创建出RedisTemplate对象并注入容器,无论使用jedis还是lettuce,都可以直接使用RedisTemplate来不动代码仅通过更改pom排除和引入另一个来更换底层操作redis的客户端第一是升级lettuce客户端操作
nettyluttuce从5.2.0.RELEASE开始就解决了这个问题,但是诡异的是
spring-boot-starter-data-redis直到最新的3.3.0【2024.5.23】都还是用的5.1.8.RELEASE【从2.1.8.RELEASE以前就开始用】,到现在还没换,直接排除原来的lettuce,更换5.2.0.RELEASE版本即可,使用这个不会报错【56w的样本】而且吞吐量较jedis大了一倍多,比5.1.8.RELEASE的吞吐量1000还要高,达到1180;如果直接从缓存拿到json不冗余转换,吞吐量能达到1200【这里使用lettuce5.2.0.RELEASE是否对从redis中拿到的数据进行冗余转换影响不大,提升了20的吞吐量】
xxxxxxxxxx<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId><exclusions><exclusion><groupId>io.lettuce</groupId><artifactId>lettuce-core</artifactId></exclusion></exclusions></dependency><!-- https://mvnrepository.com/artifact/io.lettuce/lettuce-core --><dependency><groupId>io.lettuce</groupId><artifactId>lettuce-core</artifactId><version>5.2.0.RELEASE</version></dependency>第二是使用老版客户端jedis来操作redis,缺点是更新频率低,lettuce的优点是使用netty作为底层的网络框架,吞吐量极大【据说lettuce5.2.0以后解决了该问题,弹幕说把版本改成5.3.4.RELEASE也可以】,以下是排除lettuce使用jedis来操作redis,这种方式吞吐量只有400了,比使用lettuce导致吞吐量直接少了600
xxxxxxxxxx<!--redis做缓存操作,搜索RedisAutoConfiguration能找到redis相关配置对应的属性类,所有相关配置都在该属性类中--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId><exclusions><exclusion><groupId>io.lettuce</groupId><artifactId>lettuce-core</artifactId></exclusion></exclusions></dependency><!--springboot默认jedis版本控制是2.9.3--><dependency><groupId>redis.clients</groupId><artifactId>jedis</artifactId></dependency>
缓存失效相关问题
缓存失效可能引发的问题,缓存失效指缓存没有命中,缓存一旦没有命中可能出现以下问题:缓存穿透、缓存雪崩、缓存击穿
以下用首页商品二三级分类数据演示对三个问题的解决方案
缓存穿透
概念:查询一个一定不存在的数据,默认情况下没有该数据的缓存,由于缓存不命中,请求将会去查询数据库,但是数据库也没有该记录,如果不将此次查询的结果null写入缓存,那么相同的请求每次都会去请求数据库,如果有恶意请求针对不存在商品进行高频攻击,会给数据库造成瞬时高压,可能直接把数据库压垮
解决办法:
查询查不到结果,就将空结果也进行缓存,并设置一个短暂的过期时间,这样一方面是避免缓存过大,另一个方面是避免空值数据万一有了数据无法及时更新
也可以使用布隆过滤器对高频ip进行封禁
缓存雪崩
概念:设置缓存时key使用了相同的过期时间,导致缓存再某一时刻同时失效,然而此时的并发请求非常高,瞬间请求压力全部给到数据库,数据库瞬间压力过重雪崩
解决办法:在原有失效时间上添加一个短时间内的随机值【如1-5min随机】,这样每个缓存的过期时间重复率降低,从而很难发生极短时间内缓存集体失效的情况
缓存击穿
某些热点数据可能在瞬间突然被超高并发地访问,比如秒杀,但是对应的key正好在大量请求瞬间到来前已经失效,且在超高并发请求到来前没有请求再次形成缓存,那么瞬间的超高并发对同一个key对应的数据查询压力全部落在数据库上,称为缓存击穿,又比如一个接口只缓存一个数据结果,但是这个结果总会失效,失效的瞬间加入还是高并发请求【如首页商品分类数据】,此时所有并发查询压力就会直接加到数据库上
解决办法:
对重建缓存的过程加双重检查锁,对超高的瞬时并发,只让一个请求通过去重建缓存,剩下的请求都等待缓存
针对以上问题对首页商品二三级分类数据获取进一步优化
优化点
空结果缓存,解决缓存穿透问题
设置附带随机值的过期时间,解决缓存雪崩问题
给代码加锁,解决缓存击穿问题
空结果缓存
空结果缓存,没从数据库获取到数据就给对应的key放一个带过期时间的空值进去,获取到就缓存获取到的数据
缓存雪崩问题,set方法保存数据时调用重载方法,在第三个参数写随机时间长度,在第四个参数指定时间单位TimeUnit.XXX
本地锁解决缓存击穿问题
缓存穿透和缓存雪崩都好解决,缓存击穿加锁问题比较复杂,锁加不好会引发一系列问题【重点是确认缓存是否重建和将数据放入缓存是原子操作,在同一把锁内执行,否则会导致释放锁的时序问题,导致数据库被查询超过一次】
考虑单体项目加同步代码块,缓存拿不到数据进入数据库拿数据操作逻辑,为了避免过多的数据库查询造成压力,给整个数据库查询代码加锁,使用this即service容器实例作为锁,因为service实例在IoC容器中都是单实例,只要所有的锁都是同一把锁,就能锁住需要这把锁的所有线程,因此以this指向的当前service单实例可以锁住当前并发请求的所有线程,synchronized可以加到方法上也可以加到代码块上;
注意多个请求进来竞争同一把锁,只有一个拿到锁重建缓存后,其他等待锁的请求不再次检查缓存数据是否重建还会执行相同的从数据库获取数据重建缓存的操作,因此拿到锁以后需要再次检查缓存数据是否重建,如果已经重建则直接拿缓存数据直接返回且不要再执行将数据放入缓存的操作;这样的锁称为双重检查锁
但是这样还存在问题,如果只对从数据库获取数据加双重检查锁,并没有对将数据序列化存入缓存加锁,当第一个请求从数据库拿到数据后就直接释放锁,然后再去执行重建缓存的操作,此时存在网络操作,可能时间几毫秒到几十上百毫秒不等,这个期间后续拿到锁的线程同样立即尝试检查缓存是否建立,结果数据还没来得及存入缓存,后续线程获取不到数据又再次执行查询数据库操作,无法实现只锁住执行一次数据库查询操作,经过jmeter压测,确实发生了不止一次的数据库查询操作,因此要将数据存入缓存的操作也加锁,避免后续线程因为数据发起重建缓存请求到缓存重建完毕期间因为拿不到缓存再多次发起数据库查询和再次重建缓存操作
问题:这种锁使用的是当前服务的容器单实例,集群部署时一个服务一个容器,一个容器一个实例,对于整个集群来说,这个锁只对当前服务有效,相当于有几个服务就有几把锁,因为负载均衡,每个服务上都有对应的重建缓存操作,因此这种锁无法完全锁住分布式集群的重建缓存操作,但是也极大地削减了对数据库的压力,集群环境下使用这种锁【本地锁,synchronized或者JUC包下的各种锁都称为本地锁,只能锁当前服务,也叫进程锁】也是可以的,这种锁更轻量,效率更高【对性能其实影响不大,查询数据库的过程中参数竞争锁的线程只有14个甚至更少,即便我将用户数调整到了500,一般就个位数到十几个参与竞争锁,并不是所有的请求都被受理竞争锁了,因此这里也就最多十几个请求需要一个一个拿锁操作,经过测试,十几个对象竞争锁是不对的,因为是将缓存删了才用jmeter测试,jmeter刚开始并发请求少,要jmeter运行起来再删除缓存才能看到实际效果,经过实测,这里直接将tomcat能同时处理请求的最大线程数200压满了,也就意为着一个线程处理一个请求,很快啊,几个语句执行200个请求和线程就压满了,而且感觉是早就压满了200个等待拿到锁的线程执行重建缓存操作,且后续不会再有竞争锁的请求进来,意味着定死了重建缓存每个服务会有200个线程竞争锁和串行执行,对总的吞吐量影响不大,一般少个几十,仍然在1100以上,关于tomcat线程池的只是参考博客tomcat线程池-CSDN博客】,对数据库的压力削减相当明显,即便千万并发100个服务也只会产生一百次数据库查询操作,对数据库的压力削减相当可观;但是想要完全锁住集群中的所有服务必须使用分布式锁,分布式锁相较于每个服务锁服务单例性能太低,设计更重
本地锁在分布式系统下的问题
锁不住所有服务,每个服务都会执行一次数据库查询,极端情况下每个服务都会有200个请求竞争锁并串行获取缓存数据,但是对性能影响不大,使用lettuce吞吐量1180左右只会减少几十
用分布式锁解决缓存击穿问题,这部分是大头,我的分布式锁笔记做的天衣无缝,正好全部拿来吹牛逼
重点一是自己实现基于Redis的分布式锁
重点二是使用Redisson相关工具来实现高并发请求下的缓存重建
重点三是拿到分布式锁以后马上检查缓存是否建立,分布式锁还要锁数据写入缓存的过程
重点四是缓存数据一致性的问题,如何保证缓存中的数据和数据库的数据实时相同
使用
SpringCache引申出来的问题@Cacheable:Triggers cache population.触发将数据保存到缓存的操作,标注在方法上表示当前方法的结果需要缓存;而且如果方法的返回结果在缓存中有,方法都不需要调用;如果缓存中没有,就会调用被标注的方法获取缓存并将结果进行缓存缓存数据建议按照业务类型来对缓存数据进行分区,该注解的
value属性和cacheNames属性互为别名,属性的数据类型均为String[],表示可以给一个或者多个缓存组件同时放入一份被标注方法的返回值,在Redis中缓存的key为Cache自动生成的category::SimpleKey []即缓存的名字::SimpleKey [];其中的缓存数据因为使用的是JDK的序列化方式,Redis客户端直接读取出来全是二进制码,但是读取到java客户端以后被反序列化以后就可以变成正常的字符串信息,示例如下:注意啊这种方式设置的缓存,默认是不设置有效时间的,即
ttl=-1,意味着缓存永远不会过期,这大部分情况下是不可接受的key也是系统默认自己生成而不是用户指定的,我们更希望这个key能由我们自己进行指定
使用默认的JDK来序列化缓存数据,不符合互联网数据大多以json形式交互的规范,如果一个PHP架构的异构系统想要获取缓存数据如果是经过JDK序列化就可能导致和异构系统不兼容,因此我们更希望使用json格式的缓存数据
xxxxxxxxxx({"category","product"})//将该方法的返回值同时给category和product缓存组件中各放入一份public List<CategoryEntity> getAllFirstLevelCategory() {List<CategoryEntity> firstLevelCategories = baseMapper.selectList(new QueryWrapper<CategoryEntity>().eq("cat_level", 1));return firstLevelCategories;}
检索商品页面的DSL语句构建
检索考虑了哪些方面,使用到的DSL语句
使用Java High Level REST Client API动态构建DSL语句,封装请求参数、封装检索结果
面包屑导航和Thymeleaf数据渲染的前端业务
商品详情页面
数据查询模型
销售属性倒排索引,skuId列表求交集获取对应销售属性组合的商品的skuId
对6个业务操作根据业务关系使用CompletableFuture进行异步编排
用户注册
用户注册流程
用户获取验证码前对电话号码进行校验
抽取短信发送客户端和引入对短信客户端的自动配置和自定义配置,只需要调用一个实例方法就能发送短信
使用异步任务的方式来发起发送短信请求和向redis中存储验证码的任务
设计lua脚本来对验证用户发送验证码间隔和缓存验证码以及刷新用户获取验证码冷却以及保存多个同一手机号的多条验证码设计,保持高性能的同时支持一个号码所有验证码的可用性
重定向页面并对用户数据进行回显,友好且方便用户修改;对校验或者发送频率较高通过抛异常的方式进行处理和错误信息回显,自定义弹窗来提示可再次获取验证码的时间
用户注册先对所有提交数据使用JSR303进行数据校验,所有校验信息封装到
RedirectAttributes携带数据重定向到注册页面,方便用户修改异步查询默认用户等级和其他默认用户信息提升性能,
使用MP的自动填充记录配置创建字段来自动根据系统时间生成记录的创建时间字段
校验成功后对验证码进行验证,验证失败直接抛异常,验证成功异步任务删除键值对,同时远程调用user服务创建用户账号,先检查用户名和电话号码是否唯一,通过一次查询然后检查哪一项重复来节省数据库连接开销;通过抛出自定义异常的方式并通过异常状态码来判断异常原因
校验通过后等待异步任务执行完毕,封装查询结果并保存用户记录
引入短信接口后的业务流程
短信倒计时设计,首次发送验证码完整倒计时,用户点击一次获取验证码倒计时结束前不能再次点击,刷新页面点击获取验证码查询剩余间隔时间,弹窗提示剩余等待时间并从该时间进行倒计时,防止客户端刷新来尝试获取验证码,同时redis设计也防止使用工具来恶意刷获取短信的接口
alert暂停js中所有的代码执行,包括异步定时任务
setTimeout,自定义弹窗来避免阻塞异步定时任务避免倒计时卡死
POST请求处理后转发GET请求处理接口报错
转发、重定向、视图映射器、直接指定视图名称的区别
注册成功后默认重定向到登录页
重定向的写法为
return "redirect:/login.html",此前做了视图映射/login.html对应login视图,重定向的问题在于ModelAndView中的共享数据在请求域中,无法通过重定向传递给指定视图;重定向想要向视图共享数据可以使用SpringMVC提供的RedirectAttributes对象,RedirectAttributes对象通过方法redirectAttributes.addFlashAttribute("errors",errors)来将数据携带传递到重定向视图,防止表单重复提交最好的办法就是重定向视图清空表单数据重定向防表单提交的原理是重定向刷新表单内容,再次提交过不了前端数据校验,一般表单内容前端都会校验,通过前端校验但是服务器校验过不去,不是蓄意攻击就是有意为之,清空数据不过分,成功以后重定向到登录页面也不会出现表单重复提交的现象,也比较合理
重定向只能重定向到一个URI或者URL地址,不能直接重定向到一个视图
注意
return "redirect:/login.html重定向的路径是http:192.168.137.1:20000/login.html,即以当前服务所在端口作为URL的前缀,如果我们想要指定前缀需要使用如下写法return "redirect:http://auth.earlmall.com/login.html",这种重定向写法也能将RedirectAttributes对象中的数据携带过去,只要地址是我们自己的服务器地址,RedirectAttributes对象能重定向携带数据的原理是重定向时会在cookie中携带一个JSESSIONID,重定向在页面间共享数据可以给session中放数据,我们以前通过HttpSession向session中存放数据来实现跨页面共享数据,RedirectAttributes就是通过这种方式来实现的重定向携带数据,对应的重定向请求的cookie中也携带了session的唯一标识JSESSIONID,该数据共享是通过session的原理来实现共享的,重定向请求的cookie中也有对应的JSESSIONID,重定向到页面中也会从session中取出对应的数据,该数据只要取出来就会被删掉,这种数据组织方式也能实现再次刷新页面页面中对应的校验错误提示就会消失的效果但是注意在分布式系统下使用session一定会遇到分布式下的session问题,这个问题后面专门讲
return "reg"会拼接视图地址前后缀直接找到视图,return "forward:/reg.html"控制器方法中所设置的视图名称以forward:为前缀时,创建InternalResourceView视图,此时的视图名称不会被SpringMVC配置文件中所配置的视图解析器解析,而是会将前缀forward:去掉,剩余部分作为最终路径通过转发的方式实现跳转,相当于通过路径去控制器方法获取视图映射控制器去匹配路径转发到对应的视图,相比于return "reg"效果相同只是饶了一圈注意使用这种方式可能会出现
Request method 'POST' not supported的问题,这种问题通常发生在前端使用POST的方式提交表单,后端也使用POST方式来处理提交请求,但是后端处理完请求以后通过return "forward:/reg.html转发[原来的请求原封不动转给下一个请求路径接口,如果请求是POST请求,但是被转发的接口只接受GET请求,此时就会报这个错误]的方式来跳转页面,一般路径对视图的映射在控制器方法都会设置为Get方法,通过视图映射器来设置的路径视图映射也默认使用GET方式访问的,POST请求被转发到GET请求方式的路径映射接口就会出现该错误,解决办法是不使用路径映射,直接使用return "reg"直接拼接前后缀找到对应的视图
通过
Thymeleaf来从error这个Map中获取错误校验信息,在没有发生校验错误的情况下error会为null,此时仍然从error中获取错误校验信息就会出现空指针异常,只有在error不为null的情况下才去执行从error中获取对应参数的错误校验信息注意即使
Map类型的error不为null,但是Map中没有指定的属性如username,此时仍然使用error.get("username"),Thymeleaf仍然会报错,即Map不包含指定key的数据但是仍然进行取值Thymeleaf会直接报错,我们还需要通过Thymeleaf对Map处理的API#maps.containsKey(map,key)来判断Map类型的error中是否包含key为username的数据,包含才进行取值,不包含就不取值
用户登录方案
平台账号密码登录
社交账号登录注册
OAuth2协议
单点登录
单点登录原理
单点登录开源框架
session共享
分布式集群下的session跨域跨服务跨实例共享
重定向使用
RedirectAttributes通过session把数据携带到重定向后的页面后面用
SpringSession来解决这个问题,自定义RedisSerializer为JSON序列化器和CookieSerializer为第一次使用session时下发cookie的名字和作用域来实现session的跨域跨服务跨实例共享
SpringSession原理
@EnableRedisHttpSession注解背后的session操作实现原理
购物车方案
离线购物车和用户购物车设计
拦截器来统一处理识别用户的登录状态
Feign远程调用丢失请求头
Feign远程调用携带请求头和CompletableFuture异步编排情况下请求头数据在不同线程下的共享难道还不能打动面试官吗
Feign远程调用默认不携带请求头,自然无法携带cookie,那么用户的登录状态就无法通过cookie来识别,默认情况下无法让已登录用户请求去远程调用需要用户登录的接口
我们给Feign添加一个拦截器,在Feign构建请求前先将老请求的请求头中的cookie数据同步到新构建请求的请求头中
Feign对部分接口请求的拦截器放行
接口幂等性
提交订单中的接口幂等性方案
分布式系统定理
用Seata解决分布式事务,事务隔离级别之间的关系,本地事务在分布式环境下出现的问题
❓:seata目前在AT模式下不支持批量插入记录,https://blog.csdn.net/qq_33240556/article/details/140790581,反正我们后面要换成软性事务,后面再换成批量插入
用柔性事务即可靠消息加最终一致性方案来解决高并发场景下的数据一致性问题
重点是保证消息的可靠性投递
消息队列设计,订单创建、取消和解锁库存设计
分布式系统下的各种定理理解
消息可靠投递
最害怕的就是消息丢失,柔性事务可靠投递加最终一致性最重要的事情就是防止消息丢失,防消息丢失的核心就是做好消息生产者和消息消费者两端的消息确认机制,主要策略就是生产者的消息抵达确认回调和消费者的手动应答,凡是消息不能成功抵达服务端和消费端的消息都做好消息日志记录,定期扫描数据库,将发送失败的消息定期重新发送
支付宝支付业务流程
秒杀商品上架
定时任务方案
秒杀库存预热
简历项目经验
【项目经验】
项目名称 手机商城(开发日期2020.11-至今)
项目简介
一个分布式前后端分离的电商项目,采用了当今主流的系统架构和技术栈, 后端基于SpringBoot2.0,SpringCloudAlibaba,Mybatis-Plus等技术进行基础开发,前端基于Vue组件化,Thymeleaf模板引擎进行开发。
Gitee地址: https://gitee.com/AdverseQ/gulimall_Advanced.git
技术栈 Springboot,SpringCloudAlibaba,Mybatis-Plus,MySQL,Redis,ElasticSearch,Nginx,Swagger2,VUE 项目描述 手机商城后端分为商城后台管理系统和商城本体,共由13个微服务组成,后台系统可以实现品牌管理,商品属性管理,商品发布与上架,商品库存管理等功能,商城本体可以实现商品信息查询,购物车等功能。
使用nacos作为注册中心与配置中心,可以感知各个微服务的位置,同时将各个配置上传至网上,实现源码与配置的分离。 借助nginx负载均衡到网关,搭建域名访问环境。
微服务之间使用Fegin进行远程调用, Redis作为中间件提升系统性能。 使用Seata解决分布式事务问题,对于高并发业务,使用RabbitMQ做可靠消息保证最终事务一致性。 每个微服务整合Swagger2,方便接口进行测试和生成接口文档。 项目中图片上传使用阿里云对象存储技术,所有图片存储在阿里云创建的bucket中。 商品检索使用全文索引技术ElasticSearch。 实现了Oauth2微博社交登录,单点登录,短信验证码等功能。
主要职责 全栈开发
分布式基础要点
构建分布式基础服务
微服务
注册中心
感知服务位置,服务状态
配置中心
目的是不需要修改项目的源代码文件再打包部署,而是直接通过配置中心的配置文件线上修改或者远程修改远程推送来实现动态的更改服务配置
OpenFeign远程调用
使用OpenFeign需要服务注册到注册中心,并使用
@EnableFeignClient开启了远程服务调用功能注冊服务还需要使用
@EnableDiscoveryClient注解开启服务的发现功能编写接口指定调用服务的接口、参数、响应数据类型,注意响应回来的实体类可能本服务中没有,但是此时可以使用Map来接收,只要能封装SpringBoot就会自动进行参数处理,而不一定需要使用被调用方特定的类型【比如原服务封装成特有的实体类存入响应的类型中,此时调用方没有该实体类,但是对json对象可以使用Map进行接收】
GateWay网关
网关统一对跨域问题进行处理,
对路由地址进行真实控制器地址重写,对所有单个服务的地址进行精确匹配,不能精确匹配的请求路由到renren-fast后台服务模块
基础开发
SpringBoot2
基于Spring5引入了Reactor反应式编程,带来web开发中的WebFlux,易于创建高性能高并发的web应用,此前基础篇唯一用到WebFlux的地方是跨域配置CorsWebFilter用到了WebFlux编程模式,该对象的filter方法返回了一个Mono对象
Springcloud
基础篇用到了Springcloud的服务注册发现功能、使用Feign的远程调用、配置中心
Mybatis Plus
配置Mapper包扫描
@MapperScan,打印sql语句、逐渐自增、逻辑删除、分页查询工具封装、单体事务、字段自动填充
Vue组件化
vue的基础知识,相较于谷粒学院扩展了组件化的概念
阿里云对象存储
对照第三方接口文档开发使用第三方服务
服务端签名直传,谷粒学院是自己的服务器执行文件上传服务,这样的方式在高并发的情况下不好
环境
Vagrant【快捷地一行命令启动一台虚拟机,相比于VMWare更快捷方便】、Linux、Docker、Mysql、Redis、renren开源的三个项目整合【关键是renren开源的逆向工程renren-generator,直接生成包括基础增删改查的控制器方法以及必要组件,包括带条件分页查询的功能和对应的前端增删改查的vue基础组件,在Controller、Service、Dao、Entity甚至前端基础vue页面层都能极大地减少工作量】
开发规范
JSR303数据校验、全局异常处理、全局的异常处理、全局统一返回、全局跨域处理、项目固定业务状态、
项目响应状态码使用枚举进行规范
使用VO、TO、PO对数据传输进行规范
Lombok提供的@Data提供Setter和Getter,Lombok的@Slf4j提供的log对象来对日志信息进行处理
附录
服务熔断和降级的意义
服务调用链路上的后续服务完全宕机或者网络连接不可靠,比如商品服务调用库存服务,库存服务一旦发生意外,商品服务就需要进行等待,在高并发的情况下由于不停地超时等待,导致商品服务器的资源紧张,可能导致商品服务器也会宕机,从而导致整个调用链路上的宕机发生血崩效应
降级运行可以让非核心服务不进行处理或者简单处理,比如扣减库存,物流系统暂时不进行数据库操作,减少数据库IO操作,可以将信息发送到消息队列中后续流量降下来以后再进行处理
网关
可以对所有请求进行统一认证,还可以提供服务熔断、限流【高并发情况下控制请求以恒定的速率流向上游服务器】、负载均衡、灰度发布、统一认证
VirtualBox
安装需要开启CPU虚拟化,要在bios中设置;如果要查看自己电脑是否开启虚拟化,可以点击任务管理器,然后点击性能,有个虚拟化,已启动表示已经打开了,不用重启了
vagrant用户创建的虚拟机的root用户的密码也是vagrant
Docker一个容器中的系统文件出了问题不会影响到其他容器
Docker分为Docker EE和Docker CE两个版本,CE是社区版,免费开源的;EE企业版,是收费的,个人一般使用CE就够了
docker exec -it redis redis-cli可以跳过容器的bash命令客户端直接进入redis的客户端redis有可视化客户端RedisDesktopManager
docker拉取镜像需要使用超级管理员权限
docker logs elasticsearch:7.4.2能够打印容器的相关日志,其中elasticsearch:7.4.2是容器名docker start 容器id前几位也能启动容器,id不需要完成输入docker容器的名字不允许含有冒号
软件PowerDesigner是数据库设计软件
可以打开对数据库和表设计的文件,每个表每个字段如何设计都可以通过打开pdm文件查看
人人开源下的项目
人人开源是码云上的一个组织,旗下有很多开源项目仓库
renren-fast和renren-fast-vue配合构成一个前后端分离的后台管理系统,renren-security也是后台管理系统,但是不是前后端分离项目,是将前后端写在一起使用模板引擎FreeMarker将前后端写在一个工程中人人开源项目下的.git文件看不到是因为设置了文件隐藏,因为开启我的桌面不太好看,删除人人开源项目原本的.git文件需要勾选显示隐藏文件
renren-fast:Java后台管理系统
renren-fast-vue: vue、element-ui实现的后台管理系统的前端工程
renren-security:前后端不分离的后台管理系统
renren-generator:人人开源项目的代码生成器,在线生成后端代码甚至前端组件,避免写基础的单表增删改查、重点关注高并发高可用和分布式架构,能直接把单表的分页查询等其他操作的整个接口都直接生成,连控制器方法都不用写;该代码生成器生成的接口的uri格式是
/模块名/表名/接口功能名renren-fast-adminlte:不使用vue和element-ui等组件,直接拿Html和一些前端框架开发的
shiro的@RequiresPermissions注解会配合SpringSecurity使用,后期会使用,使用代码生成器的时候先注释,不要直接删除,后面会用,前期为了在不整合SpringSecurity的情况下不报错先注释
mysql数据库对于5.7*版本驱动选择5.1或者8.0版本的都行,这两个版本是全适配的,官方推荐驱动8.0版本,这里使用的是8.0.17版本
mysql数据库的基字符集选择utf8mb4,该字符集能够兼容utf-8且能解决一些字符乱码的问题,而且在mysql8中创建的数据库在mysql5中一样能使用
navicat在数据库添加查询,使用命令
select version()能查看mysql的具体版本R表示ResultEntity
纯前端使用ajax访问本地文件出现跨域问题的,必须用live server 插件访问页面,直接访问html使用ftp不能请求到,不清楚原因,前端知识,经过测试确实使用live server开启就正常了,ajax访问本地文件使用浏览器直接打开会报跨域错误
浏览器Network中的No throtting可以选择模拟不同网速下的页面展示效果,比如数据加载比较慢,前端页面的展示效果
在pojo类中添加数据库中没有的字段需要对该属性用
@TableField(exist=false)标注,表示该属性不在数据库中,一般这样的属性用来做多级子类封装更加规范的做法是新建一个vo类专门来封装产品信息,在该vo类中定义多级子分类属性
浏览器的Network中请求的preview能直观地看到返回数据结构
响应信息
Connection refused:...是服务才启动还没有稳定的意思postman的body中的raw可以发送json数据,模拟前端请求体中提交的对象数据;x-www-form-urlencoded是表单数据
RequestBody中的json数组使用Postman发送
JS中的常用API
对数组遍历
xxxxxxxxxx//childNodes获取的是node对象中的childNodes属性,是一个数组var childNodes = node.childNodes;//对子节点对象数组进行遍历,判断节点对象的expanded属性是否为true,为true表示该子节点展开for (var i in childNodes) {if (childNodes[i].expanded == true) {//展开的子节点从默认展开节点列表数组中移除this.expandKey = this.expandKey.filter(function (item) {return item !== childNodes[i].data.catId;});}}数组追加元素
xxxxxxxxxx//this.expandKey是一个数组,data.catId是额外的一个要追加的元素this.expandKey = [this.expandKey, data.catId];//数组的push方法向数组的末尾追加一个元素this.updateNodes.push({catId:1,sort:0})数组移除指定元素
xxxxxxxxxx//从数组this.expandKey中移除childNodes[i].data.catId元素this.expandKey = this.expandKey.filter(function (item) {return item !== childNodes[i].data.catId;});拷贝一个对象的属性创建一个全新的对象
拷贝常量INITCATEGORY的属性和空对象合并成全新的对象并赋值给category,直接使用等号是把引用地址赋值给category,对category修改就会对INITCATEGORY产生修改,但是某些情况下我们更希望INITCATEGORY是常量或者初始值
xxxxxxxxxxthis.category = Object.assign({}, INITCATEGORY)
双向绑定的双引号里面可以直接写js代码,且对vue中的数据引用只需要属性名,不再需要添加this,里面调用的方法返回的是方法的返回值,不是触发事件
JS中的
||的短路性:前一个值为真,整体为真,就不去计算后一个值了,直接返回前一个值真假判别标准
对象为真,null、undefined 为假;
非空字符串为真,空字符串为假;
非零为真,零、NaN 为假;
比如
a||0:如果a是undefined判断为假,会继续判后面的0为假,整体返回0【确认就是返回0,不是布尔值】;如果第一个有值且非0,就直接返回第一个值
关闭ESLint的语法检查功能,ESLint的语法检查太严格
关闭方法
在
build\webpack.base.conf.js文件中的createLintingRule方法中的检查规则全部注释掉并重启项目
文件存储服务器可以自己搭建【使用FastDFS、vsftpd搭建】
mini似乎也很好用,尝试用nginx搭建一台文件服务器
element-ui组件的消息确认框可以通过配置
dangerouslyUseHTMLString: true把字符串渲染成html实例
xxxxxxxxxxthis.$confirm(`<b>将删除以下商品分类, 是否继续?</b><br> ${msg}`,"提示",{confirmButtonText: "确定",cancelButtonText: "取消",type: "warning",dangerouslyUseHTMLString: true}).then(() => {}).catch(() => {});
RAM【Resource Access Managment】是阿里云用来做资源权限访问控制的产品,通过主账号--AccessKey进行对RAM的控制台进行访问
VScode选中方法名快捷键ctrl+f会跳转对应的方法
v-model.number=ruleForm.age会自动将ruleForm中的字符串属性转换成数字,Number.isInteger(value)是判断value必须是一个整数的写法正则表达式.test(value)可以对数据进行格式验证,返回布尔类型
日志通过
@slf4j注解进行打印SpringBoot中以Json格式写数据需要标注
@ResponseBody注解配置文件中的中文会被读取为乱码,但是点开文件属性查看编码方式为UTF-8,需要将IDEA的Setting--Editor--File Encodings中的Project Encoding设置为UTF-8【主要问题不是这个,见下方文档,以后总结】,IDEA的默认设置是系统语言设置GBK【这是IDEA解决Properties文件中文读取乱码的问题的统一解决方案】
直接在实体类中通过添加属性并标注
@TableField(exist=false)来封装请求参数这种方式不规范,规范的方式是创建一个vo包,Spring提供的工具类
BeanUtils.copyProperties(Object source,Object target)可以将属性值从一个对象拷贝到另一个对象,前提是属性名在两个对象中是一一对应的copyProperties和mapStruct都是浅拷贝
String的API
字符串的
"str".equalsIgnoreCase(str)是无视大小写比较str的字面值是否为strString.join(",",descript)将集合descript中的元素使用分隔符逗号拼接成字符串
开发规范
Controller负责处理请求,接收和校验请求数据;最后接收Service处理完的数据,将数据封装成页面需要的指定VO
Service负责接收Controller传递来的数据进行业务处理
Service中调用别的业务方法最好直接注入对应的service,不要直接注入Dao,因为Dao是MP自带的,业务方法不丰富且不支持自定义,所以直接注入service即可
注意在流式操作foreach判断并使用lambda表达式对变量赋值操作使无法实现的,这时候需要老老实实使用集合的foreach变量来进行赋值,因为lambda表达式会把代码块写在一个动态生成类中以静态方法的形式存在,进行流式操作的类无法将局部变量传递给动态生成类,除非有类似于ThreadLocal之类的全局大Map
在
Edit Configuration中可以选择新增Compoud,添加每个应用到当前的组,以后以组为单位一键启动组内应用在应用的运行设置详情界面的Configuration选项卡下,Environment菜单中的
VM oprions添加配置-Xmx100m能设置每个应用运行的堆内存上限,这样能节省IDEA项目的运行内存占用
BigDecimal比较大小的写法是memberPriceEntity.getMemberPrice().compareTo(new BigDecimal(0))==1,其中memberPriceEntity.getMemberPrice()是BigDecimal类型的数据,compareTo(new BigDecimal(0))是和值为0的BigDecimal相比,compareTo是BigDecimal的实例方法返回-1是小于,返回0是等于,返回1是大于指定的BigDecimalStringUtils.isNotBlank(key),isNotBlank: 不能为 null,且必须有实际字符(不能为空字符),
易文档,可以用来写接口文档
list().stream().collect(Collectors.toMap(SkuHasStockVo.getSkuId,item->item.getHasStock()))是将SkuHasStockVo.getSkuId作为key,将item.getHasStock()作为value将list转换成一个Map一定注意
@PathVariable注解接收请求路径的参数,注意区分一下@RequestParam和@RequestBody以及@PathVariable的区别调试调用远程服务一般都会超时抛服务调用超时异常,调试结束后需要取消远程服务的断点
mysql数据库可以使用
show profiles;来查看sql的执行时间【duration字段默认单位是秒】,具体用法参考查看mysql语句运行时间 - smily要开心 - 博客园 (cnblogs.com)使用SewitchHostsl软件能打开直接编辑本地的hosts文件,要用管理员身份打开
nginx是被F5收购了
弹幕说向服务器上传文件建议使用finalshell或者mobaxterm
连接redis查看数据弹幕说还可以使用
another redis弹幕提到frp内网穿透,了解一下
了解一下工具Arthas,据弹幕说什么都能调
关注一下系统时间api
System.nanoTime(),看能不能搞出纳秒精度的运行时间,以后都用这个API来计算程序运行时间,老师的演示时间是可以精确到ns的typora里面还能写
SequenceDiagram时序图,卧槽,查了一下还能画流程图、时序图、顺序图、甘特图、饼状图等图,具体看链接深入了解一下,语言类型是mermaid卧槽,IDEA的debug还可以改变量的值
注意BigDecimal中有一些数字常数可以直接拿来用,BigDecimal在构建对象的时候必须传递字符串
new BigDecimal("10000")才能保证精度,使用小数仍然会有精度问题TimeUnit是JDK5以后提供的一个功能,可以将时间在多个时间单位间进行一个转换,可以把毫秒、秒转换成纳秒,TimeUnit中的实例方法
timeUnit.toNanos(timeout)是将long类型的ms时间转换成纳秒时间内部类能够访问外部类的成员变量吗?【直接通过成员变量的变量名访问,根本不需要带类名或者对象,就像在本类中定义的成员变量一样】
广义的内部类一共有四种:成员内部类、局部内部类、静态内部类和匿名内部类
其中静态内部类只能访问外部类静态的方法和属性
其余的内部类可以访问所有外部类的成员比那辆和方法
静态内部类不依赖于外部类存在,其他内部类可以像在本类中一样访问外部类的成员变量和方法是因为内部类对象依赖于外部类对象的存在,创建内部类对象前需要先创建外部类对象实例,此时因为内部类持有了外部类的引用,因此可以内部类可以自动通过外部类的引用来识别使用的外部类的成员变量和方法,静态内部类因为不依赖于外部类存在,因此没有这种必须先获取外部类实例对象的机制来保证获取到外部类的成员变量和方法
反过来因为外部类创建对象实例后内部类不一定实例化,因此不能保证外部类能在任何情况下都能成功访问到内部类的成员变量和方法,必须通过先创建内部类的对象再通过内部类对象访问其中的属性和方法
Fork/Join怎么结合Stream流来做任务拆分留意一下
SpringBoot可以通过
@Value注解获取到配置文件的值xxxxxxxxxx(${coupon.user.name})private String username;关注一下
SpEL表达式弹幕提了一下缓存的延迟双删,了解一下
关注一下ERP系统的开源项目
https://ofbiz.apache.org/官方文档:
https://ofbiz.apache.org/business-users.html官网在线Demo页面:
https://ofbiz.apache.org/ofbiz-demos.html
https://github.com/himool/HimoolERPhttps://github.com/frappe/erpnexthttps://www.odoo.com/zh_CN关注
华夏ERP关注一下南京墨博云舟开发的CRM系统
关注ERP厂商:SAP、Oracle、用友、金蝶、浪潮
关注COS和OSS,两者似乎都可以用于静态资源的网络存储
这个项目有大佬在
Gitee上前端用vue重构了,可以拿来学习一下@RestController包含@ResponseBody注解,使用了@RestController注解就不能再跳转静态页面了通过软件迅捷录屏大师我们可以把手机画面投屏到电脑上
网站
online.visual-paradigm.com/w/vzcpnizk/diagrams/可以绘制几个对象之间的先后操作流程图了解一下
Spring解码器弹幕说
EnableWebSession是整合Reactive的,了解一下关注权限相关的框架
SpringSecurity和shiro注意前端的
src和href属性如果写成src="/static/cart/js/jquery-3.1.1.min.js"就是整个覆盖URI部分即http://cart.earlmall.com/static/cart/js/jquery-3.1.1.min.js,如果写成src="static/cart/js/jquery-3.1.1.min.js"就是http://cart.earlmall.com/goods/static/cart/js/jquery-3.1.1.min.js,此时地址栏请求http://cart.earlmall.com/goods/add,即只会丢掉最后一个add,注意src="./static/cart/js/jquery-3.1.1.min.js"和src="static/cart/js/jquery-3.1.1.min.js的效果是一样的RedirectAttribute在使用重定向页面跳转下的行为redirectAttribute.addFlashAttribute():将数据放在session中,可以在重定向后的页面取出来,但是只能取一次redirectAttribute.addAttribute():将数据拼接在重定向地址URL后面
公网地址直接访问IP不带端口默认是访问80端口
yum remove docker*是移除docker的一切systemctl enable docker --now是设置docker开机启动且立即启动SpringBoot的测试类必须和项目的主启动类的包名相同,否则会报错
java.lang.IllegalStateException: Unable to find a @SpringBootConfiguration, you need to use @ContextConfiguration or @SpringBootTest(classes=...) with your test,而且SpringBoot会将包名与主启动类不同的测试类作为独立的测试类,此时该测试类对应独立的IoC容器,意味着我们无法再该测试类中注入当前Spring容器中的组件,只需要把测试类的包名和主启动类的包名改成一致即可注意IDEA会占用本机的9000端口
关注一下wsl,听说是类似于VMWare的虚拟机,目前还知道VirtualBox
solidity和区块链相关,有空看一下
前端以表单形式发起的post请求不要在接收参数前面添加
@RequestBody注解,会报错,该注解只能在前端传参为一个json对象的时候使用,表单提交的数据在请求体中仍然以addrId=1&token=825eccd7ffec46fc9585e94c67e440db&totalPrice=77692的形式提交的,后端接收不需要加任何注解,会自动根据接收对象的属性名进行匹配xxxxxxxxxx/*** @param orderParam* @return {@link String }* @描述 创建用户订单* @author Earl* @version 1.0.0* @创建日期 2024/11/30* @since 1.0.0*/("/order/submit")public String createOrder(OrderSubmitParamVo orderParam){System.out.println(orderParam);PayVo pay = orderWebService.createOrder(orderParam);return "pay";}错误提示组件
<span style="border-radius: 5px;margin: 10px 0;padding: 2px;background-color: #f2dede;color: #a94442;border: 1px solid #ebccd1;" th:if="${error!=null}" th:text="${error}">填写并核对订单信息</span>MP的list方法查询多条某个字段等于某个集合中的元素的检索条件千万别用list(new QueryWrapper<xxxEntity>().eq("字段名",集合)),会导致什么都查不出来,需要使用list(new QueryWrapper<xxxEntity>().in("字段名",集合))把当前计算机的时间手动设置到某个时间,前端后端的程序获取到的时间就是被手动设置后的时间