# Linux
Author:Earl
🔎该文档梳理Linux系统下的常用组件安装和设置、Linux常用命令、Linux常用应用和对应的快捷键操作,以下的演示均在CentOS7.6 mini版中进行实现
last update | 2023-12-29
# 软件安装
需要远程访问的应用端口需要设置安全组,即打开对应的端口
# 安装jdk
# 安装步骤
window的dev/linux下拿jdk1.8.0_261的安装包
mkdir /opt/jdk创建jdk目录,通过xftp6将压缩文件安装包上传到opt/jdk目录下【这种压缩文件被linux称为介质】cd /opt/jdk进入opt/jdk目录,tar -zxvf jdk-8u261-linux-x64.tar.gz解压压缩包到当前目录mkdir /usr/local/java在usr/local目录下创建java目录,mv /opt/jdk/jdk1.8.0_261 /usr/local/java将解压目录移动到/usr/local/java目录下作为安装目录vim /etc/profile进行linux系统java环境变量配置,shift+g来到文件最后,按o开启下一行编辑,在文件最外层添加以下配置,注意要加classpath并配置当前目录为类路径export JAVA_HOME=/usr/local/java/jdk1.8.0_261 export JRE_HOME=$JAVA_HOME/jre export CLASSPATH=.:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib export PATH=$JAVA_HOME/bin:$PATH:$JRE_HOME/bin1
2
3
4source /etc/profile让新的环境变量生效
# 安装成功测试
- 任意找一个目录编写一个java文件,在当前目录用java和javac跑一下,控制台输出目标文字即安装成功
java -version出现版本也行
# 安装Vim
# 安装步骤
vim的运行需要以下四个文件,使用
rpm -qa |grep vim可以查出来哪些有了那些没有[root@localhost /]# rpm -qa |grep vim vim-enhanced-7.4.629-8.el7_9.x86_64 vim-common-7.4.629-8.el7_9.x86_64 vim-minimal-7.4.629-8.el7_9.x86_64 vim-filesystem-7.4.629-8.el7_9.x86_641
2
3
4
5没有的使用如
yum -y install vim-enhanced对指定文件进行安装,直到四个文件都出现如果一个文件都没有,可以使用
yum -y install vim*安装所有
# 安装成功测试
- vim一个文件,能正常打开就安装成功了
# 安装Canal
Canal的运行需要linux下的jdk环境
注意,canal运行没有端口号,与外界的通讯需要通过数据库端口3306,防火墙需要放开3306端口
# 安装步骤
github下载地址:https://github.com/alibaba/canal/releases ,本项目用的1.1.4.tar.gz,输入canal1.1.4.tar.gz (opens new window)浏览器输入地址自动下载
把压缩文件上传到linux中,可以直接上传到/usr/local/canal目录,也可以上传到opt/canal目录下使用
cp canal.deployer-1.1.4.tar.gz /usr/local/canal将压缩包拷贝到/usr/local/canal目录下tar zxvf canal.deployer-1.1.4.tar.gz解压压缩文件,解压就能用,可以直接考虑在usr/local/canal目录下解压压缩包vi conf/example/instance.properties修改canal配置文件instance.properties修改成自己的数据库信息
#需要改成自己的数据库信息,linux数据库的ip【已确认】和端口号,本机可以写127.0.0.1 canal.instance.master.address=192.168.44.132:3306 #需要改成自己的数据库用户名与密码 canal.instance.dbUsername=canal canal.instance.dbPassword=canal #需要改成同步的数据库表的规则,例如只是同步一下表,比如指定哪个表进行匹配,使用perl正则表达式进行正则匹配 #canal.instance.filter.regex=.*\\..* canal.instance.filter.regex=guli_ucenter.ucenter_member #多个正则之间以逗号(,)分隔,转义符需要双斜杠(\\) #常见例子: #1. 匹配所有数据库的所有表: .* or .*\\..* #2. 匹配canal数据库下所有表: canal\\..* #3. canal数据库下的以canal打头的表: canal\\.canal.* #4. canal数据库下的一张表【具体库具体表】: canal.test1 #5. 多个规则组合使用: canal\\..*,mysql.test1,mysql.test2 (逗号分隔) #注意:此过滤条件只针对row模式的数据有效(ps. mixed/statement因为不解析sql,所以无法准确提取tableName进行过滤)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16进入bin目录下
sh bin/startup.sh启动【canal的bin目录下有启动脚本startup.sh】- 关闭有
stop.sh脚本 grep canal查看canal的进程
- 关闭有
# 安装成功测试
- 运行canal后,
ps -ef |grep canal查看canal的进程 - 通过本机数据库工具如Navicat能够远程连接上对应的linux上的数据库,就说明安装且使用成功了,用户名和密码使用linux上canal的用户名和密码
# 安装Maven
maven3的历史版本在Maven – Download Apache Maven (opens new window)的Other Releases目录下点击 Maven 3 archives (opens new window)可以进行访问
# 安装步骤
上传介质到/opt/maven目录,使用命令
cp apache-maven-3.6.3-bin.tar.gz /usr/local/maven/apache-maven-3.6.3-bin.tar.gz将介质复制一份到/usr/local/maven目录apache-maven-3.6.3-src.tar.gz是源码文件,不是maven软件
软件是apache-maven-3.6.3-bin.tar.gz
使用命令
tar -zxvf apache-maven-3.6.3-bin.tar.gz解压介质使用命令
vim /etc/profile修改环境变量,修改后使用命令source /etc/profile让文件立即生效export MAVEN_HOME=/usr/local/maven export PATH=$PATH:$MAVEN_HOME/bin1
2
# 安装成功测试
mvn -v可以显示maven版本号
# 安装Git
- 使用命令
yum -y install git即可完成安装
# 安装Docker
参考文档:https://help.aliyun.com/document_detail/60742.html?spm=a2c4g.11174283.6.548.24c14541ssYFIZ
# 安装步骤
使用命令
yum install -y yum-utils device-mapper-persistent-data lvm2安装一些必要的系统工具使用命令
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo安装一些必要的系统工具使用命令
yum makecache fast和命令yum -y install docker-ce更新并安装Docker-CE使用命令
service docker start开启Docker服务
# 安装成功测试
- 使用命令
docker -v显示docker版本信息即安装成功
# 安装Jenkins
Jenkins有很多安装方式,最方便的是使用war包进行安装,war包就是一个web项目,通过浏览器能进行访问,war包放在tomcat中能直接运行
最新版本的Jenkins不支持java8了要注意
下载地址:步骤:官网--download--stable--Past Releases 进去选择对应版本的war包就能下载
# 安装步骤
下载Jenkins的war包传到/usr/local/jenkins
使用命令
nohup java -jar /usr/local/jenkins/jenkins.war >/usr/local/jenkins/jenkins.out &直接启动java -jar /usr/local/jenkins/jenkins.war是命令的核心部分,war包目录要和命令一致/usr/local/jenkins/jenkins.out是日志输出的目录和日志名称,日志输出到jenkins.out文件nohup是命令前缀,表示后台静默启动,前台不会看见日志,日志会被输出到日志文件中&是命令后缀,表示该进程是守护线程这种方式启动后最后会提示忽略输入重定向错误到标准输出端,就是控制台不输出日志,然后再点击一次回车才能成功启动
# 安装成功测试
- 访问http://ip:8080能够成功访问Jenkins页面【ip为linux系统的ip地址】,需要放开8080端口的防火墙通讯
# 安装Zookeeper
Zookeeper分为单击版安装和集群版安装,安装前置条件是安装了JDK
# 单机版安装
注意:dataDir=/tmp/zookeeper意思是快照数据会存在/tmp/zookeeper目录下,不要使用/tmp目录存储数据,因为/tmp目录存储的临时数据,会定时清空数据,需要自定义目录,这里的/tmp/zookeeper只是示例,通常会在Zookeeper的安装目录下创建zkData目录存储数据
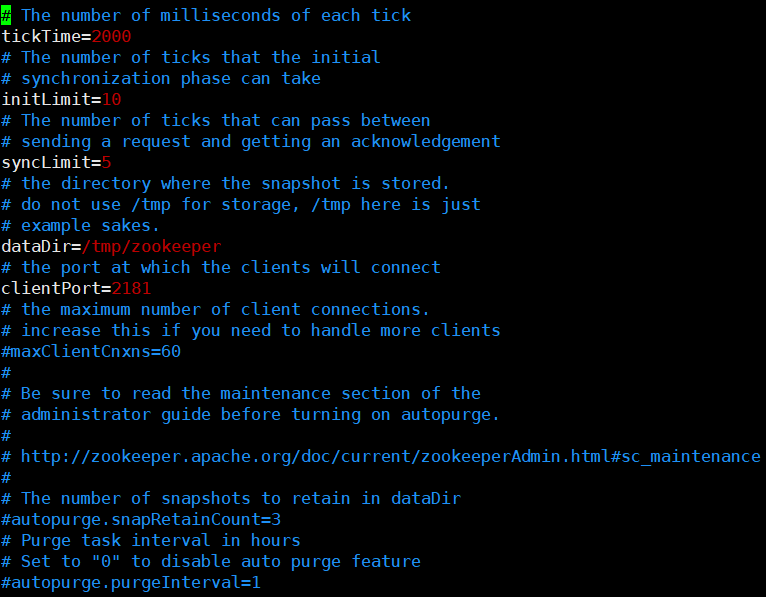
# 配置文件参数
配置文件是zoo.cfg
tickTime=2000【通信心跳时间】- 配置通信心跳时间为2000ms,该心跳客户端与服务端间可以互相发送,服务端与服务端间也可以互相发送
initLimit=10【LF初始通信时限】
- Leader和Follower建立初始连接时能容忍的最大心跳数,如果10个心跳时间内还没有成功建立Leader和Follower之间的连接,就认为本次初始通信失败
syncLimit=5【LF同步通信时限】
- 初始化通信给的时间长一些,后续通信如果超过5个心跳还没有建立连接,Leader认为Follower服务器已经挂了,会从服务器列表中删除Follower
dataDir【Zookeeper数据保持路径】
- 默认的tmp目录,容易被Linux系统定期删除,一般都要自定义目录
clientPort=2181【客户端连接服务端的端口】
- 客户端通过端口2181与服务器通讯,这个通常不做修改,就使用默认的
# 安装步骤
- 将安装包拷贝到/opt/zookeeper目录下
- 使用命令
tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz -C /usr/local/zookeeper将压缩包解压到指定目录/usr/local/zookeeper - 使用命令
mv apache-zookeeper-3.5.7-bin/ zookeeper-3.5.7将解压文件名更改为zookeeper-3.5.7 - 进入conf目录,使用命令
mv zoo_sample.cfg zoo.cfg将文件名改为zoo.cfg【不清楚这一步什么意思】 - 在/usr/local/zookeeper/目录下创建目录zkData用于存放Zookeeper的数据快照
- 使用命令
vim zoo.cfg将dataDir=/tmp/zookeeper配置成zkData所在的目录
# 安装成功测试
Zookeeper中既有服务端,又有客户端
- 使用命令
bin/zkServer.sh start启动Zookeeper服务端- 注意:当Zookeeper集群超过半数宕机Zookeeper不可用,启动集群需要启动一半以上的服务器zookeeper才能正常访问【单机版不用考虑这个问题】
- 使用命令
jps查看Zookeeper进程,使用jps -l查看Zookeeper进程的全限定类名【jps:java虚拟机会讲】 - 使用命令
bin/zkCli.sh启动并进入Zookeeper客户端,注意这个不能加start- 【ls在Zookeeper下也能使用】
- 退出zookeeper客户端命令,quit
- 使用命令
bin/zkServer.sh stop停止Zookeeper服务
# 集群版安装
Zookeeper集群最少是3台,
# 安装步骤
# 安装成功测试
# 安装RabbitMQ
官网:https://www.rabbitmq.com/download.html
RabbitMQ的运行需要Erlang语言的运行环境,RabbitMQ用的最多的是linux系统的,RabbitMQ的版本需要对应linux系统的版本,使用命令
uname -a查看当前linux系统的版本。el7表示linux7
# 安装步骤
将以下文件上传至
/opt/rabbitmq目录下![]()
将以下两个文件移动到/usr/local/rabbitmq目录下
![]()
使用以下命令安装对应软件
使用命令
rpm -ivh erlang-21.3-1.el7.x86_64.rpm安装erlang环境【i表示安装,v表示显示安装进度】使用命令
yum install socat -y【安装rabbitmq需要安装rabbitmq的依赖包socat】yum命令需要去互联网联网下载安装包
使用命令
rpm -ivh rabbitmq-server-3.8.8-1.el7.noarch.rpm安装rabbitmq


# 安装成功测试
使用命令
chkconfig rabbitmq-server on设置rab bitmq服务开机启动使用命令
/sbin/service rabbitmq-server start手动启动rabbitmq服务使用命令
/sbin/service rabbitmq-server status查看rabbitmq服务状态【如果服务是启动状态active会显示running,正在启动会显示activing,inactive表示服务已经关闭】使用命令
/sbin/service rabbitmq-server stop停止rabbitmq服务在rabbitmq服务关闭的状态下使用命令
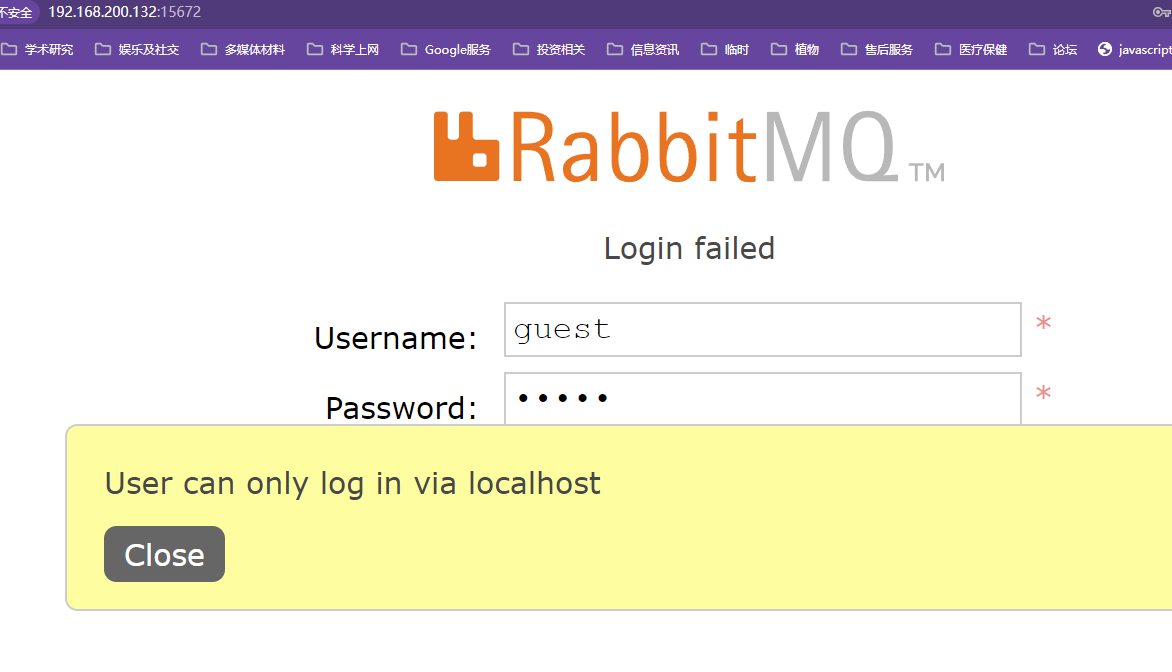
rabbitmq-plugins enable rabbitmq_management安装rabbitmq的web管理插件【执行了该命令才能通过浏览器输入地址http://主机地址:rabbitmq端口号15672访问rabbitmq,访问rabbitmq需要开启防火墙端口通讯】初始账号和密码默认都是guest,第一次登录会显示没有用户只能通过本地登录,此时需要添加一个账户进行远程登录
【开放rabbitmq防火墙端口通讯】
![]()
【web控制台】
![]()
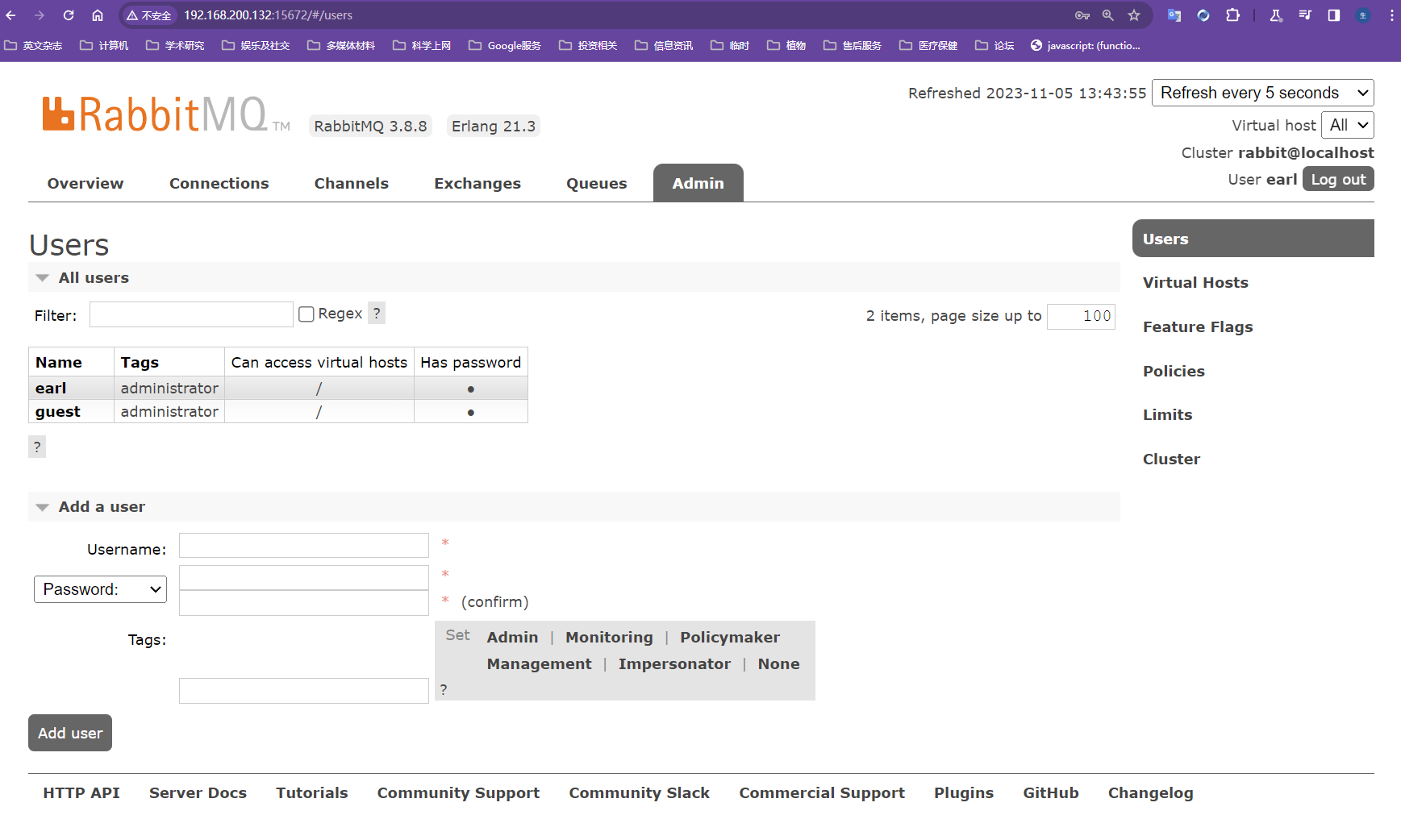
添加用户并设置超级管理员权限以登录web控制台
使用命令
rabbitmqctl add_user earl 123456创建账户,账户名earl,密码123456使用命令
rabbitmqctl set_user_tags earl administrator设置用户earl的角色为超级管理员使用命令
rabbitmqctl set_permissions -p "/" earl ".*" ".*" ".*"设置用户权限[-p <vhostpath>] <user> <conf> <write> <read>;-p<vhostpath>表示设置vhost的路径,conf表示可以配置哪些资源,user表示用户,write表示写权限、read表示读权限上个命令的意思表示对于用户earl设置具有对/vhost1这个virtual host中的所有资源的配置、写、读权限;每个vhost代表一个库,不同vhost中的交换机和队列是不同的
guest访问不了就是因为没有设置"/"vhost的路径
使用命令
rabbitmqctl list_users查看当前rabbitmq server有哪些用户
【MQ的后台管理界面】
admin路由中就可以显示增删改用户
![]()
# 安装解决延迟队列缺陷的插件
安装RabbitMQ插件解决延迟队列缺陷
官网下载插件rabbitmq_delayed_message_exchange,放在RabbitMQ的插件目录
/usr/lib/rabbitmq/lib/rabbitmq_server-3.8.8/plugins这个插件不会实时更新,一直会维持放进去时候的情况
![]()
执行命令
让插件生效并使用命令systemctl restart rabbitmq-server重启RabbitMQ安装不需要写插件的版本号
弄好之后在前端控制台的exchange列表中点击添加交换机多出来一个
x-delayed-message类型的交换机,同时也意味着延迟消息不由队列控制,由交换机来控制![]()

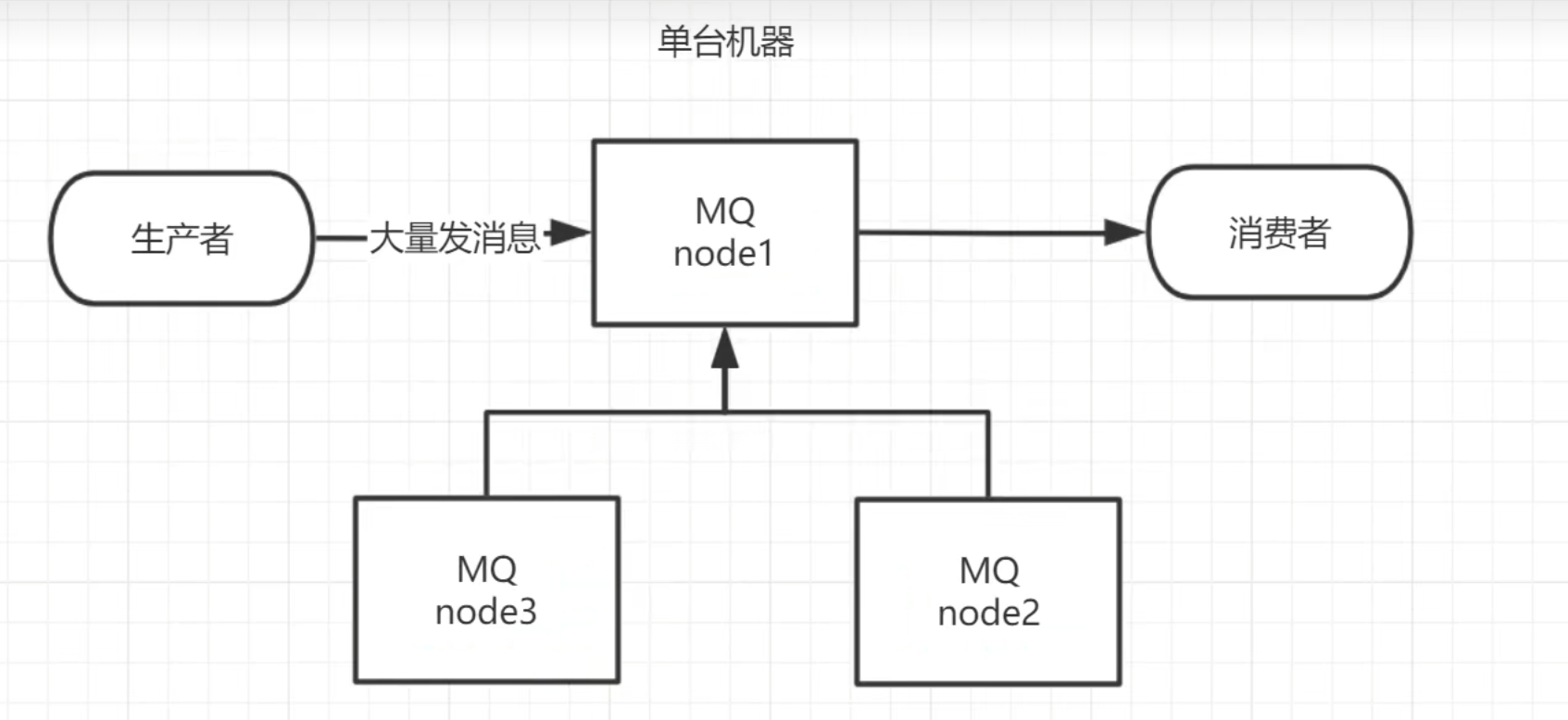
# RabbitMQ集群搭建
添加其他RabbitMQ服务器,将其加入1号节点服务器就可以形成集群,比如2加入1号,4加入2号和4加入1号效果是一样的,类似于redis集群
集群架构
添加两台新机器,都加入RabbitMQ节点1号
![]()
集群搭建实操
将当前机器克隆三份并修改三台机器的ip地址,不要使其冲突【电脑好,扛得住】,使用xshell对三台机器进行远程连接
使用命令
vim /etc/hostname修改3台机器的主机名称为目标名称node1、node2、node3并使用命令shutdown -r now重启机器,使用命令hostname查看当前机器的主机名使用命令
vim /etc/hosts添加各机器节点的ip和hostname配置各个虚拟机节点并重启机器,让各个节点能识别对方192.168.200.132 node1 192.168.200.133 node2 192.168.200.134 node31
2
3要确保各个节点的cookie文件使用的是同一个值,在node1节点上执行远程操作命令
scp /var/lib/rabbitmq/.erlang.cookie root@node2:/var/lib/rabbitmq/.erlang.cookie和scp /var/lib/rabbitmq/.erlang.cookie root@node3:/var/lib/rabbitmq/.erlang.cookie将第一台机器的cookie复制给第二台和第三台机器三台机器使用命令
rabbitmq-server -detached重启RabbitMQ服务、顺带重启Erlang虚拟机和RabbitMQ的应用服务以node1为集群将node2和node3加入进去,分别在node2和node3节点执行以下命令
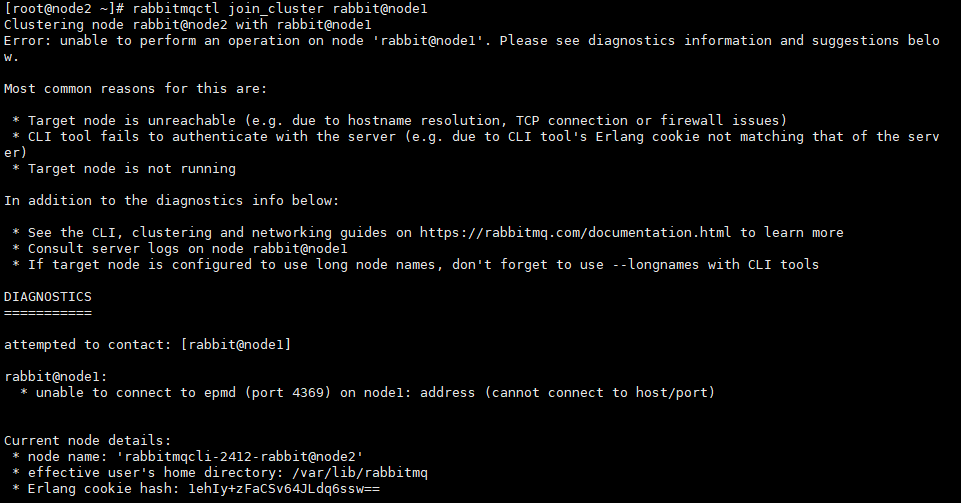
关闭RabbitMQ服务,将rabbitmq重置,将node2和node3节点分别加入node1节点【这里将node2节点加入node3节点观察后续移除node2节点后node3的效果,凉了手速过快,一起连上了】
rabbitmqctl stop_app #(rabbitmqctl stop 会将 Erlang 虚拟机关闭, rabbitmqctl stop_app 只关闭 RabbitMQ 服务,就是rabbitmq本身) rabbitmqctl reset rabbitmqctl join_cluster rabbit@node1 rabbitmqctl start_app #(只启动应用服务)1
2
3
4
5
6执行命令
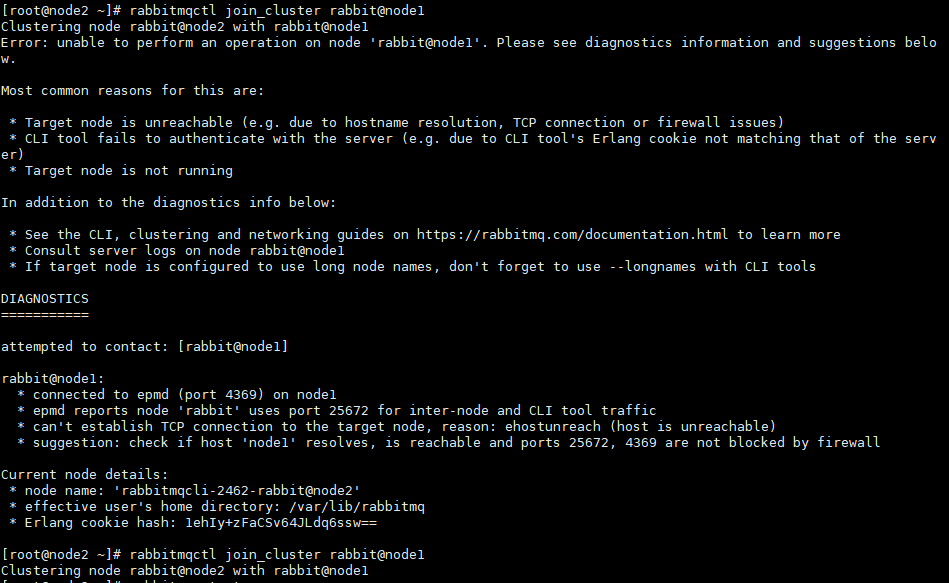
rabbitmqctl join_cluster rabbit@node1必须开放node1的4369和25672端口,否则会报错;网上一堆操作猛如虎,没一个讲到点上的;克隆的系统相关端口也是开放的我靠,血泪教训,最多只能有一个机器不开放4369和25672端口,其他所有机器都必须开放这俩接口,否则严重点会直接导致所有的RabbitMQ没有一台机器能启动,一直显示正在启动中,启动命令一直卡在运行中,其他的rabbitmq命令报错消息还很傻逼,只会提醒应用没启动,网上还没啥解决方案【fuck】,最后只启动node1发现突然能启动,且能进后台,然后启动node2突然能启动了,node3死活启动不了,终于开放node2的两个端口后node3就能自动启动了,为了方便以后不出问题,建议所有机器节点都开放这俩端口,连带5672端口和15672端口
【没开放端口的情况】
![]()
【开放4369端口的情况和开放了25672端口的情况】
![]()
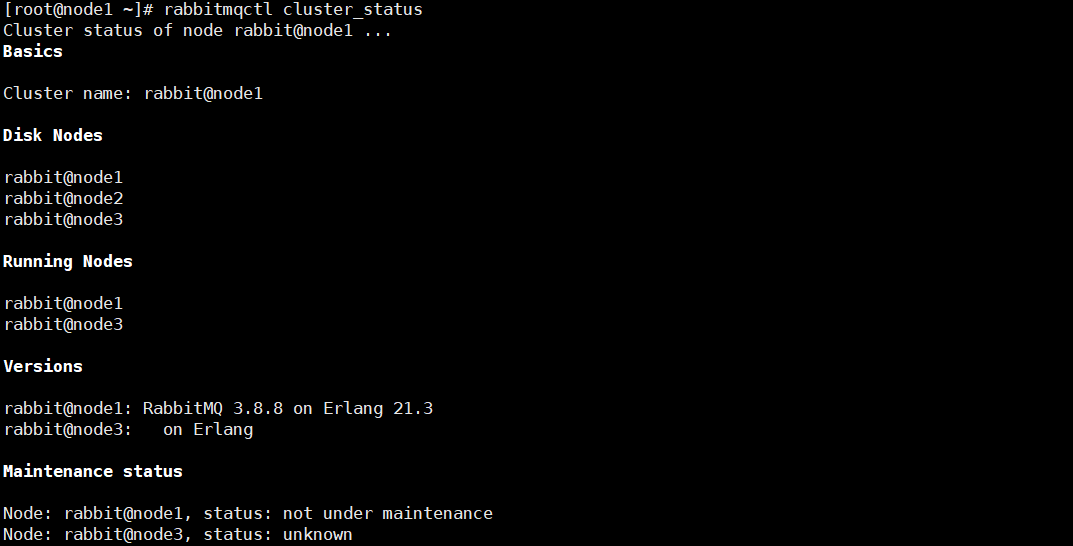
使用命令
rabbitmqctl cluster_status查看集群状态2号节点一直在启动,不知道为啥
![]()
只需要在一台机器上使用以下命令重新设置用户
rabbitmqctl add_user earl 123456 #创建账户,账户名earl,密码123456 rabbitmqctl set_user_tags earl administrator #设置用户earl的角色为超级管理员 rabbitmqctl set_permissions -p "/" earl ".*" ".*" ".*" #设置用户权限1
2
3
4
5
6
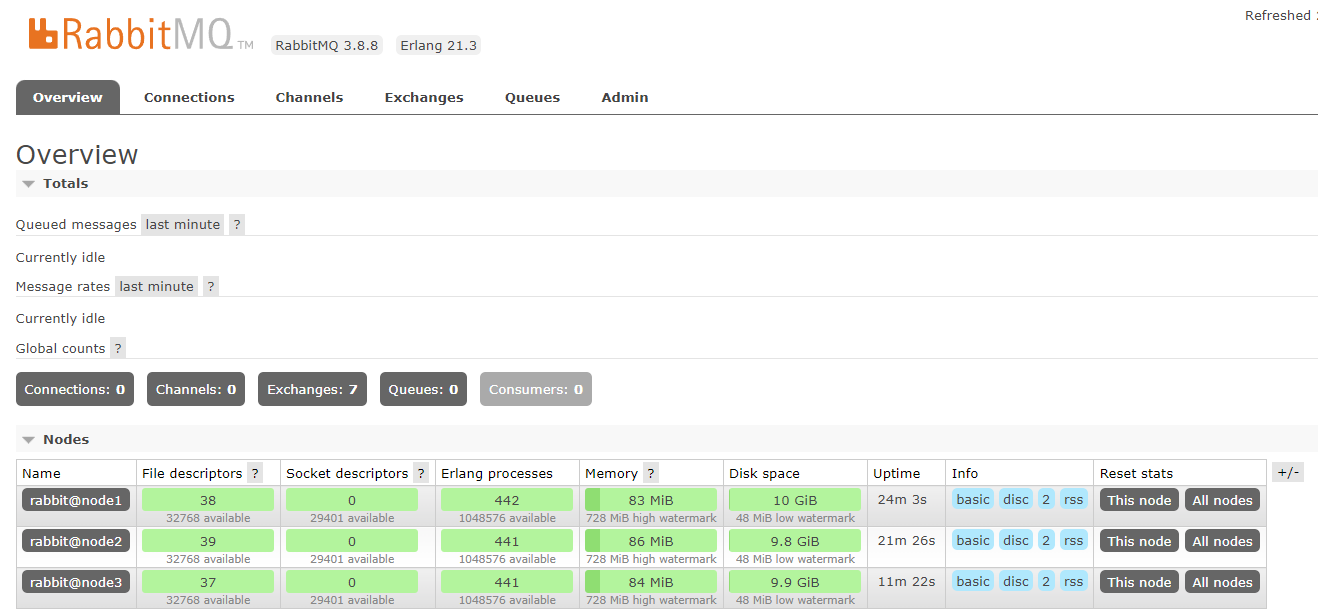
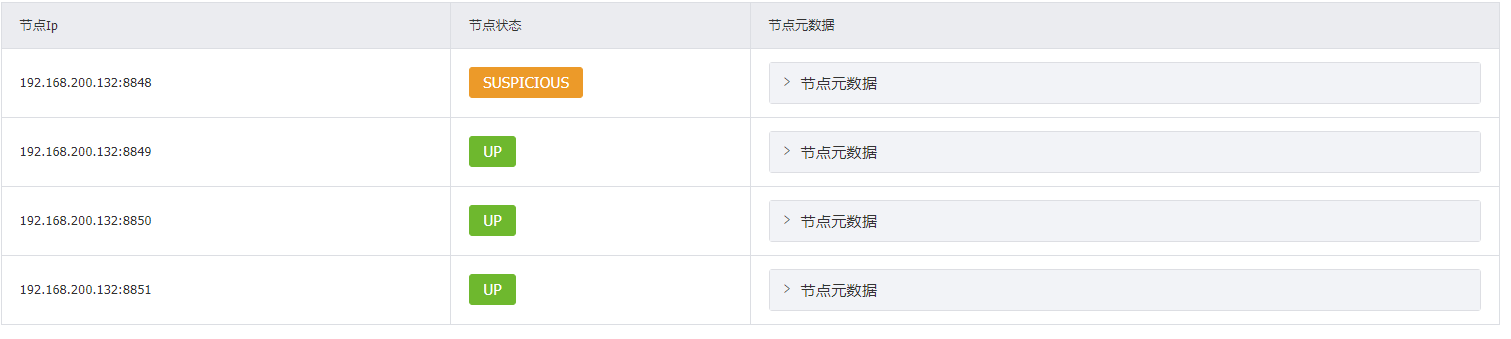
搭建成功标志
进入网页服务界面能看到3个RabbitMQ节点【状态都是绿色就表示非常健康】
![]()
解除集群节点的命令【node2和node3分别执行以脱离,最后测试一下2号机脱离通过2号机联机集群的3号机的状态,手快了全绑在node1下了】
【脱离机器node2或node3分别执行】
rabbitmqctl stop_app rabbitmqctl reset rabbitmqctl start_app rabbitmqctl cluster_status1
2
3
4【node1执行命令忘记脱离的节点】
rabbitmqctl forget_cluster_node rabbit@node21
# 安装Nacos
# 安装步骤
- 从地址
https://github.com/alibaba/nacos/tags下载linux系统下的nacos安装包nacos-server-1.3.1.tar.gz - 将
nacos-server-1.3.1.tar.gz安装包拷贝到/usr/local/nacos目录下 - 使用命令
tar -zxvf nacos-server-1.3.1.tar.gz解压安装包到当前目录 - 进入bin目录使用命令
startup 8848启动nacos
# 安装成功测试
启动nacos,使用浏览器访问
http://localhost:8848/nacos出现nacos可视化页面即安装成功启动nacos时提示
Public Key Retrieval is not allowed错误解决方法背景
在使用hive元数据服务方式访问hive时,使用jdbc连接到mysql时提示错误:
java.sql.SQLNonTransientConnectionException: Public Key Retrieval is not allowed![img]()
原因分析
如果用户使用了 sha256_password 认证,密码在传输过程中必须使用 TLS 协议保护,但是如果 RSA 公钥不可用,可以使用服务器提供的公钥;可以在连接中通过 ServerRSAPublicKeyFile 指定服务器的 RSA 公钥,或者AllowPublicKeyRetrieval=True参数以允许客户端从服务器获取公钥;但是需要注意的是 AllowPublicKeyRetrieval=True可能会导致恶意的代理通过中间人攻击(MITM)获取到明文密码,所以默认是关闭的,必须显式开启。
解决措施
在请求的url后面添加参数allowPublicKeyRetrieval=true&useSSL=false
亲测加了以后不报错正常启动
- 如果是xml配置注意&符号的转义
![img]()
注意:Xml文件中不能使用&,要使用他的转义&来代替。


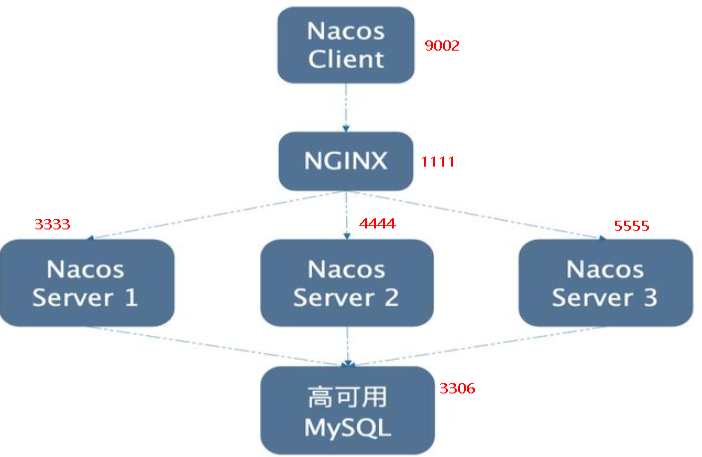
# Nacos集群配置
【集群架构图】
 )
)
nacos1.3.1能连上mysql8,且配置mysql友好,最好在根目录下创建plugins/mysql目录,把对应mysql的驱动jar包放进去,linux和windows用的驱动jar包是一样的
一台nginx+三台nacos+一台mysql实现注册配置中心集群化配置【自带消息总线】
nacos启动命令
startup 8848默认使用8848,单机版以集群的方式启动,需要修改startup.sh添加startup -p 8848,statup -p 8849,startup -p 8850以多端口的方式启动nacos配置nacos使用mysql数据库进行持久化
凡是修改配置文件的
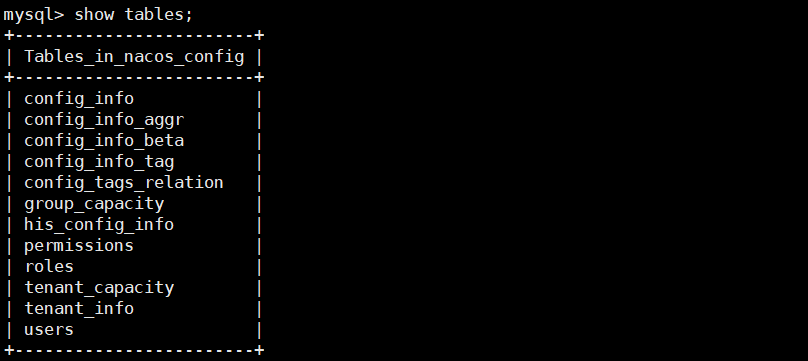
在linux系统下的mysql中创建数据库nacos_config,在该数据库下使用命令
source /usr/local/nacos/nacos/conf/nacos-mysql.sql执行nacos的confg目录下的nacos-mysql.sql中的SQL语句![]()
修改配置文件application.properties,让nacos使用外置数据库mysql
#*************** Config Module Related Configurations ***************# ### If use MySQL as datasource: spring.datasource.platform=mysql ### Count of DB: db.num=1 ### Connect URL of DB: db.url.0=jdbc:mysql://127.0.0.1:3306/nacos_config?characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true&useUnicode=true&useSSL=false&serverTimezone=UTC db.user=root db.password=Haworthia07151
2
3
4
5
6
7
8
9
10
11linux服务器上nacos的集群配置cluster.conf
定出3台nacos服务的端口号,默认出厂没有cluster.conf文件,只有一个cluster.conf.example
使用命令
|拷贝cluster.conf.example文件并重命名cluster.conf使用命令
hostname -i查看本机ens33的ip地址![]()
配置cluster.conf集群配置
集群配置一定要用上述的ip地址
#cluster server 192.168.200.132:8849 192.168.200.132:8850 192.168.200.132:88511
2
3
4修改nacos启动脚本startup.sh,使其能接受不同的启动端口
就是在启动脚本中写入命令
startup -p 8849【端口号一定要是在cluster.conf中配置过的端口】使用命令
set number或set nu在vim中显示行号,使用命令set nonu[mber]取消显示行号,使用命令set nu!或者set invnu[mber]反转行号【反转行号显示的效果是有行号变成不显示行号,没有行号的变成显示行号】,使用命令set relativenumber设置相对于某一行的行号将反转行号绑定到按键将这行代码
nnoremap <C-N><C-N> :set invnumber<CR>放入vimrc文件中,意思是连按两下<Ctrl-N>便可以反转行号显示【<Ctrl-N>就是CTRL+n的意思,CTRL+N也可以用】,如果要在【insert模式】下反转行号显示,可以使用代码:inoremap <C-N><C-N> <C-O>:set invnumber<CR>【修改启动脚本】
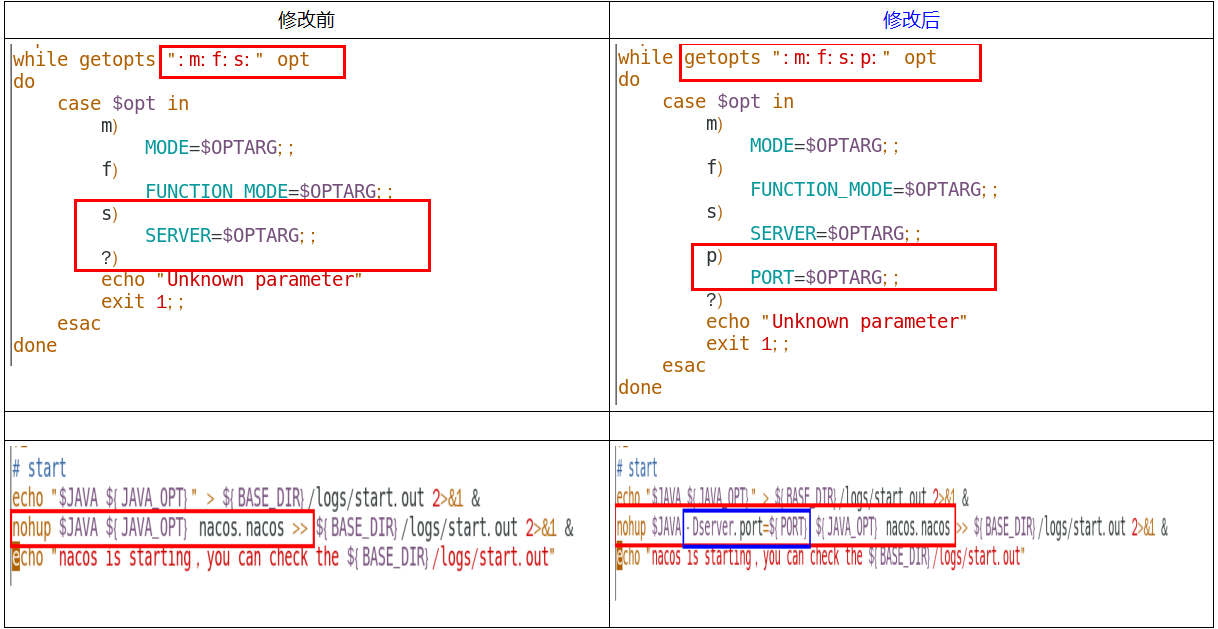
- 修改前:如果启动命令传递的是m就走模式分支MODE,传递的是f就走FUNCTION MODE分支,传递的是s就走SERVER分支
- 修改后添加了
p:,传参p就会走PORT分支,表示传递变量值$OPTARG给变量PORT
- 修改后添加了
- 在$JAVA和$JAVA_OPT之间加了
-Dserver.port=${PORT}表示把输入启动命令的参数值即此前给PORT赋值的参数值传递给$JAVA -Dserver.port- Nacos本身没做这个原因应该是,学习是在同一台机器进行。实际生产在不同服务器做分布式集群。
![]()
- 修改前:如果启动命令传递的是m就走模式分支MODE,传递的是f就走FUNCTION MODE分支,传递的是s就走SERVER分支
在nacos根目录下创建plugins/mysql目录,将对应mysql数据库的驱动引入其中,windows下用的jar包就行,经过测试,能正常启动,因为第一次的startup.sh的
-Dserver.port写到上一行去了,所以启动不起来才考虑加入mysql驱动插件的,然后发现startup.sh写错了,改了以后启动正常了,但是是否要加驱动jar包就不知道了,反正加了不会报错修改Nginx配置,让其作为负载均衡器
nginx的配置
![]()
测试
启动mysql服务
在nacos的bin目录下使用命令
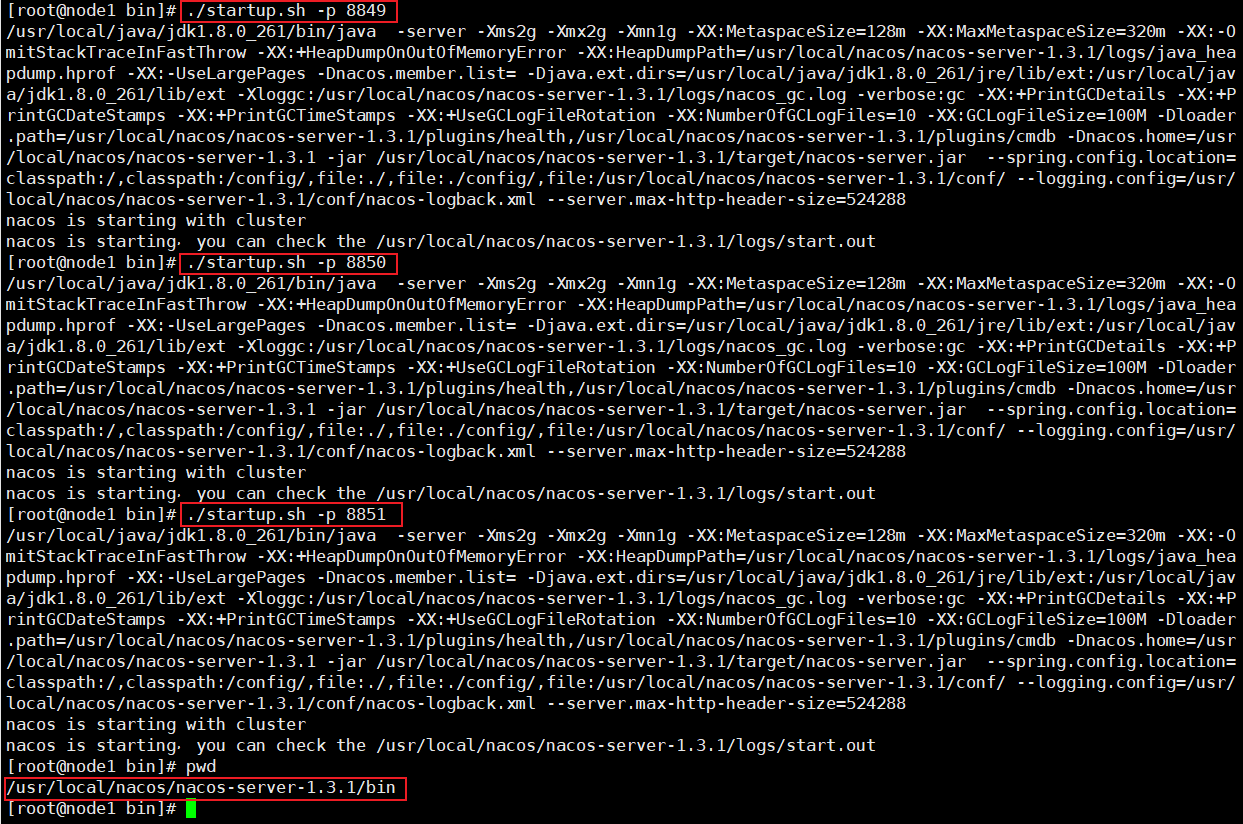
./startup.sh -p 8849和./startup.sh -p 8850和./startup.sh -p 8851在不同端口启动3台nacos服务器启动单台一定要测试是否启动成功,直接在浏览器访问对应端口的服务,启动不了nginx是访问不了的
使用ps命令确认过三台nacos服务都启动了
使用命令
ps -ef|grep nacos|grep -v grep|wc -l可以查看nacos服务器启动的台数![]()
在nginx的sbin目录下使用命令
./nginx -c /usr/local/nginx/conf/nginx.conf启动nginx使用ps命令确认过nginx服务已经启动
![]()
使用请求路径
192.168.200.132:1111/nacos访问nacos集群![]()
测试集群是否搭建成功
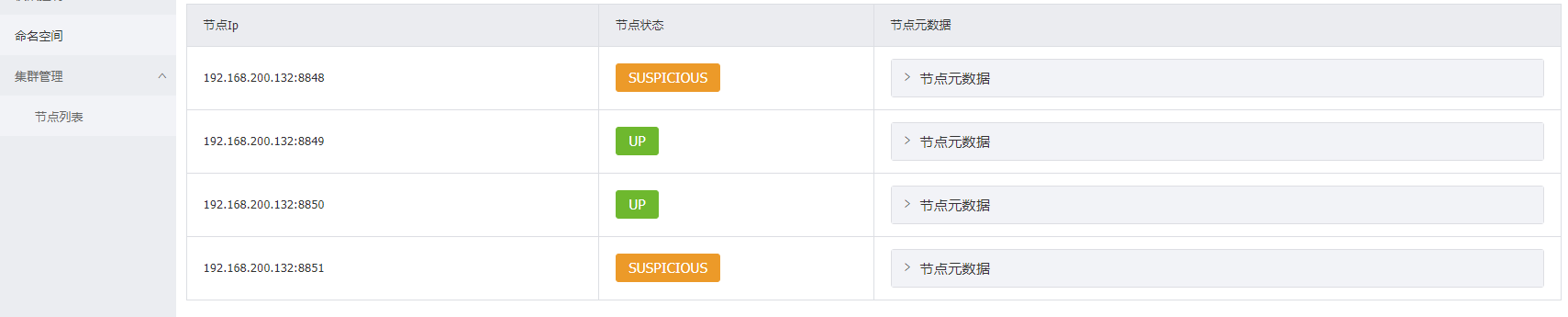
启动后发现只有两台nacos启动了,第三台无法访问
原因是虚拟机内存用完了
![]()
【nacos服务状态】
第三台因为内存不够没启动成功,这里有第一个8848端口的nacos是因为配置文件写错了,后来改了,最后一个是因为虚拟机内存不够了,启动不起来
![]()
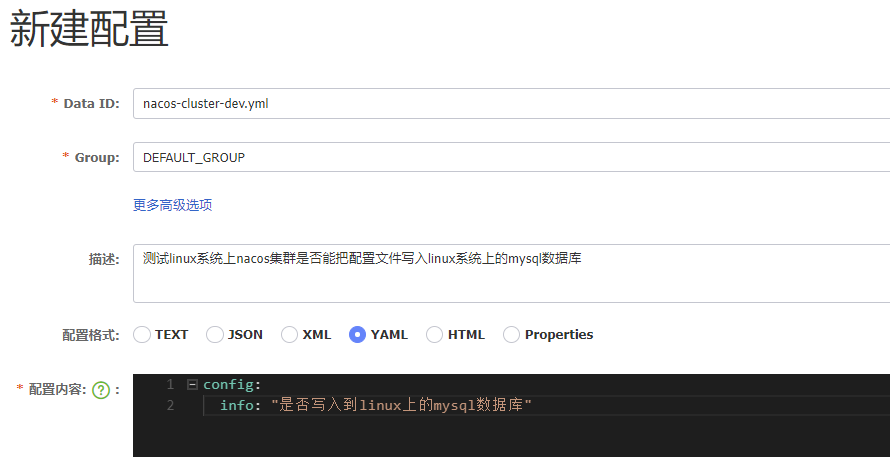
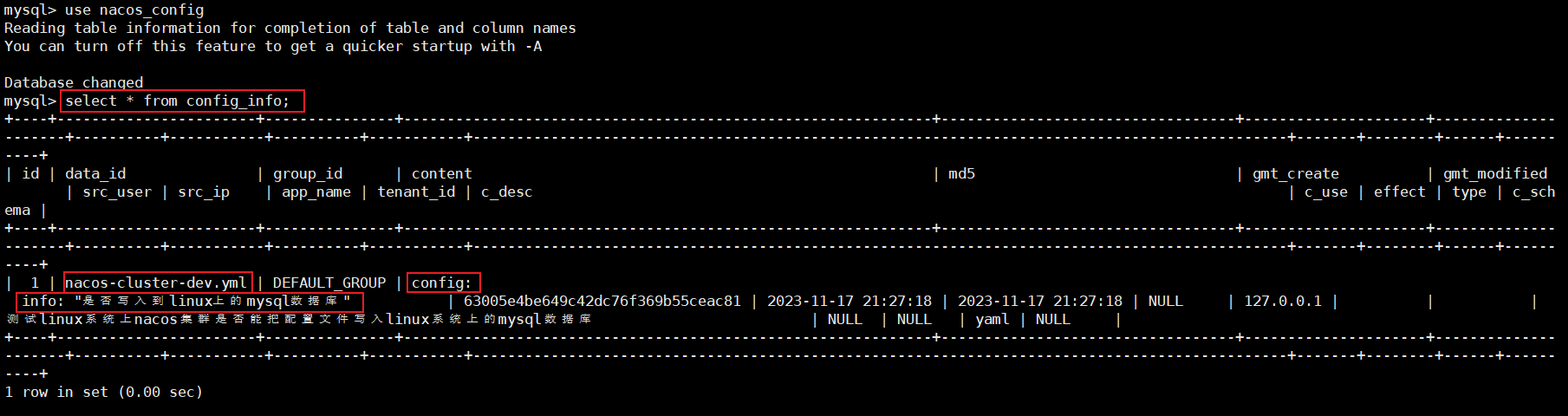
新建配置文件
配置文件会创建在数据库nacos_config的config_info表下,存在服务器没起来也能新建配置文件写入数据库,但是存在nacos服务器起不来,无法向nacos集群注册服务,服务列表是空的
![]()
【数据库配置文件存储实况】
文件名、配置文件信息都和新建配置一模一样
![]()
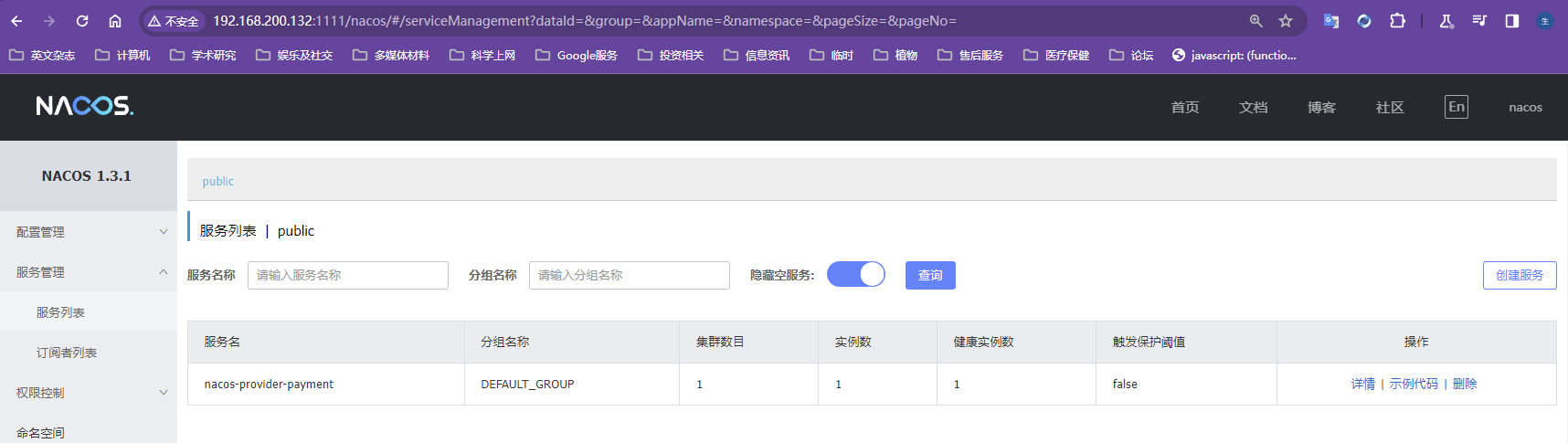
将SpringCloud学习项目的模块23的注册中心迁移到linux系统上由nginx负责负载均衡的nacos集群上来
此时读取的应该是linux上mysql数据库的配置文件
23模块配置文件切换注册中心为nacos集群
server: port: 8014 spring: application: name: nacos-provider-payment cloud: nacos: discovery: #server-addr: localhost:8848 #配置Nacos地址 server-addr: 192.168.200.132::1111 #配置Nacos地址 management: endpoints: web: exposure: include: '*' #暴露要监控的所有端点,actuator中的,雷神springboot最后有讲1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17如果nacos注册中心中服务列表显示该模块则证明服务成功注册到nacos集群中
几个要点,
- nacos中的集群管理的节点列表中会显示写在配置文件的所有nacos服务器,只要这个列表中有一台服务器起不起来,比如虚拟机内存不够了服务就启动不起来,此时服务就无法注册到nacos集群中,服务列表不会显示启动的服务【错误配置8848端口的nacos没有上线其他三台正常服务无法注册;更正8848后故意只启动两台,服务无法注册,报错拒绝连接;此时启动第三台,服务成功注册】只要有一台nacos服务器宕机,服务就无法注册到注册中心,这不是违背高可用和配置集群的原则吗?
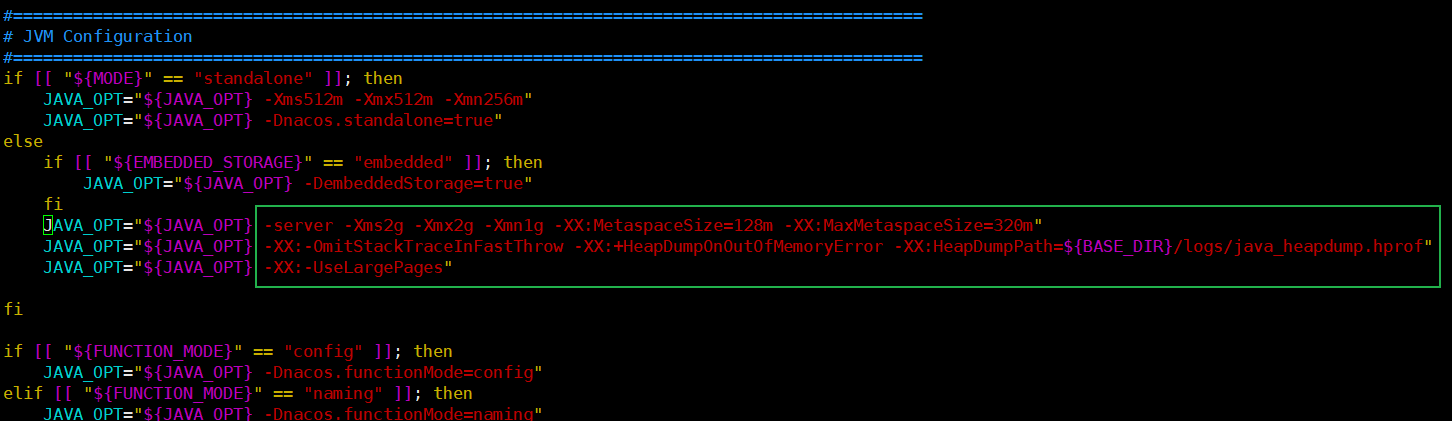
- 可以修改nacos的配置文件来限制nacos的运行内存大小,达到增加集群中服务器数量的目的
![]()
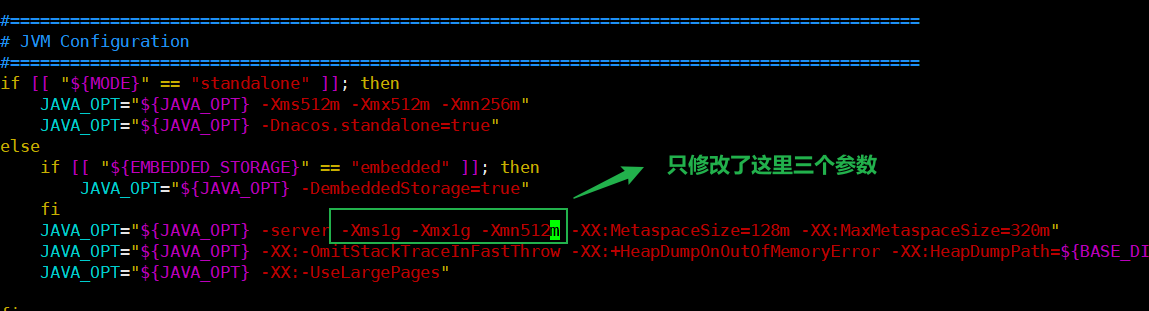
修改nacos运行内存限制
【运行内存的默认配置】
在startup.sh中的JVM配置中
![]()
【更改后的运行内存配置】
![]()
【修改后再次启动三个服务均运行正常】
第一个有8848纯属是nacos集群配置文件写错了,多加了一个8848,更改后就好了
![]()




# 安装Nginx
使用nginx1.20.2
# 安装步骤
基础部分学习使用最原始版本
将nginx的安装包
nginx-1.20.2.tar.gz上传到linux的/opt/nginx目录下使用命令
mkdir /usr/local/nginx创建/usr/local/nginx目录使用命令
tar -zxvf nginx-1.20.2.tar.gz解压文件到/opt/nginx目录进入解压目录,进入nginx解压文件,使用命令
./configure [--prefix=/usr/local/nginx]【--prefix是可选项,指定安装目录】尝试检查是否满足安装条件,期间会提示缺少的依赖,以下是需要依赖的安装成功安装的标志是没有报错
- 使用命令
yum install -y gcc安装c语言编译器gcc【-y是使用默认安装,不提示信息】 - 使用命令
yum install -y pcre pcre-devel安装perl库【pcre是perl的库】 - 使用命令
yum install -y zlib zlib-devel安装zlib库 - 检查没有问题后执行命令
make进行编译 - 执行
make install安装nginx
- 使用命令
# 安装成功测试
使用命令
cd /usr/local/nginx进入nginx安装目录,查看是否有相应文件进入sbin目录,使用命令
./nginx启动nginx服务启动时会启动多个线程
使用命令
systemctl stop firewalld.service关闭防火墙服务虚拟机是内网上的机器,外网接不进来,关闭防火墙不一定意味着不安全,当然放行端口80更完美;学习过程不需要开启,生产的时候多数时候也不需要开启,除非机器有外网直接接入,或者公司比较大,要防外边和公司里的程序员,可能开启内部的监控和日志记录,一般中小型公司是不会开内网的防火墙的,因为有硬件防火墙或者云的安全组策略
使用请求地址
http://129.168.200.132:80访问nginxnginx的默认端口就是80端口,一定要关梯子进行访问,靠北
![]()
使用命令
./nginx -s stop快速停止nginx使用命令
./nginx -s quit在退出前完成已经接受的链接请求如用户下载文件,等用户下载完成后再停机,此时不会再接收任何新请求
使用命令
./nginx -s reload重新加载nginx配置可以让nginx更新配置立即生效而不需要重启整个nginx服务器,机制是执行过程中优雅停止nginx,保持链接,reload过程开启新的线程读取配置文件,原有线程处理完任务后就会被杀掉,加载完最新配置的线程继续杀掉线程的工作
此时启动nginx比较麻烦,需要使用nginx的可执行文件,意外重启的时候很麻烦,需要登录到控制台手动启动,将nginx安装成系统服务脚本启动就会非常简单
使用命令
vi /usr/lib/systemd/system/nginx.service创建服务脚本粘贴文本普通模式粘贴可能丢字符,插入状态粘贴就不会丢字符 WantedBy=multi-user.target 属于[install],shell脚本不能有注释,否则无法设置开机自启动
[Unit] Description=nginx - web server After=network.target remote-fs.target nss-lookup.target [Service] Type=forking PIDFile=/usr/local/nginx/logs/nginx.pid ExecStartPre=/usr/local/nginx/sbin/nginx -t -c /usr/local/nginx/conf/nginx.conf ExecStart=/usr/local/nginx/sbin/nginx -c /usr/local/nginx/conf/nginx.conf ExecReload=/usr/local/nginx/sbin/nginx -s reload ExecStop=/usr/local/nginx/sbin/nginx -s stop ExecQuit=/usr/local/nginx/sbin/nginx -s quit PrivateTmp=true [Install] WantedBy=multi-user.target1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16使用命令
systemctl daemon-reload重新加载系统服务并关闭nginx服务使用命令
systemctl start nginx.service用脚本启动nginx【启动前注意关闭nginx,避免发生冲突】使用命令
systemctl status nginx查看服务运行状态使用命令
systemctl enable nginx.service设置nginx开机启动nginx.service中的[Install]部分中的WantedBy=multi-user.target不能有注释,不能拼写错误,否则无法设置开机自启动
# Nginx安装Sticky
sticky是google开源的第三方模块
sticky在nginx上的使用说明:http://nginx.org/en/docs/http/ngx_http_upstream_module.html#sticky
tengine版本中已经有sticky这个模块了,安装的时候需要进行编译;其他的版本还是需要单独安装,sticky模块用的比较多
下载地址:BitBucket下载地址,里面也有对sticky使用的介绍 (opens new window)、github下载地址,github是第三方作者的,google主要开源在BitBucket上 (opens new window)
sticky主要还是使用BitBucket下载,该Sticky由google进行的迁移,而且一般都下载这个,下载点击downloads--Tags选择版本【很多年不更新了,但是功能已经算比较完善了,有不同的压缩格式,linux选择.gz】--点击.gz进行下载【sticky安装在nginx负载均衡器上即131】
将文件
nginx-goodies-nginx-sticky-module-ng-c78b7dd79d0d.tar.gz上传至linux系统/opt/nginx目录下使用命令
tar -zxvf nginx-goodies-nginx-sticky-module-ng-c78b7dd79d0d.tar.gz将文件解压到当前目录在nginx的解压目录
/opt/nginx/nginx-1.20.2目录下使用命令./configure --prefix=/usr/local/nginx/ --add-module=/opt/nginx/nginx-goodies-nginx-sticky-module-ng-c78b7dd79d0d检查环境并配置将nginx编译安装至/usr/local/nginx目录下nginx重新编译会生成全新的nginx,如果老nginx配置比较多需要全部备份并编译后进行替换
--add-module是添加第三方的模块,如果是nginx自带的模块编译的时候用的是--vs-module命令,表示模块已经在nginx的官方安装包里了
在nginx的解压目录
/opt/nginx目录下使用命令make安装nginx编译过程如果遇到sticky报错,是因为sticky过老的问题,需要修改源码,在sticky的解压文件中找到
ngx_http_sticky_misc.h文件的第十二行添加以下代码添加后需要重新./configure一下再执行make
安装sticky模块需要openSSL依赖,如果没有make的时候也会报错没有openssl/sha.h文件,此时使用命令
yum install -y openssl-devel安装openssl-devel,再使用./configure检查环境并make进行编译安装,没有报错就安装成功了#include <openssl/sha.h> #include <openssl/md5.h>1
2在nginx解压目录使用命令
make upgrade检查新编译的安装包是否存在问题【在不替换原nginx的情况下尝试跑一下新的nginx】,而不是直接把新的替换掉旧的nginx解压目录中objs是nginx编译后的文件,objs目录下的nginx.sh就是新编译的nginx可执行文件,想要平滑升级nginx不破坏原有配置可以将该nginx.sh文件直接替换掉原安装目录中的nginx.sh,但是一定要注意原文件的备份
使用命令
mv /usr/local/nginx/sbin/nginx /usr/local/nginx/sbin/nginx.old对原nginx可执行文件进行备份,使用命令cp nginx /usr/local/nginx/sbin/将nginx解压包objs目录下的nginx.sh拷贝到目录/usr/local/nginx/sbin/使用命令
./nginx -V来查看nginx的版本和nginx的编译安装参数使用命令
systemctl start nginx启动nginx,并使用浏览器访问nginx观察访问是否正常,访问正常即nginx升级第三方模块成功
# Nginx安装Brolti
安装ngx_brotli和brotli稍微麻烦一点,因为有子项目依赖
从下载地址
https://github.com/google/ngx_brotli下载brolti在nginx上的插件ngx_brotlingx_brotli下载地址有文档,配置使用官方推荐的动态模块的方式,动态加载模块是nginx在1.9版本以后才支持的,禁用模块无需重新进行编译,直接在配置文件中进行配置要使用的模块就可以直接使用了【就是安装是安装,需要使用要在配置文件进行配置,不配置对应的模块就会禁用】
ngx_brotli下载点击release下载,只能下载到源码,需要自己在本地进行编译和安装;或者从git直接拉取到本地进行编译和安装;稳定版本现在只有1.0.0,linux系统下载tar.gz版本
![]()
从下载地址
https://codeload.github.com/google/brotli/tar.gz/refs/tags/v1.0.9下载brotli单独的算法仓库地址:https://github.com/google/brotli,也可以直接从对应仓库的release下载tar.gz的源码压缩包
使用命令
tar -zxvf ngx_brotli-1.0.0rc.tar.gz解压ngx_brotli的压缩包使用命令
tar -zxvf brotli-1.0.9.tar.gz解压brolti的压缩包进入brolti的解压目录,使用命令
mv ./* /opt/nginx/ngx_brotli-1.0.0rc/deps/brotli将brotli算法的压缩包移动到ngx_brotli解压目录下的ngx_brotli-1.0.0rc/deps/brolti目录【注意不要 把解压目录brotli-1.0.9也拷贝过去了,只拷贝该目录下的文件,目录层级不对预编译检查会报错】在nginx的解压目录使用命令
./configure --with-compat --add-dynamic-module=/opt/nginx/ngx_brotli-1.0.0rc --prefix=/usr/local/nginx/ --add-module=/opt/nginx/nginx-goodies-nginx-sticky-module-ng-c78b7dd79d0d --with-http_gzip_static_module --with-http_gunzip_module以动态化模块的方式【传统的方式模块无法禁用】对ngx_brolti进行编译,传统的编译可以在./configure中使用--add-dynamic-module=brotli目录在nginx的解压目录使用命令
make进行编译没报错就是成功的,经测试没问题
使用命令
mkdir /usr/local/nginx/modules在nginx安装目录下创建一个modules模块专门来放置第三方模块,默认是没有的在nginx解压目录进入
objs目录,使用命令cp ngx_http_brotli_filter_module.so /usr/local/nginx/modules/以及cp ngx_http_brotli_static_module.so /usr/local/nginx/modules/将模块ngx_http_brotli_filter_module.so和ngx_http_brotli_static_module.so拷贝到nginx安装目录的modules目录下,以后就可以在nginx配置文件动态的加载brotli模块了停止nginx的运行,使用命令
mv /usr/local/nginx/sbin/nginx /usr/local/nginx/sbin/nginx.old3,使用命令cp nginx /usr/local/nginx/sbin/将objs/nginx.sh复制到nginx的sbin目录只要进行了编译就要将新的主程序nginx拷贝到nginx的安装目录,否则即使之前的步骤都没问题模块也是用不了的
每次预编译都要带上之前添加的完整的模块,否则可能由于对某些模块有配置但是没有安装相应的模块,会导致服务启动不起来
可以在拷贝完成后再重启nginx服务
能成功重启nginx就是正常的
# Nginx安装Concat
官网地址:https://github.com/alibaba/nginx-http-concat
nginx官网对Concat的介绍:https://www.nginx.com/resources/wiki/modules/concat/
Tengine的官网也有介绍,该模块最早是tengine发布的,tengine已经被捐献给apache开源组织,tengine是基于nginx开源版基础上再源码层面做了很多的修改,不只是增加了模块和功能,大部分的tengine的模块直接拿到nginx中是用不了的,但是Concat模块是能直接拿过来使用的,Concat虽然很久没用了,但是比较简单,就一个C源文件,而且release中没有发行版,只能通过git clone进行安装或者点击code通过
download zip将压缩包nginx-http-concat-master.zip下载下来
将压缩包
nginx-http-concat-master.zip拷贝到/opt/nginx目录下这里有个坑,大家用git指令下载的文件是和直接下载的文件是不一样的,git下载的文件名没有-master
[root@nginx1 nginx]# unzip nginx-http-concat-master.zip Archive: nginx-http-concat-master.zip b8d3e7ec511724a6900ba3915df6b504337891a9 creating: nginx-http-concat-master/ inflating: nginx-http-concat-master/README.md inflating: nginx-http-concat-master/config inflating: nginx-http-concat-master/ngx_http_concat_module.c1
2
3
4
5
6
7在nginx的解压目录中使用命令
./configure --with-compat --add-dynamic-module=/opt/nginx/ngx_brotli-1.0.0rc --prefix=/usr/local/nginx/ --add-module=/opt/nginx/nginx-goodies-nginx-sticky-module-ng-c78b7dd79d0d --with-http_gzip_static_module --with-http_gunzip_module --add-module=/opt/nginx/nginx-http-concat-master进行预编译,然后使用make命令编译这里面为了nginx的课程连续性,添加了很多其他模块,自己根据需要选择,预编译检查的命令不是固定的,对nginx.sh使用命令
./nginx -V能够查看当前nginx的版本,gcc版本和安装的模块[root@nginx1 objs]# ./nginx -V nginx version: nginx/1.20.2 built by gcc 8.3.1 20190311 (Red Hat 8.3.1-3) (GCC) configure arguments: --with-compat --add-dynamic-module=/opt/nginx/ngx_brotli-1.0.0rc --prefix=/usr/local/nginx/ --add-module=/opt/nginx/nginx-goodies-nginx-sticky-module-ng-c78b7dd79d0d --with-http_gzip_static_module --with-http_gunzip_module --add-module=/opt/nginx/nginx-http-concat-master1
2
3
4使用命令
systemctl stop nginx停掉nginx,在/objs目录下使用命令cp nginx /usr/local/nginx/sbin/将编译好的nginx运行文件替换掉老的nginx.sh,然后重启nginx一般来说各个模块包括第三方模块之间不会有冲突性问题
# Nginx安装GEOIP2
GEOIP是一家商业公司开发的组件,现在升级到版本2,不仅可以使用在nginx,还可以使用在java、python上,提供云API供用户直接调用,IP和地区对应的库该公司也免费开放出来了,免费版比商业版的数据精确度差一点;早期的DNS解析做的不是很好使用比较广泛,现在基本各大云平台都有很强大的DNS解析技术;自己搭建一个DNS解析系统配置和部署比较麻烦,但是现在都是云平台商提供;因此现在的GEOIP的应用场景其实不是很多,主要都是阻断一些用户请求【比如站点不对一个国家开放,或者站点只对一个城市开放,又或者根据用户所属不同区域向用户展示不同的站点,现在也比较少了,用的最多的也就是一些资源只限某个地区的用户使用】
GEOIP2的安装
tcp连接IP是无法造假的,因为tcp造假服务端数据就无法正常响应给用户
GEOIP的安装比较麻烦,需要下载3个资源
GEOIP的Nginx模块配置官方文档:http://nginx.org/en/docs/http/ngx_http_geoip_module.html#geoip_proxy
需要前往GEOIP的官网下载ip数据库
要下载需要注册并登录,GEOLite2是免费版的库,GEO2是付费版的库,而且他的库更新频率特别高,线上使用也要频繁的去更新
登录使用邮箱和密码
![]()
【下载选项】
country只能检索到国家,City能够检索到城市,ASN能检索到更详细一点的区域;测试下载country版本的就行,数据库越大,检索的效率太低,下载gzip版本;csv版本可以直接导入数据库如mysql或者oracle
测试导入云服务器上,这样能解析我们自己的ip,在自己电脑上部署无法进行访问,导入
/opt/nginx目录下![]()
前往GEOIP的官方git下载GEOIP模块的相关依赖:https://github.com/maxmind/libmaxminddb
下载1.6.0版本libmaxminddb-1.6.0.tar.gz (opens new window)
安装需要gcc,使用命令
yum install -y gcc安装gcc,解压后在安装目录执行./confugure,使用make进行编译,使用make install进行安装;使用命令echo /usr/local/lib >> /etc/ld.so.conf.d/local.conf配置动态连接库【相当于在系统的动态连接库下额外增加一个目录】,使用命令ldconfig刷新系统的动态链接库前往GEOIP的官方git下载GEOIP的对应Nginx上的模块:https://github.com/leev/ngx_http_geoip2_module
下载3.3版本ngx_http_geoip2_module-3.3.tar.gz
安装GEOIP需要pcre-devel,使用命令
yum install -y pcre pcre-devel安装;安装GEOIP需要zlib,使用命令
yum install -y zlib-devel安装;解压缩GEOIP模块的压缩包,进入nginx的解压目录使用命令
./configure --prefix=/usr/local/nginx/ --add-module=/opt/nginx/ngx_http_geoip2_module进行静态安装【动态安装更好,静态安装只是安装更省事】,使用make进行编译,使用make install进行安装【此时已经安装完毕,只需要在配置文件中进行配置,我云服务器上的nginx是通过oneinstack.com安装的,不知道安装包在哪儿,且那个nginx正在跑博客,这里就不实验了,后续记录老师的演示】

# Nginx安装Purger
将文件
ngx_cache_purge-2.3.tar.gz上传到/opt/nginx目录下,使用命令tar -zxvf ngx_cache_purge-2.3.tar.gz解压缩压缩包进入nginx的解压目录,使用命令
./configure --with-compat --add-dynamic-module=/opt/nginx/ngx_brotli-1.0.0rc --prefix=/usr/local/nginx/ --add-module=/opt/nginx/nginx-goodies-nginx-sticky-module-ng-c78b7dd79d0d --add-module=/opt/nginx/ngx_cache_purge-2.3 --with-http_gzip_static_module --with-http_gunzip_module --add-module=/opt/nginx/nginx-http-concat-master进行预编译,没有报错使用命令make进行编译这里图省事加了很多其他模块的配置,自己根据需要删减或者增加即可
使用命令
mv /usr/local/nginx/sbin/nginx /usr/local/nginx/sbin/nginx.old4将老的nginx运行文件备份,使用命令cp /opt/nginx/nginx-1.20.2/objs/nginx /usr/local/nginx/sbin/nginx将新的nginx文件拷贝到nginx的安装目录在nginx中对purger进行配置
这里自定义了参数
proxy_cache_key $uri;,默认的该参数配置$scheme$proxy_host$request_uri,生成的key效果为http://stickytest/page.css,$proxy_host是upstream的名字,可以认为该参数实际读取的是proxy_pass的host部分;这个key必须和清理缓存站点的proxy_cache_purge的配置【此处配置是$1,表示uri中的第一个参数】相同,否则无法找到对应的缓存文件并删除该缓存文件自定义参数
proxy_cache_key $uri;的好处是不管访问的是http的资源,还是https的资源,或者通过各种域名访问到主机,一概不进行区分,只对访问的具体资源进行区分;这个对访问文件生成的key的协议和主机以及uri有影响,默认设置可能来自不同协议、域名等请求可能对同一份响应文件生成多个不同key的缓存文件,使用uri来作为key能够避免区分协议和不同的域名,相同的响应文件只生成同一份缓存文件proxy_cache_key $uri;还可以使用很多其他的变量,官方git举了一些例子【具体可用的参数课程没有讲过,自己总结】,比如proxy_cache_key $host$uri$is_args$args;【$is_args是判断是否有参数】,一旦修改了proxy_cache_key,proxy_cache_purge中的最后一个参数也要和key的形式保持一致worker_processes 1; events { worker_connections 1024; } http { include mime.types; default_type application/octet-stream; sendfile on; upstream stickytest{ server 192.168.200.135:8080; } proxy_cache_path /ngx_tmp levels=1:2 keys_zone=test_cache:100m inactive=1d max_size=10g ; server { listen 80; server_name localhost; #额外添加一个location,实现和proxy_cache缓存文件反向的效果,访问某个资源带/purge起头的url能够清除对应url资源的缓存文件 location ~/purge(/.*){ #调用proxy_cache_purge去清理缓存区域test_cache[proxy_cache_path中的keys_zone]的缓存文件,$1指的是请求后面的uri除去/purge的部分 proxy_cache_purge test_cache $1; } location / { proxy_cache test_cache; add_header Nginx-Cache "$upstream_cache_status"; proxy_cache_valid 23h; #自定义缓存文件的key为请求的uri proxy_cache_key $uri; proxy_pass http://stickytest; } error_page 500 502 503 504 /50x.html; location = /50x.html { root html; } } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
# 安装redis连接模块
在https://github.com/openresty/redis2-nginx-module/tags下载模块
redis2-nginx-module,这里与课程一致下载0.15版本,上传至linux的/opt/nginx目录下使用命令
tar -zxvf redis2-nginx-module-0.15.tar.gz解压压缩包进入nginx的安装目录,使用命令
./configure --prefix=/usr/local/nginx/ -add-module=/opt/nginx/redis2-nginx-module-0.15进行预编译,然后使用命令make实际不要直接用这个命令,要根据实际添加的模块来进行自定义该命令,实际我这里使用的是
./configure --with-compat --add-dynamic-module=/opt/nginx/ngx_brotli-1.0.0rc --prefix=/usr/local/nginx/ -add-module=/opt/nginx/redis2-nginx-module-0.15 --add-module=/opt/nginx/nginx-goodies-nginx-sticky-module-ng-c78b7dd79d0d --add-module=/opt/nginx/ngx_cache_purge-2.3 --with-http_gzip_static_module --with-http_gunzip_module --add-module=/opt/nginx/nginx-http-concat-master使用命令
mv /usr/local/nginx/sbin/nginx /usr/local/nginx/sbin/nginx.old5将老nginx运行文件备份,在nginx的解压目录的objs目录下使用命令cp objs/nginx /usr/local/nginx/sbin/将编译好的nginx拷贝到nginx的安装目录
# 安装keepalived
# 编译安装
安装包下载地址:https://www.keepalived.org/download.html#
解压安装包,在当前目录下使用命令
./configure查看安装环境是否完整,如果有如下报错信息需要使用命令yum install openssl-devel安装openssl-devel的依赖configure: error: !!! OpenSSL is not properly installed on your system. !!! !!! Can not include OpenSSL headers files. !!!1
2
3编译安装以前安装过,后面补充,包括上一条命令添加安装的位置
# 安装步骤
使用命令
yum install -y keepalived安装keepalived需要在线监测的所有机器都要安装keepalived
如果安装提示缺少
需要:libmysqlclient.so.18()(64bit),依次使用命令wget https://dev.mysql.com/get/Downloads/MySQL-5.7/mysql-community-libs-compat-5.7.25-1.el7.x86_64.rpm和rpm -ivh mysql-community-libs-compat-5.7.25-1.el7.x86_64.rpm安装对应的依赖【是否需要注意mysql的版本和本机匹配,我这里匹配了没有问题】,然后再次执行yum install -y keepalived安装keepalived即可keepalived的配置文件在目录
/etc/keepalived/keepalived.conf,使用命令vim /etc/keepalived/keepalived.conf修改keepalived的配置文件用来做nginx服务器在线监测的keepalived配置
【默认的keepalived配置文件】
! Configuration File for keepalived global_defs { #这一段是机器宕机以后发送email通知,作用不大 notification_email { acassen@firewall.loc failover@firewall.loc sysadmin@firewall.loc } notification_email_from Alexandre.Cassen@firewall.loc smtp_server 192.168.200.1 smtp_connect_timeout 30 #global_defs中只有router_id有点用,其他的都可以删掉 router_id LVS_DEVEL vrrp_skip_check_adv_addr vrrp_strict vrrp_garp_interval 0 vrrp_gna_interval 0 } vrrp_instance VI_1 { state MASTER interface eth0 virtual_router_id 51 priority 100 advert_int 1 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { 192.168.200.16 192.168.200.17 192.168.200.18 } } #仅仅用来检查nginx服务器的存活状态不用关心从这里往下的所有配置,即virtual_server都可以删掉 virtual_server 192.168.200.100 443 { delay_loop 6 lb_algo rr lb_kind NAT persistence_timeout 50 protocol TCP real_server 192.168.201.100 443 { weight 1 SSL_GET { url { path / digest ff20ad2481f97b1754ef3e12ecd3a9cc } url { path /mrtg/ digest 9b3a0c85a887a256d6939da88aabd8cd } connect_timeout 3 nb_get_retry 3 delay_before_retry 3 } } } virtual_server 10.10.10.2 1358 { delay_loop 6 lb_algo rr lb_kind NAT persistence_timeout 50 protocol TCP sorry_server 192.168.200.200 1358 real_server 192.168.200.2 1358 { weight 1 HTTP_GET { url { path /testurl/test.jsp digest 640205b7b0fc66c1ea91c463fac6334d } url { path /testurl2/test.jsp digest 640205b7b0fc66c1ea91c463fac6334d } url { path /testurl3/test.jsp digest 640205b7b0fc66c1ea91c463fac6334d } connect_timeout 3 nb_get_retry 3 delay_before_retry 3 } } real_server 192.168.200.3 1358 { weight 1 HTTP_GET { url { path /testurl/test.jsp digest 640205b7b0fc66c1ea91c463fac6334c } url { path /testurl2/test.jsp digest 640205b7b0fc66c1ea91c463fac6334c } connect_timeout 3 nb_get_retry 3 delay_before_retry 3 } } } virtual_server 10.10.10.3 1358 { delay_loop 3 lb_algo rr lb_kind NAT persistence_timeout 50 protocol TCP real_server 192.168.200.4 1358 { weight 1 HTTP_GET { url { path /testurl/test.jsp digest 640205b7b0fc66c1ea91c463fac6334d } url { path /testurl2/test.jsp digest 640205b7b0fc66c1ea91c463fac6334d } url { path /testurl3/test.jsp digest 640205b7b0fc66c1ea91c463fac6334d } connect_timeout 3 nb_get_retry 3 delay_before_retry 3 } } real_server 192.168.200.5 1358 { weight 1 HTTP_GET { url { path /testurl/test.jsp digest 640205b7b0fc66c1ea91c463fac6334d } url { path /testurl2/test.jsp digest 640205b7b0fc66c1ea91c463fac6334d } url { path /testurl3/test.jsp digest 640205b7b0fc66c1ea91c463fac6334d } connect_timeout 3 nb_get_retry 3 delay_before_retry 3 } } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164【做nginx代理服务器的keepalived配置文件】
! Configuration File for keepalived global_defs { #global_defs中只有router_id有点用,其他的都可以删掉,这个是当前机器的自定义名字,随便起名的,当前机器的ip是131 router_id nginx131 } #vrrp是keepalived在内网中通讯的协议【vrrp虚拟路由冗余协议】,atlisheng是实例名称,也是自定义的 vrrp_instance atlisheng { #state是当前机器的状态,当前机器是master state MASTER #interface需要和本机的网卡的名称对应上,这里修改ip地址为ens32,需要和interface对应 interface ens32 #这个不用管 virtual_router_id 51 #主备竞选的优先级,谁的优先级越高,谁就是master;Keepalived 就是使用抢占式机制进行选举,一旦有优先级高的加入,立即成为 Master priority 100 #检测间隔时间 advert_int 1 #内网中一组keepalive的凭证,因为内网中可能不止一组设备跑着keepalived,需要认证信息证明多个keepalived属于一组,同一组的authentication要保持一致,这样能决定一组keepalived中的一台机器宕机,虚拟IP是否只在本组内进行漂移,而不会漂移到其他组上 authentication { auth_type PASS auth_pass 1111 } #虚拟IP,虚拟IP可以填写好几个,意义不大,一般虚拟一个IP即可,这里设置成192.168.200.200,用户访问的是虚拟的ip,不再是真实的ip地址 virtual_ipaddress { 192.168.200.200 #192.168.200.17 #192.168.200.18 } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31【备用机的keepalived配置】
注意同一组的实例名、virtual_router_id、authentication得是一样的
注意备机的priority 要设置的比主机小,state需要改成BACKUP
且备用机使用命令
ip addr不会看到虚拟ip的信息! Configuration File for keepalived global_defs { router_id nginx132 } vrrp_instance atlisheng { state BACKUP interface ens32 virtual_router_id 51 priority 50 advert_int 1 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { 192.168.200.200 } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20使用命令
systemctl start keepalived运行keepalived
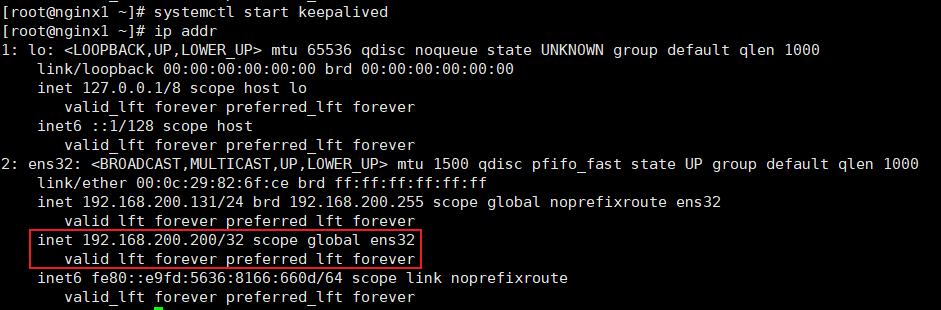
# 安装成功测试
启动keepalived后使用命令
ip addr查询ip信息在ens32下在原来真实的ip下会多出来一个inet虚拟ip:
192.168.200.200![]()
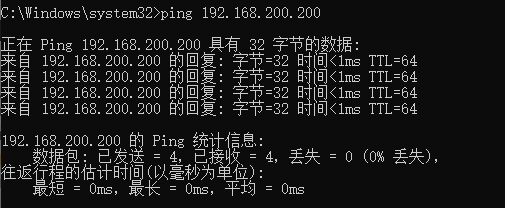
在windows命令窗口使用命令
ping 192.168.200.200 -t在windows系统ping一下这个虚拟IP,观察该ip是否能ping通没有-t只会ping4次,像下图这种情况
![]()
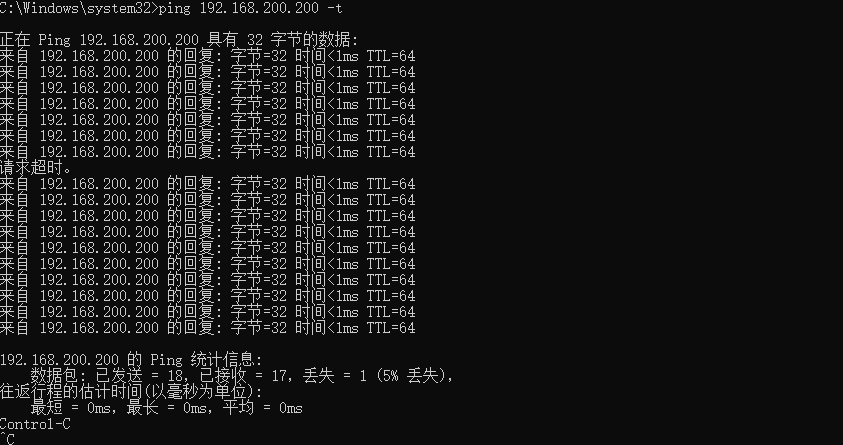
在linux系统下使用命令
init 0关掉master机器模拟nginx服务器宕机,在windows命令窗口观察网络通信情况windows通信切换时丢包一次,然后再次ping通,在备用机132上使用命令
ip addr能够观察到虚拟ip漂移到132机器上![]()
# 安装Tomcat
tomcat的运行需要jdk
# 安装步骤
将tomcat的安装包文件拷贝到linux系统下的
/opt/tomcat目录下使用命令
tar zxvf apache-tomcat-9.0.62.tar.gz -C /usr/local/将压缩包解压到/usr/local目录tomcat的目录结构
- bin --启动命令目录
- conf --配置文件目录 *重点
- lib --库文件目录
- logs --日志文件目录 *重点
- temp --临时缓存文件
- webapps --web应用家目录 *重点
- work --工作缓存目录
修改tomcat环境变量
解压后需要再tomcat中配置jdk的目录,修改tomcat环境变量有三种方法
- **第一种:**定义在全局里;如果装有多个JDK的话,定义全局会冲突,不建议
[root@Tomcat ~]# vim /etc/profile1**第二种:**写用户家目录下的环境变量文件.bash_profile
**第三种:**是定义在单个tomcat的启动和关闭程序里,建议使用这种
[root@Tomcat ~]# vim /usr/local/tomcat-9.0.62/bin/startup.sh --tomcat的启动程序 [root@Tomcat ~]# vim /usr/local/tomcat-9.0.62/bin/shutdown.sh --tomcat的关闭程序1
2把startup.sh和shutdown.sh这两个脚本里的最前面加上下面一段:
export JAVA_HOME=/usr/local/java/jdk1.8.0_261 export TOMCAT_HOME=/usr/local/tomcat-9.0.62 export CATALINA_HOME=/usr/local/tomcat-9.0.62 export CLASS_PATH=$JAVA_HOME/bin/lib:$JAVA_HOME/jre/lib:$JAVA_HOME/lib/tool.jar export PATH=$PATH:/usr/local/java/jdk1.8.0_261/bin:/usr/local/tomcat-9.0.62/bin1
2
3
4
5【配置详情】
classpath是指定你在程序中所使用的类(.class)文件所在的位置
path是系统用来指定可执行文件的完整路径
![CentOS 7 Tomcat服务的安装与配置]()
使用命令
/usr/local/tomcat/bin/startup.sh启动tomcat使用命令
/usr/local/tomcat/bin/shutdown.sh可以关闭tomcat使用命令
vim /usr/local/tomcat/conf/server.xml更改配置文件的port=80可以将tomcat的端口由8080改为8069 <Connector port="80" protocol="HTTP/1.1" ----把8080改成80的话,重启后就监听80端口 70 connectionTimeout="20000" 71 redirectPort="8443" />1
2
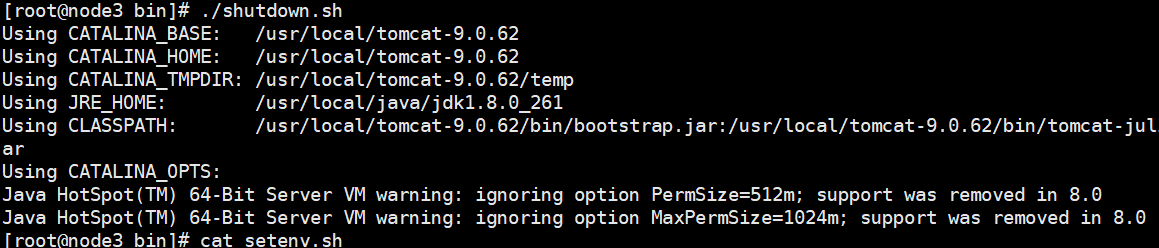
3注意这种方式安装的tomcat存在无法关闭的现象
提示信息
![]()
目前的解决方式是在bin目录下创建setenv.sh文件,写入以下配置【来自于stackOverflow】
目前测试能关闭,能起来;使用shutdown.sh进行关闭,网上有执行流程的帖子,虽然使用shutdown.sh关闭,但是实际还是用catalina.sh关闭的帖子,catalina.sh中提示缺少的参数JAVA_OPTS要写在setenv.sh文件中
export JAVA_OPTS="${JAVA_OPTS} -Xms1200m -Xmx1200m -Xss1024K -XX:PermSize=512m -XX:MaxPermSize=1024m"1关闭效果
![]()

# 安装成功测试
浏览器输入URL``访问机器上的tomcat,出现如下界面即安装成功
![CentOS 7 Tomcat服务的安装与配置]()
# 安装Gzip
用来压缩和解压缩文件为后缀
.gz的文件
- 使用命令
yum install gzip安装gzip
# 安装Unzip
用来解压缩文件为后缀
.zip的文件
- 使用命令
yum install -y unzip安装unzip
# 安装Tree
以树形结构查看文件目录结构的
- 使用命令
yum install -y tree安装tree
# 安装Strace
追踪进程在干什么
- 使用命令
yum install -y strace安装strace
# 安装Redis
Redis比memcache的流行程度更高,功能强大,性能不低,非常哇塞的缓存中间件
Nginx可以通过插件化的第三方模块
redis2-nginx-module去连接Redis,redis2-nginx-module【这里的redis的2指的是协议2.0,不是版本2.0】是一个支持 Redis 2.0 协议的 Nginx upstream 模块,它可以让 Nginx 以非阻塞方式直接访问远方的 Redis 服务,同时支持 TCP 协议和 Unix Domain Socket 模式,并且可以启用强大的 Redis 连接池功能。
使用命令
yum install epel-release更新yum源关于源的这部分基本都没讲过,以后自己研究
使用命令
yum install -y redis安装redisyum安装的坏处是软件的版本可能比较老,只是安装比较方便,但是redis的协议没怎么变化,不影响使用效果
# Linux命令大全
# 系统操作
uname -a查看当前系统的版本uname -r查看当前系统的linux内核版本,系统类型reboot重启linux系统使用
top命令能查看系统CPU和内存的消耗情况使用命令
free -h也能查看当前CPU和内存的消耗情况cat /etc/redhat-release查看当前系统的发行版版本
# 远程操作
使用Xshell对linux进行远程连接
多台linux虚拟机、多客户端、修改配置文件情况下原版界面不好用
使用命令
ip addr查看本机ip【inet】在Xshell点击新建会话,设置主机名称和远程linux主机地址
![]()
# 主机名
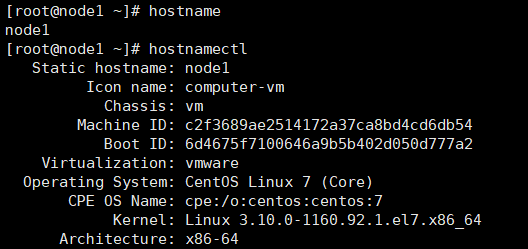
使用命令
hostname或hostnamectl可以查看本机主机名![]()
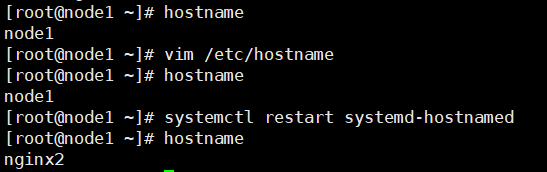
使用命令
vim /etc/hostname修改主机名称,修改后重启系统或者使用命令systemctl restart systemd-hostnamed重新加载主机名![]()
# 文件操作
# 创建文件
mkdir /usr/local/zookeeper- 创建zookeeper目录,该路径可以是相对路径,也可以是绝对路径
echo "www" >> /usr/local/nginx/1- 将内容www写入文件
/usr/local/nginx/1中
- 将内容www写入文件
# 移动文件
cp canal.deployer-1.1.4.tar.gz /usr/local/canal/- 将当前目录下的文件
canal.deployer-1.1.4.tar.gz拷贝一份到/usr/local/canal目录下,如果目标目录下存在同名文件会直接将同名文件内容覆盖
- 将当前目录下的文件
cp ngx_http_brotli_filter_module.so /usr/local/nginx/modulesmodules是一个空目录
- 将当前目录下的文件
ngx_http_brotli_filter_module.so拷贝到nginx目录下并重命名为modules
- 将当前目录下的文件
mv /opt/jdk/jdk1.8.0_261 /usr/local/java/jdk1.8.0_261将
/opt/jdk/jdk1.8.0_261文件移动到/usr/local/java目录下mv /opt/jdk/jdk1.8.0_261 /usr/local/java会直接把文件移至/usr/local目录下并将文件改名为java
mv ./* /opt/nginx/ngx_brotli-1.0.0rc/deps/brotli将当前目录下的所有文件移动【不保留】到指定目录
/opt/nginx/ngx_brotli-1.0.0rc/deps/brotli下tail -f /usr/local/nginx/logs/access.log能在linux客户端实时显示文件内容
# 文件名更改
mv apache-zookeeper-3.5.7-bin zookeeper-3.5.7- 将文件apache-zookeeper-3.5.7-bin改名为zookeeper-3.5.7【名字一般都要带版本号】
# 删除文件
rm -rf conf/- 删除conf目录下的所有文件
# 压缩文件
gzip命令是一款强大的文件压缩工具,它可以通过压缩文件的方式显著减小文件大小,常用于文件备份、数据传输和发布软件包
# Gzip
参数列表
参数 参数详情 功能 -c --stdout 将压缩数据输出到标准输出,保留原文件 -d --decompress 解压缩文件 -f --force 强制压缩文件,覆盖已有压缩文件 -r --recursive 递归地压缩目录及其内容 -t --test 测试压缩文件是否损坏 -v --verbose 显示压缩进度信息 -# #表示数字 #取值范围1-9,默认是6 -h --help 显示帮助信息 -k 压缩文件后保留原文件 常用命令示例
gzip example.txt将当前目录下的example.txt的文本文件压缩成压缩文件example.txt.gz,原始文件example.txt将被删除。
gzip -d example.txt.gz将压缩文件
example.txt.gz解压为example.txtgzip -r my_directory递归压缩当前目录下名为
my_directory的目录中的所有文件gzip -cd example.txt.gz在不解压压缩文件的前提下将压缩文件内容输出到终端
gzip -t example.txt.gz测试压缩文件是否完整或已经损坏,输出显示"example.txt.gz: OK",则表示文件完整无损。若显示错误消息,则表明文件可能已损坏。
gzip -f example.txt默认情况下,若压缩文件已经存在,gzip不会对该文件进行覆盖,使用该命令可以强制压缩文件并覆盖已有同名压缩文件
gzip -9 example.txt调整压缩级别来平衡压缩比和压缩速度。默认压缩级别为6,可以在1到9之间进行调整。较低的级别(例如1)可以更快地完成压缩,但压缩比较低;较高的级别(例如9)会产生更好的压缩比,但速度较慢
ls -l | gzip > file_list.gz显示当前目录的文件列表,并将列表内容压缩到名为file_list.gz的文件中
gzip file1.txt file2.txt file3.txt同时压缩file1.txt、file2.txt和file3.txt三个文件:
gzip -k example.txt压缩example.txt文件并保留原文件
# 解压文件
# Gunzip
gunzip -r ./能够解压当前目录下的所有gzip压缩方式压缩的文件,如果当前目录下有其他格式的文件会自动忽略
# Unzip
- ``
# Tar
tar zxvf canal.deployer-1.1.4.tar.gz- 解压文件
canal.deployer-1.1.4.tar.gz到当前目录
- 解压文件
tar zxvf canal.deployer-1.1.4.tar.gz -C /usr/local/canal
- 解压文件
canal.deployer-1.1.4.tar.gz到指定目录/usr/local/canal,该目录必须已经存在,且解压到指定目录时不能指定解压文件的名称,需要在解压目录单独更改文件名称
# 查找文件绝对路径
find / -name "hudson.model.UpdateCenter.xml"- 查找文件hudson.model.UpdateCenter.xml的绝对路径,如果找到了会返回路径,没找到说明没有该文件
# 目录操作
pwd显示当前目录绝对路径
rm -rf brotli-1.0.9强制递归删除当前目录下的
brotli-1.0.9目录,如果没有任何参数,会提示删除的是一个目录,如果只有递归删除-r会每删除一个文件确认一次删除单个文件,使用-rf就可以直接强制递归删除一个目录cd直接进入家目录
tree /usr/local/nginx/以树形图的形式展示一个目录的结构
[root@nginx1 ngx_tmp]#tree /ngx_tmp/ /ngx_tmp/ ├── 3 │ └── 25 ├── 5 │ └── 13 │ └── 4cb14647de7a8b8654a4ae94f15a0135 └── 9 └── 7d └── 6666cd76f96956469e7be39d750cc7d91
2
3
4
5
6
7
8
9
10mkdir -p /usr/local/nginx/ngx_logs递归创建子目录
/usr/local/nginx/ngx_logs
# 查找软件安装位置
which jdk
# 进程操作
# 查看端口
netstat -ntlp- 查看所有服务以及端口和进程号,可以使用grep进行过滤
使用命令
netstat -anp | grep 80- 查看端口80被占用的服务
使用命令
lsof -i:8080能查看指定的8080端口运行情况[root@Tomcat ~]# lsof -i:8080 COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME java 31259 root 49u IPv6 465528 0t0 TCP *:webcache (LISTEN)1
2
3
# 防火墙操作
systemctl start firewalld- 开启防火墙
systemctl restart firewalld- 重启防火墙
firewall-cmd --list-all- 查看防火墙已经配置的规则
systemctl disable firewalld.service虚拟机是内网上的机器,外网接不进来,关闭防火墙不一定意味着不安全,当然放行端口80更完美;学习过程不需要开启,生产的时候多数时候也不需要开启,除非机器有外网直接接入,或者公司比较大,要防外边和公司里的程序员,可能开启内部的监控和日志记录,一般中小型公司是不会开内网的防火墙的,因为有硬件防火墙或者云的安全组策略
- 禁止防火墙开机自启动
# 指定端口开启防火墙通讯
生产环境,防火墙打开外部请求数据包不能跟服务器监听端口通讯,需要打开指定的端口
firewall-cmd --permanent --add-port=3306/tcp- 开启3306端口端口通讯监听、tcp是协议,可以通过
netstat -ntlp查看
- 开启3306端口端口通讯监听、tcp是协议,可以通过
firewall-cmd --reload- 防火墙重新载入,使端口开放生效
firewall-cmd --query-port=3306/tcp- 查询3306端口是否开放
# 指定端口和指定ip访问
firewall-cmd --permanent --add-rich-rule="rule family="ipv4" source address="192.168.44.101" port protocol="tcp" port="8080" accept"- 防火墙富规则【富规则可以定义相对复杂的防火墙规则,添加到rich rule分组下,不是简单的开放端口】,开启指定ip:
192.168.44.101对本机8080端口的访问,添加该规则到ipv4这个family中
- 防火墙富规则【富规则可以定义相对复杂的防火墙规则,添加到rich rule分组下,不是简单的开放端口】,开启指定ip:
firewall-cmd --permanent --remove-rich-rule="rule family="ipv4" source address="192.168.44.101" port port="8080" protocol="tcp" accept"- 移除指定ip:
192.168.44.101对本机8080端口的访问
- 移除指定ip:
# Java操作
# 查看所有java相关命令
java- 能查看java开始的所有相关命令
# 脚本操作
# 启动shell脚本
bin/zkServer.sh start- 在bin目录上一层启动bin目录下的shell脚本zkServer.sh,可以使用快捷键
bin/后连按两次tab
- 在bin目录上一层启动bin目录下的shell脚本zkServer.sh,可以使用快捷键
./zkServer.sh start- 当前目录下启动shell脚本需要加上
./
- 当前目录下启动shell脚本需要加上
# 网络操作
# 常见公网DNS服务器
- 阿里
223.5.5.5223.6.6.6
- 腾讯
119.29.29.29182.254.118.118
- 百度
180.76.76.76
- 114DNS
114.114.114.114114.114.115.115
- 谷歌
8.8.8.88.8.4.4
# 查看windows本地IP
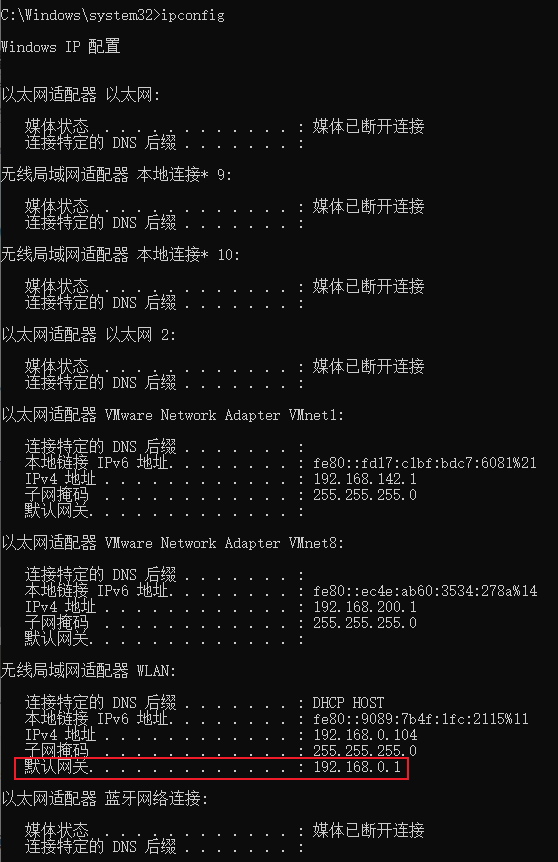
使用
ipconfig命令查出windows系统的ip地址![]()
# 查看Linux本地IP
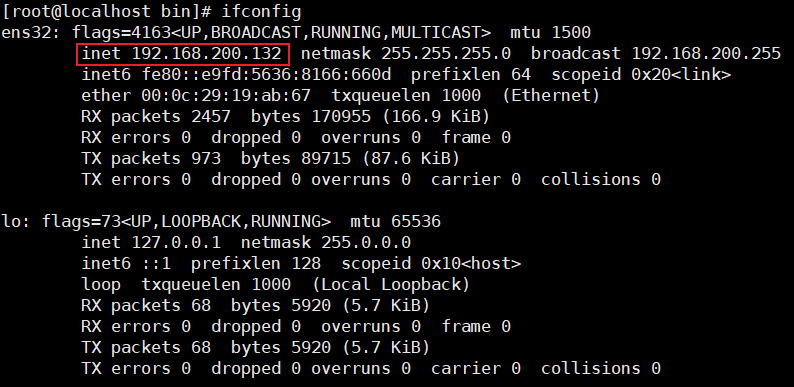
使用
ifconfig命令查看linux系统的ip地址inet就是本台linux机器的对外ip
![]()
使用命令
route -n可以查看网关地址![]()

# 修改linux的ip地址
生产环境不要随便更改ip地址,可能导致当前服务占用其他服务的ip导致其他服务无法使用
使用命令
ipconfig或ip addr查看当前系统的ip使用命令
vim /etc/sysconfig/network-scripts/ifcfg-ens32修改其中的IPADDR为目标IP迷你版没有vim使用命令
vi /etc/sysconfig/network-scripts/ifcfg-ens32修改其中的IPADDR为目标IP,开始无法联网下载vimifcfg-ens32对应
ip addr中的ens32,该目录下还有一个ifcfg-lo【lo是local的意思】,正好对应ip addr中的lo![]()
修改ifcfg-ens32
只需要关注以下三个参数,属性名都是区分大小写的
- BOOTPROTO:默认值是dhcp,意思是系统启动的时候会自动帮用户找一个ip,自定义IP必须将该属性值改为static,可以不加双引号
【以下为自定义IP才需要设置】
IPADDR:自定义固定ip需要对该属性值进行配置,IP地址可以配置多个,使用dhcp策略可以不设置
ONBOOT:意思是系统启动时是否启动网卡,默认是no,设置为yes下次启动就会自动启动网卡,不启动网卡会导致网络无法使用
NETMASK:意思是子网掩码,设置固定地址需要设置该属性值为
255.255.255.0GATEWAY:意思是网关,设置固定地址需要设置该属性值,通常来说网关设置成IPADDR相同网段,即前三位不变,最后一位设置成1【这里的示例是2】
![]()
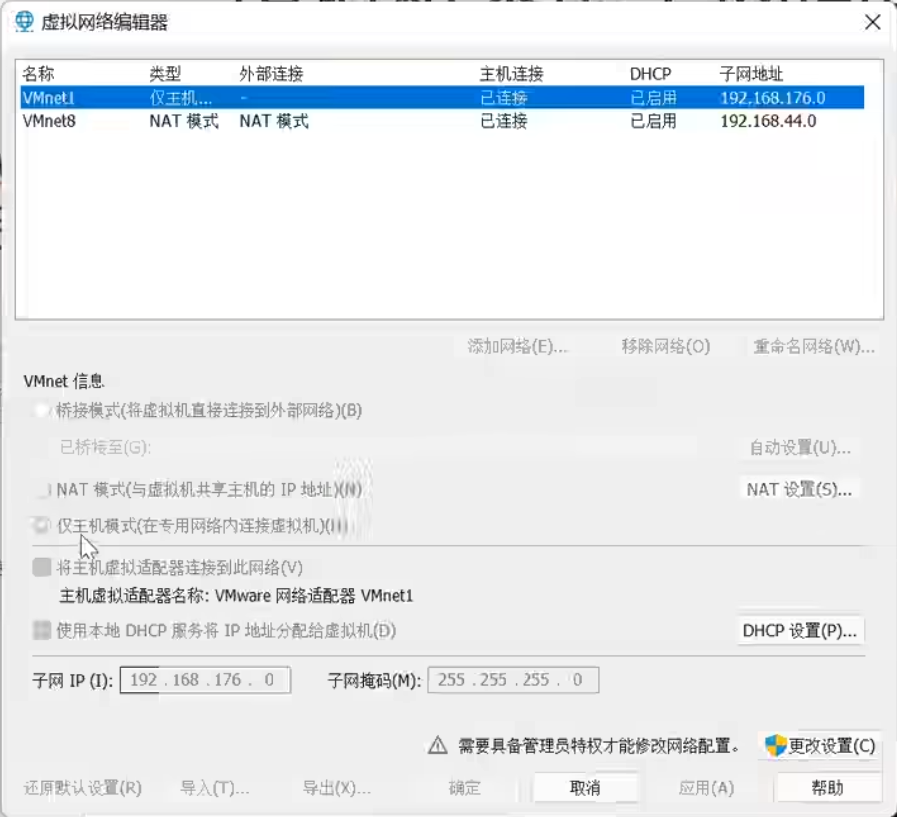
【虚拟网络编辑器】
两个选项卡对应两种虚拟网卡,分别对应两种接入互联网的模式,NAT模式对应VMnet8,点击VMnet8选项卡,下方子网IP会显示当前网段,更改这个网段可以更改虚拟机的网段
- 点击更改设置可以更改网段和网关,在弹窗选中VMnet8选项卡,点击NAT设置,可以修改网关地址,这个网关地址必须和ifcfg-ens32文件中的GATEWAY的地址保持一致
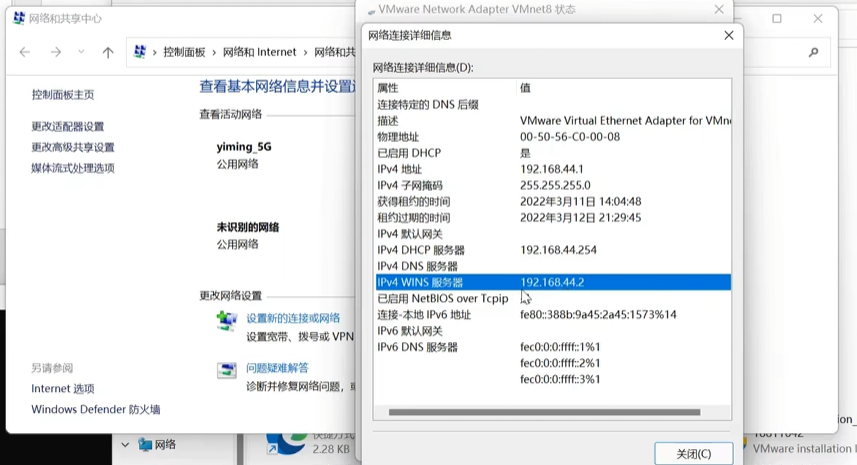
- 在windows的网络和共享中心菜单中,WLAN是无线网卡,还有VMnet1和VMnet8两个网卡,点开两个网卡点击详细信息,IPV4地址就是当前网卡地址,这个地址就是网关,虚拟机会通过该地址转发网络数据包,IPv4 WINS服务器的ip地址也可以作为网关【网关可以有两个】,设置NAT模式的虚拟机的网关地址必须和这个VMnet8选项卡下的windows网关中的一个相同才能正常联网
![]()
【windows的网关地址】
这里的网关地址决定了NAT模式的虚拟机的网关可以为
192.168.44.1和192.168.44.2![]()
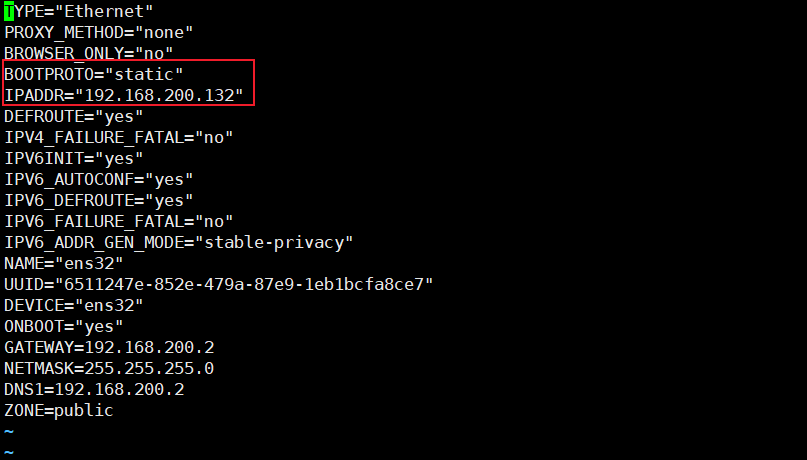
DNS1:DNS服务器,DNS服务器可以配置多个,可以直接设置成
8.8.8.8TYPE="Ethernet" PROXY_METHOD="none" BROWSER_ONLY="no" BOOTPROTO="static" IPADDR="192.168.200.135" DEFROUTE="yes" IPV4_FAILURE_FATAL="no" IPV6INIT="yes" IPV6_AUTOCONF="yes" IPV6_DEFROUTE="yes" IPV6_FAILURE_FATAL="no" IPV6_ADDR_GEN_MODE="stable-privacy" NAME="ens32" UUID="6511247e-852e-479a-87e9-1eb1bcfa8ce7" DEVICE="ens32" ONBOOT="yes" GATEWAY=192.168.200.2 NETMASK=255.255.255.0 DNS1=192.168.200.2 ZONE=public1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
![]()
使用命令
systemctl restart network重启网络服务使用命令
ping www.baidu.com测试网络是否连通也可以ping DNS服务器地址来检查网络是否通畅
# 服务操作
- 使用命令
systemctl status firewalld查看防火墙状态 - 使用命令
systemctl stop firewalld关闭防火墙 - 使用命令
systemctl disable firewalld.service可以设置防火墙下次开机也不会自动启动
# Linux快捷键大全
# 系统快捷键
crtl+c结束未完成的指令- 在
vmware选中虚拟机使用快捷键ctrl+e按一下就快速关机
# Linux系统应用操作
# Vim快捷键
- u 撤销上一步的操作
- Ctrl+r 恢复上一步被撤销的操作
# Vim设置
突破Vim粘贴50行限制
类unix系统,Vim粘贴不能超过超过50行,以下是修改方法
在当前用户主目录
~编辑.vimrc,没有则新建- ”/“是根目录,”~“是家目录。Linux存储是以挂载的方式,相当于是树状的,源头就是”/“,也就是根目录。而每个用户都有”家“目录,也就是用户的个人目录,比如root用户的”家“目录就是/root,普通用户a的家目录就是/home/a.可以看到
.vimrc文件是vim的环境设置文件,全局vim的设置在/etc/vimrc文件中。但不建议修改/etc/vimrc文件,每个用户可以在用户根目录中设置vim,新建~/.vimrc,.vimrc目录是隐藏的,在家目录下使用命令vim .vimrc可以直接编辑该文件,但是使用ll命令无法显示
在
~/.vimrc文件中添加一行set viminfo='1000,<500'后的数字表示记住的最大的文件标记数<厚度数字表示每个寄存器最大保存的行数,上面的命令也就是小于500行
# 普通模式
快捷键
区分大小写
快捷键 效果 gg 光标定位到文件首行 V 进入可视模式 G 跳转到文件末尾行 y 复制到0号寄存器,即系统粘贴板 p 系统粘贴板内容粘贴到文本 o 进入编辑模式且光标立即置于下一行首位 快捷键组合
文件内容全选复制
键盘按
ggVGy,按键区分大小写,复制内容使用p按键粘贴到文本,如果vim没有设置默认情况下最多只能粘贴50行多行删除
💡删除第7-19行
命令行模式下
7,19d【起始行在前,末尾行在后,中间用逗号隔开,d表示执行删除命令】💡删除文件所有内容
在终断使用命令
echo '' > vim_test,将空字符串重定向到vim_test文件中
# 命令行模式
- 使用命令
set nu开启行号
# tree命令
tree需要安装应用tree来使用
# Curl命令
curl -H 'accept-encoding:br' -I http://192.168.200.131-H表示向请求头中添加信息,-I表示请求URL